ICAFormer: An Image Dehazing Transformer Based on Interactive Channel Attention

Abstract
1. Introduction
2. Related Work
2.1. Image Dehazing Based on CNNs
2.2. Vision Transformer
2.3. Efficient Attention Mechanism
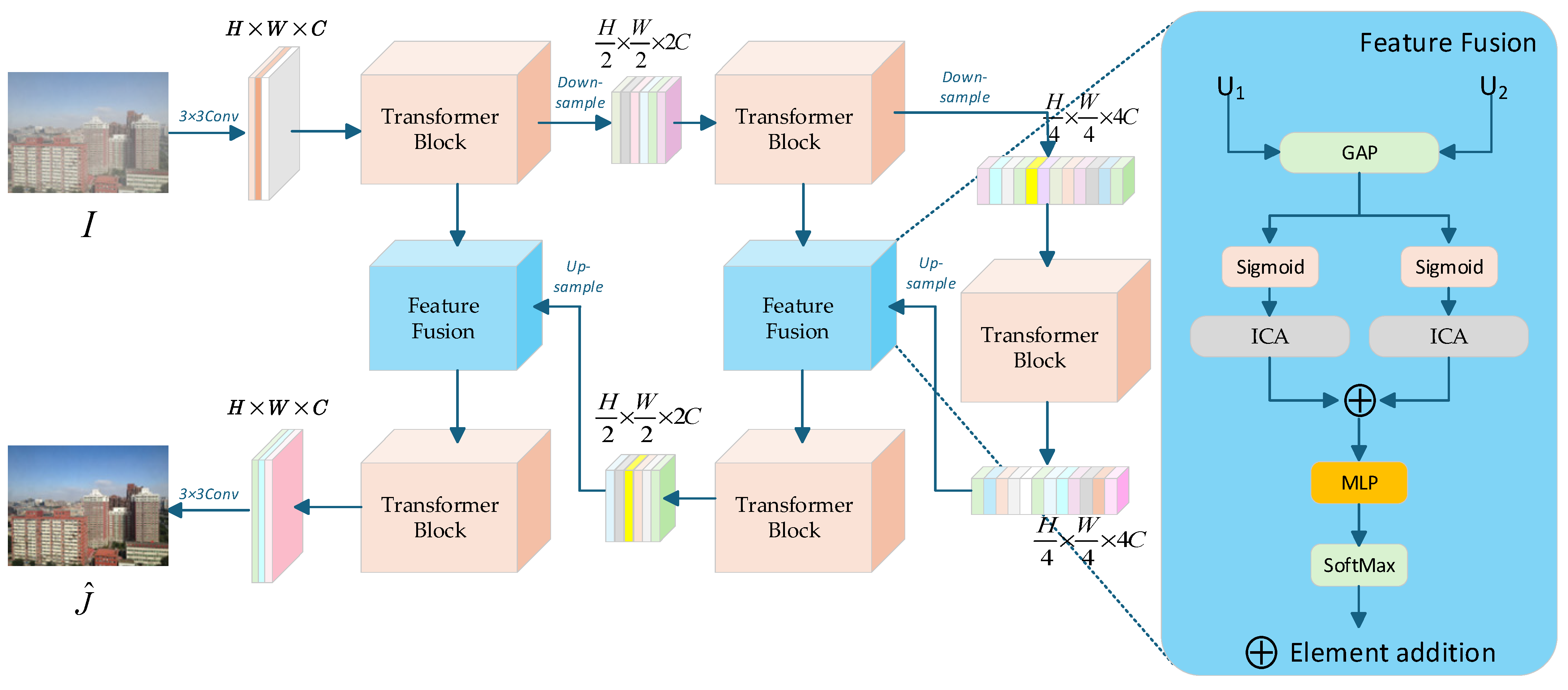
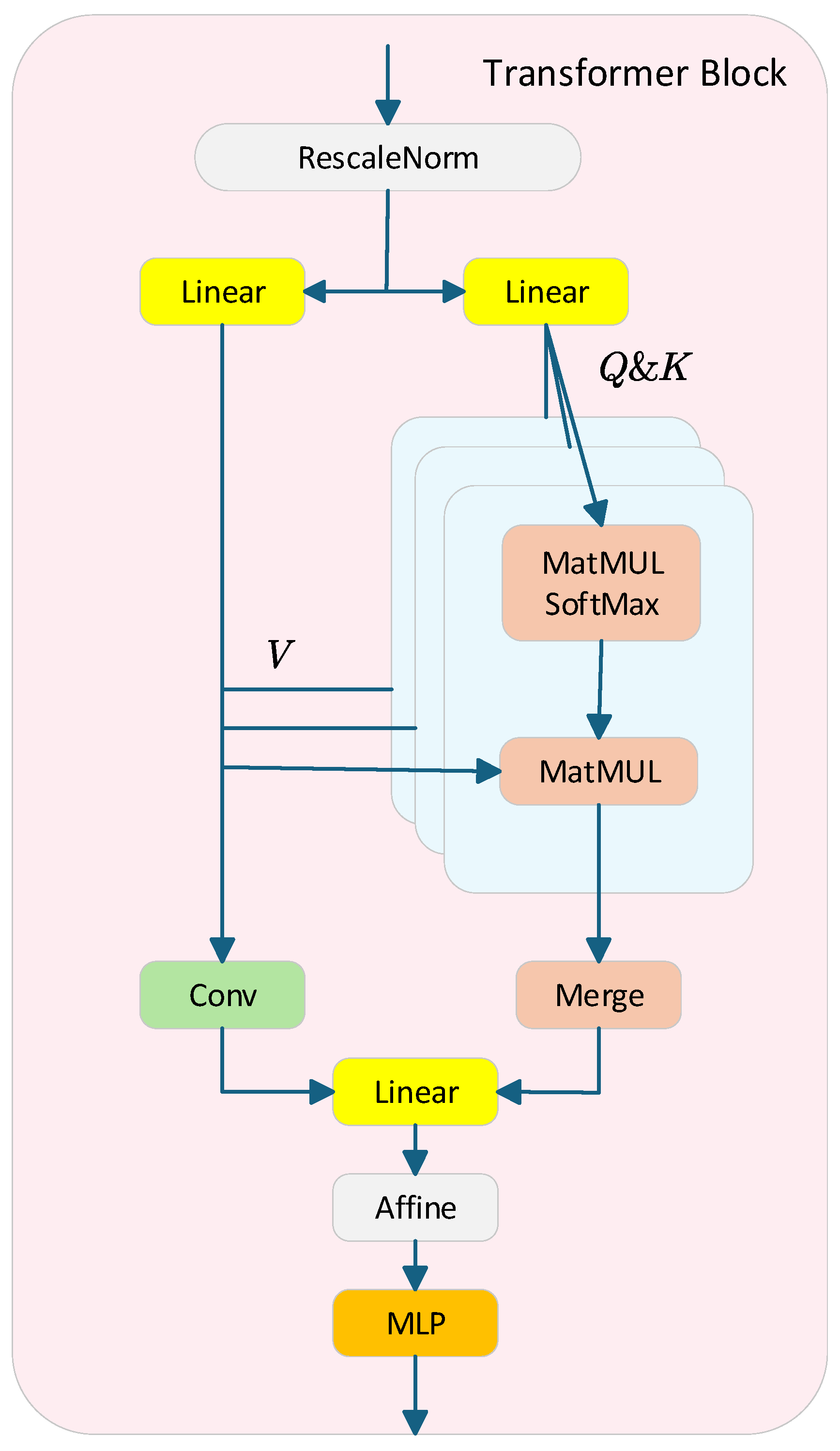
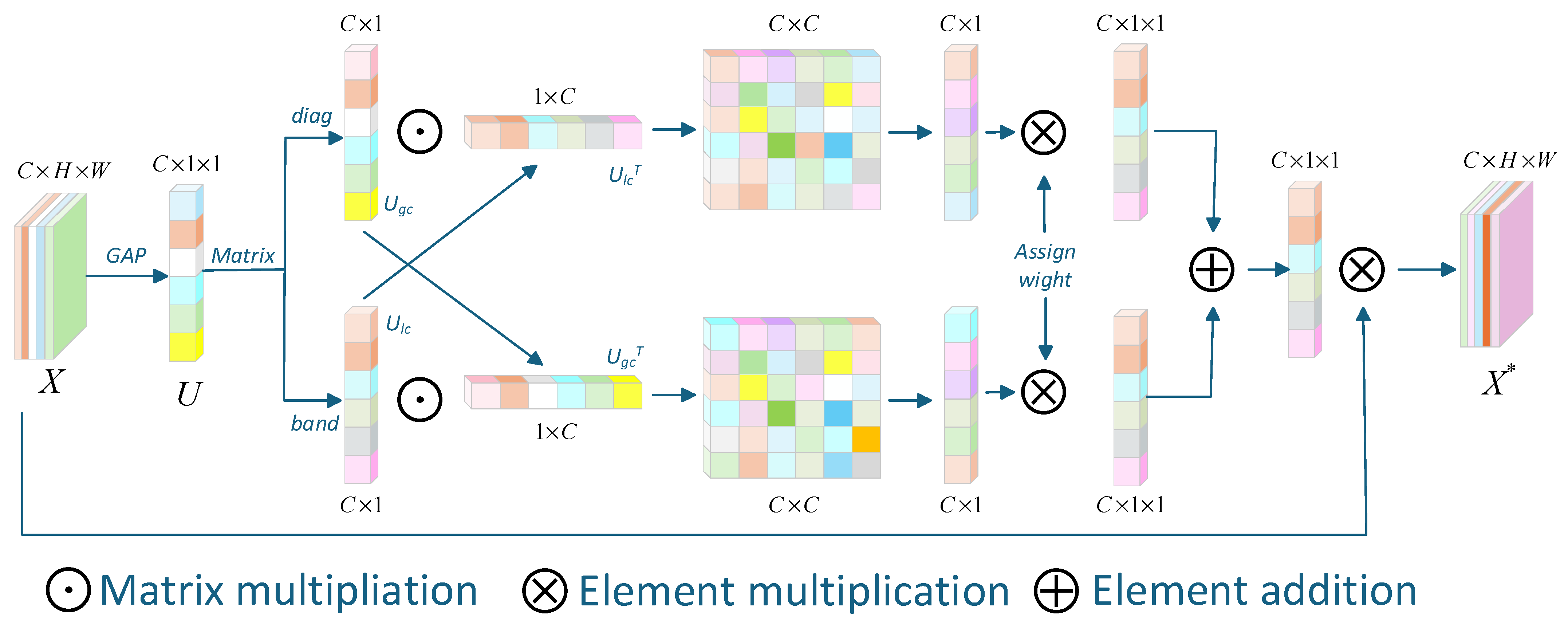
3. The Proposed Method
3.1. The Overall Architecture of the Network
3.2. Transformer Block
3.3. Interactive Channel Attention Mechanism
3.4. Loss Functions
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Comparison Experiment of Synthetic Dataset
4.4. Comparison Experiment of Real Dataset
4.5. Comparative Experiment on Params and FLOPs
4.6. Comparative Experiment on Attention Mechanisms
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. (TOG) 2014, 34, 13. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 154–169. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar]
- Zhang, X.; Wang, J.; Wang, T.; Jiang, R. Hierarchical feature fusion with mixed convolution attention for single image dehazing. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 510–522. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10729–10736. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Li, R.; Pan, J.; Li, Z.; Tang, J. Single image dehazing via conditional generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8202–8211. [Google Scholar]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Zhao, X.; Xu, F.; Liu, Z. TransDehaze: Transformer-enhanced texture attention for end-to-end single image dehaze. Vis. Comput. 2025, 41, 1621–1635. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Zhou, L.; Tao, Y.; Huang, H.; Zhu, Y. Etc-Net: A space-adaptive swin transformer-based method for underwater image enhancement integrating edge sharpening and color correction. Int. J. Mach. Learn. Cybern. 2025, 16, 3311–3327. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12504–12513. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2989–2998. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Huang, X.; Deng, Z.; Li, D.; Yuan, X. Missformer: An effective medical image segmentation transformer. arXiv 2021, arXiv:2109.07162. [Google Scholar] [CrossRef] [PubMed]
- Tu, D.; Min, X.; Duan, H.; Guo, G.; Zhai, G.; Shen, W. End-to-end human-gaze-target detection with transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2192–2200. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 280–296. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Van Gool, L. Mhformer: Multi-hypothesis transformer for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13147–13156. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3d human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11656–11665. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10231–10241. [Google Scholar]
- Lanchantin, J.; Wang, T.; Ordonez, V.; Qi, Y. General multi-label image classification with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16478–16488. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Choi, L.K.; You, J.; Bovik, A.C. Referenceless prediction of perceptual fog density and perceptual image defogging. IEEE Trans. Image Process. 2015, 24, 3888–3901. [Google Scholar] [CrossRef] [PubMed]
- Guan, T.; Li, C.; Gu, K.; Liu, H.; Zheng, Y.; Wu, X.J. Visibility and distortion measurement for no-reference dehazed image quality assessment via complex contourlet transform. IEEE Trans. Multimed. 2022, 25, 3934–3949. [Google Scholar] [CrossRef]
- Guan, T.; Li, C.; Zheng, Y.; Wu, X.; Bovik, A.C. Dual-stream complex-valued convolutional network for authentic dehazed image quality assessment. IEEE Trans. Image Process. 2023, 33, 466–478. [Google Scholar] [CrossRef] [PubMed]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2157–2167. [Google Scholar]
- Zhou, Y.; Chen, Z.; Li, P.; Song, H.; Chen, C.P.; Sheng, B. FSAD-Net: Feedback spatial attention dehazing network. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7719–7733. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Liu, P.; Zhang, Y. Multi-scale feature fusion pyramid attention network for single image dehazing. IET Image Process. 2023, 17, 2726–2735. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Indoor | Outdoor | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| DCP | 18.72 | 0.769 | 19.13 | 0.774 |
| DehazeNet | 22.75 | 0.886 | 21.29 | 0.877 |
| AOD-Net | 24.51 | 0.919 | 23.75 | 0.903 |
| MSBDN | 29.73 | 0.954 | 27.75 | 0.935 |
| FSAD-Net | 23.41 | 0.937 | 26.39 | 0.929 |
| PAN | 23.92 | 0.923 | 25.39 | 0.917 |
| Ours | 30.26 | 0.968 | 29.39 | 0.952 |
| Methods | Figure 6a | Figure 6b | Figure 6c | Figure 6d |
|---|---|---|---|---|
| Input | 1.1980 | 1.2594 | 0.9634 | 1.0366 |
| DCP | 0.1890 | 0.1780 | 0.1788 | 0.1800 |
| DehazeNet | 0.3237 | 0.5798 | 0.4277 | 0.3296 |
| AOD-Net | 0.1890 | 0.2657 | 0.2320 | 0.2332 |
| MSBDN | 0.2035 | 0.2807 | 0.2195 | 0.2762 |
| FSAD-Net | 0.2274 | 0.2606 | 0.1934 | 0.1875 |
| PAN | 0.2675 | 0.3264 | 0.2076 | 0.3417 |
| Ours | 0.1171 | 0.1477 | 0.1830 | 0.1566 |
| Methods | Params/×106 | FLOPs/×109 |
|---|---|---|
| DCP | - | - |
| DehazeNet | 0.009 | 0.581 |
| AOD-Net | 0.002 | 0.115 |
| MSBDN | 31.35 | 41.54 |
| FSAD-Net | 11.27 | 50.46 |
| PAN | 2.611 | 52.20 |
| Ours | 2.517 | 25.79 |
| Attentions | PSNR | SSIM |
|---|---|---|
| SE | 23.42 | 0.906 |
| ECA | 22.16 | 0.914 |
| CBAM | 25.88 | 0.931 |
| SK | 30.54 | 0.962 |
| ICA | 30.26 | 0.968 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Yue, T.; An, P.; Hong, H.; Liu, T.; Liu, Y.; Zhou, Y. ICAFormer: An Image Dehazing Transformer Based on Interactive Channel Attention. Sensors 2025, 25, 3750. https://doi.org/10.3390/s25123750
Chen Y, Yue T, An P, Hong H, Liu T, Liu Y, Zhou Y. ICAFormer: An Image Dehazing Transformer Based on Interactive Channel Attention. Sensors. 2025; 25(12):3750. https://doi.org/10.3390/s25123750
Chicago/Turabian StyleChen, Yanfei, Tong Yue, Pei An, Hanyu Hong, Tao Liu, Yangkai Liu, and Yihui Zhou. 2025. "ICAFormer: An Image Dehazing Transformer Based on Interactive Channel Attention" Sensors 25, no. 12: 3750. https://doi.org/10.3390/s25123750
APA StyleChen, Y., Yue, T., An, P., Hong, H., Liu, T., Liu, Y., & Zhou, Y. (2025). ICAFormer: An Image Dehazing Transformer Based on Interactive Channel Attention. Sensors, 25(12), 3750. https://doi.org/10.3390/s25123750