

DRGNet: Enhanced VVC Reconstructed Frames Using Dual-Path Residual Gating for High-Resolution Video

Abstract
1. Introduction
1.1. Signal Processing-Based Filtering Techniques
1.2. Neural Network-Based Filtering Techniques
- (I)
- (II)
- (I)
- A gating mechanism inspired by attention mechanisms is incorporated into the DPRG block to enhance feature selection. By multiplying the gating feature map with the main feature map, the model effectively retains essential features while suppressing noise. In parallel, the integration of residual networks mitigates the gradient vanishing problem, improving training stability and overall performance.
- (II)
- As prior knowledge for image reconstruction, QP Maps play a crucial role in video coding. They guide the network in reconstructing image features and noise patterns, thereby enhancing reconstruction accuracy and overall network performance.
- (III)
- The skip connection between the input image and the network’s residual output effectively preserves structural information and improves reconstruction accuracy through residual correction, leading to enhanced model performance and training efficiency.
- (IV)
- Post-filtering in video encoding significantly improves image quality. The RA mode achieves efficient random access to video sequences by utilizing a structure that combines I, P, and B frames; the LDB mode focuses on minimizing latency; and the AI approach relies on I-frames to facilitate fast navigation. To balance the trade-offs among RA, LDB, and AI in terms of quality, compression efficiency, latency, and accessibility, the proposed neural network enhances video reconstruction fidelity across all three modes. The designed dual-path CNN post-processing framework is adaptable to various encoding scenarios and robust across a wide range of QP values.
2. Related Work
2.1. Development of the Neural Network Model
2.2. Neural Network-Based In-Loop Filtering
2.3. Neural Network-Based Post-Filtering
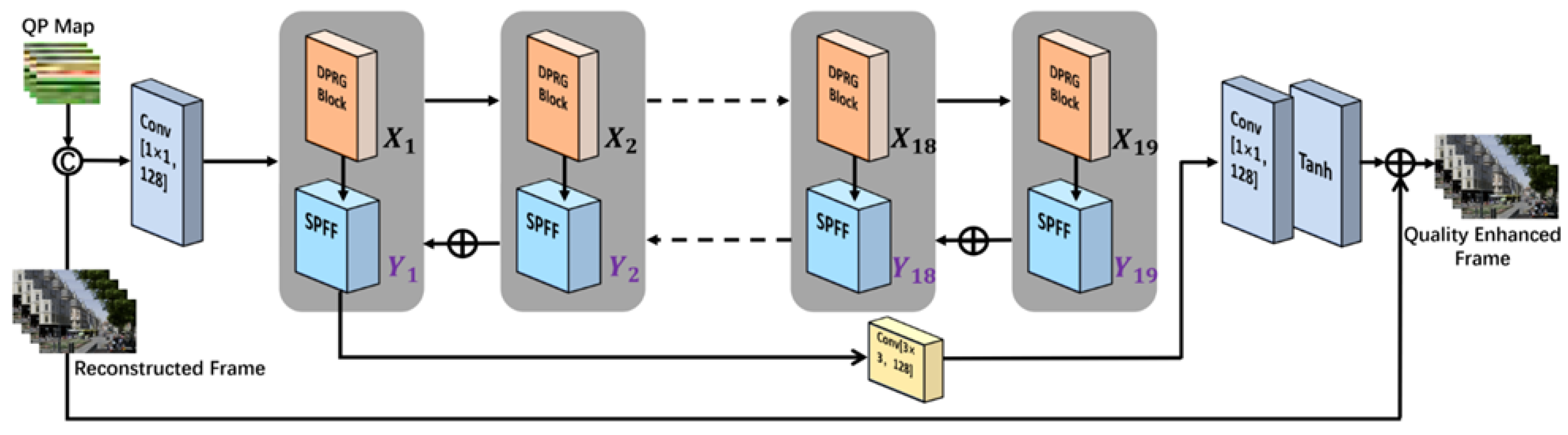
3. Proposed Method
3.1. Development of the Neural Network Model
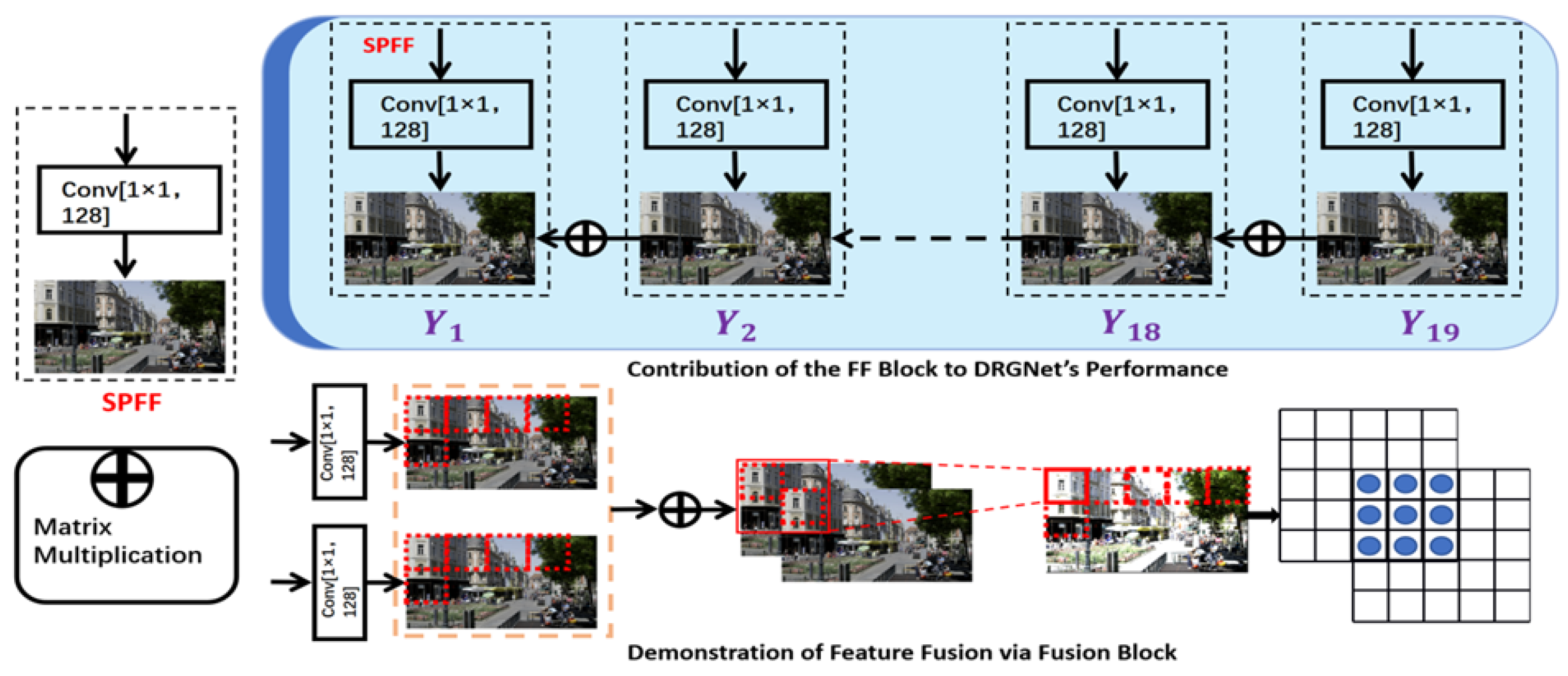
3.2. Proposed Dual-Path Residual Gating
3.2.1. Architecture Overview of DRGNet
3.2.2. DRGNet Component
3.2.3. Training Strategy
4. Results
4.1. Experimental Environment
4.2. Experimental Evaluation Method
4.3. Experimental Environment
4.4. Perceptual Quality Evaluation Results
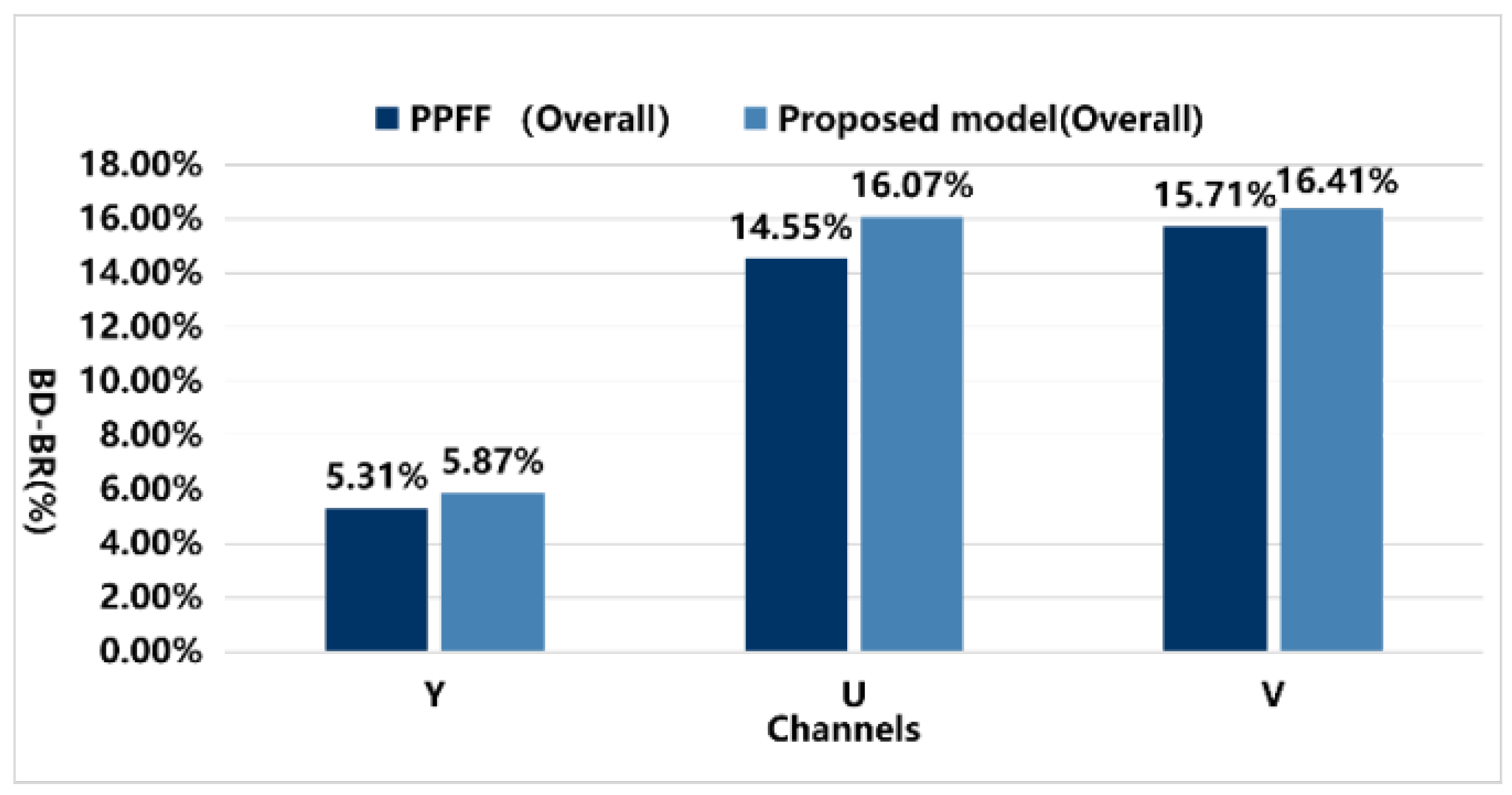
4.5. Comparative Analysis with PPFF
5. Discussion
5.1. Key Technical Enhancements
- (I).
- A CNN-Based Post-Processing Network Design
- (II).
- Application of Ultra-Deep Residual Convolutional Neural Networks
- (III).
- A High-Resolution Video-Oriented Neural Network Architecture
- (IV).
- Activation Function Synergy for High-Resolution Video Feature Representation
5.2. Limitations of This Study
5.3. Exploration Opportunities in the Proposed Framework
5.4. Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ostermann, J.; Bormans, J.; List, P.; Marpe, D.; Narroschke, M.; Pereira, F. Video coding with H.264/AVC: Tools, performance, and complexity. IEEE Circuits Syst. Mag. 2004, 4, 7–28. [Google Scholar] [CrossRef]
- Sze, V.; Budagavi, M.; Sullivan, G.J. High Efficiency Video Coding (HEVC): Algorithms and Architectures; Springer: New York, NY, USA, 2014. [Google Scholar]
- Boyce, J.M.; Chen, J.; Liu, S.; Ohm, J.-R.; Sullivan, G.J.; Wiegand, T. Guest editorial introduction to the special section on the VVC standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3731–3735. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chen, C.-Y.; Yamakage, T.; Chong, I.S.; Huang, Y.-W.; Fu, C.-M. Adaptive loop filtering for video coding. IEEE J. Sel. Top. Signal Process. 2013, 7, 934–945. [Google Scholar] [CrossRef]
- Fu, C.-M.; Alshin, E.; Alshin, A.; Huang, Y.-W.; Chen, C.-Y.; Tsai, C.-Y. Sample adaptive offset in the HEVC standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1755–1764. [Google Scholar] [CrossRef]
- Fu, C.-M.; Chen, C.-Y.; Huang, Y.-W.; Lei, S. Sample adaptive offset for HEVC. In Proceedings of the 2011 IEEE 13th International Workshop on Multimedia Signal Processing (MMSP), Hangzhou, China, 17–19 October 2011. [Google Scholar] [CrossRef]
- Andersson, K.; Misra, K.; Ikeda, M.; Rusanovskyy, D.; Iwamura, S. Deblocking filtering in VVC. In Proceedings of the 2021 Picture Coding Symposium (PCS), Bristol, UK, 29 June–2 July 2021. [Google Scholar] [CrossRef]
- Norkin, A.; Bjøntegaard, G.; Fuldseth, A.; Narroschke, M.; Ikeda, M.; Andersson, K. HEVC deblocking filter. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1746–1754. [Google Scholar] [CrossRef]
- Lu, T.; Pu, F.; Yin, P.; McCarthy, S.; Husak, W.; Chen, T. Luma mapping with chroma scaling in versatile video coding. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 23–27 March 2020. [Google Scholar] [CrossRef]
- Kim, Y.; Shin, W.; Lee, J.; Oh, K.-J.; Ko, H. Performance analysis of versatile video coding for encoding phase-only hologram videos. Opt. Express 2023, 31, 38854–38877. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Yu, K.; Dong, C.; Loy, C.C.; Tang, X. Deep convolution networks for compression artifacts reduction. arXiv 2016, arXiv:1608.02778. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. arXiv 2014, arXiv:1501.00092. [Google Scholar] [CrossRef]
- Jiang, F.; Tao, W.; Liu, S.; Ren, J.; Guo, X.; Zhao, D. An end-to-end compression framework based on convolutional neural networks. arXiv 2017, arXiv:1708.00838. [Google Scholar] [CrossRef]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. arXiv 2016, arXiv:1603.09056. [Google Scholar]
- Mishra, D.; Singh, S.K.; Singh, R.K. Deep learning-based edge-aware pre and post-processing methods for JPEG compressed images. arXiv 2021, arXiv:2104.04926. [Google Scholar]
- Poyser, M.; Atapour-Abarghouei, A.; Breckon, T.P. On the impact of lossy image and video compression on the performance of deep convolutional neural network architectures. arXiv 2020, arXiv:2007.14314. [Google Scholar]
- Li, M.; Zuo, W.; Gu, S.; Zhao, D.; Zhang, D. Learning convolutional networks for content-weighted image compression. arXiv 2017, arXiv:1703.10553. [Google Scholar]
- Cavigelli, L.; Hager, P.; Benini, L. CAS-CNN: A deep convolutional neural network for image compression artifact suppression. arXiv 2016, arXiv:1611.07233. [Google Scholar]
- Svoboda, P.; Hradis, M.; Barina, D.; Zemcik, P. Compression artifacts removal using convolutional neural networks. arXiv 2016, arXiv:1605.00366. [Google Scholar]
- Ma, D.; Zhang, F.; Bull, D.R. MFRNet: A new CNN architecture for post-processing and in-loop filtering. arXiv 2020, arXiv:2007.07099. [Google Scholar] [CrossRef]
- Lin, W.; He, X.; Han, X.; Liu, D.; See, J.; Zou, J.; Xiong, H.; Wu, F. Partition-aware adaptive switching neural networks for post-processing in HEVC. arXiv 2019, arXiv:1912.11604. [Google Scholar] [CrossRef]
- Lange, L.; Verhack, R.; Sikora, T. Video representation and coding using a sparse steered mixture-of-experts network. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016. [Google Scholar]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-SRNet: A wavelet-based CNN for multi-scale face super resolution. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1–9. [Google Scholar]
- Ding, D.; Chen, G.; Mukherjee, D.; Joshi, U.; Chen, Y. A CNN-based in-loop filtering approach for AV1 video codec. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 11–13 November 2019. [Google Scholar] [CrossRef]
- Ding, D.; Kong, L.; Chen, G.; Liu, Z.; Fang, Y. A switchable deep learning approach for in-loop filtering in video coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1871–1887. [Google Scholar] [CrossRef]
- Pham, C.D.K.; Fu, C.; Zhou, J. Deep learning-based spatial-temporal in-loop filtering for versatile video coding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1–6. [Google Scholar]
- Jia, M.; Gao, Y.; Li, S.; Yue, J.; Ye, M. An explicit self-attention-based multimodality CNN in-loop filter for versatile video coding. Multimed. Tools Appl. 2022, 81, 42497–42511. [Google Scholar] [CrossRef]
- Choi, K. Block partitioning information-based CNN post-filtering for EVC baseline profile. Sensors 2024, 24, 1336. [Google Scholar] [CrossRef] [PubMed]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated shape CNNs for semantic segmentation. arXiv 2019, arXiv:1907.05740. [Google Scholar]
- Zhu, M.; Li, Z. NGDCNet: Noise gating dynamic convolutional network for image denoising. Electronics 2023, 12, 5019. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. arXiv 2017, arXiv:1612.08083. [Google Scholar]
- Luo, Z.; Sun, Z.; Zhou, W.; Wu, Z.; Kamata, S. Rethinking ResNets: Improved stacking strategies with high order schemes. arXiv 2021, arXiv:2103.15244. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Jarrahi, A.; Mousa, R.; Safari, L. SLCNN: Sentence-level convolutional neural network for text classification. arXiv 2023, arXiv:2301.11696. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar] [CrossRef]
- Elad, M.; Kawar, B.; Vaksman, G. Image denoising: The deep learning revolution and beyond—A survey paper. arXiv 2023, arXiv:2301.03362. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, C.; Zhang, L. Denoising convolutional neural network. In Proceedings of the 2015 IEEE International Conference, Lijiang, China, 8–10 August 2015. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. arXiv 2017, arXiv:1708.02209. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. arXiv 2017, arXiv:1704.03264. [Google Scholar]
- Wu, W.; Liu, S.; Zhou, Y.; Zhang, Y.; Xiang, Y. Dual Residual Attention Network for Image Denoising. arXiv 2023, arXiv:2305.04269. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Zuo, W. Image denoising using deep CNN with batch renormalization. Neural Netw. 2020, 121, 461–473. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Qu, M.; Wang, Y.; Cao, L. A Multi-Head Convolutional Neural Network With Multi-path Attention Improves Image Denoising. arXiv 2022, arXiv:2204.12736. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, L. Rectifier Neural Network with a Dual-Pathway Architecture for Image Denoising. arXiv 2020, arXiv:1609.03024. [Google Scholar]
- Luo, D.; Ye, M.; Li, S.; Zhu, C.; Li, X. Spatio-Temporal Detail Information Retrieval for Compressed Video Quality Enhancement. IEEE Trans. Multimed. 2022, 25, 6808–6820. [Google Scholar] [CrossRef]
- Zhu, Q.; Hao, J.; Ding, Y.; Liu, Y.; Mo, Q.; Sun, M.; Zhou, C.; Zhu, S. CPGA: Coding Priors-Guided Aggregation Network for Compressed Video Quality Enhancement. arXiv 2024, arXiv:2403.10362. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual Feature Distillation Network for Lightweight Image Super-Resolution. arXiv 2020, arXiv:2009.11551. [Google Scholar]
- Xing, Q.; Guan, Z.; Xu, M.; Yang, R.; Liu, T.; Wang, Z. MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 949–963. [Google Scholar]
- Das, T.; Liang, X.; Choi, K. Versatile video coding-post processing feature fusion: A post-processing convolutional neural network with progressive feature fusion for efficient video enhancement. Appl. Sci. 2024, 14, 8276. [Google Scholar] [CrossRef]
- Schiopu, I.; Munteanu, A. Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement. Sensors 2022, 22, 1353. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, F.; Bull, D.R. CVEGAN: A Perceptually-inspired GAN for Compressed Video Enhancement. arXiv 2020, arXiv:2011.09190. [Google Scholar] [CrossRef]
- Zhang, H.; Jung, C.; Zou, D.; Li, M. WCDANN: A Lightweight CNN Post-Processing Filter for VVC-Based Video Compression. IEEE Access 2023, 11, 60162–60173. [Google Scholar] [CrossRef]
- Xing, Q.; Xu, M.; Li, S.; Deng, X.; Zheng, M.; Liu, H.; Chen, Y. Enhancing Quality of Compressed Images by Mitigating Enhancement Bias Towards Compression Domain. arXiv 2024, arXiv:2402.17200. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-Play Image Restoration with Deep Denoiser Prior. arXiv 2020, arXiv:2008.13751. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. arXiv 2021, arXiv:2108.10257. [Google Scholar]
- Park, W.-S.; Kim, M. CNN-based In-loop Filtering for Coding Efficiency Improvement. In Proceedings of the 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Beijing, China, 11–12 July 2016; pp. 1–5. [Google Scholar]
- Ma, D.; Zhang, F.; Bull, D.R. BVI-DVC: A training database for deep video compression. arXiv 2020, arXiv:2003.13552. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Curran Associates, Red Hook, NY, USA, 8–14 December 2019; pp. 1–12. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Target Codec | Dataset/Scene Type | Key Contribution |
|---|---|---|---|
| STDR [48] | N/A (Rendering only) | Synthetic and real-world dynamic scenes. D-NeRF dataset. | Spatio-temporal decoupling for real-time consistency. |
| CPGA [49] | HEVC/H.265 (HM16.25) | Compressed videos with coding priors: Motion vectors, reference frames, and residuals (trained/tested on datasets like REDS, Vimeo-90K). | Multi-frame enhancement guided by coding priors for artifact removal. |
| RFDN [50] | N/A (Single Image Super-Resolution) | Benchmark image SR datasets: DIV2K, Set5, Set14, BSD100, Urban100, Manga109. | Residual distillation for lightweight SR. |
| MFQE2.0 [51] | HEVC/H.265, AVC/H.264 | Compressed video sequences exhibiting quality fluctuations; evaluated on datasets including Xiph.org and JCT-VC | PQF-guided multi-frame enhancement using motion-compensated CNN. |
| PPFF [52] | H.266/VVC | VVC compressed videos under standard configurations. | The network fuses features from different levels to enhance spatial and semantic representations. |
| ASQE-CNN [53] | H.266/VVC (VTM reference) | VVC-decoded frames under AI, RA, LDB configurations (e.g., JVET CTC test sets). | Shared-weight attention CNN for low-complexity BD-Rate savings. |
| CVEGAN [54] | H.266/VVC | VVC decoded video frames using CLIC 2022 test sequences and VTM outputs. | Multi-frame GAN enhancement with BD-Rate gains over VTM. |
| WCDANN [55] | VVC (VTM-11.0-NNVC) | Multiple classes (A1, A2, B, C, D, E) under RA, AI, LDP. | Lightweight CNN with weakly connected dense attention and depthwise separable convolutions (WCDABs) for efficient feature extraction. |
| Model | QP Range |
|---|---|
| Video Resolution | Number of Videos | Frames | Bit Depth | Chroma |
|---|---|---|---|---|
| 3840 × 2160 | 200 | 2000 | 10 | 4:2:0 |
| 1920 × 1080 | 200 | 2000 | 10 | 4:2:0 |
| 960 × 544 | 200 | 2000 | 10 | 4:2:0 |
| 480 × 272 | 200 | 2000 | 10 | 4:2:0 |
| Class | Video Resolution | Number of Videos | Frames | Bit Depth | Chroma |
|---|---|---|---|---|---|
| A1 | 3840 × 2160 | 3 | 1314 | 10 | 4:2:0 |
| A2 | 3840 × 2160 | 3 | 1400 | 10 | 4:2:0 |
| B | 1920 × 1080 | 5 | 2802 | 10 | 4:2:0 |
| C | 832 × 480 | 4 | 1903 | 10 | 4:2:0 |
| Class | Sequence | Y | U | V |
|---|---|---|---|---|
| A1 | Tango | −5.48% | −22.48% | −20.56% |
| FoodMarket | −3.82% | −10.52% | −8.76% | |
| Campfire | −7.35% | −8.16% | −19.42% | |
| Average | −5.55% | −13.72% | −16.25% | |
| A2 | CatRobot | −7.61% | −25.62% | −22.01% |
| DaylightRoad | −8.75% | −21.50% | −19.51% | |
| ParkRunning | −2.54% | −2.55% | −2.66% | |
| Average | −6.30% | −16.56% | −14.73% | |
| B | MarketPlace | −3.47% | −18.38% | −15.71% |
| RitualDance | −6.00% | −16.57% | −17.18% | |
| Cactus | −5.11% | −13.92% | −11.56% | |
| BasketballDrive | −6.63% | −19.70% | −23.43% | |
| BQTerrace | −6.09% | −13.82% | −8.18% | |
| Average | −5.46% | −16.48% | −15.21% | |
| C | BasketballDrill | −7.27% | −15.50% | −22.19% |
| BQMall | −7.02% | −21.15% | −22.86% | |
| PartyScene | −5.61% | −10.94% | −8.19% | |
| RaceHorses | −5.31% | −20.27% | −23.91% | |
| Average | −6.30% | −16.96% | −19.29% | |
| Overall | −5.87% | −16.07% | −16.41% | |
| Class | Sequence | Y | U | V |
|---|---|---|---|---|
| B | MarketPlace | −3.50% | −32.08% | −25.54% |
| RitualDance | −4.92% | −23.68% | −21.34% | |
| Cactus | −6.16% | −25.03% | −25.21% | |
| BasketballDrive | −6.00% | −26.54% | −26.71% | |
| BQTerrace | −8.61% | −32.04% | −24.92% | |
| Average | −5.84% | −27.87% | −24.74% | |
| C | BasketballDrill | −7.65% | −26.70% | −32.48% |
| BQMall | −9.61% | −27.51% | −30.20% | |
| PartyScene | −6.98% | −27.86% | −26.98% | |
| RaceHorses | −5.89% | −29.26% | −35.87% | |
| Average | −7.53% | −27.83% | −31.38% | |
| Overall | −6.84% | −27.86% | −27.69% | |
| Class | Sequence | Y | U | V |
|---|---|---|---|---|
| A1 | Tango | −4.88% | −11.85% | −13.09% |
| FoodMarket | −4.70% | −9.55% | −7.45% | |
| Campfire | −5.53% | −4.22% | −11.49% | |
| Average | −5.04% | −8.54% | −10.68% | |
| A2 | CatRobot | −8.59% | −18.14% | −17.73% |
| DaylightRoad | −9.11% | −16.60% | −13.88% | |
| ParkRunning | −2.28% | −2.56% | −2.69% | |
| Average | −6.66% | −12.43% | −11.43% | |
| B | MarketPlace | −4.06% | −13.79% | −12.18% |
| RitualDance | −7.11% | −15.10% | −14.54% | |
| Cactus | −5.05% | −7.16% | −8.92% | |
| BasketballDrive | −5.32% | −8.83% | −16.19% | |
| BQTerrace | −4.42% | −8.29% | −6.71% | |
| Average | −5.19% | −10.64% | −11.71% | |
| C | BasketballDrill | −8.55% | −8.59% | −24.58% |
| BQMall | −7.71% | −11.62% | −15.43% | |
| PartyScene | −4.66% | −0.80% | −5.62% | |
| RaceHorses | −5.07% | −14.39% | −20.55% | |
| Average | −6.50% | −8.85% | −15.32% | |
| Overall | −5.80% | −10.10% | −12.41% | |
| Test | Sequence Class | PSNR-Y (dB) | PSNR-U (dB) | PSNR-V (dB) |
|---|---|---|---|---|
| RA | A1 | 0.153 | 0.225 | 0.308 |
| A2 | 0.134 | 0.211 | 0.235 | |
| B | 0.169 | 0.289 | 0.360 | |
| C | 0.270 | 0.405 | 0.592 | |
| LDB | B | 0.282 | 0.449 | 0.582 |
| C | 0.284 | 0.701 | 0.887 | |
| AI | A1 | 0.140 | 0.215 | 0.248 |
| A2 | 0.108 | 0.251 | 0.230 | |
| B | 0.322 | 0.324 | 0.662 | |
| C | 0.322 | 0.324 | 0.662 |
| Class | PPFF [52] | Proposed | ||||
|---|---|---|---|---|---|---|
| Y | U | V | Y | U | V | |
| A1 | −4.38% | −11.31% | −15.58% | −5.55% | −13.72% | −16.25% |
| A2 | −5.30% | −14.42% | −12.65% | −6.30% | −16.56% | −14.73% |
| Average (A1, A2) | −4.84% | −12.87% | −14.12% | −6.42% | −14.73% | −14.33% |
| B | −5.08% | −15.08% | −14.83% | −5.46% | −16.48% | −15.21% |
| C | −6.28% | −11.31% | −19.21% | −6.30% | −16.96% | −19.29% |
| Overall | −5.31% | −14.55% | −15.71% | −5.87% | −16.07% | −16.41% |
| Class | PPFF [52] | Proposed | ||||
|---|---|---|---|---|---|---|
| Y | U | V | Y | U | V | |
| B | −5.25% | −26.03% | −23.95% | −5.84% | −27.87% | −24.74% |
| C | −7.12% | −27.29% | −30.35% | −7.53% | −27.83% | −31.38% |
| Overall | −6.08% | −26.59% | −27.15% | −6.59% | −27.86% | −27.69% |
| Class | Resolution | FLOPs (G) | Total Parameters (M) |
|---|---|---|---|
| A1 | 3840 × 2160 | 47,850.78 | 8.72 |
| A2 | 3480 × 2160 | 47,850.78 | 8.72 |
| B | 1920 × 1080 | 11,961.2 | 8.72 |
| C | 832 × 480 | 2303.6 | 8.72 |
| Class | WCDANN [55] | Proposed | ||||
|---|---|---|---|---|---|---|
| Y | U | V | Y | U | V | |
| A1 | −2.23% | N/A | N/A | −5.55% | −13.72% | −16.25% |
| A2 | −2.70% | N/A | N/A | −6.30% | −16.56% | −14.73% |
| B | −2.73% | N/A | N/A | −5.46% | −16.48% | −15.21% |
| C | −3.43% | N/A | N/A | −6.30% | −16.96% | −19.29% |
| Overall | −2.77% | N/A | N/A | −5.87% | −16.07% | −16.41% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gai, Z.; Das, T.; Choi, K. DRGNet: Enhanced VVC Reconstructed Frames Using Dual-Path Residual Gating for High-Resolution Video. Sensors 2025, 25, 3744. https://doi.org/10.3390/s25123744
Gai Z, Das T, Choi K. DRGNet: Enhanced VVC Reconstructed Frames Using Dual-Path Residual Gating for High-Resolution Video. Sensors. 2025; 25(12):3744. https://doi.org/10.3390/s25123744
Chicago/Turabian StyleGai, Zezhen, Tanni Das, and Kiho Choi. 2025. "DRGNet: Enhanced VVC Reconstructed Frames Using Dual-Path Residual Gating for High-Resolution Video" Sensors 25, no. 12: 3744. https://doi.org/10.3390/s25123744
APA StyleGai, Z., Das, T., & Choi, K. (2025). DRGNet: Enhanced VVC Reconstructed Frames Using Dual-Path Residual Gating for High-Resolution Video. Sensors, 25(12), 3744. https://doi.org/10.3390/s25123744