1. Introduction
The rapid proliferation of 3D sensing technologies—spanning LiDAR, depth cameras, and structured-light sensors—has revolutionized perception capabilities in robotics, autonomous navigation, and environmental monitoring [
1]. Central to these applications is point cloud registration, a fundamental process that aligns partial scans from disparate sensor viewpoints into a unified 3D representation [
2]. However, in real-world sensing scenarios characterized by occlusions, limited sensor field-of-view, or dynamic obstacles, overlapping regions between point clouds frequently fall below 30%. This low-overlap regime severely undermines registration robustness, inducing alignment failures that propagate errors to downstream perception tasks such as simultaneous localization and mapping (SLAM) or 3D reconstruction. Current mainstream methods typically first construct a correspondence matrix and then decompose it to solve for optimal rigid transformation parameters [
3].
Traditional methods of point cloud registration primarily employ optimization-based techniques to determine the optimal rigid transformation matrix between two point clouds [
4,
5]. As this represents a nonlinear problem, it remains highly challenging. The core methodology involves two components: robust correspondence estimation and precise transformation estimation. Correspondence estimation identifies corresponding point-pairs between source and target point clouds, while transformation estimation utilizes these correspondences to compute the rigid transformation matrix. These two stages iteratively refine the transformation until convergence. Widely adopted methods include iterative closest points (ICP) [
6] and its variants [
7,
8], which implement diverse correspondence search strategies. However, these approaches require complex heuristics to address noise, outliers, density variations, and partial overlaps, thereby increasing computational costs. Furthermore, traditional methods often rely on handcrafted feature descriptors, which limits their generalizability and makes them perform poorly in low-overlap scenarios [
9].
In recent years, deep learning has gained prominence in computer vision, and numerous learning-based point cloud registration methods have emerged [
10,
11]. These approaches demonstrate the ability to handle large rotational angles and generally outperform traditional global registration methods in speed. Unlike conventional optimization-based methods, deep learning-based registration approaches fall into two categories: feature learning-based methods and end-to-end learning-based methods.
Feature learning-based methods focus on using deep neural networks to extract discriminative features for robust correspondence estimation [
12]. Specifically, deep neural networks learn robust feature correspondences, followed by one-step transformation estimation (e.g., via RANSAC [
13]). While these methods achieve high efficiency and accuracy in high-overlap scenarios by effectively obtaining sufficient matches and stable geometric structures, they remain vulnerable to noises and outliers. Insufficient geometric modeling may also lead to computational redundancy, as global features often fail to capture fine details [
14]. In low-overlap scenarios, the limitations of global features in capturing local geometric details exacerbate structural modeling deficiencies. Additionally, the reliability of initial matches becomes particularly problematic in such cases: limited overlapping regions induce bias in global feature-based correspondences, degrading initial match quality [
15]. Meanwhile, existing feature learning-based methods of point cloud registration employ a direct outlier removal strategy, resulting in underutilization of outlier information and further compromising registration robustness.
End-to-end learning-based registration methods attempt to solve registration problems through end-to-end neural network optimization [
16]. Unlike the aforementioned feature-learning approaches, end-to-end methods embed transformation estimation into neural network optimization. In high-overlap scenarios, end-to-end methods leverage abundant correspondences for precise registration but exhibit noise sensitivity and high computational complexity due to insufficient geometric modeling. In low-overlap scenarios, such methods face multiple challenges despite attempts to enhance local features and iteratively refine pose estimation [
17]. First, while local feature enhancement aims to improve geometric modeling, the absence of explicit structural constraints leaves these methods susceptible to noise interference [
18]. Second, sparse correspondences amplify the issue of unreliable initial matches, causing iterative optimization to converge to local minima [
19]. Finally, existing end-to-end methods discard outlier pairs via hard thresholds, failing to exploit potential geometric information in correspondences and aggravating information loss in scenarios of low overlap.
In summary, robust alignment of 3D point clouds acquired by ubiquitous sensors (e.g., LiDAR, depth cameras) is paramount for enhancing perception capabilities in robotics, autonomous navigation, and environmental reconstruction. However, the inherent limitations of real-world sensing scenarios like occlusions, restricted sensor field-of-view, and dynamic obstacles frequently lead to severely low-overlap data (overlap < 30%). This low-overlap regime poses significant challenges to traditional and learning-based registration methods, primarily stemming from the following: (1) inadequate exploitation of the inherent geometric constraints imposed by rigid sensor motion on the data; (2) unreliable initial feature matching due to sparse and noisy sensor data; and (3) inefficient utilization of valuable but erroneous sensor correspondences (outliers), often discarded by conventional strategies, further exacerbating data sparsity. To overcome these critical bottlenecks for robust 3D sensing, we propose GeoCORNet, a novel deep neural network. GeoCORNet integrates synergistic innovations designed specifically to enhance the reliability of registration from low-overlap, real-world sensor data, achieving significant improvements in accuracy and robustness through geometric consistency enhancement, intelligent outlier rectification, and joint optimization.
Our main contributions are summarized as follows:
Dual-Consensus Attentive Feature Enhancer (DCA): This module improves the spatial consistency constraints in SC2-PCR [
20] by incorporating angular consistency through cosine similarity. DCA module enforces geometric constraints on matched point-pairs by jointly considering spatial distance and directional consistency, substantially improving matching robustness in complex scenes.
Bidirectional Cross-Attention for Sensor Data Fusion: Unlike unidirectional attention, our novel bidirectional mechanism enables symmetric feature interaction between source and target point clouds (representing distinct sensor viewpoints). This mutual attention dynamically focuses on salient overlapping regions critical for alignment while actively suppressing interference from non-overlapping or noisy sensor data, thereby providing a significantly more reliable set of initial correspondences for downstream optimization.
Predictive Outlier Correction: Departing fundamentally from the prevalent paradigm of outlier removal, we propose a novel displacement prediction-based correction strategy. Recognizing the value of potentially informative but misaligned sensor measurements in low-overlap scenarios, we employ a lightweight MLP to predict 3D displacement offsets for both points in outlier pairs. This intelligent rectification transforms erroneous correspondences into geometrically plausible ones, maximizing the utility of sparse sensor data and enabling more accurate global transformation estimation, leading to more efficient and precise registration.
Displacement Loss Function: To ensure the corrected correspondences conform to the expected geometric structure of the sensor data, we design a novel displacement loss function. This loss explicitly constrains the geometric distribution of the rectified outlier point-pairs to align with that of the inliers, guaranteeing the effectiveness of the predictive correction process and enhancing overall registration robustness.
Experimental results on the public dataset 3DMatch and the low-overlap dataset 3DLoMatch demonstrate that our method effectively addresses the registration of low-overlap point cloud, confirming its effectiveness and generalizability. The proposed approach surpasses existing methods in registration recall rate, rotation error, and algorithmic robustness.
2. Related Works
2.1. Feature Learning-Based Point Cloud Registration
Feature learning-based point cloud registration methods leverage deep learning techniques to extract point cloud feature representations and establish correspondences, achieving efficient and robust registration.
In general scenarios, PointNet [
21] laid the foundation for subsequent research by extracting global features via shared MLPs and symmetric functions. However, its inability to capture local geometric features limited its performance on complex structures. Subsequently, PointNet++ [
22] extended this framework through hierarchical feature learning and local region sampling, significantly enhancing local geometric feature extraction. While this improved feature representations for registration, it remained constrained in low-overlap and rotation-variant scenarios. RIGA [
12] achieved efficient registration via local geometric feature extraction and global optimization but exhibited sensitivity to noise and partial overlaps, heavily relying on initial match quality. D3Feat [
23] and FCGF [
24] advanced point cloud feature extraction through joint keypoint detection as well as feature learning and sparse convolutions, respectively. D3Feat improved registration accuracy by co-learning keypoints and descriptors, while FCGF enhanced efficiency via dense feature extraction. SpinNet [
25] introduced rotation-equivariant convolutions to address rotational sensitivity, further boosting feature matching robustness. In low-overlap scenarios, Predator [
26] dynamically filtered overlapping regions with attention mechanism but struggled with symmetric structures and feature discriminability. GeoTransformer [
14] combined Transformer-based global modeling with geometric invariance for rigid transformation invariance, albeit with high memory costs for large-scale point clouds.
Our method inherits the core concept of geometric-invariant feature learning but uniquely integrates angular consistency to construct dual-dimensional geometric constraints, substantially mitigating mismatches caused by symmetric structures or repetitive local features.
2.2. End-to-End Learning-Based Point Cloud Registration
End-to-end learning-based methods jointly optimize feature extraction and correspondence estimation, and they pose refinement within a unified deep learning framework, reducing manual intervention while improving overall accuracy and robustness.
In general scenarios, PointNetLK [
16] combined PointNet [
21] with the Lucas–Kanade algorithm [
27] for end-to-end pose regression but suffered from sensitivity to initial poses and frequent failures in low-overlap cases. Based on this, Deep Closest Point (DCP) [
17] implicitly learned feature correspondences via deep networks and solved transformations with SVD, though its performance degraded in low-overlap settings due to dependency on accurate feature matching. 3DRegNet [
28] bypassed initial pose requirements by directly regressing transformation matrices but showed limited robustness in low-overlap scenarios. For partial overlaps, RPM-Net [
18] enhanced robustness with differentiable soft correspondence matching and iterative refinement, while DGR [
29] achieved outperformance via a differentiable global registration framework integrating 6D convolutional networks and weighted Procrustes optimization. HRegNet [
30] adopted a hierarchical coarse-to-fine strategy for complex and low-overlap scenarios but struggled with noise and outliers. OMNet [
19] learned overlap masks to filter non-overlapping points but faced generalization limitations due to training data biases. Despite efficiency on benchmarks like 3DMatch and KITTI, these methods still grappled with extreme low-overlap (<10%) adaptability, high computational costs for large-scale data, noise sensitivity, and initial pose dependency.
Unlike black-box regression in existing end-to-end approaches, our method explicitly models geometric constraints, achieving superior robustness in low-overlap, noisy, and initial pose-deviated scenarios.
2.3. Outlier Rejection for Point Cloud Registration
Due to the challenges such as partial overlaps or feature ambiguity, correspondence estimation tends to generate outliers. Thus, outlier rejection becomes particularly critical when the overlapping regions are sparse.
PointDSC [
31] introduced a spatial consistency score to filter outliers, significantly improving low-overlap robustness. SC2-PCR [
20] introduced a hierarchical matching strategy to further enhance registration accuracy. The method proposed a two-stage registration framework based on superpoint matching. During the coarse registration phase, superpoint matching reduced the impact of outliers; while in the fine registration phase, correspondences were further optimized. This coarse-to-fine strategy progressively refined the registration results. QGORE [
32] proposed a quadratic-time outlier rejection technique to enhance performance. PointTr [
33] leveraged Transformer-based global–local feature interaction to suppress outliers, and 3DPCP-Net [
34] incorporated normal vector consistency and progressive guidance for reliable correspondence selection. These methods share a common strategy: filtering initial matches via spatial or normal consistency or deep features to remove outliers. However, direct outlier removal risks discarding valuable information, particularly in low-overlap scenarios where correspondences are already scarce.
Different from conventional outlier rejection, our method proposes a displacement prediction-based correction strategy. We first filter obvious outliers and then rectify remaining ones via displacement prediction, balancing information retention and computational efficiency for low-overlap, large-scale registration.
3. Methods
Given a source point cloud and a target point cloud , where and denote the number of points in and , respectively, GeoCORNet aims to predict the optimal rotation matrix and translation vector from to in low-overlap scenarios.
As illustrated in
Figure 1, for the given source point cloud
and target point cloud
, the framework first extracts highly robust fused features
and
, integrating spatial geometric and cross-cloud contextual information via the DCA module. The Mutual-Confidence Correspondence Seeding (MCCS) module then picks out the top-k initial correspondences to construct a seed correspondence set
{(
)
}, which exhibit relatively reliable matches despite still existing potential outliers. Each seed correspondence point-pair in
is represented as (
)
, where
.
Assuming that a coarse transformation derived from approximately aligns and , the Predictive Displacement Rectification (PDR) module further refines the positional offsets of outlier point-pairs in , yielding an optimized correspondence set {() k}, where and denote the rectified coordinates. Finally, the optimal rigid transformation is computed via Singular Value Decomposition (SVD) based on , recovering the best 3D registration between and .
3.1. Problem Definition
Given a source point cloud
and a target point cloud
, the goal of point cloud registration is to align the two point clouds via an unknown optimal 3D rigid transformation
, comprising a rotation matrix
and a translation vector
. This transformation matrix can be obtained by minimizing the geometric error between the matched point pairs, as formalized in Equation (1):
where
denotes the set of ground-truth correspondences between
and
,
;
represents the number of points; and
refers to the squared Euclidean norm (L2 norm).
3.2. DCA Module (Dual-Consensus Attentive Feature Enhancer Module)
The Dual-Consensus Attentive Feature Enhancer (DCA) serves as the cornerstone of GeoCORNet for extracting robust and geometrically consistent features from low-overlap sensor point clouds. It directly addresses the challenges of noise, outliers, and sparse correspondences by synergistically enforcing dual geometric consistency constraints (distance and angular) and facilitating bidirectional contextual interaction between the source and target point clouds (representing distinct sensor viewpoints). The output features and exhibit enhanced discriminative power within overlapping regions and suppressed responses elsewhere, providing a reliable foundation for subsequent correspondence estimation.
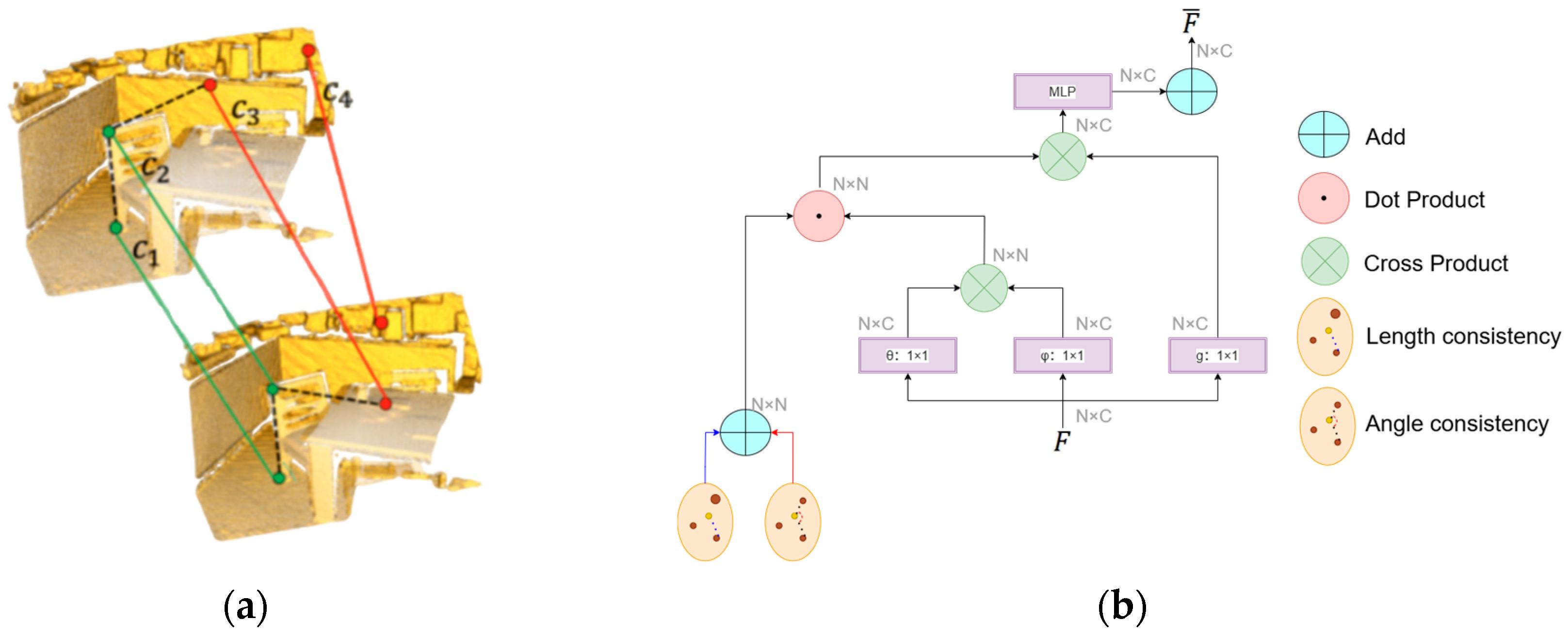
3.2.1. Self-Attention Augmented Spatial Consistency
First, three multilayer perceptrons (MLPs) are employed to extract initial features and from and , respectively. These features are then enhanced with spatial consistency through dual local geometric constraints, including length consistency and angular consistency, yielding refined features and .
Specifically, length consistency is applied to enforce invariance of Euclidean distances between matched point pairs under rigid transformations, as formalized in Equation (2):
where
denotes two points in the overlapping region of the source point cloud
, and
represents their corresponding points in
. However, relying solely on distance constraints can overlook directional information. For instance, under anisotropic deformation or noise, point pairs with similar distances but divergent orientations might yield incorrect correspondences. As illustrated in
Figure 2a, considering a neighborhood centered at
while the outlier
shares the same distance to
as the true match
, their angular relationship (e.g.,
) fails to remain consistent after transformation.
To solve ambiguities arising from distance-only constraints and enhance robustness to sensor noise and local deformations, we introduced spatial directional consistency constraints, proposing angular consistency to resolve false correspondences with similar length distances. This is achieved by computing the cosine similarity between feature vectors of point pairs, as formulated in Equation (3):
where
represents the
i-th and
j-th points’ initial features of two points from
or
. As demonstrated in
Figure 2b, the fusion of length and angular consistency yields spatially enhanced features
and
, effectively eliminating directionally inconsistent spurious matches and overcoming the limitations of relying solely on distance constraints.
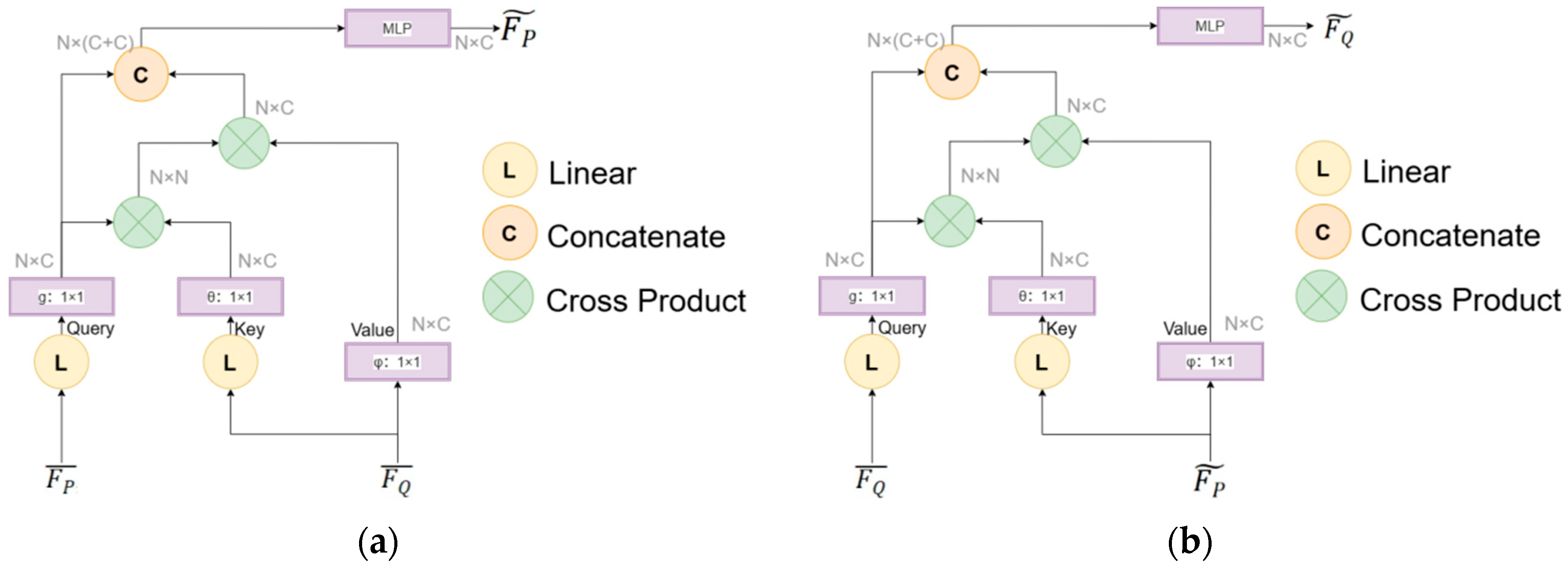
3.2.2. Bidirectional Cross-Attention Mechanism
A bidirectional cross-attention mechanism is introduced to establish global feature correlations between
and
, dynamically capturing potential correspondences in low-overlap scenarios, as illustrated in
Figure 3. This mechanism enables symmetric feature interaction between the two point clouds, mimicking the process of correlating information from multiple sensor acquisitions.
Specifically, we first computed cross-attention from
to
. As shown in
Figure 3a, the spatially enhanced feature matrix
is treated as Query, while
serves as Key and Value. The attention weights are calculated using Equation (4):
where
denoted the dimensionality of
. Based on the computed cross-cloud attention weights,
was aggregated via weighted summation as formulated in Equation (5):
Subsequently, cross-attention from
to
is computed to refine feature representations bidirectionally. As illustrated in
Figure 3b,
acts as Query, while
functions as Key and Value. The attention weights are derived via Equation (6):
where
represented the dimensionality of
. Using these weights,
was updated through aggregation, as shown in Equation (7):
This bidirectional cross-attention mechanism generates weighted aggregated features
and
, which fuses cross-cloud contextual information. The process enables adaptive focusing on overlapping regions while suppressing noise interference in non-overlapping areas.
3.3. Mutual-Confidence Correspondence Seeding (MCCS)
The MCCS module generates an initial correspondence set
by picking out top-k matched point-pairs as seed correspondences based on feature similarity, which serves as the confidence criterion. First, the feature similarity matrix
between
and
is computed. Each element
, representing the confidence score of the point pair
, is defined by Equation (8):
where
and
denoted the weighted aggregated features of points
and
, respectively.
To enhance reliability, a bidirectional nearest neighbor constraint was applied: only matches where and were mutually top-k nearest neighbors were retained. Specifically, had to satisfy that was ranked among the top-k nearest neighbors of in and simultaneously was ranked among the top-k nearest neighbors of in . The bidirectional nearest neighbor constraint reduced the initial number of matches from to () by screening high-confidence matching point pairs, significantly reducing the computational load of displacement prediction in the PDR module.
3.4. Predictive Displacement Rectification Module (PDR Module)
The network architecture of our PDR module is illustrated in
Figure 4. For the initial seed correspondence set
selected by the MCCS module, displacement vectors are computed to rectify erroneous matches, yielding the refined correspondence set
, where each rectified pair
comprises the corrected 3D coordinates of the source and target points.
Specifically, the module takes the selected initial seed correspondence set
as input and utilizes a lightweight displacement prediction network (composed of multilayer perceptrons, MLPs) to estimate 3D displacement vectors
and
for each correspondence pair (
), as formulated in Equations (9) and (10):
where
denoted the neighborhood of point
, containing
neighboring points. The predicted displacements are then applied to rectify the positions of the potentially erroneous sensor data points via Equations (11) and (12):
yielding geometrically coherent corrected correspondence set
.
Residual connections, similar to ResNet blocks, are incorporated into the MLP to serve as the backbone for fine registration. Experiments shows that this design facilitates gradient propagation and improves training performance. The final regression layer is configured with 3 output channels to match the expected displacement dimensions. Outlier correspondences are corrected based on the predicted displacement vectors. The PDR module does not just filter sensor data but actively corrects and enhances its geometric plausibility, thereby enabling more robust and accurate registration crucial for reliable 3D sensing. The subsequent displacement loss function (
Section 3.5.2) further ensures these corrected pairs conform to the expected distribution of inliers.
3.5. Loss Function
Our proposed network can achieve high accuracy and robustness in low-overlap point cloud registration through the joint optimization of Overlap Loss and Displacement Loss.
3.5.1. Overlap Loss
The Overlap Loss is designed to constrain the model to accurately predict overlapping regions between point clouds, providing reliable priors for correspondence filtering. To address class imbalance in low-overlap scenarios, a Weighted Binary Cross-Entropy (BCE) Loss is employed, as formulated in Equation (13):
where
denoted a binary overlap mask generated based on the ground-truth transformation
and
, defined in Equation (14):
with
representing the overlap threshold.
3.5.2. Displacement Loss
To ensure the accuracy of the predicted displacement vectors and enforce corrected outliers to align with inlier distributions, a displacement loss function
is designed, as formalized in Equation (15):
where
denoted the rectified correspondence pair, and
represented the nearest inlier pair for each
. By minimizing this loss, the displacement vectors of outlier pairs were constrained to match the geometric distribution of inliers, ensuring robust correction.
Physically, minimizes the geometric deviation between rectified correspondences and their nearest inliers . By pulling corrected outliers toward the inlier manifold, it enforces distributional alignment where sparse inliers define the valid transformation space. This contrasts with hard outlier rejection, which discards valuable geometric constraints.
3.5.3. Total Loss
The total training loss is formulated as the weighted sum of the Overlap Loss and Displacement Loss, as defined in Equation (16):
where the weighting coefficients were set to
and
.
4. Results
In this section, comparative experiments were conducted between our network and other mainstream methods.
Section 4.1 describes the experimental setup, including dataset selection, evaluation metrics, and implementation details.
Section 4.2 depicts the comparative results of the registration performance for GeoCORNet and other methods on the benchmarks of 3DMatch and 3DLoMatch.
Section 4.3 focuses on an ablation study to analyze the contributions of individual modules in GeoCORNet, while
Section 4.4 investigates the impact of varying b values in PDR module.
Section 4.5 quantifies computational efficiency and parameter complexity.
The proposed method was compared against five existing point cloud registration approaches: ICP [
7], RANSAC [
13], Predator [
26], PointDSC [
31], SC2-PCR [
20], and PointTr [
33]. Among these, ICP represent traditional registration methods, whereas Predator, PointDSC, SC2-PCR, and PointTr are learning-based approaches widely adopted in recent research.
4.1. Experiment Settings
4.1.1. Datasets
Experiments were conducted on the benchmark datasets (3DMatch and 3DLoMatch) to evaluate the performance of GeoCORNet. 3DMatch includes 62 scenes captured from diverse sensors and complex layouts. Following standard protocols, 46 scenes were used for training, 8 for validation, and 8 for testing. The test set comprises 1623 partially overlapping point cloud fragments with their corresponding ground-truth transformation matrices. To specifically evaluate low-overlap scenarios, 3DLoMatch was constructed by picking out point-pairs from 3DMatch with overlap ratios below 30%, which served as a challenging benchmark for extreme low-overlap registration tasks.
4.1.2. Evaluation Criteria
Three metrics were adopted to evaluate registration performance: Registration Recall (RR), Rotation Error (RE), and Translation Error (TE).
The recall rate is calculated as follows:
where RMSE(·) denotes the root mean square error;
T(·) is the ground-truth rigid transformation;
,
; and
k represents the number of filtered correspondences.
- 2.
Rotation Error (RE)
The angular deviation between predicted and ground-truth rotations is computed as follows:
- 3.
Translation Error (TE)
The Euclidean distance between predicted and ground-truth translations is defined as follows:
Thresholds for rotation and translation errors across datasets are listed in
Table 1.
4.1.3. Implementation Details
In the preprocessing stage, input point clouds were voxelized with a voxel size of 0.05 m. From 3DMatch, 14,732 points were randomly sampled per point cloud, followed by voxel downsampling. GeoCORNet was implemented using PyTorch 1.7.1, and the Adam optimizer was employed for training. The initial learning rate was set to 0.001, decayed by 50% every 10 epochs, with a batch size of 32 and 300 training epochs on 3DMatch. For hyperparameters, the feature dimensionality was set to 128, and the parameter k in
Section 3.3 was configured to 500. During training, the feature extraction module was pretrained first, followed by end-to-end training of the entire network using the pretrained features. Experiments were conducted on an Ubuntu 20.04 system with 32 GB of RAM and an NVIDIA RTX 3090 GPU (Nvidia, Santa Clara, CA, USA).
4.2. Evaluation on Indoor Scenes (3DMatch and 3DLoMatch)
To validate the performance of our method, comparative experiments were conducted against other mainstream point cloud registration approaches on large-scale benchmark datasets.
The quantitative comparison results of registration performance on both 3DMatch and 3DLoMatch for different methods are summarized in
Table 2. As shown in the table, traditional methods (ICP) exhibited significant performance degradation in low-overlap scenarios, indicating their sensitivity to initial positions and inability to handle sparse correspondences, which highlighted their limitations under low-overlap conditions. On both 3DMatch and 3DLoMatch, the proposed GeoCORNet outperformed existing methods in the core registration metric, Registration Recall (RR), especially on 3DLoMatch, achieving 80.8% RR. On 3DLoMatch, although SC2-PCR slightly surpassed GeoCORNet in Translation Error (TE: 6.48 cm vs. 6.92 cm) on 3DLoMatch, our method achieved an 11.3% higher RR (80.8% vs. 69.5%) and a 23.8% lower Rotation Error (RE) (2.34° vs. 3.07°) compared to SC2-PCR, highlighting its robustness in low-overlap matching. While PointTr demonstrated marginally better RE and TE on 3DMatch (1.47°, 4.59 cm), its RR on 3DLoMatch (75.6%) was substantially lower than GeoCORNet (80.8%). This demonstrates that GeoCORNet can adapt to challenging scenarios (e.g., dynamic occlusions, low overlap) and provides more reliable solutions for practical applications.
Additionally, the robustness of registration method is validated by calculating the percentage of the differences in Registration Recall (RR), Rotation Error (RE), and Translation Error (TE) between the general-overlap scenarios (3DMatch) and low-overlap scenarios (3DLoMatch). The percentage of the differences are computed using Equation (20), where
,
, and
represent the Registration Recall, average Rotation Error, and average Translation Error on 3DMatch, respectively, while
,
, and
denote the corresponding metrics on 3DLoMatch.
The difference percentage results were presented in
Table 3. As shown in the table, traditional methods (ICP) exhibited severe performance degradation in low-overlap scenarios, with RR decreases exceeding 60% and transformation errors nearly doubling, validating the limitations of traditional methods under low-overlap conditions. Among learning-based methods, although SC2-PCR slightly outperformed our method in translation error stability (TE↑ = 6.1% vs. 10.9%), its RR degradation (RR↓ = 25.3%) and rotation error increase (RE↑ = 50.5%) were 63.2% and 219.6% greatly higher than GeoCORNet (RR↓ = 15.5%, RE↑ = 15.8%), respectively, indicating significant degradation in registration success rate and rotational accuracy for SC2-PCR in low-overlap scenarios. While PointTr achieved better rotation and translation errors on 3DMatch (RE = 1.47°, TE = 4.59 cm), its RR↓, RE↑, and TE↑ (20.0%, 91.8%, and 23.9%) far exceeded GeoCORNet (15.5%, 15.8%, and 10.9%), particularly in rotation error degradation, revealing PointTr’s instability.
In contrast, the proposed GeoCORNet achieved the best performance in cross-dataset robustness metrics, with the smallest RR degradation (RR↓ = 15.5%) and rotation error increase (RE↑ = 15.8%), outperforming all existing methods. This validated the strong adaptability of our algorithm to scene variations. The results demonstrate that GeoCORNet possesses more reliable registration generalization capabilities and superior robustness.
The visualization results are illustrated in
Figure 5 and
Figure 6, where the source point cloud is colored in yellow and the target point cloud in blue.
Figure 5 shows the comparative registration results of traditional method (ICP) and five learning-based methods on 3DMatch. Our method achieved exceptional alignment accuracy, closely matching the ground truth (GT). It captured fine geometric details more precisely, with tighter edge alignment, whereas ICP, Predator, PointDSC, SC2-PCR, and PointTr exhibited local misalignment.
Figure 6 demonstrates the comparative registration results of traditional method (ICP) and five learning-based methods on 3DLoMatch. The registration results of GeoCORNet (ours) were the closest to GT. In the overlapping upper regions of the two point clouds, planar surfaces aligned almost perfectly by using our method, while other approaches introduced angular errors. These visual comparisons highlighted the superiority of our method in handling both standard and low-overlap scenarios.
4.3. Ablation Studies and Analysis
To investigate the importance of individual modules, an ablation study was conducted on 3DLoMatch. Specifically, the Baseline employed only a basic MLP architecture without any specialized modules. Subsequently, the DCA module, MCCS module, and PDR module were sequentially added to the Baseline. All experiments were performed under identical training strategies and hyperparameters to eliminate interference from other factors.
As shown in
Table 4, the baseline model was highly sensitive to noise and outliers, resulting in a high mismatch rate. After incorporating the DCA module, geometric consistency in features was enhanced, enabling the attention of our network to be dynamically focused on overlapping regions. The DCA module accounted for approximately 54% of the total performance improvement, serving as the core driver. The MCCS module preliminarily filtered obvious outliers, reducing computational burden for subsequent modules; its contribution was relatively minor. The PDR module optimized correspondence positions, exhibiting high adaptability to occlusions and partial overlaps, and contributed 34% to the total improvement. Overall, our phased module design ensured controlled error propagation, ultimately achieving 80.8% RR on 3DLoMatch, a 42.1% improvement over the baseline.
Notably, the time cost progressively increases from 0.041 s (Baseline) to 0.130 s (Full) as modules are added, reflecting their computational demands: the DCA module dominates with 50% time share due to its O(N2) attention operations, while the MCCS and PDR modules contribute 15% and 19%, respectively. This demonstrates a favorable accuracy–efficiency trade-off, where the 3.7× time increase yields a 109% relative RR improvement.
4.4. b Value in Predictive Displacement Rectification and Analysis
In the PDR module, the parameter b denotes the number of local neighborhood points referenced during displacement prediction, which captures local geometric structures to optimize the accuracy of displacement estimation. Experiments were conducted on 3DLoMatch to evaluate the impact of b-values (5, 10, 20, or 30) based on Registration Recall (RR) and the mean positional error (TE). Parameters for the DCA module and MCCS module were kept consistent, with only the b-value in the PDR module adjusted. The following sections present the experimental results and analysis of how different b-values influence correction effectiveness.
As shown in
Table 5, the optimal performance was achieved at b = 10, with RR = 80.8% and TE = 6.9 cm, balancing local geometric information and noise suppression. For b = 5, excessively small neighborhoods led to insufficient local geometric modeling (e.g., failure to capture surface continuity), increasing TE to 7.8 cm. For b = 20 and b = 30, overly large neighborhoods introduced noise from irrelevant regions (e.g., interference from distant points), degrading RR. Furthermore, when b-values were too large (e.g., 30), the likelihood of noise points participating in displacement prediction increased, leading to higher correction errors. Selecting an appropriate b-value (e.g., 10) could effectively filter isolated noise points while preserving local structural features.
In summary, smaller neighborhoods (b = 5) fail to capture surface continuity (e.g., planar regions), leading to unstable displacement predictions. Conversely, larger neighborhoods (b = 20/30) introduce irrelevant points from non-overlapping areas, increasing sensitivity to outliers. The value b = 10 empirically ensures sufficient local structural context while excluding distant noise points.
4.5. Complexity Analysis
To comprehensively evaluate practical applicability, which is critical for resource-constrained real-time applications, computational efficiency and model complexity are compared. The results measured on standardized hardware (Ubuntu 20.04 system with 32 GB of RAM and NVIDIA RTX 3090 GPU) are reported in
Table 6.
As shown in
Table 6, the proposed method achieved a better balance between computational efficiency and model complexity. GeoCORNet required only 0.13 s, which was significantly lower than the models with comparable parameter counts such as Predator (0.54 s) and PointTr (0.22 s). Although PointDSC (0.09 s) and SC2-PCR (0.09 s) exhibited faster inference speeds, their registration recall (RR) values were notably lower than that of GeoCORNet.
In summary, GeoCORNet achieves an optimal trade-off among computational efficiency (0.13 s), model complexity (3.8 M parameters), and registration accuracy (RR = 95.6%) through its parameter-shared lightweight design and joint optimization strategy.
4.6. Validation Under Extreme Low-Overlap Conditions
To address the critical challenge of point cloud registration under extremely sparse overlaps (e.g., in scenarios with severe occlusions or narrow sensor field-of-view), we conducted additional experiments on the 3DMatch dataset with overlap ratios below 10%. These test pairs were subsampled from the original 3DMatch test set by retaining only fragment pairs with overlap ratios strictly less than 10%.
As shown in
Table 7, GeoCORNet achieves a Registration Recall (RR) of 62.3%, with an average Rotation Error (RE) of 5.62° and Translation Error (TE) of 11.83 cm. Compared to the 30% overlap scenario (80.8% RR, 2.34° RE, 6.92 cm TE), the performance degradation at 10% overlap is primarily attributed to the extreme sparsity of reliable correspondences, which compromises the effectiveness of both the DCA module and the PDR displacement rectification. Specifically, the scarcity of initial seed correspondences in the MCCS module (less than 20 pairs in some cases) reduces the geometric constraints available for transformation estimation, leading to higher sensitivity to noise and outliers.
5. Discussions and Limitations
As shown in
Table 2 and
Table 3, GeoCORNet achieved significant performance improvements in low-overlap point cloud registration. Specifically, the DCA module enhanced feature matching robustness in low-overlap scenarios by integrating distance consistency and angular consistency to establish dual-dimensional spatial geometric constraints. As illustrated in
Figure 2a, traditional methods (e.g., ICP), which relied solely on Euclidean distance, struggled to distinguish false matches caused by local anisotropic noises. While existing deep learning methods introduced geometric self-attention, they failed to explicitly model spatial orientation. In contrast, as illustrated in
Figure 2a, the DCA module suppressed erroneous matches with similar distances but inconsistent spatial orientations by fusing neighborhood angular relationships via cosine similarity. Additionally, the bidirectional cross-attention mechanism made our network dynamically focus on overlapping regions through symmetric feature interaction, providing more reliable initial correspondences. Consequently, the DCA module improved geometric consistency and initial matching reliability, as shown in
Table 3 and
Table 4, contributing 54% of the total performance gain. On 3DLoMatch, it boosted an RR by 22.5% compared to distance-only baselines.
Existing methods remove outliers via hard thresholds, which, while reducing noise interference, exacerbate information sparsity in low-overlap scenarios. The proposed correction strategy predicts displacement offsets using a lightweight MLP to rectify the outliers to the true distribution instead of discarding them. As shown in
Table 2,
Table 4 and
Table 5, this module contributed 34% of the total performance improvement on 3DLoMatch, achieving a 4.11 cm reduction in TE compared to SC2-PCR. This result validated the dual advantages of our correction strategy: by retaining potentially useful information, it alleviated the insufficient correspondence problem caused by excessive outlier removal, while local neighborhood modeling enabled displacement prediction to capture geometric features such as surface continuity, avoiding interference from isolated noises. Through explicit geometric optimization, GeoCORNet achieved superior performance in Rotation Error (RE) metrics.
Traditional loss functions (e.g., mean squared error) struggle to address class imbalance in low-overlap scenarios. The proposed total loss function jointly optimizes overlap loss and displacement loss: the former enhances overlap region prediction through weighted cross-entropy, while the latter constrains the distribution of corrected point-pairs via geometric distance constraints. Data from
Table 3 and
Table 4 demonstrated that our design enables GeoCORNet to achieve a Registration Recall (RR) of 95.6% on 3DMatch, significantly surpassing baseline models relying on a single loss function. Compared to existing methods, the displacement loss explicitly strengthens spatial geometric consistency by minimizing the distance between corrected points and their nearest inliers, thereby achieving higher robustness in low-overlap scenarios.
Despite GeoCORNet’s strong performance in low-overlap registration, it still has limitations. In extreme low-overlap scenarios (e.g., overlap ratio < 10%), the extreme sparsity of matched point pairs may compromise the reliability of the displacement correction module. In such regimes, the sparsity of initial correspondences reduces the reliability of displacement rectification. As shown in
Table 7, we tested on 3DMatches data with 10% overlap, observing an RR drop to 68.3% (vs. 80.8% at 30%). Future work will explore adaptive neighborhood selection and uncertainty-aware rectification to address this limitation.
Additionally, as shown in
Table 5, the choice of neighborhood size b significantly impacts the effectiveness of displacement correction. Although experiments demonstrated optimal performance at b = 10, manual adjustment remains necessary across different scenarios, and future work needs to explore adaptive mechanisms for predicting b-values dynamically.
6. Conclusions
This paper presented GeoCORNet, a novel deep learning framework specifically designed to address the critical challenge of robust 3D point cloud registration under severe low-overlap conditions, a common limitation faced by LiDAR, depth cameras, and other 3D sensors in real-world applications like robotics and autonomous navigation.
GeoCORNet integrates key innovations for robust sensor data processing: the Dual-Consensus Attentive Feature Enhancer (DCA) enforces geometric consistency and employs cross-attention for reliable feature matching in overlapping regions. Crucially, the Predictive Displacement Rectification (PDR) module introduces a paradigm shift, moving beyond traditional outlier rejection to predictive correction of erroneous sensor correspondences. This maximizes the utility of sparse sensor data, transforming outliers into valuable inliers. Joint loss optimization further ensures geometric coherence.
Comprehensive evaluation on the 3DMatch and challenging 3DLoMatch sensor datasets demonstrated GeoCORNet’s superior performance. It achieved outstanding results, notably 80.8% Registration Recall (RR) and 2.34° Rotation Error (RE) on 3DLoMatch, showcasing exceptional robustness under low-overlap conditions.
These advances establish GeoCORNet as a powerful solution for enhancing the reliability and accuracy of 3D sensing systems. This work paves the way for more robust perception using ubiquitous sensors in complex, occlusion-prone environments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}