
Self-Supervised Visual Tracking via Image Synthesis and Domain Adversarial Learning




Abstract
1. Introduction
- We propose a novel self-supervised tracking framework that leverages image synthesis and domain adversarial learning to enable effective training of deep tracking networks by using complete target instances without manual annotations.
- We incorporate domain adversarial learning into the training pipeline to reduce the domain gap between synthetic and real data, which mitigates overfitting and facilitates the extraction of robust and discriminative features.
- Extensive experiments on multiple benchmarks demonstrate that our method achieves comparable performance to supervised methods.
2. Related Work
2.1. Visual Tracking Method
2.2. Self-Supervised Visual Tracking
2.3. Image Synthesis Method
2.4. Domain Adversarial Learning
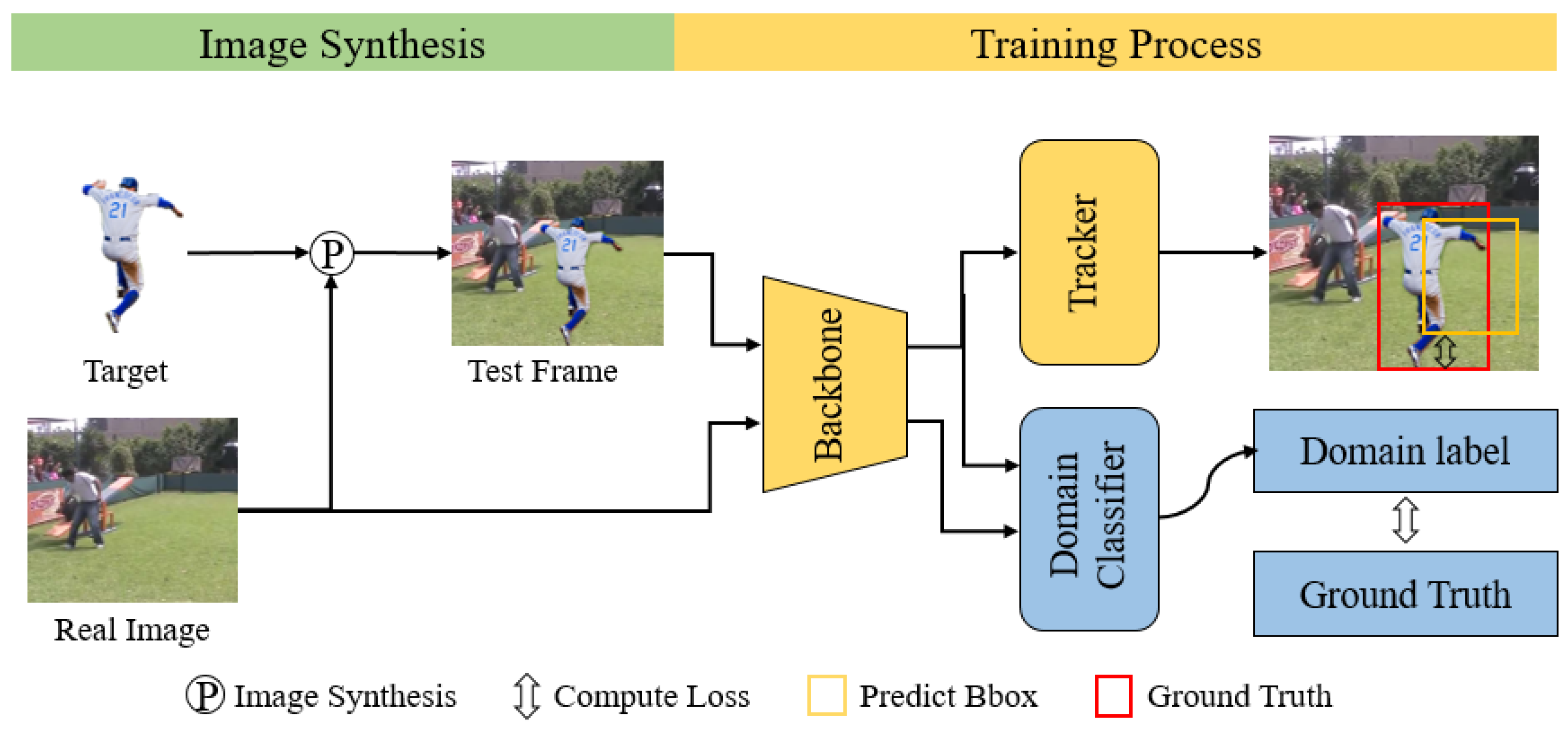
3. Methods
3.1. Construction of the Target Object Database
3.2. Image Synthesis Method
3.3. Domain Adversarial Training
4. Experiments
4.1. Experimental Details
4.2. Contrast Experiment
4.3. Ablation Study
4.3.1. Effectiveness of Each Component
4.3.2. Feature Visualization of the Effectiveness of Domain Adversarial Training
4.4. State-of-the-Art Comparison

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Supervised Method | Self-Supervised Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Trackers | Ours | BANDT [68] | TrTr [3] | TrDiMP [79] | KeepTrack [81] | PrDiMP-50 [72] | SiamFC++ [74] | DiMP-50 [18] | SiamRPN++ [75] | SiamDW [77] | Ours | ECO * [88] | LUDT * [89] | USOT * [9] |
| Precision (%) | 74.9 | 74.5 | 67.4 | 73.1 | 73.8 | 70.4 | 68.7 | 70.5 | 69.4 | 56.3 | 60.4 | 48.9 | 49.5 | 55.1 |
| Norm.prec (%) | 83.5 | 82.7 | 79.5 | 83.3 | 83.5 | 81.6 | 80.0 | 80.1 | 80.0 | 71.3 | 73.2 | 62.1 | 63.3 | 68.2 |
| Success (AUC) (%) | 78.7 | 78.5 | 70.7 | 78.4 | 78.1 | 75.8 | 75.4 | 74.0 | 73.3 | 61.1 | 66.5 | 56.1 | 56.3 | 59.9 |
| Trackers | Ours | SeqTrack [82] | DropTrack [83] | OSTrack [22] | GRM [23] | SwinTrack [33] | CSWinTT [84] | STARK [85] | TransT [4] | Ocean [73] | SiamFC++ [74] | DiMP-50 [18] | SiamDW [77] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | 90.0 | 89.1 | 91.0 | 88.7 | 90.0 | 90.2 | 87.2 | 88.4 | 89.9 | 92.0 | 89.6 | 88.8 | 89.2 |
| Success (AUC) (%) | 69.6 | 68.3 | 69.5 | 68.1 | 68.9 | 69.1 | 67.1 | 68.0 | 69.5 | 68.4 | 68.3 | 68.0 | 67.0 |
| Trackers | Ours | SiamTPN [69] | TrTr [3] | Ocean [73] | SiamFC++ [74] | SiamBAN [87] | DiMP-50 [18] | SiamDW [77] | HiFT [80] |
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | 82.7 | 82.3 | 83.9 | 82.3 | 81.0 | 83.3 | 85.8 | 77.6 | 78.7 |
| Success(AUC) (%) | 64.1 | 63.6 | 63.3 | 62.1 | 62.3 | 63.1 | 64.8 | 53.6 | 58.9 |
4.5. Qualitative Comparison
5. Limitations, Discussion, and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1–11. [Google Scholar]
- Mayer, C.; Danelljan, M.; Bhat, G.; Paul, M.; Paudel, D.P.; Yu, F.; Van Gool, L. Transforming model prediction for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8731–8740. [Google Scholar]
- Zhao, M.; Okada, K.; Inaba, M. Trtr: Visual tracking with transformer. arXiv 2021, arXiv:2105.03817. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Wang, N.; Song, Y.; Ma, C.; Zhou, W.; Liu, W.; Li, H. Unsupervised deep tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1308–1317. [Google Scholar]
- Yuan, D.; Chang, X.; Huang, P.Y.; Liu, Q.; He, Z. Self-supervised deep correlation tracking. IEEE Trans. Image Process. 2021, 30, 976–985. [Google Scholar] [CrossRef]
- Yuan, W.; Wang, M.Y.; Chen, Q. Self-supervised object tracking with cycle-consistent siamese networks. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October–24 January 2021; pp. 10351–10358. [Google Scholar]
- Sio, C.H.; Ma, Y.J.; Shuai, H.H.; Chen, J.C.; Cheng, W.H. S2siamfc: Self-supervised fully convolutional siamese network for visual tracking. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1948–1957. [Google Scholar]
- Zheng, J.; Ma, C.; Peng, H.; Yang, X. Learning to track objects from unlabeled videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13546–13555. [Google Scholar]
- Lai, Z.; Lu, E.; Xie, W. Mast: A memory-augmented self-supervised tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6479–6488. [Google Scholar]
- Li, X.; Liu, S.; De Mello, S.; Wang, X.; Kautz, J.; Yang, M.H. Joint-task self-supervised learning for temporal correspondence. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Wang, N.; Zhou, W.; Li, H. Contrastive transformation for self-supervised correspondence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 8 February 2021; Volume 35, pp. 10174–10182. [Google Scholar]
- Ndayikengurukiye, D.; Mignotte, M. CoSOV1Net: A Cone- and Spatial-Opponent Primary Visual Cortex-Inspired Neural Network for Lightweight Salient Object Detection. Sensors 2023, 23, 6450. [Google Scholar] [CrossRef]
- Emily L., D.; Vighnesh, B. Unsupervised learning of disentangled representations from video. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhao, D.; Li, Y.; Li, J.; Duan, X.; Ma, N.; Wang, Y. A Target Tracking Method Based on a Pyramid Channel Attention Mechanism. Sensors 2025, 25, 3214. [Google Scholar] [CrossRef] [PubMed]
- Shu, X.; Huang, F.; Qiu, Z.; Zhang, X.; Yuan, D. Learning Unsupervised Cross-Domain Model for TIR Target Tracking. Mathematics 2024, 12, 2882. [Google Scholar] [CrossRef]
- Li, X.; Pei, W.; Wang, Y.; He, Z.; Lu, H.; Yang, M.H. Self-supervised tracking via target-aware data synthesis. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 9186–9197. [Google Scholar] [CrossRef] [PubMed]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Shi, L.; Zhong, B.; Liang, Q.; Li, N.; Zhang, S.; Li, X. Explicit visual prompts for visual object tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26 February 2024; Volume 38, pp. 4838–4846. [Google Scholar]
- Lin, L.; Fan, H.; Zhang, Z.; Wang, Y.; Xu, Y.; Ling, H. Tracking meets lora: Faster training, larger model, stronger performance. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 300–318. [Google Scholar]
- Bai, Y.; Zhao, Z.; Gong, Y.; Wei, X. Artrackv2: Prompting autoregressive tracker where to look and how to describe. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 19048–19057. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 341–357. [Google Scholar]
- Gao, S.; Zhou, C.; Zhang, J. Generalized relation modeling for transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18686–18695. [Google Scholar]
- Cai, Y.; Liu, J.; Tang, J.; Wu, G. Robust object modeling for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 9589–9600. [Google Scholar]
- Li, Y.; Liu, M.; Wu, Y.; Wang, X.; Yang, X.; Li, S. Learning adaptive and view-invariant vision transformer for real-time UAV tracking. In Proceedings of the Forty-first International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Kang, B.; Chen, X.; Lai, S.; Liu, Y.; Liu, Y.; Wang, D. Exploring enhanced contextual information for video-level object tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 4194–4202. [Google Scholar]
- Xie, J.; Zhong, B.; Liang, Q.; Li, N.; Mo, Z.; Song, S. Robust tracking via mamba-based context-aware token learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 8727–8735. [Google Scholar]
- Zheng, Y.; Zhong, B.; Liang, Q.; Mo, Z.; Zhang, S.; Li, X. Odtrack: Online dense temporal token learning for visual tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26 February 2024; Volume 38, pp. 7588–7596. [Google Scholar]
- Li, X.; Zhong, B.; Liang, Q.; Li, G.; Mo, Z.; Song, S. MambaLCT: Boosting Tracking via Long-term Context State Space Model. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 4986–4994. [Google Scholar]
- Xu, C.; Zhong, B.; Liang, Q.; Zheng, Y.; Li, G.; Song, S. Less is More: Token Context-aware Learning for Object Tracking. arXiv 2025, arXiv:2501.00758. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Z.; Yu, H. Enhanced YOLOv5: An Efficient Road Object Detection Method. Sensors 2023, 23, 8355. [Google Scholar] [CrossRef]
- Yuan, D.; Liao, D.; Huang, F.; Qiu, Z.; Shu, X.; Tian, C.; Liu, Q. Hierarchical Attention Siamese Network for Thermal Infrared Target Tracking. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Lin, L.; Fan, H.; Zhang, Z.; Xu, Y.; Ling, H. Swintrack: A simple and strong baseline for transformer tracking. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 16743–16754. [Google Scholar]
- Li, W.; Xie, J.; Loy, C.C. Correlational image modeling for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15105–15115. [Google Scholar]
- Chen, B.; Li, P.; Bai, L.; Qiao, L.; Shen, Q.; Li, B.; Gan, W.; Wu, W.; Ouyang, W. Backbone is all your need: A simplified architecture for visual object tracking. In Proceedings of the European conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 375–392. [Google Scholar]
- Yuan, D.; Zhang, H.; Liu, Q.; Chang, X.; He, Z. Transformer-Based RGBT Tracking with Spatio-Temporal Information Fusion. IEEE Sens. Journal 2025, 25, 25386–25396. [Google Scholar] [CrossRef]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar]
- Zhao, H.; Wang, D.; Lu, H. Representation learning for visual object tracking by masked appearance transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18696–18705. [Google Scholar]
- Zhang, Z.; Xu, L.; Peng, D.; Rahmani, H.; Liu, J. Diff-tracker: Text-to-image diffusion models are unsupervised trackers. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 319–337. [Google Scholar]
- Liang, S.; Bai, Y.; Gong, Y.; Wei, X. Autoregressive Sequential Pretraining for Visual Tracking. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 7254–7264. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Jiang, J.; Wang, Z.; Zhao, M.; Li, Y.; Jiang, D. SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation. arXiv 2025, arXiv:2504.04519. [Google Scholar]
- Kostiv, M.; Adamovskyi, A.; Cherniavskyi, Y.; Varenyk, M.; Viniavskyi, O.; Krashenyi, I.; Dobosevych, O. Self-Supervised Real-Time Tracking of Military Vehicles in Low-FPS UAV Footage. In Proceedings of the 2025 International Conference on Military Communication and Information Systems (ICMCIS), Oerias, Portugal, 13–14 May 2025; pp. 1–8. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; Van De Weijer, J.; Danelljan, M.; Khan, F.S. Synthetic data generation for end-to-end thermal infrared tracking. IEEE Trans. Image Process. 2018, 28, 1837–1850. [Google Scholar] [CrossRef]
- Jiang, H.; Fels, S.; Little, J.J. Optimizing multiple object tracking and best view video synthesis. IEEE Trans. Multimed. 2008, 10, 997–1012. [Google Scholar] [CrossRef]
- Jiang, Y.; Han, D.; Cui, M.; Fan, Y.; Zhou, Y. A Video Target Tracking and Correction Model with Blockchain and Robust Feature Location. Sensors 2023, 23, 2408. [Google Scholar] [CrossRef] [PubMed]
- Kerim, A.; Celikcan, U.; Erdem, E.; Erdem, A. Using synthetic data for person tracking under adverse weather conditions. Image Vis. Comput. 2021, 111, 104187. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid data dreaming for object tracking. In Proceedings of the The DAVIS Challenge on Video Object Segmentation, Honolulu, HI, USA, 21–26 July 2017; pp. 1–6. [Google Scholar]
- Song, Y.; Zhang, Z.; Lin, Z.; Cohen, S.; Price, B.; Zhang, J.; Kim, S.Y.; Aliaga, D. Objectstitch: Object compositing with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18310–18319. [Google Scholar]
- Chen, Z.; Yang, J.; Li, F.; Feng, Z.; Chen, L.; Jia, L.; Li, P. Foreign Object Detection Method for Railway Catenary Based on a Scarce Image Generation Model and Lightweight Perception Architecture. In Proceedings of the 2025 International Conference on Military Communication and Information Systems (ICMCIS), Oerias, Portugal, 13–14 May 2025. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Rangwani, H.; Aithal, S.K.; Mishra, M.; Jain, A.; Radhakrishnan, V.B. A closer look at smoothness in domain adversarial training. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 18378–18399. [Google Scholar]
- Zhou, K.; Yang, Y.; Hospedales, T.; Xiang, T. Deep domain-adversarial image generation for domain generalisation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13025–13032. [Google Scholar]
- Uplavikar, P.M.; Wu, Z.; Wang, Z. All-in-One Underwater Image Enhancement Using Domain-Adversarial Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–8. [Google Scholar]
- Chen, M.; Zhao, S.; Liu, H.; Cai, D. Adversarial-learned loss for domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3521–3528. [Google Scholar]
- Acuna, D.; Zhang, G.; Law, M.T.; Fidler, S. f-Domain Adversarial Learning: Theory and Algorithms. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 66–75. [Google Scholar]
- Li, B.; François-Lavet, V.; Doan, T.; Pineau, J. Domain Adversarial Reinforcement Learning. arXiv 2021, arXiv:2102.07097. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Domain Adversarial Graph Convolutional Network for Fault Diagnosis Under Variable Working Conditions. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Xu, N.; Yang, L.; Fan, Y.; Yue, D.; Liang, Y.; Yang, J.; Huang, T. Youtube-vos: A large-scale video object segmentation benchmark. arXiv 2018, arXiv:1809.03327. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for UAV tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 445–461. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5374–5383. [Google Scholar]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. TrackingNet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Cieslak, M.C.; Castelfranco, A.M.; Roncalli, V.; Lenz, P.H.; Hartline, D.K. t-Distributed Stochastic Neighbor Embedding (t-SNE): A tool for eco-physiological transcriptomic analysis. Mar. Genom. 2020, 51, 100723. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Zhang, H.; Shi, J.; Ma, J. Bandt: A border-aware network with deformable transformers for visual tracking. IEEE Trans. Consum. Electron. 2023, 69, 377–390. [Google Scholar] [CrossRef]
- Xing, D.; Evangeliou, N.; Tsoukalas, A.; Tzes, A. Siamese transformer pyramid networks for real-time UAV tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2139–2148. [Google Scholar]
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph attention tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9543–9552. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.; Leibe, B. Siam R-CNN: Visual tracking by re-detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6578–6588. [Google Scholar]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7183–7192. [Google Scholar]
- Zhang, Z.; Peng, H. Ocean: Object-aware Anchor-free Tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- Fu, Z.; Liu, Q.; Fu, Z.; Wang, Y. Stmtrack: Template-free visual tracking with space-time memory networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13774–13783. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider Siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4591–4600. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4660–4669. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1571–1580. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. Hift: Hierarchical feature transformer for aerial tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15457–15466. [Google Scholar]
- Mayer, C.; Danelljan, M.; Paudel, D.P.; Van Gool, L. Learning target candidate association to keep track of what not to track. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13444–13454. [Google Scholar]
- Chen, X.; Peng, H.; Wang, D.; Lu, H.; Hu, H. Seqtrack: Sequence to sequence learning for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14572–14581. [Google Scholar]
- Wu, Q.; Yang, T.; Liu, Z.; Wu, B.; Shan, Y.; Chan, A.B. Dropmae: Masked autoencoders with spatial-attention dropout for tracking tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14561–14571. [Google Scholar]
- Song, Z.; Yu, J.; Chen, Y.P.P.; Yang, W. Transformer tracking with cyclic shifting window attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8791–8800. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10448–10457. [Google Scholar]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-performance long-term tracking with meta-updater. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6298–6307. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Wang, N.; Zhou, W.; Song, Y.; Ma, C.; Liu, W.; Li, H. Unsupervised deep representation learning for real-time tracking. Int. J. Comput. Vis. 2021, 129, 400–418. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]






| Domain Adversarial | Image Transformation | Precision (%) | AUC (%) |
|---|---|---|---|
| 86.2 | 65.1 | ||
| ✔ | 88.1 | 67.3 | |
| ✔ | 88.6 | 67.2 | |
| ✔ | ✔ | 90.0 | 69.6 |
| Trackers | AO (%) | SR0.50 (%) | SR0.75 (%) |
|---|---|---|---|
| BANDT [68] | 64.5 | 73.8 | 54.2 |
| SiamTPN [69] | 57.6 | 68.6 | 44.1 |
| SiamGAT [70] | 62.7 | 74.3 | 48.8 |
| SiamR-CNN [71] | 64.9 | 72.8 | 59.7 |
| PrDiMP-50 [72] | 63.4 | 73.8 | 54.3 |
| Ocean [73] | 61.1 | 72.1 | 47.3 |
| SiamFC++ [74] | 59.5 | 69.5 | 47.3 |
| DiMP-50 [18] | 61.1 | 71.7 | 49.2 |
| SiamDW [77] | 42.9 | 48.3 | 14.7 |
| ATOM [78] | 55.6 | 63.4 | 40.2 |
| SiamRPN++ [75] | 51.7 | 61.6 | 32.5 |
| STMTrack [76] | 64.2 | 73.7 | 57.5 |
| Ours | 66.4 | 77.9 | 59.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, G.; Zhou, S.; Tang, J.; Zhang, X.; Liu, Q.; Yuan, D. Self-Supervised Visual Tracking via Image Synthesis and Domain Adversarial Learning. Sensors 2025, 25, 4621. https://doi.org/10.3390/s25154621
Geng G, Zhou S, Tang J, Zhang X, Liu Q, Yuan D. Self-Supervised Visual Tracking via Image Synthesis and Domain Adversarial Learning. Sensors. 2025; 25(15):4621. https://doi.org/10.3390/s25154621
Chicago/Turabian StyleGeng, Gu, Sida Zhou, Jianing Tang, Xinming Zhang, Qiao Liu, and Di Yuan. 2025. "Self-Supervised Visual Tracking via Image Synthesis and Domain Adversarial Learning" Sensors 25, no. 15: 4621. https://doi.org/10.3390/s25154621
APA StyleGeng, G., Zhou, S., Tang, J., Zhang, X., Liu, Q., & Yuan, D. (2025). Self-Supervised Visual Tracking via Image Synthesis and Domain Adversarial Learning. Sensors, 25(15), 4621. https://doi.org/10.3390/s25154621