
Res-RBG Facial Expression Recognition in Image Sequences Based on Dual Neural Networks


Abstract
1. Introduction
- (1)
- To fully extract facial expression features in both spatial and temporal dimensions and achieve facial expression recognition in image sequences with few network parameters and low computational complexity, a hybrid network is proposed by cascading the ResNet50 and GRU networks;
- (2)
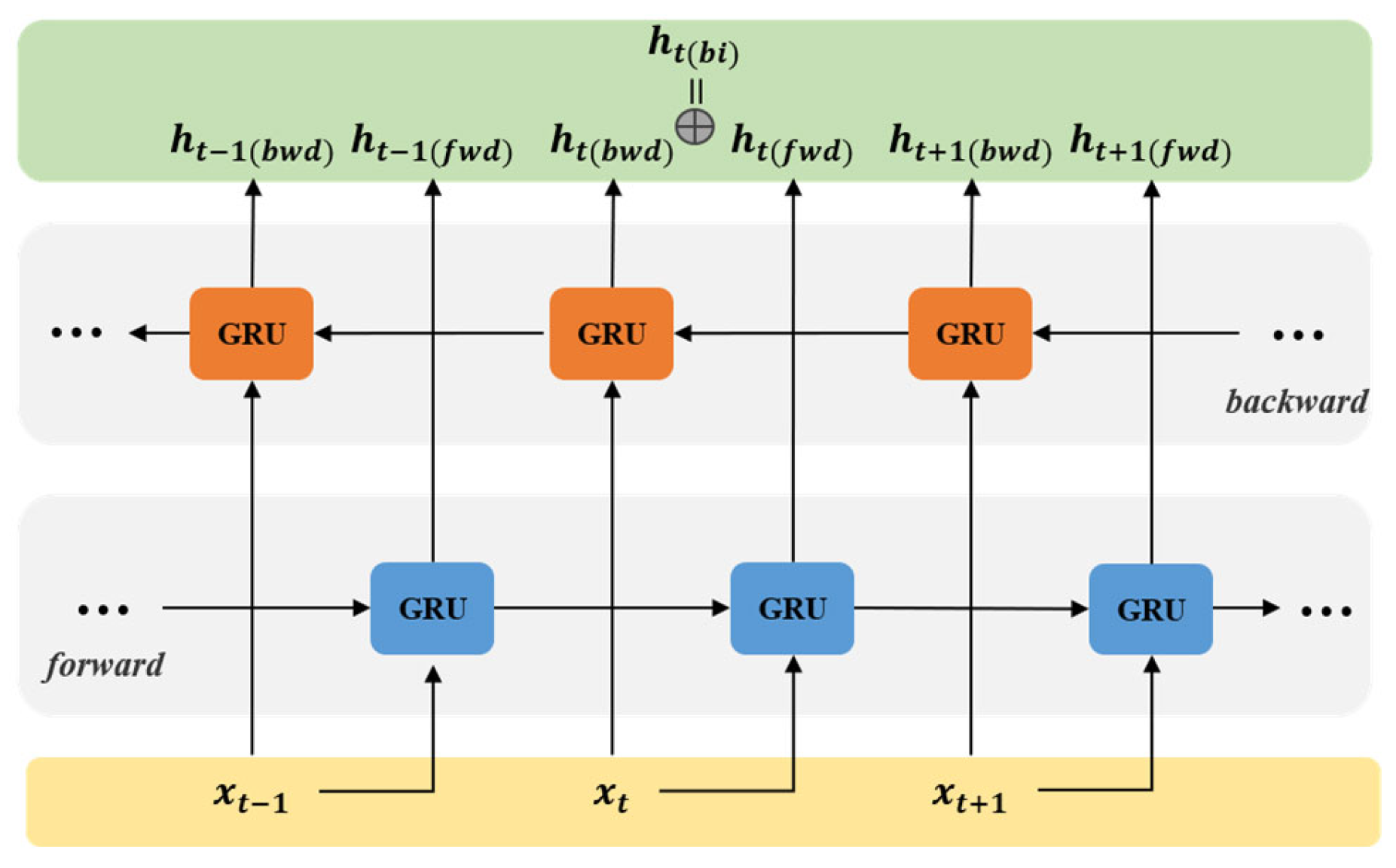
- To fully utilize temporal information between sequences, promote the integrity of the information flow throughout the network, and address issues such as gradient vanishing, this paper introduces a bidirectional GRU network based on the GRU network; additionally, following the principles of residual structures, an RBG network is designed;
- (3)
- To effectively enhance the network’s ability to extract key features and improve the efficiency of facial expression recognition in image sequences, this paper embeds an improved lightweight and efficient channel attention module (G-ECANet) into the ResNet50 network.
2. Related Work
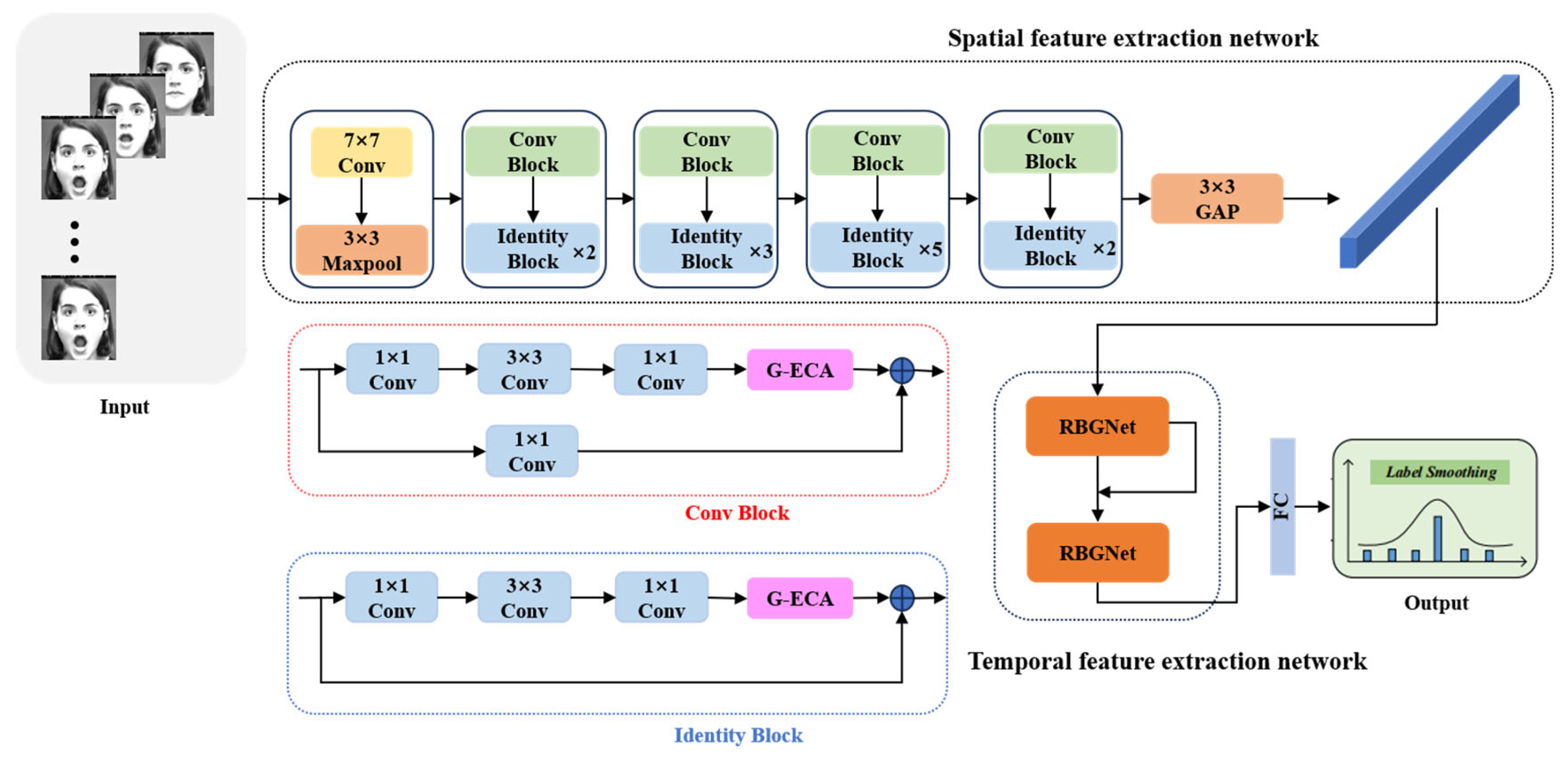
2.1. The Model of Facial Expression Recognition
2.1.1. Spatial Feature Extraction Network
2.1.2. Temporal Feature Extraction Network
2.2. Dataset and Data Preprocessing
2.2.1. Dataset
2.2.2. Data Preprocessing
3. Models and Methods
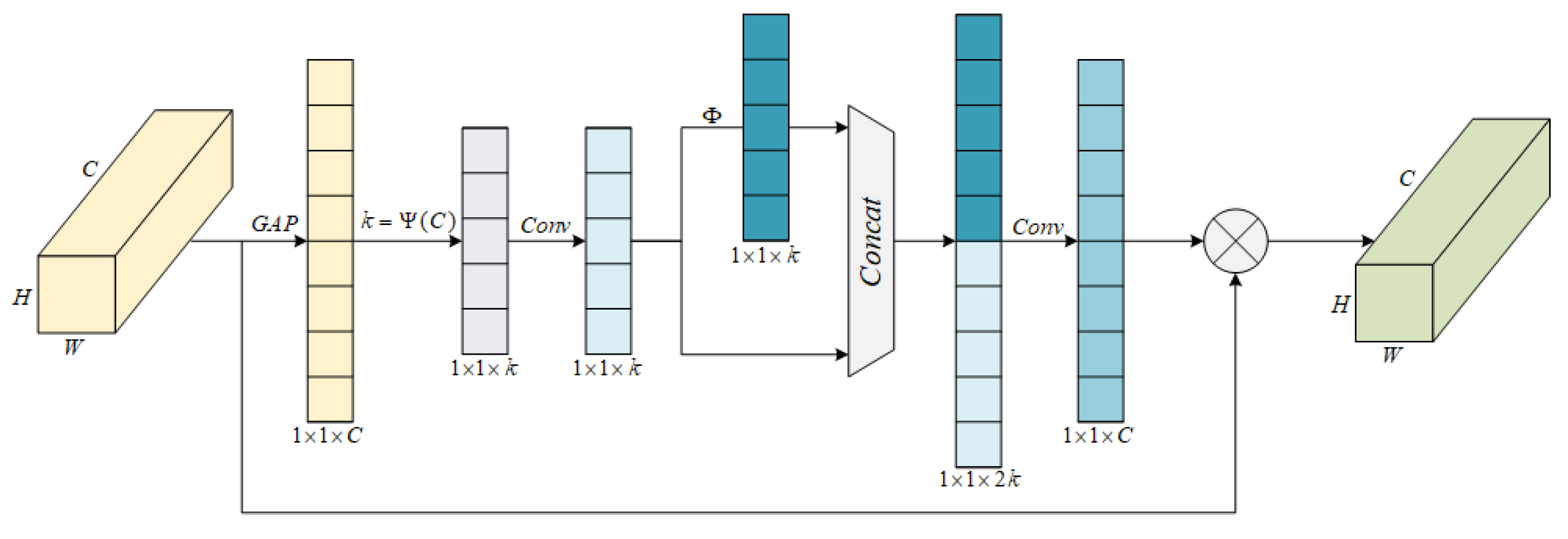
3.1. The Design of the G-ECANet Network
3.2. The Design of the RBG Network
| Algorithm 1 RBG Neural Network |
| Input: |
| X ∈ ℝ^(T×d_in) // Input sequence of length T with d_in features |
| n_layers = 6 // Total number of stacked layers |
| d_hidden // Hidden state dimension |
| training_flag // Boolean for train/inference mode |
| Output: |
| y ∈ ℝ^(T×d_out) // Output sequence |
| 1: // Initialization |
| 2: for l ← 1 to n_layers do |
| 3: if l ≤ 2 then |
| 4: W_gru[l] ← Initialize GRU Weights(d_hidden) |
| 5: else |
| 6: W_bn[l] ← Initialize BatchNorm Params() |
| 7: W_gru[l] ← Initialize Bi-GRU Weights(d_hidden) |
| 8: end if |
| 9: end for |
| 10: // Forward pass |
| 11: h ← X |
| 12: for l ← 1 to n_layers do |
| 13: if l > 2 then |
| 14: h ← BatchNorm(h, W_bn[l], training_flag) |
| 15: end if |
| 16: h ← ReLU(h) // Element-wise activation |
| 17: if l ≤ 2 then |
| 18: h ← GRU(h, W_gru[l]) // Unidirectional GRU |
| 19: else |
| 20: h ← BiGRU(h, W_gru[l]) // Bidirectional GRU |
| 21: end if |
| 22: end for |
| 23: y ← LinearProjection(h) // Final output layer |
| 24: return y |
3.3. The Construction of the Dual Neural Network Res-RBG
4. Experiments and Analysis
4.1. Experimental Evaluation Indicators
4.2. Network Parameter Settings
4.2.1. Determination of RBG Network Layers
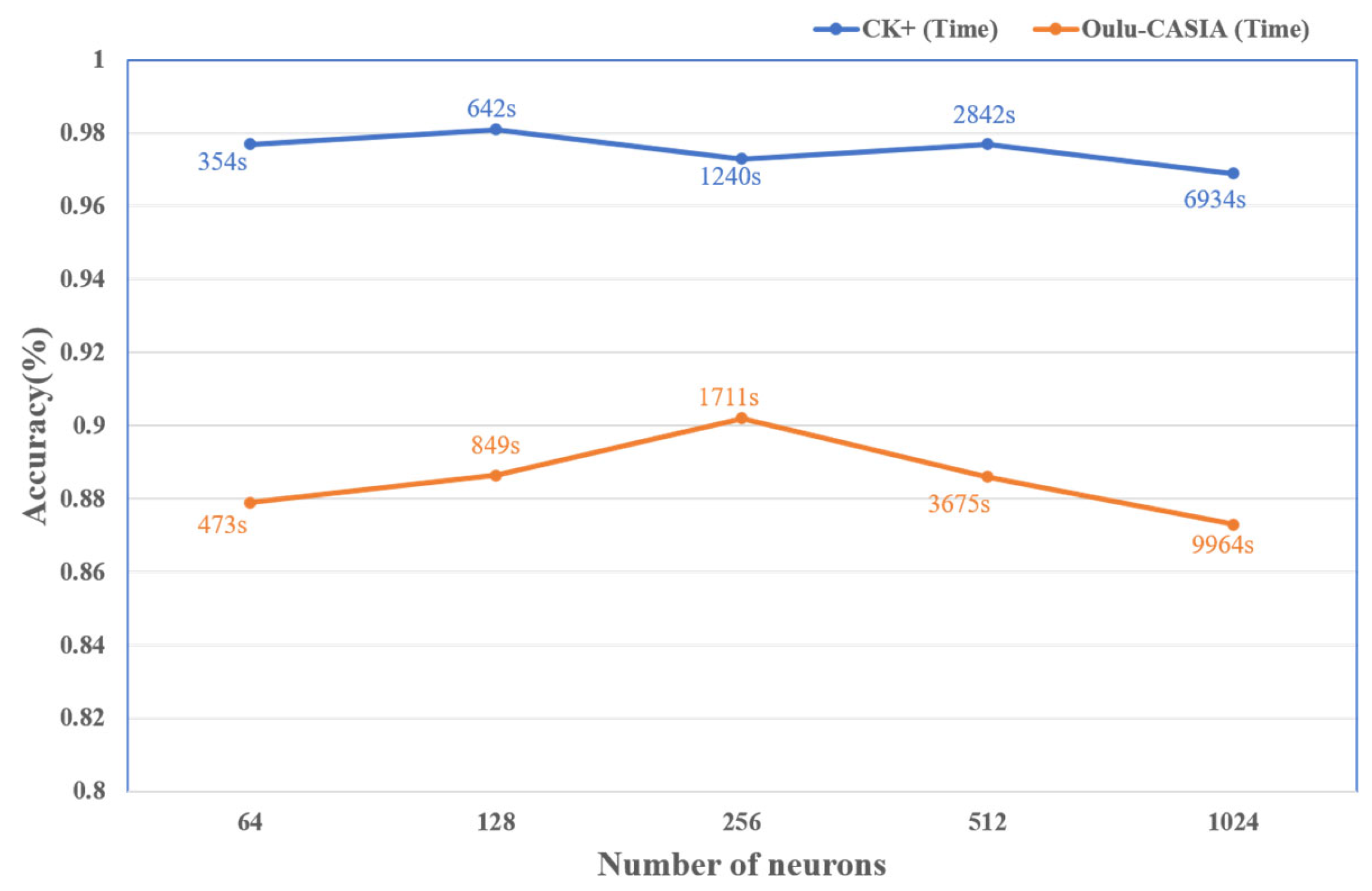
4.2.2. Determination of the Number of Neurons in the Hidden Layer of GRU
4.3. Ablation Experiments
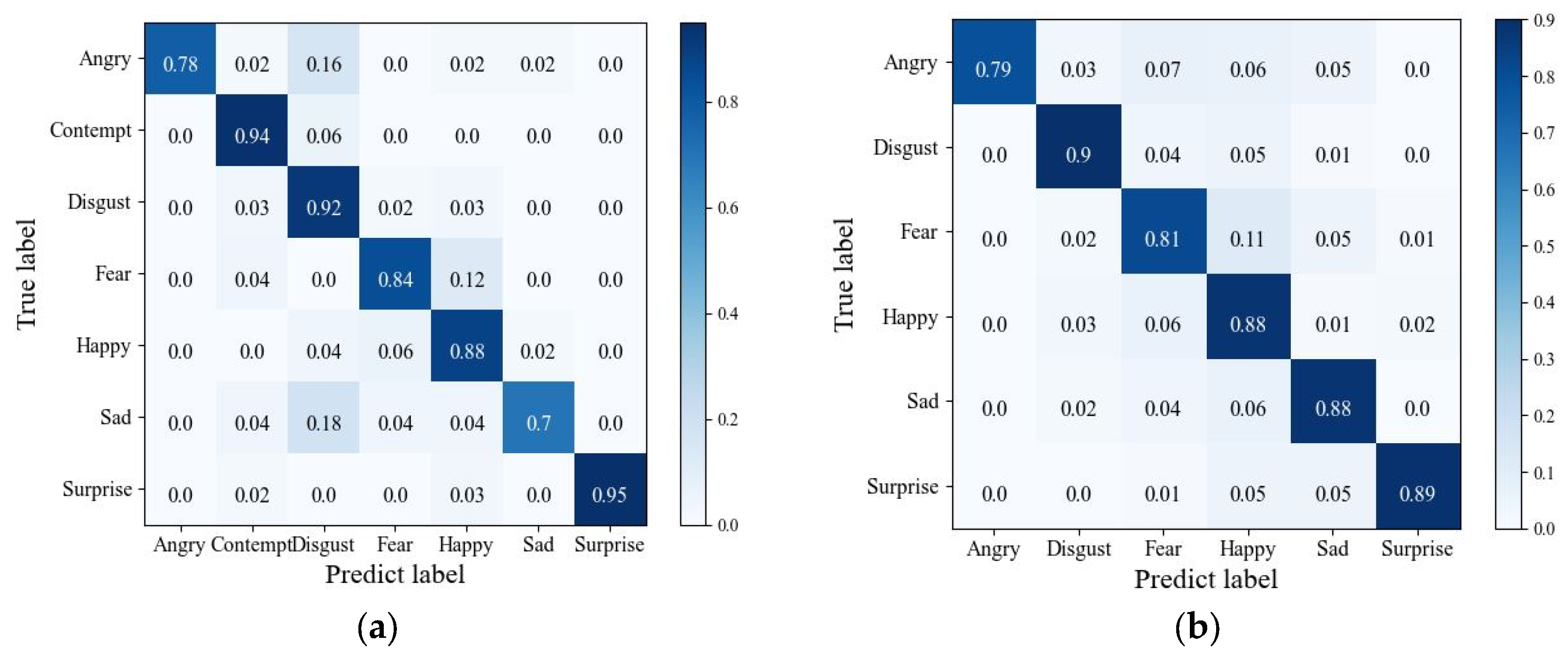
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Xie, L.; Tao, D.; Wei, H. Multi-View Exclusive Unsupervised Dimension Reduction for Video-Based Facial Expression Recognition. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Lu, C.; Zheng, W.; Li, C.; Tang, C.; Liu, S.; Yan, S.; Zong, Y. Multiple Spatio-temporal Feature Learning for Video-based Emotion Recognition in the Wild. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, New York, NY, USA, 16–20 October 2018. [Google Scholar]
- Liu, Y.J.; Zhang, J.K.; Yan, W. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Suk, M.; Prabhakaran, B. Real-time mobile facial expression recognition system-a case study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Liu, M.; Li, S.; Shan, S. Deeply learning deformable facial action parts model for dynamic expression analysis. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014. [Google Scholar]
- Qu, J.; Zhang, R.; Zhang, Z.; Pan, J.S. Facial Expression Recognition Based on Deep Residual Network. J. Internet Technol. 2020, 31, 12–19. [Google Scholar]
- Wan, J.; Xiaoyan, Z.; Huanan, X.; Dapeng, L.; Haoran, A. Micro expression recognition based on lbp and dual spatiotemporal neural network. Inf. Control. 2020, 49, 673–679. [Google Scholar]
- Khorrami, P.; Le Paine, T.; Brady, K.; Dagli, C.; Huang, T.S. How deep neural networks can improve emotion recognition on video data. In Proceedings of the 2016 IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Huanxin, C.; Xue, W.; Li, C.; Shengyi, S. Design of facial expression recognition model based on CNN and LSTM. Electron. Meas. Technol. 2021, 44, 160. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, X.; Zhou, J.; Chen, F.; Li, S.; Wang, H.; Jia, Y.; Shan, Y. A Lightweight Dual-Stream Network with an Adaptive Strategy for Efficient Micro-Expression Recognition. Sensors 2025, 25, 2866. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T. The extended cohnkanade dataset(Ck+): A complete dataset for action unit and emotion- specified expression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zhao, G.; Huang, X.; Taini, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Mou, X.; Song, Y.; Wang, R.; Tang, Y.; Xin, Y. Lightweight Facial Expression Recognition Based on Class-Rebalancing Fusion Cumulative Learning. Appl. Sci. 2023, 13, 9029. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, J.; Zhao, Z. Interpretion network knowledge with attention mechanism for bearing fault diagnosis. Appl. Soft Comput. 2020, 97, 106829. [Google Scholar] [CrossRef]
- Hu, J.; Li, S.; Gang, S. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F. ECA-net: Efficient channel attention for deep convolutional neural net-works. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P. Supplementary material for ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Han, K.; Wang, Y.H.; Tian, Q. GhostNet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 14–19 June 2020. [Google Scholar]
- Luo, D.W.; Fang, J.J.; Liu, Y.X. Feature fusion methods based on channel domain attention mechanism. J. Northeast Norm. Univ. 2021, 53, 44–48. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Liu, M.; Shan, S.; Wang, R.; Chen, X. Learning expression lets on spatio-temporal manifold for dynamic facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 24–27 June 2014. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Centro Parroquial, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-piloted deep network for facial expression recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Sikka, K.; Sharma, G.; Bartlett, M. Lomo: Latent ordinal model for facial analysis in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Afshar, S.; Salah, A.A. Facial expression recognition in the wild using improved dense trajectories and fsher vector encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ding, H.; Zhou, S.K.; Chellappa, R. Facenet2expnet: Regularizing a deep face recognition net for expression recognition. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef]
- Ofodile, I.; Kulkarni, K.; Corneanu, C.A.; Escalera, S.; Baro, X.; Hyniewska, S.J.; Allik, J.; Anbarjafari, G. Automatic recognition of deceptive facial expressions of emotion. In Proceedings of the IEEE Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Yu, Z.; Liu, Q.; Liu, G. Deeper cascaded peak-piloted network for weak expression recognition. Vis. Comput. 2018, 34, 1691–1699. [Google Scholar] [CrossRef]
- Liang, D.; Liang, H.; Yu, Z. Deep convolutional BiLSTM fusion network for facial expression recognition. Vis. Comput. 2020, 36, 499–508. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, B.; Tian, G. Facial expression recognition based on deep convolution long short-term memory networks of double-channel weighted mixture. Pattern Recognit. Lett. 2020, 131, 128–134. [Google Scholar] [CrossRef]
- Gera, D.; Balasubramanian, S. Landmark guidance independent spatio-channel attention and complementary context information based facial expression recognition. Pattern Recognit. Lett. 2021, 145, 58–66. [Google Scholar] [CrossRef]
- Klaser, A.; Marszalek, M.; Schmid, C. A spatio-temporal descriptor based on 3D-gradients. In Proceedings of the British Machine Vision Conference, Leeds, UK, 1–4 September 2008. [Google Scholar]
- Taini, M.; Zhao, G.; Li, S.Z.; Pietikainen, M. Facial expression recognition from near-infrared video sequences. In Proceedings of the International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012. [Google Scholar]
- Guo, Y.; Zhao, G.; Pietikainen, M. Dynamic facial expression recognition using longitudinal facial expression atlases. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- An, F.; Liu, Z. Facial expression recognition algorithm based on parameter adaptive initialization of CNN and LSTM. Vis. Comput. 2020, 36, 483–498. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Chen, Z. Occlusion-Robust Facial Expression Recognition Using Attention-Based Feature Completion. Affect. Comput. 2023, 14, 1123–1135. [Google Scholar]
- Wang, H.; Zhang, Q. Cross-Domain Few-Shot Learning for Facial Expression Recognition. Pattern Recognit. 2022, 128, 108976. [Google Scholar]
- Chen, J.; Liu, W.; Zhang, L. Temporal-Spatial Graph Convolution for Micro-Expression Recognition. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29–30 October 2023. [Google Scholar]
- Liu, Y.; Zhang, X.; Li, M. Label-Efficient Expression Recognition via Vision-Language Pretraining. IEEE Trans. Image Process. 2022, 31, 6543–6556. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset/Number of Sequences | Anger | Contempt | Disgust | Fear | Happiness | Sadness | Surprise | Sum | |
|---|---|---|---|---|---|---|---|---|---|
| CK+ | Original Sequence | 45 | 18 | 59 | 25 | 69 | 28 | 83 | 327 |
| Data Augmentation | 630 | 252 | 826 | 350 | 966 | 392 | 1162 | 4578 | |
| Random Masking | 630 | 252 | 826 | 350 | 966 | 392 | 1162 | 4578 | |
| Oulu-CASIA | Original Sequence | 80 | - | 80 | 80 | 80 | 80 | 80 | 480 |
| Data Augmentation | 1120 | - | 1120 | 1120 | 1120 | 1120 | 1120 | 6720 | |
| Random Masking | 1120 | - | 1120 | 1120 | 1120 | 1120 | 1120 | 6720 | |
| Model | CK+ | Oulu-CASIA | ||
|---|---|---|---|---|
| Accuracy (%) | Time (s) | Accuracy (%) | Time (s) | |
| ResNet50-1RBG | 97.30 | 574.2 | 87.90 | 775.3 |
| ResNet50-2RBG | 98.10 | 641.5 | 88.64 | 848.8 |
| ResNet50-3RBG | 98.34 | 881.8 | 88.69 | 953.7 |
| Model | CK+ | Oulu-CASIA | ||
|---|---|---|---|---|
| Accuracy (%) | Accuracy (%) | |||
| Baseline | 96.90 | 0.576 | 86.32 | 0.639 |
| Baseline + RM | 97.28 | 0.539 | 86.61 | 0.616 |
| Baseline + RM + Bi-GRU | 97.36 | 0.564 | 86.87 | 0.629 |
| Baseline + RM + RBG | 97.39 | 0.713 | 86.91 | 0.681 |
| Baseline + RM + RBG + ECA | 97.77 | 0.734 | 87.76 | 0.693 |
| Baseline + RM + RBG + G-ECA (ours) | 98.10 | 0.744 | 88.64 | 0.704 |
| Model | CK+ (%) | Improvement | Oulu-CASIA (%) | Improvement |
|---|---|---|---|---|
| STM-ExpLet [34] | 94.20 | +3.90 | 74.59 | +14.05 |
| HCNN-LSTM [10] | 84.87 | +13.23 | - | - |
| DTAGN [35] | 97.30 | +8.00 | 81.46 | +7.18 |
| PPDN [36] | 99.30 | −1.20 | 84.59 | +4.05 |
| LOMo [37] | 95.10 | +3.00 | 82.10 | +6.54 |
| IDT+FV [38] | 95.80 | +2.30 | - | - |
| FN2EN [39] | 96.80 | +1.30 | 87.70 | +0.94 |
| PHRNN-MSCNN [40] | 98.50 | −0.40 | 86.25 | +2.39 |
| ARDfee [41] | 98.70 | −0.60 | - | - |
| DeRL [2] | 97.30 | +0.80 | 88.00 | +0.64 |
| Inception-w [42] | 97.80 | +0.30 | 85.41 | +3.23 |
| ESTLNet [43] | 99.04 | −0.94 | 89.38 | −0.74 |
| WMCNN-LSTM [44] | 97.50 | +0.60 | 88.00 | +0.64 |
| SCAN [45] | 97.31 | +0.79 | 86.56 | +2.08 |
| DCNN [46] | 98.46 | −0.36 | 88.54 | +0.10 |
| STANER [47] | 98.23 | −0.13 | 89.52 | −0.88 |
| Atlases [48] | - | - | 75.52 | +13.12 |
| MMN [49] | - | - | 88.30 | +0.34 |
| ORAC-Net [50] | 98.20 | −0.10 | 89.70 | −1.06 |
| MELADA [51] | 96.80 | +1.30 | 82.40 | +6.24 |
| TSGCN [52] | - | - | 91.30 | −2.66 |
| CLIP [53] | 94.20 | +3.90 | 86.90 | +1.74 |
| Res-RBG (ours) | 98.10 | 88.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, X.; Song, Y.; Xie, X.; You, M.; Wang, R. Res-RBG Facial Expression Recognition in Image Sequences Based on Dual Neural Networks. Sensors 2025, 25, 3829. https://doi.org/10.3390/s25123829
Mou X, Song Y, Xie X, You M, Wang R. Res-RBG Facial Expression Recognition in Image Sequences Based on Dual Neural Networks. Sensors. 2025; 25(12):3829. https://doi.org/10.3390/s25123829
Chicago/Turabian StyleMou, Xiangwei, Yongfu Song, Xiuping Xie, Mingxuan You, and Rijun Wang. 2025. "Res-RBG Facial Expression Recognition in Image Sequences Based on Dual Neural Networks" Sensors 25, no. 12: 3829. https://doi.org/10.3390/s25123829
APA StyleMou, X., Song, Y., Xie, X., You, M., & Wang, R. (2025). Res-RBG Facial Expression Recognition in Image Sequences Based on Dual Neural Networks. Sensors, 25(12), 3829. https://doi.org/10.3390/s25123829