1. Introduction
The huge amount of data collected by modern commercial wearable devices, thanks to their advanced sensing capabilities, has made it necessary to perform data analysis directly on board these devices in order to increase their energy efficiency, reducing the amount of data sent via RF links (e.g., WiFi, Bluetooth Low Energy (BLE), ZigBee, …). In this sense, the wearable device can be considered the “edge” to a mobile phone, a central station, or a web server, which traditionally would perform more complex data processing [
1].
Indeed, the progress of microelectronics has allowed integrated circuit manufacturers to increase the computational capabilities of their microcontrollers used in today’s mobile and wearable devices. This has consequently allowed the porting onto microcontrollers of various machine learning tools for pattern recognition, classification, and prediction, such as recurrent neural networks (RNNs) or long short-term memory (LSTM) neural networks (NNs) [
2,
3,
4,
5,
6,
7,
8,
9]. However, trade-offs between network accuracy and resource utilization should be carefully considered in firmware implementations on low-power and low-cost wearable microcontroller platforms, where computational resource constraints severely impact the overall design of the sensor system [
10].
To facilitate the embedding of machine learning algorithms into wearable devices, there is a wide range of frameworks such as MicroPython and Lite Runtime (LiteRT), formerly known as TensorFlow Lite (TFLite) for Microcontrollers, that provide a set of tools to run neural network models on supported microcontrollers for pattern recognition and classification.
The TensorFlow platform [
11] makes it easy to build machine learning (ML) models that run in any environment and can be used for a variety of ML tasks, such as image and text classification, time series forecasting, and pattern recognition. One of the most useful high-level frameworks for using the TensorFlow platform is Keras, which lets designers create neural network models by specifying layer types and sizes, and automatically performs fitting and evaluation of the models. This greatly simplifies the process of designing and training neural networks, allowing for rapid testing, modification, and optimization. In this direction, STMicroelectronics has achieved progress in research on the implementation of ML and deep learning (DL) models using the Keras, TFLite or PyTorch frameworks on memory-limited STM32 microcontrollers [
12], supported by the X-CUBE-AI extension package [
13].
Since mobile and wearable devices have proven to be very useful for human activity recognition (HAR) [
10,
14,
15,
16], in this work we considered specific branches of HAR such as sign language recognition [
17,
18,
19] or dynamic hand gesture detection and classification [
20,
21] as simple and common interesting application scenarios for wearable devices. Gesture recognition requires a model or classification scheme whose complexity depends on the number of output classes needed. Examples include using an acceleration-based wearable device as a human–computer interface, such as for text input, drawing numbers and letters, sending commands by moving fingers and hands in the air, or determining what the user is doing at a given moment. These are multiclass classification tasks that are an excellent use case for NNs. Traditional multiclass methods for gesture recognition, such as extended support vector machines (SVMs) and k-nearest neighbors (kNNs), can offer good accuracy at the expense of the need for complex models [
22]. It is well documented that using LSTM networks for human activity classification [
23,
24] has a high degree of accuracy. As a result, LSTM neural networks, which include a memory element in each neuron, are well suited to efficiently model time series such as acceleration-based dynamic gesture recognition. For example, in [
25], DL methods using TensorFlow and Keras were evaluated in gesture recognition. A multi-layer LSTM model was trained and evaluated on data (10 gestures, 1000 trials total) from a finger ring device collecting acceleration data, achieving a per-gesture accuracy ranging from 75 to 95%, but the model turned out to be too big and/or complex to be implemented on the edge device.
The major disadvantage of larger, highly accurate networks is indeed their size, as they cannot be easily stored and loaded onto embedded devices, due to memory limitations. This can be mitigated by fusing operations in a network together, at the cost of accuracy. This is how the TFLite converter utility functions and can be used to turn Keras models into microcontroller-compatible compressed TFLite models.
Training a neural network can be a very computationally expensive task, which can be shortened by using hardware accelerators such as a graphics processing unit (GPU) or a tensor processing unit (TPU). The easiest and most straightforward way to leverage these accelerators is to use the free, cloud-based ML platform Google Colaboratory (“Colab”): Colab offers a Jupyter Notebook along with a Python environment with scikit-learn, TensorFlow, Keras, PyTorch, and other libraries designed for ML.
In this work, Colab was used to generate models for STM32CubeIDE 1.16.0 with the X-CUBE-AI 10.0 tool to implement the LSTM neural network for a hand gesture classification system on an STMicroelectronics STM32L4-series microcontroller. The novelty of this paper lies in the definition of an NN architecture optimized to fit the available 1 MiB of memory embedded in the selected microcontroller, an STM32L476RG, chosen for its low-power architecture that makes it ideal to be used in the design of a wearable smart sensor. This has been achieved through the derivation of an analytical model of network complexity (memory usage and computational cost) as a function of design variables (number of neurons and layer types) and extensive experimentation to select the best compromise between accuracy and network size. The good performance of the classification system was finally verified by running the model on the real microcontroller using the publicly available “SmartWatch Gesture Dataset” [
26], which includes data for 20 different hand gestures recorded by 10 subjects using a wrist-worn device with a triaxial accelerometer. A 4-fold subject-based cross-validation showed that the NN achieved an average accuracy of 90.25%.
The main contribution of this paper is the design of a neural network-based gesture recognizer constrained to run on the limited resources available on a wearable embedded system. To this end, this paper presents (i) a detailed statistical analysis of the gesture durations to minimize the length of the data vectors to be processed by the neural network, (ii) an accurate analysis of the memory consumption and computational complexity of LSTM-based neural networks that allowed us to select a structure that fits in the available microcontroller memory, and (iii) an analysis of the resulting accuracy and computational performance on the target and other possible candidate embedded platforms.
This paper is structured as follows:
Section 2 begins by introducing some recent works related to the state of the art for gesture recognition.
Section 3 describes the dataset used to define and evaluate the performance of the neural network, and the data preprocessing and augmentation techniques used.
Section 4 describes the network architecture and its implementation on a microcontroller.
Section 5 presents some experiments conducted for model training and validation.
Section 6 discusses the obtained results and outlines possible future improvements. Finally,
Section 7 draws some conclusions.
2. Related Works
Gesture recognition plays a crucial role in various Human–Computer Interaction (HCI) applications, including virtual game control, sign language interpretation, assisted living, and robot control [
27]. The hand serves as an effective and essential medium for interaction in these systems. Gestures can be broadly classified into two types: static gestures, which involve fixed hand shapes, and dynamic gestures, which involve a sequence of hand movements, such as waving. Therefore, developing a system that can automatically and accurately recognize or categorize these gestures is essential.
Prior studies on gesture recognition are generally classified into two principal categories based on the input modalities: image-based approaches [
28,
29] and skeleton-based approaches [
30,
31]. Image-based methods typically employ Red–Green–Blue (RGB) or RGB–Depth (RGB-D) imagery to extract visual features for gesture recognition. Conversely, skeleton-based methods utilize temporal sequences of two-dimensional (2D) or three-dimensional (3D) hand joint coordinates to model and predict gesture patterns.
Static gestures are characterized by fixed angles between the fingers and remain unchanged over time, such as pointing or grasping. In contrast, dynamic gestures involve changing finger angles over a period of time—for example, waving or drawing letters in the air [
32]. Based on this distinction, datasets for static gestures are typically composed of still images, while dynamic gesture datasets require skeletal data or/and temporal data, often captured using inertial sensors that record motion over time. For static gesture recognition, neural networks, especially convolutional neural networks (CNNs) [
33,
34,
35], have proven highly effective due to their capacity to learn spatial features and extract detailed patterns directly from RGB images. More recently, transformer-based models [
36] have advanced the field by enabling the capture of temporal and contextual information. This has been particularly beneficial in applications such as sign language recognition and HCI, where understanding the sequence and context of gestures is essential.
Regarding dynamic hand gesture recognition, a brief overview of recent works that use different types of signals follows. We nevertheless underline that all these works focus on the accuracy parameter and not on the inference time and/or memory footprint for a possible implementation of the algorithm directly on a wearable device.
Singh et al. [
37] present a deep learning approach for the dynamic recognition of hand gestures using three-dimensional (3D) skeletal data. The proposed model integrates a Bidirectional Long Short-Term Memory (Bi-LSTM) network with a soft attention mechanism. Experimental results demonstrate that the Bi-LSTM effectively captures temporal dependencies, while the subsequent soft attention layer enhances the extraction of salient features. Gesture classification is then performed using a Multi-Layer Perceptron (MLP) followed by a softmax activation function. Additionally, a data augmentation strategy is introduced, which significantly improves the model’s generalization capabilities and mitigates the risk of overfitting.
Liu et al. [
38] propose a novel and efficient gesture recognition framework using multi-channel surface electromyography (sEMG) signals acquired from a wearable sensor (Myo). To address the trade-off between accuracy and computational efficiency in existing methods, the model integrates a lightweight convolutional neural network (CNN) with a Lightweight Feature Extraction (LFE) block for effective multi-scale feature aggregation. A pyramid input structure enhances contextual understanding across resolutions, while transfer learning with pre-trained weights improves feature representation and accelerates convergence. Additionally, a Broad Attention Learning (BAL) block is introduced to further refine recognition performance. The proposed approach is validated on a dynamic gesture dataset, demonstrating superior generalization and efficiency.
With reference to accelerometer sensors, Rafiq et al. [
39] conducted an experimental evaluation using the SmartWatch Gesture dataset [
26] (the same dataset used in this work) and the Motion Gesture dataset. The proposed method resulted in average test accuracies of 57.0%, 64.6%, and 69.3% by using one, three, and five samples for six different gestures. Their method, called Latent Embedding Exploitation, learns novel gesture classes incrementally using a few samples from motor-impaired individuals, but they use a subset of the total classes of the dataset.
Other works that used similar datasets only addressed the problem of recognizing a smaller number of classes, usually just eight [
26,
40]. In particular, ref. [
41] is perhaps the most similar to our work as it also used an LSTM network, but to recognize just eight classes on an ARM Cortex-A9 microprocessor with plenty of available memory, achieving a classification error rate of 11.43%, without using a subject-based split of the training and validation data.
3. Materials and Methods
The system we envision processes data acquired at a low sampling frequency (compatible with human motion dynamics) from a 3-axis accelerometer through an RNN to be implemented on a low-power microcontroller suitable for wearable devices. An overview of the data flow can be seen in
Figure 1.
The raw data from the accelerometer must be segmented into individual gestures. This task was already manually performed in the dataset we employed, so the recorded segment length is just forwarded to the following stages. In a real-time system, a dedicated gesture segmentation unit will be needed, whose design is beyond the scope of this paper, though it is envisioned it could use an auxiliary output from the LSTM layers trained to signal the endpoint. Short sequences are then padded (by repeating the last available sample) to a fixed length, and passed to the LSTM layers that analyse them. At the end of each sequence, the state of the final LSTM layer is passed on to the dense layers which perform the actual classification. The exact details of each stage are detailed in the following sections.
3.1. Dataset
The dataset used to define and assess the performance of the neural network consists of acceleration data collected from a wrist-worn smartwatch while the user performed about 20 repetitions of 20 different hand gestures. The collection was repeated by 8 different users, for a total of 3251 sequences of varying length [
26]. A graphical representation of the different gestures can be seen in
Figure 2.
The data consist of 3-axis acceleration values sampled at about 9.1 Hz (110 ms sampling interval) and their associated timestamp. Actually, three different timestamps are provided, two of which are absolute times (referred to the Epoch as per POSIX specifications), and the other is an internal timer timestamp. Sampling turned out not to be perfectly uniform, probably due to the hardware architecture of the smartwatch employed, which did not synchronize the accelerometer sampling time base with the main clock (which is a very common practice since integrated MEM-based accelerometers are almost always self-clocked). However, after ensuring that the sampling rate jitter was indeed small enough (the standard deviation between samples is about 11 ms, i.e., 10% of the nominal period) to make it negligible for activity recognition purposes, all timestamps had been discarded to avoid leaking information from the data acquisition process into the recognizer.
3.2. Data Preprocessing and Augmentation
As mentioned above, the dataset is already segmented into separate gestures. The segmentation was actually performed by the users themselves, who tapped the screen of the smartwatch before and after performing the gesture. But the duration of each segment is obviously different, varying from 10 samples (1.1 s) to 51 samples (5.6 s), as shown in
Figure 3.
To feed the input layer of the neural network, all sequences need to be the same length. From the histogram in
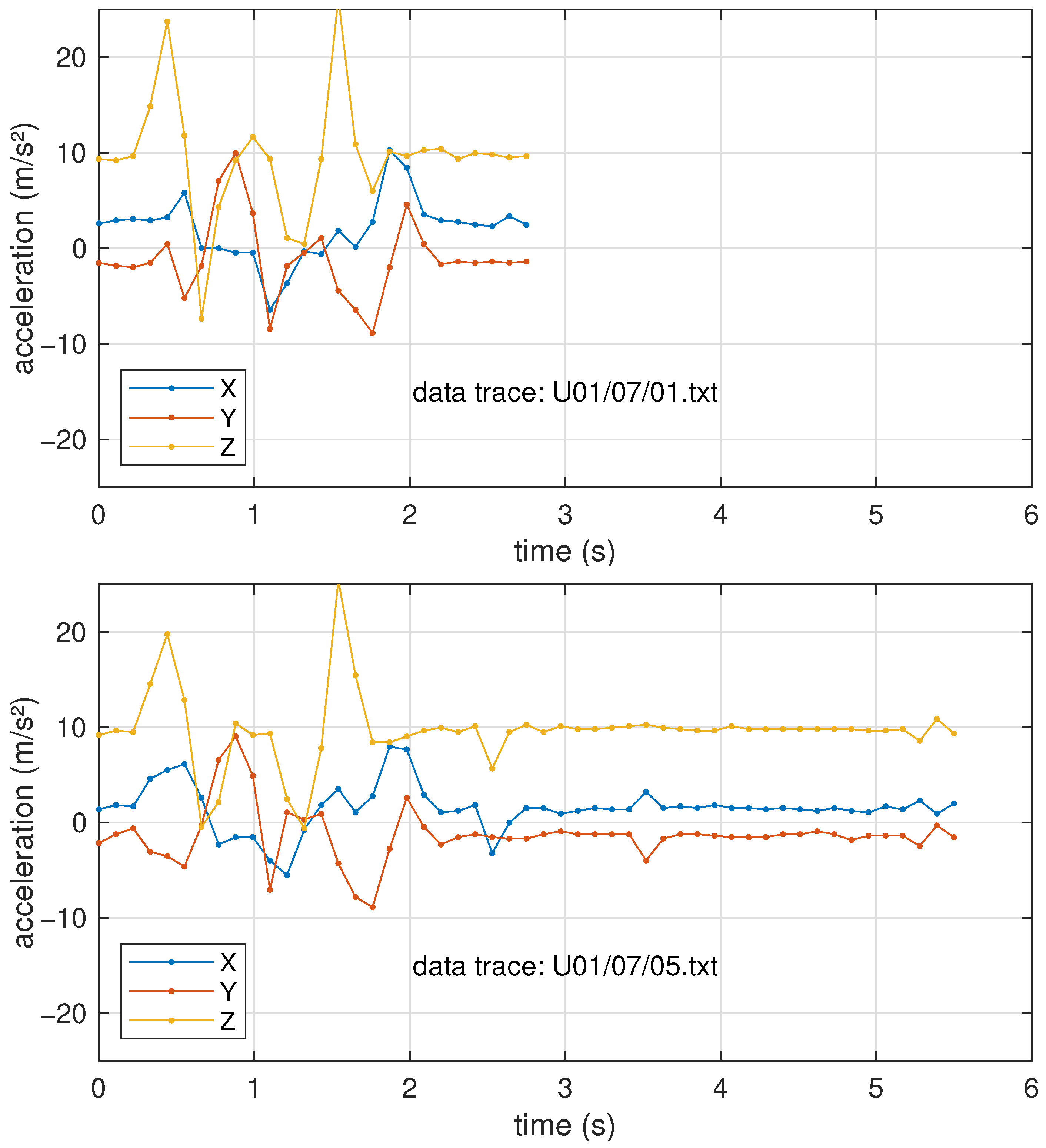
Figure 3, a common duration of 4 s (36 samples) was chosen, as only a few outliers needed to be truncated (and the discarded data turned out to be essentially constant, denoting a delay from the user in tapping the watch to stop the recording). On the contrary, the shorter segments were padded to the same length by repeating the last sample. Since most gestures end with a rest condition, it is reasonable to assume that the last acceleration samples are just due to the gravitational force, which should remain constant if no further movements are performed. An example of a couple of recordings to show this are reported in
Figure 4.
On the other hand, simple zero-padding, though it is a very common practice, would mean assuming the movement ended with a free fall, which is not reasonable.
The dataset was then prepared to train and test a network through a 4-fold subject-based cross-validation scheme, whereby a partition of the subjects into 4 groups of 2 is defined, and each group is used as validation for a network trained using the other 3 groups of subjects, as shown in
Table 1. This subject-based approach was chosen because it ensures that validation is performed with data recorded from persons never before seen during training, thus giving some confidence that the neural network is general enough to cope with real-world data acquired from diverse people.
The resulting split was already well balanced across the different classes (since most users performed the same number of repetitions of each exercise), as can be seen in
Table 2, so no further adjustments were made.
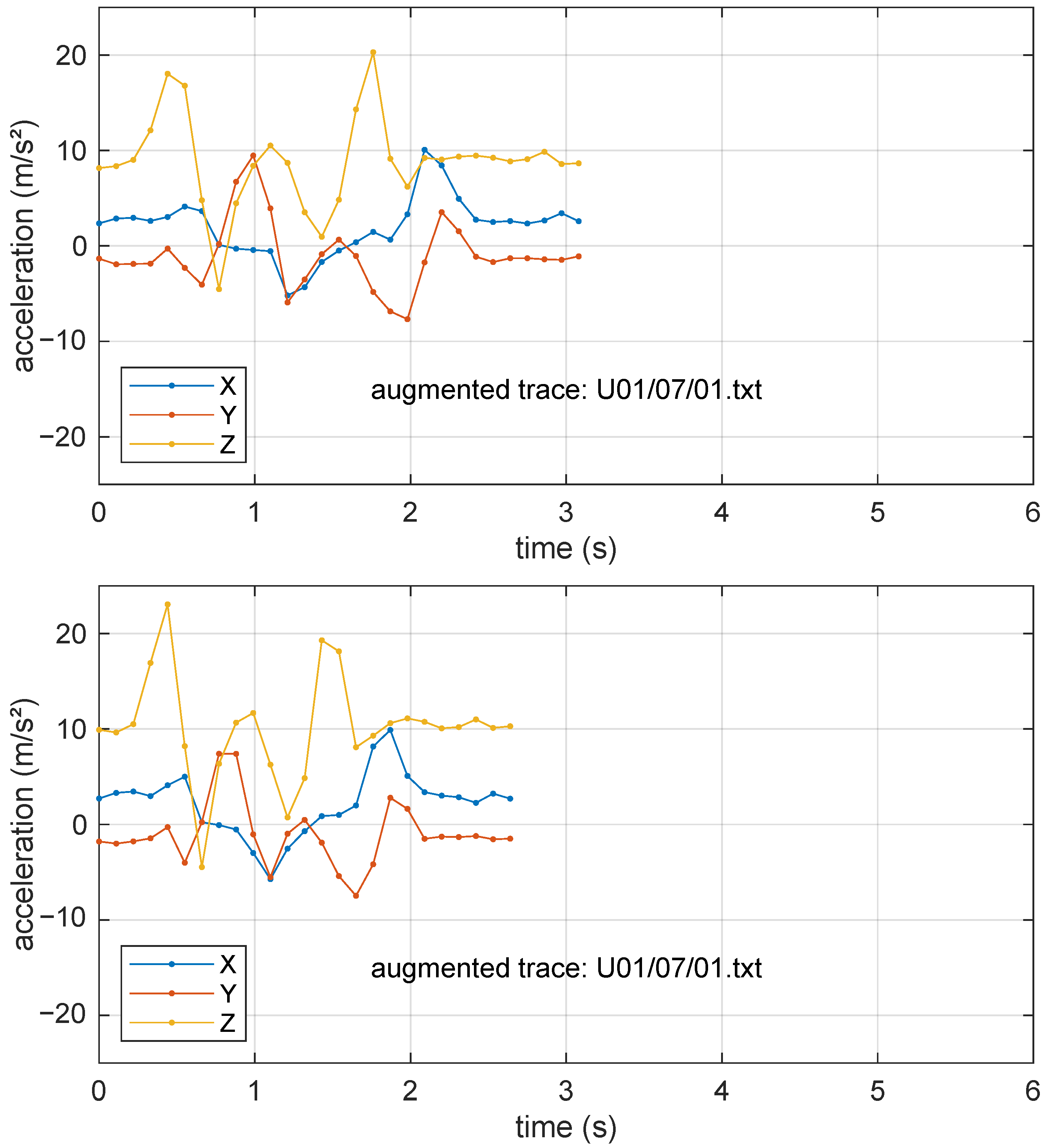
Finally, each training set was doubled in size using a data augmentation technique that included noise addition, random scaling, and time warping. The noise addition stage adds Gaussian white noise with a standard deviation equal to 5% of the signal standard deviation, while random scaling independently alters the magnitude of the three acceleration channels by a random amount between
% and
%. The time warping stage uses linear interpolation to extend or compress the gesture duration by up to 30%. As an example of what these “augmented” traces look like,
Figure 5 shows two samples of the sequence U01/07/01 (already shown in its original shape in
Figure 4) after being processed with the aforementioned steps.
4. Neural Network Architecture
Given the time-domain nature of the signals to be recognized, the neural network was chosen among the family of recurrent networks, or RNNs, so that the information on previous samples and the timing correlation between them could be better exploited. In particular, LSTM networks have been employed so that long-range correlations between samples can also be understood. The nodes of these networks are indeed more complex than regular neurons, and include, besides a hidden state, a forget gate, an update gate, and an output gate. Together, they allow for more trainable parameters while alleviating the problem of gradient vanishing or exploding during the training phase.
In order to take into account the memory limitations of the microcontroller platform on which the network is supposed to run, it is useful to perform an estimation of the computational and memory costs of different design choices.
Consider the j-th LSTM layer composed of cells attached to inputs (with because of the 3-axis acceleration data being processed, and for subsequent layers). Each LSTM cell has 4 McCulloch–Pitts neurons inside (3 to compute the “gating” factors with a “sigmoid” activation, and 1 to compute the candidate next state with a “tanh” activation) that act upon both the input ( values) and the previous state of the entire layer ( values). Each cell thus needs trainable weights (also counting the bias). The operation of the whole layer can basically be cast as a matrix multiplication between and followed by the computation of the activation functions, with , and is the concatenation of the input vector, state vector (previous output), and the constant 1 for the bias. In terms of computational cost, the matrix–vector multiplication requires multiply–accumulate operations (MACs). The computation of the non-linear activation functions is a bit more involved as it requires divisions. Counting only the floating point operations, a typical algorithm may require 5 MACs, 6 ADDs, and 1 DIV. For an LSTM layer, activations need to be computed and MACs are needed to combine them at the gates, leading to a grand total of approximately operations (neglecting the fact that the DIV is much more expensive than the others, but so are memory accesses, so this can only be a rough estimate). These layers also need to be evaluated for each sample in the input sequence, that is, 36 times in our case.
Dense layers, on the other hand, are much simpler. They need (using the same notation) weights to be stored and exactly one MAC operation per weight. ReLU activations are also much quicker to compute and basically negligible. Most importantly, they need to be evaluated only once per entire sequence.
With this information, it is possible to estimate the complexity in terms of number of weights (
) for, e.g., a four-layer network comprised of two LSTM layers and two dense layers:
where it was assumed
and
as per problem specifications.
,
, and
represent the design parameters that need to be chosen as a compromise between network complexity and classification performance. After extensive experimentation, the final choice is the structure shown in
Figure 6, with
,
, and
, resulting in an estimated number of trainable parameters (not including convergence-aiding layers such as batch normalization)
, which corresponds to about 30% memory usage for weight storage, and requires about 2,932,692 FLOPs to be computed.
The hidden dense layer uses the ReLU activation function, and the model was fitted with the aid of an L2 kernel regularization function to further prevent overfitting from occurring. The output layer finally uses softmax activation to help predict class membership probabilities. Normalization and dropout stages (with a 30% discard rate) were also added to help with data scaling and alleviating the risk of overfitting.
Table 3 shows the details of each layer with the count of trainable parameters. This architecture requires a total of 74,820 parameters, which can easily fit into the available memory of the chosen microcontroller.
4.1. Model Training
The network presented previously was trained using the TensorFlow 2.12.0 framework with the aid of Keras 2.12.0 to ease model definition and fitting, using the Google Colaboratory platform. The Adam optimizer with a learning rate of 0.0005 was used. Up to 70 training epochs with a batch size of 32 were scheduled, but the early stopping criterion (with a patience set to 10) ensured that on average only 30 epochs were needed to train each fold.
4.2. Microcontroller Platform
The platform chosen for the application was a RushUp Cloud-JAM L4 board (
https://github.com/rushup/Cloud-JAM-L4, accessed on 16 April 2025), based on an STMicroelectronics STM32L476RG microcontroller, which features an 80 MHz ARM Cortex-M4 32 bit CPU + FPU and integrates 1 MiB of flash memory and 128 KiB of SRAM. It draws 3 mA of current at full speed. The board is also equipped with an STMicroelectronics iNEMO LSM6DSL inertial platform, and, among other sensors and stuff, a WiFi module, making it ideal for acceleration-based gesture recognition tasks such as the one presented in this paper.
The trained model of the neural network was converted to C code suitable to be run on the microcontroller with the aid of the STM32Cube AI tool (version 10.0) (
https://www.st.com/en/embedded-software/x-cube-ai.html, accessed on 16 April 2025), which is integrated into the STM32Cube IDE. This tool provides a comprehensive solution for importing Keras (or other) models, analyzing them for compatibility and memory usage, and converting them into optimized C code tailored for the target architecture. The resulting network can be evaluated with test input data both on the host computer and directly on the device, enabling the collection of various performance metrics such as execution time, hardware operation counts, and accuracy.
5. Results
The network so trained had been tested both on the Colab platform and directly on the microcontroller platform, to ensure model validity and that the porting on the microcontroller did not introduce unwanted discrepancies. The results turned out to be indeed identical.
The resulting confusion matrix, averaged across all four folds, is reported in
Figure 7.
Specifically, each fold resulted in the performance shown in
Table 4, with an overall accuracy (averaged over all four folds) of 90.25%.
The addition of noise performed during the data augmentation phase should theoretically help improve noise immunity during inference. To test the network robustness to noise, an additional experiment in which white Gaussian noise was artificially added to the validation set before inference was performed. It is hard to exactly quantify the effect, as training and noise are inherently non-deterministic processes so the results tend to vary slightly from run to run, but we consistently obtained an accuracy of 90% ± 0.5% in all our test runs with a noise standard deviation of 0.2 m/s
2. This level of noise was chosen because it mimics the random fluctuations that can be seen, e.g., in the tail portion of
Figure 4, and also corresponds (on average) to the 5% that was added during data augmentation.
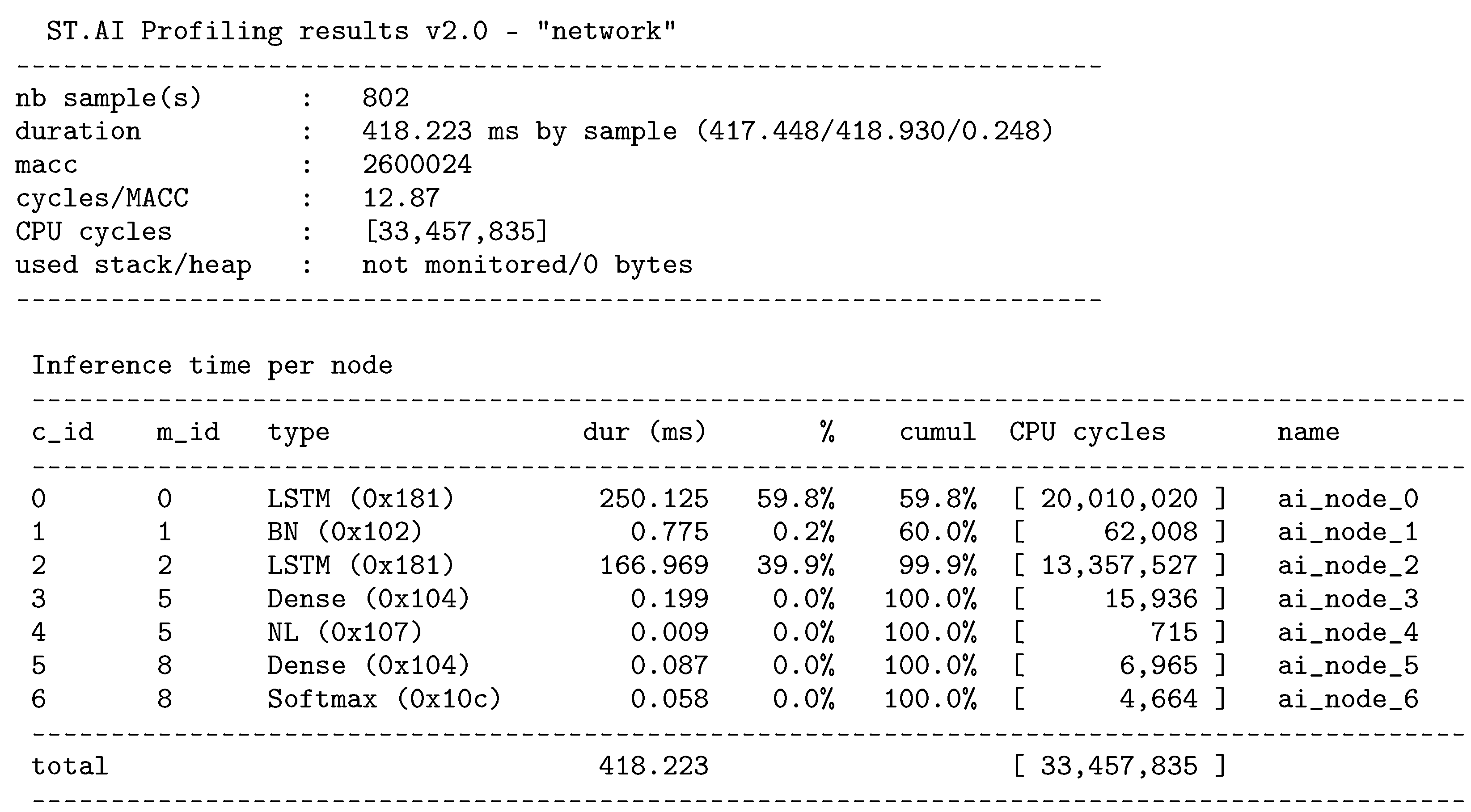
With regard to the porting of the neural network on the embedded platform, the porting consumed 291.96 KiB of flash memory for weight storage and 17.22 KiB of RAM for the activations. Finally, a summary of the computational complexity and the ensuing computation times are reported in
Figure 8.
The reference platform used in this paper (Cloud-JAM L4) was chosen for its low-power capabilities, as it employs an L-series microcontroller. As a reference, the network performance was also evaluated on higher-end microcontroller platforms using the ST Edge AI Developer Cloud (
https://stm32ai.st.com/st-edge-ai-developer-cloud/, accessed on 9 May 2025), a free online service for developing/testing AI models on ST devices, including MCU, MPU, and MEMS sensors, which offers tools for creation, optimization, and benchmarking of these models.
Table 5 shows the results achieved in terms of inference time, computational complexity, specifically MAC instructions, and memory footprint to run the model deployed in different ARM Cortex-M MCUs. The model’s weights were represented in 32-bit floating point precision.
6. Discussion
The proposed network architecture allowed a compact implementation on the selected microcontroller, using only 28.5% of the available flash memory, leaving plenty of space for application code and other system functionalities, while achieving a 90.25% average accuracy on a 4-fold subject-based cross-validation test. In terms of computation speed, the model runs in less than half a second, while processing 4 s worth of input data, despite the platform we used being the one with the lowest clock frequency amongst those customarily used for edge AI. This means that the system can easily run in real time, actually eight times faster, allowing for a clock frequency reduction (if the rest of the application allows) to further reduce power consumption from the nominal 3 mA at full speed.
As far as accuracy, the results seem very promising, as mistakes were basically only made between a gesture and another which was either a superset or a subset of the movements, or a “smoothed” version of the other, such as 9% of “square-clockwise” movements were incorrectly labeled as “circle-clockwise”, as can be seen in the confusion matrix shown in
Figure 7. Future research can try and address this problem by adding a better gesture segmentation algorithm and/or adding additional features, such as gesture duration, to the training data. Moreover, the network proved to be quite immune to noise, as tests performed by adding white Gaussian noise to the inference data with a power similar to that measured on real samples did not show significant differences in the overall accuracy.
As far as the positioning of the achieved performance with respect to the existing literature, there are no published results for a full 20-class recognition accuracy on this dataset. Some other works that used the same dataset are listed in
Table 6. These include [
39], which used the full dataset to pre-train a network then tested in a continual learning setting (named LEE, Latent Embedding Exploration) on a smaller number of classes (6), achieving accuracies between 57.0% and 69.3% depending on the length of the used sequence. Ref. [
41] also used an LSTM network to recognize eight classes (namely gestures 1, 2, 3, 4, 13, 16, 17, and 19 from
Figure 2), achieving a classification error rate of 11.43%, which is comparable to our accuracy, but using a much more powerful embedded platform based on an ARM Cortex-A9 microprocessor with plenty of available memory, and without performing a subject-based split of the training data. The same authors of the dataset used in this work presented some classification results on a slightly different and smaller version of it [
40], where they achieved an accuracy up to 95.8% using an SVM-based (which in general is much more computationally demanding than a neural network) classifier, but again without performing a subject-based split of the training data. Using a leave-one-subject-out validation, which is more similar to our 4-fold cross-validation, resulted in an accuracy ranging between 91.08% and 92.33% as shown in the table. It is worth noting that, to the best of our knowledge, there are no works in the published literature that tried to recognize this dataset on an embedded microcontroller platform, as shown in the aforementioned
Table 6.
Table 6.
Comparative studies with state-of-the-art gesture recognition methodologies on the SmartWatch Gesture Dataset.
Table 6.
Comparative studies with state-of-the-art gesture recognition methodologies on the SmartWatch Gesture Dataset.
| Work | Method | Parameter Memory | No. Classes | Accuracy | Validation Method | Embedded
Implementation |
|---|
| Rafiq et al. [39] | LEE | N/A | 6 | 69.30% | holdout | no |
| Shin et al. [41] | LSTM-RNN | 17.25 KB | 8 | 88.57% | holdout | no |
| Porzi et al. [40] | fGAK-SVMHAAR-SVM | N/A | 8 | 92.33% 91.08% | k-fold | no |
| This Work | LSTM | 292.27 KiB | 20 | 90.25% | k-fold | yes |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}