
Lightweight Dual-Attention Network for Concrete Crack Segmentation



Abstract
1. Introduction
- An edge-oriented dual-attention architecture: L-DANet combines CBAM channel–spatial excitation and DANet positional self-attention into a simple U-Net backbone. This gives L-DANet the best accuracy at the kiloflop scale.
- A full ablation study: Controlled experiments separate the effects of weight initialization, Dice-augmented loss, and attention placement, thus confirming that dual attention is the main factor that affects performance.
- Rigorous benchmarking: On the concrete crack benchmark, L-DANet surpasses MobileNetV3, ESPNetv2, CrackTree, Hybrid-2020, and YOLO-v11-Seg, thus showing an improved IoU by up to 6.1 percentage points and reduced parameter values by as much as 70%.
- Deployment-centred evaluation: Latency, throughput, power consumption, and memory footprint are profiled on four representative edge platforms, thereby demonstrating real-time feasibility for embedded structural health monitoring systems.
2. Materials and Methods
2.1. Network Architecture
2.2. Concrete Crack Dataset
- A subset of 602 images (75%) for training;
- A subset of 102 images (12.5%) for validation;
- A subset of 102 images (12.5%) for hold-out testing.
2.3. Implementation Details
2.4. Performance Metrics
3. Experiment and Results
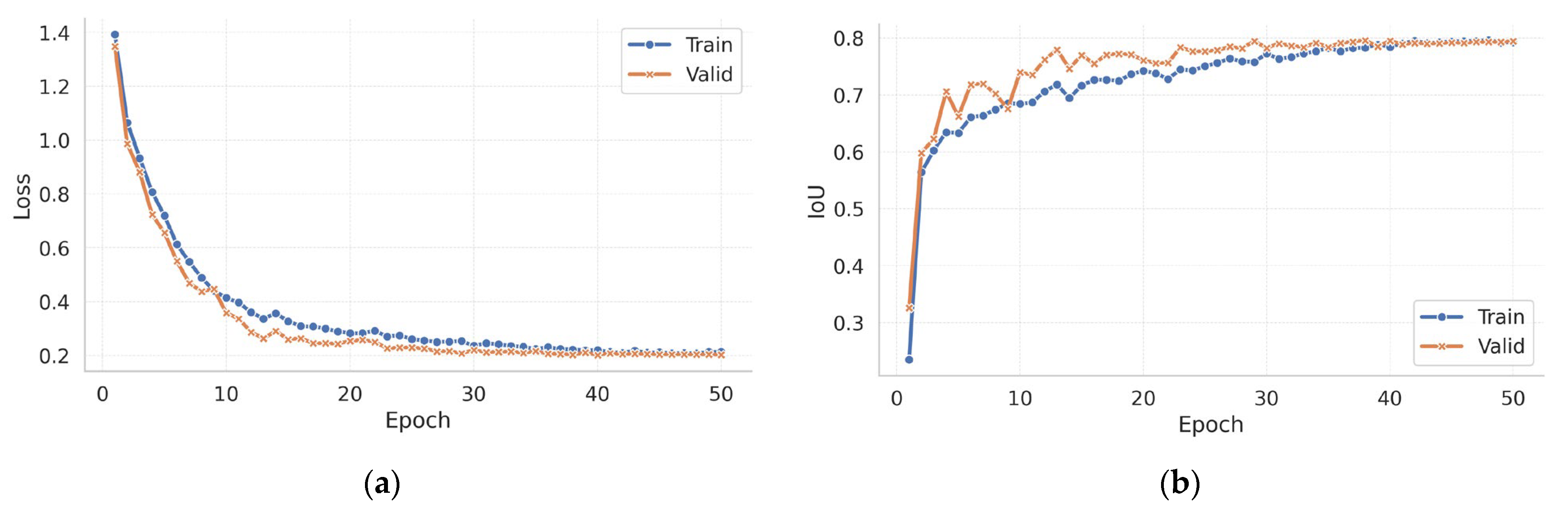
3.1. Training Dynamics
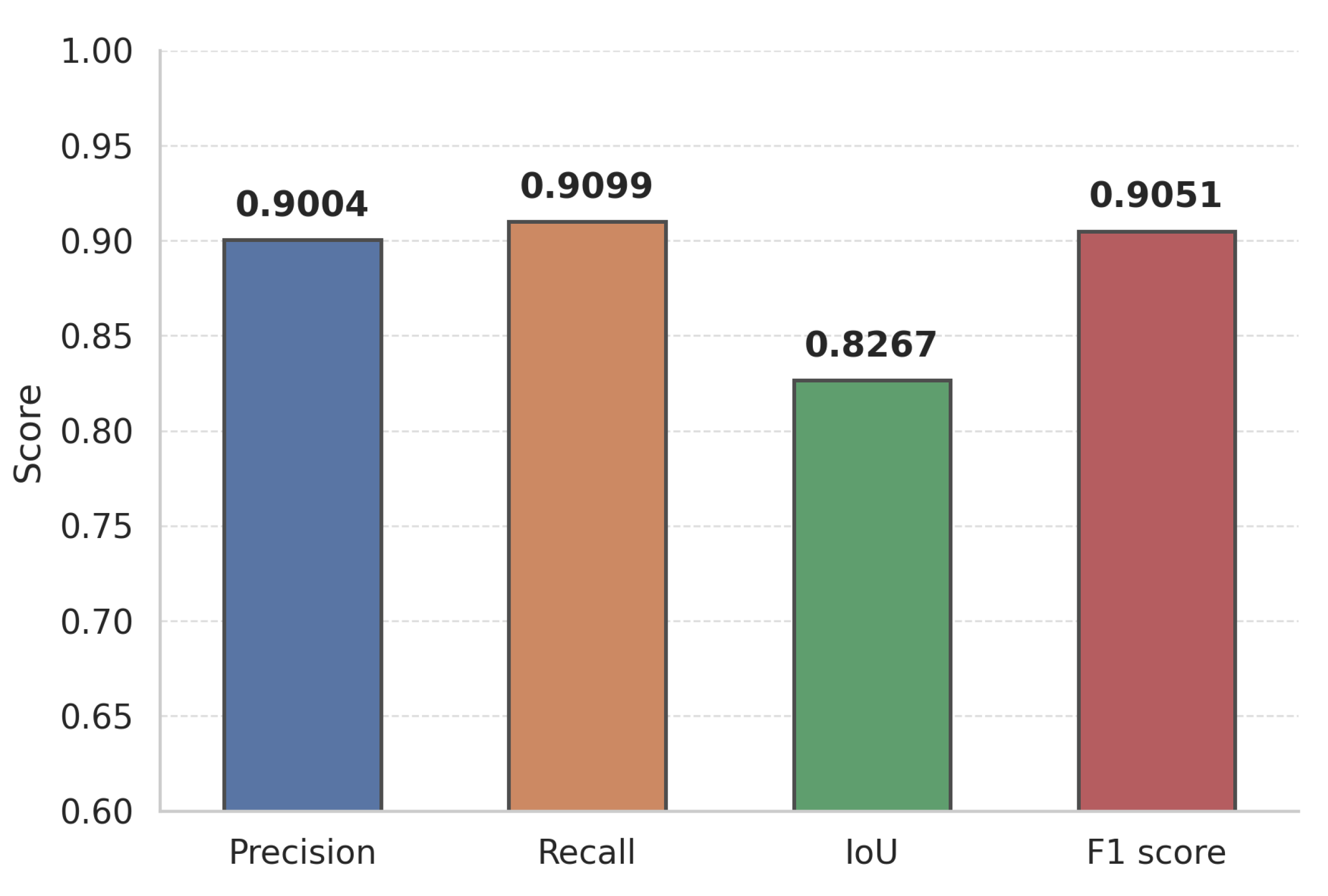
3.2. Model-to-Model Comparison
3.3. Ablation Study
3.4. Edge Device Simulation Assessment
4. Discussion
5. Conclusions
- (1)
- Embedding a carefully scoped channel and spatial attention mechanism within a streamlined encoder–decoder architecture sharpens crack-specific features without compromising computational parsimony.
- (2)
- Networks expressly tailored to the morphology and scale of concrete cracks exhibit superior discriminative power compared with broadly trained lightweight or multi-purpose vision models.
- (3)
- Constraining model depth and favouring depth-wise separable operations inherently facilitate quantization-robust, real-time inference on low-power hardware.
- (4)
- An open, ablation-driven workflow that links design choices to deployment metrics establishes a reproducible foundation for subsequent advances in lightweight defect segmentation research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Li, J.; Zhao, Y.; Wang, S.; Guan, Z. Concrete Cover Cracking and Reinforcement Corrosion Behavior in Concrete with New-to-Old Concrete Interfaces. Materials 2023, 16, 5969. [Google Scholar] [CrossRef]
- Li, G.; Boulfiza, M.; Evitts, R. On the Subtilities of Rebar Corrosion Behaviour in Cracked Concrete. Cem. Concr. Compos. 2025, 160, 106038. [Google Scholar] [CrossRef]
- Loukil, O.; Adelaide, L.; Bouteiller, V.; Quiertant, M.; Ragueneau, F.; Chaussadent, T. Investigation of Corrosion Product Distribution and Induced Cracking Patterns in Reinforced Concrete Using Accelerated Corrosion Testing. Appl. Sci. 2024, 14, 11453. [Google Scholar] [CrossRef]
- Bah, A.S.; Zhang, Y.; Sasai, K.; Chen, X. Bridge Service Life and Impact of Maintenance Events on the Structural State Index. Case Stud. Constr. Mater. 2025, 22, e04766. [Google Scholar] [CrossRef]
- Xu, J.; Yu, X. Detection of Concrete Structural Defects Using Impact Echo Based on Deep Network. J. Test. Eval. 2020, 49, 109–120. [Google Scholar] [CrossRef]
- Nepomuceno, D.T.; Vardanega, P.J.; Tryfonas, T.; Pregnolato, M.; Bennetts, J.; Webb, G. A Survey of Emerging Technologies for the Future of Routine Visual Inspection of Bridge Structures. In Proceedings of the Bridge Safety, Maintenance, Management, Life-Cycle, Resilience and Sustainability (IABMAS 2022), Barcelona, Spain, 11–15 July 2022; CRC Press: Boca Raton, FL, USA, 2022; pp. 846–854. [Google Scholar]
- Iwamoto, T.; Hayama, K.; Irie, H.; Matsuka, T. Development of Rail Camera for Bridge Inspection with Attitude Control Using Thrust of Rotors. E-J. Nondestruct. Test. 2024, 29, 1–8. [Google Scholar] [CrossRef]
- Dong, X.; Yuan, J.; Dai, J. Study on Lightweight Bridge Crack Detection Algorithm Based on YOLO11. Sensors 2025, 25, 3276. [Google Scholar] [CrossRef]
- Dong, C.; Bas, S.; Catbas, F.N. Applications of Computer Vision-Based Structural Monitoring on Long-Span Bridges in Turkey. Sensors 2023, 23, 8161. [Google Scholar] [CrossRef]
- Micozzi, F.; Morici, M.; Zona, A.; Dall’Asta, A. Vision-Based Structural Monitoring: Application to a Medium-Span Post-Tensioned Concrete Bridge under Vehicular Traffic. Infrastructures 2023, 8, 152. [Google Scholar] [CrossRef]
- Yuan, Q.; Shi, Y.; Li, M. A Review of Computer Vision-Based Crack Detection Methods in Civil Infrastructure: Progress and Challenges. Remote Sens. 2024, 16, 2910. [Google Scholar] [CrossRef]
- Shalaby, Y.M.; Badawy, M.; Ebrahim, G.A.; Abdelalim, A.M. Condition Assessment of Concrete Structures Using Automated Crack Detection Method for Different Concrete Surface Types Based on Image Processing. Discov. Civ. Eng. 2024, 1, 81. [Google Scholar] [CrossRef]
- Merkle, D.; Solass, J.; Schmitt, A.; Rosin, J.; Reiterer, A.; Stolz, A. Semi-Automatic 3D Crack Map Generation and Width Evaluation for Structural Monitoring of Reinforced Concrete Structures. J. Inf. Technol. Constr. 2023, 28, 774–805. [Google Scholar] [CrossRef]
- Kaveh, H.; Alhajj, R. Recent Advances in Crack Detection Technologies for Structures: A Survey of 2022–2023 Literature. Front. Built Environ. 2024, 10, 1321634. [Google Scholar] [CrossRef]
- Liu, Y. DeepLabV3+ Based Mask R-CNN for Crack Detection and Segmentation in Concrete Structures. Int. J. Adv. Comput. Sci. Appl. 2025, 16, 142–149. [Google Scholar] [CrossRef]
- Sohaib, M.; Arif, M.; Kim, J.-M. Evaluating YOLO Models for Efficient Crack Detection in Concrete Structures Using Transfer Learning. Buildings 2024, 14, 3928. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, B.; Chen, Y. EECD-Net: Energy-Efficient Crack Detection with Spiking Neural Networks. arXiv 2025, arXiv:2506.04526. [Google Scholar] [CrossRef]
- Mittal, P. A Comprehensive Survey of Deep Learning-Based Lightweight Object Detection Models for Edge Devices. Artif. Intell. Rev. 2024, 57, 242. [Google Scholar] [CrossRef]
- Ma, X.; Li, Y.; Yang, Z.; Li, S.; Li, Y. Lightweight Network for Millimeter-Level Concrete Crack Detection with Dense Feature Connection and Dual Attention. J. Build. Eng. 2024, 94, 109821. [Google Scholar] [CrossRef]
- Wang, R.; Chen, R.; Yan, H.; Guo, X. Lightweight Concrete Crack Recognition Model Based on Improved MobileNetV3. Sci. Rep. 2025, 15, 468. [Google Scholar] [CrossRef]
- Nyathi, M.A.; Bai, J.; Wilson, I.D. Deep Learning for Concrete Crack Detection and Measurement. Metrology 2024, 4, 66–81. [Google Scholar] [CrossRef]
- Sohaib, M.; Hasan, M.J.; Shah, M.A.; Zheng, Z. A Robust Self-Supervised Approach for Fine-Grained Crack Detection in Concrete Structures. Sci. Rep. 2024, 14, 12646. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Xu, J.; Wu, X.; Zhang, J.; Zhang, Z.; Chen, X. Concrete Crack Recognition and Geometric Parameter Evaluation Based on Deep Learning. Adv. Eng. Softw. 2025, 199, 103800. [Google Scholar] [CrossRef]
- Wu, Y.; Li, S.; Zhang, J.; Zhang, Y. Dual Attention Transformer Network for Pixel-Level Concrete Crack Segmentation Considering Camera Placement. Autom. Constr. 2024, 157, 105166. [Google Scholar] [CrossRef]
- Bai, Y.; Lu, E.; Wang, H. A Pavement Crack Segmentation Algorithm Based on I-U-Net Network. IAENG Int. J. Comput. Sci. 2025, 52, 1833–1844. [Google Scholar]
- Yan, Y.; Sun, J.; Zhang, H.; Tang, C.; Wu, X.; Wang, S.; Zhang, Y. DCMA-Net: A Dual Channel Multi-Scale Feature Attention Network for Crack Image Segmentation. Eng. Appl. Artif. Intell. 2025, 148, 110411. [Google Scholar] [CrossRef]
- Tang, W.; Wu, Z.; Wang, W.; Pan, Y.; Gan, W. VM–UNet++ Research on Crack Image Segmentation Based on Improved VM–UNet. Sci. Rep. 2025, 15, 8938. [Google Scholar] [CrossRef]
- Li, L.; Fang, B.; Zhu, J. Performance Analysis of the YOLOv4 Algorithm for Pavement Damage Image Detection with Different Embedding Positions of CBAM Modules. Appl. Sci. 2022, 12, 10180. [Google Scholar] [CrossRef]
- Nyathi, M.A.; Bai, J.; Wilson, I.D. NYA-Crack-Data: A High Variability Concrete Crack Dataset for Enhanced Model Generalisation 2024. Available online: https://data.mendeley.com/datasets/z93rb2m4fk/1 (accessed on 14 July 2025).
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An Annotated Image Dataset for Non-Contact Concrete Crack Detection Using Deep Convolutional Neural Networks. Data Brief. 2018, 21, 1664–1668. [Google Scholar] [CrossRef]
- Soni, V.; Shah, D.; Joshi, J.; Gite, S.; Pradhan, B.; Alamri, A. Introducing AOD 4: A Dataset for Air Borne Object Detection. Data Brief. 2024, 56, 110801. [Google Scholar] [CrossRef]
- Chen, B.; Wen, M.; Shi, Y.; Lin, D.; Rajbahadur, G.K.; Jiang, Z.M. Towards Training Reproducible Deep Learning Models. In Proceedings of the 44th International Conference on Software Engineering (ICSE 2022), Pittsburgh, PA, USA, 25–27 May 2022; pp. 1–13. [Google Scholar]
- Kelesis, D.; Fotakis, D.; Paliouras, G. Reducing Oversmoothing through Informed Weight Initialization in Graph Neural Networks. Appl. Intell. 2025, 55, 632. [Google Scholar] [CrossRef]
- Zhuang, Z.; Liu, M.; Cutkosky, A.; Orabona, F. Understanding AdamW through Proximal Methods and Scale-Freeness. arXiv 2022, arXiv:2202.00089. [Google Scholar] [CrossRef]
- Tummala, B.M.; Chavva, S.R.; Yallamandaiah, S.; Radhika, A.; Veeraiah, D.C.; Jaladi, R.; Peruri, A.K. Automated GI Tract Segmentation with U-Net: A Comparative Study of Loss Functions. J. Adv. Inf. Technol. 2024, 15, 1304–1314. [Google Scholar] [CrossRef]
- Xu, J.; Shen, Z. Recognition of the Distress in Concrete Pavement Using Deep Learning Based on GPR Image. In Proceedings of the Structural Health Monitoring, California, CA, USA, 10–12 September 2019; DEStech Publications, Inc.: Lancaster, PA, USA, 2019. [Google Scholar]
- Hirling, D.; Tasnadi, E.; Caicedo, J.; Caroprese, M.V.; Sjögren, R.; Aubreville, M.; Koos, K.; Horvath, P. Segmentation Metric Misinterpretations in Bioimage Analysis. Nat. Methods 2023, 21, 213–216. [Google Scholar] [CrossRef] [PubMed]
- Yeung, M.; Sala, E.; Schönlieb, C.-B.; Rundo, L. Unified Focal Loss: Generalising Dice and Cross-Entropy Based Losses to Handle Class-Imbalanced Medical Image Segmentation. Comput. Med. Imaging Graph. 2022, 95, 102026. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: New York, NY, USA, 2016; pp. 3708–3712. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Probability | Parameters |
|---|---|---|
| Horizontal flip | 0.5 | — |
| Vertical flip | 0.5 | — |
| Random rotation | 1.0 | ±15° |
| Colour jitter | 1.0 | brightness/contrast/saturation = 0.2; hue = 0.1 |
| Method | Threshold | Precision | Recall | IoU | F1 |
|---|---|---|---|---|---|
| CrackTree | 0.146 | 0.621 | 0.853 | 0.561 | 0.719 |
| Hybrid 2020 | 0.152 | 0.698 | 0.833 | 0.612 | 0.759 |
| MobileNetV3 | 0.308 | 0.855 | 0.880 | 0.766 | 0.867 |
| ESPNetv2 | 0.174 | 0.671 | 0.817 | 0.583 | 0.737 |
| L-DANet (ours) | 0.252 | 0.900 | 0.910 | 0.827 | 0.905 |
| Method | Threshold | Precision | Recall | IoU | F1 |
|---|---|---|---|---|---|
| YOLO-v11-Seg | 0.171 | 0.851 | 0.937 | 0.805 | 0.892 |
| L-DANet (ours) | 0.252 | 0.900 | 0.910 | 0.827 | 0.905 |
| Configuration | Prec. | Rec. | IoU | F1 |
|---|---|---|---|---|
| Baseline | 0.890 | 0.904 | 0.813 | 0.897 |
| +Init | 0.894 | 0.909 | 0.820 | 0.901 |
| +Init + Dice | 0.900 | 0.904 | 0.821 | 0.902 |
| +Init + Dice + DA (full) | 0.900 | 0.910 | 0.827 | 0.905 |
| Metric | Desktop CPU | Jetson Nano | Jetson Xavier | Coral TPU |
|---|---|---|---|---|
| Simulated latency (ms) | 12.86 | 9.08 | 6.11 | 4.55 |
| Simulated throughput (FPS) | 77.8 | 110.1 | 163.8 | 219.9 |
| Estimated power (W) | 15 | 10 | 10 | 5 |
| Model size (MB) | 7.4 | 7.4 | 7.4 | 7.4 |
| Working memory (MB) | 14.8 | 14.8 | 14.8 | 14.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, M.; Xu, J. Lightweight Dual-Attention Network for Concrete Crack Segmentation. Sensors 2025, 25, 4436. https://doi.org/10.3390/s25144436
Feng M, Xu J. Lightweight Dual-Attention Network for Concrete Crack Segmentation. Sensors. 2025; 25(14):4436. https://doi.org/10.3390/s25144436
Chicago/Turabian StyleFeng, Min, and Juncai Xu. 2025. "Lightweight Dual-Attention Network for Concrete Crack Segmentation" Sensors 25, no. 14: 4436. https://doi.org/10.3390/s25144436
APA StyleFeng, M., & Xu, J. (2025). Lightweight Dual-Attention Network for Concrete Crack Segmentation. Sensors, 25(14), 4436. https://doi.org/10.3390/s25144436