
SBCS-Net: Sparse Bayesian and Deep Learning Framework for Compressed Sensing in Sensor Networks

Abstract
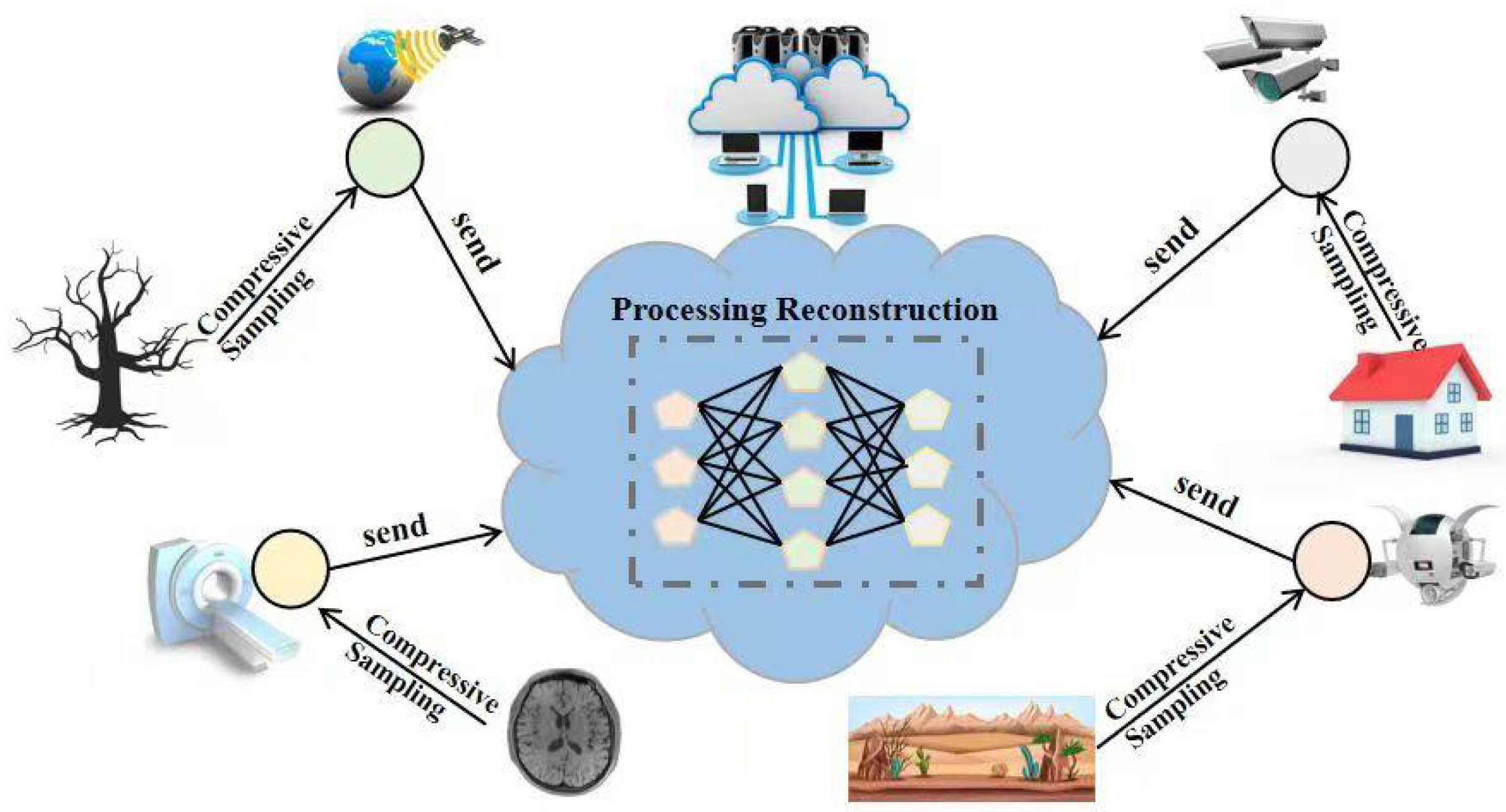
1. Introduction
- A novel compressed sensing framework, SBCS-Net, is proposed, which achieves a deep iterative integration of the core principles of SBL with deep neural networks (CNN and Transformer). Through a unique structural design, SBCS-Net effectively combines SBL’s adaptive sparse modeling, CNN’s local feature extraction, and Transformer’s global contextual awareness capabilities. It aims to achieve higher reconstruction accuracy and better noise robustness, particularly under challenging conditions such as low sampling rates and strong noise.
- Leveraging the end-to-end learning capability of neural networks, key hyperparameters from traditional BCS—such as those controlling sparsity and noise precision—are transformed into learnable parameters within the network. This design not only significantly alleviates the difficulty of hyperparameter optimization inherent in BCS but also effectively reduces the overhead of large-scale matrix computations, while retaining the theoretical advantages of Bayesian inference in uncertainty modeling and adaptive sparsity.
- The proposed model has undergone extensive experimental validation on multiple public datasets covering diverse scenarios and has been comprehensively compared with current mainstream deep learning CS methods. Preliminary experimental results indicate that the proposed method can achieve superior reconstruction quality and visual effects under various conditions, especially in cases of low sampling rates and noisy measurements.
2. Related Work
2.1. Traditional Compressed Sensing
2.2. Bayesian Compressed Sensing
2.3. Deep Compressed Sensing
2.4. Transformer
2.5. Application Scenario: SBCS-Net in Sensor Networks
3. Proposed Method
3.1. Sampling Module
3.2. Initial Reconstruction Stage
3.3. Deep Reconstruction Stage
| Algorithm 1 Forward propagation for SBCS-Net. |
| Require: Number of iterations n, measurements , sensing matrix , initial reconstruction matrix , trainable parameters Ensure: Reconstructed image
|
3.3.1. Bayesian Sparse Estimation
3.3.2. Pre-Block: Local Feature Optimization
3.3.3. Encoder: Global Feature Modeling
3.3.4. Decoder: Signal Reconstruction to Image Space
3.3.5. Post-Block: Final Refinement and Output Stage
3.3.6. Final Output Stage: Reconstructed Signal Generation
3.4. Loss Function
3.5. Computational Complexity Analysis
4. Experimental Results
4.1. Experimental Settings
4.2. Comparisons
4.2.1. Comparisons with State-of-the-Art Methods
4.2.2. Statistical Significance Analysis
4.3. Noise Robustness Analysis
4.4. Complexity Analysis
4.5. Ablation Studies
4.6. Comparison with Traditional Compressed Sensing Algorithms
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nassra, I.; Capella, J.V. Data compression techniques in IoT-enabled wireless body sensor networks: A systematic literature review and research trends for QoS improvement. Internet Things 2023, 23, 100806. [Google Scholar] [CrossRef]
- Han, X.H.; Wang, J.; Jiang, H. Recent Advancements in Hyperspectral Image Reconstruction from a Compressive Measurement. Sensors 2025, 25, 3286. [Google Scholar] [CrossRef]
- Jalal, A.; Arvinte, M.; Daras, G.; Price, E.; Dimakis, A.G.; Tamir, J. Robust compressed sensing mri with deep generative priors. Adv. Neural Inf. Process. Syst. 2021, 34, 14938–14954. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Nyquist, H. Certain topics in telegraph transmission theory. Trans. Am. Inst. Electr. Eng. 1928, 47, 617–644. [Google Scholar] [CrossRef]
- Ke, Z.; Huang, W.; Cui, Z.X.; Cheng, J.; Jia, S.; Wang, H.; Liu, X.; Zheng, H.; Ying, L.; Zhu, Y.; et al. Learned low-rank priors in dynamic MR imaging. IEEE Trans. Med. Imaging 2021, 40, 3698–3710. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Mahadevappa, M.; Dutta, P.K. Compressive holography from poisson noise plagued holograms using expectation-maximization. IEEE Trans. Comput. Imaging 2020, 6, 857–867. [Google Scholar] [CrossRef]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient Projection for Sparse Reconstruction: Application to Compressed Sensing and Other Inverse Problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 2002, 86, 2278–2324. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 261–272. [Google Scholar]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Dai, W.; Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- Chen, W.; Yang, C.; Yang, X. FSOINET: Feature-space optimization-inspired network for image compressive sensing. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2460–2464. [Google Scholar]
- Kumar, A.; Upadhyay, N.; Ghosal, P.; Chowdhury, T.; Das, D.; Mukherjee, A.; Nandi, D. CSNet: A new DeepNet framework for ischemic stroke lesion segmentation. Comput. Methods Programs Biomed. 2020, 193, 105524. [Google Scholar] [CrossRef] [PubMed]
- Metzler, C.A.; Maleki, A.; Baraniuk, R.G. From denoising to compressed sensing. IEEE Trans. Inf. Theory 2016, 62, 5117–5144. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, J. Lightweight Dilated Residual Convolution AMP Network for Image Compressed Sensing. In Proceedings of the 4th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 7–9 April 2023; pp. 747–752. [Google Scholar]
- Gilton, D.; Ongie, G.; Willett, R. Neumann networks for linear inverse problems in imaging. IEEE Trans. Comput. Imaging 2019, 6, 328–343. [Google Scholar] [CrossRef]
- Song, J.; Mou, C.; Wang, S.; Ma, S.; Zhang, J. Optimization-inspired cross-attention transformer for compressive sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6174–6184. [Google Scholar]
- Gao, X.; Chen, B.; Yao, X.; Yuan, Y. SSM-Net: Enhancing Compressed Sensing Image Reconstruction with Mamba Architecture and Fast Iterative Shrinking Threshold Algorithm Optimization. Sensors 2025, 25, 1026. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Gan, H. USB-Net: Unfolding Split Bregman Method With Multi-Phase Feature Integration for Compressive Imaging. IEEE Trans. Image Process. 2025, 34, 925–938. [Google Scholar] [CrossRef] [PubMed]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Mousavi, A.; Dasarathy, G.; Baraniuk, R.G. Deepcodec: Adaptive sensing and recovery via deep convolutional neural networks. arXiv 2017, arXiv:1707.03386. [Google Scholar] [CrossRef]
- Yao, H.; Dai, F.; Zhang, S.; Zhang, Y.; Tian, Q.; Xu, C. Dr2-net: Deep residual reconstruction network for image compressive sensing. Neurocomputing 2019, 359, 483–493. [Google Scholar] [CrossRef]
- Yu, F.; Qian, Y.; Zhang, X.; Gil-Ureta, F.; Jackson, B.; Bennett, E.; Zhang, H. Dpa-net: Structured 3d abstraction from sparse views via differentiable primitive assembly. In Proceedings of the European Conference on Computer Vision, Dublin, Ireland, 17–18 September 2025; pp. 454–471. [Google Scholar]
- Zhao, W.; Zhao, F.; Wang, D.; Lu, H. Defocus blur detection via multi-stream bottom-top-bottom network. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1884–1897. [Google Scholar] [CrossRef] [PubMed]
- Kabkab, M.; Samangouei, P.; Chellappa, R. Task-aware compressed sensing with generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Sun, Y.; Chen, J.; Liu, Q.; Liu, G. Learning image compressed sensing with sub-pixel convolutional generative adversarial network. Pattern Recognit. 2020, 98, 107051. [Google Scholar] [CrossRef]
- Gan, H.; Gao, Y.; Liu, C.; Chen, H.; Zhang, T.; Liu, F. AutoBCS: Block-based image compressive sensing with data-driven acquisition and noniterative reconstruction. IEEE Trans. Cybern. 2021, 53, 2558–2571. [Google Scholar] [CrossRef] [PubMed]
- Xiong, F.; Zhou, J.; Zhao, Q.; Lu, J.; Qian, Y. MAC-Net: Model-aided nonlocal neural network for hyperspectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–14. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Shen, M.; Gan, H.; Ning, C.; Hua, Y.; Zhang, T. TransCS: A transformer-based hybrid architecture for image compressed sensing. IEEE Trans. Image Process. 2022, 31, 6991–7005. [Google Scholar] [CrossRef] [PubMed]
- Error, M.S. Mean squared error. In The Concise Encyclopedia of Statistics; Springer: New York, NY, USA, 2008; Volume 5. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Lohit, S.; Kulkarni, K.; Kerviche, R.; Turaga, P.; Ashok, A. Convolutional neural networks for noniterative reconstruction of compressively sensed images. IEEE Trans. Comput. Imaging 2018, 4, 326–340. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Guildford, UK, 3–7 September 2012. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Özyurt, F.; Avcı, E.; Sert, E. UC-Merced Image Classification with CNN Feature Reduction Using Wavelet Entropy Optimized with Genetic Algorithm. Trait. Du Signal 2020, 37, 347–353. [Google Scholar] [CrossRef]
- Ye, D.; Ni, Z.; Wang, H.; Zhang, J.; Wang, S.; Kwong, S. CSformer: Bridging convolution and transformer for compressive sensing. IEEE Trans. Image Process. 2023, 32, 2827–2842. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Methods | 0.01 | 0.04 | 0.10 | 0.25 | 0.30 | 0.40 | 0.50 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Set5 | ISTA-Net+ (CVPR2018) | 20.25 | 0.5608 | 23.42 | 0.6287 | 28.47 | 0.8309 | 34.02 | 0.9188 | 35.38 | 0.9397 | 37.44 | 0.9573 | 39.25 | 0.9689 |
| CSNet (TIP2019) | 20.15 | 0.5447 | 27.12 | 0.7988 | 31.07 | 0.8925 | 35.89 | 0.9473 | 37.25 | 0.9473 | 38.91 | 0.9611 | 40.74 | 0.9691 | |
| CSformer (TIP2023) | 21.84 | 0.5892 | 29.27 | 0.8239 | 33.04 | 0.9243 | 37.04 | 0.9583 | 38.44 | 0.9614 | 40.62 | 0.9723 | 42.37 | 0.9793 | |
| AMP-Net (TIP2021) | 20.45 | 0.5563 | 27.25 | 0.8065 | 31.43 | 0.8977 | 36.25 | 0.9514 | 37.82 | 0.9583 | 39.55 | 0.9694 | 41.48 | 0.9756 | |
| TransCS (TIP2022) | 22.98 | 0.6287 | 29.02 | 0.8215 | 32.74 | 0.9197 | 37.26 | 0.9652 | 38.53 | 0.9693 | 41.40 | 0.9773 | 42.42 | 0.9852 | |
| SBCS-Net (Ours) | 23.50 | 0.6305 | 29.32 | 0.8252 | 33.17 | 0.9252 | 37.61 | 0.9658 | 38.74 | 0.9712 | 41.81 | 0.9796 | 42.72 | 0.9858 | |
| UCMerced | ISTA-Net+ (CVPR2018) | 17.52 | 0.4294 | 22.23 | 0.6138 | 25.65 | 0.7751 | 26.44 | 0.8859 | 31.43 | 0.9173 | 33.69 | 0.9383 | 36.71 | 0.9568 |
| CSNet (TIP2019) | 19.47 | 0.4473 | 24.16 | 0.6485 | 26.92 | 0.8059 | 28.93 | 0.9174 | 33.25 | 0.9258 | 34.79 | 0.9578 | 38.97 | 0.9695 | |
| CSformer (TIP2023) | 21.06 | 0.4793 | 24.52 | 0.6821 | 27.89 | 0.8396 | 33.72 | 0.9329 | 34.21 | 0.9418 | 37.19 | 0.9605 | 39.33 | 0.9712 | |
| AMP-Net (TIP2021) | 19.23 | 0.4416 | 23.87 | 0.6543 | 27.64 | 0.8147 | 29.92 | 0.9238 | 34.17 | 0.9349 | 35.68 | 0.9691 | 39.46 | 0.9783 | |
| TransCS (TIP2022) | 20.82 | 0.4769 | 24.39 | 0.6807 | 28.14 | 0.8409 | 33.97 | 0.9374 | 35.07 | 0.9473 | 38.02 | 0.9685 | 39.58 | 0.9780 | |
| SBCS-Net (Ours) | 21.38 | 0.4830 | 24.97 | 0.6895 | 28.94 | 0.8476 | 34.35 | 0.9412 | 35.66 | 0.9523 | 37.98 | 0.9683 | 40.18 | 0.9785 | |
| BrainImages | ISTA-Net+ (CVPR2018) | 22.59 | 0.6591 | 26.95 | 0.7852 | 29.24 | 0.8471 | 32.09 | 0.8893 | 33.29 | 0.9134 | 34.92 | 0.9287 | 36.63 | 0.9517 |
| CSNet (TIP2019) | 24.23 | 0.6962 | 29.73 | 0.8237 | 31.53 | 0.8842 | 34.49 | 0.9257 | 36.71 | 0.9403 | 37.08 | 0.9411 | 38.37 | 0.9512 | |
| CSformer (TIP2023) | 25.94 | 0.7046 | 30.49 | 0.8421 | 32.87 | 0.8997 | 35.43 | 0.9368 | 36.88 | 0.9523 | 37.59 | 0.9576 | 39.42 | 0.9711 | |
| AMP-Net (TIP2021) | 24.35 | 0.6982 | 28.47 | 0.8296 | 31.94 | 0.8863 | 34.72 | 0.9293 | 36.84 | 0.9437 | 37.62 | 0.9423 | 38.89 | 0.9568 | |
| TransCS (TIP2022) | 25.83 | 0.7032 | 30.97 | 0.8546 | 33.11 | 0.9082 | 35.62 | 0.9426 | 38.05 | 0.9572 | 38.89 | 0.9672 | 40.09 | 0.9715 | |
| SBCS-Net (Ours) | 26.46 | 0.7165 | 30.17 | 0.8306 | 33.17 | 0.9025 | 36.49 | 0.9483 | 37.31 | 0.9653 | 38.70 | 0.9676 | 40.17 | 0.9730 | |
| Urban100 | ISTA-Net+ (CVPR2018) | 15.23 | 0.4127 | 19.65 | 0.5351 | 23.44 | 0.7165 | 28.78 | 0.8825 | 30.04 | 0.9061 | 32.32 | 0.9373 | 34.36 | 0.9571 |
| CSNet (TIP2019) | 15.89 | 0.4438 | 19.69 | 0.5973 | 23.17 | 0.7789 | 28.76 | 0.9033 | 29.52 | 0.9278 | 32.83 | 0.9462 | 33.47 | 0.9627 | |
| CSformer (TIP2023) | 18.92 | 0.4893 | 22.57 | 0.6781 | 25.27 | 0.8213 | 30.57 | 0.9287 | 31.07 | 0.9313 | 33.21 | 0.9575 | 34.23 | 0.9721 | |
| AMP-Net (TIP2021) | 17.84 | 0.4562 | 20.74 | 0.6013 | 23.90 | 0.7859 | 29.55 | 0.9174 | 30.44 | 0.9317 | 33.26 | 0.9521 | 34.65 | 0.9702 | |
| TransCS (TIP2022) | 19.53 | 0.5104 | 22.30 | 0.6756 | 25.87 | 0.8347 | 30.46 | 0.9234 | 31.47 | 0.9446 | 33.49 | 0.9621 | 34.58 | 0.9735 | |
| SBCS-Net (Ours) | 19.43 | 0.4925 | 21.79 | 0.6671 | 25.43 | 0.8254 | 30.78 | 0.9297 | 31.21 | 0.9372 | 33.34 | 0.9583 | 34.93 | 0.9763 | |
| BSD100 | ISTA-Net+ (CVPR2018) | 17.45 | 0.4234 | 22.21 | 0.5397 | 24.89 | 0.6837 | 28.83 | 0.8379 | 29.92 | 0.8673 | 31.77 | 0.9063 | 33.52 | 0.9357 |
| CSNet (TIP2019) | 18.23 | 0.4576 | 23.77 | 0.6497 | 26.31 | 0.7714 | 30.04 | 0.8997 | 30.69 | 0.9135 | 32.94 | 0.9299 | 34.96 | 0.9478 | |
| CSformer (TIP2023) | 22.42 | 0.4892 | 24.96 | 0.6709 | 26.54 | 0.7749 | 30.75 | 0.9022 | 31.54 | 0.9189 | 34.21 | 0.9443 | 35.91 | 0.9589 | |
| AMP-Net (TIP2021) | 18.67 | 0.4623 | 24.04 | 0.6537 | 26.16 | 0.7688 | 30.13 | 0.9002 | 30.88 | 0.9142 | 33.24 | 0.9379 | 35.43 | 0.9517 | |
| TransCS (TIP2022) | 22.26 | 0.4848 | 24.68 | 0.6637 | 27.60 | 0.7953 | 31.45 | 0.9047 | 32.27 | 0.9215 | 34.52 | 0.9499 | 36.52 | 0.9671 | |
| SBCS-Net (Ours) | 22.53 | 0.5062 | 25.12 | 0.6716 | 27.76 | 0.7982 | 31.54 | 0.9124 | 32.79 | 0.9237 | 34.96 | 0.9522 | 36.89 | 0.9688 | |
| AMP-Net (TIP2021) | Csformer (TIP2023) | TransCS (TIP2022) | SBCS-Net | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| 0.001 | 0.04 | 23.28 | 0.5475 | 24.17 | 0.5683 | 23.76 | 0.5578 | 24.48 | 0.5824 |
| 0.10 | 25.32 | 0.6558 | 26.29 | 0.6872 | 25.53 | 0.6814 | 26.72 | 0.6933 | |
| 0.25 | 27.73 | 0.7930 | 28.24 | 0.8013 | 28.68 | 0.8087 | 29.24 | 0.8267 | |
| 0.30 | 28.37 | 0.8007 | 28.97 | 0.8279 | 29.23 | 0.8316 | 29.62 | 0.8422 | |
| 0.002 | 0.04 | 22.59 | 0.4879 | 23.21 | 0.4957 | 23.46 | 0.5083 | 23.67 | 0.5279 |
| 0.10 | 24.17 | 0.6052 | 25.31 | 0.6278 | 24.81 | 0.6169 | 25.50 | 0.6311 | |
| 0.25 | 27.23 | 0.7583 | 27.53 | 0.7597 | 27.59 | 0.7618 | 27.85 | 0.7746 | |
| 0.30 | 27.64 | 0.7625 | 28.05 | 0.7678 | 28.17 | 0.7724 | 28.31 | 0.7912 | |
| 0.004 | 0.04 | 20.56 | 0.4317 | 21.39 | 0.4423 | 21.97 | 0.4526 | 22.38 | 0.4672 |
| 0.10 | 22.53 | 0.5289 | 23.48 | 0.5413 | 23.16 | 0.5326 | 24.23 | 0.5583 | |
| 0.25 | 25.41 | 0.6825 | 25.54 | 0.6849 | 25.97 | 0.6854 | 26.21 | 0.7085 | |
| 0.30 | 25.68 | 0.7138 | 25.79 | 0.7151 | 26.19 | 0.7164 | 26.75 | 0.7399 | |
| 0.006 | 0.04 | 20.16 | 0.3859 | 20.77 | 0.3912 | 21.44 | 0.4079 | 21.83 | 0.4179 |
| 0.10 | 22.76 | 0.4827 | 22.77 | 0.4993 | 22.79 | 0.5064 | 23.41 | 0.5138 | |
| 0.25 | 24.35 | 0.6572 | 24.69 | 0.6597 | 25.04 | 0.6645 | 25.17 | 0.6728 | |
| 0.30 | 24.69 | 0.6917 | 24.89 | 0.6983 | 25.43 | 0.7034 | 25.93 | 0.7174 | |
| AMP-Net (TIP2021) | Csformer (TIP2023) | TransCS (TIP2022) | SBCS-Net | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| 0.02 | 0.04 | 19.05 | 0.3729 | 19.93 | 0.3829 | 19.87 | 0.3814 | 20.01 | 0.3863 |
| 0.10 | 19.54 | 0.4977 | 20.72 | 0.5044 | 20.39 | 0.5032 | 20.92 | 0.5099 | |
| 0.25 | 21.71 | 0.6783 | 21.99 | 0.6837 | 22.07 | 0.6845 | 22.70 | 0.6864 | |
| 0.30 | 22.14 | 0.7175 | 22.10 | 0.7195 | 23.09 | 0.7214 | 23.29 | 0.7250 | |
| 0.05 | 0.04 | 15.08 | 0.2219 | 16.93 | 0.2331 | 17.18 | 0.2385 | 17.35 | 0.2405 |
| 0.10 | 16.59 | 0.3422 | 17.51 | 0.3591 | 17.46 | 0.3579 | 17.95 | 0.3609 | |
| 0.25 | 18.13 | 0.5490 | 18.52 | 0.5604 | 19.04 | 0.5601 | 19.34 | 0.5690 | |
| 0.30 | 18.27 | 0.6018 | 18.27 | 0.6093 | 19.54 | 0.6159 | 19.84 | 0.6209 | |
| 0.10 | 0.04 | 13.27 | 0.1430 | 14.73 | 0.1544 | 14.72 | 0.1520 | 15.00 | 0.1577 |
| 0.10 | 14.06 | 0.2669 | 15.21 | 0.2713 | 15.44 | 0.2769 | 15.45 | 0.2747 | |
| 0.25 | 15.58 | 0.4776 | 16.07 | 0.4959 | 16.57 | 0.4943 | 16.61 | 0.4996 | |
| 0.30 | 15.93 | 0.5423 | 16.54 | 0.5517 | 16.99 | 0.5523 | 17.04 | 0.5591 | |
| Methods | GPU Time Consumption (s) | Platform | ||||
|---|---|---|---|---|---|---|
| ISTA-Net+ | 0.0227 | 0.0232 | 0.0238 | 0.0241 | 0.0247 | RTX 4090 |
| CSNet | 0.0078 | 0.0084 | 0.0089 | 0.0095 | 0.0099 | |
| CSformer | 0.0469 | 0.0471 | 0.0476 | 0.0480 | 0.0486 | |
| AMP-Net | 0.0165 | 0.0177 | 0.0181 | 0.0189 | 0.0194 | |
| TransCS | 0.0241 | 0.0245 | 0.0247 | 0.0251 | 0.0257 | |
| SBCS-Net | 0.0492 | 0.0494 | 0.0495 | 0.0496 | 0.0499 | |
| Methods | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | Run Time | PSNR | Run Time | PSNR | Run Time | ||||
| CPU | GPU | CPU | GPU | CPU | GPU | ||||
| CO-SBCS-Net | 26.42 | 0.118 | 0.0413 | 30.19 | 0.121 | 0.0413 | 30.97 | 0.134 | 0.0414 |
| TO-SBCS-Net | 26.53 | 0.109 | 0.0439 | 30.43 | 0.115 | 0.0441 | 31.18 | 0.119 | 0.0442 |
| SBCS-Net | 27.76 | 0.221 | 0.0492 | 31.54 | 0.224 | 0.0494 | 32.79 | 0.235 | 0.0495 |
| Layer | CO-SBCS-Net | TO-SBCS-Net | SBCS-Net | |
|---|---|---|---|---|
| PSNR | PSNR | PSNR | ||
| 2 | 0.04 | 22.53 | 21.07 | 24.38 |
| 0.10 | 27.52 | 26.74 | 30.29 | |
| 0.25 | 28.17 | 31.02 | 31.49 | |
| 4 | 0.04 | 26.46 | 27.33 | 28.59 |
| 0.10 | 30.04 | 31.59 | 32.83 | |
| 0.25 | 34.63 | 35.87 | 37.26 | |
| 6 | 0.04 | 27.84 | 28.37 | 29.32 |
| 0.10 | 32.08 | 32.67 | 33.17 | |
| 0.25 | 37.13 | 37.22 | 37.61 |
| Method | GPU (s) | PSNR (dB) | SSIM | MES |
|---|---|---|---|---|
| OMP | 0.9 | 17.21 | 0.4011 | 0.0274 |
| BCS | 16.06 | 8.99 | 0.2666 | 0.1399 |
| SBCS-Net | 0.86 | 32.73 | 0.9200 | 0.0006 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Yao, X.; Chen, B.; Zhang, H. SBCS-Net: Sparse Bayesian and Deep Learning Framework for Compressed Sensing in Sensor Networks. Sensors 2025, 25, 4559. https://doi.org/10.3390/s25154559
Gao X, Yao X, Chen B, Zhang H. SBCS-Net: Sparse Bayesian and Deep Learning Framework for Compressed Sensing in Sensor Networks. Sensors. 2025; 25(15):4559. https://doi.org/10.3390/s25154559
Chicago/Turabian StyleGao, Xianwei, Xiang Yao, Bi Chen, and Honghao Zhang. 2025. "SBCS-Net: Sparse Bayesian and Deep Learning Framework for Compressed Sensing in Sensor Networks" Sensors 25, no. 15: 4559. https://doi.org/10.3390/s25154559
APA StyleGao, X., Yao, X., Chen, B., & Zhang, H. (2025). SBCS-Net: Sparse Bayesian and Deep Learning Framework for Compressed Sensing in Sensor Networks. Sensors, 25(15), 4559. https://doi.org/10.3390/s25154559