
Enhancing UAV Object Detection in Low-Light Conditions with ELS-YOLO: A Lightweight Model Based on Improved YOLOv11


Abstract
1. Introduction
- We develop LFSPN, which enables efficient cross-scale feature fusion and improves both model generalization and detection capability across diverse object scales.
- We propose SCSHead, a lightweight detection head that leverages shared convolutions with separate batch normalization layers to minimize computational complexity and enhance inference efficiency. Furthermore, we incorporate Layer-Adaptive Magnitude-Based Pruning (LAMP) [20] to precisely prune redundant parameters, thereby reducing computational costs without compromising detection performance.
- Extensive experiments conducted on the ExDark and DroneVehicle datasets demonstrate that ELS-YOLO achieves an optimal balance between detection accuracy and inference speed, validating its practical deployment potential.
2. Background
2.1. DVOD: Drone-View Object Detection
2.2. LLOD: Low-Light Object Detection
3. Baseline Algorithm
4. Methodology
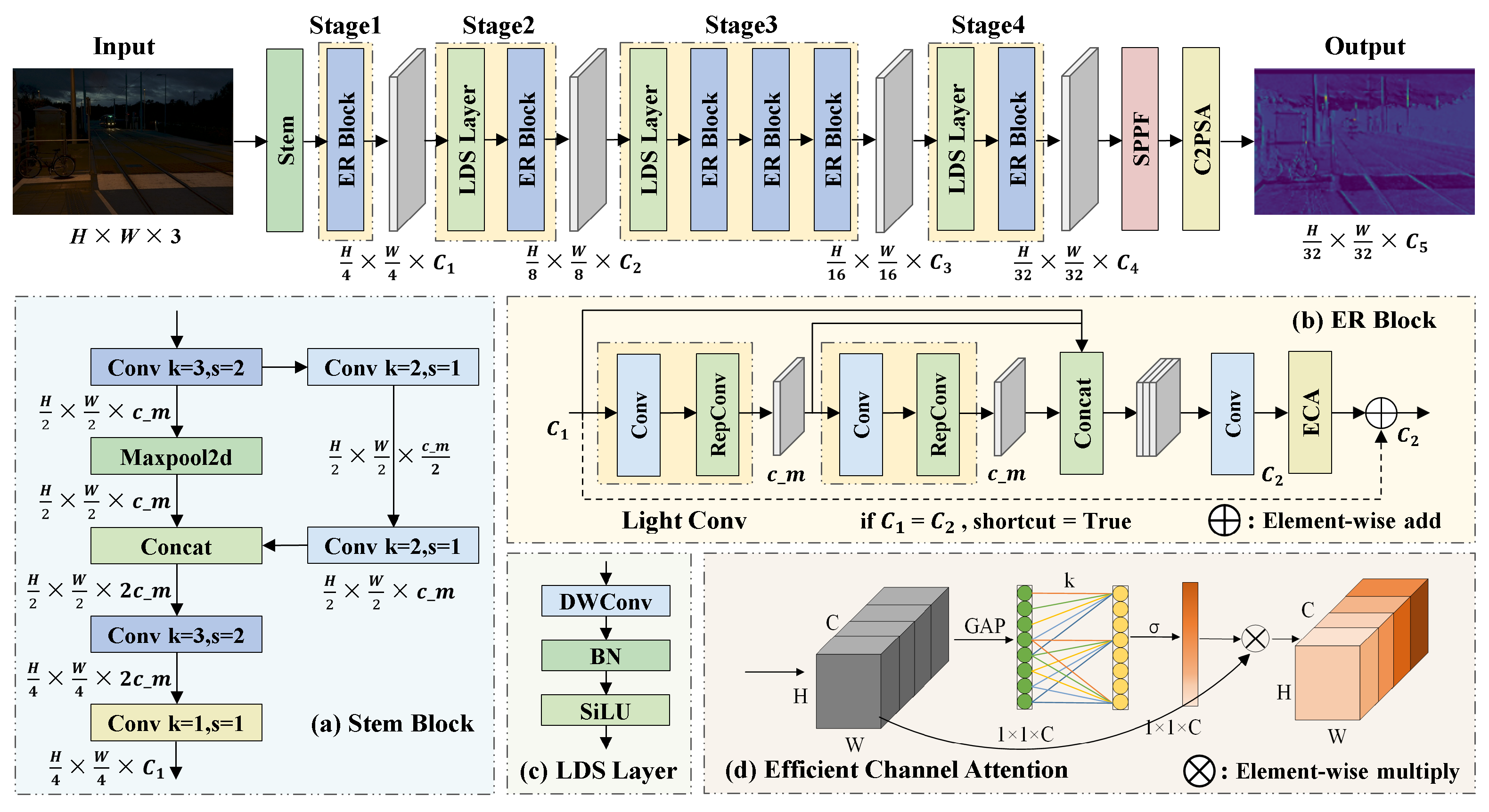
4.1. ER-HGNetV2: Re-Parameterized Backbone
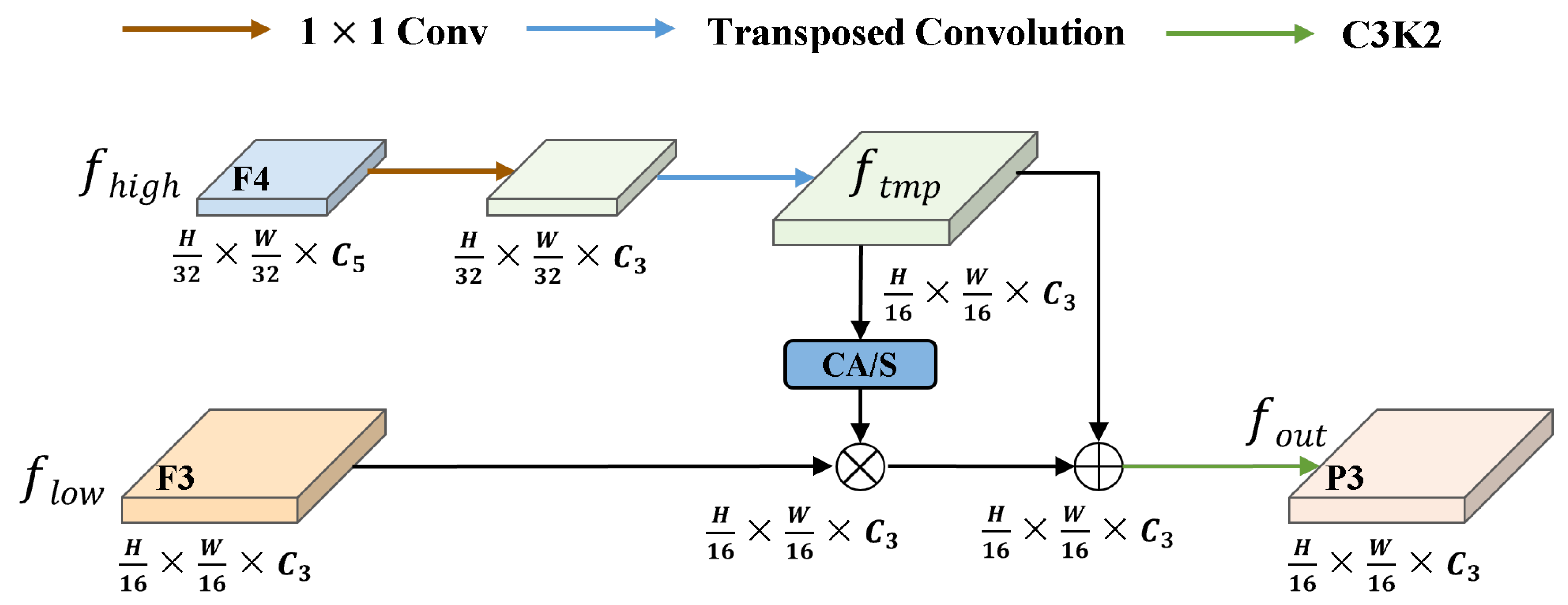
4.2. LFSPN: Lightweight Feature Selection Pyramid Network
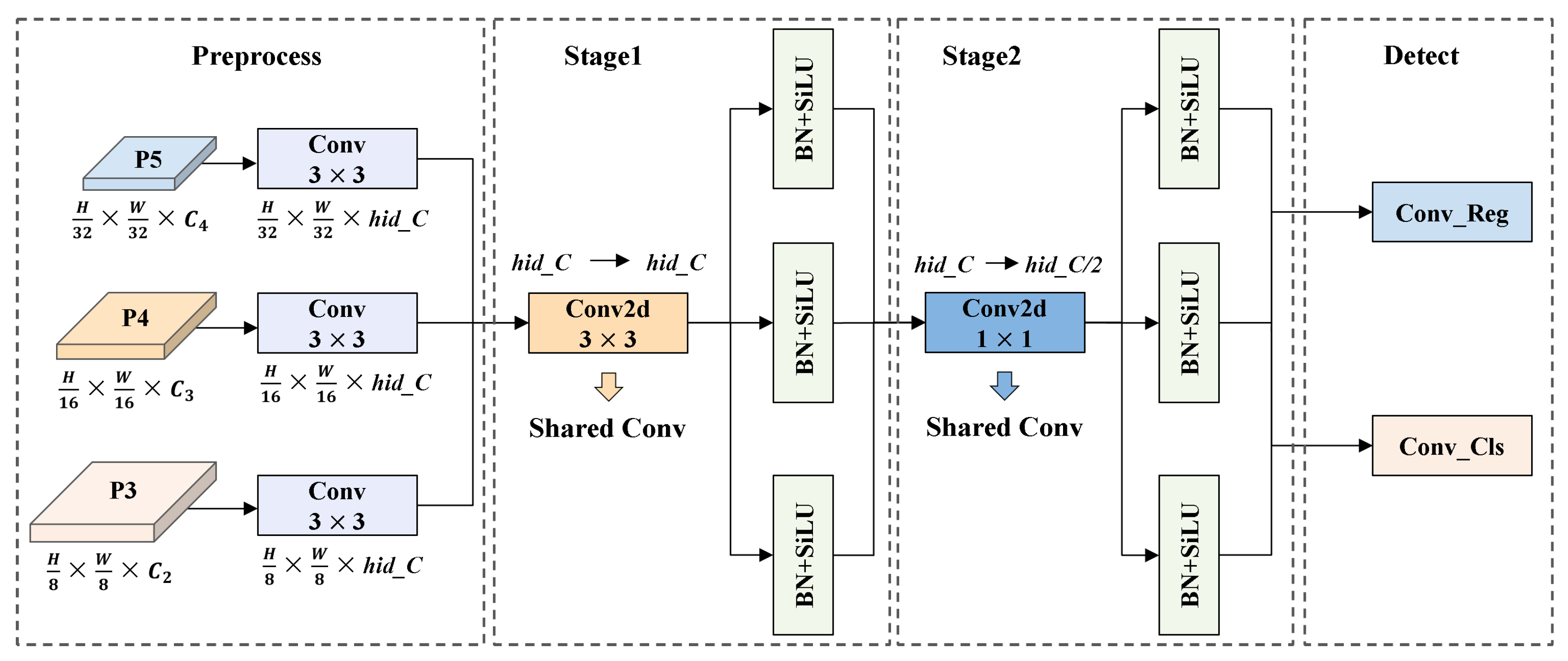
4.3. SCSHead: Shared Convolution and Separate Batch Normalization Head
4.4. Network Structure of ELS-YOLO
4.5. Channel Pruning
5. Experimental Results
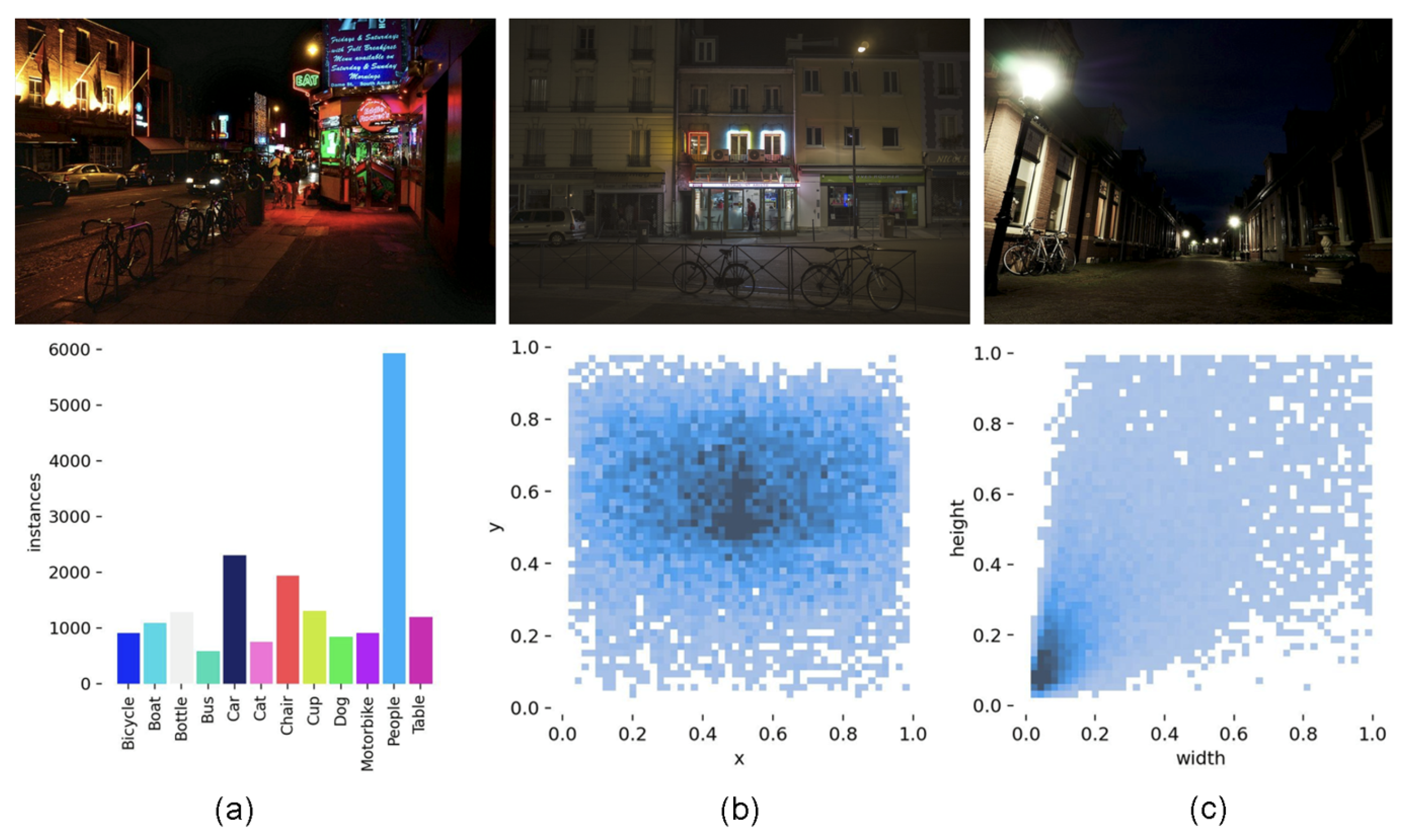
5.1. Dataset
5.1.1. ExDark
5.1.2. DroneVehicle
5.2. Experimental Environment
5.3. Evaluation Indicators
5.4. Experimental Analysis on the ExDark Dataset
5.4.1. ER-HGNetV2 Experiment
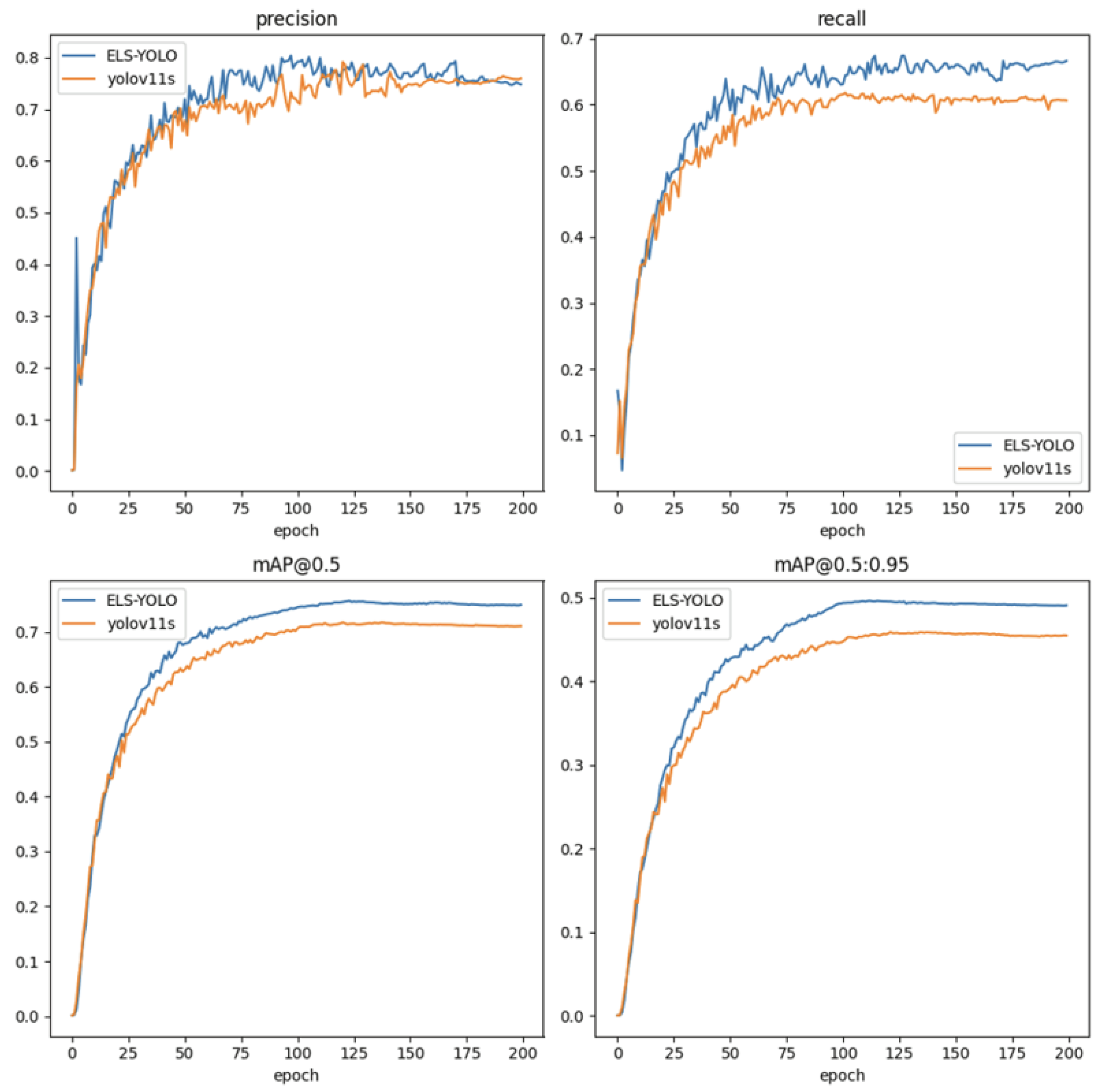
5.4.2. Comparison with YOLOv11
5.4.3. LAMP Experiment
5.4.4. Ablation Experiments
5.4.5. Comparison Experiments with Other Baseline Methods
5.4.6. Visualization Analysis
5.5. Experimental Analysis on the DroneVehicle Dataset
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Hong, D.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517010. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022. [Google Scholar]
- Zhan, J.; Hu, Y.; Zhou, G.; Wang, Y.; Cai, W.; Li, L. A high-precision forest fire smoke detection approach based on ARGNet. Comput. Electron. Agric. 2022, 196, 106874. [Google Scholar] [CrossRef]
- Hu, J.; Wei, Y.; Chen, W.; Zhi, X.; Zhang, W. CM-YOLO: Typical Object Detection Method in Remote Sensing Cloud and Mist Scene Images. Remote Sens. 2025, 17, 125. [Google Scholar] [CrossRef]
- Peng, L.; Lu, Z.; Lei, T.; Jiang, P. Dual-Structure Elements Morphological Filtering and Local Z-Score Normalization for Infrared Small Target Detection against Heavy Clouds. Remote Sens. 2024, 16, 2343. [Google Scholar] [CrossRef]
- Zhou, L.; Dong, Y.; Ma, B.; Yin, Z.; Lu, F. Object detection in low-light conditions based on DBS-YOLOv8. Clust. Comput. 2025, 28, 55. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Liu, X.; Wu, Z.; Li, A.; Vasluianu, F.A.; Zhang, Y.; Gu, S.; Zhang, L.; Zhu, C.; Timofte, R.; Jin, Z.; et al. NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 6571–6594. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Yi, W.; Hu, K.; Guo, Y.; Jing, X.; Liu, P. FHSI and QRCPE-Based Low-Light Enhancement with Application to Night Traffic Monitoring Images. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6978–6993. [Google Scholar] [CrossRef]
- Jeon, J.J.; Park, J.Y.; Eom, I.K. Low-light image enhancement using gamma correction prior in mixed color spaces. Pattern Recognit. 2024, 146, 110001. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8693. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Lee, J.; Park, S.; Mo, S.; Ahn, S.; Shin, J. Layer-Adaptive Sparsity for the Magnitude-Based Pruning. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtually, 3–7 May 2021. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A Global-Local Self-Adaptive Network for Drone-View Object Detection. IEEE Trans. Image Process. 2021, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11217. [Google Scholar] [CrossRef]
- Xi, Y.; Zheng, J.; He, X.; Jia, W.; Li, H.; Xie, Y.; Feng, M.; Li, X. Beyond context: Exploring semantic similarity for small object detection in crowded scenes. Pattern Recognit. Lett. 2020, 137, 53–60. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Kang, Y.; Chen, H.; Zhao, Z.; Zhao, Z.; Zhai, Y. Adaptively attentional feature fusion oriented to multiscale object detection in remote sensing images. IEEE Trans. Instrum. Meas. 2023, 72, 5008111. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-based RGB-Infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]
- Jie, H.; Zhao, Z.; Zeng, Y.; Chang, Y.; Fan, F.; Wang, C.; See, K.Y. A review of intentional electromagnetic interference in power electronics: Conducted and radiated susceptibility. IET Power Electron. 2024, 17, 1487–1506. [Google Scholar] [CrossRef]
- Jie, H.; Zhao, Z.; Li, H.; Gan, T.H.; See, K.Y. A Systematic Three-Stage Safety Enhancement Approach for Motor Drive and Gimbal Systems in Unmanned Aerial Vehicles. IEEE Trans. Power Electron. 2025, 40, 9329–9342. [Google Scholar] [CrossRef]
- Farid, H. Blind inverse gamma correction. IEEE Trans. Image Process. 2001, 10, 1428–1433. [Google Scholar] [CrossRef] [PubMed]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Academic Press Professional, Inc.: Williston, VT, USA, 1994; pp. 474–485. [Google Scholar]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-revealing low-light image enhancement via robust Retinex model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef] [PubMed]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Feng, X.; Li, M. Deep parametric Retinex decomposition model for low-light image enhancement. Comput. Vis. Image Underst. 2024, 241, 103948. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1777–1786. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4225–4238. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Wang, R.; Fu, C.-W.; Jia, J. SNR-aware low-light image enhancement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17693–17703. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5627–5636. [Google Scholar] [CrossRef]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Xu, L.; Ngan, K.N.; Shi, H. Hierarchical context features embedding for object detection. IEEE Trans. Multimed. 2020, 22, 3039–3050. [Google Scholar] [CrossRef]
- Hu, J.; Cui, Z. YOLO-Owl: An occlusion aware detector for low illuminance environment. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; pp. 167–170. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Zhang, T.; Liu, Y.; Zheng, Y. Self-attention guidance and multiscale feature fusion-based UAV image object detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6004305. [Google Scholar] [CrossRef]
- Wu, R.; Huang, W.; Xu, X. AE-YOLO: Asymptotic enhancement for low-light object detection. In Proceedings of the 2024 17th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 26–28 October 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, G.; Cao, H.; Hu, K.; Wang, Q.; Deng, Y.; Gao, J.; Tang, Y. Geometry-Aware 3D Point Cloud Learning for Precise Cutting-Point Detection in Unstructured Field Environments. J. Field Robot. 2025; Early View. [Google Scholar] [CrossRef]
- Li, X.; Hu, Y.; Jie, Y.; Zhao, C.; Zhang, Z. Dual-Frequency Lidar for Compressed Sensing 3D Imaging Based on All-Phase Fourier Transform. J. Opt. Photon. Res. 2023, 1, 74–81. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to Know Low-light Images with The Exclusively Dark Dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 17256–17267. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Rep ViT: Revisiting Mobile CNN From ViT Perspective. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Howard, A.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer: Cham, Switzerland, 2025; Volume 15098. [Google Scholar] [CrossRef]
- Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 5694–5703. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mAP@0.5/% | mAP/% | Params/M | GFLOPs/G | FPS |
|---|---|---|---|---|---|
| YOLO11n | 67.6 | 42.2 | 2.6 | 6.3 | 282 |
| YOLO11s | 71.4 | 45.7 | 9.4 | 21.3 | 251 |
| YOLO11m | 73.2 | 47.7 | 20.0 | 67.7 | 218 |
| YOLO11l | 74.6 | 48.9 | 25.2 | 86.6 | 183 |
| YOLO11x | 75.7 | 49.7 | 56.8 | 194.5 | 169 |
| ELS-YOLO | 74.3 | 48.5 | 4.6 | 15.0 | 274 |
| Models | P/% | R/% | mAP@0.5/% | mAP/% | Params/M | GFLOPs/G |
|---|---|---|---|---|---|---|
| YOLOv8n | 70.2 | 59.6 | 65.7 | 41.1 | 3.0 | 8.1 |
| YOLOv8s | 73.9 | 62.7 | 70.4 | 44.3 | 11.1 | 28.5 |
| YOLOv9t | 74.0 | 56.7 | 65.2 | 40.8 | 2.0 | 7.6 |
| YOLOv9s | 74.1 | 62.1 | 69.8 | 44.8 | 7.2 | 26.8 |
| YOLOv10n | 71.8 | 58.1 | 65.0 | 40.5 | 2.7 | 8.2 |
| YOLOv10s | 77.2 | 60.2 | 69.0 | 43.8 | 8.1 | 24.5 |
| Faster R-CNN | 67.4 | 52.6 | 58.9 | 35.2 | 41.2 | 208 |
| RetinaNet | 66.3 | 50.7 | 57.6 | 33.9 | 36.5 | 210 |
| DETR | 71.9 | 57.3 | 63.8 | 39.7 | 40.8 | 86.2 |
| RT-DETR-r50 | 75.4 | 61.5 | 67.1 | 42.2 | 41.9 | 125.7 |
| RT-DETR-L | 73.1 | 58.1 | 64.6 | 39.9 | 32.0 | 103.5 |
| ELS-YOLO | 79.2 | 65.8 | 74.3 | 48.5 | 4.6 | 15.0 |
| Backbone | mAP@0.5/% | mAP/% | Params/M | GFLOPs/G | FPS |
|---|---|---|---|---|---|
| baseline | 71.4 | 45.7 | 9.4 | 21.3 | 251 |
| EfficientViT [48] | 68.5 | 43.1 | 7.98 | 19.0 | 214 |
| RepViT [49] | 69.3 | 43.9 | 10.14 | 23.5 | 201 |
| HGNetV2 | 69.7 | 44.6 | 7.61 | 18.9 | 220 |
| MobileNetV4 [50] | 66.3 | 41.9 | 9.53 | 27.8 | 267 |
| StarNet [51] | 65.8 | 40.1 | 8.63 | 17.6 | 174 |
| ER-HGNetV2 | 72.6 | 46.5 | 7.6 | 18.3 | 255 |
| Models | mAP@0.5/% | mAP/% | Params/M | GFLOPs/G | FPS |
|---|---|---|---|---|---|
| ELS-YOLO | 74.3 | 48.5 | 4.6 | 15.0 | 274 |
| ELS-YOLO (ratio = 1.33) | 74.3 | 48.4 | 2.4 | 11.2 | 283 |
| ELS-YOLO (ratio = 2.0) | 74.2 | 48.1 | 1.3 | 7.4 | 298 |
| ELS-YOLO (ratio = 4.0) | 62.4 | 37.5 | 0.5 | 3.7 | 359 |
| Models | mAP@0.5/% | mAP/% | Params/M | GFLOPs/G | FPS |
|---|---|---|---|---|---|
| baseline | 71.4 | 45.7 | 9.4 | 21.3 | 251 |
| +A | 72.6 | 46.5 | 7.6 | 18.3 | 255 |
| +B | 72.2 | 46.2 | 9.03 | 20.4 | 253 |
| +C | 72.7 | 45.9 | 6.64 | 18.7 | 262 |
| +A+B | 73.8 | 47.9 | 7.3 | 17.6 | 268 |
| +A+C | 73.5 | 47.6 | 4.84 | 15.5 | 271 |
| +A+B+C | 74.3 | 48.5 | 4.6 | 15.0 | 274 |
| Models | P/% | R/% | mAP@0.5/% | mAP/% |
|---|---|---|---|---|
| YOLO11n | 58.4 | 58.9 | 61.7 | 38.6 |
| YOLO11s | 68.2 | 63.7 | 67.2 | 42.9 |
| RT-DETR-r50 | 65.7 | 63.2 | 66.7 | 41.2 |
| RT-DETR-L | 67.9 | 66.4 | 68.1 | 43.3 |
| ELS-YOLO | 68.3 | 67.5 | 68.7 | 44.5 |
| ELS-YOLO (ratio = 2.0) | 68.2 | 67.3 | 68.5 | 44.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weng, T.; Niu, X. Enhancing UAV Object Detection in Low-Light Conditions with ELS-YOLO: A Lightweight Model Based on Improved YOLOv11. Sensors 2025, 25, 4463. https://doi.org/10.3390/s25144463
Weng T, Niu X. Enhancing UAV Object Detection in Low-Light Conditions with ELS-YOLO: A Lightweight Model Based on Improved YOLOv11. Sensors. 2025; 25(14):4463. https://doi.org/10.3390/s25144463
Chicago/Turabian StyleWeng, Tianhang, and Xiaopeng Niu. 2025. "Enhancing UAV Object Detection in Low-Light Conditions with ELS-YOLO: A Lightweight Model Based on Improved YOLOv11" Sensors 25, no. 14: 4463. https://doi.org/10.3390/s25144463
APA StyleWeng, T., & Niu, X. (2025). Enhancing UAV Object Detection in Low-Light Conditions with ELS-YOLO: A Lightweight Model Based on Improved YOLOv11. Sensors, 25(14), 4463. https://doi.org/10.3390/s25144463