The proposed model introduces a new approach to analyzing long-term and episodic temporal dependencies for depression. The experimental data are sourced from established multimodal datasets, which include synchronized video, audio, and text streams. These modalities are collected using sensors such as RGB cameras and condenser microphones—commonly embedded in consumer-grade devices like webcams and smartphones—under controlled recording environments. The video recordings provide facial expressions and head movements, while the audio captures vocal tone, rhythm, and energy. These sensor-acquired signals offer crucial cues for assessing mental health status.Unlike previous approaches that mainly rely on momentary or handcrafted fusion mechanisms, our framework is tailored to depression’s long-term and episodic nature by learning temporal dependencies through a graph-based formulation.
First, video is segmented into utterance-level instances and encoded into contextual representations, so as to analyze short-term features. These contextual representations are processed as nodes in a graph with dual connections to model both chronological development and relevant intermittent information among nodes. This allows the model to capture multi-dimensional temporal dependencies that are critical for understanding depression disorders.
3.1. Preprocessing
The multimodal data used in this study were originally collected through commonly used sensor devices. Specifically, visual signals were captured using RGB cameras at a frame rate of 30 frames per second (FPS), and audio signals were recorded through standard microphones at a sample rate of 16 kHz. These sensors recorded participants’ facial expressions, vocal characteristics, and spoken content under controlled interview or conversational settings. The transcribed text was obtained by applying automatic speech recognition (ASR) to the audio recordings. To clarify the segmentation by utterance using ASR, we directly utilize the transcriptions provided by the AVEC2019 dataset, which were pre-processed by the dataset creators using automatic speech recognition. The dataset provides utterance-level transcriptions with corresponding timestamps. We simply extract features from each pre-defined utterance segment: audio features from the temporal boundaries specified in the dataset, visual features from the corresponding video frames, and textual features from the provided transcribed content. This approach ensures consistent temporal alignment across all three modalities based on the dataset’s established utterance boundaries.
Assuming that we have a dataset , is the sample of a subject that consists with . represents the acoustic features extracted from speech, represents the visual features extracted from facial expressions, and represents the linguistic features extracted from speech transcripts. is the corresponding BDI or PHQ-8 score. BDI (Beck Depression Inventory) is a 21-item self-report measure designed to assess depressive symptom severity. PHQ-8 (Patient Health Questionnaire-8) is a clinically validated 8-item scale widely adopted for screening and grading depression severity. The proposed approach considers information from the audio modality, visual modality, and text modality. In order to ensure that all three modalities are available at the same time and aligned with each other, we intercepted samples according to the moment of the speaker’s utterances and re-organize them in the temporal order.
Acoustic features: Acoustic features were extracted using the OpenSmile toolkit with IS10 configuration [
36];
, where
is the index of the sample and
n is the number of utterances. The same notation applies below. We divided each speech recording using a sliding window of 4 s with a 1-second step size, and extracted feature vectors within each window using the Bag-of-audio-words eGeMAPS [
37] approach. The 100-dimensional feature vector is empirically determined based on the Bag-of-audio-words approach, which is commonly used in the audio processing literature for effective acoustic representation. Finally, the dimension of
is
.
Visual features: Facial features were extracted from video clips using a DenseNet pretrained on the FER+ dataset [
38] as
. The DenseNet was pretrained on the FER+ dataset for classifying eight basic emotions using cross-entropy loss. We first extract the region of facial expression and align it with the OpenFace toolkit, and then feed the aligned face images to the pretrained ResNet-50 [
39] to obtain the deep representation. The 2048-dimensional vector follows the standard output dimension of ResNet-50’s feature layer, which is widely adopted for visual feature representation in multimodal analysis.
Textual features: We utilized a fine-tuned RoBERTa Large model [
40] for text transcripts, appending an
token to tokenized utterances as
. We employed a pretrained BERT model to convert the transcript into sentence embeddings. The 768-dimensional representation corresponds to the hidden state size of the BERT model, which is the standard dimension for BERT-based text embeddings. The dimension of textural features is
.
3.2. Model Architecture
The proposed DepressionMIGNN has 3 procedures as depicted in
Figure 2: (1) Multimodal Context Encoding, (2) Graph Construction and Transformation, and (3) Score Prediction.
Multimodal Context Encoding: As the features obtained from the pre-processing procedure only reflect short-term information, to account for contextual information, inspired by [
41], bidirectional GRUs were utilized to update features across time-steps. The following equations adapted from [
42] demonstrate the process.
where
, indicates that the outputs of the forward GRU and the backward GRU are concatenated along the channel dimension. Here,
represents the updated hidden state for each modality, and
denotes the context-enhanced representation obtained by concatenating forward and backward outputs, which is then used for subsequent multimodal fusion. Each modality is processed with an independent GRU, and their weights are not shared. After the contextual representation is obtained for each modality, the representations of the three modalities are concatenated to jointly represent a short-term segmentation:
where
denotes the multimodal context matrix of the
i-th short-term segment.
Graph Construction and Feature Transformation: Given the multimodal contextual representation, we construct a temporal graph where each node represents a segment (utterance) from the sample. Specifically, each node corresponds to the multimodal feature representation of an utterance segment with dimension 160. refers to the set of nodes (utterance segments), denotes the set of edges connecting these segments, represents the types of temporal relationships among consecutive and non-consecutive utterances (including forward and backward temporal connections), and contains the corresponding edge weights that are learned and optimized during training. The edges are generated based on temporal proximity and semantic similarity between utterance segments and . Each edge has a relation type and a weight with , which is updated through the training process.
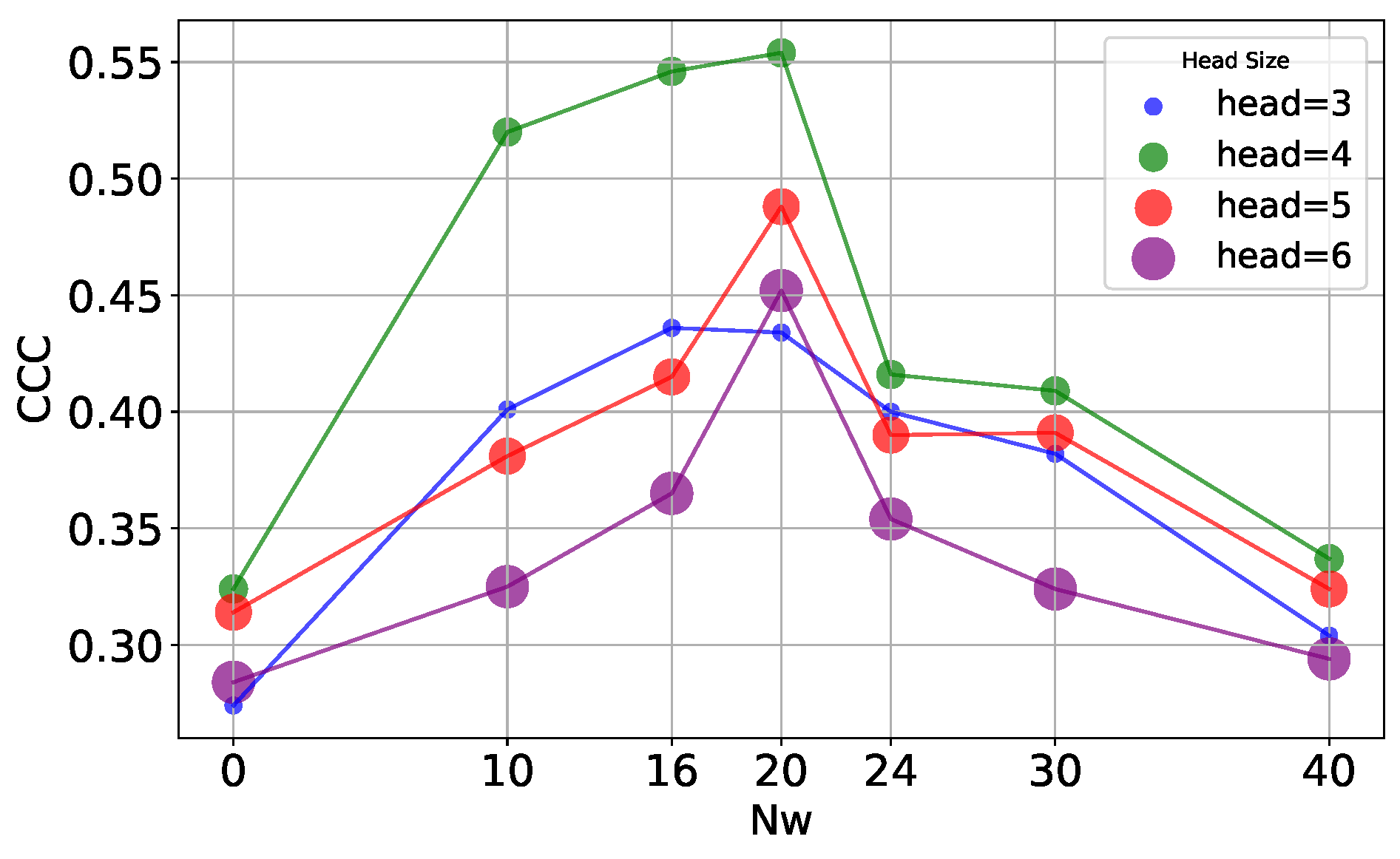
Additionally, a window range is implemented around a central utterance when constructing the graph to constrain the number of nodes. This aims to improve the model’s ability to capture relationships within a specific time period. In detail, we selected sentences before and after the current central utterance to form the graph nodes, meaning that refers to the number of sentences on each side of the central one. The graph hops along the time sequence with a step length of 1.
As
Figure 2 demonstrates, we designed two relation types, FFC and BFC. The adjacent matrices are learnable with an attention-like process as Equation (
3) shows.
where
is a trainable weight matrix for the relation type
r. Once the graph is constructed, we update the features with graph neural networks. First, we use RGCN to update the node representation according to our definition of both FFC and BFC connections, considering the past-future chronological development.
where
and
refer to weight matrices that are learned during training. The variable
represents the weights of the edges, and
is the set of indices for nodes in the neighborhood of node
i under the relation
r. The activation function is denoted by
. Next, in order to capture the association among intermittent relevant information, we utilized GAT with the RGCN output features
as input to compute the new connection weight
based on the updated features, followed by another round of feature updating with the new weights, as shown in Equation (
5), which is derived from the paper on Graph Attention Networks cited in [
21]:
where
represents a learnable weight matrix,
represents a parameterized weight vector, and
is an activation function.
To stabilize the learning process of self-attention, we found that extending our mechanism to employ multi-head attention was beneficial. Specifically,
K independent attention mechanisms execute the transformation of Equation (
6), and then their features are concatenated, resulting in the following output feature representation:
where ‖ represents concatenation,
are normalized attention coefficients computed by the k-th attention mechanism, and
is the corresponding input linear transformation’s weight matrix.
Subject-Level Prediction: It is important to clarify that the AVEC datasets used in our study provide depression severity scores at the subject level, not at the utterance level. Therefore, all utterances from a given subject share the same label. Following the Multiple-Instance Learning (MIL) paradigm, we segment each video into utterance-level instances to allow the model to capture fine-grained temporal patterns within the session. These utterances are treated as instances in a bag, and the model is trained to make predictions based on the collective evidence of all utterances.
The MIL formulation offers several advantages for depression detection: it enables automatic identification of the most diagnostically relevant utterances rather than treating all segments equally, handles noise in long-term behavioral data by focusing on discriminative instances, and aligns with clinical assessment practices where depression is evaluated based on overall symptom patterns. The subject-level prediction is obtained by averaging the instance-level predictions from all utterances, ensuring the final score reflects collective evidence while allowing the model to emphasize more informative temporal segments through learned representations. This approach enables our framework to focus on the most informative segments while still producing a subject-level prediction, aligning with the nature of depression as a long-term disorder.
Score Prediction: To predict the BDI/PHQ-8 score, we first concatenate the contextual representations
and node features
. Then, we perform predictions for each utterance-level short-term information and calculate the average score of all utterances as the final estimation result. The PHQ-8 and BDI scores are continuous values that quantify depression severity, where higher scores indicate more severe depressive symptoms. These scores are provided as ground truth labels in the AVEC dataset at the subject level. Our model outputs a regression score that directly corresponds to these clinical assessment scales, enabling clinicians to interpret the results in terms of established depression severity categories.
where
denotes the activation function,
is the predicted score for utterance
i,
is a learnable weight matrix, and
is bias.
We adopted Concordance Correlation Coefficient (CCC) loss as the cost function during the training procedure.
where
is the Pearson correlation coefficient,
and
are the mean values of predictions and ground truth labels, respectively, and
and
are the corresponding standard deviations. The value of CCC ranges from −1 to 1, where 1 denotes an ideal positive correlation and −1 denotes a completely negative correlation.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}