1. Introduction
The exponential growth of the Internet of Things (IoT) is transforming both urban and rural ecosystems through an interconnected web of devices. These devices are often deployed in remote, inaccessible, or resource-constrained environments that require communication systems that prioritize long-range coverage, energy efficiency, and cost-effectiveness. This need has led to the rise of Low-Power Wide-Area Networks (LPWANs), among which the LoRaWAN (Long-Range Wide-Area Network) has emerged as a dominant protocol [
1]. The LoRaWAN has the ability to support battery-powered devices with lifetimes of several years. It also supports the capacity for wide-area communication over the unlicensed spectrum, which makes it especially suitable for several fields and applications, such as industry, healthcare, and environmental monitoring [
2].
These IoT applications present several operational constraints. Devices that are known as End Nodes (ENs), are often deployed in the contexts of forests, mountains, or wildlife to address the sector-specific challenges [
3]. In the agricultural domain, the LoRaWAN has demonstrated its potential through deployments in palm oil plantations in Malaysia, where traditional wireless systems struggled with signal degradation caused by dense foliage and terrain [
4]. In such settings, devices must communicate reliably while minimizing power consumption, as replacing batteries may be impractical or impossible [
5]. The LoRaWAN addresses this challenge through key configurable parameters like Spreading Factor (SF), Transmission Power (TP), and Bandwidth (BW), which determine the trade-off between data rate, range, and energy use. However, choosing the optimal configuration is highly sensitive to environmental dynamics and network density [
6]. Among other use cases, smart city initiatives have also adopted the LoRaWAN to power applications across diverse urban and indoor settings. In large geographical outdoors, extensive sensor networks using the LoRaWAN have enabled the real-time monitoring of parameters such as CO2 levels [
7], temperature, humidity, and motion [
8].
Despite its advantages, the performance of the LoRaWAN can be significantly influenced by various environmental conditions and deployment-specific characteristics. A major challenge in LoRaWAN planning lies in accurately predicting Path Loss (PL), which quantifies signal attenuation during transmission [
9]. Traditional PL models, such as Log-Distance or Okumura-Hata, typically rely on geometric parameters like distance and frequency [
1]. It has been observed that several environmental dynamics such as temperature, humidity, and barometric pressure are usually ignored as they all can substantially alter signal propagation. Therefore, there is a need to incorporate real-world variability into PL estimation methods. In addition, the Adaptive Data Rate (ADR) mechanism that is responsible for configuring transmission parameters such as Spreading Factor (SF), Bandwidth (BW), and Transmission Power (TP) usually use static, rule-based logic, which does not react well to environmental variability, node mobility, or non-stationary channel conditions [
10].
To address these limitations, researchers have used Machine Learning (ML) techniques to optimize LoRaWAN performance in areas such as power control, transmission rate, SF selection, and network scalability [
11]. ML’s data-driven nature allows it to capture non-linear dependencies and hidden patterns in wireless environments that rule-based algorithms often overlook. Supervised learning methods like Random Forests (RF) and Support Vector Machines (SVM) have also been found effective [
12]. Beyond supervised ML, researchers have also begun applying Reinforcement Learning (RL) for continuous adaptation in unpredictable environments. RL models enabled LoRaWAN devices to autonomously adjust communication strategies through trial-and-error learning [
13].
However, many studies remain environment-specific or target specific use cases, which limits the generalizability of the results. González-Palacio et al. [
1] highlighted the limitations of traditional models relying solely on distance and frequency, demonstrating the benefits of incorporating environmental variables, such as temperature and humidity, achieving an RMSE of 1.84 dB. Similarly, Anzum et al. [
4] improved path loss predictions in LoS and Non-LoS scenarios, achieving an RMSE of 2.74 dB in palm oil plantations. El Chall et al. [
14] evaluated path loss in urban and rural Lebanon, showing a reliable coverage of up to 45 km in rural settings. However, many studies remain environment-specific, which limits the generalizability of the results. Callebaut and Perre [
15] analyzed urban, forest, and coastal terrains, emphasizing signal diffraction challenges. Bianco et al. [
16] demonstrated the viability of LoRa for search and rescue operations but noted significant range reductions in harsh conditions. Other studies, such as those by Jawad et al. [
17] and Yang et al. [
18], applied machine learning and optimization techniques to enhance accuracy but focused solely on specific use cases. This study highlights the need for comprehensive models incorporating environmental factors while ensuring adaptability across varying conditions and network configurations.
This study highlights the need for comprehensive models incorporating environmental factors while ensuring adaptability across varying conditions and network configurations. This study also investigates the potential of boosting algorithms to improve path loss prediction accuracy in LoRaWANs by incorporating these environmental influences.
The objectives of this study include the following:
Address the identified gaps by employing five boosting ML algorithms—Adaptive Boosting (AdaBoost), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LGBM), GentleBoost (GB), and LogitBoost (LB)—for accurate path loss prediction in LoRaWAN environments.
Evaluate the effect of critical environmental parameters (e.g., temperature, relative humidity, barometric pressure, and PM2.5) on signal attenuation using permutation feature importance.
Benchmark the prediction performance of ML models against classical propagation models such as Log-Distance and Okumura-Hata.
Conduct a performance vs. complexity analysis by measuring training time, inference time, energy consumption, and model size to assess real-time deployment feasibility.
Apply Bayesian Optimization to fine-tune hyperparameters (e.g., learning rate and number of learning cycles) to improve model generalization and predictive accuracy.
This study used an on-premises and physical dataset incorporating various environmental variables, such as temperature, humidity, barometric pressure, and particulate matter. The performance metrics considered in this research were throughput, reduction in latency, jitter, and delay.
The rest of the paper is organized as follows:
Section 2 presents an overview of LoRaWAN Technology;
Section 3 provides a brief review of related work;
Section 4 details the adopted methodology, including data collection and description, PL modeling and transmission parameters, data preparation and preprocessing, boosting algorithms and hyperparameter optimization, cross-validation and evaluation metrics, feature importance assessment, and network simulation setup;
Section 5 presents the results and analysis;
Section 6 discusses the findings; and
Section 7 concludes the paper with future work.
2. LoRaWAN Architecture
The networking protocol LoRaWAN has been built upon LoRa’s physical layer, is specifically designed for scalable, low-power, and long-range communication in IoT systems [
12]. It features a star-of-stars topology that centralizes traffic from numerous battery-operated End Devices (EDs) through intermediary gateways to a core network server [
2]. This structure is optimized for asynchronous, uplink-heavy communication, which suits the nature of most IoT traffic [
19], where nodes report data periodically and frequently [
3].
The end devices in LoRaWANs communicate directly with nearby gateways using the LoRa modulation. These gateways, in turn, forward the packets without interpreting them to the network server using high-speed backhaul connections like Ethernet or cellular network [
12]. The network server handles crucial responsibilities such as data de-duplication, message scheduling, and ADR control. A unique feature of LoRaWANs is the classification of end devices into three operational device classes (A, B, and C), each class is designed for different energy and latency requirements [
20]:
Class A devices, the most energy-conservative, initiate uplinks and then briefly open two receive windows.
Class B devices synchronize with periodic beacons from gateways, allowing scheduled downlink slots.
Class C devices are always listening unless transmitting. While highly responsive, they consume significantly more power, making them suitable only for latency-sensitive tasks.
Table 1 presents a quick comparison of the different classes of end nodes in the LoRaWAN architecture.
LoRaWAN communication is generally uplink-dominant due to power-saving strategies, and downlinks are used sparingly to avoid congestion. This is especially because all downlink slots must compete with acknowledgments, ADR commands, and multicast messages [
23]. Therefore, scalability is a critical design goal for the LoRaWAN, but it is limited by its reliance on the ALOHA protocol for media access. In dense networks, this contention-based scheme leads to collisions and degraded Packet Delivery Ratios (PDR), particularly in Class A deployments [
24].
Furthermore, network performance depends on effective management of radio parameters such as SF, TP, BW, and Coding Rate (CR). These factors are mutually dependent; for example, a higher SF increases communication range but also leads to longer airtime and lower data throughput [
12]. However, a major research challenge with the LoRaWAN is packet collision in densely populated networks. Collisions can result in data loss when there are hundreds or thousands of network nodes [
25].
LoRaWAN Datasets
The LoRa research community has observed a lack of large-scale and well-documented datasets that can be used to study resource allocation, interference, collision issues, and the behavior of the LoRaWAN under various conditions [
26]. Ref. [
27] presented a large-scale LoRaWAN dataset comprising over 86 million transmissions collected from 390 sensors deployed across five floors in a multi-level building over two years. The dataset was subsampled to approximately 1 million balanced transmissions across 1560 sensor-gateway pairs, resulting in 909,414 samples. This dataset has supported both explanatory and predictive modeling of signal quality metrics (ESP, RSSI, and SNR), and represents one of the first real-world, long-term indoor LoRaWAN deployments beyond simulations or small-scale studies. Another study [
28] included three LPWAN datasets across rural and urban areas in Belgium. It comprises over 25,000 Sigfox messages from a rural commute area and 14,000 urban Sigfox messages from postal vehicles in Antwerp. Additionally, a LoRaWAN dataset was collected in the same urban area using OCTA-Connect modules. Each message includes GPS coordinates, RSSI, and base station data, enabling spatial correlation for signal strength analysis. Despite some GPS drift in fast-moving conditions, the dataset provided a valuable benchmark for LPWAN localization and performance evaluation in real-world settings.
However, most available datasets are small and often tailored to specific networks or applications as large-scale LoRaWAN deployments are rare. This limits their ability to conduct comprehensive studies across diverse scenarios. Furthermore, using the data gathered by the LoRaWAN for this study is challenging because it is not documented. Despite these drawbacks, the available datasets can be utilized to investigate a range of LoRaWAN network-related concerns [
2,
29]. For example, these datasets can be used to determine the traffic patterns of LoRaWAN end nodes, the effect of their resource allocation on the network, and the performance of the LoRaWAN itself.
3. Related Work
González-Palacio et al. [
1] discussed that previous research focused on developing path loss models primarily based on distance and frequency. However, path loss is also affected by variations in weather conditions. Thus, making predictions based solely on conventional and standard methodologies may not account for the significant environmental effects. Consequently, González-Palacio et al. [
30] produced a collection of LoRaWAN measurements in Medellín, Colombia. They recorded the path loss, distance, frequency, temperature, relative humidity, barometric pressure, particulate matter, and energy. Therefore, this dataset is highly useful for those aiming to design high-accuracy path loss prediction models. The dataset was implemented using model fittings, including Log-Distance and Multiple Linear Regression (MLR) models that accounted for environmental effects. This analysis demonstrated that incorporating these environmental variables enhanced path loss predictions, yielding an RMSE of 1.84 dB and an R
2 of 0.917.
Anzum et al. [
4] developed an accurate path loss prediction model for LoRaWAN communication at 433 MHz in foliage-rich environments, particularly within Malaysian palm oil plantations. Unlike traditional models that often fail to capture environmental obstructions, such as vegetation, this study introduces a multiwall empirical model adapted to Line-of-Sight (LoS), Non-Line-of-Sight (NLoS), and Obstructed Line-of-Sight (OLoS) scenarios. This study employed a deterministic modeling approach, utilizing empirical data fitting. The authors have collected real-world data from three palm oil plantations in Malaysia under three different propagation scenarios such as LoS, OLoS (one obstruction), and NLoS (two or more obstructions). They used 433 MHz LoRaWAN nodes, deployed at heights of 1.5 m and 3 m, and corresponding gateways, with signal measurements taken at multiple distances. Key parameters such as PL, RSSI, number and type of obstacles (foliage layers), transmission distance, and antenna height were evaluated. The authors enhanced classical models by incorporating a Vegetation Attenuation Factor (VAF) to account for foliage-induced signal degradation. The model demonstrated strong performance, with RMSE values of 2.23 dB, 2.51 dB, and 2.74 dB noted across LoS, OLoS, and NLoS scenarios, respectively.
El Chall et al. [
14] developed path loss models for LoRaWAN communications and evaluated them using popular empirical models. Real measurements were taken in both indoor and outdoor settings at urban and rural sites in Lebanon to assess the coverage and performance of the LoRaWAN implementation. The findings demonstrate the accuracy and ease of use of the suggested path loss models in Lebanon and other comparable settings. Urban and rural areas returned coverage ranges of up to 8 km and 45 km, respectively.
Callebaut and Perre [
15] utilized urban, forest, and coastal environments to assess coverage and path loss. Diffraction effects cause greater signal loss than a traditional star-of-stars topology because the terminals are usually positioned at low altitudes. They also considered censored data to estimate realistic path loss parameters. Because 80% of the transmitted packets were successfully received at approximately 200 m, the packet error ratio was calculated using the expected path loss characteristics to assess the performance of the point-to-point networks. In addition, a range of more than 4 km was observed in the LoS situation. Even with heavily forested terrain and complex urban radio propagation, a maximum range of 1 km has been attained.
Bianco et al. [
16] presented and examined a LoRa-based system for search and rescue operations. Measurements were used to derive radio path loss models for body-worn LoRa devices in harsh mountain environments. Due to its extended radio range, researchers have found that Low-Power Wide-Area Network (LPWAN) technology is highly promising for search and rescue applications. Even though the range of LoRa drops from kilometers to hundreds of meters in the testing environment. The researchers determined that at least 50% of the transmitted packets can be received at distances roughly five times greater than with gold standard technologies, such as ARVA.
Masek et al. [
26] presented measurements of various operational aspects of LoRaWAN communication technology collected in Brno, Czech Republic. This dataset aims to assist researchers who lack access to LoRaWAN devices. It provided data collected from 303 outdoor test locations. These locations are transmitted to up to 20 gateways operating in the 868 MHz band. The data encompassed a range of urban landscapes, enabling comparison and analysis across diverse environments. Furthermore, they developed a prototype with a Microchip RN2483 LPWAN LoRaWAN technology transceiver module for field measurements. Researchers have demonstrated the relationship between the Received Signal Strength Indicator (RSSI) and the Signal-to-Noise Ratio (SNR) and the distance from the closest gateway.
Using the MATLAB curve-fitting tool, Jawad et al. [
17] proposed two novel path loss models for a ZigBee WSN in a farm field. Polynomial and exponential functions were the foundation for developing the two path loss models. Both functions were merged with Particle Swarm Optimization (PSO) to determine the ideal coefficients of the functions that would produce the POLY-PSO algorithms. The obtained values surpassed those of earlier state-of-the-art PL models. The findings demonstrate that the hybrid EXP-PSO and POLY-PSO models significantly increased the regression line’s coefficient of determination, with the Mean Absolute Error (MAE) for EXP-PSO and POLY-PSO being 1.6 and 2.7 dBm, respectively.
Yang et al. [
18] proposed a feature selection strategy to improve the accuracy and generalization of ML approaches for predicting path loss and delay spread in air-to-ground millimeter-wave channels. The researchers employed transfer learning techniques to predict path loss with little data. They compared the Okumura–Hata and COST-231 Hata models with the suggested methods for path loss prediction. The lognormal distribution is used as a comparison or baseline model to predict the delay spread. The novel techniques, therefore, had lower RMSE values than contrast models based on data produced by the ray-tracing software.
Aernouts et al. [
28] presented a well-documented dataset covering urban and rural areas in Belgium. The study captured LoRaWAN transmissions using GPS-tagged mobile devices over Proximus’s national LoRaWAN network. Data included over 14,000 transmissions in urban Antwerp and 25,000 in a rural corridor between Antwerp and Ghent, recorded between November 2017 and February 2018. The authors have analyzed signal strength using parameters such as RSSI across various terrains using Proximus’s nationwide LoRaWAN network. Devices sent GPS-tagged messages at regular intervals, allowing for precise correlation between signal quality and location. The basic KNN fingerprint algorithm has been used to determine the optimal K value for each set. The rural Sigfox dataset achieved the lowest mean location error of 214.58 m, and the urban Sigfox dataset had a mean error of 688.97 m. For the urban LoRaWAN dataset, the mean error was 398.4 m. These results demonstrated a significant impact of environmental complexity on localization accuracy.
A summary of related work is presented in
Table 2.
As presented in
Table 2, the measurement and path loss modeling studies for the LoRaWAN mainly focused on distance, frequency, and antenna height. However, previous studies have shown that environmental factors such as temperature, relative humidity, barometric pressure, and particulate matter influence path loss variability. These environmental effects have not been measured in the available LoRaWAN datasets. Therefore, this research adopts a comprehensive LoRaWAN measurement study conducted over four months in an urban environment in Medellín, Colombia, by González-Palacio et al. [
1].
5. Results and Analysis
This study conducted comprehensive evaluations to assess the performance and practical implications of boosting algorithms. The analysis encompassed five key dimensions: (1) network performance evaluation, including throughput, latency, jitter, and delay; (2) performance vs. complexity trade-off by comparing each model in terms of training time, inference time, and model size; (3) energy efficiency assessment, measured by the number of alive nodes remaining after network simulation; (4) feature impact analysis using permutation importance to determine which environmental parameter (e.g., temperature, humidity, barometric pressure, PM2.5) most significantly affected path loss; and (5) predictive accuracy assessment, using model accuracy, RMSE, MAE, MSE, and R2. These evaluations provided a multi-dimensional understanding of each algorithm’s strengths, weaknesses, and suitability for real-world deployment in LoRaWAN environments.
5.1. Network Performance Analysis
The network performance of each boosting model was evaluated across four key metrics: throughput, latency, jitter, and end-to-end delay, measured per node.
Table 4 presents a comparative analysis of the average performance demonstrated by each model across all evaluated metrics. The results were collected from a simulation evaluating each model under identical conditions with 500 nodes.
LightGBM demonstrated strong efficiency in handling data. It recorded the highest average throughput among all models. GentleBoost showed slightly lower throughput but still outperformed AdaBoost, LogitBoost, and XGBoost. AdaBoost achieved the lowest average latency. It responded faster than the other models in message delivery. GentleBoost had almost the same latency. Jitter was lowest in AdaBoost and GentleBoost. These models maintained more consistent transmission intervals. XGBoost had the highest jitter. It showed more variation in packet delivery times. Delay values were similar across all models. AdaBoost recorded the lowest delay, showing the best performance in minimizing end-to-end transmission time.
5.2. Performance vs. Complexity Analysis
A comprehensive performance versus complexity analysis was conducted to evaluate the practical deployment viability of the boosting models in LoRaWAN scenarios. This analysis considers multiple dimensions of computational cost, including training time, inference time, energy consumption, and model size, in addition to model accuracy.
Table 5 summarizes these metrics across all five models. The AdaBoost model exhibited the highest training time, at 492.60 s, and the highest inference time, at 2.75 milliseconds. Additionally, it required 202.68 MB of memory. XGBoost, on the other hand, offered the highest accuracy of 89.10%. It demonstrated better efficiency than AdaBoost, with a training time of 297.02 s and an inference time of 1.03 milliseconds. However, its model size reached 250.09 MB.
LightGBM achieved a near-peak accuracy of 89.17% and outperformed others in computational efficiency. It recorded the lowest training time, 190.36 s, and the shortest inference time, 0.90 milliseconds. The model size, however, was the largest, at 291.89 MB, which may pose storage concerns on memory-constrained devices. The GentleBoost model achieved an accuracy of 88.85%, with moderate training times (316.14 s) and inference times (2.31 milliseconds). The model size was 222.89 MB. These results suggest a balanced trade-off between performance and complexity. LogitBoost produced 88.69% accuracy with a training time of 281.94 s and an inference time of 1.51 milliseconds. It had the smallest model size, 176.29 MB.
5.3. Energy Efficiency Analysis
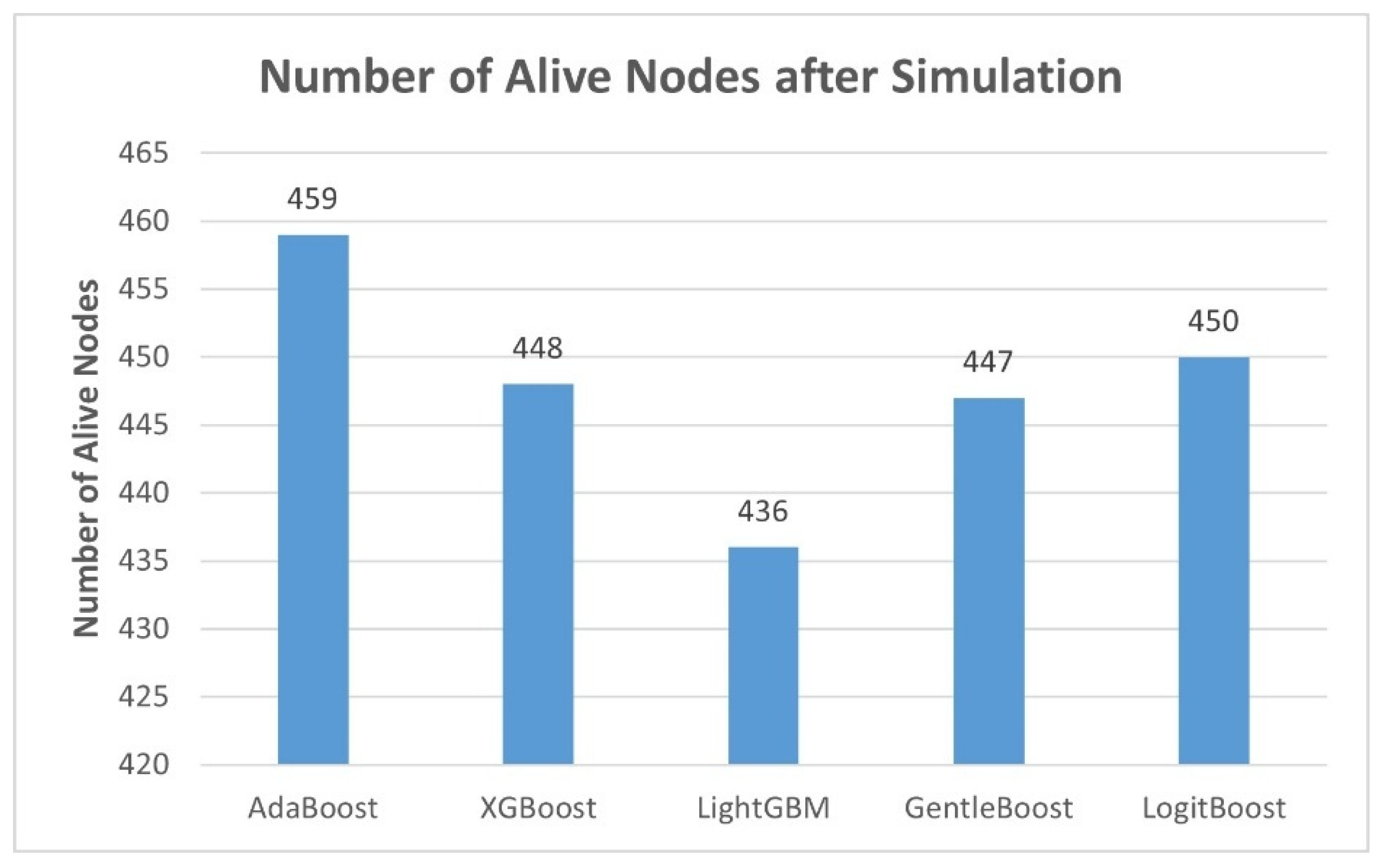
Figure 1 illustrates the energy efficiency analysis across the evaluated boosting models by showing the number of alive nodes remaining after the simulation. In energy-constrained LoRaWAN environments, a higher number of alive nodes directly reflects lower energy depletion during communication processes and better overall energy optimization of the model. AdaBoost demonstrates the highest energy efficiency among all models, retaining 459 alive nodes. LogitBoost and XGBoost follow closely, with 450 and 448 alive nodes, respectively, while GentleBoost maintains 447. LightGBM results in the fewest alive nodes at 436.
5.4. Feature Impact Analysis Using Permutation Importance
A permutation importance approach was utilized to evaluate the relative contribution of environmental features in influencing path loss predictions across all boosting models. This method quantifies the importance of each feature by measuring the decrease in model performance when that feature’s values are randomly shuffled, thereby breaking the relationship between the feature and the target variable.
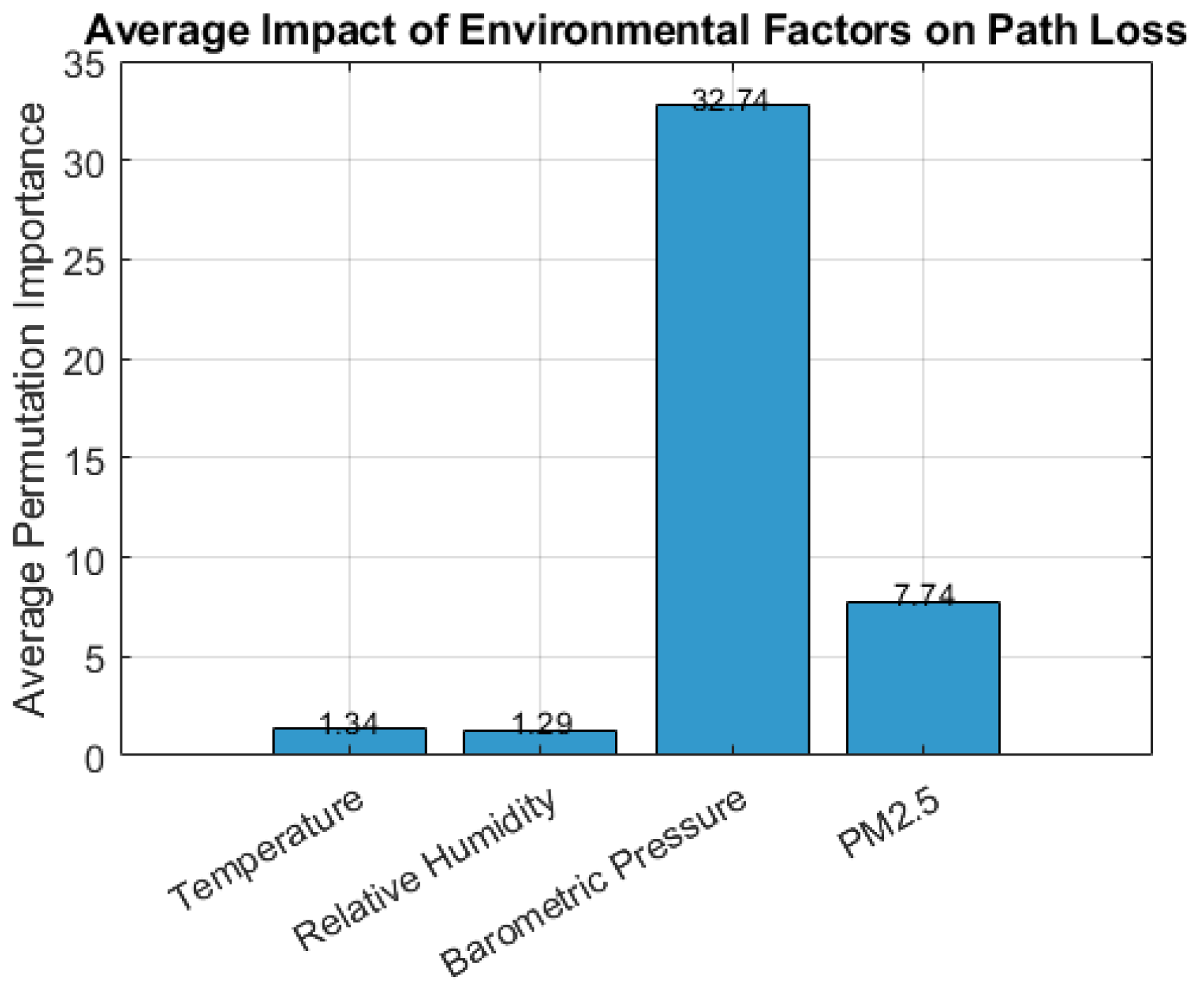
Figure 2 presents the average permutation importance scores aggregated across all five boosting models. Among the features analyzed, barometric pressure exhibited the highest influence on path loss, with an average impact score of 32.74. This indicates that variations in barometric pressure contribute most substantially to fluctuations in signal attenuation.
PM2.5 concentration followed with a moderate average importance of 7.74, implying a secondary but notable influence on signal degradation. In contrast, temperature and relative humidity showed lower average impact values of 1.34 and 1.29, respectively, suggesting a relatively minimal effect on path loss in the examined urban LoRaWAN scenario. These findings reinforce that barometric conditions and particulate matter levels are critical environmental factors of LoRaWAN.
5.5. PL Prediction Accuracy Assessment of Boosting ML Models
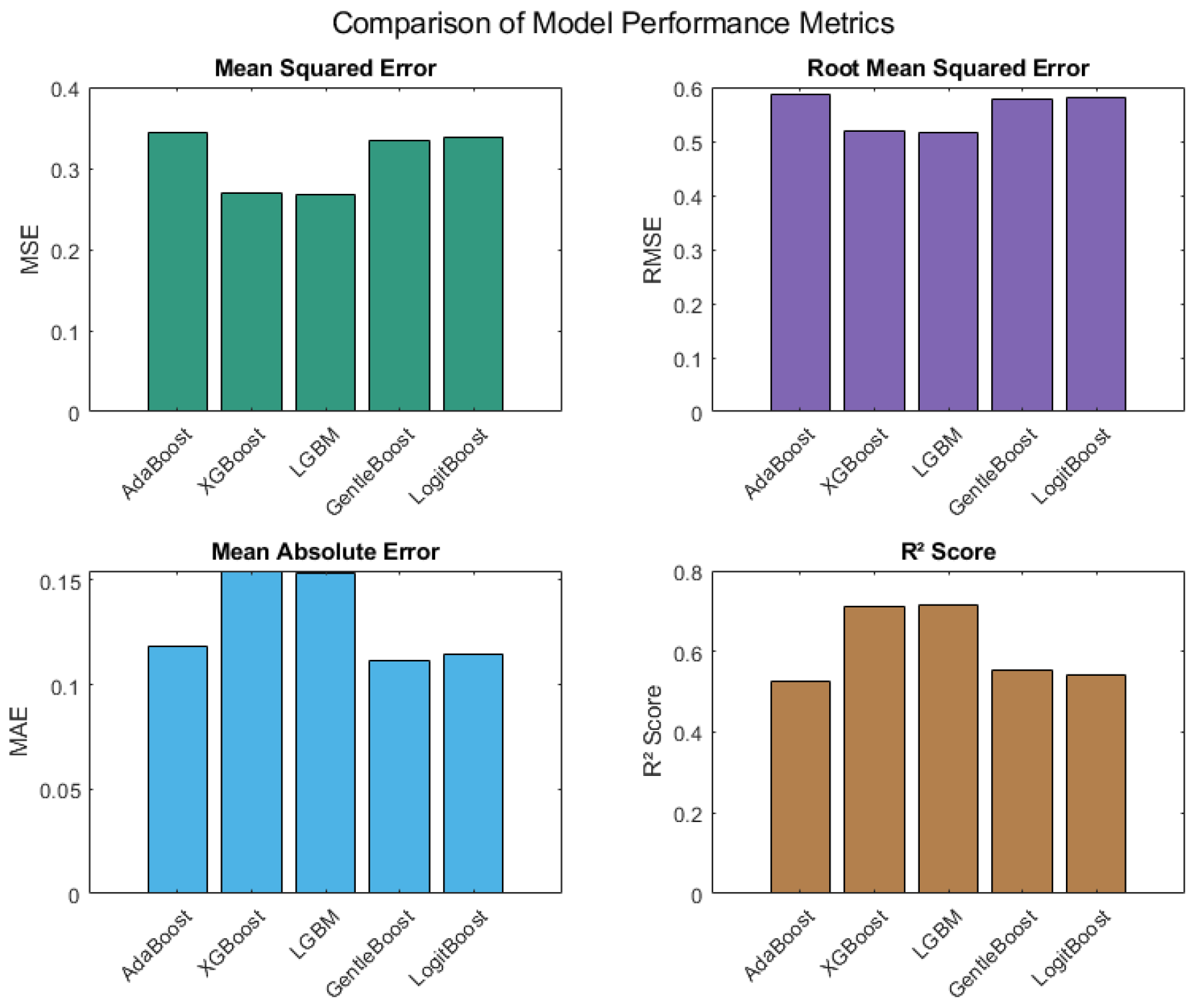
Figure 3 compares the five boosting models based on four key predictive performance metrics: MSE, RMSE, MAE, and R
2. The LightGBM model attained the lowest MSE value of 0.2669 and the lowest RMSE of 0.5166, indicating superior error minimization. It also achieved the highest R
2 score of 0.7151, suggesting the strongest ability to explain variance in the predicted path loss. XGBoost followed with an MSE of 0.2694, RMSE of 0.5190, and R
2 of 0.7097. GentleBoost and LogitBoost returned RMSEs of 0.5778 and 0.5820, respectively, and R
2 scores of 0.5541 and 0.5411. AdaBoost showed relatively higher MSE and RMSE values (0.3442 and 0.5867, respectively) and a lower R
2 of 0.5261 compared to LightGBM and XGBoost. However, AdaBoost achieved the lowest MAE value (0.1185), reflecting good average error magnitude. These findings, illustrated in
Figure 3, offer a comprehensive quantitative basis for comparing each model’s predictive performance under the tested conditions.
5.6. PL Prediction Accuracy: Boosting vs. Other ML Models
RMSE and R
2 score metrics were used to compare the predictive accuracy of the five boosting algorithms employed in this study with those of ML models reported in existing studies.
Table 6 presents a side-by-side comparison that includes Multiple Linear Regression (MLR) from González-Palacio et al. [
1], as well as Artificial Neural Networks (ANN), Random Forests (RF), and Support Vector Regression (SVR) from González-Palacio et al. [
30].
Table 5 shows that the RF model achieved the lowest RMSE of 1.566 dB and the highest R
2 of 0.9389 among the referenced models. Similarly, SVR and ANN also recorded competitive RMSE values of 1.626 dB and 1.613 dB, respectively, with corresponding R
2 scores of 0.9342 and 0.935.
In this study, boosting-based models demonstrated notably improved performance in terms of prediction accuracy. Specifically, LightGBM and XGBoost achieved the lowest RMSE values of 0.5166 dB and 0.5190 dB, respectively, surpassing all prior models in error minimization. These were followed by LogitBoost (0.5820 dB), GentleBoost (0.5778 dB), and AdaBoost (0.5867 dB). Regarding the R2 score, XGBoost and LightGBM produced the highest values among the boosting models, with values of 0.7097 and 0.7151, respectively. These findings indicate a meaningful reduction in prediction error. However, this observed improvement in RMSE among the boosting models is accompanied by a notable decrease in R2 compared to traditional models such as RF and SVR. This divergence reflects a critical trade-off between minimizing point-wise error and explaining overall variance in predictive modeling. RMSE, being a scale-dependent metric, captures the average magnitude of residuals but does not assess how well the model accounts for variability in the target variable.
Conversely, R
2 measures the proportion of variance in the observed data explained by the model, making it sensitive to both dispersion and model structure. Boosting algorithms, such as AdaBoost, LightGBM, and XGBoost, are specifically designed to iteratively reduce errors by optimizing loss functions, including squared error. As a result, these models often achieve superior RMSE performance. However, they may not yield high R
2 scores if the variance structure of the dataset is not effectively captured. This behavior is well-documented in the ensemble learning literature, where boosting emphasizes bias reduction at the expense of variance explanation under certain conditions [
34,
35,
36].
The boosting models succeeded in reducing absolute prediction errors. Still, they failed to match the R
2 levels observed in models like RF, which are known for capturing complex variance through bagging and feature randomness [
35]. The discrepancy between RMSE and R
2 thus highlights an important modeling insight: boosting techniques are optimal when the primary objective is precise prediction. At the same time, models with higher R
2 are better suited for interpretability and variance attribution [
37].
5.7. PL Prediction Accuracy: Boosting vs. Theoretical Models
The Log-Distance and Okumura-Hata theoretical models are compared with boosting ML models in predicting PL. These models are widely adopted in wireless communication studies for estimating signal attenuation based on distance and environmental parameters. The Log-Distance model is commonly used in empirical radio propagation scenarios, offering flexibility across different terrain types. In contrast, the Okumura-Hata model is a well-established empirical model specifically designed for urban environments, taking into account factors such as frequency, base station height, and distance.
Table 7 presents the RMSE and R
2 Scores for each of the five boosting algorithms evaluated in this study, compared to the Log-Distance and Okumura-Hata theoretical models.
The RMSE values for the boosting models are significantly lower than those of the theoretical models. The theoretical models exhibited relatively high R
2 scores, which can be attributed to their inherent structure, which closely aligns with the large-scale path loss trends in idealized conditions. Models like Log-Distance and Okumura-Hata are structured to fit large-scale signal trends using log-distance formulations [
38], which closely match the global variance patterns present in the dataset. As a result, they explain a larger portion of the variance, leading to a higher R
2. However, these models overlook local signal fluctuations caused by environmental factors such as humidity, temperature, and particle density. This leads to higher absolute errors, reflected in their poor RMSE. Boosting models capture these fine-grained variations through feature learning [
34,
36], which significantly reduces RMSE but may not necessarily maximize R
2, as the learned variance is more distributed and less aligned with the dominant global trend.
These results highlight the improved predictive precision of boosting ML approaches in modeling complex environmental conditions that affect signal propagation in LoRaWAN.
6. Discussion
This study extensively evaluated boosting ML models to assess their effectiveness in predicting path loss in LoRaWAN environments under realistic environmental conditions. The boosting ML models were thoroughly benchmarked using RMSE, R2, MAE, and MSE alongside network performance and computational complexity indicators. LightGBM achieved the lowest RMSE (0.5166) and highest R2 (0.7151). Furthermore, LightGBM not only demonstrated the highest throughput and lowest inference time but also required the least training time among the ensembles. This makes it particularly attractive for real-time and resource-constrained deployments. However, this advantage came at the cost of a slight compromise in energy efficiency, as evidenced by the lower number (436) of alive nodes after simulation.
LightGBM consistently outperformed the other boosting models in prediction and computational metrics due to its leaf-wise tree growth strategy, histogram-based decision tree learning, and Exclusive Feature Bundling (EFB). Unlike traditional boosting models, such as AdaBoost or XGBoost, which grow trees level-wise, LightGBM grows trees leaf-wise, selecting the leaf with the maximum split gain to grow [
32]. This strategy enables the model to converge more quickly and achieve lower loss with fewer iterations, thereby directly improving PL prediction accuracy, as observed in this study. Furthermore, LightGBM applies a Gradient-Based One-Side Sampling (GOSS) technique, which retains instances with large gradients and randomly samples those with slight gradients. This approach significantly reduces the number of data points used in training while preserving accuracy, thereby reducing training time and inference delay [
39,
40]. The histogram-based algorithm used in LightGBM further contributes to speed by discretizing continuous feature values into bins. This significantly reduces memory usage and computation time compared to the greedy algorithms used in models like XGBoost [
39,
41]. Additionally, EFB helps address sparse features by bundling mutually exclusive features into a single feature, thereby significantly reducing dimensionality and enhancing performance [
39].
AdaBoost achieved the highest number of alive nodes (459), indicating strong energy-aware performance, and maintained a consistent throughput with the lowest average delay fluctuation. However, it exhibited the longest training time (492.6 s) and the lowest throughput. XGBoost offered a balance. It shows lower training time than AdaBoost, moderate latency, and good performance in network metrics. Hence, it strikes a middle ground between LightGBM speed and AdaBoost’s energy preservation. Performance vs. complexity analysis further highlighted that models with faster inference times (LightGBM and XGBoost) had increased memory consumption and energy trade-offs.
Permutation importance analysis consistently revealed barometric pressure as the most dominant factor influencing PL in LoRaWANs. This observation aligns with physical propagation principles and validates the inclusion of environmental variability in ML-based PL modeling. Unlike theoretical models such as Log-Distance and Okumura-Hata, which rely on static propagation conditions, boosting models effectively learn from dynamically varying sensor inputs.
Table 6 confirms that both theoretical models produced RMSEs significantly above 2.5 dB, compared to sub-0.6 dB RMSEs achieved by ML models. When compared to ML models proposed in prior works, such as ANN, RF, and SVR, the boosting models in this study demonstrated superior RMSEs and comparable R
2 values, despite relying on a leaner set of input features and requiring less computational overhead. This reflects a more practical application potential for network scenarios requiring prediction precision and efficiency.
The principal outcomes derived from this study are summarized as follows:
LightGBM emerged as the most accurate and computationally efficient model, with the lowest RMSE (0.5166), highest throughput (151.54), and fastest inference (0.90 ms).
AdaBoost offered exceptional energy efficiency, maintaining the highest number of alive nodes (459), but it incurred higher training costs and longer inference delays.
Performance vs. complexity analysis confirmed that lower inference times often came with increased memory and energy costs.
Permutation importance confirmed barometric pressure as the dominant environmental factor affecting path loss, far surpassing humidity, temperature, and PM2.5.
Boosting models substantially outperformed theoretical models (Log-Distance, Okumura-Hata) and provided better accuracy than the ANN, RF, and SVR models reported in the literature.
7. Conclusions
This study comprehensively evaluated the effectiveness of boosting ML models for path loss prediction in the LoRaWAN using real-world environmental data. The analysis incorporated a multidimensional assessment, including predictive accuracy, network performance, computational complexity, energy efficiency, and environmental factor sensitivity, as determined through permutation importance.
LightGBM consistently outperformed other models in predictive performance and computational efficiency among the evaluated models. It achieved the lowest MSE, RMSE, and MAE while recording the highest R2 score, demonstrating superior generalization capabilities. Furthermore, LightGBM exhibited the fastest inference time and lowest training time. Comparative analysis with RF, ANN, MLR, SVR, and theoretical models Log-Distance and Okumura-Hata revealed that the boosting-based ML models, particularly LightGBM and XGBoost, significantly enhance prediction accuracy. The permutation importance analysis further identified barometric pressure and PM2.5 as the most influential environmental features affecting signal attenuation.
This study highlights the potential of boosting ML algorithms to provide robust, efficient, and adaptive solutions for path loss estimation in dynamic IoT environments. Future work will broaden the experimental scope by exploring neural network architectures, such as Long Short-Term Memory (LSTM) for time-series path loss prediction to provide a comparative perspective against the boosting models. Furthermore, the models will be validated on multi-regional datasets containing diverse environmental conditions, such as coastal, desert, and rural settings.




{kind=link}
{kind=link}
{kind=link}