1. Introduction
Cross-view geo-localization refers to the process of matching a given image (typically a ground-level or drone-captured image) with a geo-tagged reference satellite image. This process can be viewed as a retrieval task, where the goal is to identify and locate the satellite image most relevant to the given image. This technology has a wide range of applications in several fields, including target detection, environmental monitoring and management, precision agriculture, military reconnaissance, intelligence gathering, target tracking, and even the monitoring of archaeological sites and cultural heritage sites [
1,
2,
3,
4]. Cross-view geo-localization, when combined with an inertial measurement unit (IMU), also holds significant application potential, while ground-view geo-localization provides precise positioning for autonomous vehicles, and drone-view geo-localization enhances the attitude control (i.e., pitch, yaw, and roll stabilization), navigation accuracy, and autonomous flight capabilities of drones [
5], especially promising for high-precision localization and path planning in environments with weak or absent GPS signals [
6].
Due to great spatial and temporal differences, e.g., varying angles and fields of view, between satellite and ground-view images, the matching task is very challenging in dealing with significant disparities in scale, perspective, and background [
7,
8]. On the other side, with the continuous development of drone technology, drones have become more convenient and cost-effective for image acquisition in recent years. Compared with traditional ground-based imagery, the angular difference between the drone view and satellite view is smaller, and there are fewer obstacles, such as trees and surrounding environments, in the images captured by drones. These advantages make drone-view images more suitable for cross-view matching tasks [
9,
10].
With the rapid development of deep learning, significant progress has been made in cross-view geo-localization technology [
11,
12]. However, in practical applications, drone-based cross-view geo-localization still faces numerous challenges, particularly due to factors such as viewpoint, illumination, resolution, and seasonal variations. Specifically, existing research has shown that extreme weather conditions, such as heavy rain and snow, will lead to a significant decline in cross-view geo-localization performance [
13].
To address the impact of extreme weather, traditional solutions typically focused on first denoising the images affected by weather noise before performing cross-view geo-localization. Weather noise removal methods can be categorized into single-weather and multi-weather denoising approaches. Single-weather denoising methods, such as those proposed by Ren et al. [
14] and Jiang et al. [
15], primarily focused on removing specific weather noise (e.g., snow and raindrops). The DID-MDN network proposed by Zhang and Patel [
16] and the dual attention mechanism introduced by Quan et al. [
17] also successfully removed raindrop noise. However, these methods are typically limited to specific weather noise and struggle to effectively handle varying weather conditions, particularly in complex weather environments where their performance is constrained.
For multi-weather noise removal, CRNet [
18] and DSANet [
19] effectively removed various types of weather noise, such as fog, snow, and rain, through multi-branch modules and domain attention mechanisms. The adversarial learning approach proposed by Li et al. [
20] can handle multiple severe weather conditions, while Chen et al. [
21] improved denoising efficiency through a two-stage knowledge-learning process. Despite these advancements in noise removal, these methods often result in the loss of key image features, as shown in
Figure 1, which affects the accuracy of cross-view geo-localization [
22]. The multi-environment adaptive network proposed by Wang et al. [
23] adjusted domain transfer adaptively based on environmental style information, achieving good experimental results, particularly excelling across multiple datasets. However, this method still has significant limitations when dealing with extreme weather conditions in real-world scenarios and has not fully addressed the problems in practical applications.
In summary, existing image denoising and cross-view geo-localization methods have made significant progress, particularly in handling images under multi-weather conditions. They still face great challenges, especially in handling images with severe weather noise; the optimization and enhancement of deep learning frameworks remains an imperative and unsolved problem.
To address the challenges, this paper proposes a twin network model, AGEN, which fully leverages the advantages of DINOv2 [
24], especially its strong global feature extraction capabilities. However, DINOv2 exhibits certain limitations in capturing fine-grained features. To overcome this, the Local Pattern Network (LPN) [
25] is creatively integrated, effectively compensating for DINOv2’s shortcomings in fine-grained feature extraction. Additionally, we innovatively propose the fuzzy PID control-based Adaptive Error Control (AEC) module. The AEC module dynamically adjusts loss weights by incorporating historical error information and its temporal evolution, aiming to mitigate training instability caused by extreme weather conditions. By enabling stage-aware optimization throughout the training process, the AEC module enhances the model’s robustness and convergence under severe environmental variations. Furthermore, we employ a data enhancement algorithm for better model training, which applies nine different weather conditions to the drone images in the University-1652 dataset [
26]. Our main contributions are summarized as follows.
We propose a twin network AGEN with shared weights for cross-view geo-localization under extreme weather conditions, which effectively employs DINOv2 as the backbone network and integrates LPN for more comprehensive feature information extraction and matching.
The innovative fuzzy control-based AEC module is proposed to dynamically adjust the loss weights and optimize the learning process of the model according to the historical errors and their trends so that the model can adaptively learn the knowledge at different training stages. To further guarantee the robustness of AGEN under various weather conditions, we also extend the original dataset by 9 times for model training.
To validate the effectiveness of AGEN, we conduct extensive experiments. On the University-1652 dataset, AGEN achieves an impressive Recall@1 accuracy of 95.43% on the drone-view target localization task and 96.72% accuracy on the drone navigation task, outperforming other state-of-the-art models. Under extreme weather conditions on the University160k-WX dataset, the AGEN model delivers remarkable results with a Recall@1 of 91.62%, and it also performs well on the SUES-200 dataset. These results highlight the model’s robustness and effectiveness in handling complex environmental conditions.
The organization of this paper is as follows:
Section 2 reviews the latest advancements in cross-view geo-localization, explores the application of modern backbone networks in scene matching, and summarizes key trends in the development of loss functions.
Section 3 provides a detailed introduction to our proposed framework, including dataset extension, the integration of DINOv2, the role of the LPN module in fine-grained feature extraction, and the implementation of the AEC module for loss optimization.
Section 4 presents an in-depth analysis of our experiments, covering dataset characteristics, implementation strategies, comparisons with state-of-the-art methods, and ablation studies.
Section 5 discusses the limitations of the proposed approach and outlines potential directions for future improvement. Finally,
Section 6 summarizes the research findings and outlines directions for future work.
3. Methods
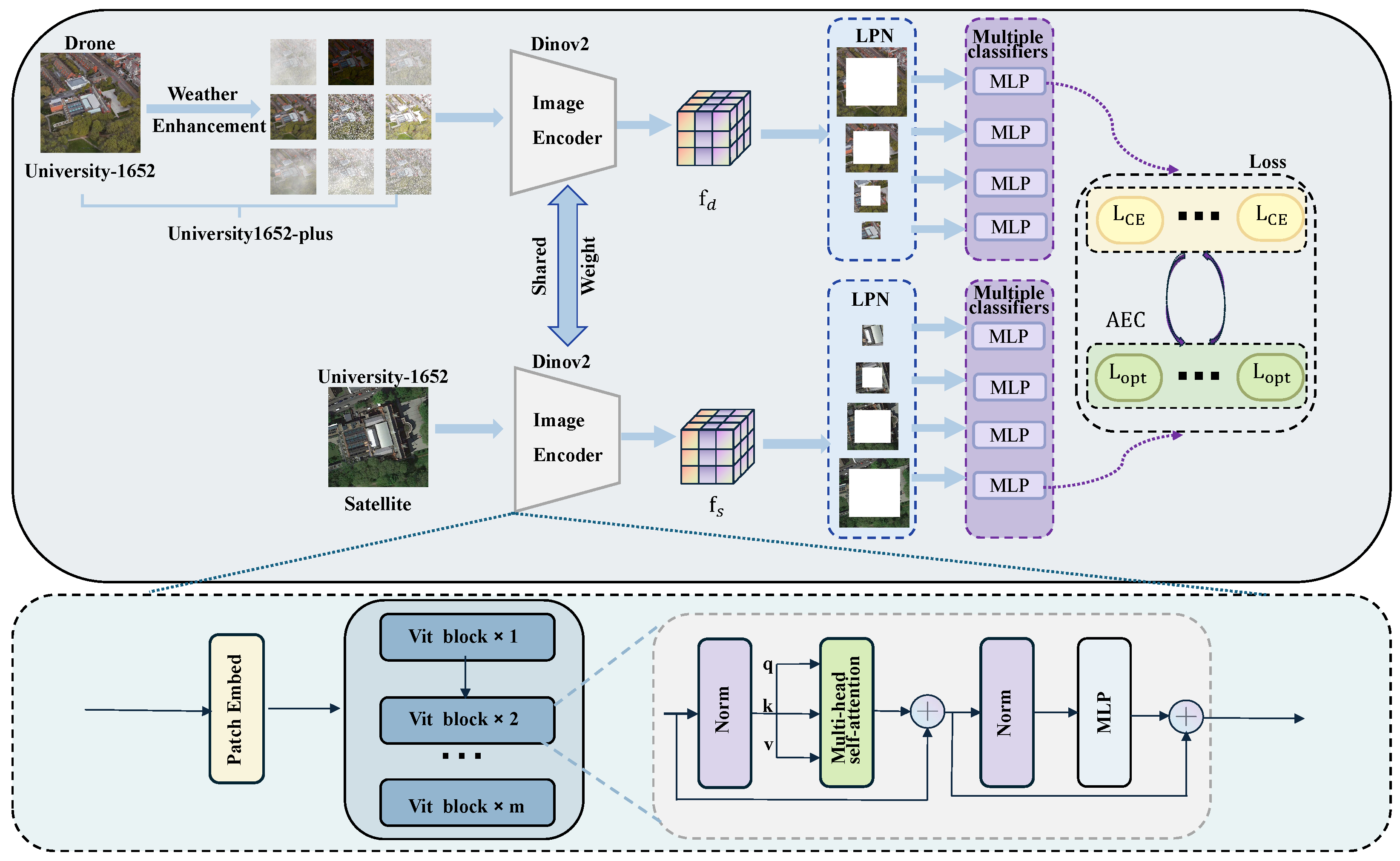
3.1. Overall Architecture
The overall framework of our solution is depicted in
Figure 2. First, we propose a dataset expansion and augmentation method to address the challenges of cross-view matching under extreme weather conditions. Second, we innovatively adopt DINOv2 as the backbone network for feature extraction and feed its deep-level features into the Local-Pattern Network (LPN) and multi-branch classification heads to capture more fine-grained pattern features. Finally, we introduce a loss function optimization module based on fuzzy control, aiming to adaptively adjust the cross-entropy loss function.
3.2. Dataset Expansion
This section outlines the process and rationale for creating our augmented dataset, University1652-plus. In order to enhance the robustness of cross-view geo-localization models under adverse weather conditions, the University1652-plus dataset is developed by extensively expanding the original University-1652 dataset. Specifically, nine distinct weather conditions are selected to simulate various challenging environments for drone-view images, including dark, rain, fog, snow, fog and rain, fog and snow, sleet, light, and wind, as shown in
Figure 3. These selections aim to cover a wide range of weather scenarios that could affect drone images.
The original University-1652 training set contains 37,854 drone-view images, while the augmented dataset contains a total of 378,540 drone-view images. Furthermore, the satellite-view images are not augmented, as usually do not encounter the same weather-related distortions as drone-view images. Advanced image processing techniques are employed to simulate the selected weather conditions. For example, we simulate dark condition by adjusting brightness and contrast, overlay realistic raindrops and snowflakes using a particle system. University1652-plus ensures that each drone-view image in the training set is represented under ten different conditions, i.e., original and nine weather conditions, not only improving the model’s resilience to weather-related challenges but also better meeting the data requirements of the attention-based model.
3.3. Backbone Network: DINOv2
DINOv2 is a self-supervised learning method based on the Transformer architecture, designed to extract high-quality feature representations from images. The model employs a self-distillation strategy, where the student and teacher networks learn from each other, effectively capturing both global and local features from images without the use of labels. In this study, DINOv2 is used as the first-stage feature extractor. The input image
is first divided into non-overlapping patches, which are mapped to the initial feature space
(
1) through the Patch Embed layer.
These features are then processed through Vision Transformer (ViT) blocks, where self-attention mechanisms compute the relationships between the patches. The self-attention calculation is given by Equation (
2).
where
,
, and
are the query, key, and value matrices derived from the input feature
.
Within each ViT block, the features undergo non-linear transformations via an Multilayer Perceptron (MLP). This MLP consists of two fully connected layers, followed by the SwiGLU activation function. The mathematical representation of the MLP is as Equations (
3) and (
4).
where
and
are the weights and biases of the first layer, and
and
are the weights and biases of the second layer. The
activation function is defined as Equation (
5).
To enhance robustness and generalization, DINOv2 adopts the masking strategy from iBOT, where random patches of the input image are masked for the student network while the teacher network receives the complete image. This strategy allows the student network to learn from incomplete information and improves its ability to generalize. The feature diversity is further enhanced by the use of the Sinkhorn–Knopp algorithm [
57] to center the teacher network’s output.
Leveraging the powerful unsupervised learning capabilities of DINOv2, our AGEN can effectively capture deep image features and provide high-quality input for subsequent tasks.
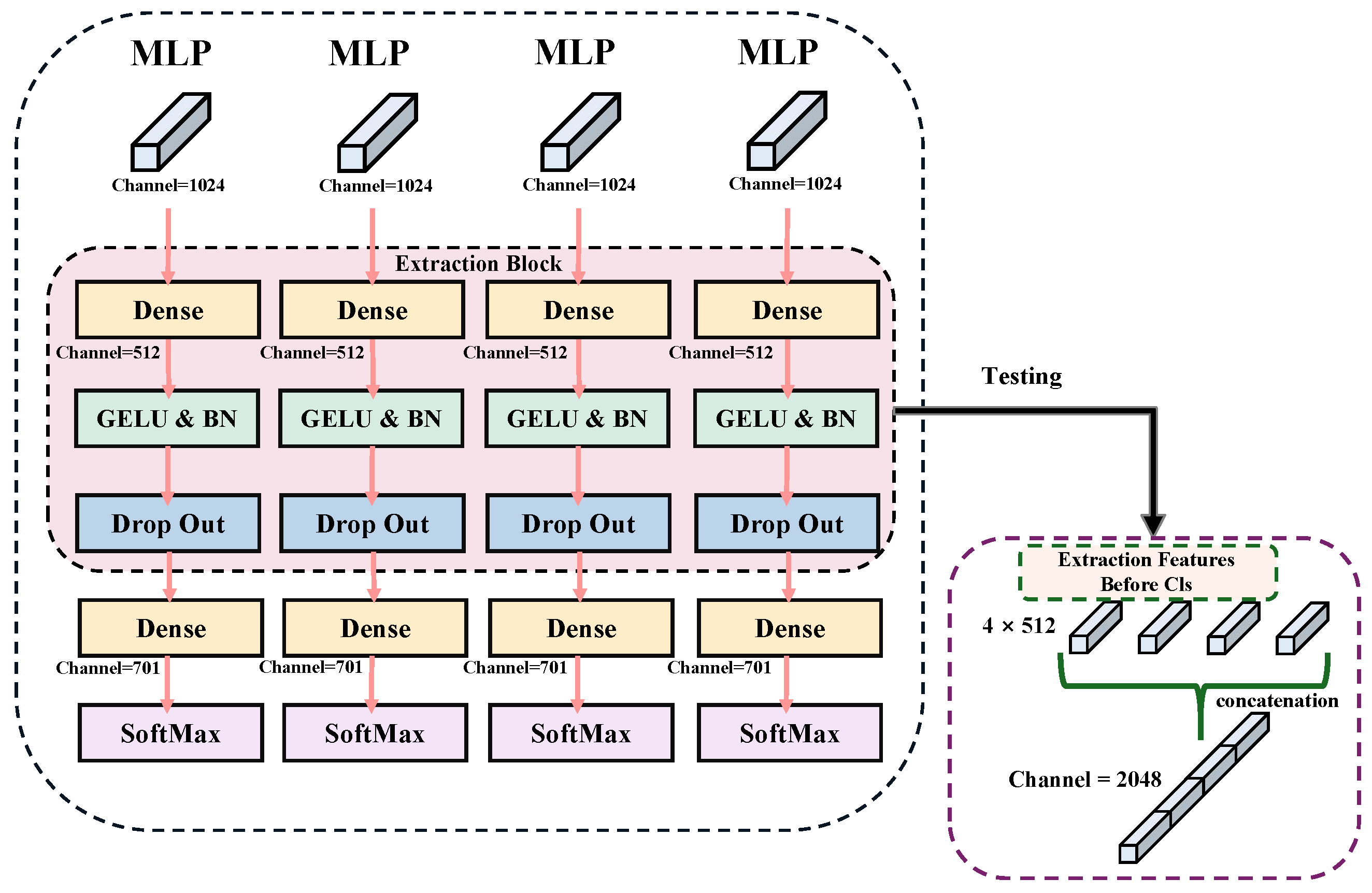
3.4. LPN and Multi-Branch Classification
The extracted features after the image encoder are further processed by LPN in the backbone network with a multi-branch classification structure to gather environmental information. The use of LPN allows the model to extract more local feature details. These high-precision, fine-grained features are crucial for accurately interpreting and classifying complex scenes. Specifically, LPN is applied in the last layer of the backbone network using a specific feature pooling method. We first divide the input feature map into chunks to ensure each chunk captures the local details of the image. Then, adaptive average pooling or maximum pooling is used to extract key information from each chunk. To avoid overlapping and redundancy, the pooling process is adjusted according to the size and location of the chunk. Formally, given an input feature map
, it is partitioned into
k non-overlapping regions
, and the pooled feature for each region is obtained as Equation (
6).
In order to preserve spatial detail and structural semantics, these local features are concatenated into a unified representation as Equation (
7).
Finally, all pooled feature chunks are stitched together to form a feature map with rich local details. The multi-branch classification header responsible for categorizing these fine-grained features consists of multiple branches, each corresponding to a part of the feature map. Each branch first performs a spreading operation on its corresponding feature block, which is followed by using a separate classifier. Mathematically, each branch applies an independent classifier
to its input
, producing a prediction as in Equation (
8).
During training, the classification loss from each branch is directly summed to form the final LPN loss as Equation (
9), allowing the model to fully leverage the contribution of each local feature region.
where
y is the ground-truth label. This allows each branch’s classifier to focus on specific local features, improving classification accuracy and fine-grained feature interpretation. During training, classification results from each branch are integrated to optimize overall model performance. During inference, classification results from each branch are stacked to provide detailed outputs, as illustrated in
Figure 4.
This structure fully leverages the advantages of the LPN and the multi-branch classification head, addressing the limitations of traditional feature extraction methods in capturing fine-grained features in complex scenes. As a result, the model is able to more accurately perform target localization and recognition under adverse conditions, enhancing classification accuracy and robustness.
3.5. Fuzzy PID Control Mechanism
The fuzzy proportional–integral–derivative (PID) controller integrates the strengths of classical PID control and fuzzy logic systems, making it particularly suitable for handling complex systems characterized by nonlinearity, time variance, and uncertainty. In contrast to traditional optimization strategies that depend on fixed hyperparameters, the fuzzy PID controller adaptively determines the proportional (P), integral (I), and derivative (D) gains by evaluating the current error, its temporal variation, and the accumulated error over time. This enables more robust and adaptive control behavior. In recent years, as deep learning models have become increasingly complex, the training process has exhibited strong non-linear and dynamic properties, such as slow gradient updates in early stages and oscillations in later stages. Conventional learning rate scheduling strategies (e.g., preset decay or cosine annealing) often fail to simultaneously ensure both fast convergence and stable training. To address these challenges, this study introduces a fuzzy PID control mechanism into the deep learning optimization process to enhance the model’s adaptive learning capacity.
The optimization strategy proposed in this study introduces a fuzzy PID controller to dynamically adjust the relative importance of each training epoch in the global loss computation. Specifically, let
denote the average loss of the
t-th epoch. The input error signal to the controller is defined as a weighted combination of recent epoch losses as Equation (
10).
The fuzzy PID controller computes a control signal based on this error, its cumulative history, and its temporal variation as Equation (
11).
The output control signal
(
12) is then normalized using a softmax function to yield the weight assigned to epoch
t:
where
m denotes the number of historical epochs considered in the weighting window. The global loss (
13) is reformulated as a weighted sum over multiple recent epochs:
This weighting strategy allows the controller to distinguish and emphasize training stages with slower convergence or larger errors. When an epoch exhibits higher average loss, its corresponding control signal increases, leading to a higher normalized weight . As a result, the training process is guided to focus more on suboptimal epochs that require greater learning attention.
From an optimization perspective, assuming a learning rate
, the parameter update rule can be approximated as Equation (
14).
Compared with uniform weighting (e.g.,
), the fuzzy PID-based weighting mechanism increases the influence of more error-prone epochs on the update direction. This yields a more effective descent in the expected loss gradient (
15).
Therefore, the proposed epoch-level weighting approach, guided by fuzzy PID control, enhances convergence speed in the early training phase by emphasizing high-error epochs while maintaining smooth and stable optimization behavior in later stages. This mechanism effectively restructures the optimization trajectory based on training dynamics, promoting more efficient and robust learning.
3.6. Loss Function Optimization
In extreme weather conditions such as heavy rain and dense fog, significant discrepancies between drone-view and satellite-view images introduce substantial nonlinearity, time variance, and uncertainty into the training process. As the dataset is expanded, the number of samples per epoch becomes limited relative to the overall dataset size, resulting in each epoch covering only a small fraction of the entire data distribution. Consequently, it becomes challenging for a single epoch to fully capture the variations across geographic regions, meteorological conditions, and perspective differences. This problem is particularly pronounced under extreme weather scenarios, substantially impairing convergence speed and training stability.
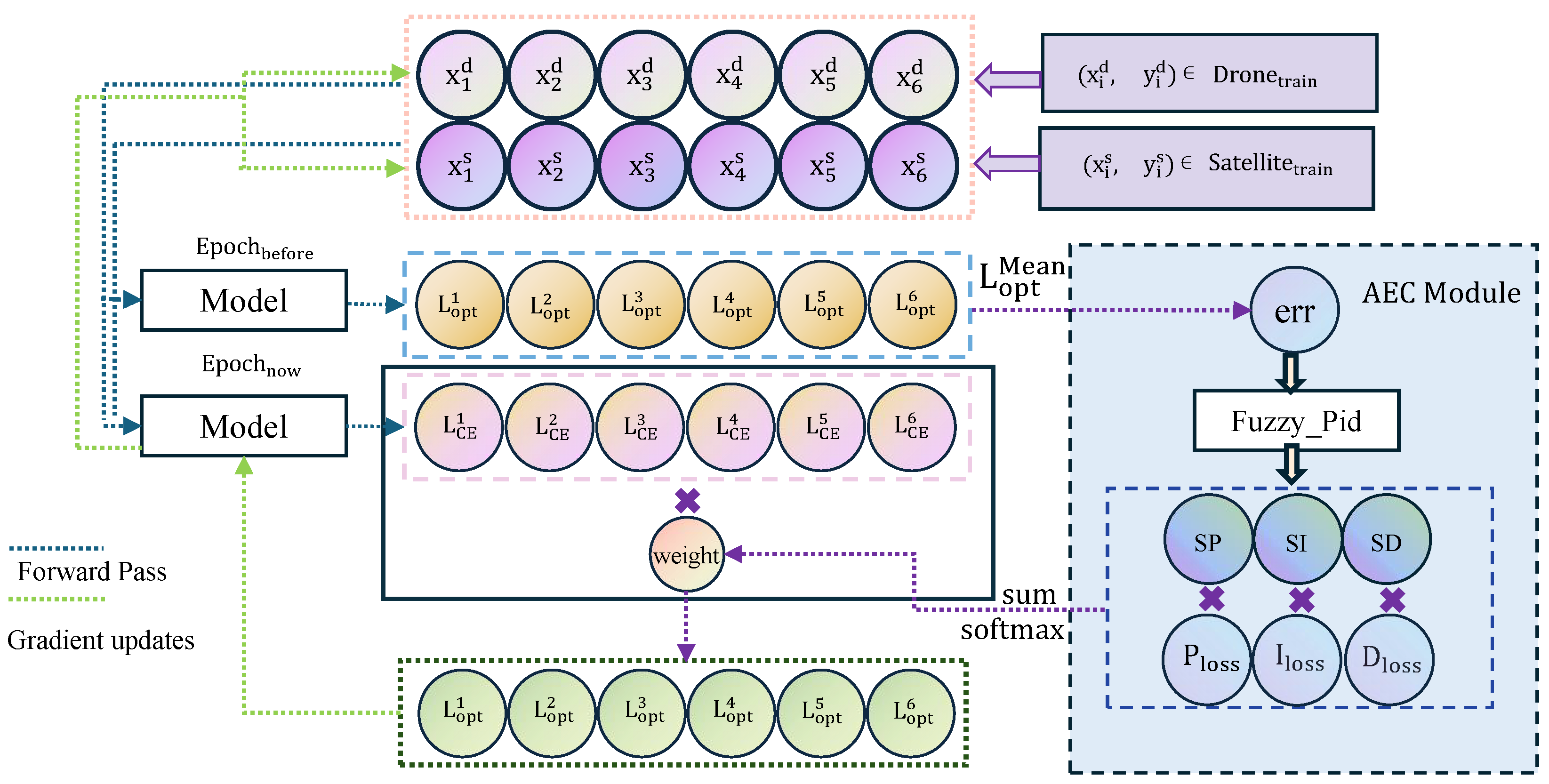
To address these challenges, an Adaptive Error Control (AEC) module is introduced to improve the effectiveness of the conventional cross-entropy loss function during training. By incorporating a fuzzy PID control mechanism, the AEC module adaptively adjusts loss weights through proportional (P), integral (I), and derivative (D) control strategies. The P control enables real-time adjustment according to the current error, enhancing sensitivity to abrupt variations. The I control accumulates historical error information to correct long-term biases, while the D control captures the trend of error evolution to suppress fluctuations caused by environmental perturbations. By jointly considering multiple epochs, the AEC mechanism effectively expands the model’s temporal perception, allowing it to better integrate historical information and improve robustness under extreme conditions.
The overall training process, as illustrated in
Figure 5, demonstrates how historical information and the Adaptive Error Control (AEC) mechanism optimize parameters using six data samples. The dataset consists of drone-view and satellite-view image samples, denoted as
and
, respectively, to address multi-view image-matching tasks. After each sample undergoes forward propagation, the cross-entropy loss function
is used to calculate the error between the model’s predictions and the ground truth labels, defined as Equation (
16).
where
denotes the ground-truth label and
denotes the predicted probability.
To enhance adaptability during training, control parameters , , and are dynamically generated based on fuzzy logic reasoning. These parameters adjust the loss weights in subsequent iterations according to the magnitude and dynamics of the current loss. Samples with higher losses are assigned greater weights, directing the optimization to focus on more difficult learning instances.
The AEC module dynamically computes the control signal
u via the fuzzy PID controller, as formulated in Equation (
17):
where
,
, and
correspond to the proportional, integral, and derivative components, respectively. These components reflect the dynamic adjustment of the control signal according to both the current and historical training states. Their values are not statically assigned but are dynamically adjusted during training through a fuzzy logic controller. This adaptive mechanism aims to minimize the discrepancy between predictions and ground-truth labels by responding to variations in the loss trend, thereby enhancing the model’s ability to adapt to changes in training dynamics. Moreover, the integral term
aggregates recent epoch losses to capture long-term trends and correct potential bias, as formulated in Equation (
18).
where
are decay coefficients (with
), and
represents the number of past epochs considered. This accumulation enhances robustness to transient fluctuations by preserving temporal context. The derivative term
is computed as the difference between the most recent two epoch losses in Equation (
19).
This term evaluates the velocity of loss change and contributes to damping oscillations, thereby stabilizing the optimization trajectory under extreme weather disturbances.
The current error is dynamically computed based on the losses of recent epochs, following the conditions outlined below:
When , only the previous epoch’s loss is available: .
When , the error is a weighted combination of the previous two epochs: .
When , the error incorporates the last three epochs: with .
This formulation ensures a balanced incorporation of historical information, enabling the model to maintain sensitivity to both short-term and long-term variations during training.
The
for each sample are obtained by applying a softmax normalization to the control signal
u, as shown in Equation (
21):
The optimized per-sample loss
is then computed by weighting the cross-entropy loss for each sample as shown in Equation (
22):
where
n denotes the batch size,
is the original cross-entropy loss, and
is the corresponding adaptive weight for sample
i. The weighted losses are then used for gradient updates on a per-sample basis, ensuring that more challenging samples receive greater attention during optimization.
By integrating historical losses across multiple epochs and dynamically adjusting the optimization trajectory, the proposed AEC module significantly improves convergence efficiency, enhances model stability, and strengthens generalization under extreme weather and complex viewpoint variations.
4. Experiments
4.1. Datasets Description
University-1652 [
26] includes 1652 locations across 72 universities worldwide, offering a diverse range of urban and campus environments. This multi-view, multi-source methodology allows for a robust examination of geo-localization from diverse perspectives, presenting unique challenges. To support this framework, satellite-view images are acquired by projecting geographic coordinates from Wikipedia metadata of university buildings onto Google Maps, with one high-resolution image per building serving as a static reference. Drone-view images are generated via simulated flights around 3D building models from Google Earth, where a virtual drone follows a three-orbit spiral trajectory descending from 256 m to 121.5 m. Video is recorded at 30 fps, and one frame is extracted every 15 frames, yielding 54 images per building that capture diverse viewpoints and realistic scales. This approach captures diverse viewpoints and scales, thereby providing high-quality and realistic samples for cross-view matching tasks.
University160k-WX [
13] dataset is presented by the ACM MM2024 Workshop on UAVs in Multimedia, aiming to simulate real-world geo-localization scenarios by introducing multi-weather cross-view variants. University160k-WX extends the University-1652 dataset by adding 167,486 satellite-view gallery distractors and includes weather variations such as fog, rain, snow, and multiple weather compositions, as shown in
Figure A1. This significantly increases the complexity and challenge for representation learning.
University1652-Plus, an extensive expansion of the University-1652 dataset, introduces nine extreme weather conditions (darkness, rain, fog, snow, fog and rain, fog and snow, sleet, light, and wind) to enhance model robustness for cross-view geo-localization. This augmented dataset expands the original 37,854 drone-view images to 378,540 images, simulating challenging environments. We generate fog by combining Gaussian blur and particle effects and overlay rain and snow effects when applicable. Simulate different light intensities and direction changes, and apply motion blur to simulate wind effects.
SUES-200 [
27] is a cross-view image-matching dataset that contains 24,120 images captured by UAVs at four different altitudes and corresponding satellite views of the same target scene. All images are acquired in realistic environments with multiple types of scenes, including real-world lighting, shadow transformations, and interference. In order to address the shortcomings of existing public datasets, SUES-200 also takes into account the differences that occur when UAVs shoot at different altitudes. More over, the SUES-200 dataset contains 200 distinct locations, each associated with one satellite-view image and 50 drone-view images. Satellite-view images are sourced from AutoNavi Map and Bing Maps, with a single high-resolution image
assigned per location. Drone-view images are captured along a predefined curved trajectory with varying altitudes to ensure multi-angle coverage. Each flight video yields 50 uniformly sampled frames, and the original resolution of
is preserved to retain visual detail and minimize information loss. The details of the datasets used in this paper are provided in
Table 1,
Table 2 and
Table 3, where “Locations” denotes the number of distinct geographic spots within the dataset.
4.2. Implementation Details
In this investigation, the network initialization is based on DINOv2’s large version, with weights pre-trained on the ImageNet dataset, serving as a cornerstone for the transfer learning paradigm. Each input image is first resized to pixels using bicubic interpolation to ensure consistency in spatial resolution. To enhance generalization under diverse imaging conditions, the pipeline applies 10-pixel edge padding to suppress boundary artifacts, performs random cropping to introduce spatial variation, and uses horizontal flipping to increase viewpoint robustness. For satellite-view images, random affine transformations with up to ±90∘ rotation simulate sensor-induced misalignment and orbital drift. Image normalization with ImageNet statistics stabilizes training dynamics. The network is developed using the PyTorch framework (version 2.5.0, CUDA 11.8) and optimized with the Rectified Adam (RAdam) optimizer. This optimizer uses a weight decay parameter set to . The initial learning rate is set to for the backbone layer and for the classification layer. Computational experiments are conducted on an NVIDIA A40 GPU with 48 GB of memory.
4.3. Comparison with Other Data Augmentation Methods
The original University-1652 training set contained 37,854 drone viewpoint images. A total of 378,540 drone view images were generated from this data expansion. The satellite view images were not augmented because they are not subject to the same weather-related effects as the drone view images. To simulate these selected weather conditions, advanced image processing techniques are used in this paper. Three major image processing libraries, the imgaug, OpenCV, and Pillow, are used to compare the matching results.
In this paper, a series of enhancement operations using imgaug library are defined to simulate dark environments by adjusting brightness and contrast, superimposing real raindrops and snowflakes using a particle system, generating fog by combining Gaussian blur and particle effects, and superimposing rain and snow effects when appropriate. In addition, different light intensities and direction changes are simulated, and wind effects are simulated by motion blur to enhance the realism of the image.
OpenCV is mainly used to implement a variety of weather effects. In this paper, a black rain layer of the same size as the original image is created to simulate rainfall by randomly generating a certain number of white lines. An all-white fog layer is created and combined with the original image using a weighted average method; the blending ratio is adjusted to simulate different intensities of mist and haze; white circles are drawn randomly on an empty white snow layer to form snowflakes and combined with the original image for superimposition; bright light and darkness are simulated by adjusting the brightness and contrast of the image; and affine transforms are combined with image translation to simulate the effect of wind.
The Pillow library (version 10.2.0), on the other hand, provides easy-to-use image processing functions. Rain and snow are simulated by drawing white lines and circles at random locations. For fog simulation, Pillow generates a mist effect by weighted blending an all-white layer with the original image. The contents of the original image are duplicated, and then Gaussian blur is used to generate the visual effect of wind. In addition, Pillow is used for simple brightness and contrast adjustments to further enhance the image’s diversity.
The effectiveness of data augmentation methods was evaluated based on the Recall@1, Recall@5, and Recall@10 accuracy scores. As shown in
Table 4, the imgaug library achieved Recall@1, Recall@5, and Recall@10 scores of 85.58%, 92.83%, and 94.02%. In comparison, using OpenCV and Pillow resulted in lower scores. Specifically, imgaug improved Recall@1 by 10.52% and 4.83%, Recall@5 by 8.30% and 4.28%, and Recall@10 by 7.24% and 3.10% over OpenCV and Pillow, respectively. These results indicate that the weather augmentation method using imgaug significantly enhances model performance. Therefore, we choose the imgaug library as the preferred library due to its powerful customization capabilities and rich enhancement features. This may provide useful guidance for future deep-learning applications under complex weather conditions.
To validate the effectiveness of the data augmentation method, we conducted experiments using the Swin Transformer model [
38]. First, we applied a multi-weather denoising method [
19] to process the weather-noisy images in the University160K-WX training set, and then we trained the model on the denoised training set before testing. In contrast, the second experiment involved training directly on the original training set, which contains weather noise, in order to adapt the model to extreme weather conditions. The experimental results, as shown in
Table 5, indicate that when training directly on the weather-noisy training set, the model’s performance on the test set achieved Recall@1 of 62.71%, Recall@5 of 74.07%, and Recall@10 of 77.24%. On the other hand, when training on the denoised training set, the model achieved Recall@1 of 53.48%, Recall@5 of 64.68%, and Recall@10 of 68.14%. These results further confirm that while image denoising can effectively remove weather noise, it may also lead to the loss of certain image information, which impacts the matching performance.
4.4. Comparison with Other Methods
In the context of our study, the drone view target localization task refers to the process of matching a target in a satellite view with the corresponding position in a drone view. On the other hand, drone navigation applications involve the reciprocal task of matching the drone view with the corresponding location in the satellite view.
As shown in
Table 6, the comparative efficacy of the proposed AGEN network is first evaluated using the University-1652 dataset. Notably, when applied to the task of drone-view target localization, the AGEN model achieves a Recall@1 accuracy of 95.43% and an AP of 96.18%. Furthermore, for the drone navigation application task, the network achieves a Recall@1 accuracy of 96.72% and an AP of 95.52%. The performance has surpassed the state-of-the-art methods, e.g., WELN and SRLN. Specifically, WELN achieved a Recall@1 accuracy of 92.87% and an AP of 94.00% for drone-view target localization task and 93.46% Recall@1 with an AP of 93.25% for the drone navigation application task. Similarly, SRLN reached a Recall@1 accuracy of 92.70% and an AP of 93.77% for the drone-view target localization task, while in the drone navigation application task, it achieved 95.14% Recall@1 and an AP of 91.97%. Overall, these results demonstrate an improvement in performance, highlighting the effectiveness of our network.
We further perform a systematic comparison of AGEN with existing algorithms under the SUES-200 dataset. The result is illustrated in
Table 7. For the drone viewpoint target localization task, the AGEN network shows a significant improvement in Recall@1 accuracy, which is 94.38% at 150 m above sea level and reaches a maximum point of 97.12% at 300 m above sea level. At the same time, the AP score gradually increases from 95.58% to 97.81%. Compared with the state-of-the-art model CCR [
64], the accuracy of Recall@1 increased by 7.30% and the AP score by 6.03% at 150 m above sea level, while at 300 m above sea level, the accuracy of Recall@1 increased by 0.30% and the AP score increased by 0.42%. Similarly, in the drone navigation task example, the AGEN network achieves Recall@1 accuracy of 97.50% at 150 m and 96.52% at 300 m above sea level. Meanwhile, the AP score increased from 92.58% to 95.36%. These statistics not only outperform the Safe-Net [
63] model, which has AP scores between 86.36% and 95.67%, but also emphasize the excellent uniform performance of the AGEN network at all flight altitudes. The insights gained from these data demonstrate the leading position of the AGEN model in terms of accuracy and stability, thus significantly advancing the field of geographic information.
To validate the effectiveness of the proposed Adaptive Error Control (AEC) module, we conduct comprehensive comparative experiments on the University-1652 dataset. Three representative backbone networks are selected for evaluation, including the conventional convolutional architectures VGG16 and ResNet34/50, as well as the Vision Transformer (ViT), pre-trained with enhanced regularization. As shown in
Table 8, the integration of the AEC module consistently improves the performance across all models in both the drone viewpoint target localization task and the drone navigation task, as measured by Recall@1, Recall@5, Recall@10, and AP. In the table, a check mark (✓) indicates that the AEC module is applied. For instance, under the ViT architecture, AEC improves the Recall@1 from 83.72% to 85.68% and the AP from 86.08% to 87.76% in the drone viewpoint target localization task while yielding a 2.0% improvement in Recall@1 in the drone navigation task. Similarly, under the ResNet50 architecture, the Recall@1 increases from 65.62% to 68.87% and AP from 69.75% to 72.80% in the localization task; in the navigation task, Recall@1 improves from 77.46% to 82.17%, and AP from 65.15% to 69.77%. These results indicate that the AEC module promotes more effective learning of task-relevant knowledge, contributing to improved feature representations and overall matching performance.
Since University160k-WX only provides a mask-processed test set, our model uses University1652-Plus, an extension of the University-1652 training set, during the debugging phase. As shown in
Table 9, we submit our best Recall@1 results for the challenge using the University160k-WX test set, achieving a Recall@1 accuracy of 91.71%, Recall@5 accuracy of 96.36%, and Recall@10 accuracy of 97.03%. Compared with the WELN model, our approach improved Recall@1 by 6.04%, Recall@5 by 3.55%, and Recall@10 by 2.99%. In addition, compared with the EDTA model, which achieved 85.08% at Recall@1, 91.18% at Recall@5, and 92.72% at Recall@10, our method shows a substantial performance gain of 6.63%, 5.18%, and 4.31%, respectively. These results clearly demonstrate the superior generalization ability and robustness of our proposed method under diverse and challenging weather conditions.
4.5. Ablation Study
In our ablation study, as shown in
Table 10, we evaluate the impact of various components, including shared weights, LPN, training on University1652-Plus, and the AEC module, with performance results on both the University160k-WX and University-1652 datasets.
The baseline model is defined as the DINOv2-large version without shared weights, trained solely on the University-1652 dataset. This initial model achieves a Recall@1 of 30.67% on University160k-WX and 91.71% on University-1652, providing a reference point for measuring the effectiveness of added components. Adding shared weights significantly boosts performance, raising Recall@1 to 46.09% on University160k-WX and to 93.98% on University-1652, indicating the benefit of shared feature learning across views. Incorporating LPN further improves results, particularly on University160k-WX, where Recall@1 increases to 55.07%, highlighting LPN’s ability to capture fine-grained details in diverse conditions. Training on the University1652-Plus dataset yields the most substantial improvement, with Recall@1 reaching 88.80% on University160k-WX and 94.65% on University-1652, demonstrating the advantage of data expansion in model robustness. Finally, integrating the AEC module leads to further gains, achieving Recall@1 of 91.71% on University160k-WX and 95.43% on University-1652, underscoring the module’s impact on enhancing adaptability and accuracy under challenging conditions.
These findings highlight the contribution of each component to improving model robustness and accuracy across diverse datasets and weather conditions.
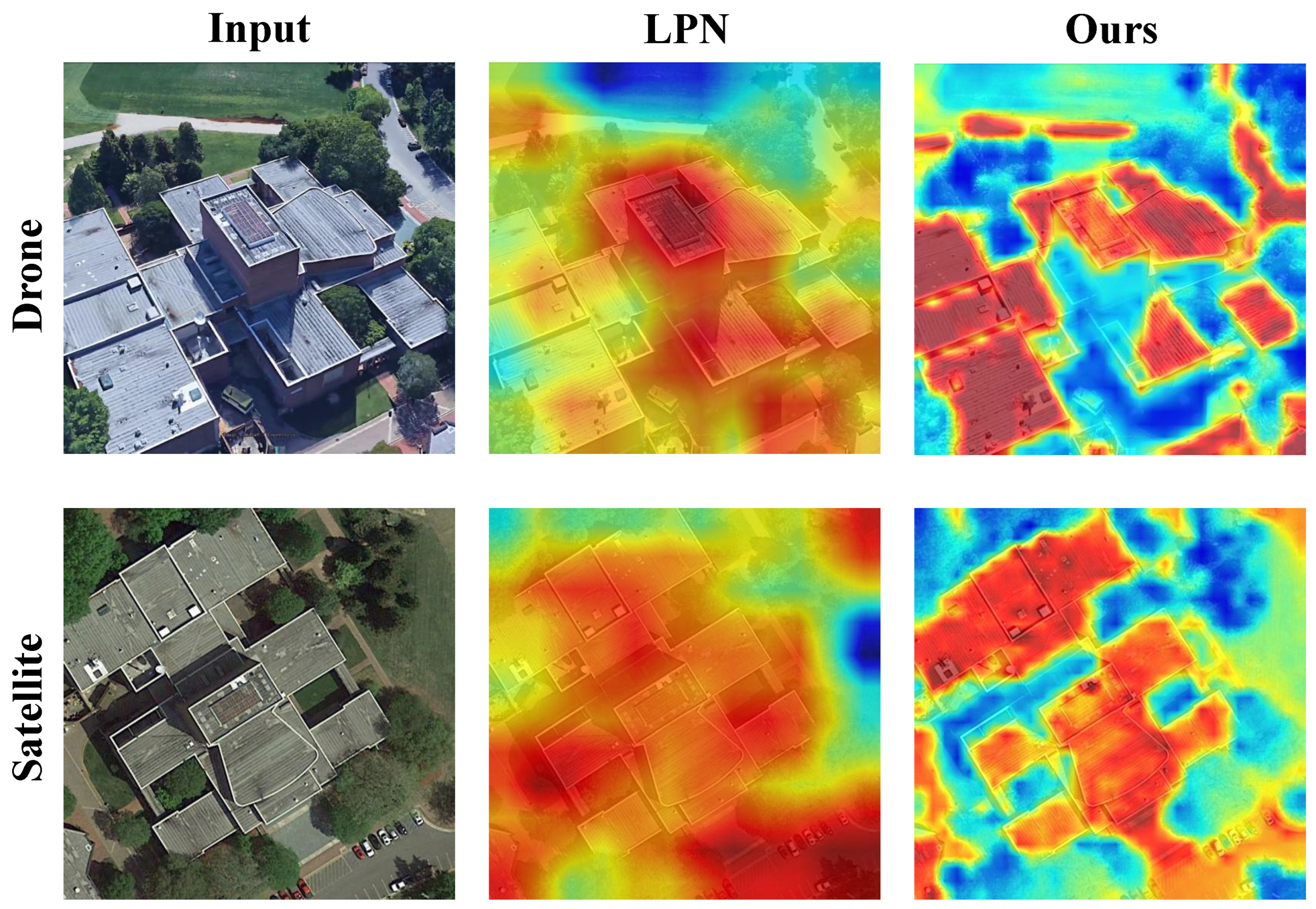
4.6. Visualization
In order to better demonstrate the matching effect of AGEN, we plot the heat maps of the LPN methods and the proposed AGEN, as shown in
Figure 6. The images in the first column are the input images from drone view and satellite view. The images in the second column are the heatmaps of LPN [
25]. The images in the last column are our heatmaps. The presented comparison illustrates the effectiveness of our proposed method in enhancing image matching between drone and satellite views. The input images clearly show detailed architectural features, while the corresponding heatmaps reveal significant differences in model performance. The previous method’s heatmaps, although providing some activation, lack precision in capturing critical details, especially around the edges of the buildings. In contrast, our method produces heatmaps that better highlight the intricate structures and contours of the buildings, showcasing improved clarity and accuracy.
To further investigate the weather robustness of different backbone architectures, we visualize and compare the attention heatmaps generated by ResNet50 [
68], ViT [
69], and our proposed DINOv2-based model under four representative extreme weather conditions from the University160k-WX dataset. These conditions include wind, overexposure, fog and snow, and darkness. This comparison allows us to assess how each model attends to salient regions under different types of environmental degradation. As illustrated in
Figure 7, the ResNet50 model tends to produce scattered and low-contrast attention regions, especially in low-visibility scenes. The ViT backbone exhibits moderately improved attention localization but remains sensitive to adverse illumination and occlusion. In contrast, the DINOv2-based model consistently captures focused, object-aligned attention maps across all conditions, demonstrating its superior capacity for learning weather-invariant representations. This qualitative comparison complements the quantitative results and further supports the effectiveness of our approach in challenging environments.
5. Discussion
Although the proposed method performs reliably across a range of extreme weather scenarios, it still presents several limitations that merit further investigation.
First, although the proposed method shows strong robustness under extreme weather, the test set uses a masked evaluation protocol without revealing specific weather labels, limiting fine-grained analysis under conditions like fog or rain. Future work could introduce datasets with explicit annotations to support targeted evaluation and model improvement.
Second, the dataset assumes that nine representative weather types sufficiently capture major visual degradations and use synthetic augmentation to simulate extreme conditions. However, a potential domain gap may exist between simulated and real-world data, which can hinder generalization. To address this, future research may define a more granular taxonomy of weather types or collect and label real remote sensing imagery under adverse conditions, thereby enhancing model reliability and deployment robustness.
Finally, despite covering typical extreme conditions, the current weather types are limited. In more complex scenarios, performance may degrade. Exploring generative models such as the diffusion model [
74] could help synthesize realistic weather data and facilitate the restoration of clean images from weather-degraded inputs. These capabilities support the creation of high-fidelity datasets and enhance both the generalization and interpretability of geo-localization models in real-world applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}