
Multi-Area, Multi-Service and Multi-Tier Edge-Cloud Continuum Planning

 and
and 
Abstract
1. Introduction
- Planning of a regional edge–cloud system, where multiple services from various end devices across multiple areas, multiple types of processing nodes, and multiple CC tiers coexist in the same concept. The type of computing nodes, their number, and their allocation in the CC based on service’s requirements and network capacity is chosen. We model the CC system as a hierarchical tree-based system where services’ request flow is one-way, directed from end devices to the cloud.
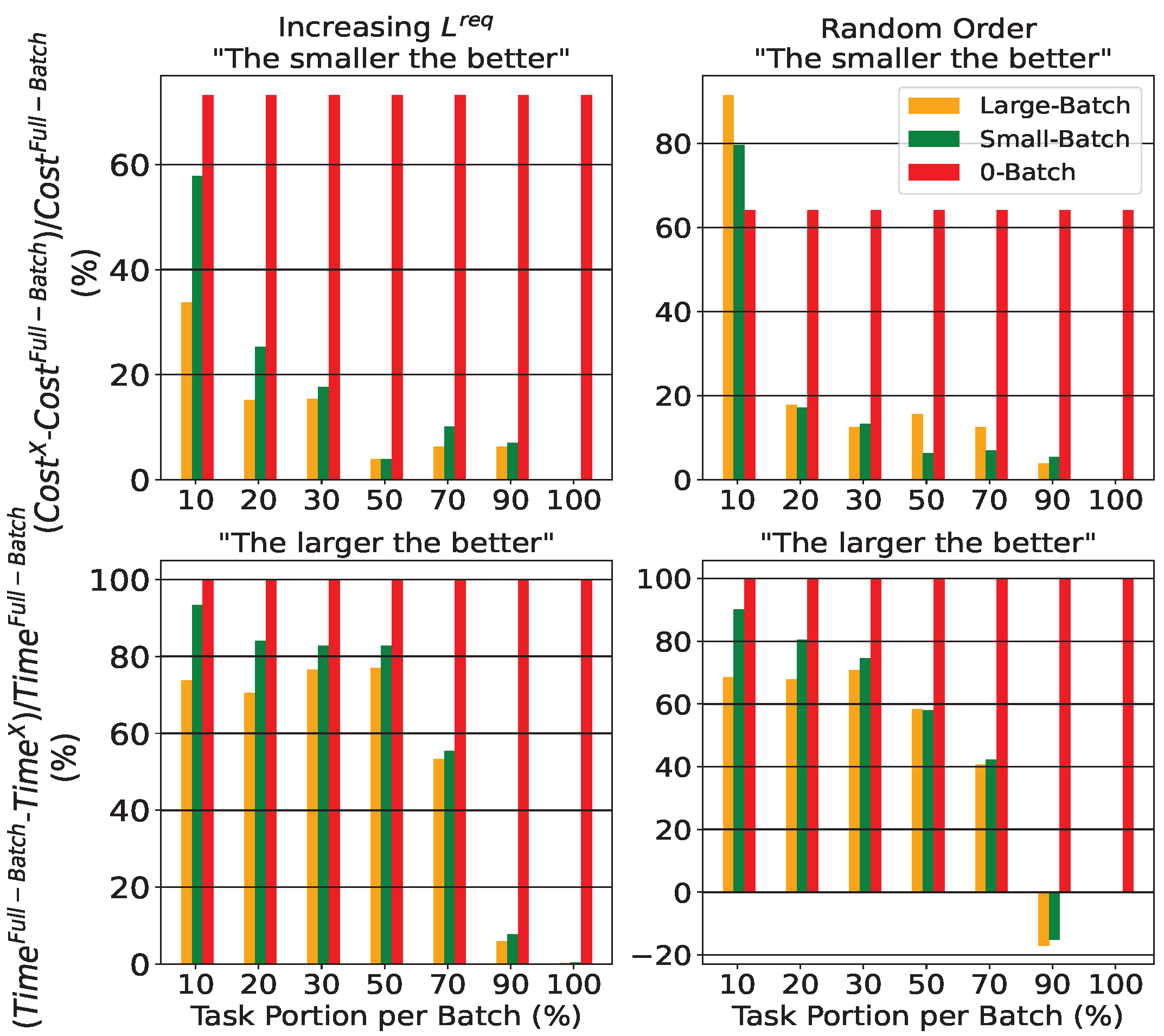
- Two strategies are proposed to manage the computational complexity of the method that processes all tasks simultaneously (referred to as Full-Batch). A batch-based approach (assuming two different heuristics), configuring resources iteratively for smaller task groups, and a per-task allocation method that optimizes resources individually, enhances efficiency, and reduces time complexity in resource configuration. For the batch-based approaches two different concepts are provided: (a) the Large-Batch framework that has ‘memory’ of already used processing devices from previously allocated tasks and (b) the memoryless Small-Batch framework adding new processing devices to execute the tasks of the current batch.
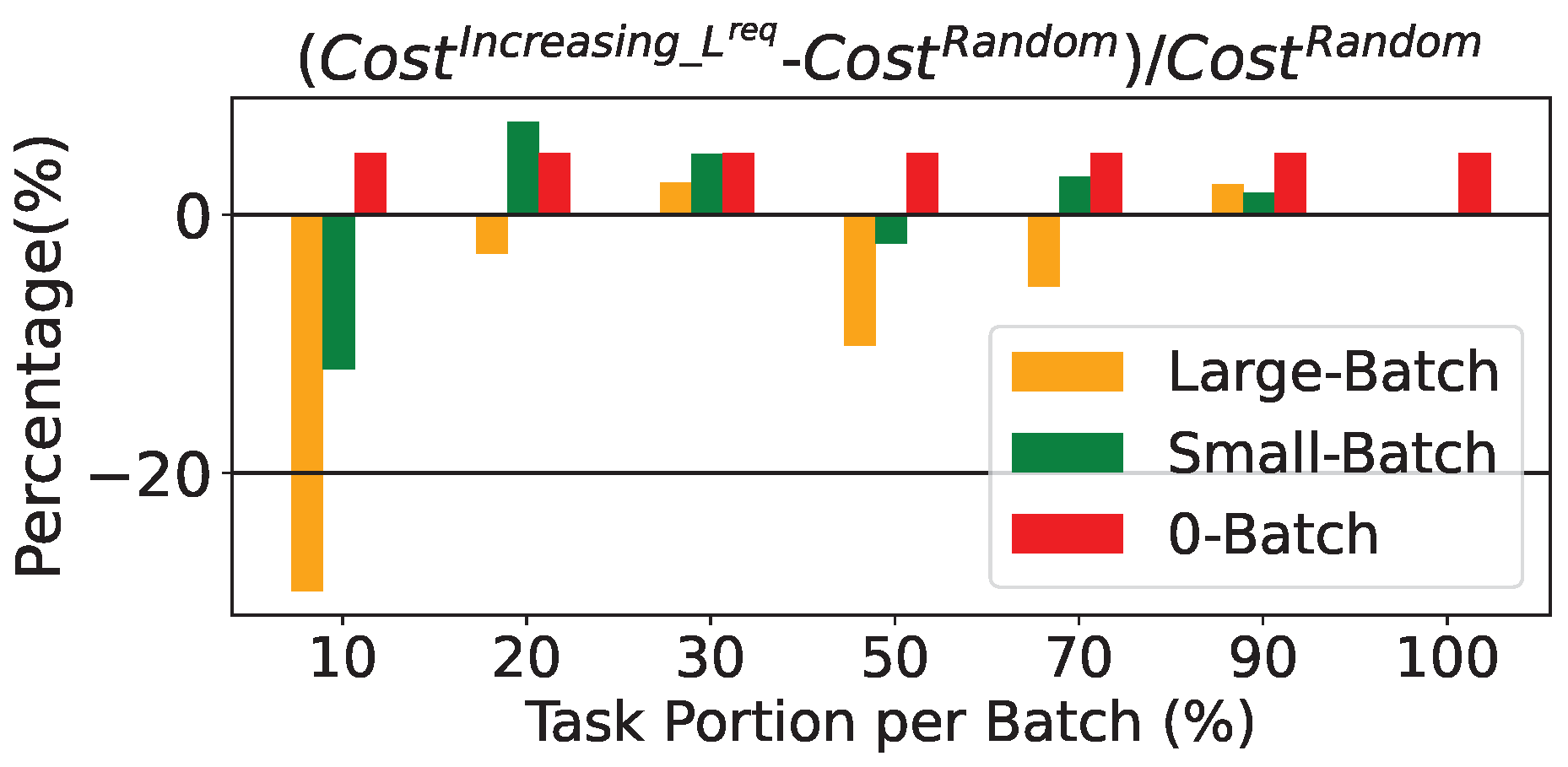
- Unlike the Full-Batch scheme, which considers all tasks simultaneously, the other methods depend on the order of the tasks. The importance of task selection in each group is shown through the comparison between different ordering approaches, some of which are K-means and Agglomerative clustering methods. Based on the simulations, random task ordering provides better results in most cases. This could be explained by the fact that random selection of tasks better reflects the overall task mixture compared to fixed selection rules, leading to improved performance in batch-based approaches.
- Finally, service providers responsible for designing the system can use the proposed schemes to plan the compute continuum offline. Our findings help guide key design choices—such as the type of optimization strategy, the number of tasks processed at once, and their order. Specifically, our strategies highlight the trade-off between solution quality and computational efficiency. The Full-Batch approach, which processes all tasks together, offers the best performance but requires significant resources. In contrast, group-based schemes are more time-efficient and still effective—especially with medium-sized groups. Additionally, random task ordering often leads to better results, likely because each batch maintains a distribution similar to the original task set. These insights suggest promising directions for addressing the complex offline task planning in the edge–cloud environments, including the selection of batch’s size and tasks’ ordering.
2. Related Work
3. System Model
3.1. Scenario Setup
3.2. Problem Formulation
3.3. Heuristic Approaches
4. Simulation Results and Discussion
4.1. Simulated Scenarios
4.2. Performance Analysis of the Proposed Schemes
4.3. Further Analysis of Task Ordering Schemes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| AR | Augmented reality |
| BINLP | Binary non-linear programming |
| CC | Compute continuum |
| CD | Compute device |
| DML | Distributed machine learning |
| DRL | Deep reinforcement learning |
| E2E | End-to-end |
| ED | End device |
| GPON | Gigabyte passive optical network |
| ILP | Integer linear programming |
| IoT | Internet of Things |
| ML | Machine learning |
| OD | Object detection |
| PC | Personal computer |
| PD | Pose detection |
| PL | Processing layer |
| S2T | Speech-to-text |
| SP | Service provider |
| TOPS | Tera operations per second |
| UAV | Unmanned aerial vehicle |
| UL | Uplink |
References
- Gkonis, P.; Giannopoulos, A.; Trakadas, P.; Masip-Bruin, X.; D’Andria, F. A Survey on IoT-Edge-Cloud Continuum Systems: Status, Challenges, Use Cases, and Open Issues. Future Internet 2023, 11, 383. [Google Scholar] [CrossRef]
- EU. 2023 Report on the State of the Digital Decade. Available online: https://digital-strategy.ec.europa.eu/en/library/2023-report-state-digital-decade (accessed on 23 June 2025).
- Raeisi-Varzaneh, M.; Dakkak, O.; Habbal, A.; Kim, B.-S. Resource Scheduling in Edge Computing: Architecture, Taxonomy, Open Issues and Future Research Directions. IEEE Access 2023, 11, 25329–25350. [Google Scholar] [CrossRef]
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Pettorali, M.; Righetti, F.; Vallati, C.; Das, S.K.; Anastasi, G. J-NECORA: A Framework for Optimal Resource Allocation in Cloud–Edge–Things Continuum for Industrial Applications With Mobile Nodes. IEEE Internet Things J. 2025, 12, 16525–16542. [Google Scholar] [CrossRef]
- Mihaiu, M.; Mocanu, B.-C.; Negru, C.; Petrescu-Niță, A.; Pop, F. Resource Allocation Optimization Model for Computing Continuum. Mathematics 2025, 13, 431. [Google Scholar] [CrossRef]
- Sonkoly, B.; Czentye, J.; Szalay, M.; Németh, B.; Toka, L. Survey on Placement Methods in the Edge and Beyond. IEEE Commun. Surv. Tutor. 2021, 23, 2590–2629. [Google Scholar] [CrossRef]
- Puliafito, C.; Cicconetti, C.; Conti, M.; Mingozzi, E.; Passarella, A. Balancing local vs. remote state allocation for micro-services in the cloud–edge continuum. Pervasive Mob. Comput. 2023, 93, 101808. [Google Scholar] [CrossRef]
- Malazi, H.T.; Chaudhry, S.R.; Kazmi, A.; Palade, A.; Cabrera, C.; White, G.; Clarke, S. Dynamic Service Placement in Multi-Access Edge Computing: A Systematic Literature Review. IEEE Access 2022, 10, 32639–32688. [Google Scholar] [CrossRef]
- Wang, K.; Jin, J.; Yang, Y.; Zhang, T.; Arumugam, N.; Chintha, T.; Bijan, J. Task Offloading With Multi-Tier Computing Resources in Next Generation Wireless Networks. IEEE J. Sel. Areas Commun. 2023, 41, 306–319. [Google Scholar] [CrossRef]
- Tong, L.; Li, Y.; Gao, W. A hierarchical edge cloud architecture for mobile computing. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), San Francisco, CA, USA, 10–14 April 2016. [Google Scholar]
- Kouloumpris, A.; Stavrinides, G.L.; Michael, M.K.; Theocharides, T. An optimization framework for task allocation in the edge/hub/cloud paradigm. Future Gener. Comput. Syst. 2024, 155, 354–366. [Google Scholar] [CrossRef]
- Soumplis, P.; Kontos, G.; Kokkinos, P.; Kretsis, A.; Barrachina-Muñoz, S.; Nikbakht, R.; Baranda, J.; Payaró, M.; Mangues-Bafalluy, J.; Varvarigos, E. Performance Optimization Across the Edge-Cloud Continuum: A Multi-agent Rollout Approach for Cloud-Native Application Workload Placement. SN Comput. Sci. 2024, 5, 318. [Google Scholar] [CrossRef]
- Cozzolino, V.; Tonetto, L.; Mohan, N.; Ding, A.Y.; Ott, J. Nimbus: Towards latency-energy efficient task offloading for ar services. IEEE Trans. Cloud Comput. 2023, 11, 1530–1545. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Opadere, J.; Han, T. An edge network orchestrator for mobile augmented reality. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Honolulu, HI, USA, 15–19 April 2018. [Google Scholar]
- Sartzetakis, I.; Soumplis, P.; Pantazopoulos, P.; Katsaros, K.V.; Sourlas, V.; Varvarigos, E. Edge/Cloud Infinite-Time Horizon Resource Allocation for Distributed Machine Learning and General Tasks. IEEE Trans. Netw. Serv. Manag. 2024, 21, 697–713. [Google Scholar] [CrossRef]
- Ullah, I.; Lim, H.K.; Seok, Y.J.; Han, Y.H. Optimizing task offloading and resource allocation in edge-cloud networks: A DRL approach. J. Cloud Comput. 2023, 12, 112. [Google Scholar] [CrossRef]
- Qin, Y.; Chen, J.; Jin, L.; Yao, R.; Gong, Z. Task offloading optimization in mobile edge computing based on a deep reinforcement learning algorithm using density clustering and ensemble learning. Sci. Rep. 2025, 15, 211. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Roumeliotis, A.J.; Kosmatos, E.; Katsaros, K.V.; Amditis, A.J. Multi-Service And Multi-Tier Edge-Cloud Continuum Planning. In Proceedings of the 2024 7th International Conference on Advanced Communication Technologies and Networking (CommNet), Rabat, Morocco, 4–6 December 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Karp, R.M. On the computational complexity of combinatorial problems. Networks 1975, 5, 45–68. [Google Scholar] [CrossRef]
- Singh, R.; Gill, S.S. Edge AI: A survey. Internet Things Cyber-Phys. Syst. 2023, 3, 71–92. [Google Scholar] [CrossRef]
- Firouzi, F.; Farahani, B.; Marinšek, A. The convergence and interplay of edge, fog, and cloud in the AI-driven Internet of Things (IoT). Inf. Syst. 2022, 107, 101840. [Google Scholar] [CrossRef]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark analysis of representative deep neural network architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Reddi, V.J.; Cheng, C.; Kanter, D.; Mattson, P.; Schmuelling, G.; Wu, C.; Anderson, B.; Breughe, M.; Charlebois, M.; Chou, W.; et al. Mlperf inference benchmark. In Proceedings of the ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Virtual, 30 May–3 June 2020. [Google Scholar]
- Zhang, X.; Debroy, S. Resource management in mobile edge computing: A comprehensive survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Huawei. 5G ToB Service Experience Standard. White Paper. 2021. Available online: https://carrier.huawei.com/~/media/cnbgv2/download/products/servies/5g-b2b-service-experience-standard-white-paper-en1.pdf (accessed on 23 June 2025).
- Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual. Available online: https://www.gurobi.com (accessed on 23 June 2025).
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| System Parameters (Known) | |
| L | Number of processing layers in the cloud continuum |
| Processing layer z in area a | |
| Number of processing layers (except extreme layer) in each area | |
| Number of end devices | |
| S | Number of different services |
| A | Number of areas |
| N | Number of different types of computing devices |
| Indices | |
| d | Index for end devices, |
| s | Index for services, |
| a | Index for areas, |
| j | Index for computing device types, |
| z | Index for processing layers, |
| Replication indices for devices, services, and areas, respectively | |
| Decision Variables (To be computed) | |
| Binary variable: 1 if s task of d ED is served at z level by device | |
| Binary indicator (based on f): 1 if task is executed at layer z | |
| System Matrices (Known) | |
| Binary matrix of dimensions indicating service allocation | |
| Binary matrix of dimensions for processing device-layer allocation | |
| Network Parameters | |
| Data rate from end device d for service s in area a (Known) | |
| Network capacity of links connecting layers and z (for ) (Known) | |
| Network capacity for area a of links connecting layers and z (for ) (Known) | |
| Network transmission latency for service s connecting layers and z in area a (Known) | |
| Total network latency for task (To be computed) | |
| Computing Resources and Latency | |
| Processing (inference) latency for service s on device type j (Known) | |
| Total computation latency for task (To be computed) | |
| CPU resource consumption (%) for service s on device type j (Known) | |
| GPU resource consumption (%) for service s on device type j (Known) | |
| Latency Requirements and Constraints | |
| Maximum tolerable service latency for task (Known) | |
| Total end-to-end latency (based on the solution f) for task (To be computed) | |
| Objective Function | |
| Cost of computing device type j (Known) | |
| Number of type j devices used at layer z in area a (for ) (To be computed) | |
| Number of type j devices used at layer z (for ) (To be computed) | |
| Devices | CC Layer | Metrics (Inference, CPU, GPU) | Source |
|---|---|---|---|
| Raspberry Pi 4 | Extreme, Far | Measured | https://xgain-project.eu/ |
| Nvidia Jetson Xavier | Extreme, Far | Measured | https://xgain-project.eu/ |
| Nvidia Jetson AGX Orin | Extreme, Far | Related to | https://developer.nvidia.com/embedded/downloads (accessed on 23 June 2025) |
| RTX System (PC + RTX 3090) | Near, Cloud | Measured | https://xgain-project.eu/ |
| NVIDIA A100 GPU | Near, Cloud | Related to | https://www.nvidia.com/en-eu/data-center/a100/ (accessed on 23 June 2025) |
| NVIDIA L4 GPU | Near, Cloud | Related to | https://resources.nvidia.com/l/en-us-gpu (accessed on 23 June 2025) |
| NVIDIA H100 GPU | Near, Cloud | Related to | https://resources.nvidia.com/l/en-us-gpu (accessed on 23 June 2025) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roumeliotis, A.J.; Myritzis, E.; Kosmatos, E.; Katsaros, K.V.; Amditis, A.J. Multi-Area, Multi-Service and Multi-Tier Edge-Cloud Continuum Planning. Sensors 2025, 25, 3949. https://doi.org/10.3390/s25133949
Roumeliotis AJ, Myritzis E, Kosmatos E, Katsaros KV, Amditis AJ. Multi-Area, Multi-Service and Multi-Tier Edge-Cloud Continuum Planning. Sensors. 2025; 25(13):3949. https://doi.org/10.3390/s25133949
Chicago/Turabian StyleRoumeliotis, Anargyros J., Efstratios Myritzis, Evangelos Kosmatos, Konstantinos V. Katsaros, and Angelos J. Amditis. 2025. "Multi-Area, Multi-Service and Multi-Tier Edge-Cloud Continuum Planning" Sensors 25, no. 13: 3949. https://doi.org/10.3390/s25133949
APA StyleRoumeliotis, A. J., Myritzis, E., Kosmatos, E., Katsaros, K. V., & Amditis, A. J. (2025). Multi-Area, Multi-Service and Multi-Tier Edge-Cloud Continuum Planning. Sensors, 25(13), 3949. https://doi.org/10.3390/s25133949