
MCFA: Multi-Scale Cascade and Feature Adaptive Alignment Network for Cross-View Geo-Localization


Abstract
1. Introduction
- The MSCM enhances the model’s ability to capture and represent intricate spatial relationships between target-adjacent regions and global features, thereby improving robustness.
- The FAAM effectively adapts to feature variations of targets under different orientations and platforms, achieving cross-view feature alignment between drone and satellite images.
- Performance comparisons on benchmark datasets validate the robustness and effectiveness of our method over existing SOTA solutions. In generalization experiments, our model consistently surpasses previous SOTA approaches, achieving an average improvement of 1.74% in R@1 and 2.47% in AP, further validating its effectiveness and robustness.
2. Related Work
2.1. Cross-View Geo-Localization
2.2. Part-Based Feature Representation
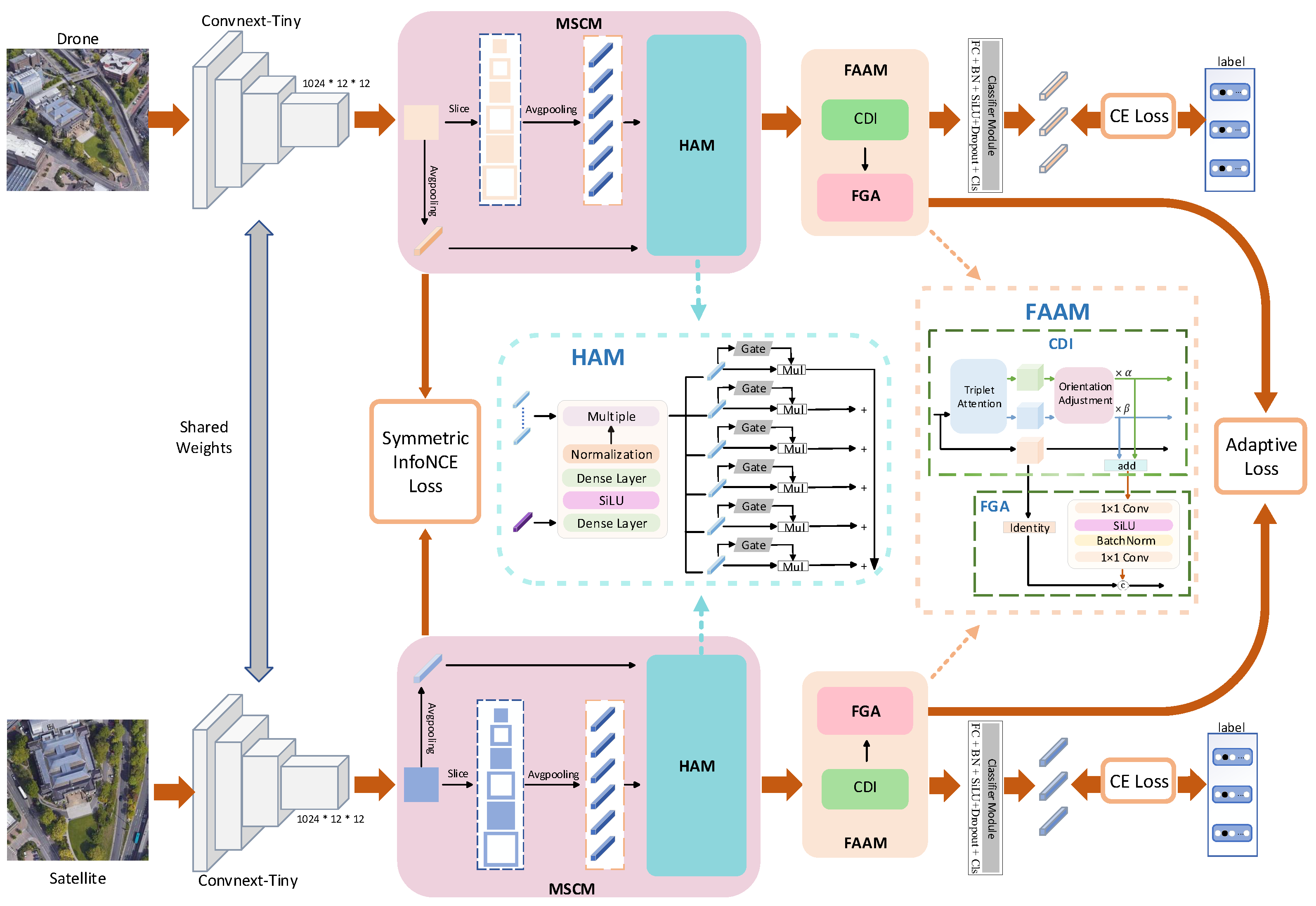
3. Proposed Method
3.1. Problem Formulation
3.2. Overall Architecture
3.3. Feature Extraction Module
3.4. MSCM
3.5. FAAM
3.6. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
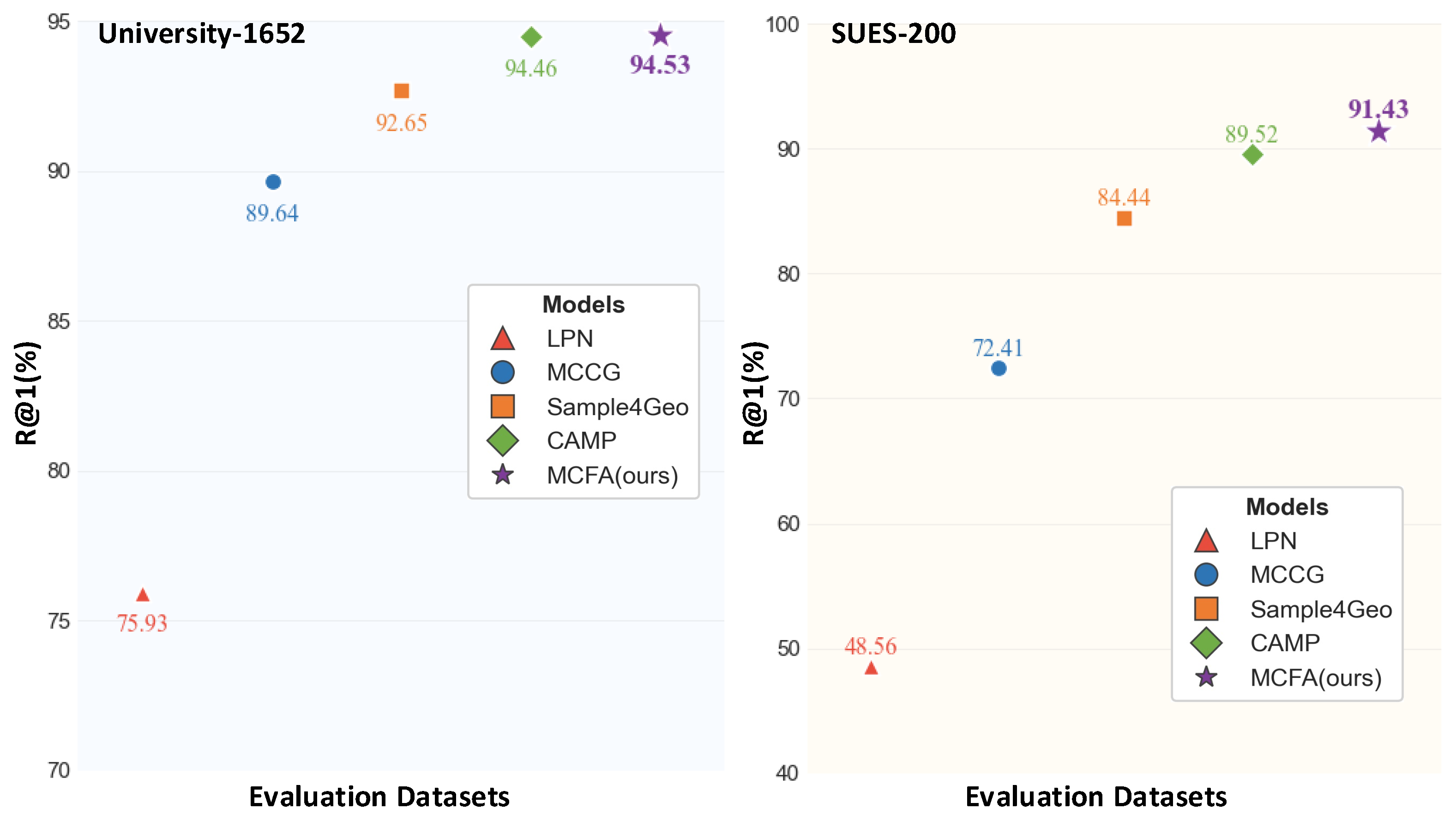
4.3. Comparison with SOTA Methods
4.3.1. Results on University-1652
4.3.2. Results on SUES-200
4.4. Generalization Experiments
4.5. Ablation Studies
4.5.1. Effect of the Multi-Scale Cascaded Module
4.5.2. Effect of the Feature Adaptive Alignment Module
4.5.3. Effect of the CDIM
4.5.4. Effect of SiLU Activation in FGA
4.5.5. Backbone Selection and Efficiency Analysis
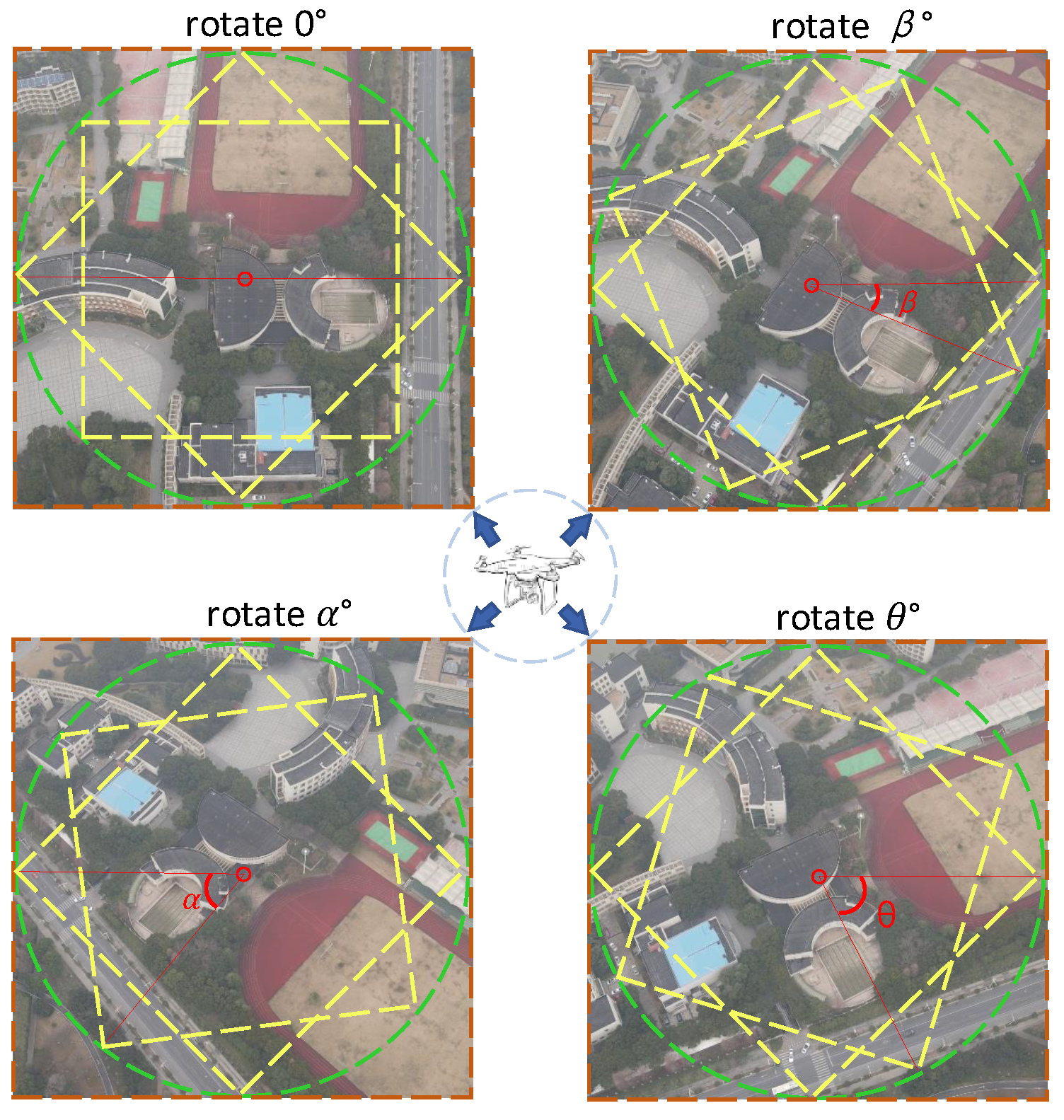
4.5.6. Effect of Image Offset in Test Data
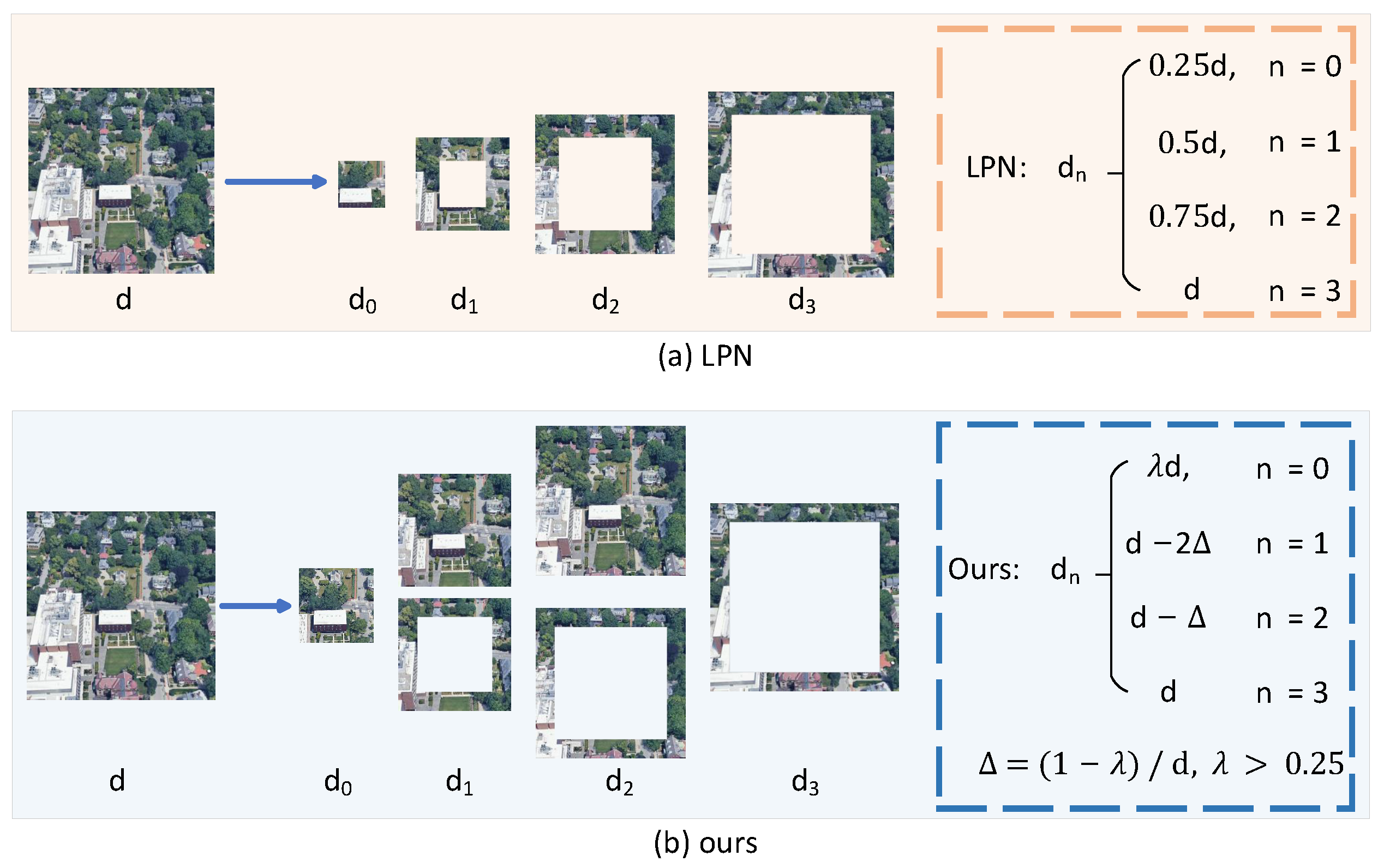
4.5.7. Impact of Center Region Size on Different Cutting Methods
4.5.8. Selection of the Number of Segments
4.5.9. Comparison of Different Loss Functions on Fine-Grained Alignment
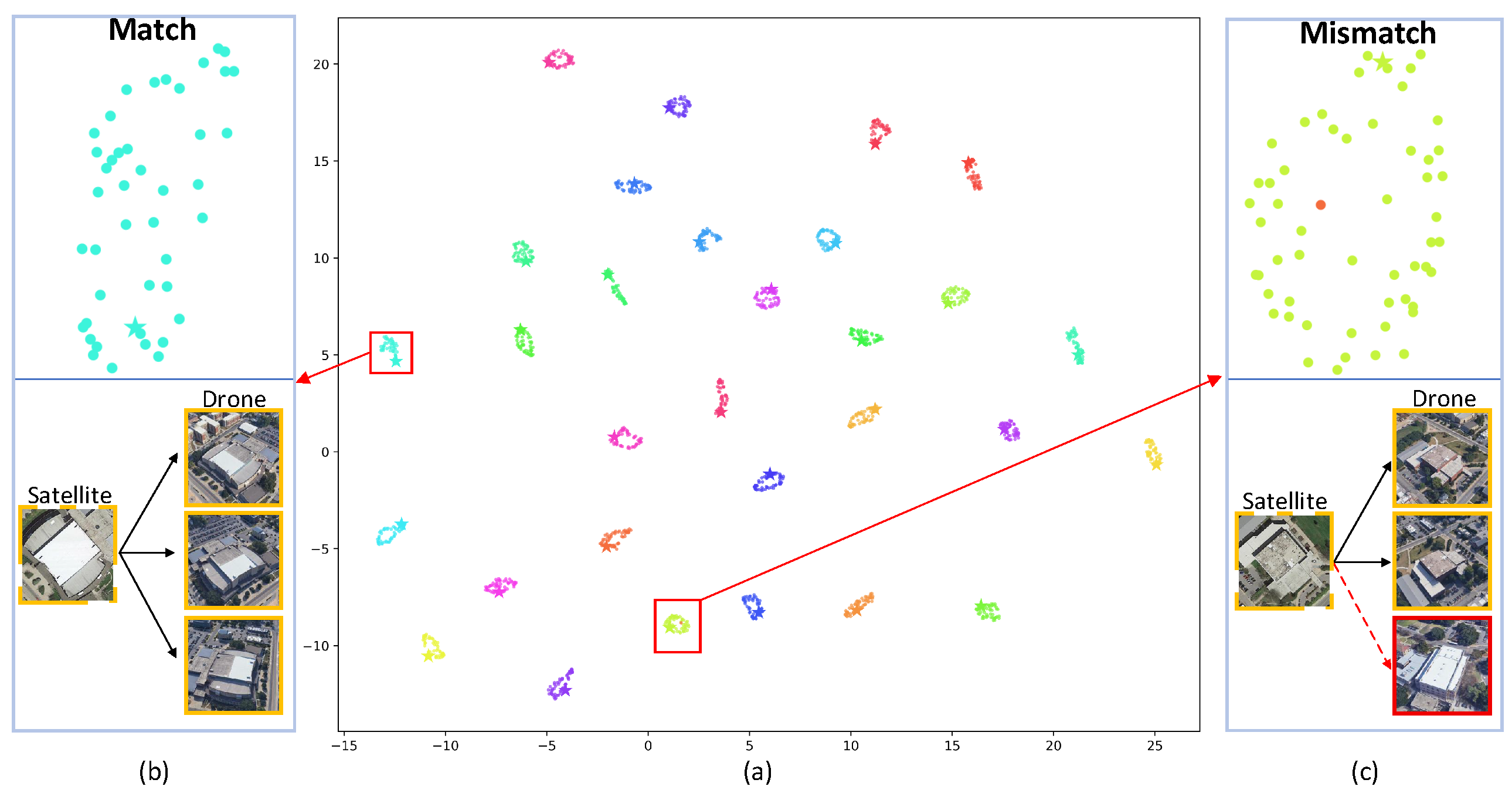
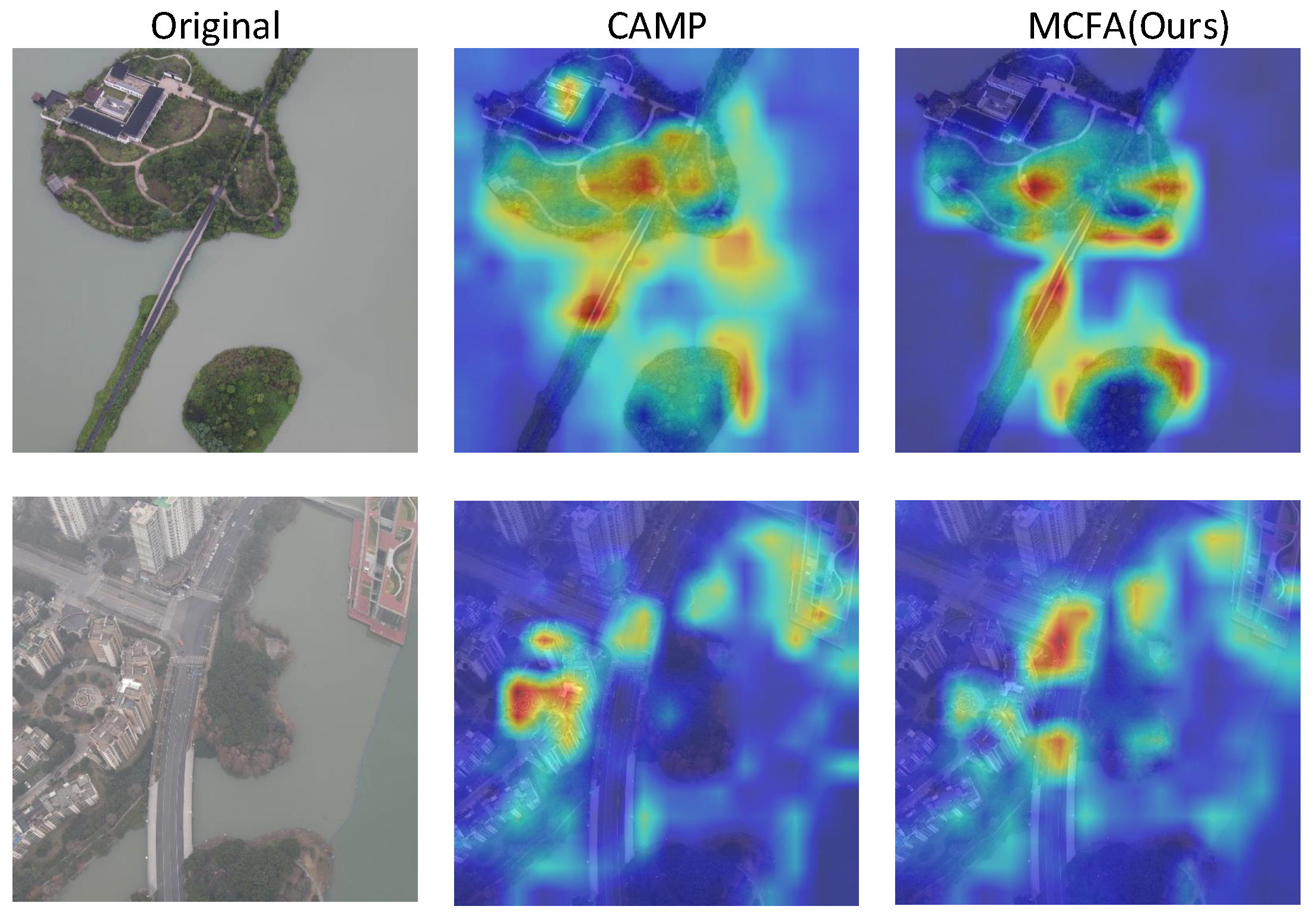
4.6. Model Visualization
5. Limitation
5.1. Feature Separability and Failure Case Analysis
5.2. Robustness Analysis Under Illumination Variations
5.3. Analysis at 300 m Altitude in Generalization Setting
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the 28th ACM international conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1395–1403. [Google Scholar]
- Zhu, R.; Yin, L.; Yang, M.; Wu, F.; Yang, Y.; Hu, W. SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4825–4839. [Google Scholar] [CrossRef]
- Shen, T.; Wei, Y.; Kang, L.; Wan, S.; Yang, Y.H. MCCG: A ConvNeXt-based multiple-classifier method for cross-view geolocalization. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1456–1468. [Google Scholar] [CrossRef]
- Deuser, F.; Habel, K.; Oswald, N. Sample4geo: Hard negative sampling for cross-view geo-localisation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16847–16856. [Google Scholar]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zheng, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 867–879. [Google Scholar] [CrossRef]
- Dai, M.; Hu, J.; Zhuang, J.; Zheng, E. A transformer-based feature segmentation and region alignment method for UAV-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4376–4389. [Google Scholar] [CrossRef]
- Zhao, H.; Ren, K.; Yue, T.; Zhang, C.; Yuan, S. TransFG: A Cross-View Geo-Localization of Satellite and UAVs Imagery Pipeline Using Transformer-Based Feature Aggregation and Gradient Guidance. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4700912. [Google Scholar] [CrossRef]
- Chu, Y.; Tong, Q.; Liu, X.; Liu, X. ODAdapter: An Effective Method of Semi-supervised Object Detection for Aerial Images. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Urumqi, China, 18–20 October 2024; pp. 158–172. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Workman, S.; Jacobs, N. On the location dependence of convolutional neural network features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 70–78. [Google Scholar]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-area image geolocalization with aerial reference imagery. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3961–3969. [Google Scholar]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and orienting street views using overhead imagery. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 494–509. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.; Lee, G.H. Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7258–7267. [Google Scholar]
- Ding, L.; Zhou, J.; Meng, L.; Long, Z. A practical cross-view image matching method between UAV and satellite for UAV-based geo-localization. Remote Sens. 2020, 13, 47. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shao, J.; Jiang, L. Style alignment-based dynamic observation method for UAV-view geo-localization. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 15–17 February 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Li, H.; Xu, C.; Yang, W.; Yu, H.; Xia, G.S. Learning cross-view visual geo-localization without ground truth. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5632017. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2138–2147. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Zhuang, J.; Dai, M.; Chen, X.; Zheng, E. A faster and more effective cross-view matching method of UAV and satellite images for UAV geolocalization. Remote Sens. 2021, 13, 3979. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, T.; Yang, Z.; Li, H.; Lu, R.; Sun, Y.; Zheng, B.; Yan, C. SDPL: Shifting-Dense Partition Learning for UAV-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 11810–11824. [Google Scholar] [CrossRef]
- Ge, F.; Zhang, Y.; Liu, Y.; Wang, G.; Coleman, S.; Kerr, D.; Wang, L. Multibranch Joint Representation Learning Based on Information Fusion Strategy for Cross-View Geo-Localization. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Ge, F.; Zhang, Y.; Wang, L.; Liu, W.; Liu, Y.; Coleman, S.; Kerr, D. Multi-level Feedback Joint Representation Learning Network Based on Adaptive Area Elimination for Cross-view Geo-localization. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5913915. [Google Scholar]
- Sun, J.; Sun, H.; Lei, L.; Ji, K.; Kuang, G. TirSA: A Three Stage Approach for UAV-Satellite Cross-View Geo-Localization Based on Self-Supervised Feature Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7882–7895. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, Z.; Zhu, Z.; Sun, Y.; Yan, C.; Yang, Y. Learning cross-view geo-localization embeddings via dynamic weighted decorrelation regularization. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5647112. [Google Scholar] [CrossRef]
- Liu, C.; Li, S.; Du, C.; Qiu, H. Adaptive Global Embedding Learning: A Two-Stage Framework for UAV-View Geo-Localization. IEEE Signal Process. Lett. 2024, 31, 1239–1243. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Wu, Y.; Miao, Q. SeGCN: A Semantic-Aware Graph Convolutional Network for UAV Geo-Localization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 6055–6066. [Google Scholar] [CrossRef]
- Wu, Q.; Wan, Y.; Zheng, Z.; Zhang, Y.; Wang, G.; Zhao, Z. Camp: A cross-view geo-localization method using contrastive attributes mining and position-aware partitioning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5637614. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3139–3148. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Xu, B. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Loshchilov, I. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ko, B.; Gu, G. Embedding expansion: Augmentation in embedding space for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7255–7264. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Publication | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|---|
| R@1 | AP | R@1 | AP | ||
| Instance Loss [2] | ACM MM’2020 | 59.69 | 64.80 | 73.18 | 59.40 |
| LPN [6] | TCSVT’22 | 75.93 | 79.14 | 86.45 | 74.79 |
| FSRA [7] | TCSVT’22 | 82.25 | 84.82 | 87.87 | 81.53 |
| TransFG [8] | TGRS’24 | 84.01 | 86.31 | 90.16 | 84.61 |
| SeGCN [38] | JSTARS’24 | 89.18 | 90.89 | 94.29 | 89.65 |
| MCCG [4] | TSCVT’23 | 89.64 | 91.32 | 94.30 | 89.39 |
| SDPL [32] | TSCVT’24 | 90.16 | 91.64 | 93.58 | 89.45 |
| Sample4Geo [5] | ICCV’23 | 92.65 | 93.81 | 95.14 | 91.39 |
| CAMP [39] | TGRS’24 | 94.46 | 95.38 | 96.15 | 92.72 |
| MCFA (ours) | 94.53 | 95.40 | 96.43 | 93.95 | |
| Drone→Satellite | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Publication | 150 m | 200 m | 250 m | 300 m | ||||
| R@1 | AP | R@1 | AP | R@1 | AP | R@1 | AP | ||
| SUES-200 Baseline [3] | TCSVT’23 | 55.65 | 61.92 | 66.78 | 71.55 | 72.00 | 76.43 | 74.05 | 78.26 |
| LPN [6] | TCSVT’22 | 61.58 | 67.23 | 70.85 | 75.96 | 80.38 | 83.80 | 81.47 | 84.53 |
| MCCG [4] | TCSVT’23 | 82.22 | 85.47 | 89.38 | 91.41 | 93.82 | 95.04 | 95.07 | 96.20 |
| SDPL [32] | TCSVT’24 | 82.95 | 85.82 | 92.73 | 94.07 | 96.05 | 96.69 | 97.83 | 98.05 |
| SeGCN [38] | JSTARS’24 | 90.80 | 92.32 | 91.93 | 93.41 | 92.53 | 93.90 | 93.33 | 94.61 |
| Sample4Geo [5] | ICCV’23 | 92.60 | 94.00 | 97.38 | 97.81 | 98.28 | 98.64 | 99.18 | 99.36 |
| CAMP [39] | TGRS’24 | 95.40 | 96.38 | 97.63 | 98.16 | 98.05 | 98.45 | 99.23 | 99.46 |
| MCFA (ours) | 96.00 | 96.89 | 97.38 | 97.86 | 98.25 | 98.67 | 99.28 | 99.42 | |
| Satellite→Drone | |||||||||
| Method | Publication | 150 m | 200 m | 250 m | 300 m | ||||
| R@1 | AP | R@1 | AP | R@1 | AP | R@1 | AP | ||
| SUES-200 Baseline [3] | TCSVT’23 | 75.00 | 55.46 | 85.00 | 66.05 | 86.25 | 69.94 | 88.75 | 74.46 |
| LPN [6] | TCSVT’22 | 83.75 | 66.78 | 88.75 | 75.01 | 92.50 | 81.34 | 92.50 | 85.72 |
| MCCG [4] | TCSVT’23 | 93.75 | 89.72 | 93.75 | 92.21 | 96.25 | 96.14 | 98.75 | 96.64 |
| SDPL [32] | TCSVT’24 | 93.75 | 83.75 | 96.25 | 92.42 | 97.50 | 95.65 | 96.25 | 96.17 |
| SeGCN [38] | JSTARS’24 | 93.75 | 92.45 | 95.00 | 93.65 | 96.25 | 94.39 | 97.50 | 94.55 |
| Sample4Geo [5] | ICCV’23 | 97.50 | 93.63 | 98.75 | 96.70 | 98.75 | 98.28 | 98.75 | 98.05 |
| CAMP [39] | TGRS’24 | 96.25 | 93.69 | 97.50 | 96.76 | 98.75 | 98.10 | 100.00 | 98.85 |
| MCFA (ours) | 97.50 | 94.76 | 98.75 | 96.60 | 98.75 | 98.16 | 98.75 | 98.68 | |
| Drone→Satellite | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | 150 m | 200 m | 250 m | 300 m | ||||
| R@1 | AP | R@1 | AP | R@1 | AP | R@1 | AP | |
| LPN [6] | 32.85 | 40.10 | 43.80 | 50.67 | 49.75 | 56.55 | 54.10 | 60.73 |
| MCCG [4] | 57.62 | 62.80 | 66.83 | 71.60 | 74.25 | 78.35 | 82.55 | 85.27 |
| Sample4Geo [5] | 74.70 | 78.47 | 81.28 | 84.40 | 86.88 | 89.28 | 89.28 | 91.24 |
| CAMP [39] | 76.53 | 80.47 | 87.18 | 89.60 | 93.75 | 95.04 | 96.40 | 97.18 |
| MCFA (ours) | 82.38 | 85.28 | 90.70 | 92.21 | 94.38 | 95.24 | 95.30 | 96.00 |
| Satellite→Drone | ||||||||
| Method | 150 m | 200 m | 250 m | 300 m | ||||
| R@1 | AP | R@1 | AP | R@1 | AP | R@1 | AP | |
| LPN [6] | 32.50 | 26.60 | 40.00 | 35.10 | 46.50 | 41.88 | 53.50 | 48.47 |
| MCCG [4] | 61.25 | 53.51 | 82.50 | 67.06 | 81.25 | 74.99 | 87.50 | 80.20 |
| Sample4Geo [5] | 82.50 | 76.20 | 85.00 | 82.93 | 92.50 | 87.77 | 92.50 | 88.38 |
| CAMP [39] | 88.75 | 78.17 | 95.00 | 88.31 | 95.00 | 91.85 | 96.25 | 93.43 |
| MCFA (ours) | 92.50 | 85.22 | 95.00 | 91.46 | 95.00 | 93.46 | 97.50 | 94.93 |
| Method | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| w/o both | 91.96 +0.00 | 93.25 +0.00 | 94.15 +0.00 | 90.86 +0.00 |
| w/MSCM | 93.31 +1.35 | 94.43 +1.18 | 95.58 +1.43 | 92.14 +1.28 |
| w/FAAM | 93.15 +1.19 | 94.21 +0.96 | 95.00 +0.85 | 92.18 +1.32 |
| MCFA (ours) | 94.53 +2.57 | 95.40 +2.15 | 96.43 +2.28 | 93.95 +3.09 |
| Method | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| SE [48] | 93.58 | 94.56 | 95.29 | 92.84 |
| CBAM [42] | 92.69 | 93.81 | 95.01 | 92.11 |
| CDIM (ours) | 94.53 | 95.40 | 96.43 | 93.95 |
| Activation Function | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| ReLU [44] | 93.94 | 94.95 | 96.14 | 93.45 |
| SiLU [45] | 94.53 | 95.40 | 96.43 | 93.95 |
| Method | Runtime | Params | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|---|---|
| (ms) | (M) | R@1 | AP | R@1 | AP | |
| LPN [6] | 4.68 | 58.29 | 75.93 | 79.14 | 86.45 | 74.79 |
| Sample4Geo [5] | 3.64 | 87.57 | 92.65 | 93.81 | 95.14 | 91.39 |
| MCFA (ViT) | 8.80 | 85.51 | 88.73 | 90.66 | 95.01 | 92.11 |
| MCFA (ConvNeXt) | 3.75 | 97.57 | 94.53 | 95.40 | 96.43 | 93.95 |
| Offset | MCFA (Ours) | SDPL [32] | FRSA [7] | LPN [6] | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | AP | R@1 | AP | R@1 | AP | R@1 | AP | |
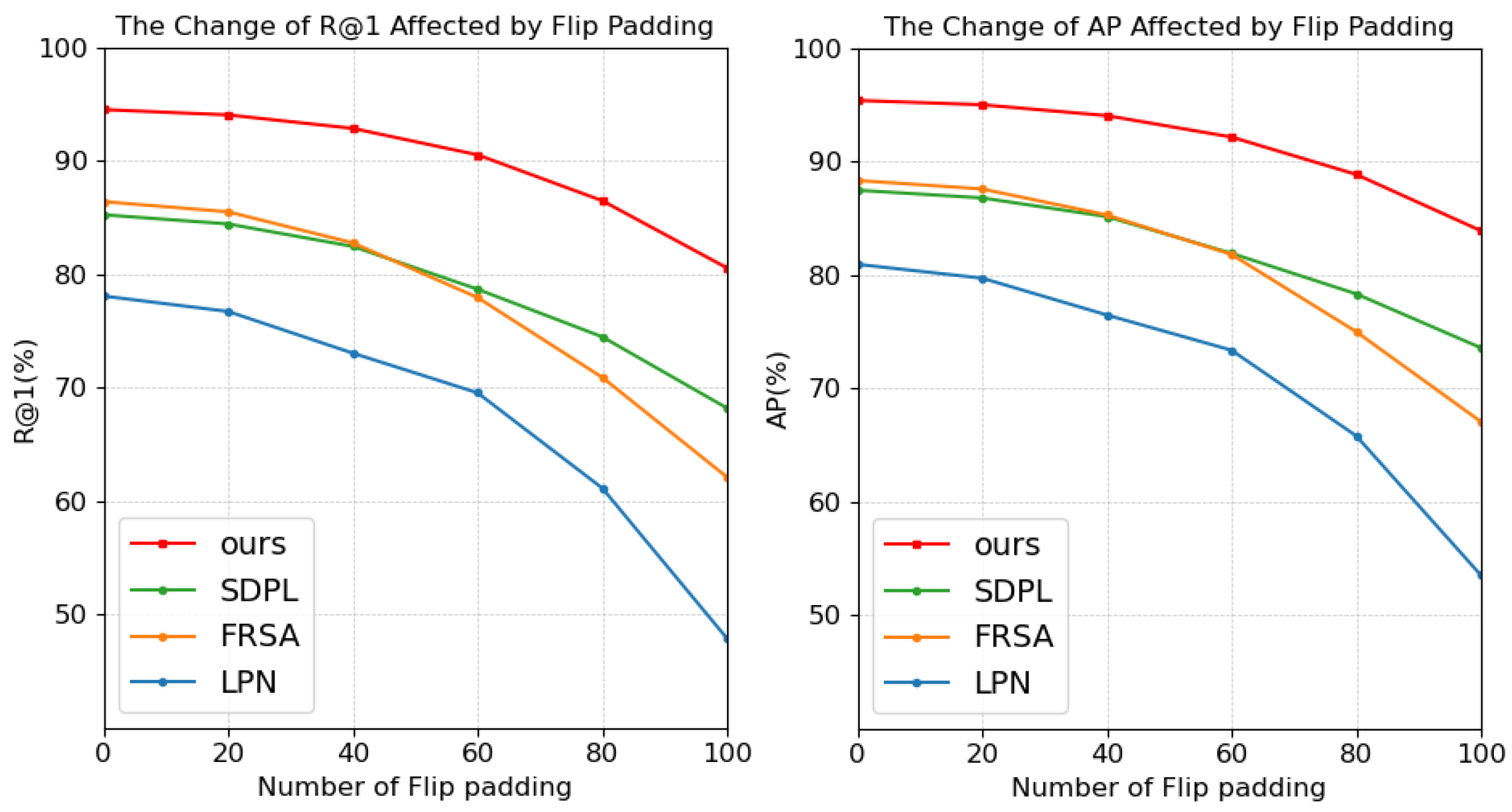
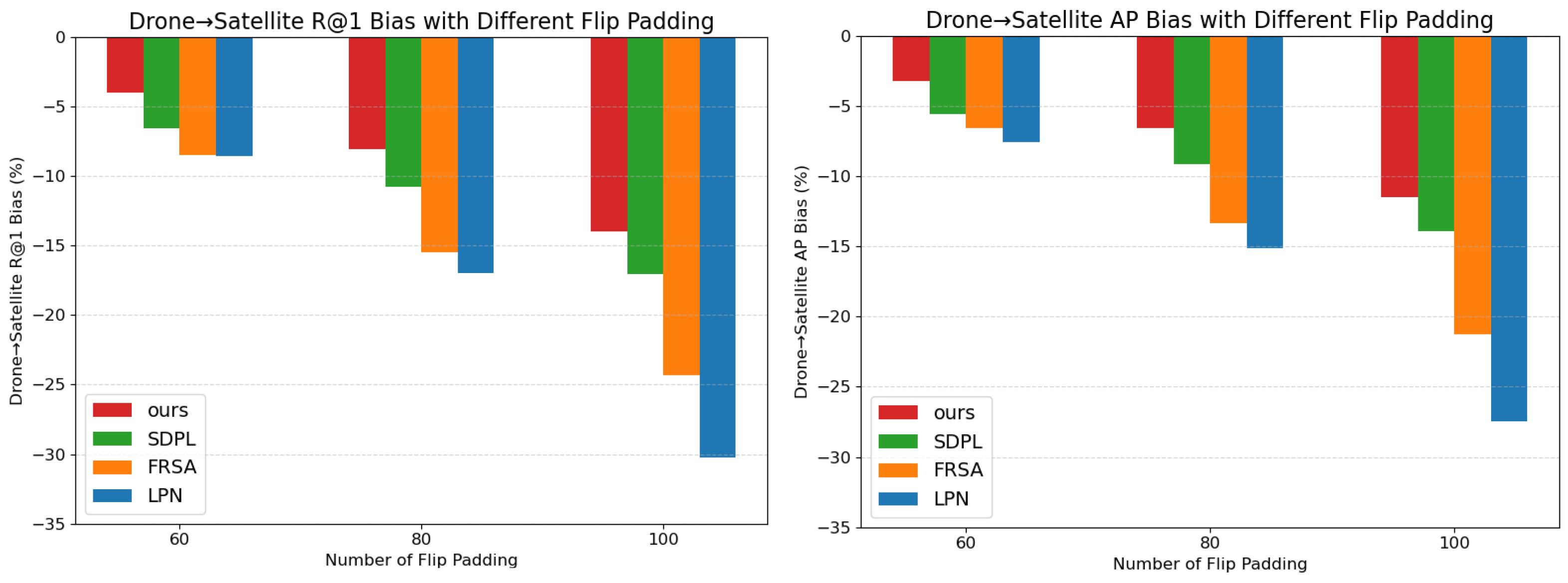
| 0 | 94.53 −0.00 | 95.40 −0.00 | 85.25 −0.00 | 87.48 −0.00 | 86.41 −0.00 | 88.34 −0.00 | 78.08 −0.00 | 80.94 −0.00 |
| +20 | 94.06 −0.47 | 95.02 −0.38 | 84.44 −0.81 | 86.80 −0.68 | 85.51 −0.90 | 87.59 −0.75 | 76.72 −1.36 | 79.72 −1.22 |
| +40 | 92.87 −1.66 | 94.06 −1.34 | 82.46 −2.79 | 85.15 −2.33 | 82.77 −3.64 | 85.30 −3.04 | 73.04 −5.04 | 76.47 −4.47 |
| +60 | 90.54 −3.99 | 92.17 −3.23 | 78.68 −6.57 | 81.91 −5.57 | 77.95 −8.46 | 81.18 −7.16 | 69.54 −8.54 | 73.36 −7.58 |
| +80 | 86.49 −8.04 | 88.87 −6.53 | 74.48 −10.77 | 78.33 −9.15 | 70.90 −15.51 | 74.99 −13.35 | 61.13 −16.95 | 65.80 −15.14 |
| +100 | 80.56 −13.97 | 83.91 −11.49 | 68.19 −17.06 | 73.57 −13.91 | 62.10 −24.31 | 67.05 −21.29 | 47.87 −30.21 | 53.50 −27.44 |
| Size | Satellite→Drone | Drone→Satellite | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| 92.72 +0.00 | 93.88 +0.00 | 95.29 +0.00 | 92.40 +0.00 | |
| 93.84 +1.12 | 94.80 +0.92 | 96.15 +0.86 | 93.26 +0.86 | |
| 93.66 +0.94 | 94.64 +0.76 | 96.29 +1.00 | 93.34 +0.94 | |
| 93.89 +1.17 | 94.82 +0.94 | 95.58 +0.29 | 92.94 +0.54 | |
| 92.34 −0.38 | 93.51 −0.37 | 95.15 −0.14 | 91.99 −0.41 | |
| Size | Satellite→Drone | Drone→Satellite | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| 93.84 +0.00 | 94.82 +0.00 | 95.58 +0.00 | 93.34 +0.00 | |
| 94.53 +0.69 | 95.40 +0.58 | 96.43 +0.85 | 93.95 +0.61 | |
| 94.03 +0.19 | 94.97 +0.15 | 96.15 +0.57 | 93.59 +0.25 | |
| 93.88 +0.04 | 94.87 +0.05 | 96.15 +0.57 | 93.24 −0.10 | |
| 92.42 −1.42 | 93.60 −1.22 | 95.44 −0.14 | 91.99 −1.35 | |
| Number | Drone→Satellite | Satellite→Drone | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| Ours (4) | 93.26 | 94.34 | 95.72 | 92.73 |
| Ours (6) | 94.53 | 95.40 | 96.43 | 93.95 |
| Ours (8) | 92.44 | 93.58 | 95.72 | 92.47 |
| Ours (10) | 92.46 | 93.63 | 95.29 | 92.30 |
| Loss Function | Satellite→Drone | Drone→Satellite | ||
|---|---|---|---|---|
| R@1 | AP | R@1 | AP | |
| InfoNCE | 91.65 | 93.02 | 94.72 | 90.78 |
| MSE loss | 93.09 | 94.15 | 95.58 | 92.18 |
| Triplet loss | 93.21 | 94.25 | 94.86 | 92.09 |
| Hard Triplet Loss [49] | 94.13 | 95.04 | 95.72 | 93.57 |
| Cosine Similarity Loss | 94.53 | 95.40 | 96.43 | 93.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, K.; Tong, Q.; Yan, N.; Liu, X.; Hou, S. MCFA: Multi-Scale Cascade and Feature Adaptive Alignment Network for Cross-View Geo-Localization. Sensors 2025, 25, 4519. https://doi.org/10.3390/s25144519
Hou K, Tong Q, Yan N, Liu X, Hou S. MCFA: Multi-Scale Cascade and Feature Adaptive Alignment Network for Cross-View Geo-Localization. Sensors. 2025; 25(14):4519. https://doi.org/10.3390/s25144519
Chicago/Turabian StyleHou, Kaiji, Qiang Tong, Na Yan, Xiulei Liu, and Shoulu Hou. 2025. "MCFA: Multi-Scale Cascade and Feature Adaptive Alignment Network for Cross-View Geo-Localization" Sensors 25, no. 14: 4519. https://doi.org/10.3390/s25144519
APA StyleHou, K., Tong, Q., Yan, N., Liu, X., & Hou, S. (2025). MCFA: Multi-Scale Cascade and Feature Adaptive Alignment Network for Cross-View Geo-Localization. Sensors, 25(14), 4519. https://doi.org/10.3390/s25144519