
Scene Graph and Natural Language-Based Semantic Image Retrieval Using Vision Sensor Data



Abstract
1. Introduction
Contribution of This Work
- A novel similarity measurement method for heterogeneous graph structures: We propose a technique that transforms scene graphs extracted from images and semantic graphs generated from text into embedding representations that preserve both node and edge information. By leveraging a GCN, our method enables quantitative similarity computation between the two graph structures.
- Subgraph extraction from region-based scene graphs: Scene graphs generated from images often contain a large number of objects and relationships, which leads to increased computational complexity and potential interference from irrelevant information during training. To address this, we propose a region-based subgraph extraction method that selectively retains only semantically meaningful relationships around a central node, thereby reducing graph processing overhead. By employing a window-based depth-first search (DFS) strategy, the method mitigates central node bias and captures localized semantic structures. These localized subgraphs are then merged to construct a semantically focused summary of the global scene graph. Experimental results demonstrate that the dataset generated using this method contributes to improved retrieval performance.
- An effective training strategy for text-to-image retrieval: We adopt a contrastive GCN-based framework that matches semantic graphs with scene graphs to retrieve semantically similar images. To further enhance learning, we incorporate hard negative mining (HNM) [8], allowing the model to focus on more challenging negative samples. Unlike conventional negative sampling methods that select samples randomly, HNM selects hard negatives—samples the model is more likely to confuse—after an initial training phase. This approach improves the model’s ability to distinguish subtle differences between similar images, leading to enhanced retrieval accuracy and better similarity evaluation performance relative to training time.
2. Related Work
2.1. Scene Graph Generation
2.2. Image Retrieval
2.3. Subgraph Extraction
3. Preliminaries
3.1. Natural Language Processing
3.2. Sentence-BERT (SBERT)
3.3. SGG (Scene Graph Generation)
3.4. GCN (Graph Convolutional Network)
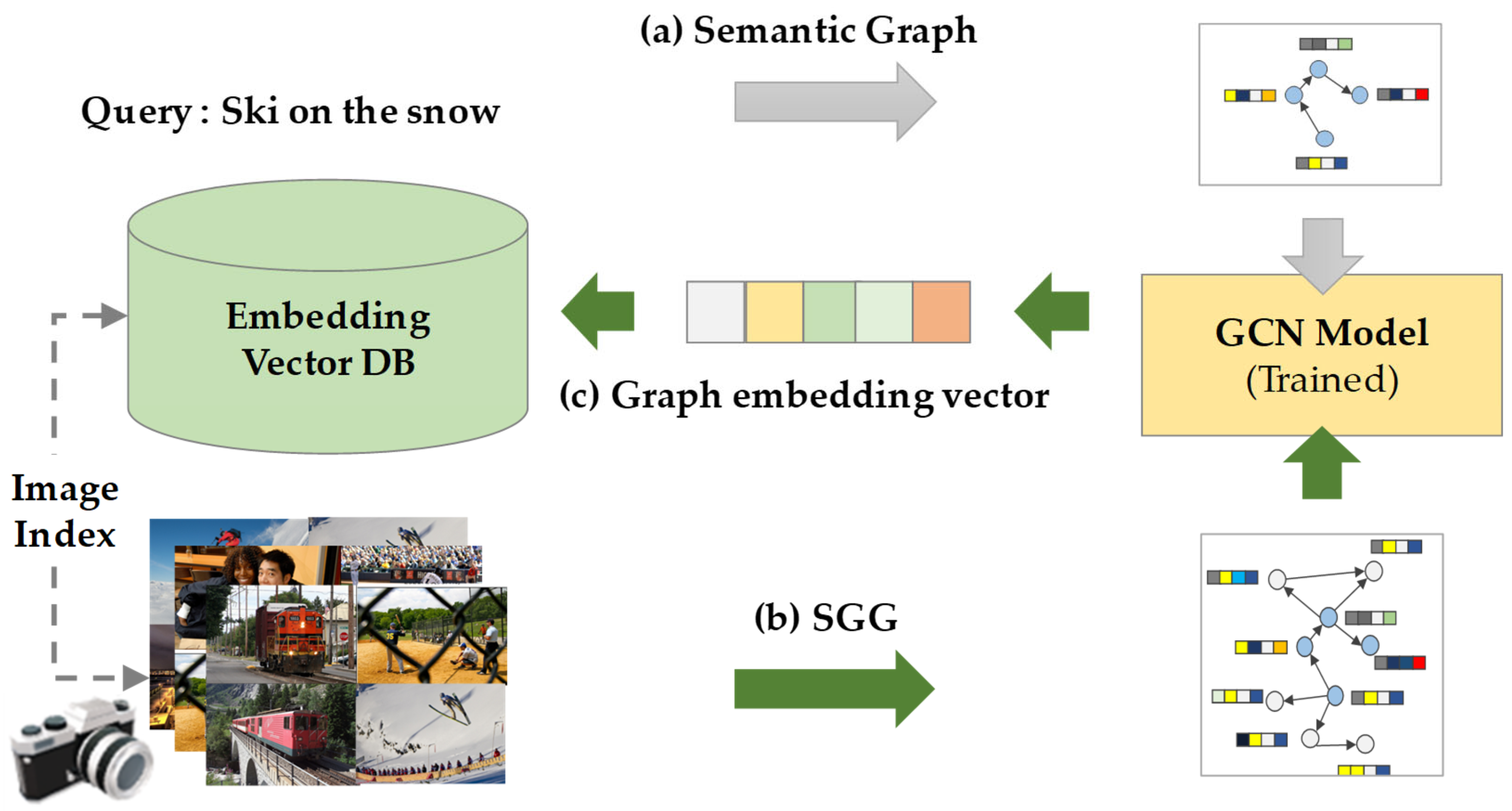
4. Semenatic Image Retrieal
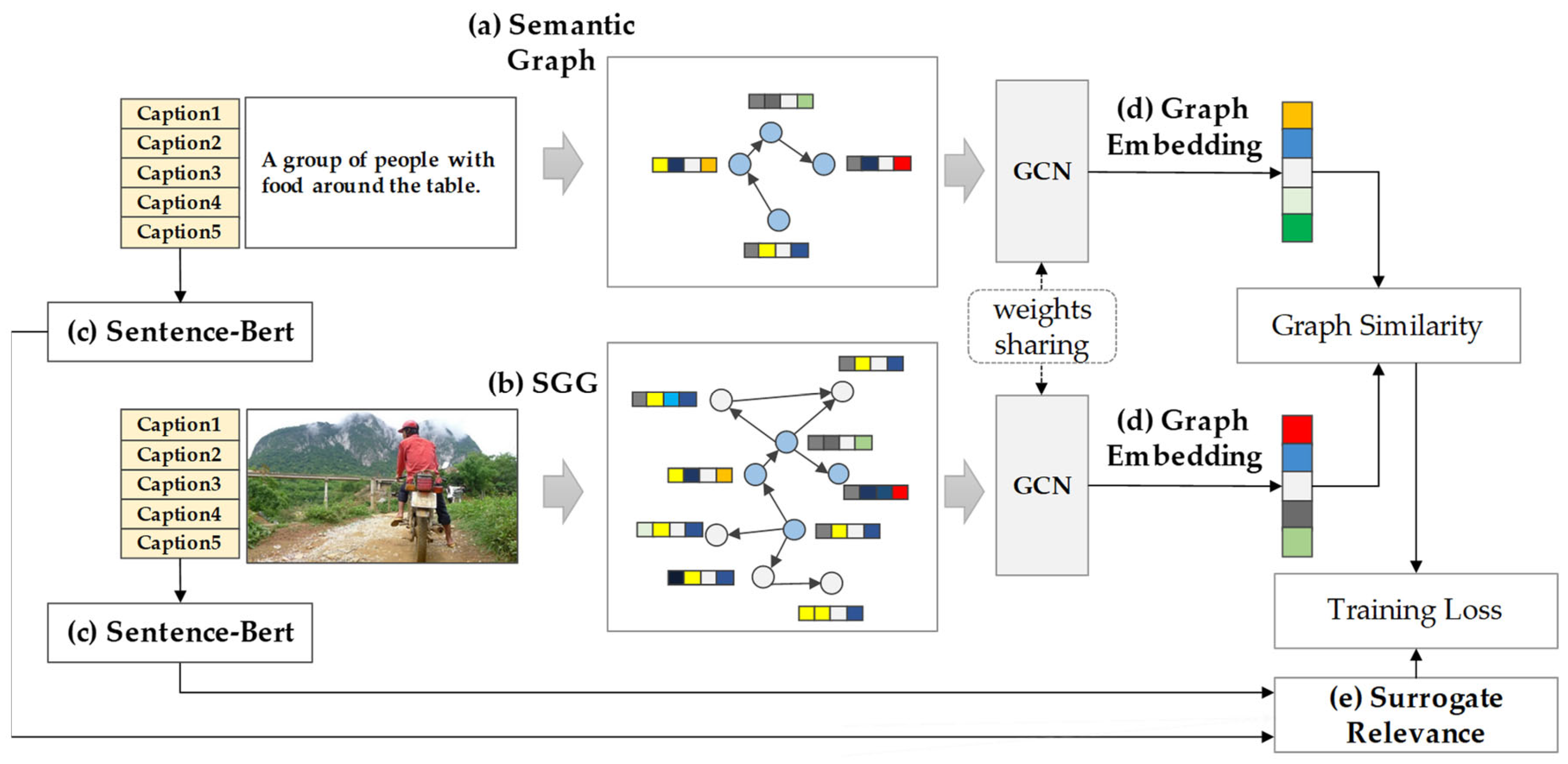
4.1. Semantic Text Graph Construction
4.2. Scene Graph Similarity
4.3. Pair Sampling and Training Loss
- (1)
- Definition of Surrogate Relevance
- (2)
- Uniform Pair Sampling (Initial Training Strategy)
- (3)
- Hard Negative Mining (Progressive Strategy)
- (4)
- Definition of Loss Function
5. Proposed Subgraph Extraction
5.1. Motivation for Subgraph-Based Representation
5.2. R-SSE (Region-Based Semantic Subgraph Extraction)
- (1)
- Region-based Central Node Selection
- (2)
- DFS-Based Regional Graph Extraction
- Maximum depth: ;
- Maximum number of nodes: (including the central node);
- Search node restriction: .
- (3)
- Subgraph Merge
- V_merge: the normalized set of nodes obtained by removing duplicates across all merged nodes;
- E_merge: the set of edges preserving the original relationships among the merged nodes.
| Algorithm 1. Region-based Semantic Subgraph Extraction with Subgraph Merge (R-SSE) |
| Input: Scene graph , sliding windows , max node count , max depth Output: Merged subgraph 1: // Set of all regional subgraphs 2: for each center window do 3: node in with the largest blob area 4: 5: Stack 6: while Stack is not empty and 7: Stack:pop() 8: for each do 9: if and and and 10: then 11. 12: Stack:push() 13: 14: 15: 16: union of all nodes in , duplicates removed 17: all edges among from 18: Return |
6. Dataset and Experimental Results
6.1. Dataset and Sampling Strategy
- (1)
- Random Sampling:
- (2)
- Uniform Pair Sampling (UPS):
- (3)
- Hard Negative Mining (HNM):
6.2. Training Details
6.3. Evaluation
- (1)
- Baseline Methods
- Keyword Match: A simple method that computes similarity based on the number of matching words between the text query and image captions. This approach does not account for structural or semantic relationships between words and therefore yielded the lowest performance.
- Contrastive Language–Image Pretraining (CLIP): Similar to the method proposed by Karthik et al. [5], this baseline utilizes a pretrained model based on ResNet and Vision Transformer (ViT) to directly learn semantic similarity between text and images. Among the text-based methods, CLIP achieved the highest performance in this experiment.
- Ground Truth Scene Graph (GT/SG): This approach uses manually annotated scene graphs provided by Visual Genome without modification. By leveraging accurate object and relation information, this method achieved the best performance among the graph-based approaches.
- (2)
- Scene Graphs
- (3)
- Sampling Pair
- (4)
- Subgraph Structure Analysis
6.4. Qualitative Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Karpathy, A.; Li, F.-F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep Image Retrieval: Learning Global Representations for Image Search. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part VI; Springer: Cham, Switzerland, 2016; pp. 241–257. [Google Scholar]
- Xuan, H.; Stylianou, A.; Liu, X.; Pless, R. Hard Negative Examples Are Hard, but Useful. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XIV 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 126–142. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, ICML 2021, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Karthik, S.; Roth, K.; Mancini, M.; Akata, Z. Vision-by-Language for Training-Free Compositional Image Retrieval. arXiv 2023, arXiv:2310.09291. [Google Scholar]
- Datta, R.; Li, J.; Wang, J.Z. Content-Based Image Retrieval: Approaches and Trends of the New Age. In Proceedings of the 7th ACM SIGMM International Workshop on Multimedia Information Retrieval, Singapore, 10–11 November 2005; pp. 253–262. [Google Scholar]
- Baldrati, A.; Bertini, M.; Uricchio, T.; Del Bimbo, A. Conditioned and Composed Image Retrieval Combining and Partially Fine-Tuning CLIP-Based Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 4959–4968. [Google Scholar]
- Robinson, J.; Chuang, C.-Y.; Sra, S.; Jegelka, S. Contrastive Learning with Hard Negative Samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Xu, D.; Zhu, Y.; Choy, C.B.; Li, F.-F. Scene Graph Generation by Iterative Message Passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Ali, N.; Bajwa, K.B.; Sablatnig, R.; Chatzichristofis, S.A.; Iqbal, Z.; Rashid, M.; Habib, H.A. A Novel Image Retrieval Based on Visual Words Integration of SIFT and SURF. PLoS ONE 2016, 11, e0157428. [Google Scholar] [CrossRef] [PubMed]
- Wasson, V. An Efficient Content Based Image Retrieval Based on Speeded Up Robust Features (SURF) with Optimization Technique. In Proceedings of the 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 19–20 May 2017; pp. 730–735. [Google Scholar]
- Gautam, G.; Khanna, A. Content Based Image Retrieval System Using CNN based Deep Learning Models. Procedia Comput. Sci. 2024, 235, 3131–3141. [Google Scholar] [CrossRef]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Gupta, S.; Malik, J. Visual Semantic Role Labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar]
- spaCy. Available online: https://spacy.io/ (accessed on 1 March 2025).
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Yoon, S.; Kang, W.Y.; Jeon, S.; Lee, S.; Han, C.; Park, J.; Kim, E.-S. Image-to-Image Retrieval by Learning Similarity between Scene Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 10718–10726. [Google Scholar]
- Kim, H.; Kim, S.; Ahn, D.; Lee, J.T.; Ko, B.C. Scene Graph Generation Strategy with Co-occurrence Knowledge and Learnable Term Frequency. arXiv 2024, arXiv:2405.12648. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; pp. 1–8. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Kim, J.; Ko, B.C. Semantic Image Retrieval Using Scene Graphs and Natural Language Queries. In Proceedings of the 2025 International Conference on Electronics, Information, and Communication (ICEIC), Osaka, Japan, 19–22 January 2025; pp. 1–5. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Data | nDCG@ 10 | nDCG@ 20 | nDCG@ 30 | nDCG@ 40 | nDCG@ 50 |
|---|---|---|---|---|---|---|
| Keyword Match | Caption | 0.205 | 0.213 | 0.218 | 0.223 | 0.229 |
| CLIP | Caption | 0.845 | 0.846 | 0.845 | 0.844 | 0.844 |
| GAT (Node) | GT/SG | 0.628 | 0.644 | 0.653 | 0.660 | 0.666 |
| GAT (Edge) | GT/SG | 0.632 | 0.648 | 0.657 | 0.664 | 0.669 |
| GCN (Node) | GT/SG | 0.681 | 0.705 | 0.718 | 0.729 | 0.738 |
| GCN (Edge) | GT/SG | 0.676 | 0.700 | 0.715 | 0.725 | 0.734 |
| GCN (Node) | I/SG | 0.625 | 0.641 | 0.649 | 0.658 | 0.668 |
| GCN (Edge) | I/SG | 0.624 | 0.638 | 0.649 | 0.658 | 0.662 |
| Subgraph Extraction | Sampling Pair | nDCG@ 10 | nDCG@ 20 | nDCG@ 30 | nDCG@ 40 | nDCG@ 50 |
|---|---|---|---|---|---|---|
| Full | Random | 0.625 | 0.641 | 0.649 | 0.658 | 0.668 |
| Full | UPS | 0.680 | 0.695 | 0.704 | 0.710 | 0.714 |
| Top (k = 20) | UPS | 0.696 | 0.711 | 0.721 | 0.727 | 0.732 |
| Top (k = 40) | UPS | 0.697 | 0.716 | 0.726 | 0.733 | 0.739 |
| Top (k = 80) | UPS | 0.691 | 0.710 | 0.721 | 0.729 | 0.735 |
| R-SSE | UPS | 0.697 | 0.715 | 0.725 | 0.733 | 0.740 |
| Full | UPS + HNM | 0.679 | 0.697 | 0.707 | 0.713 | 0.717 |
| Top (k = 40) | UPS + HNM | 0.699 | 0.718 | 0.728 | 0.735 | 0.740 |
| R-SSE | UPS + HNM | 0.704 | 0.722 | 0.732 | 0.740 | 0.745 |
| Step | Full | Top (k = 20) | Top (k = 40) | Top (k = 80) | R-SSE |
|---|---|---|---|---|---|
| Preprocessing (Subgraph) | 4 ms | 0.1 ms | 0.24 ms | 0.5 ms | 8 ms |
| Training (Iteration) | 917 ms | 54 ms | 71 ms | 125 ms | 83 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Ko, B.C. Scene Graph and Natural Language-Based Semantic Image Retrieval Using Vision Sensor Data. Sensors 2025, 25, 3252. https://doi.org/10.3390/s25113252
Kim J, Ko BC. Scene Graph and Natural Language-Based Semantic Image Retrieval Using Vision Sensor Data. Sensors. 2025; 25(11):3252. https://doi.org/10.3390/s25113252
Chicago/Turabian StyleKim, Jaehoon, and Byoung Chul Ko. 2025. "Scene Graph and Natural Language-Based Semantic Image Retrieval Using Vision Sensor Data" Sensors 25, no. 11: 3252. https://doi.org/10.3390/s25113252
APA StyleKim, J., & Ko, B. C. (2025). Scene Graph and Natural Language-Based Semantic Image Retrieval Using Vision Sensor Data. Sensors, 25(11), 3252. https://doi.org/10.3390/s25113252