
Rice Canopy Disease and Pest Identification Based on Improved YOLOv5 and UAV Images




Abstract
1. Introduction
2. Materials and Methods
2.1. Image Collection of Rice Diseases and Pests
2.2. Dataset Construction
3. Models and Training
3.1. YOLOv5 Algorithm
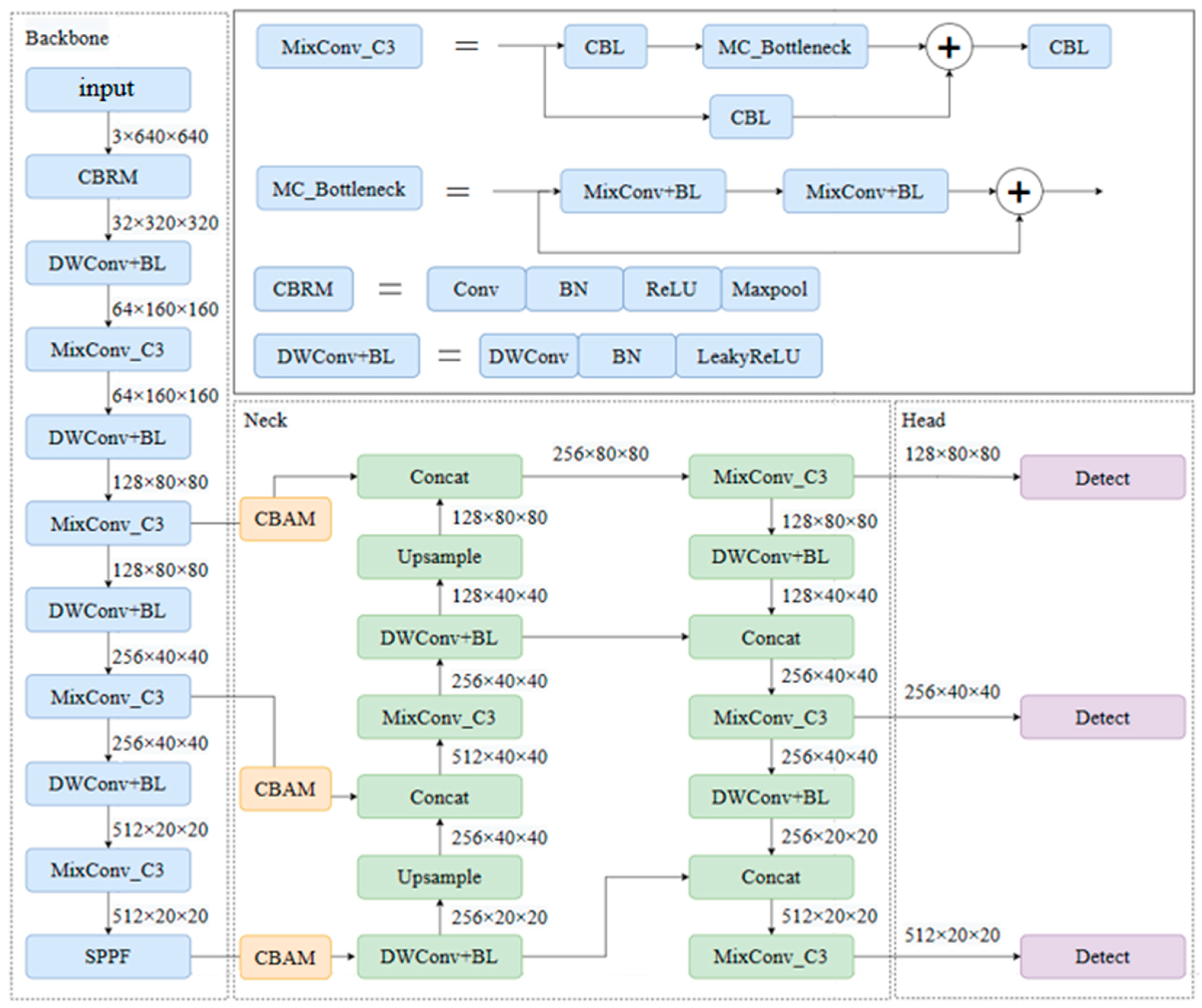
3.2. Improving YOLOv5 Algorithm
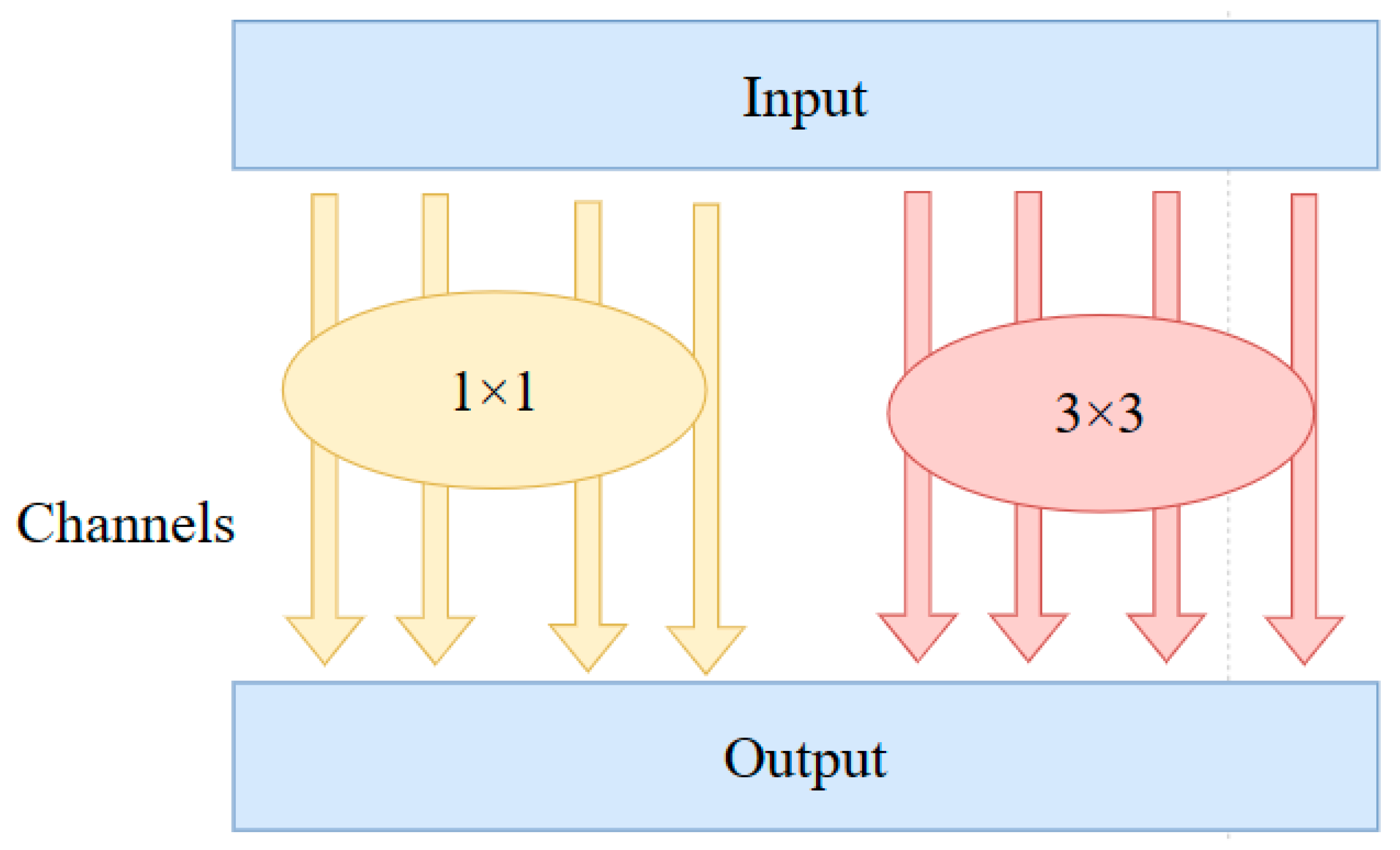
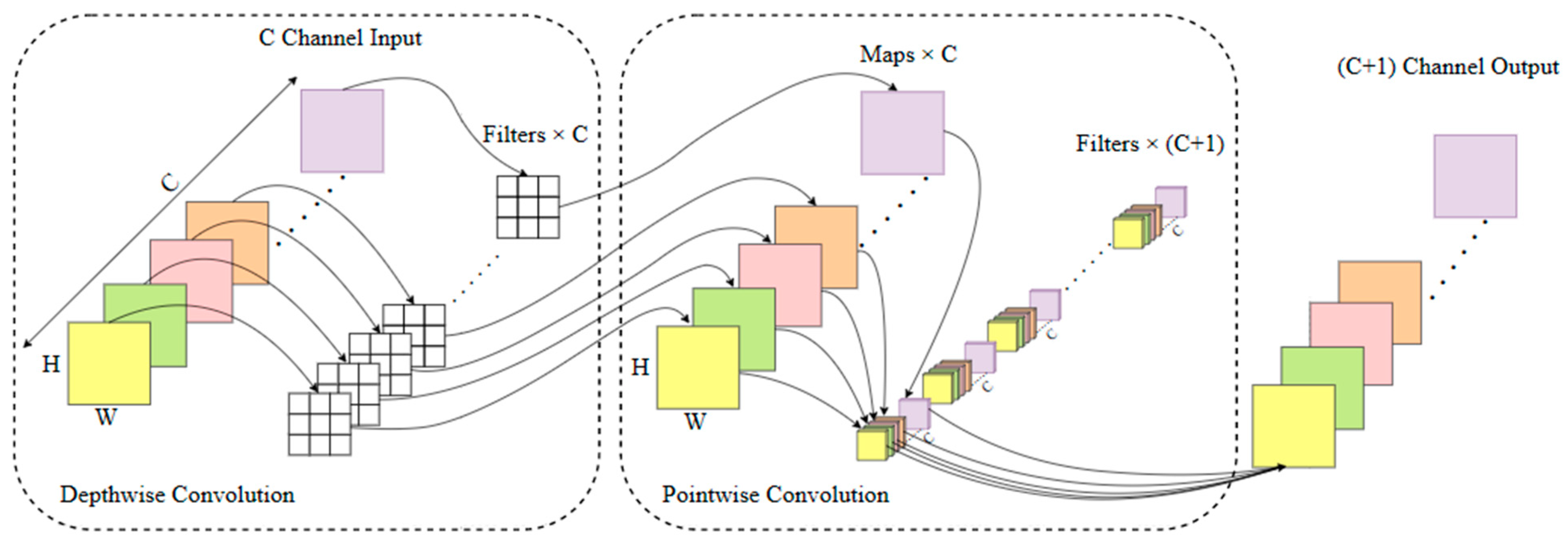
- Replace the first layer in the original YOLOv5 backbone network with CBRM. CBR includes normal convolution (Conv), Batch Normalization (BN), and the activation function (ReLU), where M represents the MaxPooling operation to reduce the feature map dimension. The MaxPooling operation achieves feature dimensionality reduction and position shift invariance by taking the maximum value within a window. Replace the normal convolution module in C3 with MixConv, which automatically selects the convolution kernel size most suitable for different feature sizes to enhance feature extraction ability and improve algorithm performance. Replace the downsampling module with separable convolution. Compared to traditional convolution operations, depthwise separable convolution consists of depthwise convolution and pointwise convolution, greatly reducing the model’s parameter and computation complexity.
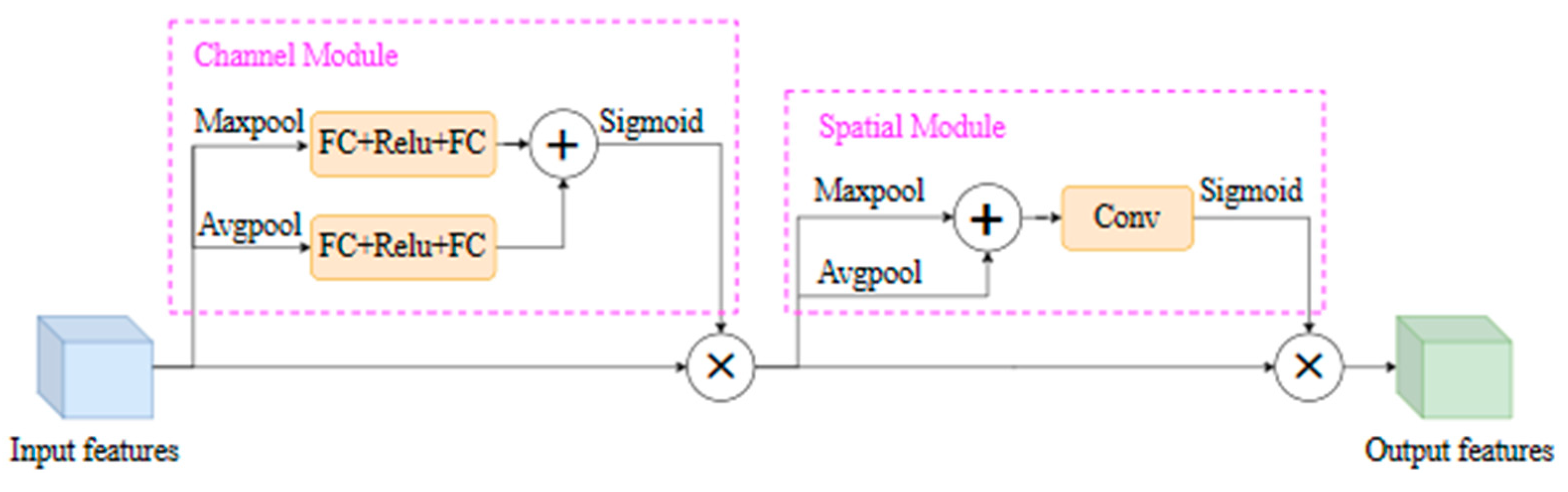
- Add the Convolutional Block Attention Module (CBAM) to the results of the three feature layers’ outputs by the main feature extraction network. By combining the channel attention mechanism and spatial attention mechanism, the CBAM can adaptively weight the feature maps, enhance effective feature information extraction, compress useless feature information, and improve the quality of feature representation.
- Update the bounding box information of YOLOv5 through the k-means clustering algorithm to enable the network to learn better detectors, avoiding blind learning of target sizes and positions during the training process and improving the model’s detection performance.
- Replace the original YOLOv5 loss function with the ComputeLossOTA, which comprehensively considers the existence, position, and classification accuracy of targets and helps the model continuously adjust its parameters. It provides better robustness for targets of different sizes, shapes, and categories, enabling better adaptation to complex scenarios and different target categories.
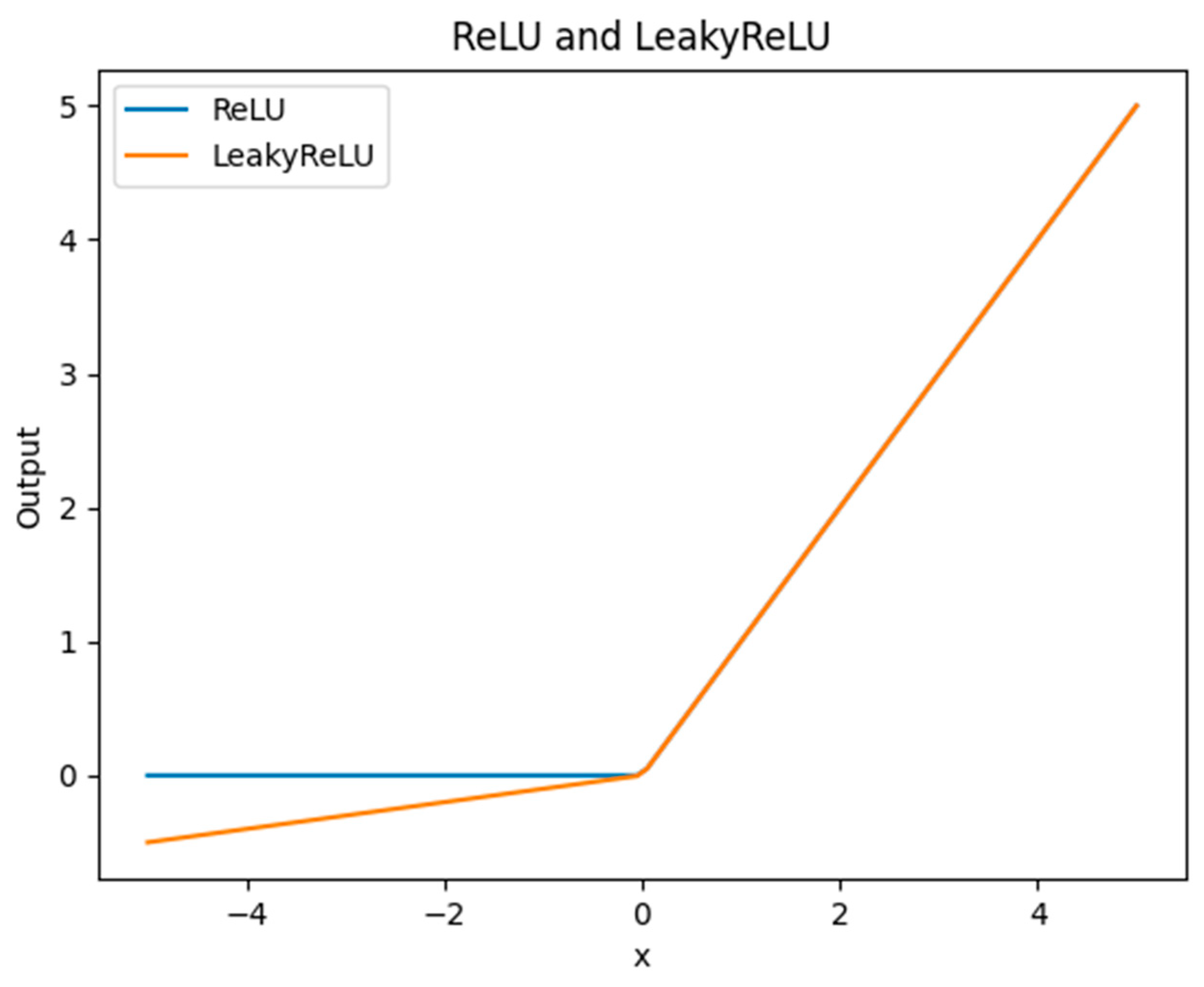
- Change the activation function to LeakyReLU (0.1), introducing a small slope in the negative part to pass a certain gradient during backpropagation, helping alleviate the problem of gradient vanishing, especially in deep networks.
3.2.1. MixConv
3.2.2. Depthwise Separable Convolutional
3.2.3. CBAM
3.2.4. K-Means Clustering Algorithm Updates Bounding Boxes
3.2.5. ComputeLossOTA
3.2.6. LeakyReLU
3.3. Model Training and Evaluation Metrics
3.3.1. Training Platform
3.3.2. Training Parameters
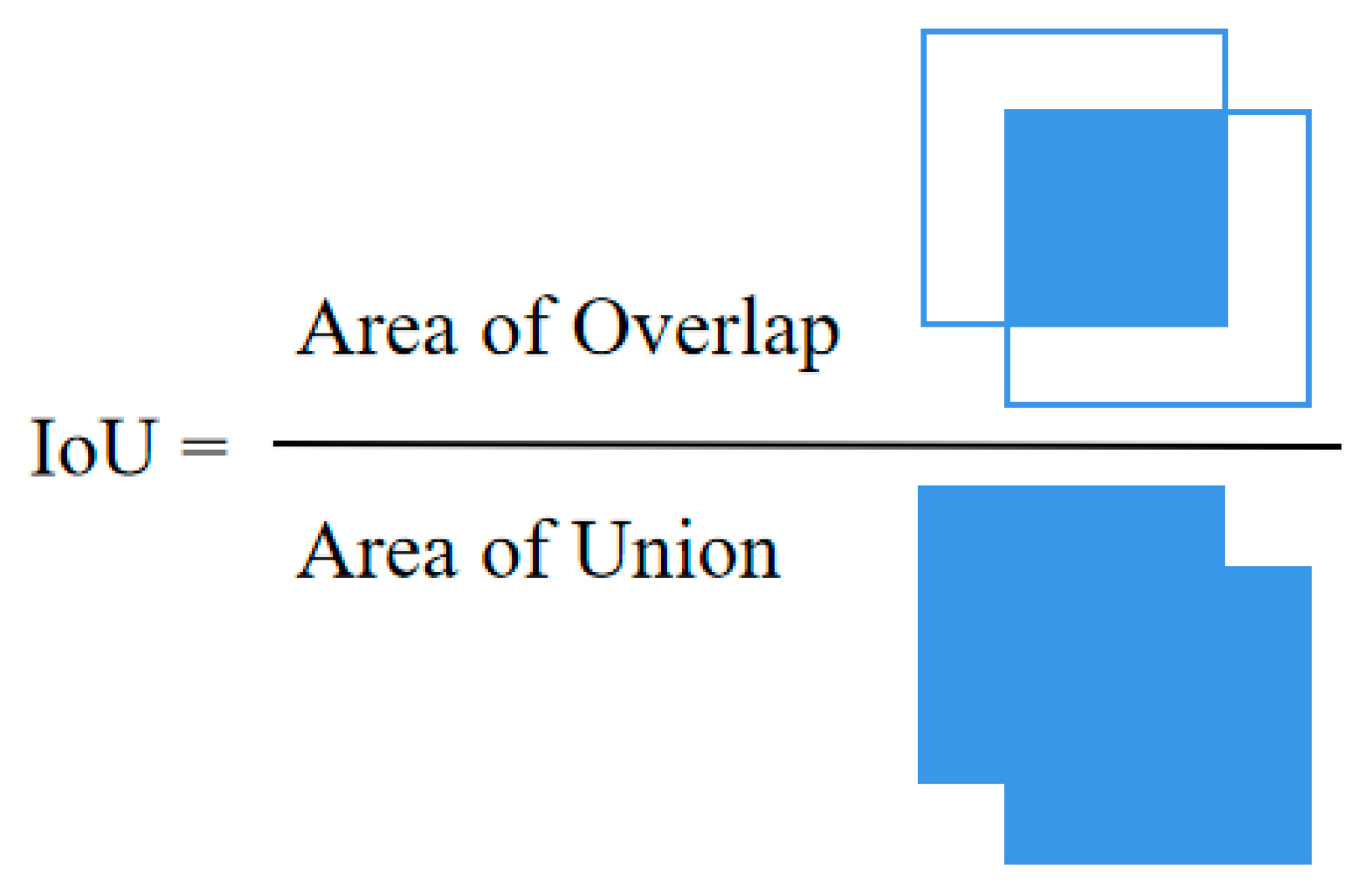
3.3.3. Evaluation Metrics
4. Result and Analysis
4.1. Comparison of Classic Model Performance
4.2. Performance Comparison of Different Attention Mechanisms
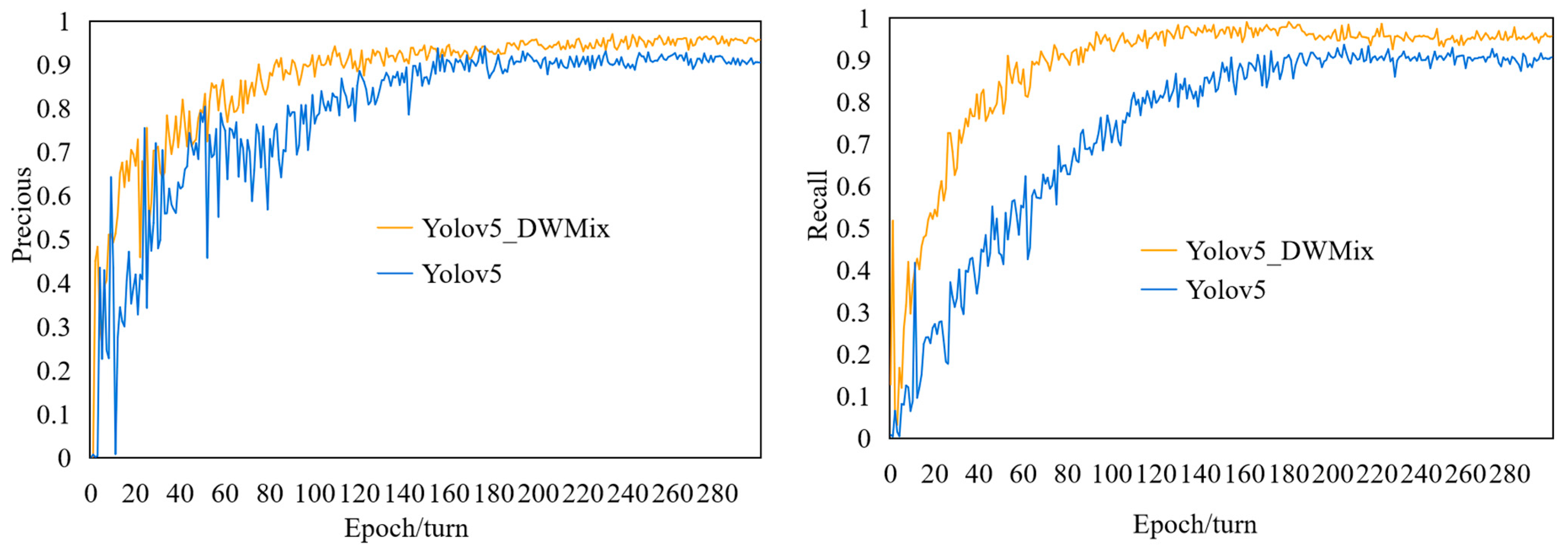
4.3. Comparison of Ablation Experiments Performance
- Regarding data preprocessing, image augmentation is applied to generate more diverse training samples, thereby expanding the dataset, reducing overfitting issues, and enhancing the model’s generalization ability.
- In the backbone network, the first layer utilizes the CBRM module, which achieves dimension reduction of features and translation invariance of positions through max pooling operations. The MixConv is used to replace the regular convolutions in the C3 module. The DWConv is employed for feature downsampling to enhance feature extraction capabilities and improve algorithm performance.
- The CBAM is added to adaptively weight the feature maps, enhancing the extraction of effective feature information while compressing irrelevant feature information to improve the quality of feature representation.
- The bounding box information in YOLOv5 is updated using the k-means clustering algorithm.
- The ComputeLossOTA function is utilized as the loss function, considering the key factors of object existence, position, and classification accuracy. LeakyReLU (0.1) serves as the activation function, effectively alleviating the problem of gradient disappearance.
4.4. Identification Results of Rice Diseases and Pests Using Different Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Zeng, J.; Yang, Q.P.; Bian, Y.; Zhang, Y.Y.; Huang, C. Forecast of major crop pest occurrence trends in 2023. China Plant Prot. 2023, 43, 32–35. [Google Scholar]
- Liang, Q.L.; Jiang, Y.Z.; Chen, W.D.; Zhang, F.S.; Lang, W.Q.; Huang, Q.; Zhong, Z.F. Monitoring and Development Trend Analysis of Rice Diseases and Pests Occurrence in the Field. Agric. Dev. Equip. 2021, 12, 189–190. [Google Scholar]
- Patricio, D.I.; Rieder, R. Computer Vision and Artificial Intelligence in Precision Agriculture for Grain Crops: A Systematic Review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef]
- Zhai, Z.Y.; Cao, Y.F.; Xu, H.L.; Yuan, P.; Wang, H. Review of Key Techniques for Crop Disease and Pest Detection. Trans. Chin. Soc. Agric. Mach. 2021, 52, 1–18. [Google Scholar]
- Brahimi, M.; Boukhalfa, K.; Moussaoui, A. Deep Learning for Tomato Diseases: Classification and Symptoms Visualization. Appl. Artif. Intell. 2017, 31, 299–315. [Google Scholar] [CrossRef]
- Sagarika, G.K.; Prasad, S.J.K.; Kumar, S.M. Paddy Plant Disease Classification and Prediction Using Convolutional Neural Network. In Proceedings of the 2020 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 12–13 November 2020; pp. 208–214. [Google Scholar]
- Wang, Y.; Wang, H.; Peng, Z. Rice diseases detection and classification using attention-based neural network and bayesian optimization. Expert Syst. Appl. 2021, 178, 114770. [Google Scholar] [CrossRef]
- Burhan, S.A.; Minhas, S.; Tariq, A.; Hassan, M.N. Comparative study of deep learning algorithms for disease and pest detection in rice crops. In Proceedings of the 12th International Conference on Electronics, Computers and Artificial Intelligence, Bucharest, Romania, 25–27 June 2020; 1–5. [Google Scholar]
- Hu, Y.; Deng, X.; Lan, Y.; Chen, X.; Long, Y.; Liu, C. Detection of Rice Pests Based on Self-Attention Mechanism and Multi-Scale Feature Fusion. Insects 2023, 14, 280. [Google Scholar] [CrossRef]
- Li, D.; Wang, R.; Xie, C.; Liu, L.; Zhang, J.; Li, R.; Wang, F.; Zhou, M.; Liu, W. A Recognition Method for Rice Plant Diseases and Pests Video Detection Based on Deep Convolutional Neural Network. Sensors 2020, 20, 578. [Google Scholar] [CrossRef]
- Wang, Z.; Chu, G.K.; Zhang, H.J.; Liu, S.X.; Huang, X.C.; Gao, F.R.; Zhang, C.Q.; Wang, J.X. Identification of Diseased Empty Rice Panicles Based on Haar-like Feature of UAV Optical Image. Trans. Chin. Soc. Agric. Eng. 2018, 34, 73–82. [Google Scholar]
- Wei, L.; Luo, Y.; Xu, L.; Zhang, Q.; Cai, Q.; Shen, M. Deep Convolutional Neural Network for Rice Density Prescription Map at Ripening Stage Using Unmanned Aerial Vehicle-Based Remotely Sensed Images. Remote Sens. 2022, 14, 46. [Google Scholar] [CrossRef]
- Yao, Q.; Gu, J.L.; Lv, J.; Guo, L.J.; Tang, J.; Yang, B.; Xu, W. Automatic detection model for pest damage symptoms on rice canopy based on improved RetinaNet. Trans. Chin. Soc. Agric. Eng. 2020, 36, 182–188. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, Y.M.; Hu, K.; Nie, J.W.; Xie, T. Rice disease and pest identification based on MSDB-ResNet. J. South China Agric. Univ. 2023, 44, 978–985. [Google Scholar]
- Tan, M.X.; Le, Q.V. MixConv: Mixed Depthwise Convolutional Kernels. arXiv 2019, arXiv:1907.09595. [Google Scholar]
- Yang, X.; Duan, J.M.; Dong, M.G. Mobile-oriented Plant Disease Image Recognition Method and its Application. Jiangsu Agric. Sci. 2023, 51, 191–197. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Jia, L.; Ye, Z.H. Grape Disease Recognition Model Based on Attention Mechanism and Feature Fusion. Trans. Chin. Soc. Agric. Mach. 2023, 54, 223–233. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Xie, S.Q.; Song, J.; Tang, X.Y.; Bai, Y. Identification of Grape Leaf Diseases Based on Transfer Learning and Residual Networks. J. Agric. Mech. Res. 2023, 45, 18–23, 28. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, H.; Jiang, Y.C.; Ren, D.Y.; Li, Y.; Wei, Y. Detection Method of Potato Leaf Diseases Based on Deep Learning. J. Chin. Agric. Mech. 2022, 43, 183–189. [Google Scholar]
- Zhou, W.; Niu, Y.Z.; Wang, Y.W.; Li, D. Rice Pests and Diseases Identification Method Based on Improved YOLOv4-GhostNet. Jiangsu J. Agric. Sci. 2022, 38, 685–695. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.M.; Cheng, P.L.; Huang, Y. Faster R-CNN: Towards real-time object detection with region proposal networks. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Rahman, C.R.; Arko, P.S.; Ali, M.E.; Khan, M.A.I.; Apon, S.H.; Nowrin, F.; Wasif, A. Identification and recognition of rice diseases and pests using convolutional neural networks. Biosyst. Eng. 2020, 194, 112–120. [Google Scholar] [CrossRef]
- Pan, C.L.; Zhang, Z.H.; Gui, W.H.; Ma, J.J.; Yan, C.X.; Zhang, X.M. Rice Disease and Pest Recognition Method Integrating ECA Mechanism and DenseNet201. Smart Agric. 2023, 5, 45–55, (In Chinese and English). [Google Scholar]
- Ni, H.; Shi, Z.; Karungaru, S.; Lv, S.; Li, X.; Wang, X.; Zhang, J. Classification of Typical Pests and Diseases of Rice Based on the ECA Attention Mechanism. Agriculture 2023, 13, 1066. [Google Scholar] [CrossRef]
- Jia, L.; Wang, T.; Chen, Y.; Zang, Y.; Li, X.; Shi, H.; Gao, L. MobileNet-CA-YOLO: An Improved YOLOv7 Based on the MobileNetV3 and Attention Mechanism for Rice Pests and Diseases Detection. Agriculture. 2023, 13, 1285. [Google Scholar] [CrossRef]
- Liang, K.; Wang, Y.; Sun, L.; Xin, D.; Chang, Z. A Lightweight-Improved CNN Based on VGG16 for Identification and Classification of Rice Diseases and Pests. In Proceedings of the International Conference on Image, Vision and Intelligent Systems (ICIVIS 2021), Changsha, China, 21–23 May 2022; pp. 195–207. [Google Scholar]
- Cao, Z.; Kooistra, L.; Wang, W.; Guo, L.; Valente, J. Real-Time Object Detection Based on UAV Remote Sensing: A Systematic Literature Review. Drones 2023, 7, 620. [Google Scholar] [CrossRef]
- Li, L.; Zhao, H.; Liu, N. MCD-Yolov5: Accurate, Real-Time Crop Disease and Pest Identification Approach Using UAVs. Electronics 2023, 12, 4365. [Google Scholar] [CrossRef]
- Yin, N.; Bao, W.; Yang, R.; Wang, N.; Liu, W. LWSDNet: A Lightweight Wheat Scab Detection Network Based on UAV Remote Sensing Images. Remote Sens. 2024, 16, 2820. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Zhao, G.Y.; Zhang, Y.L.; Lan, Y.B.; Deng, J.Z.; Zhang, Q.Z.; Zhang, Z.C.; Li, Z.Y.; Liu, L.H.; Huang, X.; Ma, J.J. Application Progress of UAV-LARS in Identification of Crop Diseases and Pests. Agronomy 2023, 13, 2232. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | R/% | mAP/% | FPS/s |
|---|---|---|---|---|
| YOLOv5_DWMix | 95.8 | 95.1 | 98.7 | 25.93 |
| YOLOv5 | 91 | 90.9 | 95.3 | 11.78 |
| YOLOv5_MobileNet | 86.7 | 91.8 | 93.0 | 17.68 |
| YOLOv5_Ghost | 81.8 | 88.9 | 90.2 | 18.7 |
| YOLOv7 | 62.6 | 51.0 | 69.6 | 10 |
| Faster_RCNN1 (vgg16) | 71.2 | 48.5 | 76.2 | 9.46 |
| Faster_RCNN2 (resnet50) | 70.4 | 47.9 | 74.1 | 7.57 |
| Model | P/% | R/% | mAP/% |
|---|---|---|---|
| CBAM | 95.8 | 95.1 | 98.7 |
| SimAM | 94.7 | 94.8 | 98.4 |
| SE | 94.3 | 97.4 | 98.9 |
| CA | 93.1 | 94.7 | 96.5 |
| ECA | 95.6 | 96.3 | 98.3 |
| Test | Image Augmentation | Backbone Network | CBAM | K-Means | Loss + Activation Function | P/% |
|---|---|---|---|---|---|---|
| 1 | - | - | - | - | - | 92 |
| 2 | √ | - | - | - | - | 92.9 |
| 3 | √ | √ | - | - | - | 94.0 |
| 4 | √ | √ | √ | - | - | 94.7 |
| 5 | √ | √ | √ | √ | - | 95.1 |
| 6 | √ | √ | √ | √ | √ | 95.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, G.; Lan, Y.; Zhang, Y.; Deng, J. Rice Canopy Disease and Pest Identification Based on Improved YOLOv5 and UAV Images. Sensors 2025, 25, 4072. https://doi.org/10.3390/s25134072
Zhao G, Lan Y, Zhang Y, Deng J. Rice Canopy Disease and Pest Identification Based on Improved YOLOv5 and UAV Images. Sensors. 2025; 25(13):4072. https://doi.org/10.3390/s25134072
Chicago/Turabian StyleZhao, Gaoyuan, Yubin Lan, Yali Zhang, and Jizhong Deng. 2025. "Rice Canopy Disease and Pest Identification Based on Improved YOLOv5 and UAV Images" Sensors 25, no. 13: 4072. https://doi.org/10.3390/s25134072
APA StyleZhao, G., Lan, Y., Zhang, Y., & Deng, J. (2025). Rice Canopy Disease and Pest Identification Based on Improved YOLOv5 and UAV Images. Sensors, 25(13), 4072. https://doi.org/10.3390/s25134072