
ZoomHead: A Flexible and Lightweight Detection Head Structure Design for Slender Cracks

Abstract
1. Introduction
2. Related Works
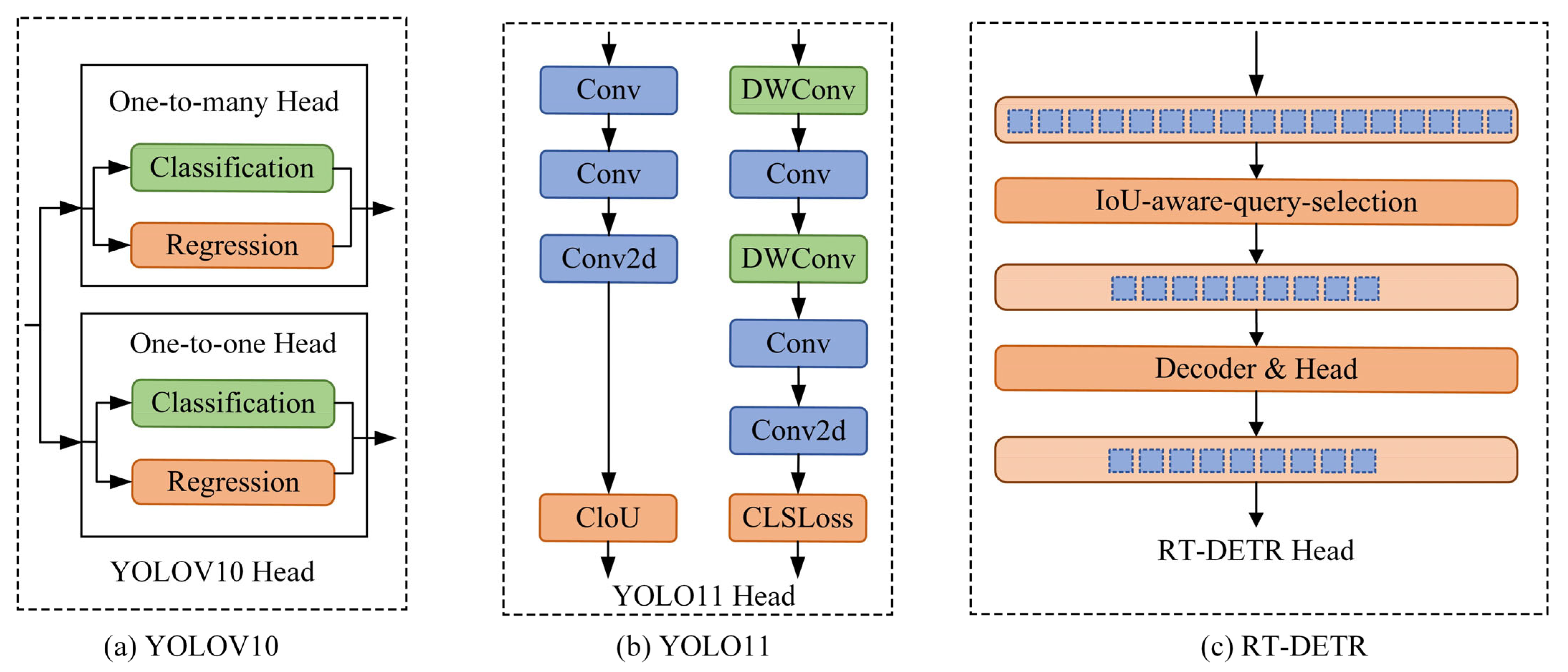
2.1. Head Structure Function
2.2. Exploration and Improvement Work Around the Head Structure
3. Methods
3.1. Replace BN with GN
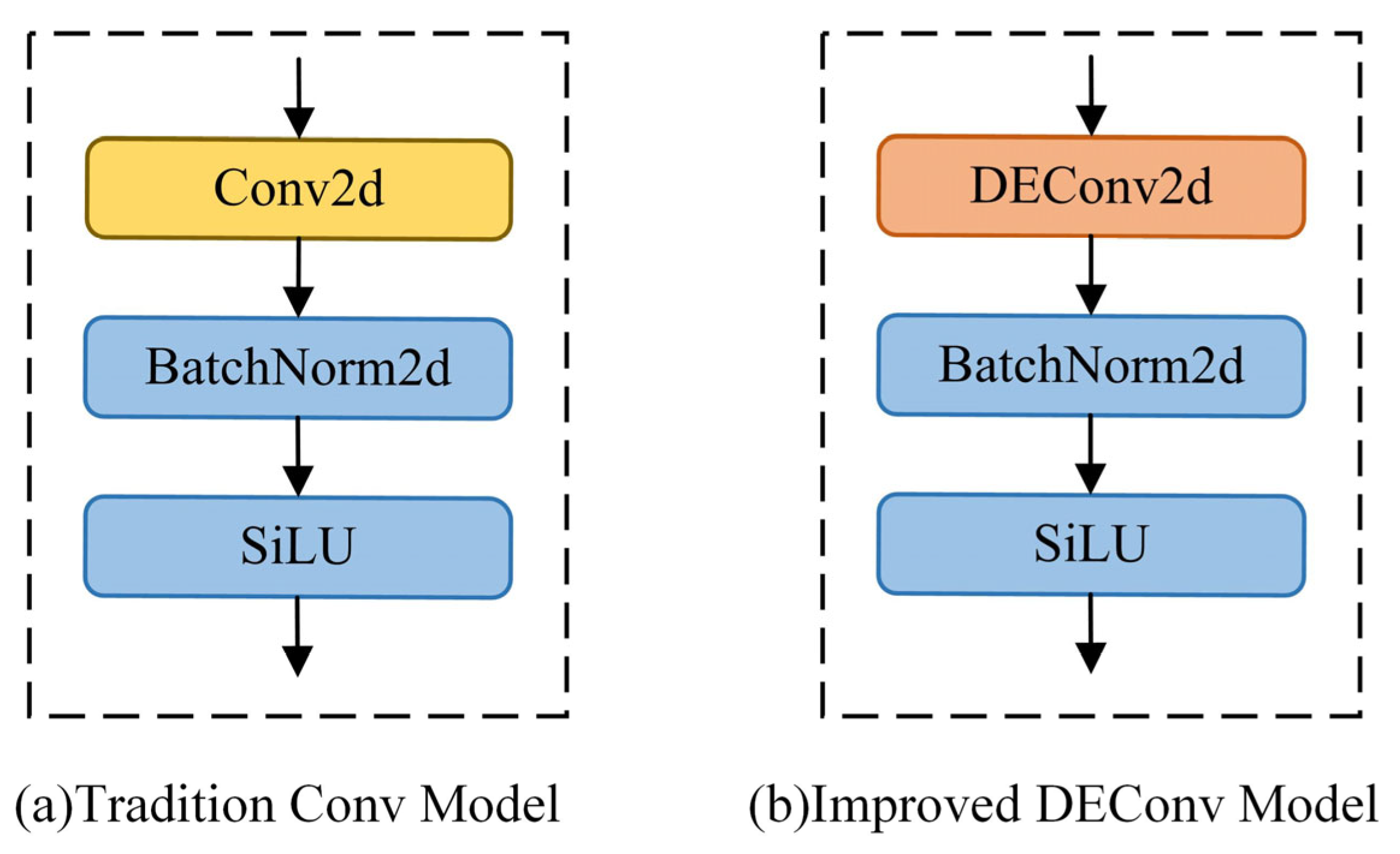
3.2. Detail-Enhanced Convolution
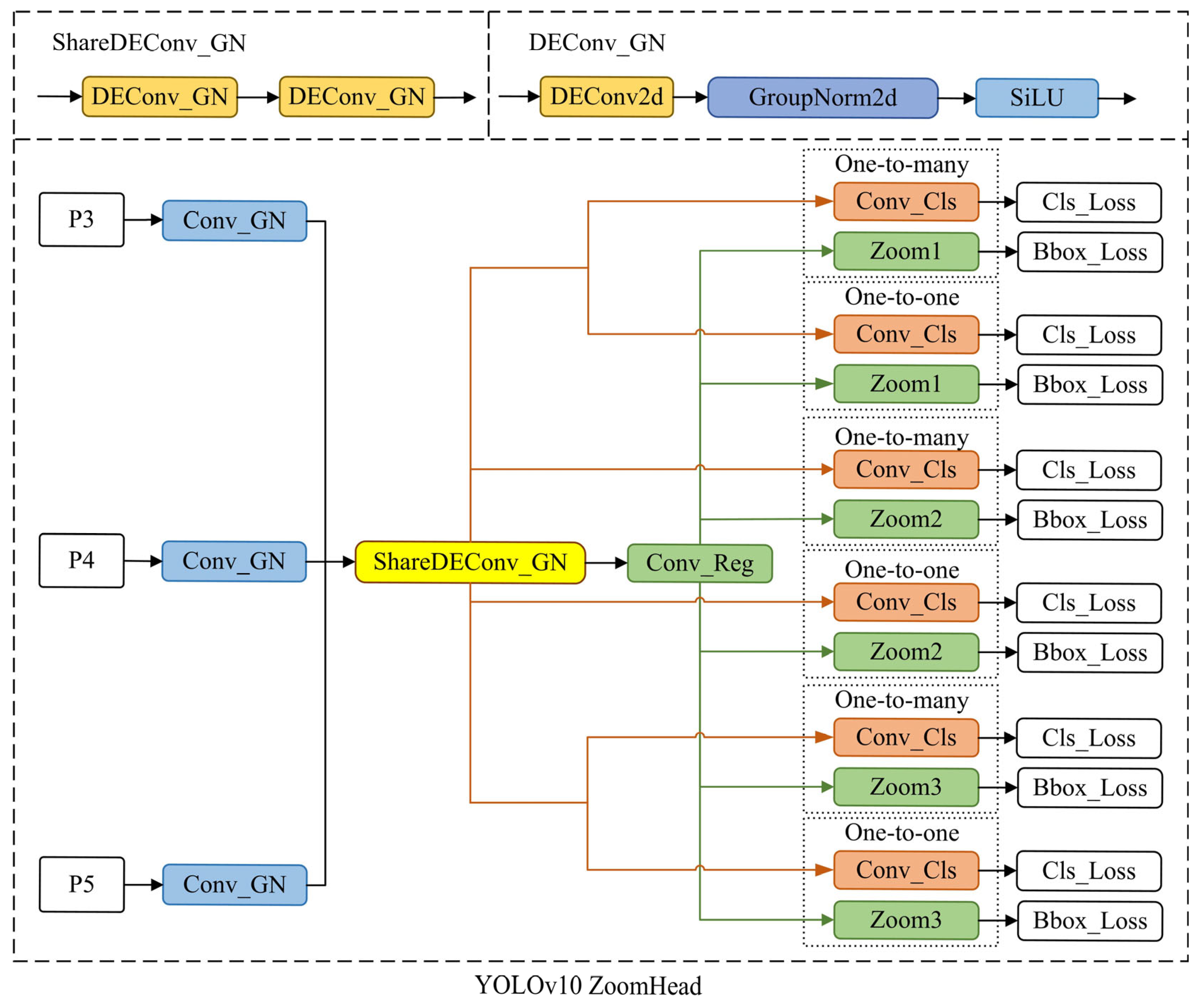
3.3. Overview of Head Structure
4. Experiments, Results, and Analysis
4.1. Experimental Setup
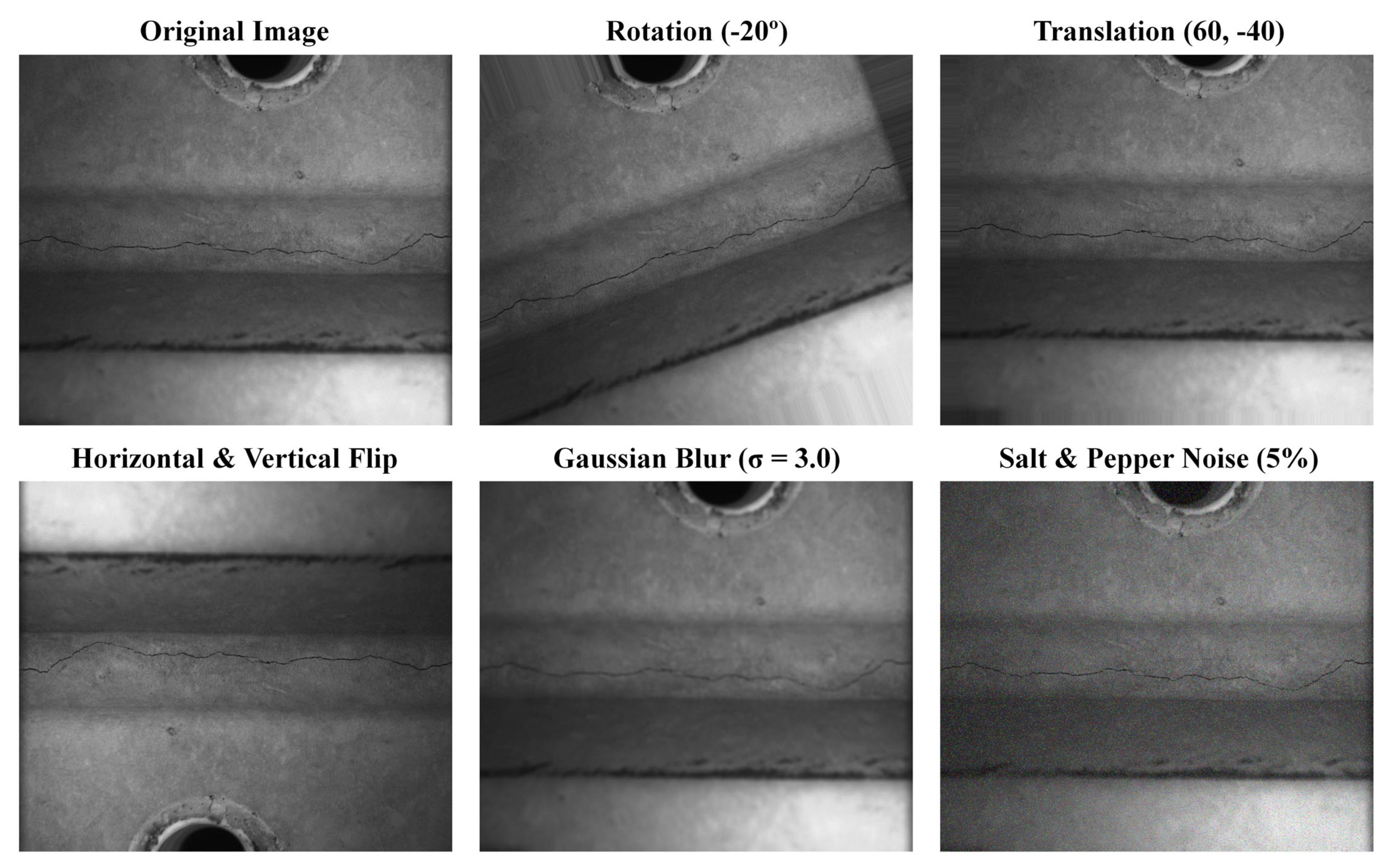
4.1.1. Dataset
4.1.2. Experiment Settings
4.1.3. Evaluation Metrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Ground Truth | ||
|---|---|---|---|
| True | False | ||
| Predicted Value | Positive | TP | FP |
| Negative | FN | TN | |
4.1.4. Baseline Models
4.2. Experimental Analysis and Verification
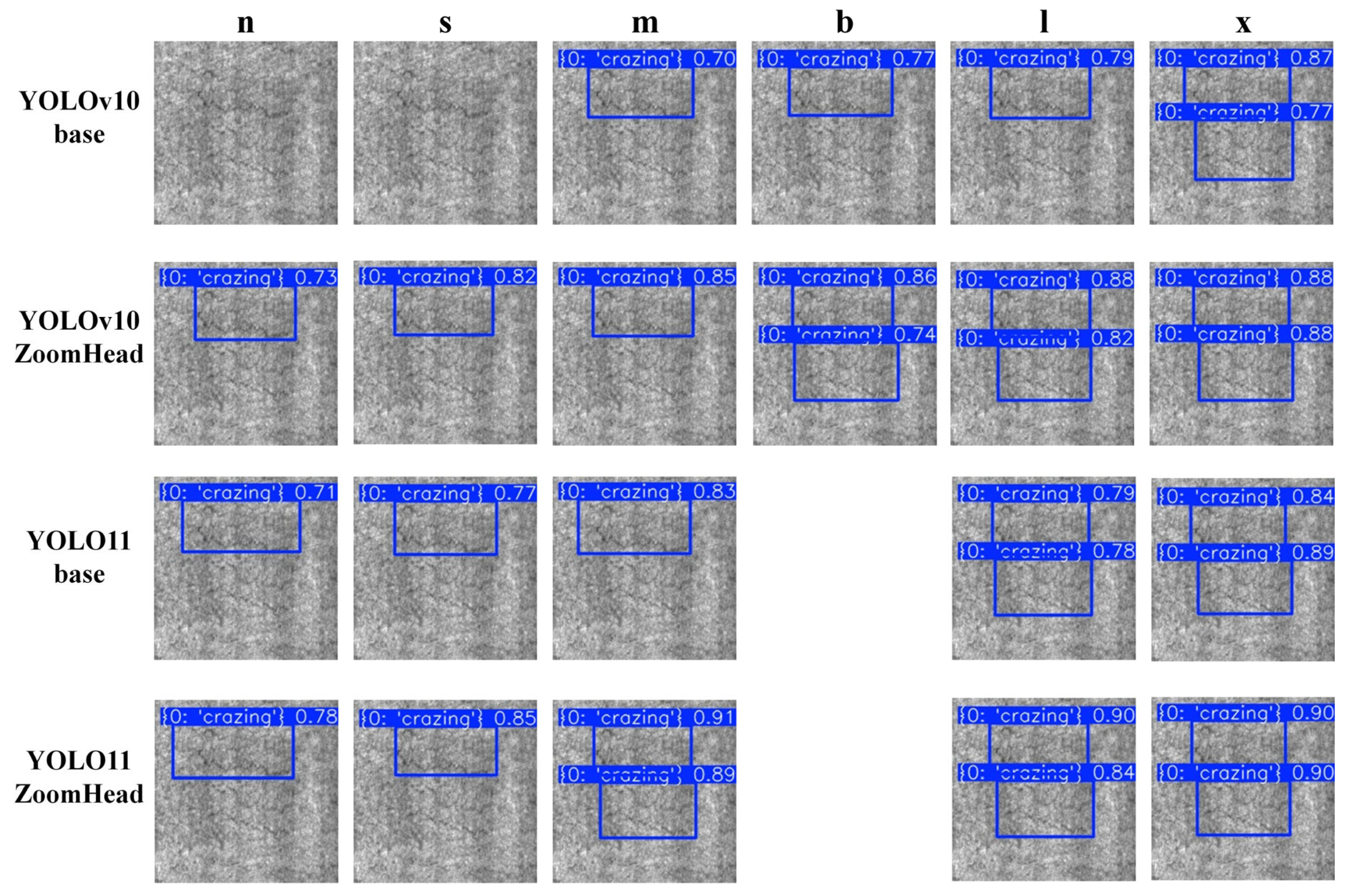
4.2.1. Comparative Experiment on Model Performance Based on Rail Surface Crack Dataset
| Model | P | R | mAP@50 | mAP@50-95 | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv10n | 0.660 | 0.589 | 0.614 | 0.316 | 2.265M | 6.5 | 719.7 |
| YOLOv10n-ZoomHead | 0.674 (↑0.014) | 0.593 (↑0.004) | 0.620 (↑0.006) | 0.325 (↑0.009) | 1.943M (↓0.322M) | 6.2 (↓0.3) | 726.4 (↑6.7) |
| YOLOv10s | 0.752 | 0.648 | 0.721 | 0.412 | 7.218M | 21.4 | 325.0 |
| YOLOv10s-ZoomHead | 0.788 (↑0.036) | 0.666 (↑0.018) | 0.734 (↑0.013) | 0.420 (↑0.008) | 6.821M (↓0.397M) | 20.8 (↓0.6) | 337.1 (↑12.1) |
| YOLOv10m | 0.776 | 0.716 | 0.746 | 0.467 | 15.314M | 58.9 | 151.8 |
| YOLOv10m-ZoomHead | 0.786 (↑0.010) | 0.729 (↑0.013) | 0.757 (↑0.011) | 0.476 (↑0.009) | 14.776M (↓0.538M) | 50.4 (↓8.5) | 154.9 (↑3.1) |
| YOLOv10b | 0.803 | 0.732 | 0.782 | 0.521 | 19.005M | 91.6 | 111.5 |
| YOLOv10b-ZoomHead | 0.829 (↑0.026) | 0.751 (↑0.019) | 0.797 (↑0.015) | 0.527 (↑0.006) | 18.624M (↓0.381M) | 87.8 (↓3.8) | 117.4 (↑5.9) |
| YOLOv10l | 0.751 | 0.742 | 0.725 | 0.470 | 24.310M | 120.0 | 88.2 |
| YOLOv10l-ZoomHead | 0.775 (↑0.024) | 0.767 (↑0.025) | 0.764 (↑0.039) | 0.499 (↑0.029) | 23.829M (↓0.481M) | 115.2 (↓4.8) | 94.6 (↑6.4) |
| YOLOv10x | 0.768 | 0.713 | 0.755 | 0.499 | 29.397M | 160.0 | 58.2 |
| YOLOv10x-ZoomHead | 0.778 (↑0.010) | 0.741 (↑0.028) | 0.773 (↑0.018) | 0.526 (↑0.027) | 29.088M (↓0.309M) | 153.6 (↓6.4) | 61.1 (↑2.9) |
| YOLO11n | 0.656 | 0.546 | 0.561 | 0.281 | 2.582M | 6.3 | 733.3 |
| YOLO11n-ZoomHead | 0.663 (↑0.007) | 0.552 (↑0.006) | 0.569 (↑0.008) | 0.288 (↑0.007) | 2.260M (↓0.322M) | 6.0 (↓0.3) | 744.1 (↑10.8) |
| YOLO11s | 0.733 | 0.626 | 0.670 | 0.369 | 9.413M | 21.3 | 309.8 |
| YOLO11s-ZoomHead | 0.743 (↑0.010) | 0.665 (↑0.039) | 0.681 (↑0.011) | 0.386 (↑0.017) | 9.015M (↓0.398M) | 20.7 (↓0.6) | 320.5 (↑10.7) |
| YOLO11m | 0.764 | 0.704 | 0.733 | 0.471 | 20.031M | 67.6 | 120.4 |
| YOLO11m-ZoomHead | 0.795 (↑0.031) | 0.726 (↑0.022) | 0.757 (↑0.024) | 0.484 (↑0.013) | 19.750M (↓0.281M) | 64.8 (↓2.8) | 125.4 (↑5.0) |
| YOLO11l | 0.801 | 0.724 | 0.751 | 0.505 | 25.281M | 80.6 | 93.5 |
| YOLO11l-ZoomHead | 0.826 (↑0.025) | 0.734 (↑0.010) | 0.763 (↑0.012) | 0.519 (↑0.014) | 25.099M (↓0.182M) | 75.7 (↓4.9) | 99.0 (↑5.5) |
| YOLO11x | 0.811 | 0.734 | 0.751 | 0.522 | 56.828M | 194.4 | 47.9 |
| YOLO11x-ZoomHead | 0.819 (↑0.008) | 0.746 (↑0.012) | 0.783 (↑0.032) | 0.554 (↑0.032) | 56.509M (↓0.319M) | 189.4 (↓5.0) | 49.5 (↑1.6) |
4.2.2. Performance Comparison Experiment of Models Based on NEU Surface Defect Database
| Model | P | R | mAP@50 | mAP@50-95 |
|---|---|---|---|---|
| YOLOv10n | 0.742 | 0.693 | 0.735 | 0.393 |
| YOLOv10n-ZoomHead | 0.787 (↑0.045) | 0.702 (↑0.009) | 0.767 (↑0.032) | 0.412 (↑0.019) |
| YOLOv10s | 0.739 | 0.689 | 0.738 | 0.403 |
| YOLOv10s-ZoomHead | 0.798 (↑0.059) | 0.707 (↑0.018) | 0.762 (↑0.024) | 0.419 (↑0.016) |
| YOLOv10m | 0.702 | 0.693 | 0.727 | 0.407 |
| YOLOv10m-ZoomHead | 0.727 (↑0.025) | 0.711 (↑0.018) | 0.744 (↑0.017) | 0.404 (↓0.003) |
| YOLOv10b | 0.762 | 0.705 | 0.744 | 0.400 |
| YOLOv10b-ZoomHead | 0.742 (↓0.020) | 0.707 (↑0.002) | 0.752 (↑0.008) | 0.418 (↑0.018) |
| YOLOv10l | 0.762 | 0.660 | 0.745 | 0.399 |
| YOLOv10l-ZoomHead | 0.753 (↓0.009) | 0.664 (↑0.004) | 0.737 (↓0.008) | 0.407 (↑0.008) |
| YOLOv10x | 0.711 | 0.684 | 0.744 | 0.411 |
| YOLOv10x-ZoomHead | 0.779 (↑0.068) | 0.684 | 0.754 (↑0.010) | 0.417 (↑0.006) |
| YOLO11n | 0.695 | 0.744 | 0.748 | 0.416 |
| YOLO11n-ZoomHead | 0.734 (↑0.039) | 0.762 (↑0.018) | 0.762 (↑0.014) | 0.422 (↑0.006) |
| YOLO11s | 0.789 | 0.693 | 0.755 | 0.428 |
| YOLO11s-ZoomHead | 0.811 (↑0.022) | 0.691 (↓0.002) | 0.759 (↑0.004) | 0.444 (↑0.016) |
| YOLO11m | 0.742 | 0.710 | 0.757 | 0.416 |
| YOLO11m-ZoomHead | 0.769 (↑0.027) | 0.740 (↑0.030) | 0.776 (↑0.019) | 0.423 (↑0.007) |
| YOLO11l | 0.727 | 0.731 | 0.765 | 0.422 |
| YOLO11l-ZoomHead | 0.763 (↑0.036) | 0.75 (↑0.019) | 0.779 (↑0.014) | 0.429 (↑0.007) |
| YOLO11x | 0.775 | 0.687 | 0.759 | 0.409 |
| YOLO11x-ZoomHead | 0.770 (↓0.005) | 0.688 (↑0.001) | 0.770 (↑0.011) | 0.419 (↑0.010) |
| Model | All | Crazing | Patches | Inclusion | Pitted Surface | Rolled-in Scale | Scratches |
|---|---|---|---|---|---|---|---|
| YOLOv10m-base | 0.407 | 0.157 | 0.53 | 0.392 | 0.565 | 0.235 | 0.563 |
| YOLOv10m-ZoomHead | 0.404 | 0.152 | 0.541 | 0.396 | 0.534 | 0.223 | 0.575 |
| Model | All | Crazing | Patches | Inclusion | Pitted Surface | Rolled-in Scale | Scratches |
|---|---|---|---|---|---|---|---|
| YOLOv10m-base | 0.399 | 0.171 | 0.486 | 0.403 | 0.502 | 0.238 | 0.594 |
| YOLOv10m-ZoomHead | 0.407 | 0.169 | 0.517 | 0.426 | 0.490 | 0.236 | 0.601 |
4.3. Ablation Studies
4.3.1. Ablation Experiment Based on Rail Surface Crack Dataset
| Model | GN | DEConv | Zoom | mAP@50 | mAP@50-95 | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv10x | 0.755 | 0.499 | 29.397M | 160.0 | 58.2 | |||
| ✓ | 0.765 (↑0.010) | 0.511 (↑0.012) | 29.405M (↑0.007M) | 160.8 (↑0.8) | 58.0 (↓0.2) | |||
| ✓ | ✓ | 0.775 (↑0.020) | 0.527 (↑0.028) | 29.422M (↑0.025M) | 162.1(↑2.1) | 56.8 (↓1.4) | ||
| ✓ | ✓ | ✓ | 0.773 (↑0.018) | 0.526 (↑0.027) | 29.088M (↓0.309M) | 153.6 (↓6.4) | 61.1 (↑2.9) | |
| YOLO11x | 0.751 | 0.522 | 56.828M | 194.4 | 47.9 | |||
| ✓ | 0.766 (↑0.015) | 0.535 (↑0.013) | 56.836M (↑0.008M) | 194.9 (↑0.5) | 47.2 (↓0.7) | |||
| ✓ | ✓ | 0.784 (↑0.033) | 0.554 (↑0.032) | 57.101M (↑0.273M) | 196.5 (↑2.1) | 45.5 (↓2.4) | ||
| ✓ | ✓ | ✓ | 0.783 (↑0.032) | 0.554 (↑0.032) | 56.509M (↓0.319M) | 189.4 (↓5.0) | 49.5 (↑1.6) |
4.3.2. Ablation Experiment Based on NEU Surface Defect Database
| Model | GN | DEConv | Zoom | mAP@50 | mAP@50-95 |
|---|---|---|---|---|---|
| YOLOv10x | 0.744 | 0.411 | |||
| ✓ | 0.748 (↑0.004) | 0.412 (↑0.001) | |||
| ✓ | ✓ | 0.751 (↑0.007) | 0.416 (↑0.005) | ||
| ✓ | ✓ | ✓ | 0.754 (↑0.010) | 0.417 (↑0.006) | |
| YOLO11x | 0.759 | 0.409 | |||
| ✓ | 0.766 (↑0.007) | 0.411 (↑0.002) | |||
| ✓ | ✓ | 0.769 (↑0.010) | 0.418 (↑0.009) | ||
| ✓ | ✓ | ✓ | 0.770 (↑0.011) | 0.419 (↑0.010) |
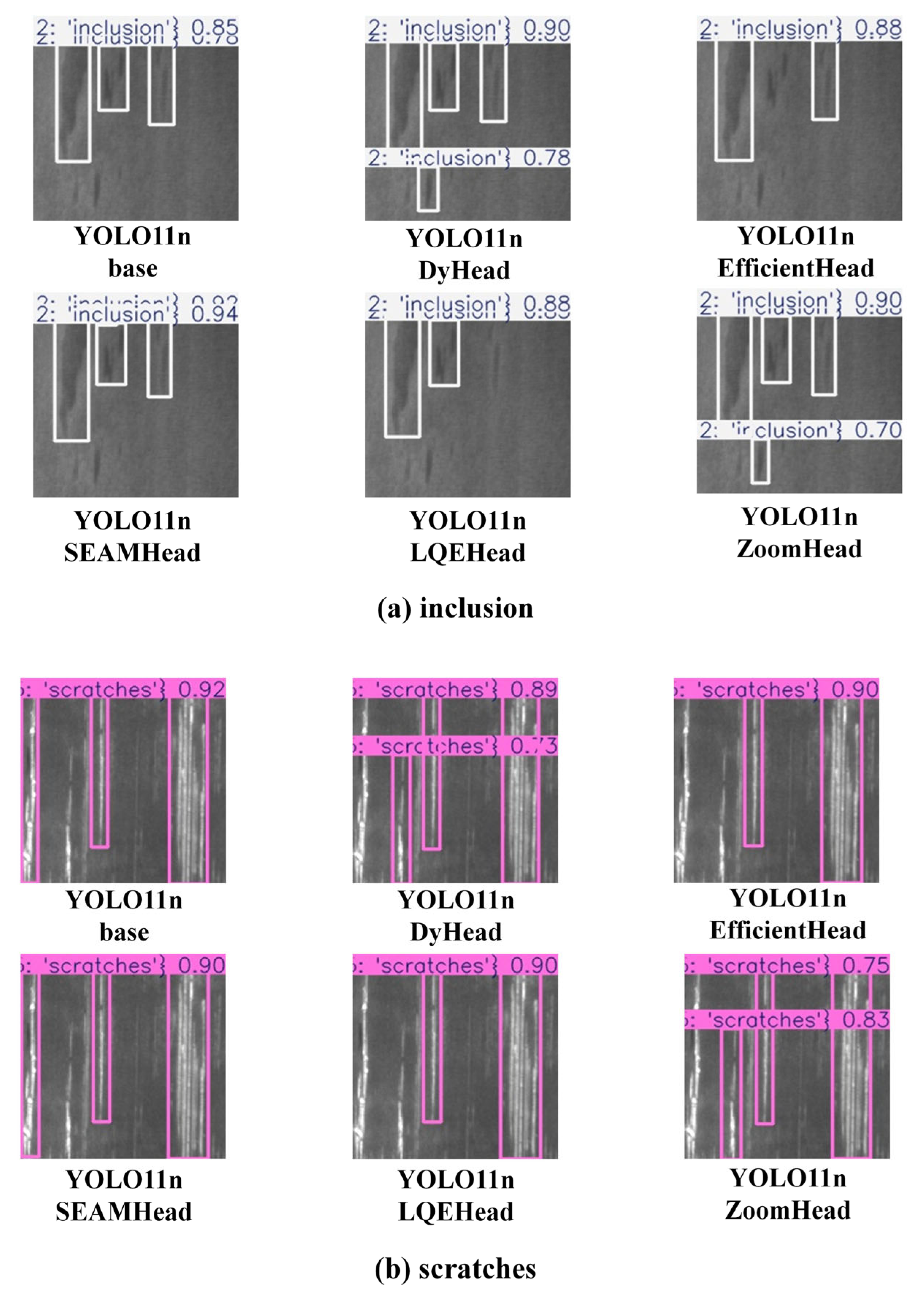
4.4. Comparative Experiment with SOTA Model
4.4.1. Comparative Experiment Based on Rail Surface Crack Dataset
| Model | mAP@50 | mAP@50-95 | Params | GFLOPs | FPS |
|---|---|---|---|---|---|
| YOLO11n-base | 0.561 | 0.281 | 2.582M | 6.3 | 733.3 |
| YOLO11n-DyHead | 0.570 (↑0.009) | 0.289 (↑0.008) | 3.099M (↑0.517M) | 7.4 (↑1.1) | 307.3 (↓426.0) |
| YOLO11n-EfficientHead | 0.555 (↓0.006) | 0.272 (↓0.009) | 2.312M (↓0.270M) | 5.1 (↓1.2) | 710.9 (↓22.4) |
| YOLO11n-SEAMHead | 0.565 (↑0.004) | 0.285 (↑0.004) | 2.491M (↓0.091M) | 5.8 (↓0.5) | 682.3 (↓51.0) |
| YOLO11n-LQEHead | 0.558 (↓0.003) | 0.275 (↓0.006) | 2.587M (↑0.005M) | 6.3 | 624.9 (↓108.4) |
| YOLO11n-ZoomHead | 0.569 (↑0.008) | 0.288 (↑0.007) | 2.260M (↓0.322M) | 6.0 (↓0.3) | 744.1 (↑10.8) |
4.4.2. Comparative Experiment Based on NEU Surface Defect Database
| Model | mAP@50 | mAP@50-95 |
|---|---|---|
| YOLOv11n-base | 0.748 | 0.416 |
| YOLOv11n-DyHead | 0.755 (↑0.011) | 0.419 (↑0.003) |
| YOLOv11n-EfficientHead | 0.747 (↓0.001) | 0.416 |
| YOLOv11n-SEAMHead | 0.752 (↑0.004) | 0.421 (↑0.005) |
| YOLOv11n-LQEHead | 0.742 (↓0.006) | 0.411 (↓0.005) |
| YOLOv11n-ZoomHead | 0.772 (↑0.024) | 0.422 (↑0.006) |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, Q.; Qin, X.; Xiong, X. Investigating the effects of data and image enhancement techniques on crack detection accuracy in FMPI. Adv. Eng. Inform. 2025, 65, 103169. [Google Scholar] [CrossRef]
- Lei, Z.; Zhou, Y.; Xue, X.; Su, Y.; Wen, G.; Zhang, Z.; Chen, X. Eddy current testing in nickel-based superalloy turbine blades: Finite element modeling and tiny crack defects analysis. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2025. [Google Scholar] [CrossRef]
- Yang, F.; Wang, F.; Li, R.; Sfarra, S.; Xu, L.; Yang, Y.; Liu, L.; Yue, H.; Liu, J. Research on flexible ultrasonic infrared detection of crack defects in irregular metal components. Infrared Phys. Technol. 2025, 146, 105755. [Google Scholar] [CrossRef]
- Ma, X.; Kang, Z.; Pu, C.; Lin, Z.; Niu, M.; Wang, J. Stamping part surface crack detection based on machine vision. Measurement 2025, 251, 117168. [Google Scholar] [CrossRef]
- Guclu, E.; Aydin, I.; Akin, E. Enhanced defect detection on steel surfaces using integrated residual reffnement module with synthetic data augmentation. Measurement 2025, 250, 117136. [Google Scholar] [CrossRef]
- Hou, X.; Zeng, H.; Jia, L.; Peng, J.; Wang, W. MobGSim-YOLO: Mobile Device Terminal-Based Crack Hole Detection Model for Aero-Engine Blades. Aerospace 2024, 11, 676. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, S.; Xiang, Y.; Zhu, Z. Crack Defect Detection Processing Algorithm and Method of MEMS Devices Based on Image Processing Technology. IEEE Access 2023, 11, 126323–126334. [Google Scholar] [CrossRef]
- Muhammad, Z.; Sahil, J.; Enrique, N.; Bhagwan, D.; Samreen, H.; Bhawani, S. FaultSeg: A Dataset for train Wheel Defect Detection. Sci. Data 2025, 12, 309. [Google Scholar]
- Liu, T.; Gu, M.; Sun, S. RIEC-YOLO: An improved road defect detection model based on YOLOv8. Signal Image Video Process. 2025, 19, 285. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Wang, Y.; Li, D. Adaptive dense pyramid network for object detection in UAV imagery. Neurocomputing 2022, 489, 377–389. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentatio. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Berg, A.; Fu, C.; Szegedy, C. SSD: Single Shot Multi-Box Detector; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Su, Y.; Yan, P.; Yi, R.; Chen, J.; Hu, J.; Wen, C. A cascaded combination method for defect detection of metal gear end-face. J. Manuf. Syst. 2022, 63, 439–453. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Wan, Z. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 108208. [Google Scholar] [CrossRef]
- Wu, R.; Zhou, F.; Li, N.; Liu, H.; Guo, N.; Wang, R. Enhanced You Only Look Once X for surface defect detection of strip steel. Front. Neurorobotics 2022, 16, 1042780. [Google Scholar] [CrossRef]
- Hu, H.; Zhu, Z. Sim-YOLOv5s: A method for detecting defects on the end face of lithium battery steel shells. Adv. Eng. Inform. 2023, 55, 101824. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Y.; Sun, J.; Ji, R.; Zhang, P.; Shan, H. Surface defect detection of wind turbine based on lightweight YOLOv5s model. Measurement 2023, 220, 113222. [Google Scholar] [CrossRef]
- Yan, R.; Zhang, R.; Bai, J.; Hao, H.; Guo, W.; Gu, X.; Liu, Q. STMS-YOLOv5: A Lightweight Algorithm for Gear Surface Defect Detection. Sensors 2023, 23, 5992. [Google Scholar] [CrossRef]
- Ma, Z.; Li, Y.; Huang, M.; Huang, Q.; Cheng, J.; Tang, S. A lightweight detector based on attention mechanism for aluminum strip surface defect detection. Comput. Ind. 2022, 136, 103585. [Google Scholar] [CrossRef]
- Ni, Y.; Wu, Q.; Zhang, X. FMR-YOLO: An improved YOLOv8 algorithm for steel surface defect detection. IET Image Process. 2025, 19, e70009. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly Kernel Inception Network for Remote Sensing Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 27706–27716. [Google Scholar]
- Huang, X.; Zhu, J.; Huo, Y. SSA-YOLO: An Improved YOLO for Hot-Rolled Strip Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2024, 73, 5040017. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, S.; Abdullahi, H.; Gao, S.; Zhang, H.; Chen, X.; Zhao, H. Multiclass small target detection algorithm for surface defects of chemicals special steel. Front. Phys. 2024, 12, 1451165. [Google Scholar] [CrossRef]
- Liang, Y.; Feng, S.; Zhang, Y.; Xue, F.; Shen, F.; Guo, J. A stable diffusion enhanced YOLOV5 model for metal stamped part defect detection based on improved network structure. J. Manuf. Process. 2024, 111, 21–31. [Google Scholar] [CrossRef]
- Chen, F.; Deng, M.; Gao, H.; Yang, X.; Zhang, D. NHD-YOLO: Improved YOLOv8 using optimized neck and head for product surface defect detection with data augmentation. IET Image Process. 2024, 18, 1915–1926. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, L.; Lei, G.; Guo, C.; Qiang, M. Lightweight UAV Small Target Detection and Perception Based on Improved YOLOv8-E. Drones 2024, 8, 681. [Google Scholar] [CrossRef]
- Chen, Z.; He, Z.; Lu, Z. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defect. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Wang, H.; Tan, F.; Bai, Z. LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field. arXiv 2024, arXiv:2409.18057. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W. Yolo-facev2: A scale and occlusion aware face detector. arXiv 2022, arXiv:2208.02019. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11632–11641. [Google Scholar]





| Model | Head | All |
|---|---|---|
| YOLOv5n | 3.64 (47.3%) | 7.7 |
| YOLOv8n | 3.64 (41.8%) | 8.7 |
| YOLOv10n | 3.8 (56.7%) | 6.7 |
| YOLO11n | 1.9 (29.2%) | 6.5 |
| Category | Detail Information |
|---|---|
| CPU | Intel(R) Xeon(R) E5-2698v3 |
| GPU | Tesla V100 16 GB × 2 |
| RAM | 64 GB |
| Operating System | Ubuntu 22.04 |
| Operating Environment | Anaconda3, CUDA12.1, Python3.9 |
| Deep Learning Framework | PyTorch 2.2.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yang, F.; Huo, J.; Gao, Q.; Deng, S.; Guo, C. ZoomHead: A Flexible and Lightweight Detection Head Structure Design for Slender Cracks. Sensors 2025, 25, 3990. https://doi.org/10.3390/s25133990
Li H, Yang F, Huo J, Gao Q, Deng S, Guo C. ZoomHead: A Flexible and Lightweight Detection Head Structure Design for Slender Cracks. Sensors. 2025; 25(13):3990. https://doi.org/10.3390/s25133990
Chicago/Turabian StyleLi, Hua, Fan Yang, Junzhou Huo, Qiang Gao, Shusen Deng, and Chang Guo. 2025. "ZoomHead: A Flexible and Lightweight Detection Head Structure Design for Slender Cracks" Sensors 25, no. 13: 3990. https://doi.org/10.3390/s25133990
APA StyleLi, H., Yang, F., Huo, J., Gao, Q., Deng, S., & Guo, C. (2025). ZoomHead: A Flexible and Lightweight Detection Head Structure Design for Slender Cracks. Sensors, 25(13), 3990. https://doi.org/10.3390/s25133990