

Fusion of Multimodal Spatio-Temporal Features and 3D Deformable Convolution Based on Sign Language Recognition in Sensor Networks


Abstract
1. Introduction
2. Related Work
2.1. Raw Image-Based SLR
2.2. Skeleton-Based SLR
2.3. Multimodality-Based SLR
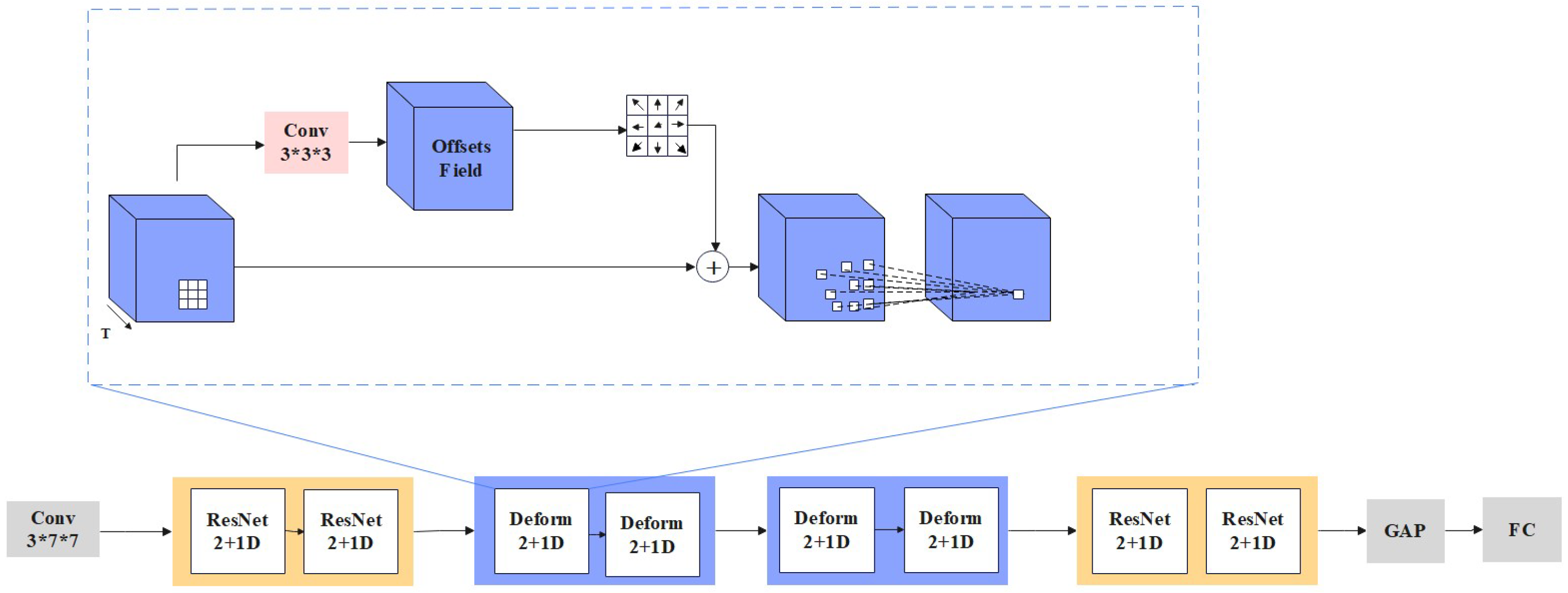
3. Proposed Method
3.1. Skeleton Modality
3.1.1. Multi-Stream Skeleton Features
3.1.2. MSGCN
3.2. Raw Image Modality
3.3. Multimodal Fusion
4. Experiments and Results Analysis
4.1. Evaluation Datasets
4.2. Implementation Details
4.3. Performance Comparison
4.3.1. Comparison Experiment on AUTSL Dataset
4.3.2. Comparison Experiment on WLASL Dataset
4.4. Ablation Study
4.4.1. Effects of Multi Skeleton Features
4.4.2. Effects of Different Components in MSGCN
4.4.3. Effects of 3D Deformable Convolution
4.4.4. Effects of Multimodal Fusion
4.5. Limitation Discussion
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aditya, W.; Shih, T.K.; Thaipisutikul, T.; Fitriajie, A.S.; Gochoo, M.; Utaminingrum, F.; Lin, C.-Y. Novel Spatio-Temporal Continuous Sign Language Recognition Using an Attentive Multi-Feature Network. Sensors 2022, 22, 6452. [Google Scholar] [CrossRef] [PubMed]
- Khan, Y.N.; Mehdi, S.A. Sign language recognition using sensor gloves. In Proceedings of the 9th International Conference on Neural Information Processing, Singapore, 18–22 November 2002; pp. 2204–2206. [Google Scholar]
- Amin, M.S.; Rizvi, S.T.H.; Hossain, M.M. A comparative review on applications of different sensors for sign language recognition. J. Imaging 2022, 8, 98. [Google Scholar] [CrossRef]
- Lu, Z.; Chen, X.; Li, Q.; Wei, W.; Li, Y.; Xu, W.; Li, K. A hand gesture recognition framework and wearable gesture-based interaction prototype for mobile devices. IEEE Trans. -Hum.-Mach. Syst. 2014, 44, 293–299. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Online early-late fusion based on adaptive hmm for sign language recognition. Acm Trans. Multimed. Comput. Commun. Appl. TOMM 2017, 21, 1–18. [Google Scholar] [CrossRef]
- Dardas, N.H.; Georganas, N.D. Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Sincan, O.M.; Tur, A.O.; Keles, H.Y. Isolated sign language recognition with multi-scale features using LSTM. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Sign language recognition using 3d convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Wang, S.; Wang, K.; Yang, T.; Li, Y.; Fan, D. Improved 3D-ResNet sign language recognition algorithm with enhanced hand features. Sci. Rep. 2022, 12, 17812. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Attention-based 3D-CNNs for large-vocabulary sign language recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2822–2832. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Hassanien, A.E.; Shahin, M.K.; Refaat, B. Sift-based arabic sign language recognition system. In Afro-European Conference for Industrial Advancement, Proceedings of the First International Afro-European Conference for Industrial Advancement AECIA 2014, Addis Ababa, Ethiopia, 17–19 November 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 359–370. [Google Scholar]
- Zhang, J.; Zhou, W.; Xie, C.; Pu, J.; Li, H. Chinese sign language recognition with adaptive HMM. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Lee, G.C.; Fu, Y.; Yi, H. Kinect-based Taiwanese sign-language recognition system. Multimed. Tools Appl. 2016, 75, 261–279. [Google Scholar] [CrossRef]
- Rahman, M.M.; Islam, M.S.; Rahman, M.H.; Sassi, R.; Rivolta, M.W.; Aktaruzzaman, M. A new benchmark on american sign language recognition using convolutional neural network. In Proceedings of the 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Mittal, A.; Kumar, P.; Roy, P.P.; Balasubramanian, R.; Chaudhuri, B.B. A modified LSTM model for continuous sign language recognition using leap motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, K. ASL-3DCNN: American sign language recognition technique using 3-D convolutional neural networks. Multimed. Tools Appl. 2021, 80, 26319–26331. [Google Scholar] [CrossRef]
- Liu, T.; Zhou, W.; Li, H. Sign language recognition with long short-term memory. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2871–2875. [Google Scholar]
- Masood, S.; Srivastava, A.; Thuwal, H.C.; Ahmad, M. Real-time sign language gesture (word) recognition from video sequences using CNN and RNN. In Intelligent Engineering Informatics, Proceedings of the 6th International Conference on FICTA; Springer: Berlin/Heidelberg, Germany, 2018; pp. 623–632. [Google Scholar]
- Basnin, N.; Nahar, L.; Hossain, M.S. An integrated CNN-LSTM model for Bangla lexical sign language recognition. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering, TCCE 2020, Dhaka, Bangladesh, 17–18 December 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 695–707. [Google Scholar]
- Bendarkar, D.S.; Somase, P.A.; Rebari, P.K.; Paturkar, R.R.; Khan, A.M. Web based recognition and translation of American sign language with CNN and RNN. Int. J. Online Eng. 2021, 17, 34–50. [Google Scholar] [CrossRef]
- Yang, Z.; Shi, Z.; Shen, X.; Tai, Y.-W. Sf-net: Structured feature network for continuous sign language recognition. arXiv 2019, arXiv:1908.01341. [Google Scholar]
- Hu, H.; Zhou, W.; Li, H. Hand-model-aware sign language recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1558–1566. [Google Scholar]
- Boháček, M.; Hrúz, M. Sign pose-based transformer for word-level sign language recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 182–191. [Google Scholar]
- Liu, Y.; Lu, F.; Cheng, X.; Yuan, Y.; Tian, G. Multi-stream gcn for sign language recognition based on asymmetric convolution channel attention. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 16–19 December 2022; IEEE: Piscataway, NJ, USA, 2022; Volume 23, pp. 614–619. [Google Scholar]
- Coster, M.D.; Herreweghe, M.V.; Dambre, J. Sign language recognition with transformer networks. In Proceedings of the 12th International Conference on Language Resources and Evaluation, European Language Resources Association (ELRA), Palais du Pharo, Marseille, 11–16 May 2020; pp. 6018–6024. [Google Scholar]
- Tunga, A.; Nuthalapati, S.V.; Wachs, J. Pose-based sign language recognition using gcn and bert. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 31–40. [Google Scholar]
- Parelli, M.; Papadimitriou, K.; Potamianos, G.; Pavlakos, G.; Maragos, P. Spatio-temporal graph convolutional networks for continuous sign language recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 8457–8461. [Google Scholar]
- Meng, L.; Li, R. An attention-enhanced multi-scale and dual sign language recognition network based on a graph convolution network. Sensors 2021, 21, 1120. [Google Scholar] [CrossRef]
- Naz, N.; Sajid, H.; Ali, S.; Hasan, O.; Ehsan, M.K. Signgraph: An efficient and accurate pose-based graph convolution approach toward sign language recognition. IEEE Access 2023, 11, 19135–19147. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, S.; Tan, L.; Fang, K.; Du, Y. Interactive attention and improved GCN for continuous sign language recognition. Biomed. Signal Process. Control 2023, 85, 104931. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Jang, S.-W.; Lee, H.-S.; Shin, J. Multi-stream general and graph-based deep neural networks for skeleton-based sign language recognition. Electronics 2023, 12, 2841. [Google Scholar] [CrossRef]
- Gao, Q.; Ogenyi, U.E.; Liu, J.; Ju, Z.; Liu, H. A two-stream CNN framework for American sign language recognition based on multimodal data fusion. In Advances in Computational Intelligence Systems, Proceedings of the 19th UK Workshop on Computational Intelligence, Portsmouth, UK, 4–6 September 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 107–118. [Google Scholar]
- Xiao, F.; Shen, C.; Yuan, T.; Chen, S. CRB-Net: A sign language recognition deep learning strategy based on multi-modal fusion with attention mechanism. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 24, pp. 2562–2567. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Hand pose aware multimodal isolated sign language recognition. Multimed. Tools Appl. 2021, 80, 127–163. [Google Scholar] [CrossRef]
- Singla, N.; Taneja, M.; Goyal, N.; Jindal, R. Feature Fusion and Multi-Stream CNNs for ScaleAdaptive Multimodal Sign Language Recognition. In Proceedings of the 2023 9th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 17–18 March 2023; IEEE: Piscataway, NJ, USA, 2023; Volume 1, pp. 1266–1273. [Google Scholar]
- Almeida, S.G.M.; Guimarães, F.G.; Ramírez, J.A. Feature extraction in Brazilian Sign Language Recognition based on phonological structure and using RGB-D sensors. Expert Syst. Appl. 2014, 41, 7259–7271. [Google Scholar] [CrossRef]
- Gökçe, Ç.; Özdemir, O.; Kındıroğlu, A.A.; Akarun, L. Score-level multi cue fusion for sign language recognition. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 294–309. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Sign language recognition via skeleton-aware multi-model ensemble. arXiv 2021, arXiv:2110.06161. [Google Scholar]
- Hu, H.; Zhao, W.; Zhou, W.; Li, H. SignBERT+: Hand-Model-Aware Self-Supervised Pre-Training for Sign Language Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11221–11239. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Q.; Wang, Q. A sign language recognition framework based on cross-modal complementary information fusion. IEEE Trans. Multimed. 2024, 26, 8131–8144. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, L.; Huang, W.; Wu, H.; Song, A. Deformable convolutional networks for multimodal human activity recognition using wearable sensors. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef]
- Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.; Cheng, J.; Lu, H. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 536–553. [Google Scholar]
- Song, Y.; Zhang, Z.; Shan, C.; Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Volume 25, pp. 6450–6459. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Sincan, O.M.; Keles, H.Y. Autsl: A large scale multi-modal turkish sign language dataset and baseline methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Li, D.; Opazo, C.R.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Coster, M.D.; Herreweghe, M.V.; Dambre, J. Isolated sign recognition from rgb video using pose flow and self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3441–3450. [Google Scholar]
- Laines, D.; Gonzalez-Mendoza, M.; Ochoa-Ruiz, G.; Bejarano, G. Isolated Sign Language Recognition based on Tree Structure Skeleton Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 276–284. [Google Scholar]
- Vázquez-Enríquez, M.; Alba-Castro, J.L.; Docío-Fernández, L.; Rodríguez-Banga, E. Isolated sign language recognition with multi-scale spatial-temporal graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3462–3471. [Google Scholar]
- Deng, Z.; Leng, Y.; Chen, J.; Yu, X.; Zhang, Y.; Gao, Q. TMS-Net: A multi-feature multi-stream multi-level information sharing network for skeleton-based sign language recognition. Neurocomputing 2024, 572, 127194. [Google Scholar] [CrossRef]
- Hrúz, M.; Gruber, I.; Kanis, J.; Boháček, M.; Hlaváč, M.; Krňoul, Z. One model is not enough: Ensembles for isolated sign language recognition. Sensors 2022, 22, 5043. [Google Scholar] [CrossRef]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3413–3423. [Google Scholar]
- Novopoltsev, M.; Verkhovtsev, L.; Murtazin, R.; Milevich, D. Fine-tuning of sign language recognition models: A technical report. arXiv 2023, arXiv:2302.07693. [Google Scholar]
- Albanie, S.; Varol, G.; Momeni, L.; Afouras, T.; Chung, J.S.; Fox, N.; Zisserman, A. BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI 16. Springer: Berlin/Heidelberg, Germany, 2020; Volume 26, pp. 35–53. [Google Scholar]
- Song, N.; Xiang, Y. Slgtformer: An attention-based approach to sign language recognition. arXiv 2022, arXiv:2212.10746. [Google Scholar]
- Maruyama, M.; Singh, S.; Inoue, K.; Roy, P.P.; Iwamura, M.; Yoshioka, M. Word-level sign language recognition with multi-stream neural networks focusing on local regions. arXiv 2021, arXiv:2106.15989. [Google Scholar]
- Zhao, W.; Hu, H.; Zhou, W.; Shi, J.; Li, H. Best: Bert pre-training for sign language recognition with coupling tokenization. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; Volume 37, pp. 3597–3605. [Google Scholar]
- Hu, H.; Zhao, W.; Zhou, W.; Wang, Y.; Li, H. Signbert: Pre-training of hand-model-aware representation for sign language recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11087–11096. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Classes | Language | Signers |
|---|---|---|---|---|
| WLASL | 21,083 | 2000 | American | 119 |
| AUTSL | 36,302 | 226 | Turkish | 43 |
| CSL-500 | 125,000 | 500 | Chinese | 50 |
| LSA64 | 3200 | 64 | Argentinian | 10 |
| BSL-1K | 273,000 | 1064 | British | 40 |
| Methods | Modalities | Top-1 (%) | Top-5 (%) |
|---|---|---|---|
| BLSTM [50] | R | 49.22 | - |
| VTN-PF [52] | R | 92.92 | - |
| SL-TSSI-DenseNet [53] | S | 93.13 | - |
| SamSLR-V2 (R) [40] | R | 95.00 | 99.47 |
| D-ResNet (Ours) | R | 95.83 | 99.73 |
| MS-G3D [54] | S | 95.95 | 99.55 |
| SamSLR-V2 (S) [40] | S | 96.53 | 99.81 |
| TMS-Net [55] | S | 96.62 | 99.71 |
| MSGCN (Ours) | S | 96.85 | 99.84 |
| MS-G3D [54] | R + S | 96.15 | - |
| NTIS [56] | R + S + O | 96.37 | - |
| SamSLR-V1 [57] | R + S + D + O | 97.51 | 100 |
| SamSLR-V2 [40] | R + S + D + O | 98.53 | 100 |
| Ours | R + S | 98.13 | 100 |
| Methods | Modalities | Top-1 (%) | Top-5 (%) |
|---|---|---|---|
| WLASL [51] | S | 22.54 | 49.81 |
| I3D [51] | R | 32.48 | 57.31 |
| BSL [59] | R | 46.82 | 79.36 |
| SamSLR-V2 (R) [40] | R | 47.51 | 80.30 |
| D-ResNet (Ours) | R | 48.67 | 83.45 |
| SamSLR-V2 (S) [40] | S | 51.50 | 84.94 |
| Slgtformer [60] | S | 47.42 | 79.58 |
| TMS-Net [55] | S | 56.40 | 88.96 |
| MSGCN (Ours) | S | 54.89 | 87.35 |
| MSNN [61] | R + S + F | 47.26 | 87.21 |
| BEST [62] | R + S | 54.59 | 88.08 |
| Sign-BEST [63] | R + S | 54.69 | 87.49 |
| SamSLR-V1 [57] | R + S + D + O | 58.73 | 91.64 |
| SamSLR-V2 [40] | R + S + D + O | 59.39 | 91.48 |
| Ours | R + S | 59.05 | 91.50 |
| Skeleton Feature | AUTSL | WLASL | FPS | ||
|---|---|---|---|---|---|
| Top-1 (%) | Top-5 (%) | Top-1 (%) | Top-5 (%) | ||
| Joint | 95.64 | 99.65 | 46.04 | 78.86 | 320 |
| Bone | 96.02 | 99.60 | 46.75 | 79.45 | 322 |
| Joint Motion | 93.99 | 99.23 | 34.78 | 65.53 | 355 |
| Bone Motion | 94.63 | 99.41 | 34.90 | 66.47 | 335 |
| Multi-Stream | 96.85 | 99.84 | 54.89 | 87.35 | 160 |
| Skeleton Feature | Decoupling GCN | SJAM | SETCN | |||
|---|---|---|---|---|---|---|
| Top-1 (%) | Top-5 (%) | Top-1 (%) | Top-5 (%) | Top-1 (%) | Top-5 (%) | |
| Joint | 94.82 | 99.36 | 95.08 | 99.55 | 95.64 | 99.65 |
| Bone | 95.08 | 99.31 | 95.64 | 99.52 | 96.02 | 99.60 |
| Joint Motion | 93.08 | 98.90 | 93.59 | 99.20 | 93.99 | 99.23 |
| Bone Motion | 92.89 | 98.96 | 93.93 | 99.33 | 94.63 | 99.41 |
| Multi-Stream | 96.25 | 99.57 | 96.55 | 99.81 | 96.85 | 99.84 |
| Models | AUTSL | WLASL | FPS | ||
|---|---|---|---|---|---|
| Top-1 (%) | Top-5 (%) | Top-1 (%) | Top-5 (%) | ||
| D-ResNet | 95.83 | 99.73 | 48.67 | 83.45 | 90 |
| MSGCN | 96.85 | 99.84 | 54.89 | 87.35 | 160 |
| Multimodal | 98.13 | 100 | 59.05 | 91.50 | 70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Li, H.; Meng, W.; Dai, H.; Zhou, T.; Zheng, G. Fusion of Multimodal Spatio-Temporal Features and 3D Deformable Convolution Based on Sign Language Recognition in Sensor Networks. Sensors 2025, 25, 4378. https://doi.org/10.3390/s25144378
Zhou Q, Li H, Meng W, Dai H, Zhou T, Zheng G. Fusion of Multimodal Spatio-Temporal Features and 3D Deformable Convolution Based on Sign Language Recognition in Sensor Networks. Sensors. 2025; 25(14):4378. https://doi.org/10.3390/s25144378
Chicago/Turabian StyleZhou, Qian, Hui Li, Weizhi Meng, Hua Dai, Tianyu Zhou, and Guineng Zheng. 2025. "Fusion of Multimodal Spatio-Temporal Features and 3D Deformable Convolution Based on Sign Language Recognition in Sensor Networks" Sensors 25, no. 14: 4378. https://doi.org/10.3390/s25144378
APA StyleZhou, Q., Li, H., Meng, W., Dai, H., Zhou, T., & Zheng, G. (2025). Fusion of Multimodal Spatio-Temporal Features and 3D Deformable Convolution Based on Sign Language Recognition in Sensor Networks. Sensors, 25(14), 4378. https://doi.org/10.3390/s25144378