

Perception-Based H.264/AVC Video Coding for Resource-Constrained and Low-Bit-Rate Applications

Abstract
1. Introduction
1.1. Literature Review
1.1.1. Foundations of Perceptual Video Coding
1.1.2. ROI Detection and Bit Allocation
1.1.3. JND-Based Perceptual Coding
1.1.4. Face-Centric and Attention-Driven ROI Coding
1.1.5. ROI-Based Transcoding and Mobile Adaptation
1.1.6. Real-World Applications and Frameworks
1.2. Motivation
1.3. Innovation and Contribution of This Work
- A.
- Dual-criteria ROI Definition for Perceptual PrioritizationWe propose a dual-criteria ROI detection strategy that identifies both (i) face regions and (ii) motion-intensive macroblocks (MBs) based on motion vector magnitude. This design ensures that regions most relevant to human visual perception receive enhanced visual quality, even under very low bit rate constraints.
- B.
- Low-Complexity ROI Detection using Viola–Jones and Motion AnalysisTo maintain a lightweight system, we employed a Haar cascade classifier (Viola–Jones) for face detection and identified fast-moving MBs by comparing the current MB’s motion vector magnitude with the average motion vector of the previous frame. This strategy eliminates the need for computationally expensive saliency modeling or optical flow, making it well-suited for real-time applications on IoT and edge platforms.
- C.
- Adaptive QP Control with Four-Level ROI ClassificationWe developed a macroblock-level QP adjustment scheme based on a four-level ROI classification that allocates finer quantization to more perceptually sensitive regions. To further reduce visual artifacts such as blocking and maintain spatial consistency, we also introduced an inter-MB QP smoothness constraint.
- D.
- System-Level Deployability and Encoder IntegrationWe integrated our algorithm into the JM9.8 and JM18.4 versions of the H.264/AVC reference software and ensured its compatibility with the CPDT (Cascaded Pixel Domain Transcoder) frameworks. This facilitates seamless integration into both encoder and transcoder systems for real-world deployment.
- E.
- Experimental Comparison between Viola–Jones Face Detection and Lightweight Deep Face DetectorWe conducted extensive experiments to compare our Viola–Jones-based detector with a MobileNetV1-SSD (INT8) deep learning model. We evaluated key performance metrics such as FLOPs, model size, memory usage, detection accuracy, and frame rate, including tests on Raspberry Pi 4 hardware. The results demonstrate that the Viola–Jones-based face detector offers a favorable trade-off between computational complexity and coding quality.
- F.
- Improved Subjective and Objective Quality with Minimal Complexity OverheadOur run-time analysis reveals that the proposed method incurs only a 3–10% increase in execution time, while delivering notable improvements in both subjective visual perception and objective metrics (e.g., PSNR) within ROI areas. These benefits remain consistent even under ultra-low-bit-rate or bandwidth-limited scenarios, confirming the method’s practicality in resource-constrained environments.

| Method Type | ROI Detection Technique | Computational Complexity | Real-Time Feasibility | Suitability for IoT Devices |
|---|---|---|---|---|
| Traditional Heuristics | Frame difference, skin-color detection | Low to Moderate | Moderate | Partial |
| Saliency-Based | Visual attention, saliency models (Itti-Koch, GBVS) | Moderate to High | Limited | No |
| Deep Learning-Based | CNNs (e.g., YOLO, SSD), semantic segmentation | High | No (requires GPU) | No |
| Proposed Method | Viola-Jones for faces + MV-based fast MBs | Very Low | Yes | Yes |
2. Human Face Detection with Adaptive Boosting Algorithm
2.1. Fundamentals of the AdaBoost Classifier
2.2. Face Detection with the OpenCV AdaBoost Classifier
- CascadeClassifier face_cascade //define a variable with type classifier
- String face_cascade_name=“haarcascade_frontalface_alt.xml” //Declare the use of a frontal face classifier
- face_cascade.load (face_cascade_name) //Read in the declared classifier
- face_cascade.detectMultiScale (frame_gray, faces, 1.1, 2, 0 | CV_HAAR_SCALE_IMAGE, Size (30, 30)) //Perform face detection with a minimal size of pixels
- faces[i] //Center position of the detected ith face
- faces[i].width //Width of the detected ith face
- faces[i].height //Height of the detected ith face
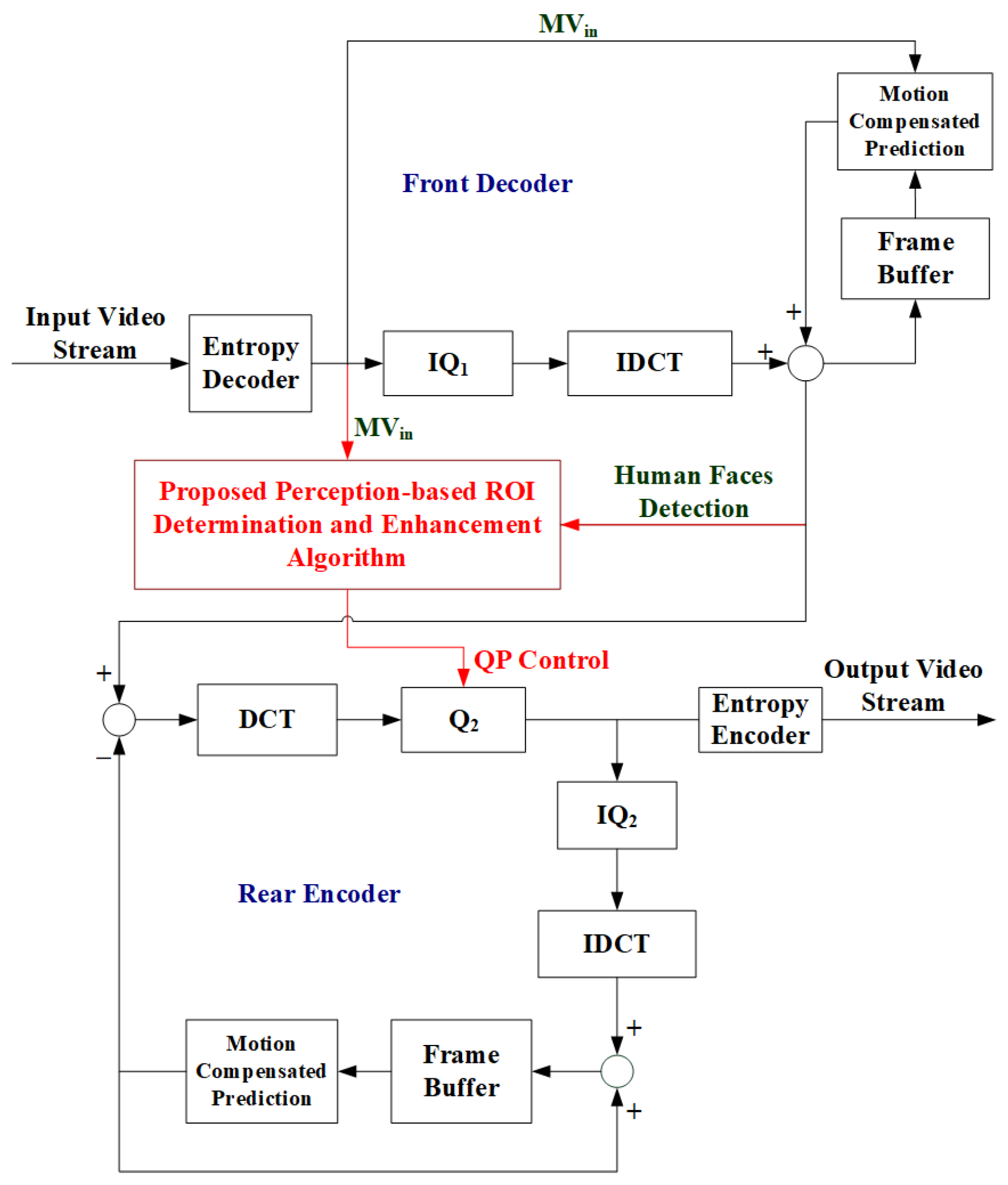
3. Proposed Perception-Based Visual Quality Enhancement Algorithm
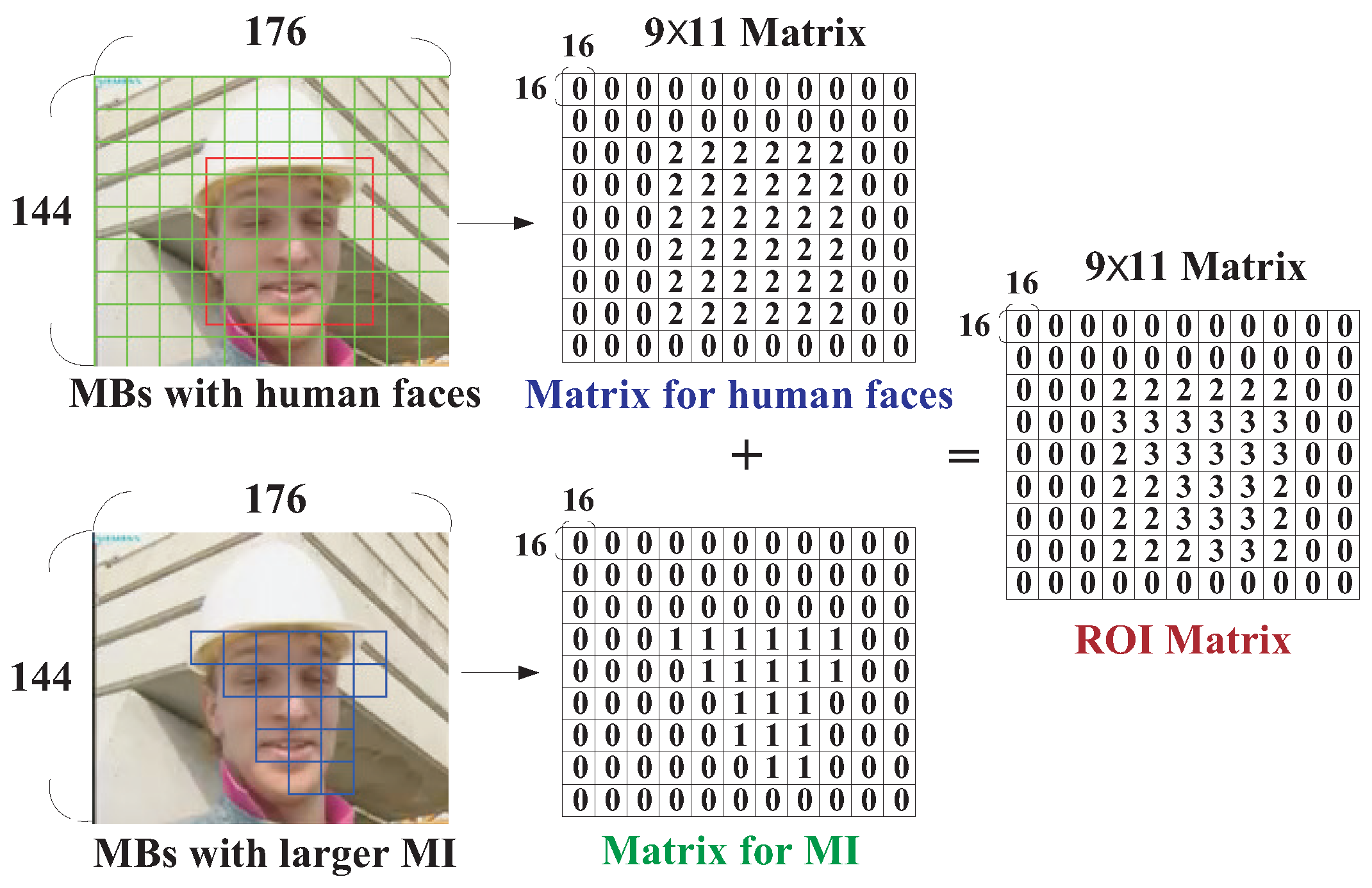
- Type 3: MB with both human faces and larger motion activities.
- Type 2: MB with human faces.
- Type 1: MB with greater motion activities.
- Type 0: Background MBs, i.e., MB with neither human faces nor larger motion activities.
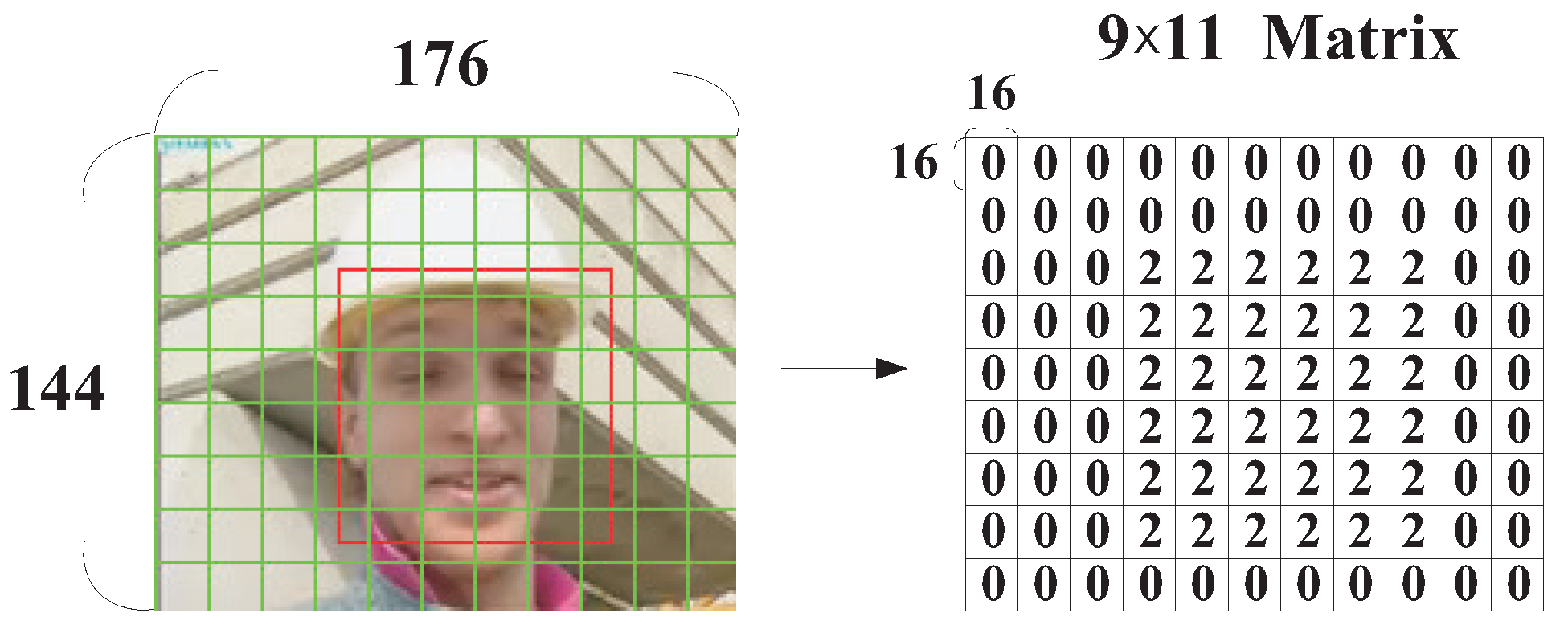
3.1. ROI with Human Faces
3.2. ROIs with Greater Motion Activities
3.3. Proposed Dynamic QP Adjustment Strategy
3.4. Applying the Proposed Algorithm to H.264/AVC Transcoding Systems
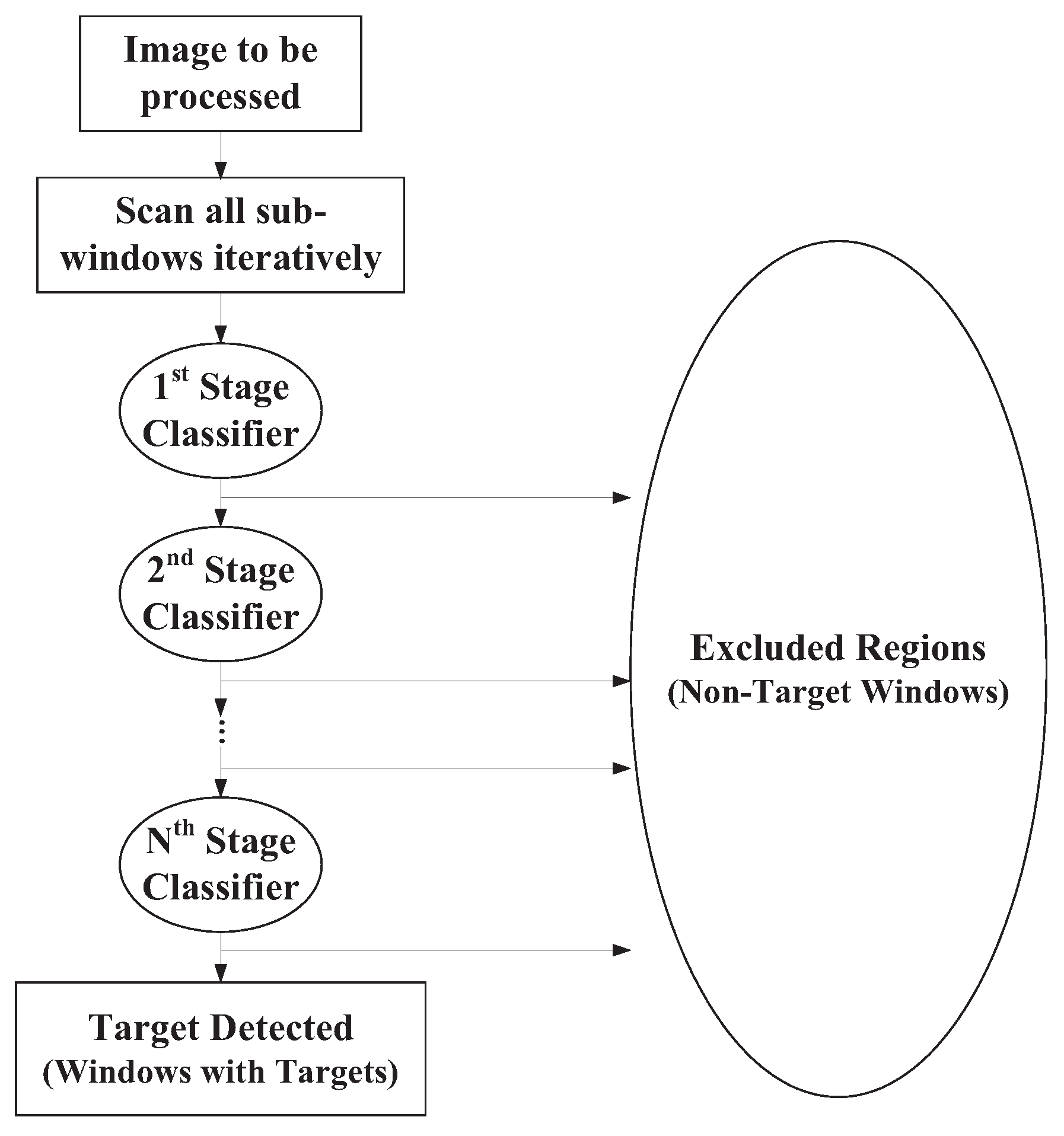
4. Experiments
4.1. Face Detection by Adaboost Algorithm
4.2. Face Detection Complexity: Haar Cascade vs. MobileNet-SSD
4.3. Subjective and Objective ROI Visual Quality Evaluation
- 01.
- RD Optimization: on
- 02.
- Entropy coding: CABAC
- 03.
- SearchRange: 16
- 04.
- NumberReferenceFrames: 2
- 05.
- NumberBFrames: 0
- 06.
- RateControlEnable: 1
- 07.
- InitialQP: 30
- 08.
- BasicUnit: 1
4.4. Objective Quality Comparisons with State-of-the-Art Encoders on JM9.8
4.5. Comparisons with Standard JM18.4 Software
- 1.
- RD Optimization: on
- 2.
- Entropy coding: CABAC
- 3.
- SearchRange: 16
- 4.
- NumberReferenceFrames: 2
- 5.
- NumberBFrames: 0
- 6.
- RateControlEnable: 1
4.6. Run-Time Performance on JM9.8 and JM18.4
5. Limitations and Future Work
5.1. Transcoding Integration and Limitations
- A.
- Impact on End-to-End LatencyThe proposed perception-based QP control is implemented at the macroblock level during re-quantization. As the proposed method involves region-of-interest (ROI) analysis prior to QP reassignment, it introduces a slight additional delay in the transcoding process. This added latency, measured at approximately 3–10%, is generally acceptable for offline or buffered applications but may pose a concern for ultra-low-latency live-streaming scenarios.
- B.
- Streaming Protocol CompatibilityOur method operates entirely within the pixel-domain transcoding stage (CPDT), without modifying the bitstream syntax or introducing any non-standard metadata. Therefore, the output video remains fully compliant with existing H.264/AVC decoders and compatible with standard streaming protocols such as RTSP, HLS, or MPEG-DASH. That said, the additional transcoding step may require re-buffering or increased segment preparation time in certain adaptive streaming implementations.
- C.
- Potential Limitations and Non-Applicable ScenariosThe proposed method is most effective in scenarios where faces or motion regions are perceptually important and where some transcoding latency can be tolerated. It may not be applicable in applications that demand frame-level latency (e.g., interactive video conferencing) or in content types without clear perceptual saliency (e.g., screen-captured content, static slides, or surveillance with minimal motion). In such cases, the cost–benefit trade-off of the ROI-based re-quantization may not justify the added processing.
5.2. Failure Case Analysis
- A.
- Face Detection Failures:The Viola–Jones classifier may fail in detecting faces with non-frontal poses, strong lighting variations, or partial occlusions. In such cases, inaccurate ROI detection can result in inappropriate QP assignments, degrading visual quality in perceptually important regions.
- B.
- Non-Salient Content Types:In scenarios such as static slides, screen recordings, or low-activity surveillance footage, the lack of perceptual saliency may cause the ROI detection mechanism to either fail to identify any meaningful regions or to assign QP levels uniformly, resulting in negligible visual improvement despite added processing.
- C.
- False Positives from Motion Detection:Background motion (e.g., moving trees, passing cars) may be misclassified as perceptually important due to high motion vector magnitudes. This can lead to inefficient bit rate allocation and loss of quality in more relevant regions, such as faces.
- D.
- Real-Time Constraints:Although not a failure of functionality, the method may not be suitable in real-time systems with strict latency requirements, as the added 3–10% computational cost could affect responsiveness.
5.3. Potential Strategies for Reducing Computational Complexity
- A.
- Reduced ROI Evaluation FrequencyInstead of performing ROI analysis (including face and motion detection) on every frame, we propose a content-adaptive update strategy based on encoding parameters readily available from the H.264/AVC encoder:
- Skip Mode Ratio: For example, if more than 80% of macroblocks in the current frame are encoded in Skip Mode (i.e., no residuals or motion compensation is needed), this suggests scene stability. In such cases, ROI analysis can be safely skipped for that frame.
- Motion Vector Variability: We measure the frame-to-frame difference in motion vector magnitude histograms. If the histogram remains stable between two consecutive frames, this implies little change in motion saliency, and ROI re-analysis can be avoided.
- B.
- Simplified Motion AnalysisTo reduce the arithmetic complexity involved in computing motion vector magnitudes for macroblocks, we replace costly floating-point operations with hardware-efficient alternatives:
- L1 Norm Approximation: Replace the Euclidean norm () with the Manhattan distance (), avoiding multiplication and square root operations.
- Fixed Thresholding: Instead of calculating the average motion vector magnitude per frame, we use an empirically determined fixed threshold (e.g., 4 MV units for CIF resolution) to classify motion-intensive regions.
- Quantized MV Binning: Motion vector magnitudes are quantized into discrete bins (e.g., 0–1, 2–3, 4–5, etc.) and mapped to pre-defined ROI weights via a lookup table. This removes the need for real-time numerical comparisons.
- C.
- Hardware-Level OptimizationsTo further improve performance on embedded platforms such as the Raspberry Pi 4 Model B, low-level optimizations can be applied:
- NEON SIMD Instructions: Utilize ARM NEON SIMD instructions to accelerate macroblock-level pixel processing and QP assignment logic.
- Fixed-point Arithmetic: Where applicable, convert floating-point operations (e.g., ROI weighting, QP adjustment calculations) to fixed-point approximations to take advantage of hardware-supported integer math.
5.4. Incorporating Perceptual Quality Metrics in Future Evaluations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AdaBoost | Adaptive Boosting |
| AVC | Advanced Video Coding |
| CCTV | Closed-Circuit Television |
| CDDT | Cascade DCT Domain Transcoder |
| CIF | Common Intermediate Format |
| CPDT | Cascade Pixel Domain Transcoder |
| HD | High Definition |
| HEVC | High-Efficiency Video Coding |
| IoT | Internet of Things |
| JM | Joint Model |
| JND | Just Noticeable Distortion |
| MB | Macroblock |
| NZTC | Non-zero Transform Coefficients |
| PSNR | Peak Signal-to-Noise Ratio |
| QCIF | Quarter Common Intermediate Format |
| QP | Quantization Parameter |
| RDO | Rate Distortion Optimization |
| ROI | Region of Interest |
| VVC | Versatile Video Coding |
References
- Wei, H.; Zhou, W.; Bai, R.; Duan, Z. A Rate Control Algorithm for HEVC Considering Visual Saliency. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 November 2018; pp. 36–42. [Google Scholar]
- Zhu, S.; Xu, Z. Spatiotemporal Visual Saliency Guided Perceptual High Efficiency Video Coding with Neural Network. Neurocomputing 2018, 275, 511–522. [Google Scholar] [CrossRef]
- Sun, X.; Yang, X.; Wang, S.; Liu, M. Content-aware Rate Control Scheme for HEVC Based on Static and Dynamic Saliency Detection. Neurocomputing 2020, 411, 393–405. [Google Scholar] [CrossRef]
- Li, T.; Yu, L.; Wang, H.; Kuang, Z. A Bit Allocation Method Based on Inter-View Dependency and Spatio-Temporal Correlation for Multi-View Texture Video Coding. IEEE Trans. Broadcast. 2021, 67, 159–173. [Google Scholar] [CrossRef]
- Ku, C.; Xiang, G.; Qi, F.; Yan, W.; Li, Y.; Xie, X. Bit Allocation Based on Visual Saliency in HEVC. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Taipei, Taiwan, 1–4 December 2019. [Google Scholar]
- Zhao, Z.; He, X.; Xiong, S.; He, L.; Chen, H.; Sheriff, R.E. A High-Performance Rate Control Algorithm in Versatile Video Coding Based on Spatial and Temporal Feature Complexity. IEEE Trans. Broadcast. 2023, 69, 753–766. [Google Scholar] [CrossRef]
- Bi, J.; Wang, L.; Han, Y.; Zhou, C. Real-time Face Perception Based Encoding Strategy Optimization Method for UHD Videos. IET Image Process. 2023, 17, 2764–2779. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Y.; Zhu, L.; Liu, H. Perception-Based CTU Level Bit Allocation for Intra High Efficiency Video Coding. IEEE Access 2019, 7, 154959–154970. [Google Scholar] [CrossRef]
- ITU-T H.264; Advanced Video Coding for Generic Audiovisual Services. ITU-T: Geneva, Switzerland, 2024.
- ITU-T H.265; High Efficiency Video Coding. ITU-T: Geneva, Switzerland, 2024.
- ITU-T H.266; Versatile Video Coding. ITU-T: Geneva, Switzerland, 2023.
- Wiegand, T.; Sullivan, G.; Bjøntegaard, G.; Luthra, A. Overview of the H.264/AVC Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Ostermann, J.; Bormans, J.; List, P.; Marpe, D.; Narroschke, M.; Pereira, F.; Stockhammer, T.; Wedi, T. Video Coding with H.264/AVC: Tools, Performance, and Complexity. IEEE Circuits Syst. Mag. 2004, 4, 7–28. [Google Scholar] [CrossRef]
- Richardson, I.E.G. H.264/MPEG-4 Part 10 White Paper. Vcodex. Available online: http://www.vcodex.com (accessed on 3 July 2025).
- Xin, J.; Lin, C.-W.; Sun, M.-T. Digital Video Transcoding. Proc. IEEE 2005, 93, 84–97. [Google Scholar] [CrossRef]
- Vetro, A.; Christopoulos, C.; Sun, H. Video Transcoding Architectures and Techniques: An Overview. IEEE Signal Process. Mag. 2003, 20, 18–29. [Google Scholar] [CrossRef]
- Lee, J.-S.; Ebrahimi, T. Perceptual Video Compression: A Survey. IEEE J. Sel. Top. Signal Process. 2012, 6, 684–697. [Google Scholar] [CrossRef]
- Wu, H.-R.; Reibman, A.R.; Lin, W.; Pereira, F.; Hemami, S.S. Perceptual Visual Signal Compression and Transmission. Proc. IEEE 2013, 101, 2025–2043. [Google Scholar] [CrossRef]
- Le Callet, P.; Niebur, E. Visual Attention and Applications in Multimedia Technologies. Proc. IEEE 2013, 101, 2058–2067. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.G.; Soh, Y.C. Region-of-Interest Based Resource Allocation for Conversational Video Communication of H.264/AVC. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 134–139. [Google Scholar] [CrossRef]
- Hu, H.-M.; Li, B.; Lin, W.; Li, W.; Sun, M.-T. Region-Based Rate Control for H.264/AVC for Low Bit-Rate Applications. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1564–1576. [Google Scholar] [CrossRef]
- Chiang, J.-C.; Hsieh, C.-S.; Chang, G.; Jou, F.-D.; Lie, W.-N. Region-Of-Interest Based Rate Control Scheme with Flexible Quality on Demand. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo (ICME 2010), Singapore, 19–23 July 2010; pp. 238–242. [Google Scholar]
- Luo, Z.; Song, L.; Zheng, S.; Ling, N. H.264/Advanced Video Control Perceptual Optimization Coding Based on JND-Directed Coefficient Suppression. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 935–948. [Google Scholar] [CrossRef]
- Ou, T.-S.; Huang, Y.-H.; Chen, H.H. SSIM-Based Perceptual Rate Control for Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 682–691. [Google Scholar]
- Xiong, B.; Fan, X.; Zhu, C.; Jing, X.; Peng, Q. Face Region Based Conversational Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 917–931. [Google Scholar] [CrossRef]
- Lee, J.-S.; De Simone, F.; Ebrahimi, T. Subjective Quality Evaluation of Foveated Video Coding Using Audio-Visual Focus of Attention. IEEE J. Sel. Top. Signal Process. 2011, 5, 1322–1331. [Google Scholar] [CrossRef]
- Huang, S.-F.; Chen, M.-J.; Tai, K.-H.; Li, M.-S. Region-of-Interest Determination and Bit-Rate Conversion for H.264 Video Transcoding. EURASIP J. Adv. Signal Process. 2013, 2013, 112. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Fan Jiang, S.-J.; Lin, C.-Y.; Chen, M.-J. Temporal Video Transcoding Based on Frame Complexity Analysis for Mobile Video Communication. IEEE Trans. Broadcast. 2013, 59, 38–46. [Google Scholar]
- Pietrowcew, A.; Buchowicz, A.; Skarbek, W. Bit-Rate Control Algorithm for ROI Enabled Video Coding. In Proceedings of the 11th International Conference on Computer Analysis of Images and Patterns (CAIP 2005), Berlin, Germany, 5–8 September 2005; Springer: Berlin, Germany, 2005; pp. 514–521. [Google Scholar]
- Chi, M.-C.; Yeh, C.-H.; Chen, M.-J. Robust Region-of-Interest Determination Based on User Attention Model Through Visual Rhythm Analysis. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 1025–1038. [Google Scholar]
- Lin, C.-W.; Chen, Y.-C.; Sun, M.-T. Dynamic Region of Interest Transcoding for Multipoint Video Conferencing. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 982–992. [Google Scholar]
- H.264/AVC Software Coordination. Available online: http://iphome.hhi.de/suehring/tml (accessed on 20 April 2025).
- Kau, L.-J.; Lee, M.-X. Perception-Based Video Coding with Human Faces Detection and Enhancement in H.264/AVC Systems. In Proceedings of the 2015 IEEE 58th International Midwest Symposium on Circuits and Systems (IEEE MWSCAS 2015), Fort Collins, CO, USA, 2–5 August 2015; IEEE: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Jiang, H.; Learned-Miller, E. Face Detection with the Faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 650–657. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 4875–4884. [Google Scholar]
- Zhang, J.; Wu, X.; Hoi, S.C.H.; Zhu, J. Feature Agglomeration Networks for Single Stage Face Detection. Neurocomputing 2020, 380, 180–189. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; IEEE: New York, NY, USA, 2001; Volume 1, pp. 511–518. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
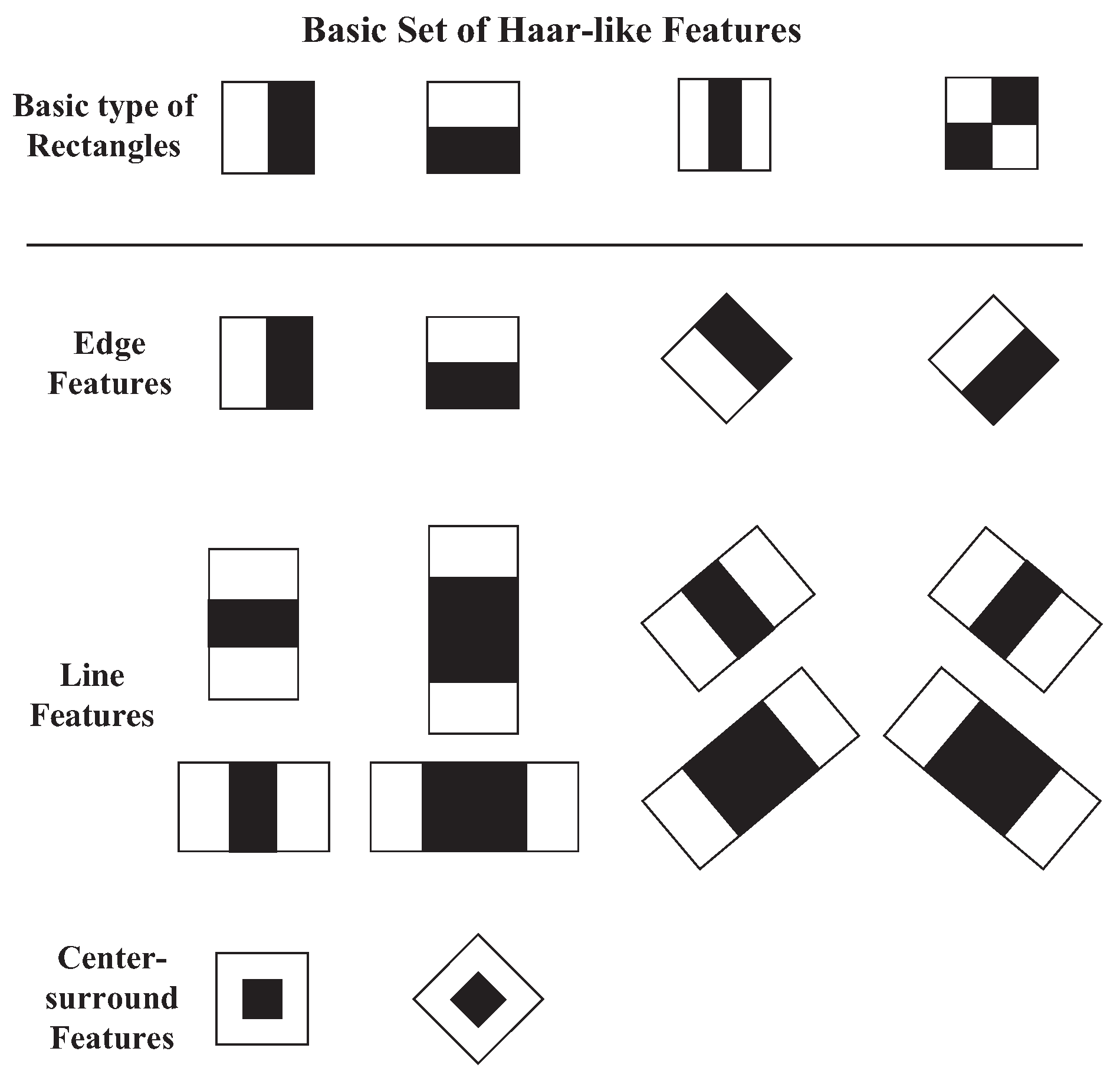
- Lienhart, R.; Maydt, J. An Extended Set of Haar-Like Features for Rapid Object Detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; IEEE: New York, NY, USA, 2002; Volume 1, pp. 900–903. [Google Scholar]
- OpenCV (Open Source Computer Vision Library). Available online: http://opencv.org (accessed on 30 June 2025).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Arm Software. SSD MobileNetV1 (INT8) TFLite Model Definition. 2025. Available online: https://github.com/ARM-software/ML-zoo/blob/master/models/object_detection/ssd_mobilenet_v1/tflite_int8/definition.yaml (accessed on 30 June 2025).
- Jain, V.; Learned-Miller, E. FDDB: A Benchmark for Face Detection in Unconstrained Settings; University of Massachusetts Amherst: Amherst, MA, USA, 2025; Available online: https://github.com/cezs/FDDB?utm_source=chatgpt.com (accessed on 30 June 2025).
- Demonstration of the Proposed System. Available online: https://tinyurl.com/3kw5yc2c (accessed on 30 June 2025).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











| Image Resolution Target Bitrates | QCIF Test Sequences | CIF Test Sequences |
|---|---|---|
| 244 kbps | Foreman (15 fps) | Foreman (15 fps) |
| 118 kbps | Mother-Daughter (30 fps) | Mother-Daughter (30 fps) |
| 68 kbps | MissAmerica (30 fps) | Akiyo (30 fps) |
| 64 kbps | Foreman (15 fps) | Foreman (15 fps) |
| 22 kbps | Mother-Daughter (30 fps) | Mother-Daughter (30 fps) |
| 19 kbps | Foreman (15 fps) | Foreman (15 fps) |
| 11 kbps | MissAmerica (30 fps) Mother-Daughter (30 fps) | Akiyo (30 fps) Mother-Daughter (30 fps) |
| 8 kbps | MissAmerica (30 fps) | Akiyo (30 fps) |
| Metric | Viola-Jones (Haar) | MobileNetV1-SSD (INT8) | Remarks |
|---|---|---|---|
| Input Resolution | CIF (352 × 288) | 300 × 300 | |
| FLOPs | 2 M | 570 M | Inference per image |
| Model Size | <1 MB | 6.8 MB | |
| RAM Usage | 20 MB | 30 MB | Includes model, input, buffer memory |
| FPS | Approx. 15 | Approx. 8 | Estimated on Raspberry Pi 4 |
| Detection Rate | 70% | 88% | |
| Precision | 0.85 | 0.87 | With IoU = 0.5 |
| Recall | 0.68 | 0.85 | With IoU = 0.5 |
| Applicable Scenarios | Frontal face detection in real-time low-power systems | Robust detection across multiple views, occlusion and lighting conditions | |
| Platform Compatibility | High | High |
| QCIF Video | Metric | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | |
| Foreman 15 fps | Actual Bitrates (Kbps) | 19.03 | 19.20 | 19.04 | 64.02 | 64.30 | 64.03 | 244.00 | 244.46 | 244.02 |
| PSNR (dB) | 29.58 | 27.84 | 27.10 | 36.11 | 33.13 | 33.86 | 43.25 | 38.72 | 41.07 | |
| PSNR/Bitrate | 1.554 | 1.450 | 1.423 | 0.564 | 0.515 | 0.529 | 0.177 | 0.158 | 0.168 | |
| QCIF Video | Metric | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | |
| Miss America 30 fps | Actual Bitrates (Kbps) | 8.06 | 8.59 | 8.04 | 11.07 | 11.16 | 11.04 | 68.16 | 68.37 | 68.03 |
| PSNR (dB) | 32.98 | 32.95 | 32.82 | 35.15 | 34.53 | 34.61 | 42.40 | 42.74 | 42.23 | |
| PSNR/Bitrate | 4.091 | 3.836 | 4.082 | 3.175 | 3.094 | 3.135 | 0.622 | 0.625 | 0.621 | |
| QCIF Video | Metric | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | JM9.8 | Proposed | Ref. [20] | |
| Mother-Daughter 30 fps | Actual Bitrates (Kbps) | 11.04 | 11.25 | 11.05 | 22.05 | 22.15 | 22.05 | 118.11 | 118.40 | 118.07 |
| PSNR (dB) | 31.62 | 31.54 | 28.74 | 34.31 | 34.03 | 30.85 | 42.09 | 42.30 | 37.98 | |
| PSNR/Bitrate | 2.864 | 2.804 | 2.600 | 1.556 | 1.536 | 1.399 | 0.356 | 0.357 | 0.322 | |
| CIF Video | Metric | Target Bitrate 19 kb/s | Target Bitrates 64 kb/s | Target Bitrates 244 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | |
| Foreman 15 fps | Actual Bitrates (Kbps) | 19.02 | 19.29 | −0.27 | 64.05 | 64.06 | −0.01 | 244.06 | 244.11 | −0.05 |
| PSNR (dB) | 24.66 | 24.68 | −0.02 | 31.29 | 31.69 | −0.40 | 37.00 | 37.11 | −0.11 | |
| PSNR/Bitrate | 1.297 | 1.279 | 0.018 | 0.489 | 0.495 | −0.006 | 0.152 | 0.152 | 0.000 | |
| CIF Video | Metric | Target Bitrate 8 kb/s | Target Bitrates 11 kb/s | Target Bitrates 68 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | |
| Akiyo 30 fps | Actual Bitrates (Kbps) | 8.22 | 8.66 | −0.44 | 11.04 | 11.62 | −0.58 | 68.12 | 68.28 | −0.16 |
| PSNR (dB) | 29.57 | 29.85 | −0.28 | 31.74 | 32.11 | −0.37 | 38.59 | 39.39 | −0.80 | |
| PSNR/Bitrate | 3.597 | 3.447 | 0.150 | 2.875 | 2.763 | 0.112 | 0.567 | 0.577 | −0.010 | |
| CIF Video | Metric | Target Bitrate 11 kb/s | Target Bitrates 22 kb/s | Target Bitrates 118 kb/s | ||||||
| Scheme | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | JM9.8 | Proposed | Difference JM-Proposed | |
| Mother-Daughter 30 fps | Actual Bitrates (Kbps) | 11.05 | 11.37 | −0.32 | 22.06 | 22.38 | −0.32 | 118.18 | 118.19 | −0.01 |
| PSNR (dB) | 29.17 | 29.76 | −0.59 | 31.92 | 31.96 | −0.04 | 38.51 | 38.21 | 0.30 | |
| PSNR/Bitrate | 2.640 | 2.617 | 0.0023 | 1.447 | 1.428 | 0.019 | 0.326 | 0.323 | 0.003 | |
| QCIF Video | Metric | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Foreman 15 fps | Actual Bitrates (Kbps) | 19.02 | 18.97 | 0.05 | 64.00 | 64.05 | −0.05 | 243.91 | 243.85 | 0.06 |
| PSNR (dB) | 29.98 | 29.89 | 0.09 | 36.63 | 36.56 | 0.07 | 43.82 | 43.75 | 0.07 | |
| PSNR/Bitrate | 1.576 | 1.576 | 0.000 | 0.572 | 0.571 | 0.001 | 0.180 | 0.179 | 0.001 | |
| QCIF Video | Metric | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Miss America 30 fps | Actual Bitrates (Kbps) | 10.78 | 11.45 | −0.67 | 13.18 | 14.18 | −1.00 | 67.98 | 67.93 | 0.05 |
| PSNR (dB) | 35.03 | 35.36 | −0.33 | 36.18 | 36.28 | −0.10 | 42.96 | 42.82 | 0.14 | |
| PSNR/Bitrate | 3.250 | 3.088 | 0.162 | 2.745 | 2.559 | 0.186 | 0.632 | 0.630 | 0.002 | |
| QCIF Video | Metric | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Mother-Daughter 30 fps | Actual Bitrates (Kbps) | 12.06 | 12.16 | −0.10 | 22.12 | 22.65 | −0.53 | 118.36 | 118.55 | −0.19 |
| PSNR (dB) | 32.55 | 32.57 | −0.02 | 35.06 | 34.99 | 0.07 | 42.58 | 42.40 | 0.18 | |
| PSNR/Bitrate | 2.699 | 2.678 | 0.021 | 1.585 | 1.545 | 0.040 | 0.360 | 0.358 | 0.002 | |
| CIF Video | Metric | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Foreman 15 fps | Actual Bitrates (Kbps) | 34.73 | 39.31 | −4.58 | 64.12 | 64.08 | 0.04 | 243.65 | 243.82 | −0.17 |
| PSNR (dB) | 28.84 | 29.30 | −0.46 | 31.87 | 31.75 | 0.12 | 37.42 | 37.36 | 0.06 | |
| PSNR/Bitrate | 0.830 | 0.745 | 0.085 | 0.497 | 0.495 | 0.032 | 0.154 | 0.153 | 0.001 | |
| CIF Video | Metric | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Akiyo 30 fps | Actual Bitrates (Kbps) | 14.51 | 19.30 | −4.79 | 14.51 | 19.30 | −4.79 | 67.98 | 67.96 | 0.02 |
| PSNR (dB) | 33.52 | 34.75 | −1.23 | 33.52 | 34.75 | −1.23 | 39.73 | 39.20 | 0.53 | |
| PSNR/Bitrate | 2.310 | 1.800 | 0.510 | 2.310 | 1.800 | 0.510 | 0.584 | 0.577 | 0.007 | |
| CIF Video | Metric | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | ||||||
| Scheme | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | JM18.4 | Proposed | Difference JM-Proposed | |
| Mother-Daughter 30 fps | Actual Bitrates (Kbps) | 18.84 | 22.48 | −3.64 | 24.01 | 24.92 | −0.91 | 118.17 | 118.21 | −0.04 |
| PSNR (dB) | 32.02 | 32.62 | −0.60 | 32.84 | 32.81 | 0.03 | 39.40 | 39.06 | 0.34 | |
| PSNR/Bitrate | 1.700 | 1.451 | 0.249 | 1.368 | 1.317 | 0.051 | 0.333 | 0.330 | 0.003 | |
| QCIF Video | Foreman 15 fps | Target Bitrate | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 376.73 | 378.24 | 0.40% | 430.48 | 417.39 | −3% | 534.08 | 477.06 | −10.70% | ||
| Miss America 30 fps | Target Bitrate | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | |||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 169.54 | 178.70 | 5.40% | 173.86 | 180.79 | 4% | 195.05 | 206.01 | 5.60% | ||
| Mother-Daughter 30 fps | Target Bitrate | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | |||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 352.76 | 362.75 | 2.80% | 371.49 | 381.64 | 2.70% | 445.60 | 465.91 | 4.60% | ||
| CIF Video | Foreman 15 fps | Target Bitrate | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 1400.90 | 1482.68 | 5.80% | 1509.80 | 1581.95 | 4.80% | 1696.96 | 1760.39 | 3.75% | ||
| Akiyo 30 fps | Target Bitrate | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | |||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 1290.65 | 1401.30 | 8.60% | 1322.32 | 1412.32 | 6.80% | 1503.19 | 1588.81 | 5.70% | ||
| Mother-Daughter 30 fps | Target Bitrate | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | |||||||
| Scheme | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | JM9.8 | Proposed | % Increased | ||
| RunTime (in Second) | 1340.95 | 1424.93 | 6.30% | 1388.86 | 1459.98 | 5.10% | 1526.84 | 1580.95 | 3.50% | ||
| QCIF Video | Foreman 15 fps | Target Bitrate | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 262.16 | 274.36 | 4.70% | 287.67 | 299.65 | 4.20% | 329.02 | 342.23 | 4.00% | ||
| Miss America 30 fps | Target Bitrate | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | |||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 105.53 | 114.74 | 8.70% | 107.25 | 116.14 | 8.30% | 115.99 | 124.99 | 7.80% | ||
| Mother-Daughter 30 fps | Target Bitrate | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | |||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 221.68 | 234.70 | 5.90% | 234.11 | 246.03 | 5.10% | 260.80 | 274.65 | 5.30% | ||
| CIF Video | Foreman 15 fps | Target Bitrate | Target Bitrate 19 kb/s | Target Bitrate 64 kb/s | Target Bitrate 244 kb/s | ||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 952.50 | 1025.92 | 7.70% | 982.54 | 1050.12 | 6.90% | 1085.37 | 1157.42 | 6.60% | ||
| Akiyo 30 fps | Target Bitrate | Target Bitrate 8 kb/s | Target Bitrate 11 kb/s | Target Bitrate 68 kb/s | |||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 795.62 | 877.65 | 10.30% | 795.60 | 876.63 | 10.20% | 850.86 | 918.82 | 8.00% | ||
| Mother-Daughter 30 fps | Target Bitrate | Target Bitrate 11 kb/s | Target Bitrate 22 kb/s | Target Bitrate 118 kb/s | |||||||
| Scheme | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | JM18.4 | Proposed | % Increased | ||
| RunTime (in Second) | 802.54 | 881.92 | 9.90% | 808.80 | 886.72 | 9.60% | 893.76 | 967.14 | 8.20% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kau, L.-J.; Tseng, C.-K.; Lee, M.-X. Perception-Based H.264/AVC Video Coding for Resource-Constrained and Low-Bit-Rate Applications. Sensors 2025, 25, 4259. https://doi.org/10.3390/s25144259
Kau L-J, Tseng C-K, Lee M-X. Perception-Based H.264/AVC Video Coding for Resource-Constrained and Low-Bit-Rate Applications. Sensors. 2025; 25(14):4259. https://doi.org/10.3390/s25144259
Chicago/Turabian StyleKau, Lih-Jen, Chin-Kun Tseng, and Ming-Xian Lee. 2025. "Perception-Based H.264/AVC Video Coding for Resource-Constrained and Low-Bit-Rate Applications" Sensors 25, no. 14: 4259. https://doi.org/10.3390/s25144259
APA StyleKau, L.-J., Tseng, C.-K., & Lee, M.-X. (2025). Perception-Based H.264/AVC Video Coding for Resource-Constrained and Low-Bit-Rate Applications. Sensors, 25(14), 4259. https://doi.org/10.3390/s25144259