1. Introduction
Visual Place Recognition (VPR) is an important research direction in the field of computer vision and robotics, aiming to determine the location of a device by matching images with a series of databases. VPR is commonly used in the fields of robot navigation, autonomous driving, and augmented reality [
1]. There are a number of serious challenges in visual location recognition tasks, including changing lighting conditions [
2], seasonal changes and time lapse [
3], weather fluctuations [
4], perspective shifts [
5], and dynamic object occlusion [
6], which can significantly interfere with the accuracy and robustness of image matching.
Current research approaches in visual location recognition follow two main technical routes: the classification paradigm and the retrieval paradigm. Under the classification paradigm, researchers achieve recognition by constructing location classification models. CosPlace [
7] constructs classifier training descriptors through geographic region division. D-Cosplace [
8] introduces distributed training to improve model generalization. Hussaini et al. [
9] draws on the classification idea to organize data and models, but the core is still retrieval. The classification paradigm has inherent flaws: there is a semantic divide between the continuity of geographic scenes and the discrete nature of classification labels, leading to insufficient zero-sample generalization for untrained regions. Mainstream research methods more often regard VPR as a retrieval problem, and their technical routes focus on constructing feature spaces with strong discriminative properties to support similarity matching. Li et al. [
10] proposed the PPT-Hashing framework, which employs hash coding to achieve efficient image retrieval. Wu et al. [
11] combined SCA and GIA to propose GICNet, which enhances the model’s feature extraction and feature aggregation capabilities to further improve the retrieval performance.
With the increase of task complexity and the deepening of practical application requirements, regardless of the adoption of classification or retrieval technology routes, in recent years the mainstream methods have widely adopted deep learning models as the basic support. Traditional feature matching methods such as SIFT [
12] and SURF [
13] are gradually being replaced by new methods based on deep learning. With the rapid development of the Transformer architecture in the field of computer vision, by virtue of its advantages in spatial feature modeling and global dependency capturing, it shows excellent performance in tasks such as image matching, which is especially suitable for scenarios that are highly dependent on contextual understanding such as VPR. In this context, academics have conducted systematic research on structural adaptation and feature enhancement of Transformer in VPR tasks, which has contributed to the continuous progress in this field. Zhu et al. [
14] were the first to verify the performance advantage of the underlying Transformer backbone network in VPR tasks. Its global modeling capability significantly outperforms that of the traditional CNN backbone network. Keetha et al. [
15] proposed DINO/DINOv2-driven ViT as the base backbone network on this basis, establishing a new performance benchmark for the VPR task. To further enhance the characterization capability of the backbone network, Lu et al. [
16] achieved efficient migration of pre-trained models and task adaptation by adding adapters inside the Transformer encoder. The team further proposed multi-scale convolutional adapters in the concurrent work [
17], which significantly improved the performance of the VPR task by fusing the local a priori and global modeling capabilities in the backbone network performance. Zhang et al. [
18] proposed introducing the RGA attention mechanism into the feature fusion and enhancement module to model the fused features as a whole so as to effectively suppress redundant information and noise interference. Liu et al. [
19] introduced POD attention between the feature extraction module and the feature aggregation module to suppress the high-frequency noise present in the shallow network by means of attention focusing. Although such methods enhance the robustness of feature representation to a certain extent, most of their suppression of noise occurs after the features have already been generated, failing to intervene directly in the process of feature formation, resulting in noise that may have propagated at an early stage and affected the quality of subsequent representations. Notably, studies have shown the potential limitations of the attention mechanism that comes with Transformer. Ye et al. [
20] found through visual analysis that traditional Transformer often suffers from distraction in visual tasks, i.e., part of the attention head is focused on contextual information that is not relevant to localization. To solve this problem, they innovatively proposed a differential attention mechanism that effectively suppresses attentional noise and strengthens the feature response in key regions by establishing an adaptive correction module for the distribution of attention. Although this mechanism shows significant advantages in language models, its generalization efficacy in the task of cross-view visual place recognition is still to be studied in depth.
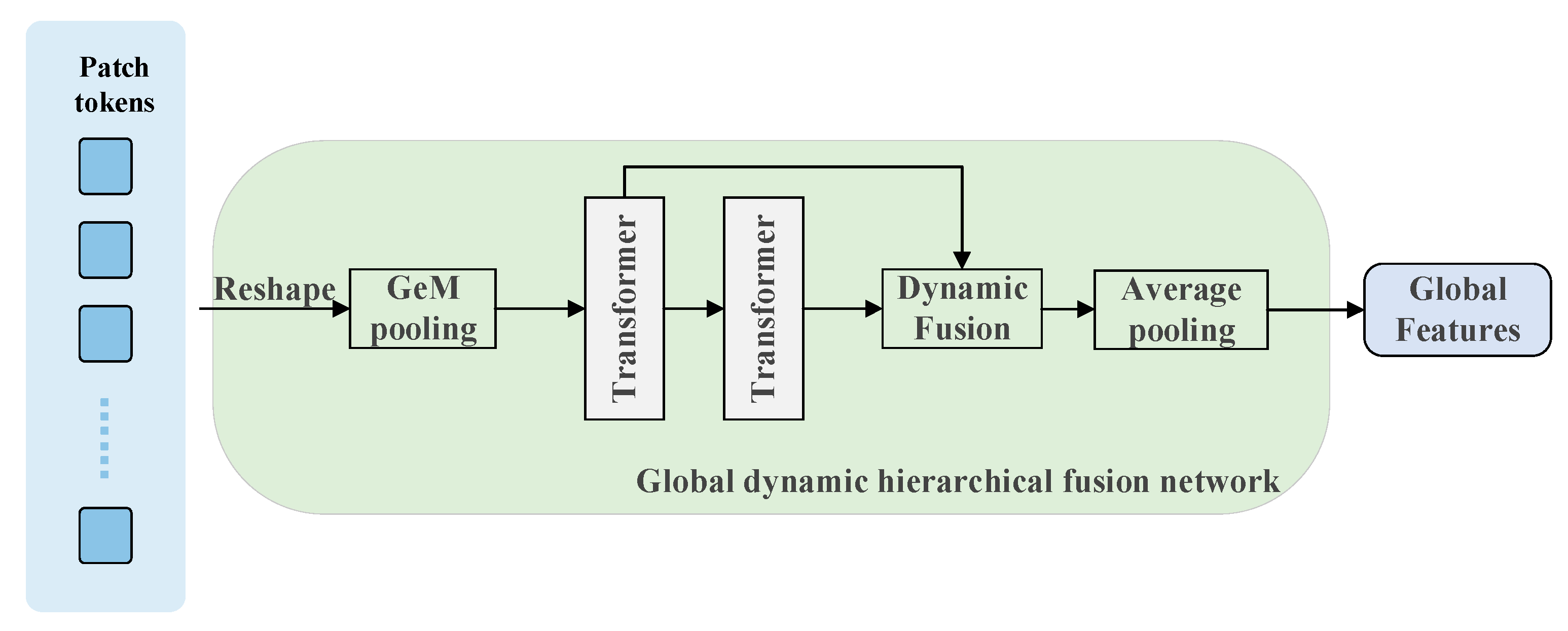
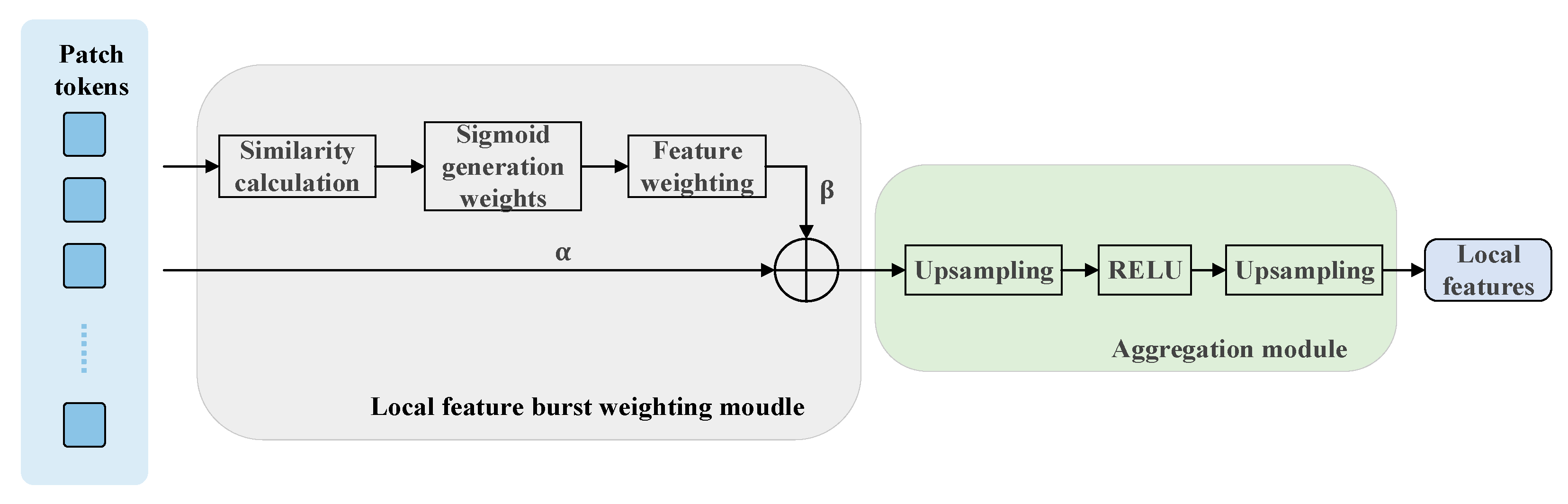
In the research direction of global and local feature representation optimization, scholars generally focus on improving the discrimination and robustness of feature representation to further enhance the matching accuracy in visual localization tasks. For the construction of global features, most of the existing mainstream methods achieve feature map dimension reduction through feature aggregation techniques, specifically using pooling operations such as GeM [
21], mean pooling [
22], NetVLAD [
23], etc., to encode higher-order statistics of features to obtain global feature representations. Wang et al. [
24] achieved adaptive attentional weighting by cross-layer aggregation of multi-scale patch tokens from the Transformer encoder, which is the most effective way to optimize feature representation. Adaptive attention assigns weights to patch tokens, then realizes the global feature representation of context-awareness. Lu et al. [
17] first divided the patch tokens’ output from the backbone network into different scales and performed pooling and cross-scale feature splicing, then realized cross-region feature interactions through the self-attention mechanism of the Transformer encoder. The structure was able to effectively realize the high-level integration of global context information. In terms of local feature modeling, research focuses more on improving the responsiveness and robustness of local features to critical regions. Garg et al. [
25] revealed that feature matching in the VPR task is sensitive to the noise in non-overlapping regions and proposed a method to enhance the focusing ability on critical regions through a feature weighting mechanism. Kannan et al. [
26] proposed a multi-scale patch fusion method to enhance the focusing ability on critical regions by integrating image features at different scales to improve the matching performance of images under scale transformation and viewpoint change. Khaliq et al. [
27] revealed the systematic risk of feature redundancy in the VPR task: the proliferation of repetitive patterns in the feature space will lead to discriminative degradation and mismatch propagation. It is proposed to construct an adaptive suppression weight matrix in the feature similarity space through a dynamic feature competitive learning mechanism, dynamically adjust the contribution of local features to the aggregated vector, suppress the degradation of the representations triggered by the high-frequency repetitive patterns, and make the aggregated vector closer to low-conflict and high-discriminative local features.
The main contributions of the work in this paper are as follows:
- (1)
We innovatively construct a dynamic differential DINOv2 model, which introduces the differential attention mechanism to the visual place recognition task for the first time. The mechanism effectively decouples the noise from the key features, adaptively adjusts the noise suppression strength through dynamic parameters, and significantly enhances the model’s adaptability to environmental changes and cross-domain generalization ability.
- (2)
We propose a dual-path feature enhancement module. The global path adopts a dynamic hierarchical fusion mechanism, retains the initial feature statistics through multilevel semantic association modeling, effectively solves the problem of apparent offset caused by drastic lighting/viewing angle changes, and significantly improves the global consistency of cross-scene representations. Local paths are weighted by adaptive aggregation to suppress repetitive texture interference and enhance discriminative local detail representation. The dual-path cooperative mechanism optimizes global–local features and significantly improves cross-domain matching performance.
- (3)
Comprehensive experiments on DD–DPFE on six mainstream VPR datasets including extreme weather/light conditions show that DD–DPFE exhibits advantages on multiple datasets, especially in challenging scenes.
The other sections are structured as follows:
Section 2 describes in detail the research methodology proposed;
Section 3 is the experimental part, which verifies the superiority of this paper’s methodology through comparative experiments and further analyzes the contribution of each module to the overall performance in conjunction with ablation experiments; and in
Section 4 the paper is summarized.
3. Experiments
3.1. Dataset and Evaluation Indicators
In order to comprehensively evaluate the performance of this paper’s method in complex real-world scenarios, six representative and challenging VPR public datasets were selected as the evaluation benchmarks, which mainly include Pitts30k, MSLS, Nordland, AmsterTime, SF_XL, and SVOX. These datasets cover a wide range of real-world environment variation factors, such as illumination, viewing angle, seasonal changes, weather changes, and dynamic object interference, which can fully verify the robustness and generalization ability of the model in different dimensions. The specific information is shown in
Table 1.
We adopted the recall rate (R@N) as a metric for evaluating the performance of VPR, where R@N refers to the probability that a correctly matched target location appears among the first N retrieval results in the query image. Specifically, R@1 indicates whether the first ranked retrieval result is the target location, and R@5 indicates whether the target location appears in the first five retrieval results. By calculating the metrics such as R@1 and R@5, the performance of the algorithm can be comprehensively evaluated under different difficulties and scenarios.
3.2. Implementation Details
We used DINOv2’s ViT-L/14 (1024 dimensions) as the base model. Experiments were performed on an NVIDIA GeForce RTX 4070 using Pytorch 2.0.0. All images were resized to for training and evaluation, and the reordering was performed among the top 100 candidate images with the interval set. The bottleneck ratio of the adapter in the ViT block was 0.5, the scaling factor , in the differential attention, and the local feature aggregation module used a convolution of , where and . The Adam optimizer training process (, batch = 4) terminates automatically upon detecting no validation R@5 improvement over three successive epochs. The model in this paper was trained on the MSLS dataset, and the weights of the model were fine-tuned at Pitts30k.
3.3. Comparison with State-of-the-Art Methods
We compared the method in this paper with several other state-of-the-art VPR methods, including three one-stage methods using global feature retrieval: CosPlace [
7], EigenPlace [
28], and CircaVPR [
17], alongside two-stage reordering-enhanced architectures including R
2Former [
14] and SelaVPR [
16]. Among them, CircaVPR, R
2Former, and SelaVPR are Transformer-based methods and CosPlace and EigenPlace are CNN-based methods, all of which have Resnet and VGG in their backbone networks. CosPlace’s backbone training network also contains a CCT and Transformer network. In this paper, the backbone network with the best effect in the literature was selected for the comparison test.
Table 2 systematically summarizes the architecture and training dataset details of the network models used for the VPR comparison experiments in this study. The test results for the baseline assessment data are presented in
Table 3 and
Table 4. These results present both optimal values (bolded) and suboptimal values (underlined), where “ave” indicates the average value, with all numerical results retained to one decimal place. It should be noted that all comparison experiments were conducted using unified hardware equipment for training and testing, which has led to slight deviations in some results compared to the original literature-reported data.
As demonstrated by the quantitative assessments in
Table 3 and
Table 4, DD–DPFE shows significant advantages in cross-scene generalization ability and extreme environment robustness, which are analyzed as follows:
In the benchmark dataset comparison, the proposed method achieved an overall lead on the Pitts30k dataset with 93.3% R@1 and 96.9% R@5, verifying its high-precision positioning capability in large-scale urban scenarios. At the same time, in extreme environment scenarios, its adaptability to long time spans (AmsterTime dataset R@1 is 59.3%) and its ability to express features of complex urban scenes (SF_XL (v1) dataset R@1 is 81.1%, surpassing most comparison methods) were more prominent. Although it was slightly less than the optimal method on the Nordland and MSLS-test datasets, its overall performance was stable, reflecting a good balance.
In the test of multiple weather scenes, the technical advantages of this method were further highlighted. In night scenes, the R@1 of 90% far exceeded that of CircaVPR (80.0%) and SelaVPR (71.6%). In rainy and snowy weather, the R@1 of 94.8% and 96.8%, respectively, set new performance records, which were 3.9% and 3.4% higher than the suboptimal methods. In strong light conditions, the R@1 of 92.9% far exceeded other advanced methods, indicating its strong robustness to low light, strong light, occlusion, and noise interference. At the same time, under overcast conditions, R@1 reached 96.3%, and the average R@1 of all weather scenes was as high as 94.2%, which is 5–25.7% higher than the comparison method. The R@5 index generally exceeded 92.9%, which verifies the effective trade-off between the precision and recall stability of the method.
Through the above experimental comparison and analysis, it can be seen that the proposed method has significant advantages in cross-dataset generalization, extreme weather robustness, and complex scene adaptability. It not only breaks through the bottleneck of large-scale positioning with the highest accuracy in urban scenes such as Pitts30k and SF_XL (v1) but also refreshes the performance record with more than 90% R@1 under extreme conditions such as night, rain, and snow. At the same time, it maintains a comprehensive lead in changeable weather such as cloudy days and strong light, providing an effective solution for visual positioning in actual complex environments.
3.4. Ablation Study
3.4.1. Effect of Core Module Ablation
To scientifically evaluate the effectiveness of the three key enhancement modules proposed in this paper, systematic ablation experiments were designed under several typical cross-domain and complex weather scenarios. Specifically, based on the unified feature aggregation backbone structure, the dynamic differential attention mechanism (A), the local feature adaptive weighting module (W), and the global dynamic hierarchical fusion strategy (T) were gradually introduced, and several combination models were constructed to evaluate their performances one by one. The experimental results are shown in
Table 5 and
Table 6.
Based on the above ablation experiment results conducted on different datasets, the effectiveness and synergy of the global feature optimization module (T), the local burst weighting module (W), and the backbone network attention mechanism (A) are verified. The experimental results are analyzed as follows.
First, the introduction of the differential attention mechanism significantly reduces the attention noise on multiple VPR datasets and shows excellent performance. However, when dealing with the challenges of the AmsterTime dataset (involving long-term scene changes) and the SF_XL dataset (including dynamic viewpoint interference), as well as when dealing with some extreme weather scenes in the SVOX dataset (such as night, rain, and snow), the performance of the mechanism declined, which reveals the shortcomings of the model in terms of fine-grained matching accuracy, dynamic object robustness, cross-viewpoint consistency, and long-term environmental adaptability.
Subsequently, a local burst weighting module was introduced, which alleviated the above problems to a certain extent and strengthened the model’s local feature processing capabilities. The performance on the night scene was significantly improved to 76.7 (+2.5%), and the performance of all weather scenes tended to be stable, verifying its ability to suppress local feature redundancy. At the same time, the performance on the AmsterTime dataset improved to 57.8%. However, when faced with drastic viewpoint changes and high-frequency dynamic interference in the SF_XL dataset, due to the independence of local features, the model performance dropped significantly (from 78.4% to 57.4%), indicating that the model needs a higher-level scene understanding mechanism.
Finally, after the introduction of the global feature optimization module (module T), the system achieved a comprehensive breakthrough through the spatiotemporal semantic fusion mechanism: the model performance was significantly improved in long-term changing scenes (AmsterTime increased to 59.3%), dynamic perspective scenes (SF_XL increased to 81.1%), and changing weather conditions (at night increased to 90%, strong light interference increased to 92.9%). This hierarchical progressive optimization verifies the synergistic advantages of the “global scene modeling-local detail enhancement” dual-path mechanism, especially the key role of the Transformer architecture in establishing cross-perspective spatiotemporal associations (Nordland increased by 6.4% to 79.6%) and resisting dynamic interference (SF_XL recovered to 81.1%).
The results show the universal optimization capability of the DD–DPFE in complex VPR scenarios. The hierarchical coordination mechanism of local-global features achieves a robust representation of cross-modal scenarios through the organic integration of spatial constraints (local modules suppress feature redundancy) and temporal associations (global modules establish scene schemas). The model systematically solves the core problems of weather changes, dynamic interference response, and long-term robustness in complex VPR tasks.
3.4.2. Impact of the Backbone Network on Model Performance
This subsection explores the impact of the DD–DPFE backbone model size on the performance, focusing on comparing the model performance of two backbone networks based on DINOv2&ViT-L/14 and DINOv2&ViT-B/14. The results are shown in
Table 7.
Experimental data shows that DINOv2&ViT-L/14 significantly surpasses ViT-B/14 (85.16%) with an average performance of 86.89% and an absolute advantage of 1.73%. The model performs particularly well in complex dynamic scenes. Its robustness is significantly enhanced in extreme weather conditions such as SVOX-Night (+6.5%) and SVOX-Sun (+3.4%), and it achieves a 19.9% performance jump in the Nordland dataset, demonstrating its strong modeling capabilities for seasonal changes and fine-grained differences. Although ViT-B/14 surpasses ViT-L/14 (59.3%) with 80.8% in the AmsterTime dataset, suggesting the potential advantages of lightweight models under specific data distributions, ViT-L/14 leads in nine of the ten datasets, especially in scenarios with high environmental robustness requirements. Therefore, DINOv2&ViT-L/14 was selected as the default backbone network.
3.4.3. Impact of Key Parameter Configurations on Model Performance
This section designs an ablation experiment to explore the mechanism of the influence of the number of Transformer stacking layers on the model’s performance in the local dynamic hierarchical fusion network and analyzes the impact of different numbers of Transformer stacking layers on the model’s performance.
The other parts of the model remain unchanged. Trained and tested on the MSLS dataset, the number of Transformer stacking layers was set to 1, 2, 3, 4, and 5. The experimental results are shown in
Figure 5.
The results show that with the increase of fusion depth, the model performance shows a trend of increasing and then decreasing, in which the model performs better and more stably in R@1, R@5, and R@10 indexes when and . Further observation shows that when the fusion depth is increased to , the performance of the model decreases significantly, which we believe may be due to the redundancy of information and feature perturbation caused by the deep fusion layer, resulting in the dilution of the effective information and exacerbating the risk of overfitting, which in turn affects the model’s generalization ability. Although the result of is slightly recovered compared with that of , the overall result is still lower than that of and , and the difference is obvious.
In order to further verify the model’s generalization ability under different fusion depths, we selected
and
with better performance and
with obvious degradation for full training and performed detailed tests on several datasets. The results are shown in
Table 8 and
Table 9.
Referring to the contents of the above table, has the best or near-optimal performance overall. On most data sets, performs better than and . In the complex scene SVOX dataset, achieved the best R@1 performance under multiple weather conditions. performs slightly better in some scenes. For example, on the Nordland dataset, the R@1 of is 82.5%, higher than the 79.6% of , indicating that moderate fusion helps to extract more robust features. The overall performance of declines. As the fusion depth increases, the model introduces more redundant features, which in turn affects the discriminability. For example, in the night scene, the R@1 of drops to 78.9%, which is significantly degraded compared to (90.0%). Considering the performance, stability, and generalization ability, the parameters of were selected as the default settings.
3.5. Visual Analytics
The local matching results of cross-view images for the same scene are shown in
Figure 6. The proposed method achieves up to 271 high-confidence feature matches. This result verifies that the feature descriptors generated by the model have stronger geometric consistency and discriminability and can effectively support the refined local matching requirements in the visual position recognition (VPR) task, thereby improving the robustness of loop closure detection and pose estimation.
Figure 7 shows the Top-1 results retrieved by the proposed method in all scenes. As shown in the figure, all prediction results are located at the same position as the query image. For the MSLS and Pitts30k datasets, although there are weather and perspective differences between the query image and the retrieval image, the model mainly relies on the stable structure of the building for matching. In the Nordland dataset, there are significant seasonal changes (such as snow in winter and no snow in summer) and lighting differences between images; the direction of the railroad tracks and the position of street lights provide recognition bases as invariant features, but snow may block part of the track and introduce noise interference. In the AmsterTime dataset, there is a time difference between the black and white query image and the color image, but the building morphology is still the key recognition feature. The query image of the SF_XL dataset has occlusions (such as circular road signs) and large perspective changes, but the building outlines and street lights provide stable recognition information. The SVOX dataset faces challenges under different weather conditions: night scenes are insufficiently lit or partially overexposed, overcast and snow scenes have low light problems, rain scenes are blurred due to rain, and sun scenes may be overexposed due to strong light. Despite this, static elements such as building structures and intersection directions in all scenes are still the main matching basis.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}