In this section, we conduct extensive experiments to evaluate the performance of FRDR using MATLAB R2020b.
6.3. Performance Analysis
The performance metrics employed in our simulation are packet delivery rate (PDR), mean transmission delay (MTD), mean number of transmission hops (MTHs), mean energy consumption for delivering a data packet (MECP), and network lifetime. The network lifetime can be commonly measured in terms of the first node dead (FND), half node dead (HND), and the last node dead (LND). However, only HND is adopted in our simulation as the network was disabled long before LND, while the death of the first EN had little impact on network performance.
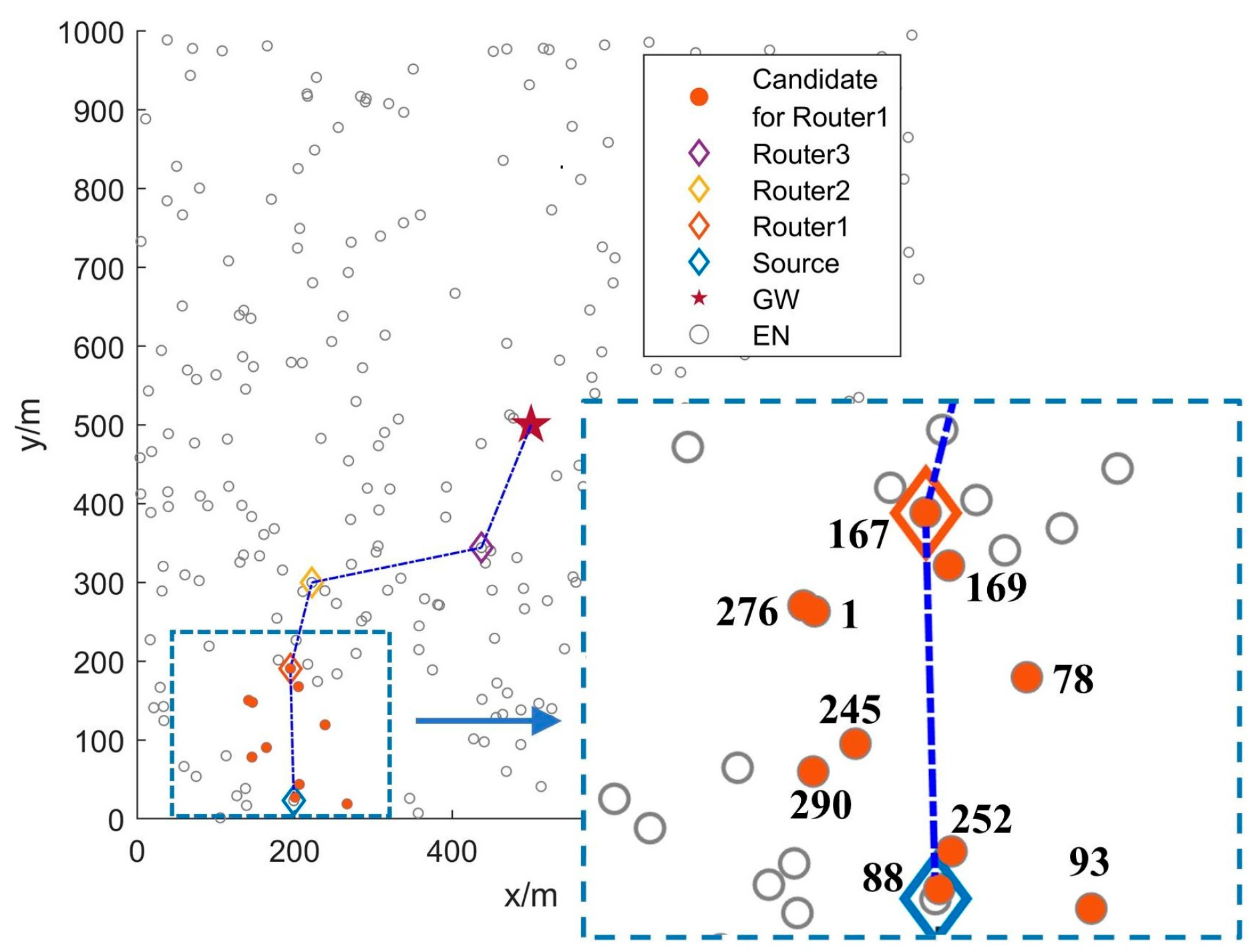
We randomly select an experimental scenario with 300 ENs from our simulations and use the routing process of the first data packet after network deployment to visually demonstrate the FRDR protocol in
Figure 5. To clarify the relay selection mechanism of FRDR,
Figure 5 further illustrates the spatial distribution of candidate ENs for Router1. Specifically, the source EN first adjusts its transmission power level according to PRM, thereby optimizing the EN activation range based on the average SNR of received signals from neighbors. In this case, the source EN broadcasts an ADV packet at Level 6. Subsequently, ENs that receive the ADV packet and satisfy pre-selection rules form the candidate set for Router1.
Table 9 quantitatively summarizes their critical attributes, including ID, RFRV, distance to the GW, and residual energy. Then, by utilizing the DQN-based routing decision mechanism (Algorithm 3), the source EN determines Router1 from the candidates. Experimental result indicates that EN167, the candidate EN exhibiting the lowest RFRV and shortest distance to the GW, is selected as Router1. This outcome is consistent with the relay selection objective of FRDR defined in Equation (14).
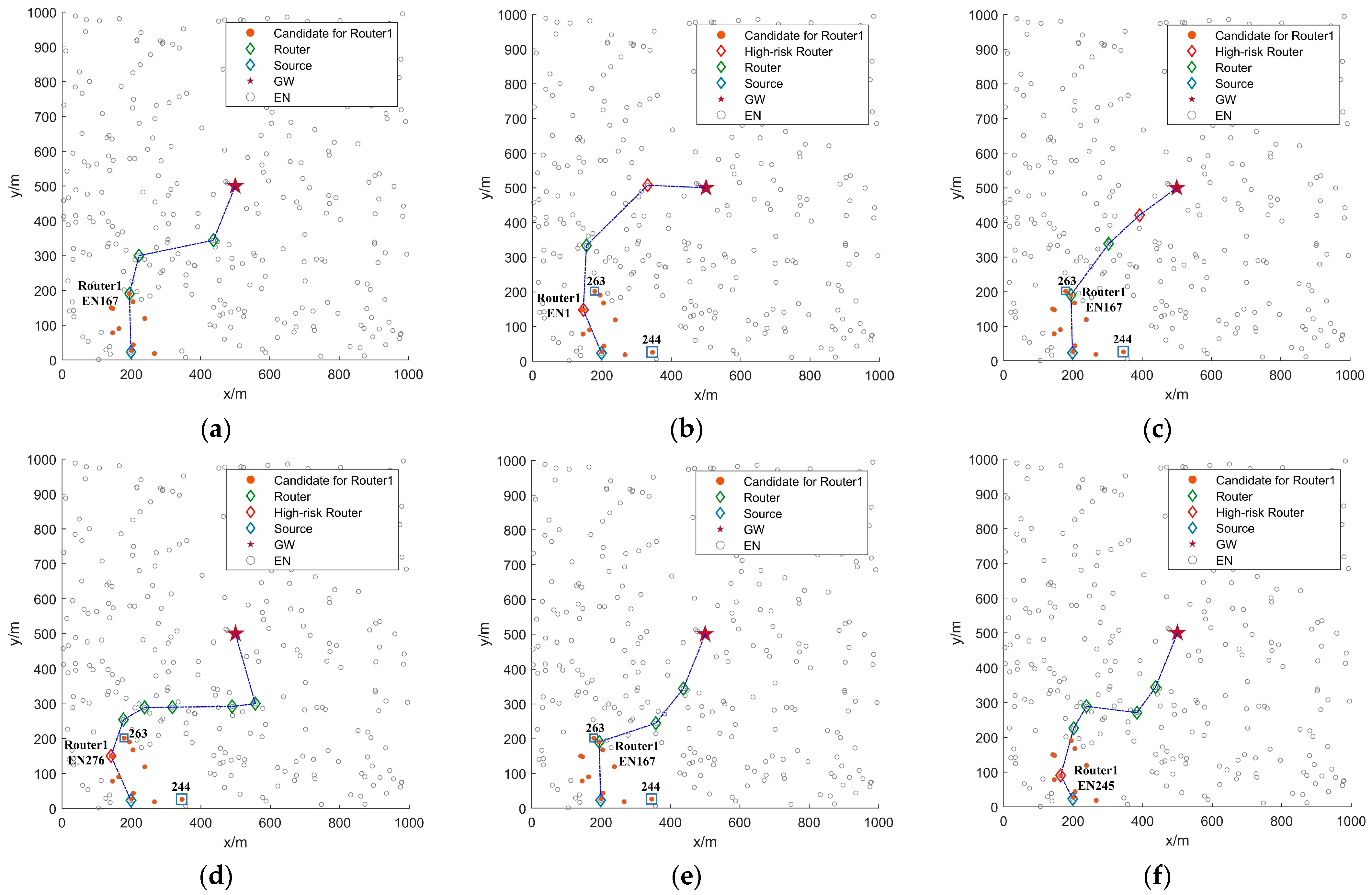
With the identical configuration as
Figure 5,
Figure 6 further compares routing processes across different multi-hop routing algorithms. As shown in
Figure 6, both FRDR and PRRS exhibit fewer candidate ENs for Router1. This reduction is primarily attributed to the PRM, which adjusts EN activation ranges based on the average SNR of received signals from neighbors. By utilizing PRM, the source EN in FRDR and PRRS reduces transmission power to Level 6, thereby confining the ADV broadcast range. In contrast, non-PRM protocols broadcast ADV packets at maximum power (Level 7), which can easily cause redundant EN activation (e.g., EN263 and EN244). Following candidate screening, each algorithm applies distinct criteria for final relay selection. Notably, PFRS and PRRS exhibit higher hop counts due to random relay selection, whereas FRDR, MHR, DQIR, and PFRD achieve lower hop counts through effective selection rules. Specifically, MHR selects relays via pre-stored routing tables guided by minimum hop counts, while DQIR prioritizes relays that minimize distance to the GW and balance residual energy distribution. FRDR and PFRD incorporate multi-dimensional neighborhood state characteristics of candidate ENs into routing decisions, effectively avoiding relays that introduce high routing failure risk (e.g., Router1 in MHR and Router3 in DQIR).
First, the performance analysis of the proposed PRM and Algorithm 3 is provided.
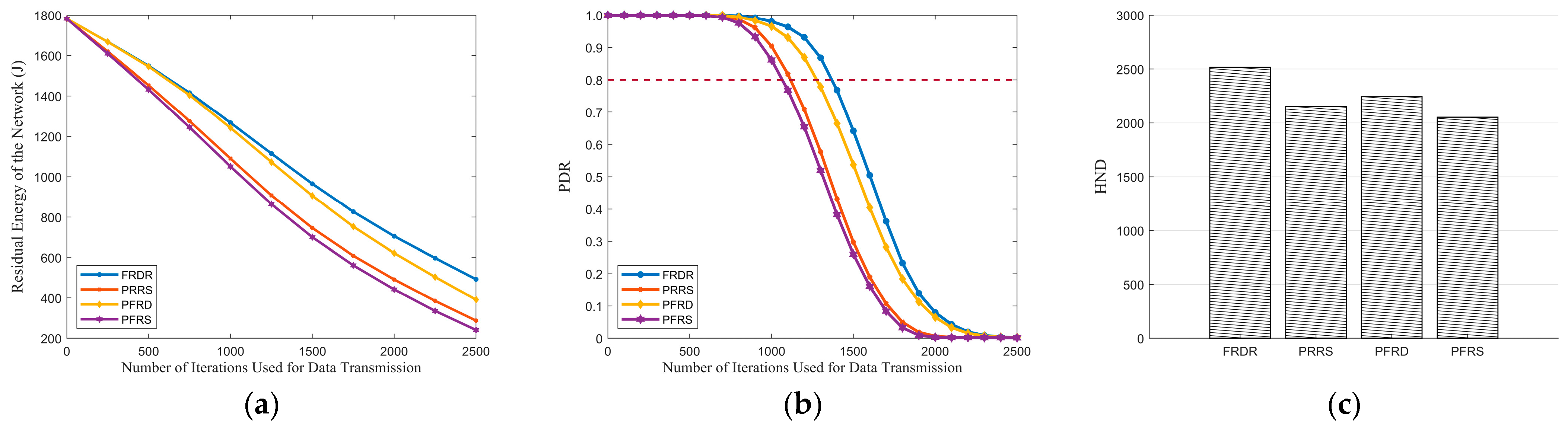
Figure 7a demonstrates that PRM effectively reduces energy consumption. By employing PRM, DENs in FRDR and PRRS adjust transmission power levels according to demand, thereby reducing redundant EN activations. Consequently, the lifetime of individual EN can be extended, which in turn enhances the overall network lifetime and PDR.
Figure 7b further illustrates that the PDR curves of PRRS and FRDR decline more slowly than PFRS and PFRD. Specifically, when the PDR of PFRD and PFRS drops to 0.80, FRDR and PRRS maintain values of 0.88 and 0.85, representing improvements of 10.00% and 6.25%, respectively. Additionally, as depicted in
Figure 7c, both FRDR and PRRS achieve higher HND than their respective counterparts, which confirms the effectiveness of PRM in extending network lifetime.
Table 10 presents a comparison of MTH, MTD, and MECP for delivering the first 1000 packets, during which the PDR of each algorithm remains at a relatively high level. It reveals that PRM introduces a slight increase in transmission delay. Compared to PFRD and PFRS, the MTH of FRDR and PRRS increased by 0.20 and 0.30, respectively. This increase is attributed to the fact that the execution of PRM prevents the single-hop range from consistently reaching its maximum, potentially increasing the number of hops required for data delivery. Nevertheless, through the effective combination with pre-selection rules, PRM further amplifies the benefits of reducing redundant EN activations, thereby significantly decreasing the delay and energy consumption associated with REQ packet reception. As a result, the impact of these additional hops on overall delay is minimal. Specifically, the 0.14 s increase in MTD for FRDR constitutes only 3.26% of its total MTD, while for PRRS, it accounts for 3.13%. Overall, PRM achieves an effective balance between transmission efficiency and other critical performance metrics, including energy consumption, PDR, and network lifetime.
As for Algorithm 3,
Figure 7b clearly illustrates its superiority in PDR. Specifically, when the PDR of PRRS and PFRS decreases to 0.80, FRDR and PFRD sustain values of 0.96 and 0.94, achieving improvements of 20.00% and 17.5%. These improvements arise from the multi-factor routing strategy of Algorithm 3, where RFRV, distance to the GW, transmission hops, and residual energy are considered in tandem. Therefore, Algorithm 3 effectively reduces transmission disruption and enables faster delivery to the GW while balancing energy consumption. The results presented in
Figure 7c and
Table 10 further confirm the advantage of Algorithm 3. In terms of HND, FRDR improved by 16.81%, while PFRD achieved a growth rate of 9.46%. Additionally, during the whole network lifetime, FRDR achieves reductions of 21.48%, 25.35%, and 24.64% in MTH, MTD, and MECP, respectively, compared to PRRS, while PFRD demonstrates reductions of 20.75%, 25.45%, and 26.03%.
Second, to fully illustrate the superiority of FRDR, a comparison among FRDR, MHR, and DQIR is presented.
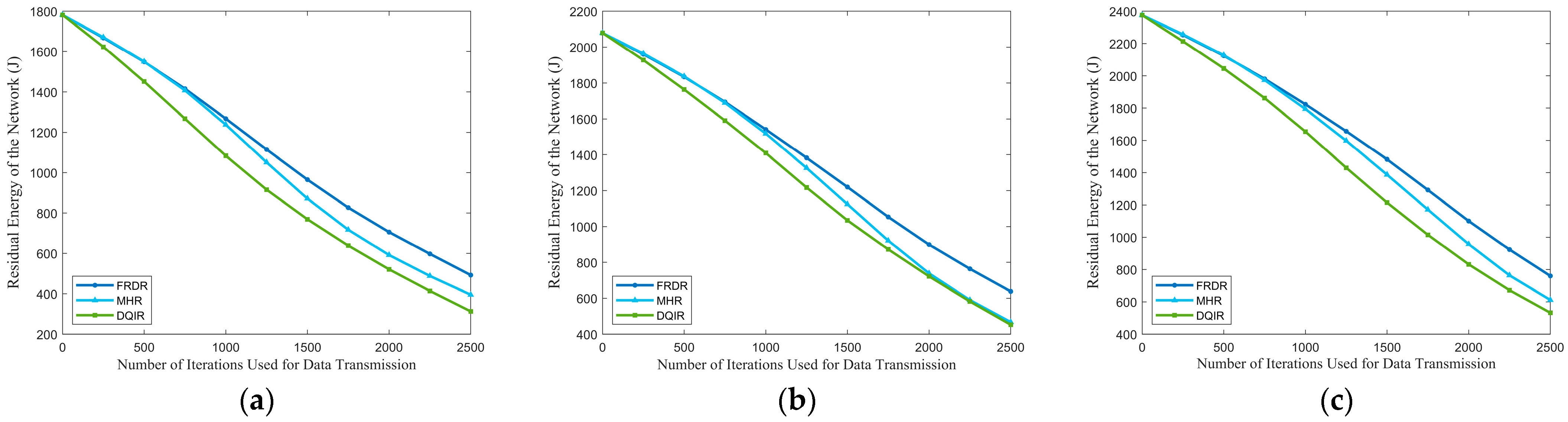
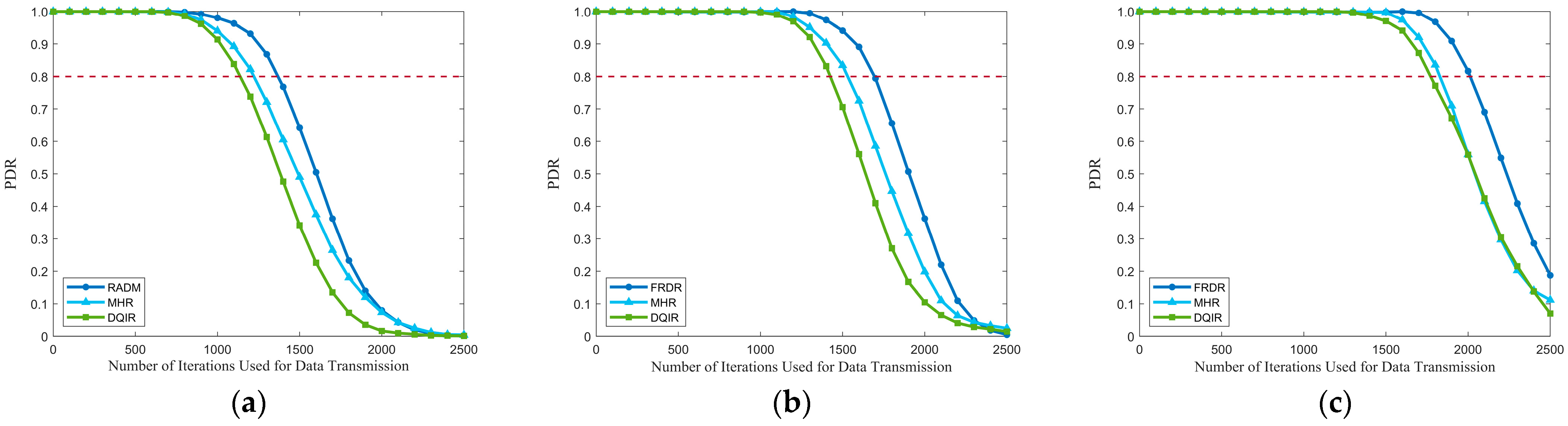
The comparisons of PDR and residual energy of the network among different EN densities are depicted in
Figure 8 and
Figure 9. It is evident that FRDR significantly outperforms MHR and DQIR by maintaining a higher PDR and reducing energy consumption. Moreover,
Table 11 provides a comparison of network lifetime, while a more detailed comparison of MTH, MTD, and MECP across different EN densities is presented in
Table 12. They demonstrate that FRDR achieves the longest network lifetime while maintaining comparable transmission delay. These improvements are attributed to the integration of PRM and the DQN-based multi-factor routing strategy, which dynamically adjusts activation range to reduce redundant activation and optimizes routing decisions based on RFRV, residual energy, transmission hops, and the distance to the GW.
MHR focuses solely on minimizing transmission hops, which contributes to its superiority in MTH, as shown in
Table 12. However, to achieve this goal, the maximum transmission power is fixed in MHR, which leads to higher redundant activation than FRDR, particularly as EN density increases. This increased redundancy diminishes the delay and energy efficiency advantages gained by minimizing transmission hops, as higher reception delay and energy consumption occur during REQ reception.
Table 12 further reveals that MHR results in a higher MECP than FRDR, while achieving a marginal reduction in MTD. Moreover, the exclusive consideration of hop count in MHR inevitably leads to hotspot issues due to the overutilization of partial ENs, which in turn leads to a shorter network lifetime and lower PDR. Conversely, by integrating RFRV and residual energy into routing decisions, FRDR effectively avoids routers that will introduce high routing failure risk and realizes a more balanced energy distribution. As a result, FRDR achieves a higher network lifetime and PDR. Specifically, when the PDR of MHR drops to 0.80, FRDR maintains a higher PDR, achieving improvements of 14.71%, 15.69%, and 18.90% at EN densities of 300, 350, and 400, respectively. Consequently, compared to MHR, FRDR effectively improves the PDR and network lifetime while maintaining a comparable transmission delay.
As for DQIR, multiple factors, including residual energy and distance to the GW, are considered when selecting the next-hop router from candidate ENs to minimize delay and balance energy distribution.
Table 12 indicates that DQIR achieves lower MTH at EN densities of 350 and 400 compared to FRDR. However, DQIR requires all ENs that receive broadcast information to transmit a message to a designated agent for routing decisions. Although this method offloads the reception energy consumption from DEN to an additional agent without energy constraints, leading to more balanced energy consumption, the excessive overhead from replies significantly increases energy consumption and delay. In contrast, through the combination of PRM and pre-selection rules, FRDR effectively reduces redundant transmissions by dynamically adjusting activation ranges and requiring only ENs that meet the pre-selection rules to respond. As a result, compared to DQIR, FRDR achieves lower MTD and MECP, as well as a higher network lifetime. Moreover, by considering RFRV, FRDR effectively avoids selecting candidate routers that will introduce high routing failure risk, which further enhances the performance of PDR. Specifically, when the PDR of DQIR drops to 0.80, FRDR maintains a higher PDR, achieving improvements of 18.90%, 20.68%, and 21.96% at EN densities of 300, 350, and 400, respectively.
To summarize, the performance superiority of FRDR mainly comes from the PRM and DQN-based routing decision mechanism. PRM dynamically adjusts activation ranges, which works with pre-selection rules, further reducing unnecessary reception overhead. Meanwhile, the RFRV, in conjunction with other factors such as residual energy, distance to the GW, and transmission hops, is integrated into the DQN-based routing decision mechanism, effectively reducing transmission disruption and enabling faster delivery to the GW while balancing energy consumption. Consequently, FRDR significantly enhances PDR and network lifetime while maintaining a comparable transmission delay.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}