
Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm

 , and
, and
Abstract
1. Introduction
2. Methodology
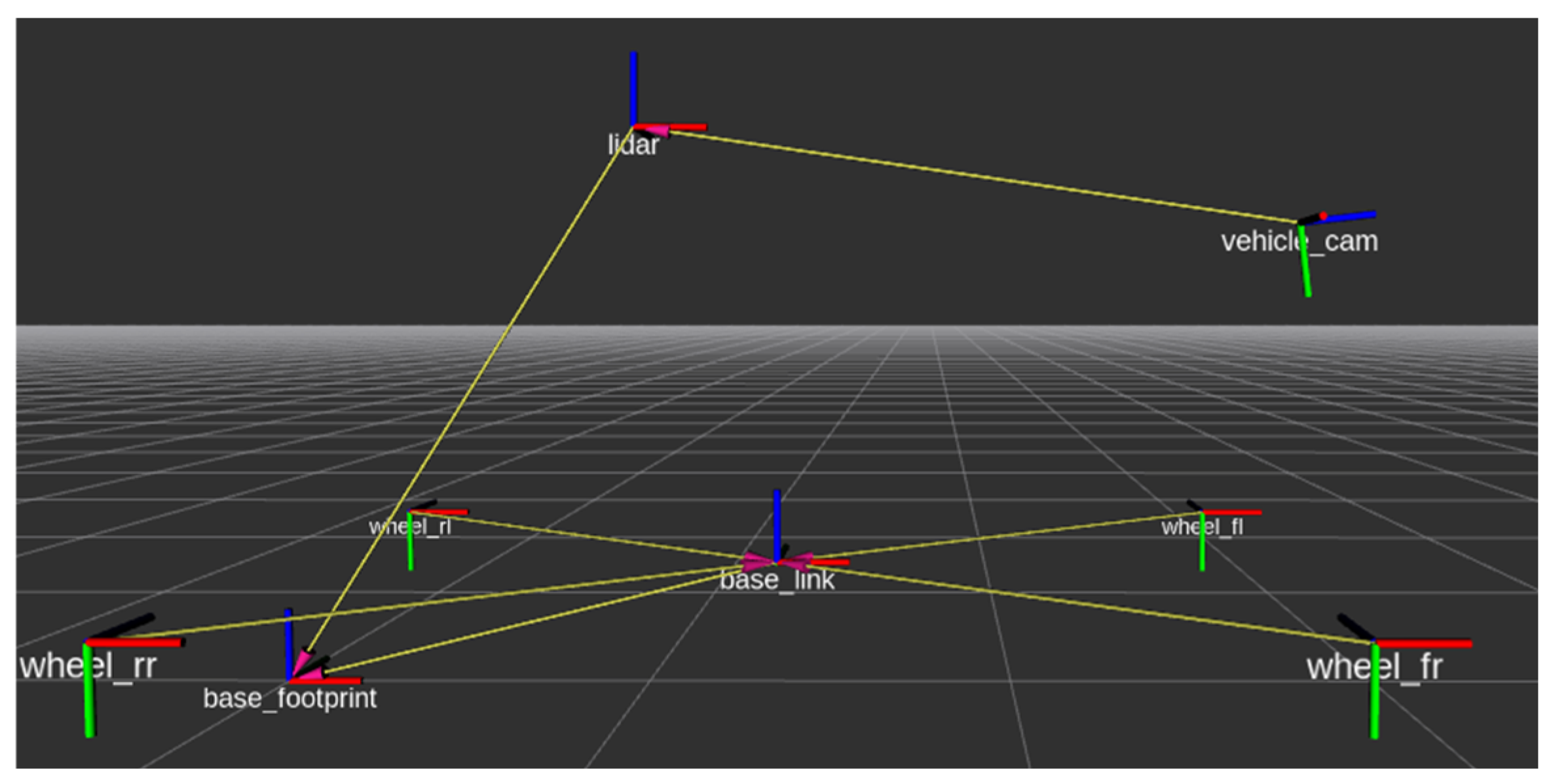
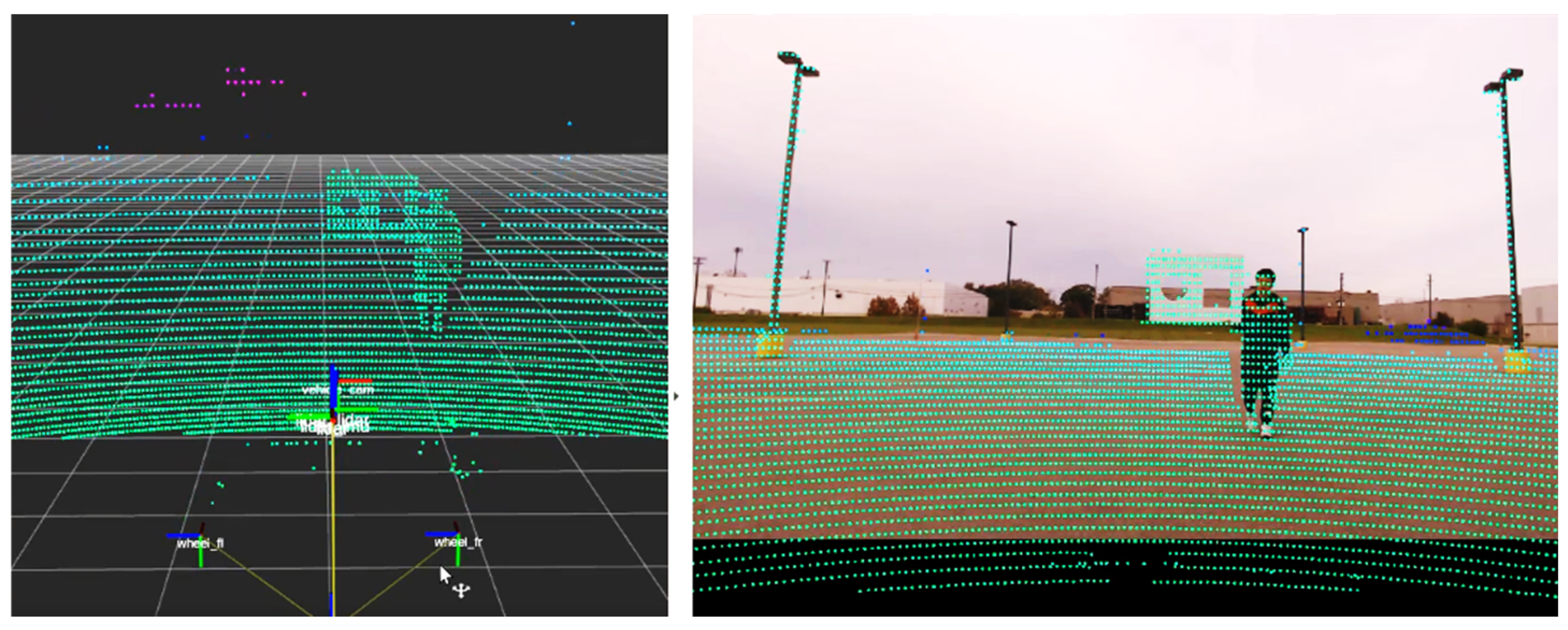
2.1. Sensor Setup and Calibration
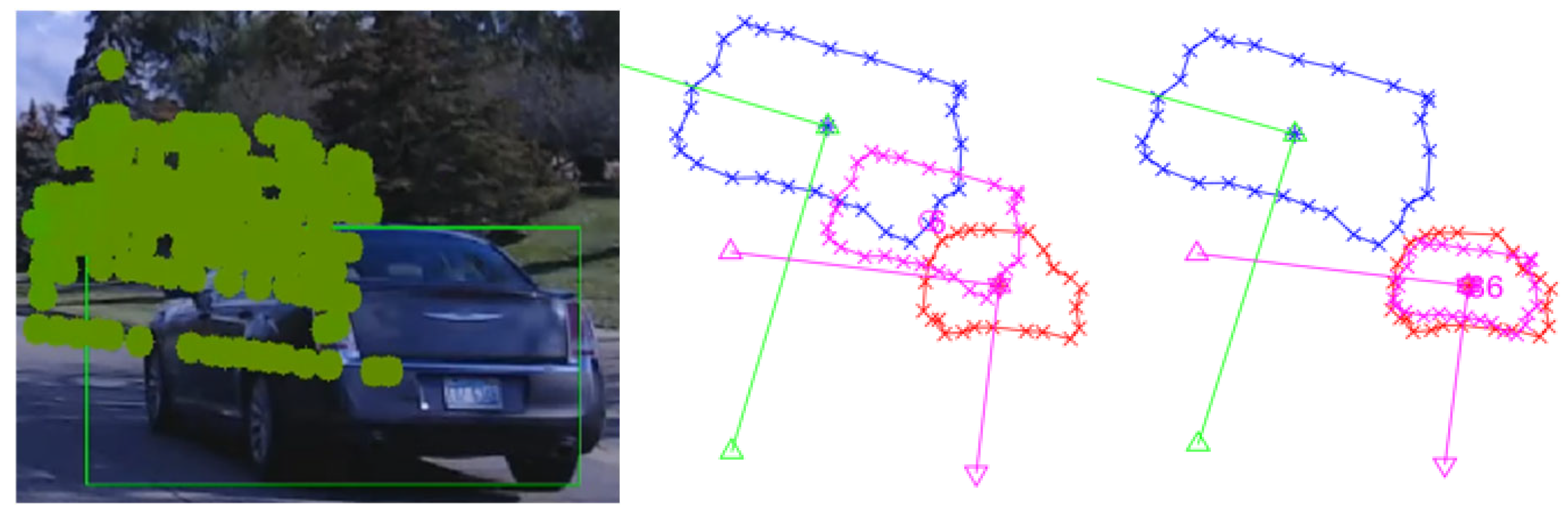
2.2. Pattern Matching Algorithm
3. Experimental Results
3.1. Test Scenarios
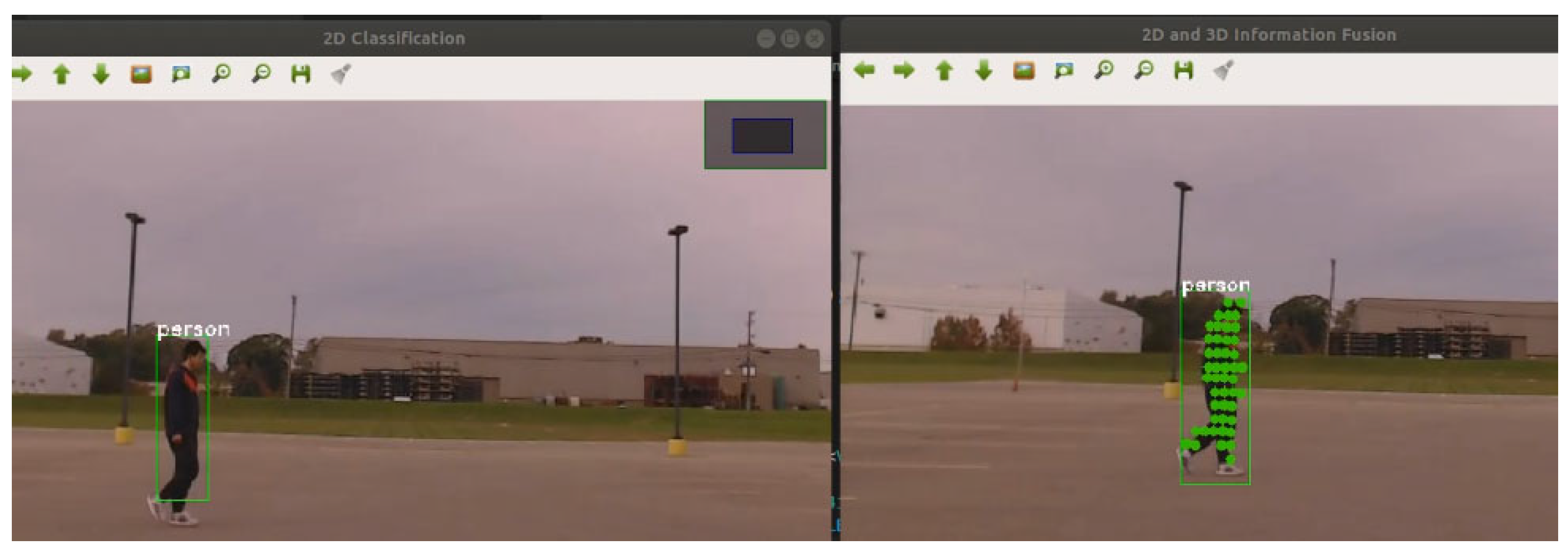
3.1.1. General Misalignment Correction (Figure 6)
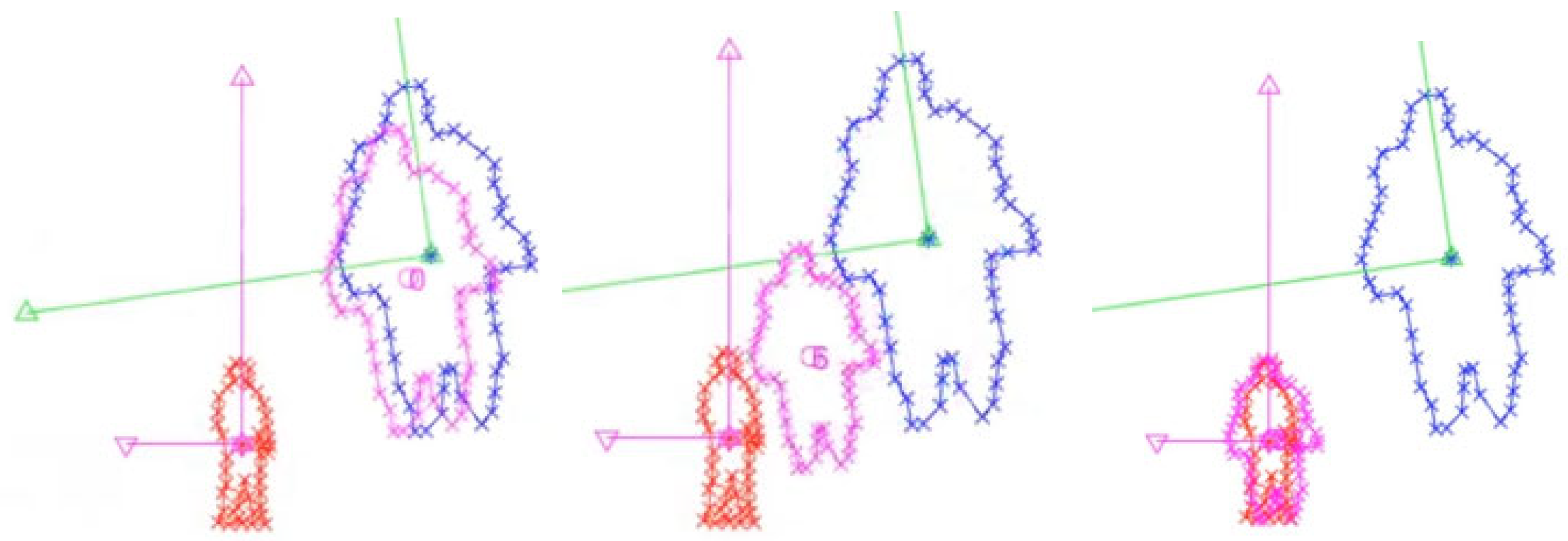
3.1.2. Checkerboard Misalignment (Figure 7)

3.1.3. Camera Distortion (Figure 8)

3.1.4. LiDAR Mounting Drift (Figure 9)
3.1.5. Extreme Misalignment (Figure 10)

3.2. Quantitative Evaluation
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LiDAR | Light Detection and Ranging |
| CNN | Convolutional Neural Network |
| SVD | Singular Value Decomposition |
| GD | Gradient Descent |
| ROS | Robot Operating System |
| PCD | Point Cloud Data |
| YOLO | You Only Look Once (object detection model) |
References
- Zhang, F.; Clarke, D.; Knoll, A. Vehicle detection based on LiDAR and camera fusion. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1620–1625. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef]
- Zhao, X.; Sun, P.; Xu, Z.; Min, H.; Yu, H. Fusion of 3D LIDAR and camera data for object detection in autonomous vehicle applications. IEEE Sens. J. 2020, 20, 4901–4913. [Google Scholar] [CrossRef]
- Zhong, H.; Wang, H.; Wu, Z.; Zhang, C.; Zheng, Y.; Tang, T. A survey of LiDAR and camera fusion enhancement. Procedia Comput. Sci. 2021, 183, 579–588. [Google Scholar] [CrossRef]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Zhao, L.; Zhou, H.; Zhu, X.; Song, X.; Li, H.; Tao, W. Lif-seg: Lidar and camera image fusion for 3d lidar semantic segmentation. IEEE Trans. Multimed. 2023, 26, 1158–1168. [Google Scholar] [CrossRef]
- Berrio, J.S.; Shan, M.; Worrall, S.; Nebot, E. Camera-LIDAR integration: Probabilistic sensor fusion for semantic mapping. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7637–7652. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Li, J.; Liu, Y.; Wang, J. Building and optimization of 3D semantic map based on Lidar and camera fusion. Neurocomputing 2020, 409, 394–407. [Google Scholar] [CrossRef]
- Huang, J.K.; Grizzle, J.W. Improvements to target-based 3D LiDAR to camera calibration. IEEE Access 2020, 8, 134101–134110. [Google Scholar] [CrossRef]
- Pusztai, Z.; Hajder, L. Accurate calibration of LiDAR-camera systems using ordinary boxes. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 394–402. [Google Scholar]
- Veľas, M.; Španěl, M.; Materna, Z.; Herout, A. Calibration of rgb camera with velodyne lidar. J. WSCG 2014, 2014, 135–144. [Google Scholar]
- Grammatikopoulos, L.; Papanagnou, A.; Venianakis, A.; Kalisperakis, I.; Stentoumis, C. An effective camera-to-LiDAR spatiotemporal calibration based on a simple calibration target. Sensors 2022, 22, 5576. [Google Scholar] [CrossRef] [PubMed]
- Tsai, D.; Worrall, S.; Shan, M.; Lohr, A.; Nebot, E. Optimising the selection of samples for robust lidar camera calibration. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2631–2638. [Google Scholar]
- Li, X.; Xiao, Y.; Wang, B.; Ren, H.; Zhang, Y.; Ji, J. Automatic targetless LiDAR–camera calibration: A survey. Artif. Intell. Rev. 2023, 56, 9949–9987. [Google Scholar] [CrossRef]
- Li, X.; Duan, Y.; Wang, B.; Ren, H.; You, G.; Sheng, Y.; Ji, J.; Zhang, Y. Edgecalib: Multi-frame weighted edge features for automatic targetless lidar-camera calibration. IEEE Robot. Autom. Lett. 2024, 9, 10073–10080. [Google Scholar] [CrossRef]
- Tan, Z.; Zhang, X.; Teng, S.; Wang, L.; Gao, F. A Review of Deep Learning-Based LiDAR and Camera Extrinsic Calibration. Sensors 2024, 24, 3878. [Google Scholar] [CrossRef] [PubMed]
- Yamada, R.; Yaguchi, Y. Probability-Based LIDAR–Camera Calibration Considering Target Positions and Parameter Evaluation Using a Data Fusion Map. Sensors 2024, 24, 3981. [Google Scholar] [CrossRef] [PubMed]
- Bisgard, J. Analysis and Linear Algebra: The Singular Value Decomposition and Applications; American Mathematical Society: Providence, RI, USA, 2020; Volume 94. [Google Scholar]
- Jaradat, Y.; Masoud, M.; Jannoud, I.; Manasrah, A.; Alia, M. A tutorial on singular value decomposition with applications on image compression and dimensionality reduction. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; pp. 769–772. [Google Scholar]
- He, Y.L.; Tian, Y.; Xu, Y.; Zhu, Q.X. Novel soft sensor development using echo state network integrated with singular value decomposition: Application to complex chemical processes. Chemom. Intell. Lab. Syst. 2020, 200, 103981. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Initial Misalignment | Residual Error After SVD-GD | Improvement (%) | Runtime per Frame (s) |
|---|---|---|---|---|
| Checkerboard Scene (Figure 7) | 5.3 px | 0.8 px | 84.9% | 0.34 |
| Camera Distortion (Figure 8) | 7.2 px | 1.1 px | 84.7% | 0.39 |
| LiDAR Drift on Highway (Figure 9) | 10.0° rotation | 1.2° rotation | 88.0% | 0.42 |
| Extreme Misalignment (Figure 10) | 45° + scale shift | 2.5°/3.5 px | 93.5% (avg) | 0.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, K.; Song, M.; Cheok, K.C.; Radovnikovich, M.; Kobayashi, K.; Cai, C. Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm. Sensors 2025, 25, 3876. https://doi.org/10.3390/s25133876
Tian K, Song M, Cheok KC, Radovnikovich M, Kobayashi K, Cai C. Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm. Sensors. 2025; 25(13):3876. https://doi.org/10.3390/s25133876
Chicago/Turabian StyleTian, Kaiqiao, Meiqi Song, Ka C. Cheok, Micho Radovnikovich, Kazuyuki Kobayashi, and Changqing Cai. 2025. "Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm" Sensors 25, no. 13: 3876. https://doi.org/10.3390/s25133876
APA StyleTian, K., Song, M., Cheok, K. C., Radovnikovich, M., Kobayashi, K., & Cai, C. (2025). Singular Value Decomposition (SVD) Method for LiDAR and Camera Sensor Fusion and Pattern Matching Algorithm. Sensors, 25(13), 3876. https://doi.org/10.3390/s25133876