
Unlabeled-Data-Enhanced Tool Remaining Useful Life Prediction Based on Graph Neural Network



Abstract
1. Introduction
- (1)
- To better achieve unlabeled data enhancement, this paper innovatively introduces a GNN to multi-sensor data fusion for tool RUL prediction. The GNN can directly process non-Euclidean data and capture complex dependencies between sensors, thus extracting more information from the intricate spatial and dynamic correlations in multi-sensor data.
- (2)
- By training on unlabeled data, this paper defines a criterion and loss function to learn knowledge crucial for tool RUL prediction. Model parameters trained on unlabeled data contain the knowledge and are then transferred to another model based on labeled data for tool RUL prediction, completing the unlabeled data enhancement.
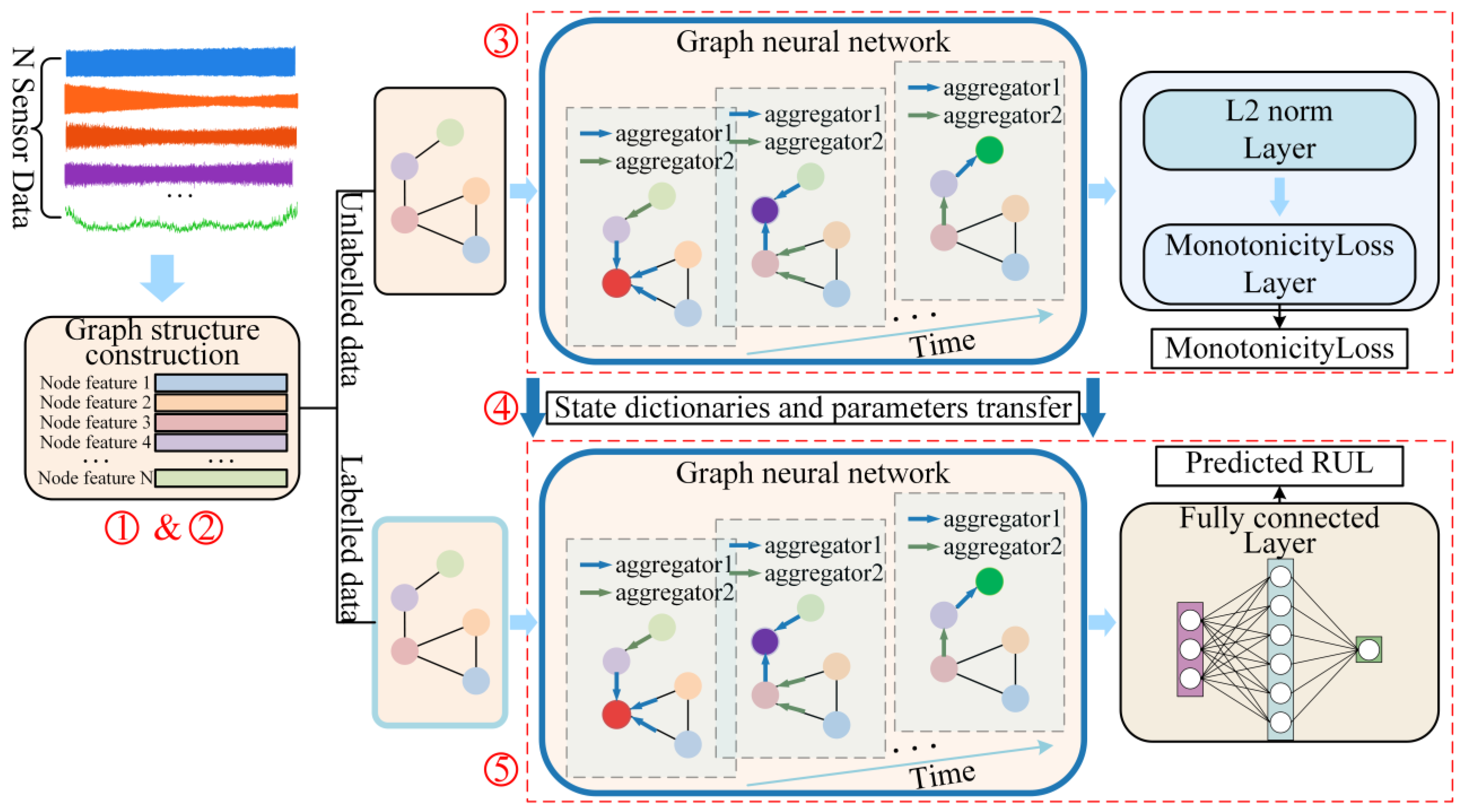
2. Methodology
2.1. Feature Extraction
2.2. Graph Neural Network
- Node: Each sensor is viewed as a node in the graph.
- Node Embedding: The 30-dimensional feature vector extracted from each sensor’s signal is used to embed the corresponding node.
- Edges: Edges between nodes represent the dependencies or correlations among sensors.
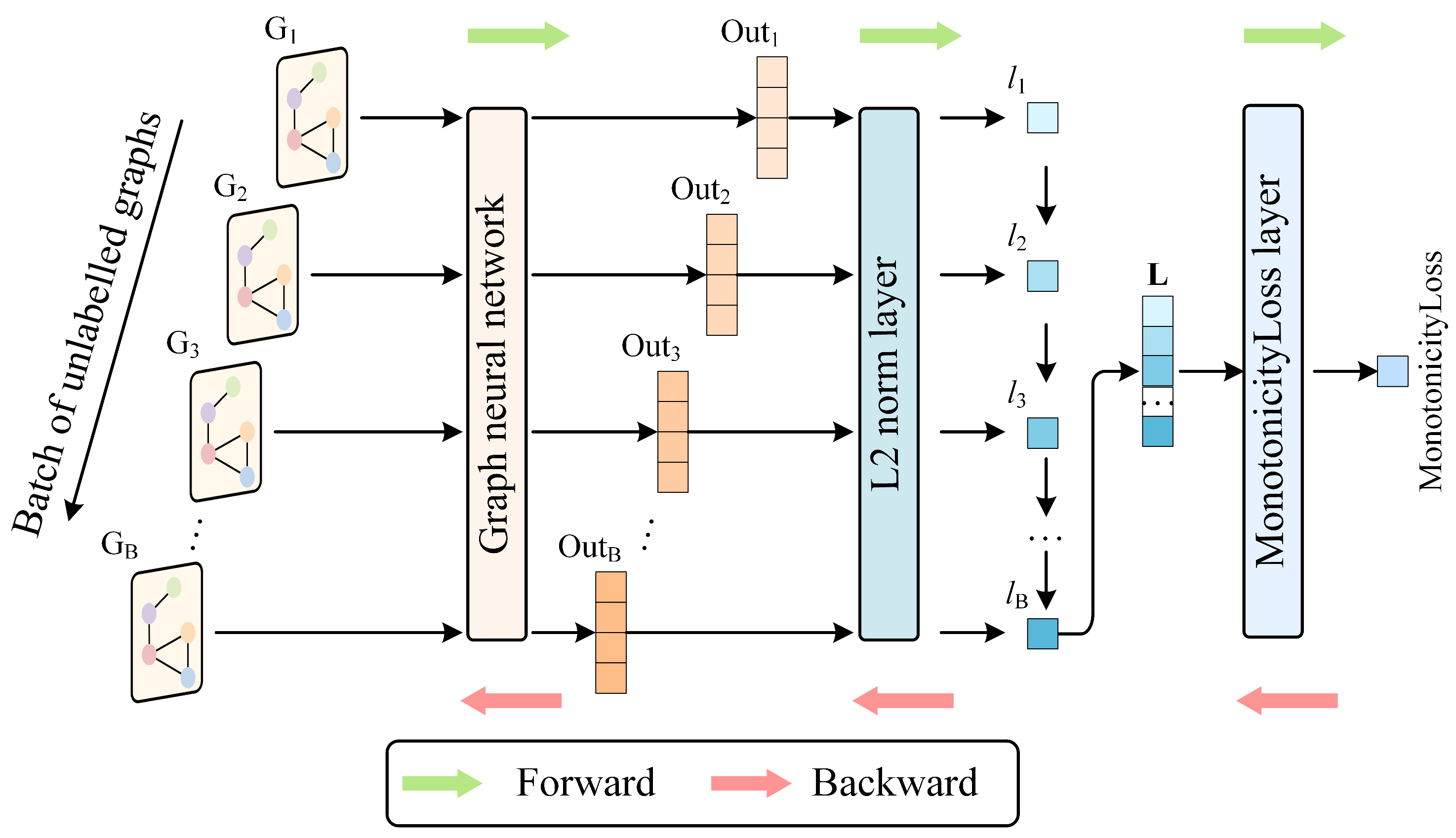
2.3. Unlabeled-Data-Trained Model Training
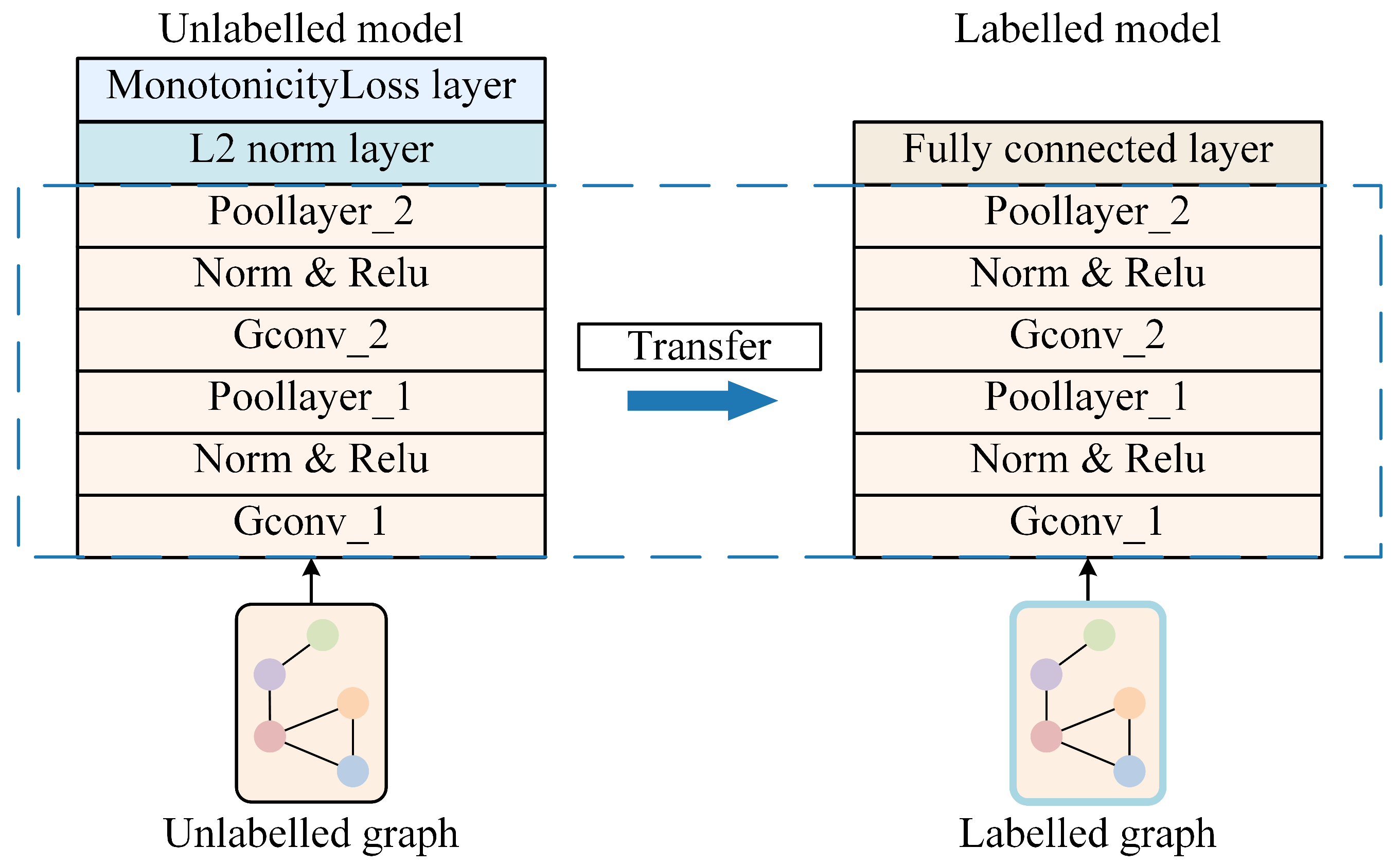
2.4. Tool RUL Prediction and Transfer Learning
3. Experimental Design
3.1. Experimental Design of PHM2010
3.2. Experimental Design of JUST_T05
4. Results and Discussion
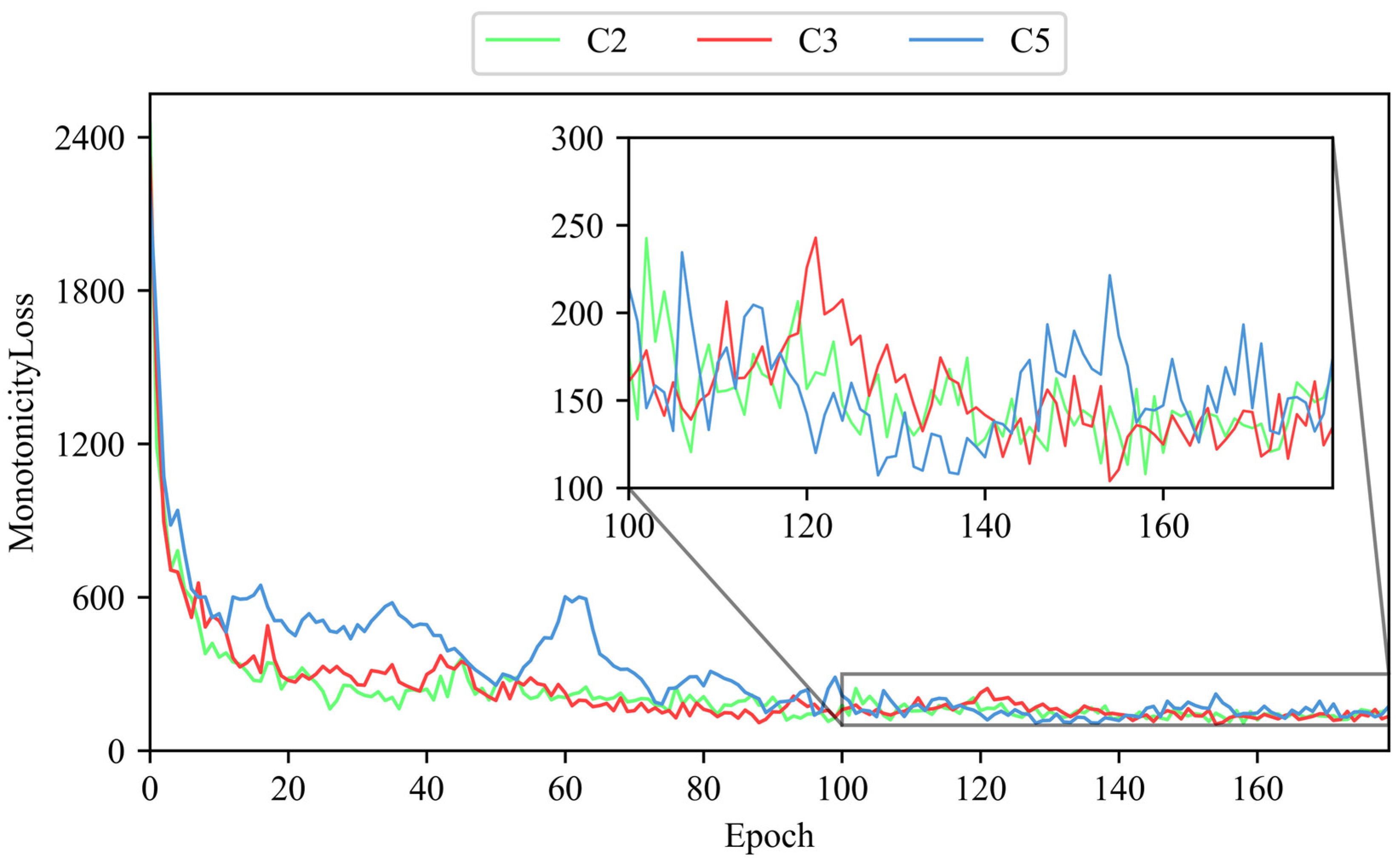
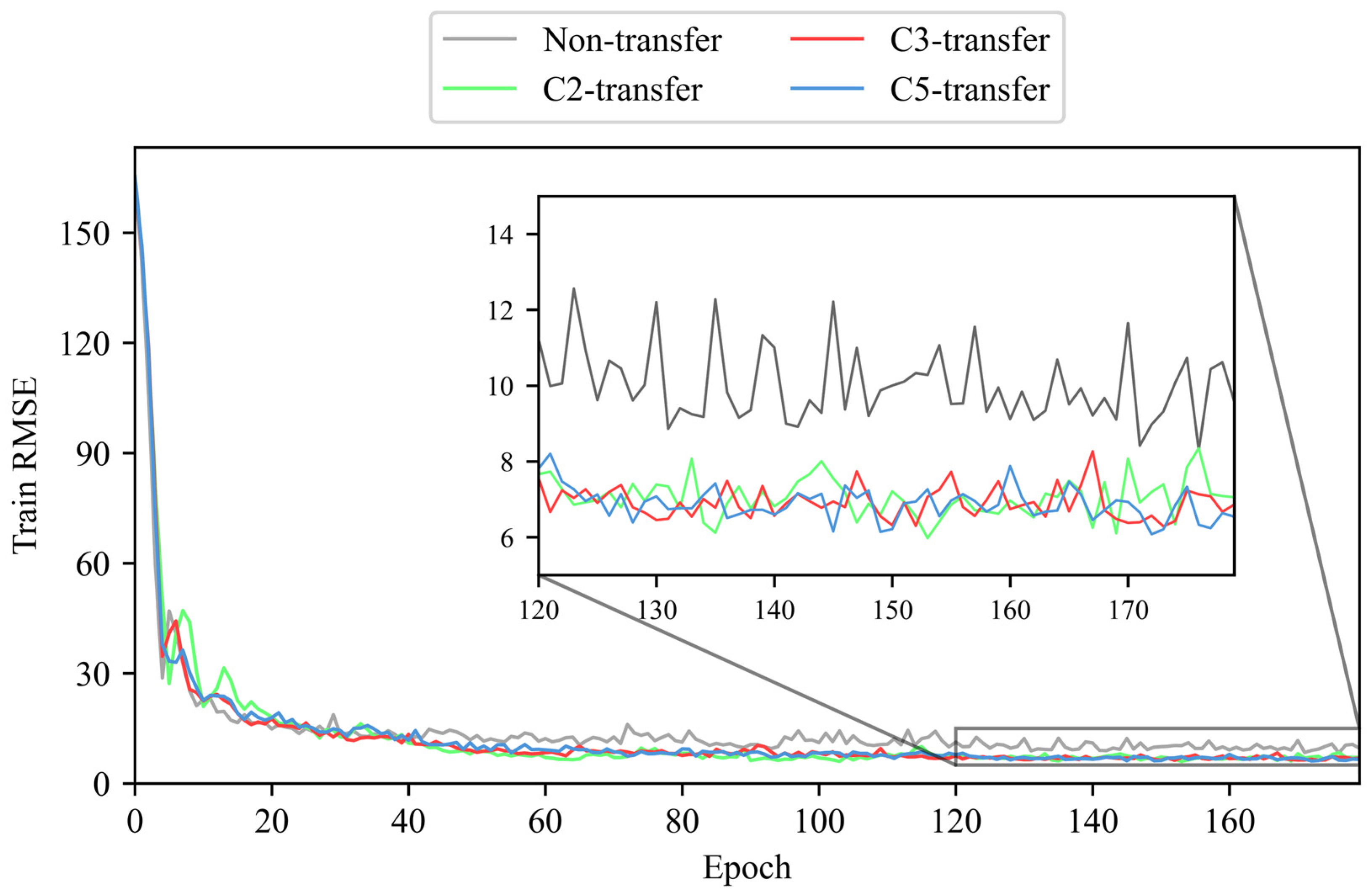
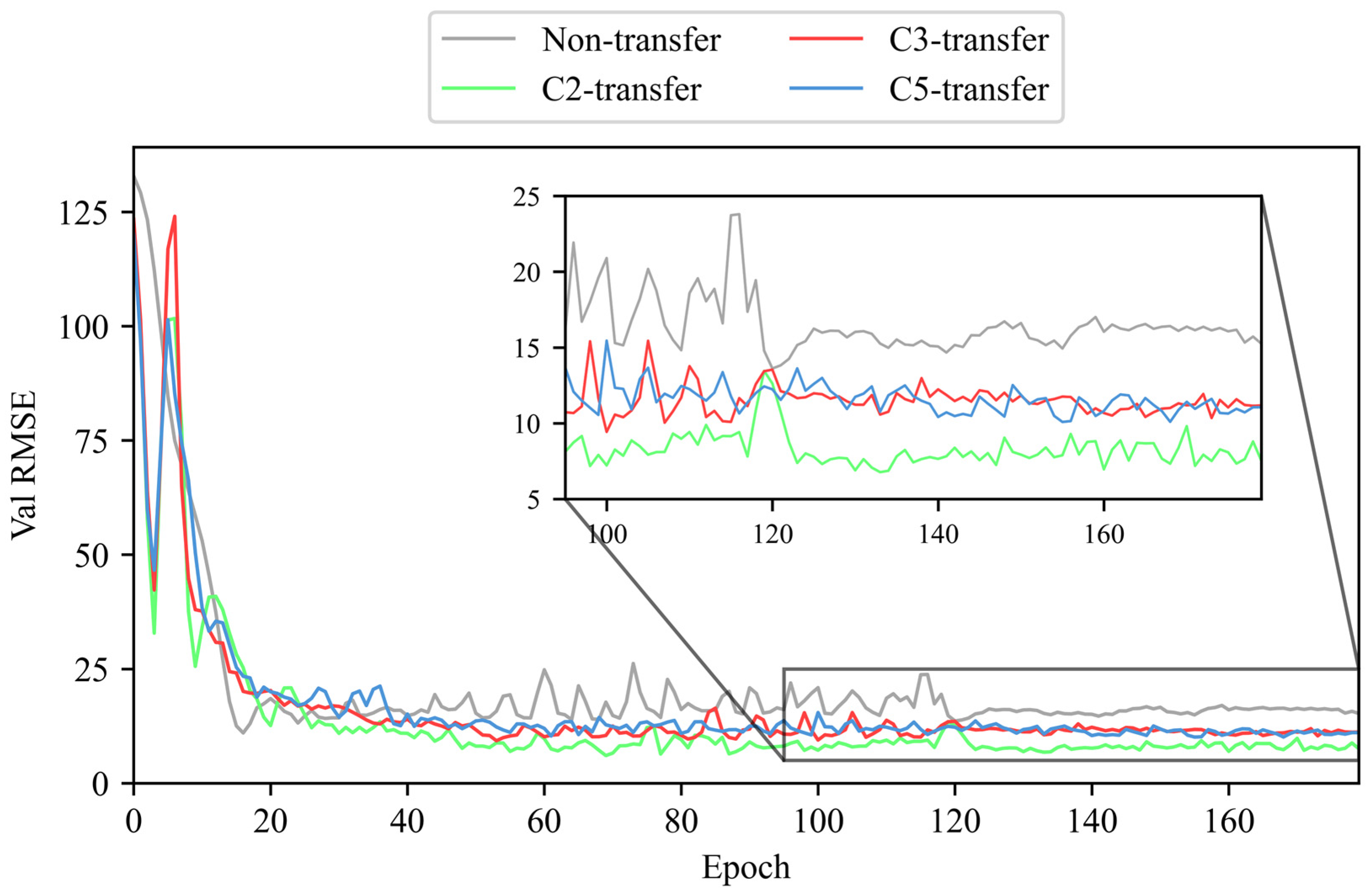
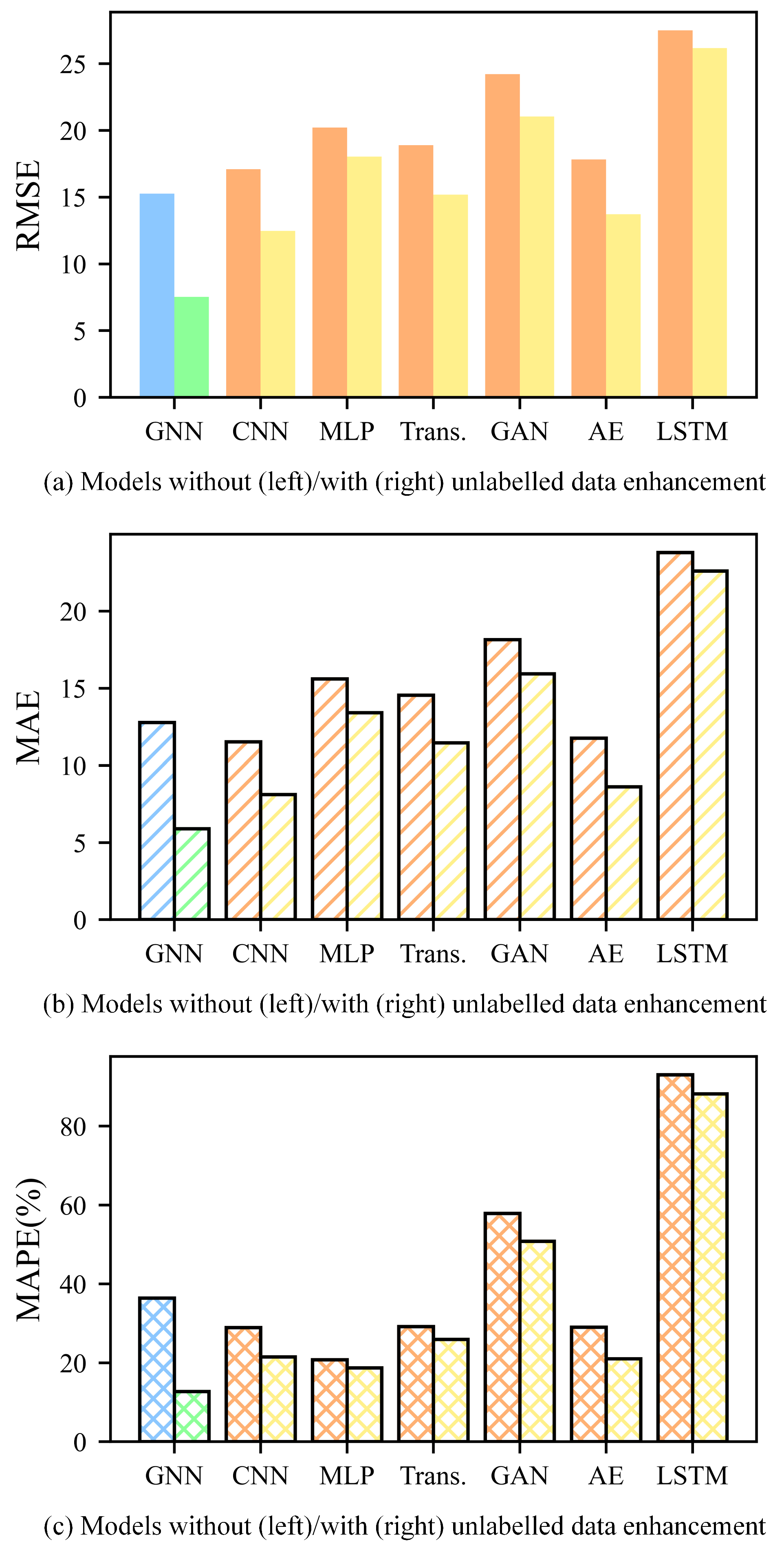
4.1. PHM2010
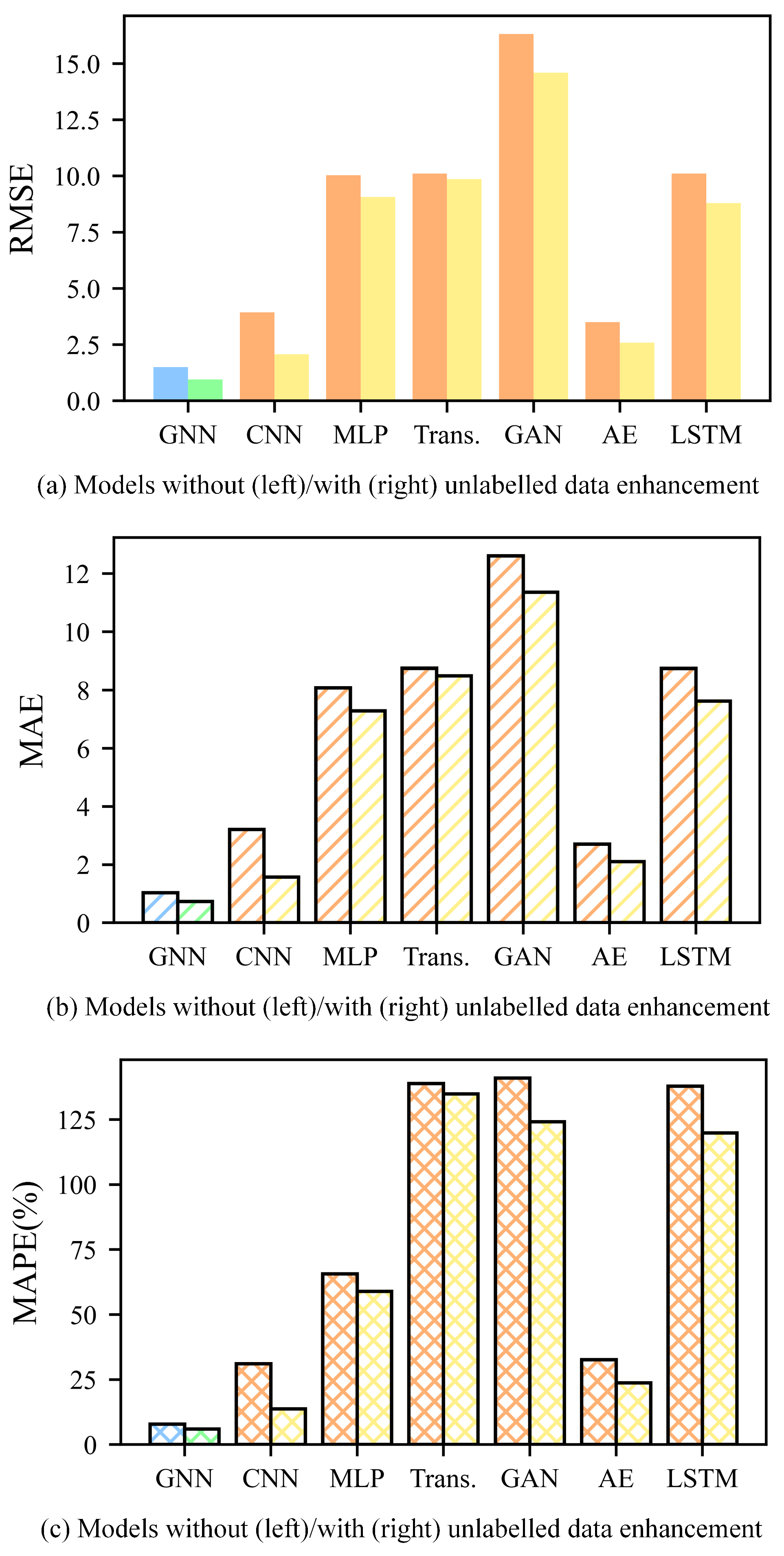
4.2. JUST_T05
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, K.; Guo, H.; Li, S.; Lin, X. Online tool wear monitoring by super-resolution based machine vision. Comput. Ind. 2023, 144, 103782. [Google Scholar] [CrossRef]
- Thangamuthu, M.; Tamilvanan, A. Decision support system for tool condition monitoring in milling process using artificial neural network. J. Eng. Res. 2022, 10, 142–155. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Huang, Z.; Gao, R.X. Physics-informed meta learning for machining tool wear prediction. J. Manuf. Syst. 2022, 62, 17–27. [Google Scholar] [CrossRef]
- Karandikar, J.; Schmitz, T.; Smith, S. Physics-guided logistic classification for tool life modeling and process parameter optimization in machining. J. Manuf. Syst. 2021, 59, 522–534. [Google Scholar] [CrossRef]
- Duan, J.; Hu, C.; Zhan, X.; Zhou, H.; Liao, G.; Shi, T. MS-SSPCANet: A powerful deep learning framework for tool wear prediction. Robot. Comput.-Integr. Manuf. 2022, 78, 102391. [Google Scholar] [CrossRef]
- Gharesi, N.; Arefi, M.M.; Razavi-Far, R.; Zarei, J.; Yin, S. A neuro-wavelet based approach for diagnosing bearing defects. Adv. Eng. Inform. 2020, 46, 101172. [Google Scholar] [CrossRef]
- Painuli, S.; Elangovan, M.; Sugumaran, V. Tool condition monitoring using K-star algorithm. Expert Syst. Appl. 2014, 41, 2638–2643. [Google Scholar] [CrossRef]
- Cai, W.; Zhang, W.; Hu, X.; Liu, Y. A hybrid information model based on long short-term memory network for tool condition monitoring. J. Intell. Manuf. 2020, 31, 1497–1510. [Google Scholar] [CrossRef]
- Ma, Z.; Zhao, M.; Dai, X.; Chen, Y. A hybrid-driven probabilistic state space model for tool wear monitoring. Mech. Syst. Signal Process. 2023, 200, 110599. [Google Scholar] [CrossRef]
- Wang, M.; Zhou, J.; Gao, J.; Li, Z.; Li, E. Milling tool wear prediction method based on deep learning under variable working conditions. IEEE Access 2020, 8, 140726–140735. [Google Scholar] [CrossRef]
- Gao, K.; Xu, X.; Jiao, S. Measurement and prediction of wear volume of the tool in nonlinear degradation process based on multi-sensor information fusion. Eng. Fail. Anal. 2022, 136, 106164. [Google Scholar] [CrossRef]
- Li, G.; Jiang, R.; Sun, L.; Zhou, H.; Liu, Y.; Shang, X. Prediction of bidirectional milling forces based on spindle current signals by using deep learning algorithms. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2025. [Google Scholar] [CrossRef]
- Marani, M.; Zeinali, M.; Songmene, V.; Mechefske, C.K. Tool wear prediction in high-speed turning of a steel alloy using long short-term memory modelling. Measurement 2021, 177, 109329. [Google Scholar] [CrossRef]
- Wang, J.; Yan, J.; Li, C.; Gao, R.X.; Zhao, R. Deep heterogeneous GRU model for predictive analytics in smart manufacturing: Application to tool wear prediction. Comput. Ind. 2019, 111, 1–14. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, J.; Mo, R.; Zhang, X. In-process tool condition forecasting based on a deep learning method. Robot. Comput.-Integr. Manuf. 2020, 64, 101924. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Han, Z.; Zhang, X.; Jin, H. Intelligent tool wear prediction based on Informer encoder and stacked bidirectional gated recurrent unit. Robot. Comput.-Integr. Manuf. 2022, 77, 102368. [Google Scholar] [CrossRef]
- Shu, R.; Xu, Y.; He, J.; Yang, X.; Zhao, Z.; Huang, G.Q. Multi-view contrastive learning framework for tool wear detection with insufficient annotated data. Adv. Eng. Inform. 2024, 62, 102666. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Zhao, R.; Gao, R.X. Physics guided neural network for machining tool wear prediction. J. Manuf. Syst. 2020, 57, 298–310. [Google Scholar] [CrossRef]
- Sun, Y.; He, J.; Gao, H.; Song, H.; Guo, L. A New Semi-supervised Tool-wear Monitoring Method using Unreliable Pseudo-Labels. Measurement 2024, 226, 113991. [Google Scholar] [CrossRef]
- Warke, V.; Kumar, S.; Bongale, A.; Kotecha, K. Robust Tool Wear Prediction using Multi-Sensor Fusion and Time-Domain Features for the Milling Process using Instance-based Domain Adaptation. Knowl.-Based Syst. 2024, 288, 111454. [Google Scholar] [CrossRef]
- Zhu, Y.; Zi, Y.; Xu, J.; Li, J. An unsupervised dual-regression domain adversarial adaption network for tool wear prediction in multi-working conditions. Measurement 2022, 200, 111644. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Zhuo, Y.; Liu, C.; Jin, H. Semi-supervised multi-source meta-domain generalization method for tool wear state prediction under varying cutting conditions. J. Manuf. Syst. 2023, 71, 323–341. [Google Scholar] [CrossRef]
- Liu, B.; Liu, C.; Zhou, Y.; Wang, D.; Dun, Y. An unsupervised chatter detection method based on AE and merging GMM and K-means. Mech. Syst. Signal Process. 2023, 186, 109861. [Google Scholar] [CrossRef]
- Yan, B.; Zhu, L.; Dun, Y. Tool wear monitoring of TC4 titanium alloy milling process based on multi-channel signal and time-dependent properties by using deep learning. J. Manuf. Syst. 2021, 61, 495–508. [Google Scholar] [CrossRef]
- Kou, R.; Lian, S.W.; Xie, N.; Lu, B.E.; Liu, X.M. Image-based tool condition monitoring based on convolution neural network in turning process. Int. J. Adv. Manuf. Technol. 2022, 119, 3279–3291. [Google Scholar] [CrossRef]
- Hou, W.; Guo, H.; Luo, L.; Jin, M. Tool wear prediction based on domain adversarial adaptation and channel attention multiscale convolutional long short-term memory network. J. Manuf. Process. 2022, 84, 1339–1361. [Google Scholar] [CrossRef]
- Li, G.; Shang, X.; Sun, L.; Fu, B.; Yang, L.; Zhou, H. Application of audible sound signals in tool wear monitoring: A review. J. Adv. Manuf. Sci, Technol. 2025, 5, 2025003. [Google Scholar] [CrossRef]
- Traini, E.; Bruno, G.; D’antonio, G.; Lombardi, F. Machine learning framework for predictive maintenance in milling. IFAC-PapersOnLine 2019, 52, 177–182. [Google Scholar] [CrossRef]
- Ma, J.; Luo, D.; Liao, X.; Zhang, Z.; Huang, Y.; Lu, J. Tool wear mechanism and prediction in milling TC18 titanium alloy using deep learning. Measurement 2021, 173, 108554. [Google Scholar] [CrossRef]
- Lin, M.; Wanqing, S.; Chen, D.; Zio, E. Evolving connectionist system and hidden semi-Markov model for learning-based tool wear monitoring and remaining useful life prediction. IEEE Access 2022, 10, 82469–82482. [Google Scholar] [CrossRef]
- Li, X.; Liu, X.; Yue, C.; Wang, L.; Liang, S.Y. Data-model linkage prediction of tool remaining useful life based on deep feature fusion and Wiener process. J. Manuf. Syst. 2024, 73, 19–38. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, G.; Zhang, C.; Liu, J.; Chang, F.; Zhou, Y.; Han, C.; Zhao, D. An adaptive RUL prediction approach for cutting tools incorporated with interpretability and uncertainty. Reliab. Eng. Syst. Saf. 2025, 256, 110705. [Google Scholar] [CrossRef]
- Li, C.; Mo, L.; Yan, R. Fault diagnosis of rolling bearing based on WHVG and GCN. IEEE Trans. Instrum. Meas. 2021, 70, 3519811. [Google Scholar] [CrossRef]
- Yu, X.; Tang, B.; Zhang, K. Fault diagnosis of wind turbine gearbox using a novel method of fast deep graph convolutional networks. IEEE Trans. Instrum. Meas. 2021, 70, 6502714. [Google Scholar] [CrossRef]
- Chen, K.; Hu, J.; Zhang, Y.; Yu, Z.; He, J. Fault location in power distribution systems via deep graph convolutional networks. IEEE J. Sel. Areas Commun. 2019, 38, 119–131. [Google Scholar] [CrossRef]
- Li, X.; Yan, X.; Gu, Q.; Zhou, H.; Wu, D.; Xu, J. Deepchemstable: Chemical stability prediction with an attention-based graph convolution network. J. Chem. Inf. Model. 2019, 59, 1044–1049. [Google Scholar] [CrossRef]
- Li, G.; Xu, S.; Jiang, R.; Liu, Y.; Zhang, L.; Zheng, H.; Sun, L.; Sun, Y. Physics-informed inhomogeneous wear identification of end mills by online monitoring data. J. Manuf. Process. 2024, 132, 759–771. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Z.; Li, S.; Sun, C.; Yan, R.; Chen, X. The emerging graph neural networks for intelligent fault diagnostics and prognostics: A guideline and a benchmark study. Mech. Syst. Signal Process. 2022, 168, 108653. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time-Domain Characteristics | Formula |
|---|---|
| Peak value | |
| Form factor | |
| Clearance factor | |
| Shape factor |
| Frequency-Domain Characteristics | Formula |
|---|---|
| Mean value | |
| Centroid frequency | |
| Variance of frequency | |
| Frequency spread | |
| Fourth moment of frequency | |
| Form factor | |
| Coefficient of skewness | |
| Third moment of the mean | |
| Fourth moment of the mean | |
| Energy concentration factor |
| Unlabeled | Labeled | |||||
|---|---|---|---|---|---|---|
| Experiment number | C2 | C3 | C5 | C1 | C4 | C6 |
| Number of cuts | 315 | 315 | 315 | 315 | 315 | 315 |
| Number of sensors | 7 | 7 | 7 | 7 | 7 | 7 |
| Number of signals | 7 | 7 | 7 | 7 | 7 | 7 |
| PHM2010 Dataset | Chosen Samples | Description |
|---|---|---|
| C2 | 289 | ULDTM training dataset |
| C3 | 238 | ULDTM training dataset |
| C5 | 238 | ULDTM training dataset |
| C1 | 306 | LDTM training dataset_1 |
| C4 | 278 | LDTM training dataset_2 |
| C6 | 238 | LDTM validation dataset |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, D.; Zhou, H.; Sun, L.; Li, G. Unlabeled-Data-Enhanced Tool Remaining Useful Life Prediction Based on Graph Neural Network. Sensors 2025, 25, 4068. https://doi.org/10.3390/s25134068
Guo D, Zhou H, Sun L, Li G. Unlabeled-Data-Enhanced Tool Remaining Useful Life Prediction Based on Graph Neural Network. Sensors. 2025; 25(13):4068. https://doi.org/10.3390/s25134068
Chicago/Turabian StyleGuo, Dingli, Honggen Zhou, Li Sun, and Guochao Li. 2025. "Unlabeled-Data-Enhanced Tool Remaining Useful Life Prediction Based on Graph Neural Network" Sensors 25, no. 13: 4068. https://doi.org/10.3390/s25134068
APA StyleGuo, D., Zhou, H., Sun, L., & Li, G. (2025). Unlabeled-Data-Enhanced Tool Remaining Useful Life Prediction Based on Graph Neural Network. Sensors, 25(13), 4068. https://doi.org/10.3390/s25134068