
LiGenCam: Reconstruction of Color Camera Images from Multimodal LiDAR Data for Autonomous Driving

Abstract
Highlights
- Color camera images can be realistically and semantically reconstructed from multimodal LiDAR data using a GAN-based model.
- The fusion of multiple LiDAR modalities enhances reconstruction quality, and the incorporation of a segmentation-based loss further improves the reconstruction fidelity.
- LiDAR can serve as a backup to cameras by reconstructing semantically meaningful visual information, enhancing system redundancy and safety in autonomous driving.
- LiGenCam has the potential to perform data augmentation by generating virtual camera viewpoints using panoramic LiDAR data.
Abstract
1. Introduction
2. Related Works
2.1. Non-GAN-Based Approaches
2.2. GAN-Based Approaches
2.3. Research Gaps
2.4. Relation to 3D Reconstruction Methods
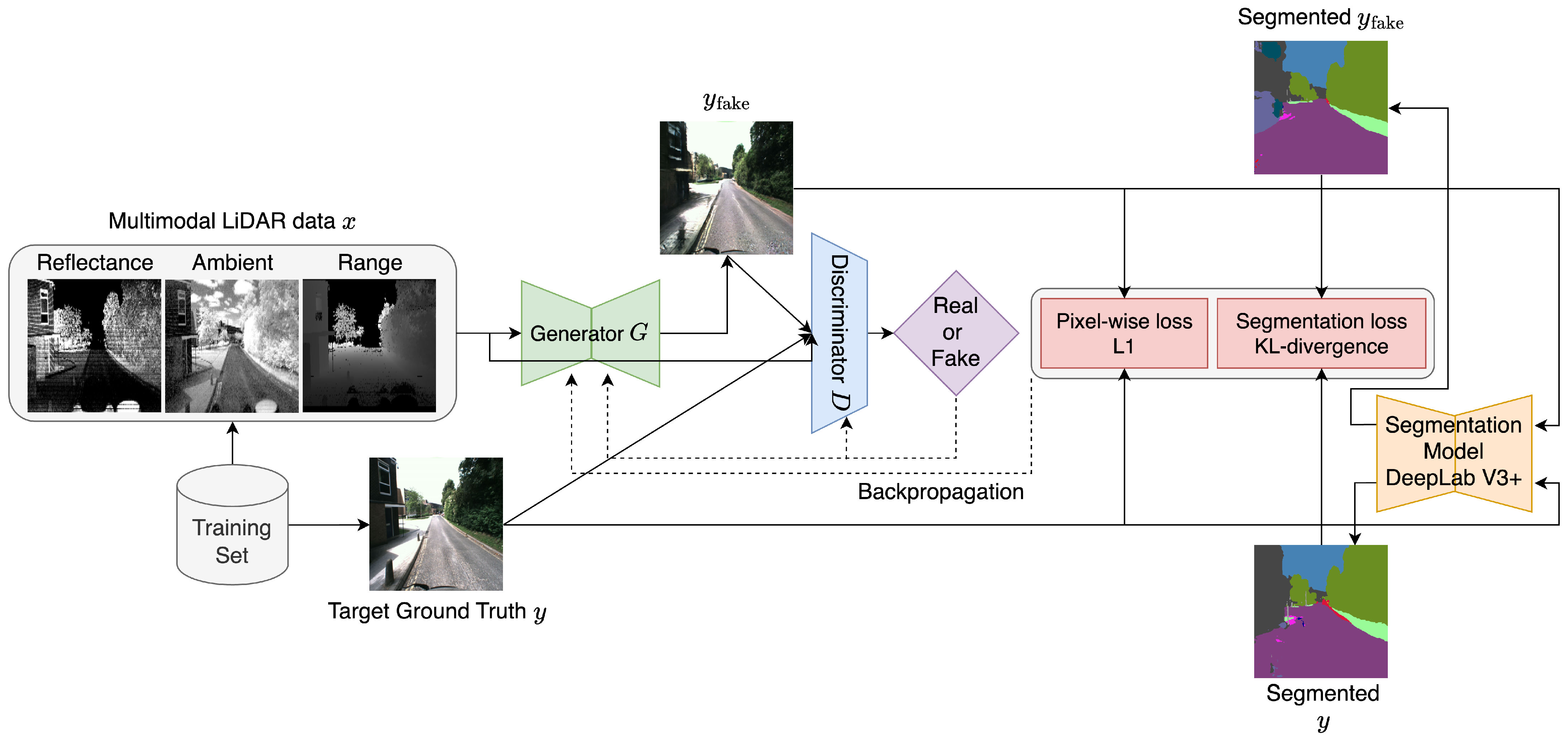
3. Approach
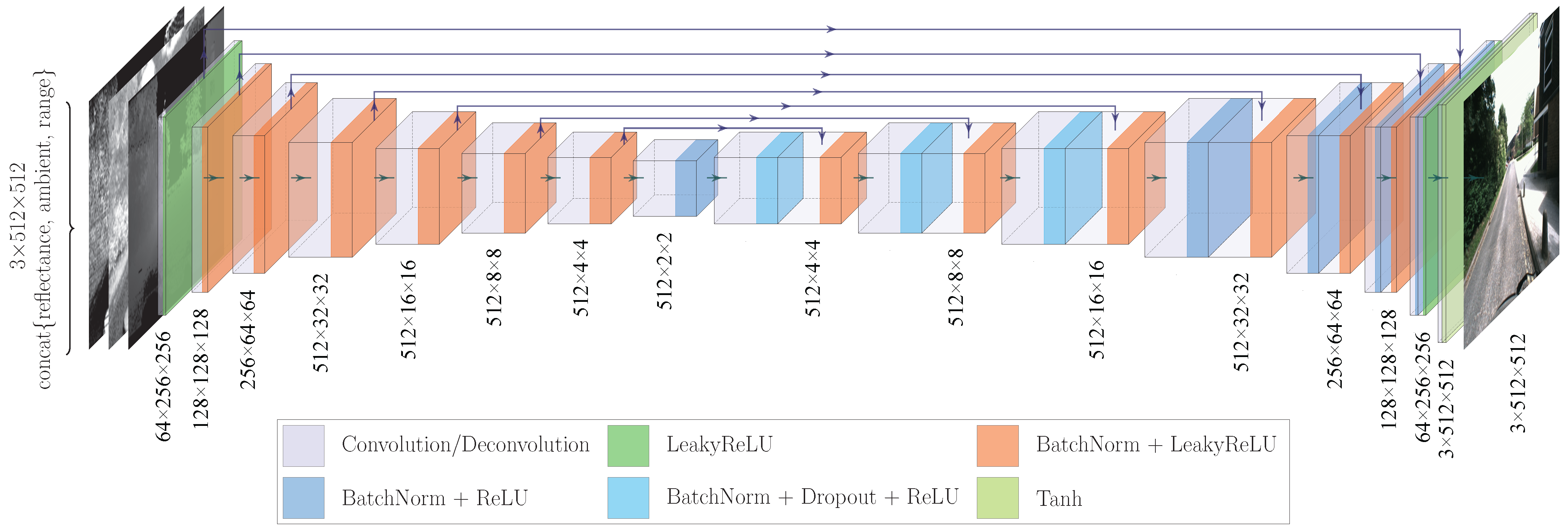
3.1. Model Architectures
3.1.1. Generator Loss Function
3.1.2. Discriminator Loss Function
3.1.3. U-Net as Generator
3.1.4. PatchGAN as Discriminator
3.2. Model Objectives
3.2.1. L1 Loss
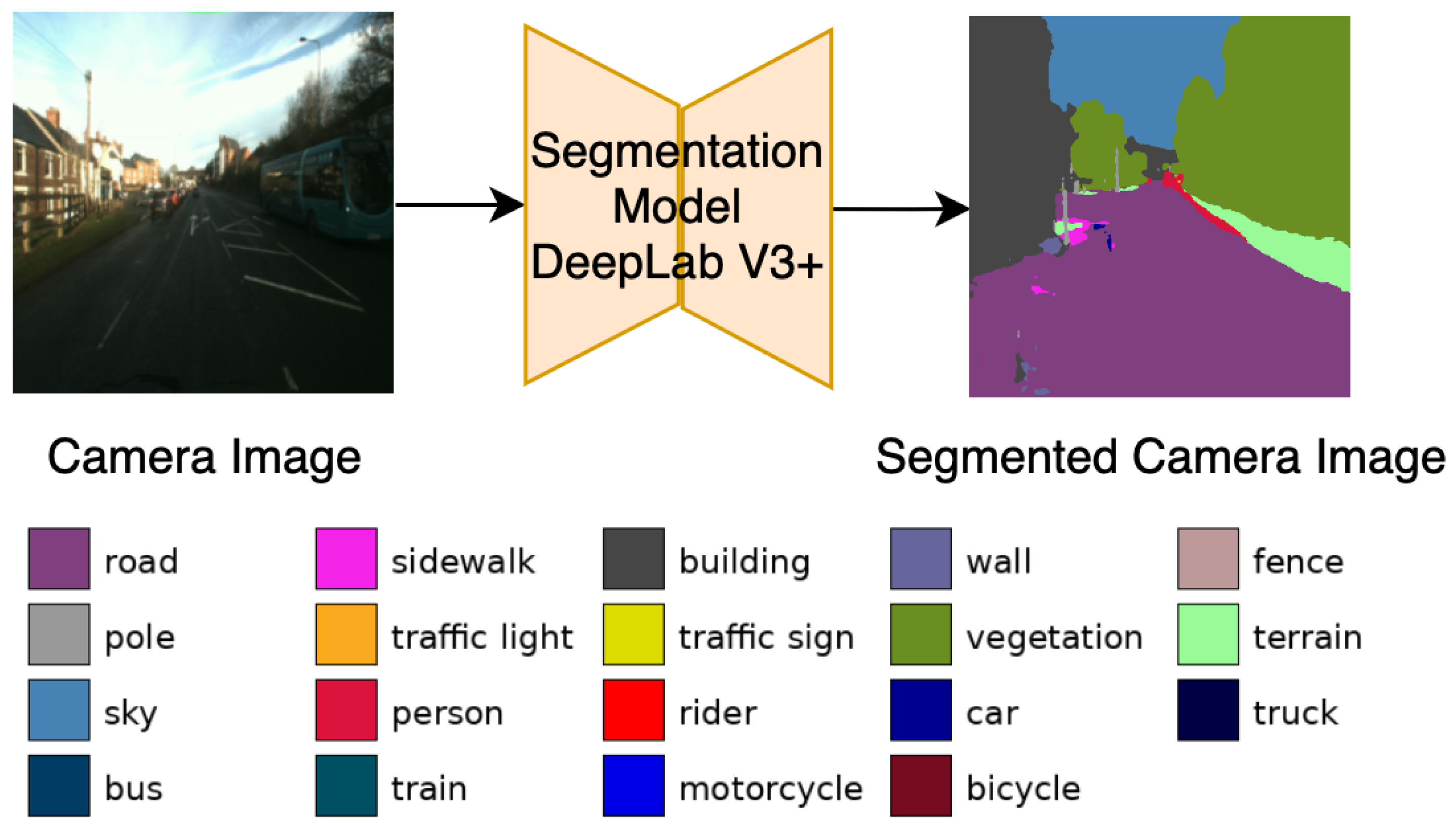
3.2.2. KL-Divergence Loss
3.2.3. Final Objectives
4. Experiments
4.1. Selection of the Multimodal Dataset DurLAR
- Point Clouds: Offering 3D spatial information about the surroundings, this modality captures the environment’s structure with high precision. The point cloud format is KITTI-compatible, in , where x, y, and z represent coordinates and r denotes reflectance strength.
- Reflectance Panoramic Image: This modality is crucial for understanding the interaction of light with various materials in a scene. It provides detailed information about the reflectance properties of objects. (see Figure 5).
- Ambient Panoramic Image: Operating in the near-infrared spectrum, this modality adeptly captures environmental nuances under diverse lighting conditions, excelling particularly in low-light scenarios. (see Figure 6).
- Camera Image: Captured in the visible spectrum, this modality offers a conventional, human-eye-like perspective of the environment. (see Figure 7).
- GNSS/INS: While this data provides precise geo-referencing and motion tracking, its primary utility is in navigation and positioning tasks. It is less directly applicable to our focus on image reconstruction.




4.2. Selection of Modalities and Fusion Techniques
4.3. Data Preparation from the DurLAR Dataset
- Step 1: Radial Distance Calculation
- Step 2: Azimuth and Elevation Angle Calculation
- Step 3: Field of View Filtering
- Step 4: Image Coordinate Mapping
- Step 5: Radial Distance Mapping to Image Intensity
- Step 6: Cropping, Resizing, and Concatenation:
4.4. Training Details
5. Results and Discussion
5.1. Quantitative Evaluation
5.2. Qualitative Evaluation
6. Limitations and Future Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kochanthara, S.; Singh, T.; Forrai, A.; Cleophas, L. Safety of Perception Systems for Automated Driving: A Case Study on Apollo. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–28. [Google Scholar] [CrossRef]
- Standard J3016_202104; SAE On-Road Automated Driving (ORAD) Committee. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. SAE International: Warrendale, PA, USA, 2021. [CrossRef]
- Bosch. Redundant Systems Automated Driving. Available online: https://www.bosch.com/stories/redundant-systems-automated-driving/ (accessed on 15 February 2025).
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2443–2451. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3D Reconstruction in Real-Time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar] [CrossRef]
- Min, C.; Xiao, L.; Zhao, D.; Nie, Y.; Dai, B. Multi-Camera Unified Pre-Training via 3D Scene Reconstruction. IEEE Robot. Autom. Lett. 2024, 9, 3243–3250. [Google Scholar] [CrossRef]
- Dahnert, M.; Hou, J.; Niessner, M.; Dai, A. Panoptic 3D Scene Reconstruction From a Single RGB Image. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 8282–8293. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 2672–2680. [Google Scholar]
- Chang, H.; Gu, Y.; Goncharenko, I.; Hsu, L.T.; Premachandra, C. Cyclist Orientation Estimation Using LiDAR Data. Sensors 2023, 23, 3096. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Kim, H.K.; Yoo, K.Y.; Park, J.H.; Jung, H.Y. Asymmetric Encoder-Decoder Structured FCN Based LiDAR to Color Image Generation. Sensors 2019, 19, 4818. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.K.; Yoo, K.Y.; Jung, H.Y. Color Image Generation from LiDAR Reflection Data by Using Selected Connection UNET. Sensors 2020, 20, 3387. [Google Scholar] [CrossRef] [PubMed]
- Liang, D.; Pan, J.; Yu, Y.; Zhou, H. Concealed object segmentation in terahertz imaging via adversarial learning. Optik 2019, 185, 1104–1114. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Ouyang, Z.; Liu, Y.; Zhang, C.; Niu, J. A cGANs-Based Scene Reconstruction Model Using Lidar Point Cloud. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 1107–1114. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Milz, S.; Simon, M.; Fischer, K.; Pöpperl, M.; Groß, H.M. Points2Pix: 3D Point-Cloud to Image Translation Using Conditional GANs. In Proceedings of the Pattern Recognition (DAGM GCPR), Dortmund, Germany, 10–13 September 2019; Volume 11824, pp. 387–400. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Cortinhal, T.; Kurnaz, F.; Aksoy, E.E. Semantics-Aware Multi-Modal Domain Translation: From LiDAR Point Clouds to Panoramic Color Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, QC, Canada, 11–17 October 2021; pp. 3032–3041. [Google Scholar] [CrossRef]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Proceedings of the 15th International Symposium on Visual Computing (ISVC), San Diego, CA, USA, 5–7 October 2020; Volume 12510, pp. 207–222. [Google Scholar] [CrossRef]
- Khan, N.; Ullah, A.; Haq, I.U.; Menon, V.G.; Baik, S.W. SD-Net: Understanding overcrowded scenes in real-time via an efficient dilated convolutional neural network. J. Real-Time Image Process. 2021, 18, 1729–1743. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-Video Synthesis. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Cortinhal, T.; Aksoy, E.E. Depth-and semantics-aware multi-modal domain translation: Generating 3D panoramic color images from LiDAR point clouds. Robot. Auton. Syst. 2024, 171, 104583. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 405–421. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkuhler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. (TOG) 2023, 42, 139. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar] [CrossRef]
- Kossale, Y.; Airaj, M.; Darouichi, A. Mode Collapse in Generative Adversarial Networks: An Overview. In Proceedings of the 8th International Conference on Optimization and Applications (ICOA), Saidia, Morocco, 6–7 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Demir, U.; Unal, G. Patch-Based Image Inpainting with Generative Adversarial Networks. arXiv 2018, arXiv:1803.07422. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar] [CrossRef]
- Li, L.; Ismail, K.N.; Shum, H.P.H.; Breckon, T.P. DurLAR: A High-Fidelity 128-Channel LiDAR Dataset with Panoramic Ambient and Reflectivity Imagery for Multi-Modal Autonomous Driving Applications. In Proceedings of the 2021 International Conference on 3D Vision (3DV), Virtual, 1–3 December 2021; pp. 1227–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Huang, K.; Shi, B.; Li, X.; Li, X.; Huang, S.; Li, Y. Multi-modal Sensor Fusion for Auto Driving Perception: A Survey. arXiv 2022, arXiv:2202.02703. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Biewald, L. Experiment Tracking with Weights and Biases. Software Available from wandb.com. 2020. Available online: https://www.wandb.com/ (accessed on 6 July 2025).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 6626–6637. [Google Scholar]
- Parmar, G.; Zhang, R.; Zhu, J.Y. On Aliased Resizing and Surprising Subtleties in GAN Evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 11410–11420. [Google Scholar] [CrossRef]
- NVIDIA Corporation. NVIDIA Unveils DRIVE Thor—Centralized Car Computer Unifying Cluster, Infotainment, Automated Driving, and Parking in a Single, Cost-Saving System. Available online: https://nvidianews.nvidia.com/news/nvidia-unveils-drive-thor-centralized-car-computer-unifying-cluster-infotainment-automated-driving-and-parking-in-a-single-cost-saving-system (accessed on 19 June 2025).
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 8768–8780. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR (dB) ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Reflectance only | 11.1819 | 0.1598 | 0.7859 |
| Ambient only | 9.9761 | 0.2934 | 0.6921 |
| Range only | 8.2648 | 0.1160 | 0.8470 |
| All (no Seg) | 19.4384 | 0.5639 | 0.3721 |
| All + Seg | 19.8535 | 0.6310 | 0.3052 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Gu, Y.; Goncharenko, I.; Kamijo, S. LiGenCam: Reconstruction of Color Camera Images from Multimodal LiDAR Data for Autonomous Driving. Sensors 2025, 25, 4295. https://doi.org/10.3390/s25144295
Xu M, Gu Y, Goncharenko I, Kamijo S. LiGenCam: Reconstruction of Color Camera Images from Multimodal LiDAR Data for Autonomous Driving. Sensors. 2025; 25(14):4295. https://doi.org/10.3390/s25144295
Chicago/Turabian StyleXu, Minghao, Yanlei Gu, Igor Goncharenko, and Shunsuke Kamijo. 2025. "LiGenCam: Reconstruction of Color Camera Images from Multimodal LiDAR Data for Autonomous Driving" Sensors 25, no. 14: 4295. https://doi.org/10.3390/s25144295
APA StyleXu, M., Gu, Y., Goncharenko, I., & Kamijo, S. (2025). LiGenCam: Reconstruction of Color Camera Images from Multimodal LiDAR Data for Autonomous Driving. Sensors, 25(14), 4295. https://doi.org/10.3390/s25144295