Author Contributions
N.M.: Conceptualization, Methodology, Software, Investigation, Validation, Writing—original draft,. K.A.H.: Validation, Writing—original draft, Writing—review and editing. H.P.: Conceptualization, Methodology, Validation, Writing—review and editing, Supervision. All authors have read and agreed to the published version of the manuscript.
Figure 1.
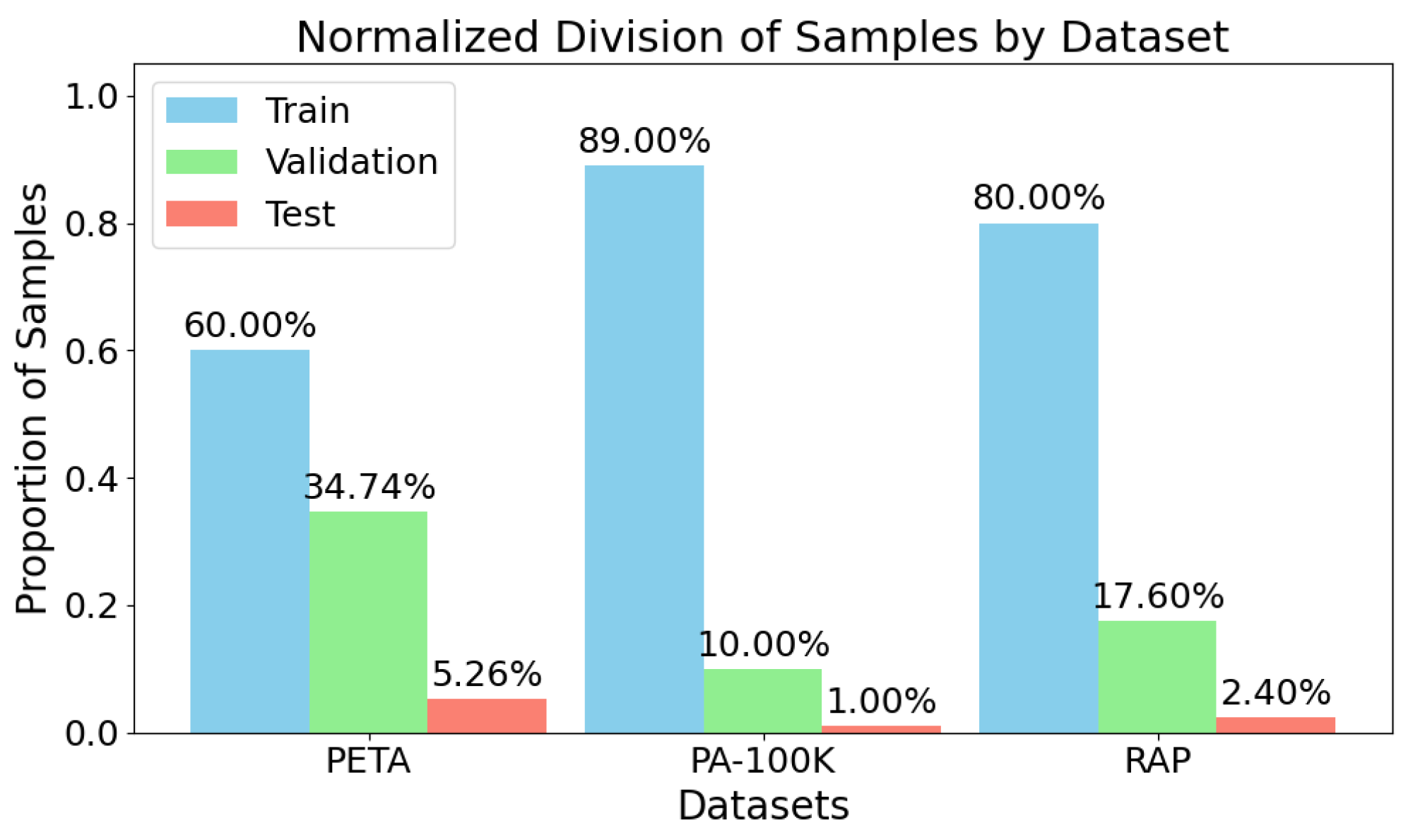
Dataset sample distribution across splits. Total number of images allocated to training, validation, and test sets for PETA, PA-100K, and RAP. All datasets used a consistent test size of 1000 images to ensure comparability.
Figure 1.
Dataset sample distribution across splits. Total number of images allocated to training, validation, and test sets for PETA, PA-100K, and RAP. All datasets used a consistent test size of 1000 images to ensure comparability.
Figure 2.
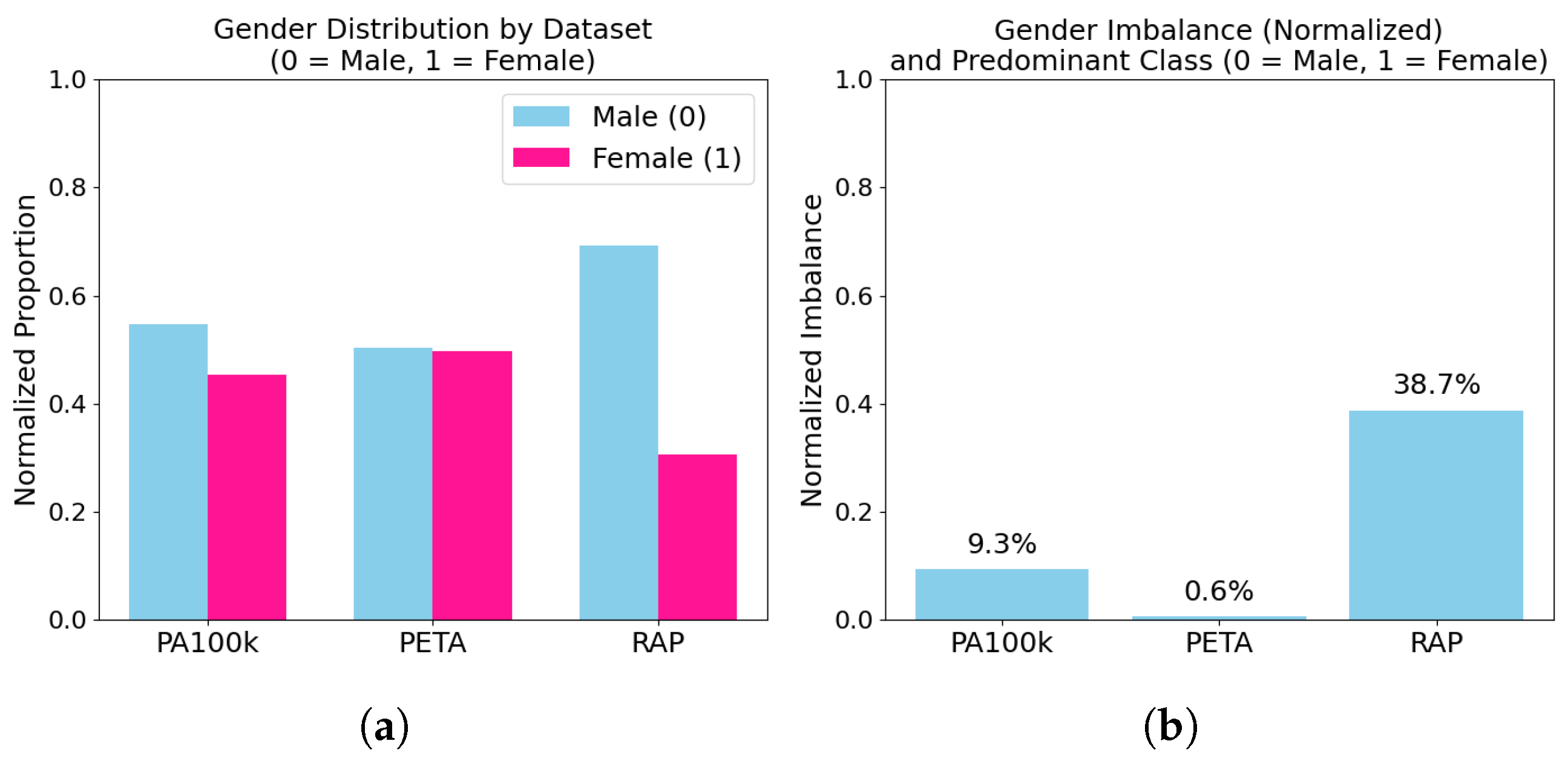
Gender distribution and imbalance visualization. (a): stacked bar plots showing the proportion of male vs. female samples in each dataset. (b): bar chart of absolute gender imbalance percentages. RAP exhibits strong male bias, while PETA is close to parity.
Figure 2.
Gender distribution and imbalance visualization. (a): stacked bar plots showing the proportion of male vs. female samples in each dataset. (b): bar chart of absolute gender imbalance percentages. RAP exhibits strong male bias, while PETA is close to parity.
Figure 3.
Experimental workflow for gender recognition under domain shift. Models were trained and evaluated across three datasets (PETA, PA-100K, and RAP), each characterized by different levels of visual complexity and label imbalance. The pipeline included intra- and cross-domain evaluations, yielding standard classification scores and robustness metrics (CDD, SD, and URM). This framework reveals not only how well models perform, but how reliably they generalize.
Figure 3.
Experimental workflow for gender recognition under domain shift. Models were trained and evaluated across three datasets (PETA, PA-100K, and RAP), each characterized by different levels of visual complexity and label imbalance. The pipeline included intra- and cross-domain evaluations, yielding standard classification scores and robustness metrics (CDD, SD, and URM). This framework reveals not only how well models perform, but how reliably they generalize.
Figure 4.
In
Figure 4, the green and red colors represent the model’s prediction outcomes. The areas highlighted in green indicate successful cases where the model made confident and correct predictions. In contrast, the red areas correspond to failure cases, where the model’s predictions were incorrect.
Figure 4.
In
Figure 4, the green and red colors represent the model’s prediction outcomes. The areas highlighted in green indicate successful cases where the model made confident and correct predictions. In contrast, the red areas correspond to failure cases, where the model’s predictions were incorrect.
Figure 5.
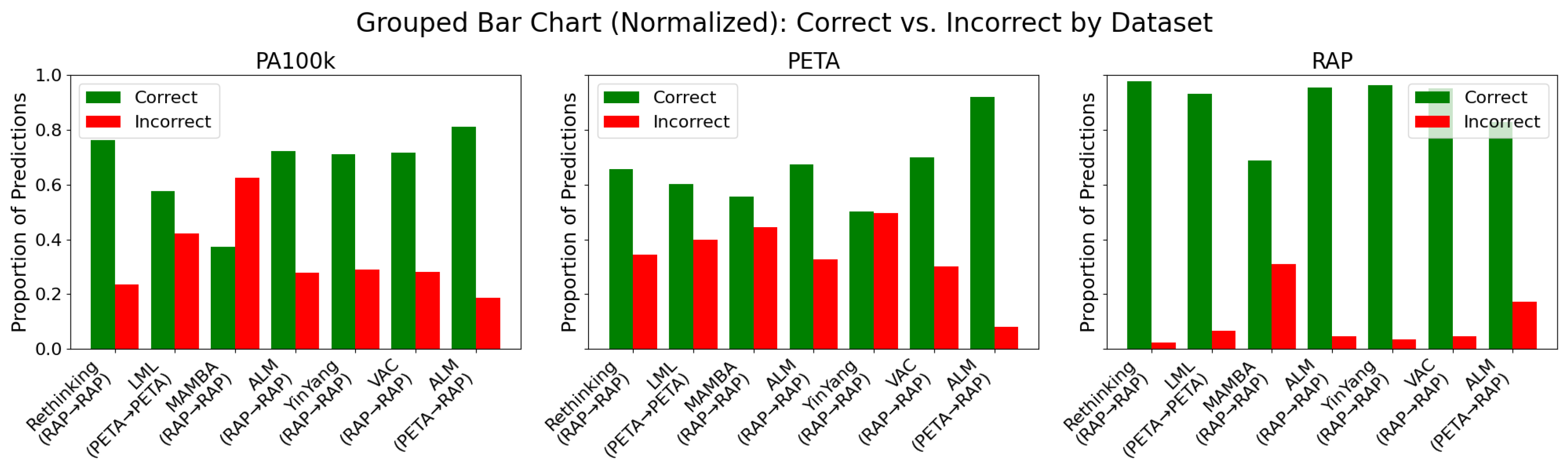
This figure is organized by dataset (PA100k, PETA, and RAP), providing a clear view of each model’s performance across different domains. Green bars represent correct classifications, while red bars indicate errors. Each subplot groups models based on their proportions of correct and incorrect predictions during testing, facilitating both intra- and cross-domain analysis. Notably, the RAP dataset demonstrated greater overall robustness, with the ALM model achieving the lowest error rate. In contrast, the PA100k and PETA datasets exhibited higher performance variability and error rates, highlighting the generalization challenges posed by domain shift.
Figure 5.
This figure is organized by dataset (PA100k, PETA, and RAP), providing a clear view of each model’s performance across different domains. Green bars represent correct classifications, while red bars indicate errors. Each subplot groups models based on their proportions of correct and incorrect predictions during testing, facilitating both intra- and cross-domain analysis. Notably, the RAP dataset demonstrated greater overall robustness, with the ALM model achieving the lowest error rate. In contrast, the PA100k and PETA datasets exhibited higher performance variability and error rates, highlighting the generalization challenges posed by domain shift.
Figure 6.
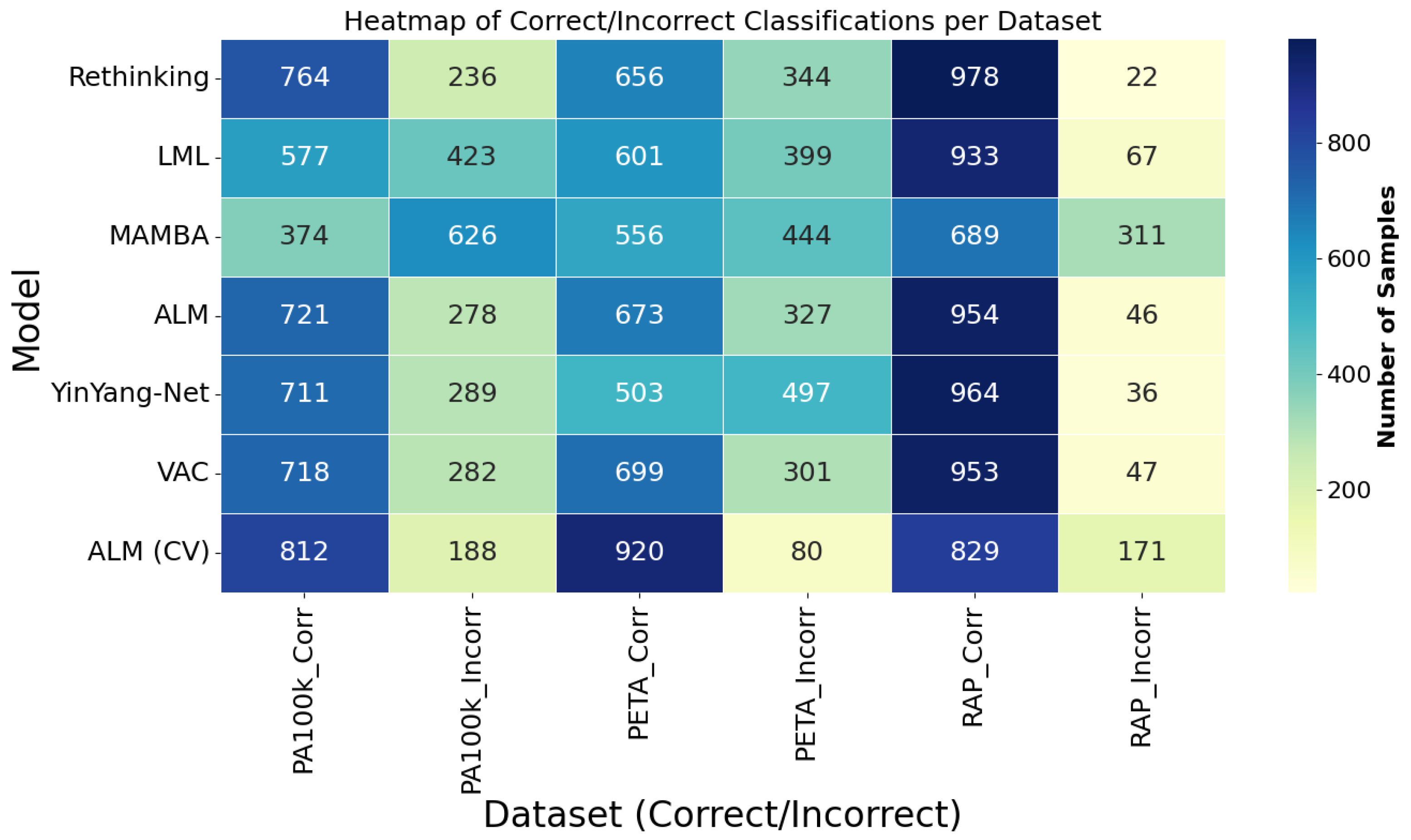
This figure presents a heatmap that provides a consolidated view focused on the models. Each row corresponds to a model, and the columns indicate the number of correct and incorrect predictions in each dataset. The color intensity allows for quick identification of models that stood out in performance. The ALM model, especially in the cross-validation (CV) version, stood out with the highest values of correct classifications and the lowest error rates, particularly on the PA100k and PETA datasets. This representation is especially useful for recognizing performance patterns and assessing the consistency of each model across different domains.
Figure 6.
This figure presents a heatmap that provides a consolidated view focused on the models. Each row corresponds to a model, and the columns indicate the number of correct and incorrect predictions in each dataset. The color intensity allows for quick identification of models that stood out in performance. The ALM model, especially in the cross-validation (CV) version, stood out with the highest values of correct classifications and the lowest error rates, particularly on the PA100k and PETA datasets. This representation is especially useful for recognizing performance patterns and assessing the consistency of each model across different domains.
Table 1.
Dataset partitioning. Division of the PETA, PA-100K, and RAP datasets into training, validation, and test subsets. Each dataset used a fixed test size of 1000 images to maintain evaluation consistency.
Table 1.
Dataset partitioning. Division of the PETA, PA-100K, and RAP datasets into training, validation, and test subsets. Each dataset used a fixed test size of 1000 images to maintain evaluation consistency.
| Dataset | Training | Validation | Test | Total Samples |
|---|
| PETA | 11,400 | 6600 | 1000 | 19,000 |
| PA-100K | 89,000 | 10,000 | 1000 | 100,000 |
| RAP | 33,268 | 7317 | 1000 | 41,585 |
Table 2.
Gender distribution across datasets. Absolute counts, class percentages, and gender imbalance scores for male and female categories in PETA, PA-100K, and RAP. Imbalance was calculated as the absolute difference between male and female proportions.
Table 2.
Gender distribution across datasets. Absolute counts, class percentages, and gender imbalance scores for male and female categories in PETA, PA-100K, and RAP. Imbalance was calculated as the absolute difference between male and female proportions.
| Dataset | Male | Female | Total | Male | Female | Imbalance |
|---|
| PA-100K | 54,664 | 45,336 | 100,000 | 54.66 | 45.34 | 9.32 |
| PETA | 9557 | 9443 | 19,000 | 50.30 | 49.70 | 0.60 |
| RAP | 28,759 | 12,701 | 41,460 | 69.37 | 30.63 | 38.74 |
Table 3.
Overview of evaluated models. Each model was benchmarked for binary gender classification. The table lists the base architecture, publication year, and key methodological contribution as described in the original source.
Table 3.
Overview of evaluated models. Each model was benchmarked for binary gender classification. The table lists the base architecture, publication year, and key methodological contribution as described in the original source.
| Model | Backbone | Year | Key Contribution |
|---|
| ALM [13] | BN-Inception | 2019 | Weakly supervised multi-scale attention maps for improved attribute localization. |
| VAC [12] | ResNet-50 | 2019 | Enforces spatial attention consistency to stabilize predictions under geometric transformations. |
| Rethinking [4] | Swin Transformer | 2021 | Revisits label-dependency structures in multi-attribute prediction. |
| YinYang-Net [16] | ResNet-50 | 2022 | Combines face and body cues via matrix-based attention fusion for gender recognition. |
| LML [14] | Swin Transformer | 2024 | Proposes label-balanced loss to mitigate prediction skew in multi-label classification. |
| MAMBA [17] | VisionMamba | 2024 | Introduces Mamba blocks for efficient modeling of long-range dependencies in attribute recognition. |
Table 4.
Comparison of domain robustness and divergence metrics.
Table 4.
Comparison of domain robustness and divergence metrics.
| Metric | Requires Access to Embeddings | Ease of Interpretation | Level of Analysis |
|---|
| MMD [23] | Yes (✓) | Moderate—requires understanding of RKHS and kernel embeddings | Feature space (mean discrepancy in high-dimensional space) |
| CORAL [22] | Yes (✓) | Moderate/High—based on covariance matrix alignment | Feature space (second-order statistics) |
| CMD [24] | Yes (✓) | Moderate—depends on interpretation of high-order moments | Feature space (moments up to order 5) |
| Wasserstein Distance [25] | Yes (✓) | Low—based on optimal transport theory; computationally complex | Probability distribution space (transport-based) |
| URM (Ours) | No (✗) | High—directly based on F1-score across domains | Model output level (cross-domain predictive stability) |
Table 5.
Training hyperparameters used across all experiments.
Table 5.
Training hyperparameters used across all experiments.
| Hyperparameter | Value/Setting |
|---|
| Optimizer | Adam (lr = 0.0001) |
| Batch size | 32 |
| Epochs | 60 |
| Early stopping | Patience = 10 epochs |
| Learning rate schedule | ReduceLROnPlateau (patience = 5, factor = 0.1) |
| Weight Decay | 0.0005 |
| Data augmentation | AutoAugment (p = 0.5), Resize, RandomHorizontalFlip, |
| | Normalize |
Table 6.
Performance of the different methods for the gender attribute across the PA100k, PETA, and RAP datasets.
Table 6.
Performance of the different methods for the gender attribute across the PA100k, PETA, and RAP datasets.
| Train | Val | Acc | Auc | Prec | Rec | F1 |
|---|
| PA | PA | 92.19 | 97.00 | 90.00 | 88.93 | 89.46 |
| PA | PE | 79.02 | 89.00 | 76.00 | 67.10 | 71.27 |
| PA | RA | 89.00 | 96.00 | 86.00 | 82.00 | 83.95 |
| PE | PA | 81.00 | 89.00 | 77.00 | 89.00 | 82.57 |
| PE | PE | 93.21 | 99.00 | 94.00 | 94.07 | 94.03 |
| PE | RAP | 79.00 | 91.00 | 72.24 | 65.10 | 68.48 |
| RA | PA | 79.80 | 90.00 | 70.00 | 91.00 | 79.13 |
| RA | PE | 74.90 | 85.00 | 75.00 | 90.50 | 82.02 |
| RA | RA | 96.12 | 99.00 | 96.00 | 95.92 | 95.96 |
| (a) Rethinking |
| Train | Val | Acc | Auc | Prec | Rec | F1 |
| PA | PA | 90.00 | 96.00 | 87.83 | 88.00 | 87.91 |
| PA | PE | 76.81 | 86.00 | 73.43 | 67.02 | 70.08 |
| PA | RA | 86.00 | 94.00 | 80.02 | 81.80 | 80.90 |
| PE | PA | 80.28 | 88.00 | 75.89 | 75.30 | 75.59 |
| PE | PE | 90.97 | 97.00 | 90.00 | 89.19 | 89.59 |
| PE | RA | 82.40 | 90.00 | 73.75 | 81.19 | 77.29 |
| RA | PA | 74.50 | 82.00 | 69.60 | 80.00 | 74.44 |
| RA | PE | 68.00 | 76.00 | 68.50 | 78.08 | 72.98 |
| RA | RA | 92.20 | 97.00 | 88.50 | 90.10 | 89.29 |
| (b) LML |
| Train | Val | Acc | Auc | Prec | Rec | F1 |
| PA | PA | 79.80 | 87.00 | 75.00 | 78.00 | 76.47 |
| PA | PE | 65.60 | 71.00 | 64.50 | 68.30 | 66.35 |
| PA | RA | 75.00 | 84.00 | 64.80 | 80.20 | 71.68 |
| PE | PA | 67.00 | 73.00 | 68.03 | 70.00 | 69.00 |
| PE | PE | 90.10 | 96.00 | 88.00 | 92.30 | 90.01 |
| PE | RA | 68.00 | 74.00 | 75.06 | 65.00 | 70.06 |
| RA | PA | 63.30 | 70.00 | 61.00 | 70.00 | 65.19 |
| RA | PE | 65.30 | 76.00 | 69.00 | 91.00 | 78.49 |
| RA | RA | 91.50 | 97.00 | 88.00 | 97.51 | 92.50 |
| (c) MAMBA |
| Train | Val | Acc | Auc | Prec | Rec | F1 |
| PA | PA | 90.50 | 96.00 | 81.82 | 89.58 | 85.52 |
| PA | PE | 76.66 | 85.00 | 75.00 | 71.63 | 73.28 |
| PA | RA | 87.99 | 94.00 | 84.62 | 79.74 | 82.11 |
| PE | PA | 77.75 | 84.00 | 72.73 | 62.54 | 67.25 |
| PE | PE | 93.30 | 98.00 | 100.00 | 95.24 | 97.56 |
| PE | RA | 83.18 | 89.00 | 92.21 | 86.07 | 89.02 |
| RA | PA | 74.02 | 86.00 | 81.14 | 89.74 | 85.22 |
| RA | PE | 74.18 | 86.00 | 67.95 | 88.35 | 76.82 |
| RA | RA | 96.00 | 99.00 | 99.69 | 99.42 | 99.54 |
| (d) ALM |
| Train | Val | Acc | Auc | Prec | Rec | F1 |
| PA | PA | 90.58 | 96.00 | 87.47 | 88.50 | 87.98 |
| PA | PE | 63.05 | 68.00 | 63.05 | 62.90 | 62.97 |
| PA | RA | 88.10 | 94.00 | 87.96 | 88.10 | 88.03 |
| PE | PA | 61.69 | 60.00 | 63.58 | 61.69 | 62.62 |
| PE | PE | 90.88 | 96.00 | 90.85 | 92.89 | 91.86 |
| PE | RA | 69.48 | 61.00 | 64.50 | 69.48 | 66.90 |
| RA | PA | 70.44 | 83.00 | 76.18 | 70.44 | 73.20 |
| RA | PE | 49.82 | 68.00 | 68.73 | 48.82 | 57.09 |
| RA | RA | 96.81 | 99.00 | 96.82 | 96.81 | 96.81 |
| (e) YinYang-Net |
| Train | Val | Acc | Auc | Prec | Rec | F1 |
| PA | PA | 87.89 | 94.00 | 94.00 | 84.59 | 89.05 |
| PA | PE | 76.72 | 86.00 | 81.23 | 62.78 | 70.82 |
| PA | RA | 88.93 | 94.00 | 88.92 | 88.93 | 88.92 |
| PE | PA | 75.86 | 84.00 | 79.27 | 64.43 | 71.08 |
| PE | PE | 79.96 | 92.00 | 79.23 | 75.50 | 77.32 |
| PE | RA | 84.18 | 91.00 | 84.47 | 84.18 | 84.32 |
| RA | PA | 76.00 | 83.00 | 76.86 | 76.09 | 76.46 |
| RA | PE | 69.89 | 83.00 | 73.86 | 69.89 | 71.82 |
| RA | RA | 95.69 | 99.00 | 95.69 | 95.69 | 95.69 |
| (f) VAC |
Table 7.
Unified Robustness Metric (URM) results for each evaluated model. VAC achieved the highest URM score, indicating the strongest generalization under domain shift, while YinYang-Net showed the lowest robustness. ACDD: average cross-domain degradation. SD: standard deviation of F1-scores. URM: unified robustness metric (higher is better).
Table 7.
Unified Robustness Metric (URM) results for each evaluated model. VAC achieved the highest URM score, indicating the strongest generalization under domain shift, while YinYang-Net showed the lowest robustness. ACDD: average cross-domain degradation. SD: standard deviation of F1-scores. URM: unified robustness metric (higher is better).
| Model | ACDD | SD (F1) | URM |
|---|
| VAC | 0.1078 | 8.65 | 0.8986 |
| LML | 0.1542 | 7.04 | 0.8709 |
| Rethinking | 0.1632 | 8.8 | 0.8594 |
| ALM | 0.1589 | 10.03 | 0.8587 |
| MAMBA | 0.1828 | 9.34 | 0.844 |
| YinYang-Net | 0.2546 | 14.02 | 0.7797 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}