
An Improved Segformer for Semantic Segmentation of UAV-Based Mine Restoration Scenes

Abstract
1. Introduction
- (1)
- We propose a Segformer-based semantic segmentation model with an encoder–FPN–decoder architecture. An FPN is introduced between the encoder and decoder to strengthen top-down fusion of multi-level features, addressing the limitations of the original Segformer in semantic–spatial information interaction.
- (2)
- We design the multi-scale feature-enhanced FPN (MSFE-FPN). Specifically, we incorporate a selective feature aggregation pyramid pooling module (SFA-PPM) in the deepest lateral connection to enhance global semantic perception and integrate efficient local attention (ELA) modules into other lateral connections to improve edge feature extraction and small-object recognition.
- (3)
- We construct a UAV-based semantic segmentation dataset for mine restoration—the HUNAN Mine UAV Dataset (HNMUD), which contains 2700 high-resolution annotated images. Additionally, we conduct generalization experiments on the publicly available Aeroscapes dataset to validate the cross-domain adaptability and robustness of the proposed model.
2. Related Work
2.1. Deep Learning for Image Segmentation
2.2. Semantic Segmentation of UAV Images
3. Materials and Methods
3.1. Datasets
3.1.1. HUNAN Mine UAV Datasets
3.1.2. Aeroscapes Dataset
3.2. Methods
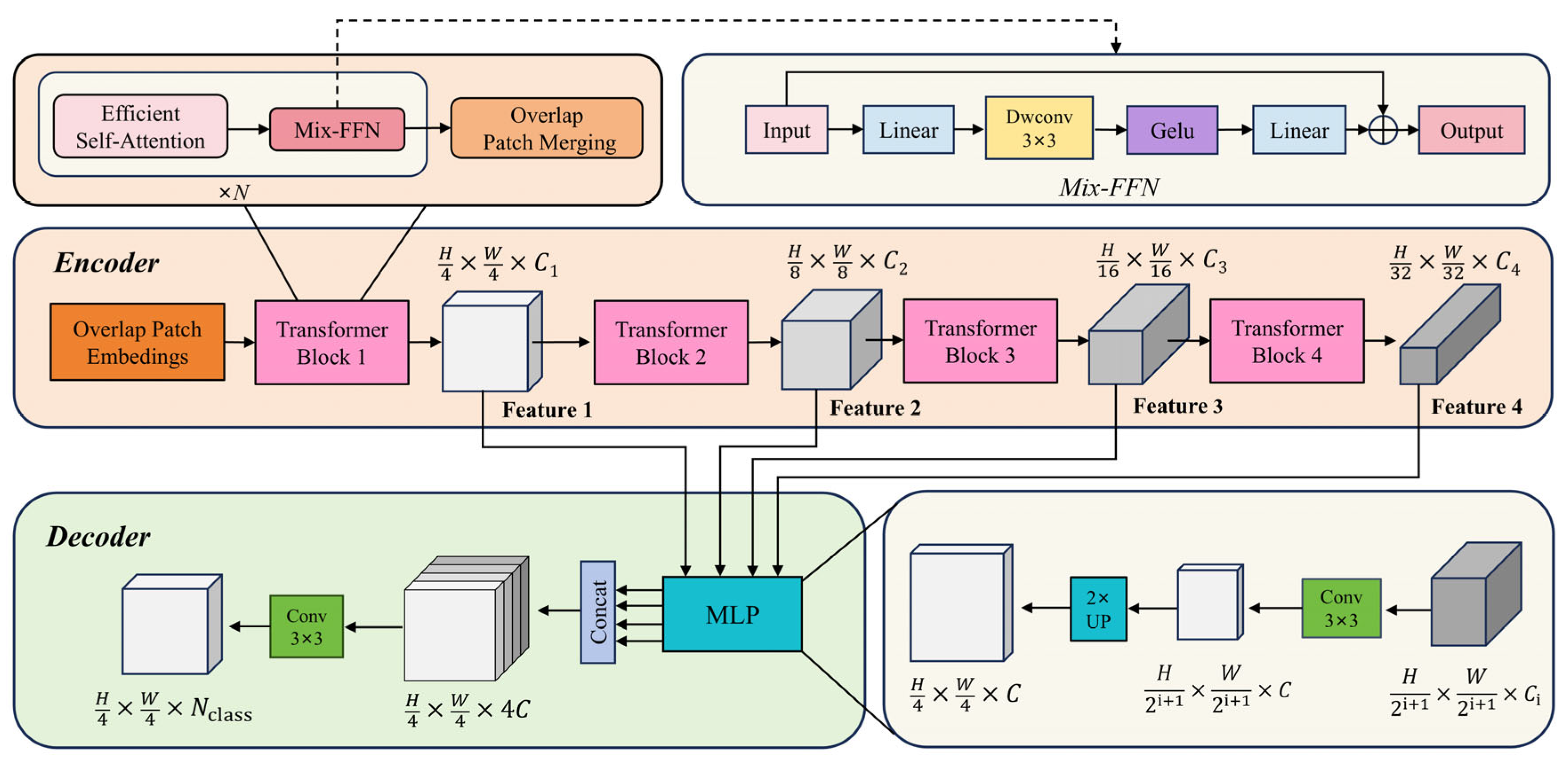
3.2.1. The Segformer Network
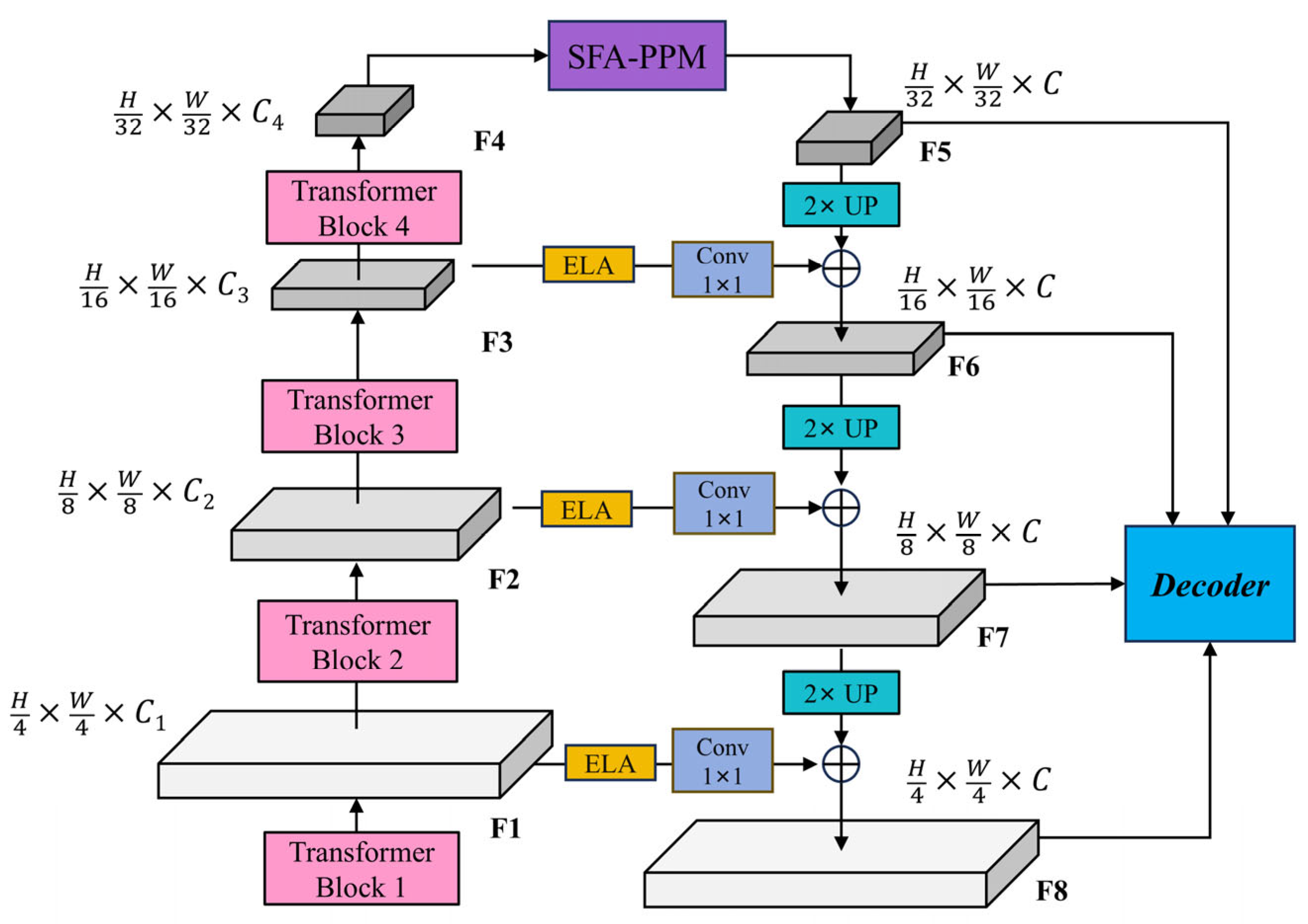
3.2.2. The Overview of Improved Segformer Architecture
3.2.3. The Multi-Scale Feature Enhancement Feature Pyramid Network Structure
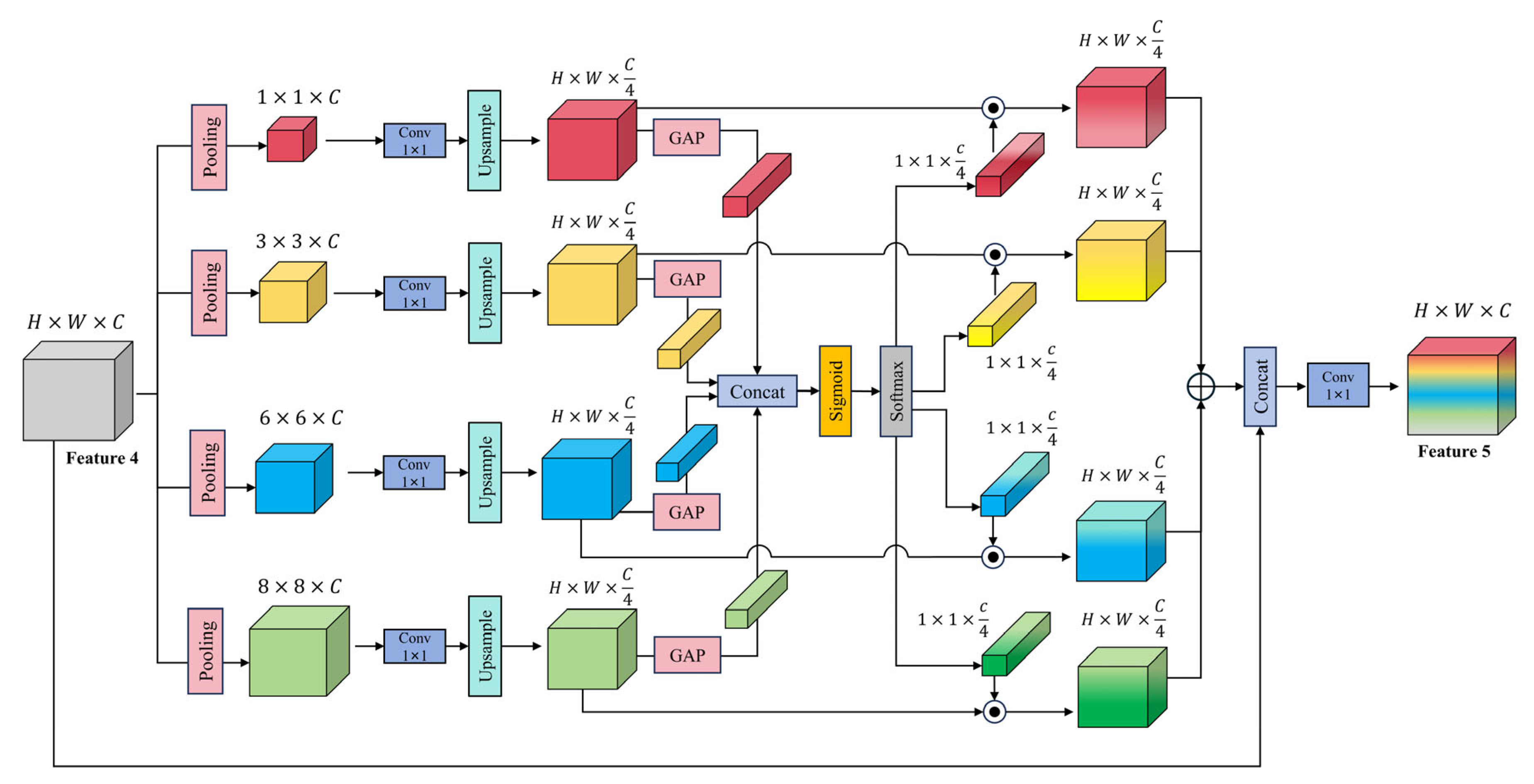
3.2.4. The Selective Feature Aggregation Pyramid Pooling Module
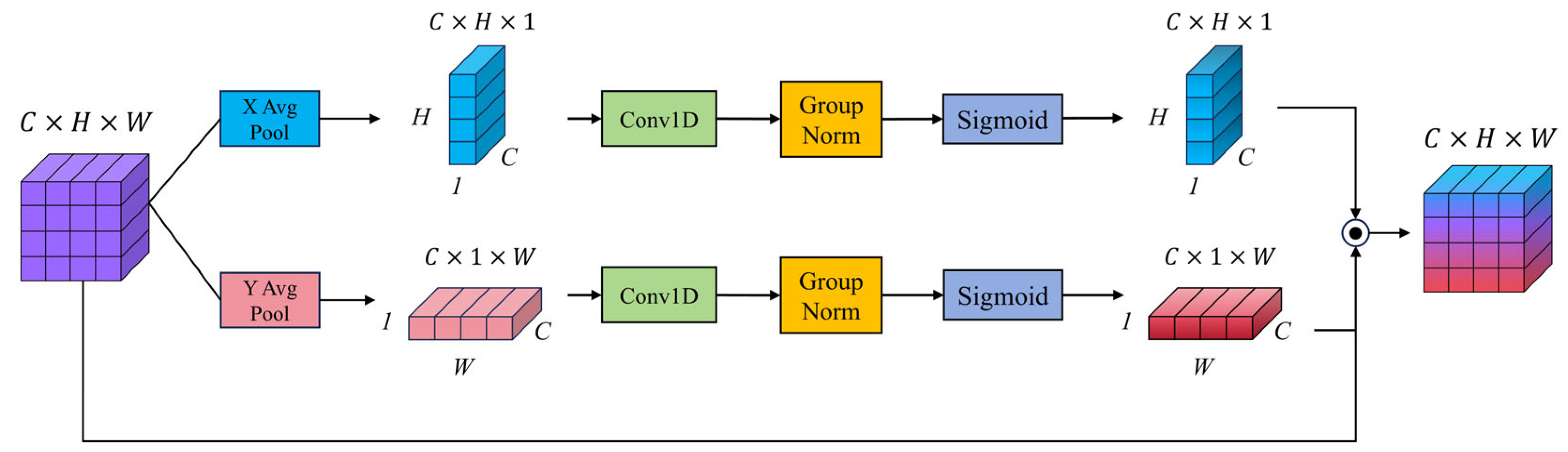
3.2.5. The Efficient Local Attention Module
4. Experimental Results and Analyses
4.1. Experimental Setup and Evaluation Metrics
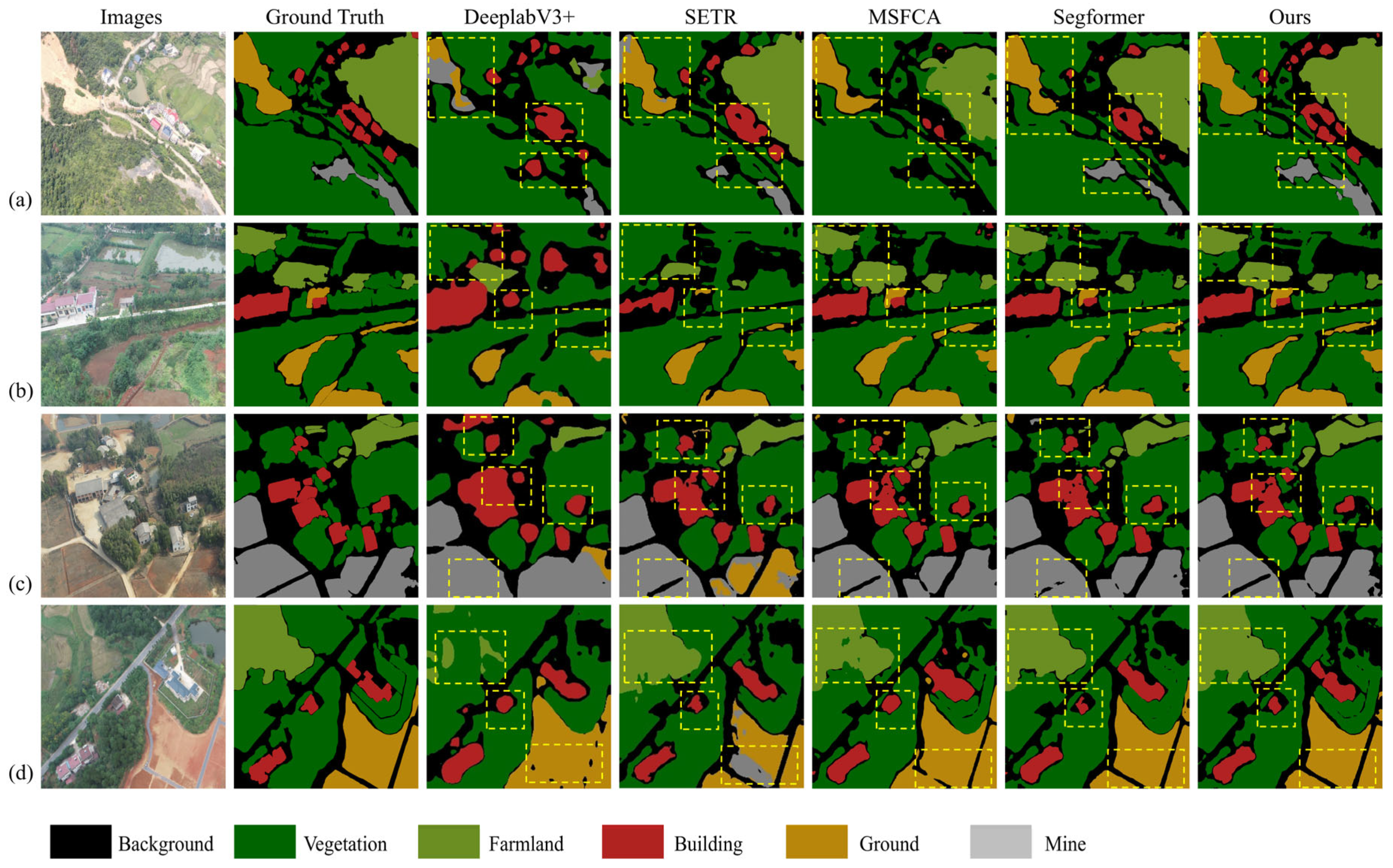
4.2. Comparison with Other Methods
4.2.1. Experiments on the HUNAN Mine UAV Datasets
4.2.2. Experiments on the Aeroscapes Dataset
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, C.; Min, A.; Zhang, W.; Long, Y.; Zhang, D.; Wu, H.; Wu, B.; Zhang, Z.; Xiong, P. Vegetation Restoration Effectiveness in Mianshan Abandoned Mine, Dongzhi County, China: Considering Habitat Diversity and Critical Drivers. Forests 2024, 15, 2213. [Google Scholar] [CrossRef]
- Li, M.S. Ecological Restoration of Mineland with Particular Reference to the Metalliferous Mine Wasteland in China: A Review of Research and Practice. Sci. Total Environ. 2006, 357, 38–53. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Yu, B.; Jia, Y.; Xu, X.; Zhou, P.; Yu, M.; Liu, J. Influence of Sewage Sludge Compost on Heavy Metals in Abandoned Mine Land Reclamation: A Large-Scale Field Study for Three Years. J. Hazard. Mater. 2025, 486, 137098. [Google Scholar] [CrossRef] [PubMed]
- Tibbett, M. Post-Mining Ecosystem Reconstruction. Curr. Biol. 2024, 34, R387–R393. [Google Scholar] [CrossRef]
- Harries, K.L.; Woinarski, J.; Rumpff, L.; Gardener, M.; Erskine, P.D. Characteristics and Gaps in the Assessment of Progress in Mine Restoration: Insights from Five Decades of Published Literature Relating to Native Ecosystem Restoration after Mining. Restor. Ecol. 2024, 32, e14016. [Google Scholar] [CrossRef]
- Cheng, J.; Deng, C.; Su, Y.; An, Z.; Wang, Q. Methods and Datasets on Semantic Segmentation for Unmanned Aerial Vehicle Remote Sensing Images: A Review. ISPRS J. Photogramm. Remote Sens. 2024, 211, 1–34. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; Farias, P.R.S.; Marcato Junior, J.; Calil, F.N.; Teodoro, P.E. A Review on Deep Learning in UAV Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Li, X.; Ding, H.; Yuan, H.; Zhang, X.; Lu, Y.; Luo, P. Transformer-Based Visual Segmentation: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10138–10163. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI 2015: Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You NeedJ. arXiv 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. Segformer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar] [CrossRef]
- Xu, W.; Wan, Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks. arXiv 2024, arXiv:2403.01123. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar] [CrossRef]
- Giang, T.L.; Dang, K.B.; Le, Q.T.; Nguyen, V.G.; Tong, S.S.; Pham, V.-M. U-Net Convolutional Networks for Mining Land Cover Classification Based on High-Resolution UAV Imagery. IEEE Access 2020, 8, 186257–186273. [Google Scholar] [CrossRef]
- Saxena, V.; Jain, Y.; Mittal, S. A Deep Learning Based Approach for Semantic Segmentation of Small Fires from UAV Imagery. Remote Sens. Lett. 2025, 16, 277–289. [Google Scholar] [CrossRef]
- Hanyu, T.; Yamazaki, K.; Tran, M.; McCann, R.A.; Liao, H.; Rainwater, C.; Adkins, M.; Cothren, J.; Le, N. AerialFormer: Multi-Resolution Transformer for Aerial Image Segmentation. arXiv 2023, arXiv:2306.06842. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UnetFormer: A Unet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- He, W.; Li, J.; Cao, W.; Zhang, L.; Zhang, H. Building Extraction from Remote Sensing Images via an Uncertainty-Aware Network. arXiv 2023, arXiv:2307.12309. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep Learning and Transformer Approaches for UAV-Based Wildfire Detection and Segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef]
- Cao, X.; Tian, Y.; Yao, Z.; Zhao, Y.; Zhang, T. Semantic Segmentation Network for Unstructured Rural Roads Based on Improved SPPM and Fused Multiscale Features. Appl. Sci. 2024, 14, 8739. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Dinavahi, V.; Yang, L.; Wu, D.; Shen, M. Landslide Recognition Based on DeepLabv3+ Framework Fusing ResNet101 and ECA Attention Mechanism. Appl. Sci. 2025, 15, 2613. [Google Scholar] [CrossRef]
- Xu, S.; Yang, B.; Wang, R.; Yang, D.; Li, J.; Wei, J. Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network. Drones 2025, 9, 237. [Google Scholar] [CrossRef]
- Zheng, Z.; Yuan, J.; Yao, W.; Yao, H.; Liu, Q.; Guo, L. Crop Classification from Drone Imagery Based on Lightweight Semantic Segmentation Methods. Remote Sens. 2024, 16, 4099. [Google Scholar] [CrossRef]
- Jin, Y.; Liu, X.; Huang, X. EMR-HRNet: A Multi-Scale Feature Fusion Network for Landslide Segmentation from Remote Sensing Images. Sensors 2024, 24, 3677. [Google Scholar] [CrossRef]
- Wang, C.; Yang, S.; Zhu, P.; Li, M.; Li, Y. Extraction of Winter Wheat Planting Plots with Complex Structures from Multispectral Remote Sensing Images Based on the Modified Segformer Model. Agronomy 2024, 14, 2433. [Google Scholar] [CrossRef]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble knowledge transfer for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1499–1508. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 19–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| CPU | Intel Xeon Gold 5218R |
| GPU | NVIDIA GTX 3090 |
| Memory | 128G |
| Operating System | Windows10 |
| CUDA | Cuda 11.8 |
| Pytorch | Pytorch 2.0.1 |
| Model | mIoU (%) | mPA (%) | mRecall (%) | mF1 (%) |
|---|---|---|---|---|
| U-Net [12] | 62.43 | 81.25 | 73.26 | 75.90 |
| PSPNet [22] | 67.14 | 83.47 | 82.28 | 82.84 |
| Deeplabv3+ [15] | 76.20 | 86.35 | 85.97 | 86.13 |
| SETR [18] | 76.59 | 86.69 | 86.57 | 86.48 |
| Swin Transformer [23] | 83.78 | 89.98 | 89.68 | 89.60 |
| Mask2former [24] | 84.32 | 91.26 | 91.46 | 91.36 |
| Segformer [19] | 88.25 | 92.10 | 93.16 | 92.83 |
| EMR-HRNet [35] | 88.45 | 92.63 | 92.47 | 92.58 |
| MSFCA [36] | 89.27 | 93.85 | 93.54 | 93.67 |
| Ours | 90.85 | 94.77 | 94.62 | 94.69 |
| Model | mIoU (%) | mPA (%) | mRecall (%) | mF1 (%) |
|---|---|---|---|---|
| U-Net [12] | 70.88 | 81.25 | 79.26 | 80.90 |
| PSPnet [22] | 75.81 | 85.11 | 84.35 | 84.75 |
| Deeplabv3+ [15] | 77.24 | 86.24 | 85.52 | 85.87 |
| SETR [18] | 78.59 | 86.69 | 86.57 | 86.48 |
| Swin Transformer [23] | 81.36 | 88.37 | 87.96 | 88.12 |
| Mask2former [24] | 81.91 | 89.87 | 89.19 | 89.50 |
| Segformer [19] | 81.46 | 89.25 | 89.36 | 89.32 |
| EMR-HRNet [35] | 82.93 | 88.31 | 89.02 | 88.46 |
| MSFCA [36] | 83.27 | 89.82 | 90.24 | 90.07 |
| Ours | 84.20 | 91.17 | 91.41 | 91.25 |
| Baseline | FPN | SFA-PPM | ELA | mIoU (%) | mPA (%) | mRecall (%) | mF1 (%) |
|---|---|---|---|---|---|---|---|
| √ | - | - | - | 88.25 | 92.10 | 93.16 | 92.83 |
| √ | √ | - | - | 88.58 | 92.52 | 93.54 | 93.24 |
| √ | √ | √ | - | 89.82 | 94.28 | 94.58 | 94.37 |
| √ | √ | √ | √ | 90.85 | 94.77 | 94.62 | 94.69 |
| Baseline | FPN | SFA-PPM | ELA | mIoU (%) | mPA (%) | mRecall (%) | mF1 (%) |
|---|---|---|---|---|---|---|---|
| √ | - | - | - | 81.46 | 89.25 | 89.36 | 89.32 |
| √ | √ | - | - | 82.55 | 89.92 | 90.12 | 90.08 |
| √ | √ | √ | - | 83.68 | 90.73 | 91.04 | 90.92 |
| √ | √ | √ | √ | 84.20 | 91.17 | 91.41 | 91.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Zhang, L.; Jiang, T.; Li, Z.; Wu, W.; Kuang, Y. An Improved Segformer for Semantic Segmentation of UAV-Based Mine Restoration Scenes. Sensors 2025, 25, 3827. https://doi.org/10.3390/s25123827
Wang F, Zhang L, Jiang T, Li Z, Wu W, Kuang Y. An Improved Segformer for Semantic Segmentation of UAV-Based Mine Restoration Scenes. Sensors. 2025; 25(12):3827. https://doi.org/10.3390/s25123827
Chicago/Turabian StyleWang, Feng, Lizhuo Zhang, Tao Jiang, Zhuqi Li, Wangyu Wu, and Yingchun Kuang. 2025. "An Improved Segformer for Semantic Segmentation of UAV-Based Mine Restoration Scenes" Sensors 25, no. 12: 3827. https://doi.org/10.3390/s25123827
APA StyleWang, F., Zhang, L., Jiang, T., Li, Z., Wu, W., & Kuang, Y. (2025). An Improved Segformer for Semantic Segmentation of UAV-Based Mine Restoration Scenes. Sensors, 25(12), 3827. https://doi.org/10.3390/s25123827