1. Introduction
Noise pollution regulations mainly focus on controlling the impact produced by industrial activities, road, rail and aviation traffic. However, in recent years, cities have been impacted by a different type of noise pollution derived from commercial and leisure activities, affecting increasingly extensive pedestrian areas. Most of these activities extend into residential areas, exposing neighbours to high noise levels for much of the day and night. From a technical point of view, the problem is complex due to the variability in sound intensity levels of the noise sources, the simultaneity and directionality of the sound emission, the variability in the number of sources present and their spatial distribution, which make it difficult to apply specific control measures. From a social point of view, it is a conflict between economic, environmental and public health interests. Sometimes it is also a problem of public order. It should be added that, whatever the particular issue under study, scientific research on the subject is scarce (see, e.g., [
1,
2,
3,
4,
5]).
While there is a mandatory path to follow to prevent and mitigate noise exposure under the EU Environmental Noise Directive (END) [
6], in many countries, the law only specifies the acoustic quality objectives applicable to these areas, i.e., the noise levels that must never be exceeded by all the sources present. This means that public administrations are committed to carrying out periodical measurements of noise levels in the affected areas, to confirm that these limits are not exceeded or to adopt measures if they are. To achieve this, the most appropriate method is to install a permanent network of measuring instruments (sound level meters) to instantly relay information to a control and evaluation centre. This data would allow real-time noise maps to be produced using specific software [
7]. In Spain, to the best of the researchers’ knowledge, such an installation only exists in the cities of Madrid and Barcelona, and they only extend over part of the affected areas [
8]. The problem is that although in recent years the price of these measurement stations has been reduced considerably, this type of solution continues to be very expensive to install, maintain and operate. Very recently, other direct measurement strategies based on citizen collaboration have been launched in which participants use their personal mobile phones or low-cost sensors that they place in their homes to measure noise levels. In this context, a recent literature review about low-cost and Internet of Things (IoT) sensors in this context have been made by Picaut et al. [
9]. The data collected is then sent to a web server that processes the information and generates noise maps in real time that are shared in open access. There are already some applications available that make use of this idea (see, e.g., [
10]). Although interesting, this is, however, not a reliable system because it depends on the use of devices with calibrations difficult to monitor over time and on information collected by potentially affected citizens that may be impartial. In this respect, an interesting compendium and analysis of innovative solutions for noise pollution management can be found at [
11].
However, an indirect approach to the problem is also possible: We can calculate a reasonable estimate of the noise level generated by determining the number of people present on the streets of these areas and their distribution. To generate this information, we only need images and a computational tool that can process them. A network of cameras suitable for this purpose is a less expensive measure than a network of sound level meters. What is more, networks of cameras already exist in many cities and densely populated areas for the purpose of surveillance and the maintenance of public order. The proposal therefore is the use of tools based on Artificial Neural Networks (ANNs) to efficiently find the crowd density in these environments from the images taken by this camera network.
Nevertheless, the propagation of acoustic waves in urban environments does not solely depend on the crowd density. It is also influenced by the geometry and planimetry of these areas. Tall buildings and narrow streets can act as acoustic canyons, making it difficult to dissipate noise and amplifying acoustic levels. The architectural features of buildings, planning and urban design therefore play a crucial role in noise management.
To address this problem, in this work, the authors propose to initiate a line of research aimed at creating applications based on numerical models in the frequency domain to reproduce the propagation of acoustic waves produced by human activity in urban areas (anthropogenic noise) in conjunction with other techniques in the field of artificial intelligence for crowd density estimation. Specifically, using the geometry of the studied area and the number of people, as well as their distribution captured by the installed cameras as input data, these tools will return as a result an estimate of the noise level at all points of the model (the noise map). In the first phase of the work, a simplified semi-analytical numerical model is proposed to reproduce the acoustic propagation produced by point sources located between two parallel reflecting boundaries, and a third one perpendicular to the previous ones, also reflecting. This model represents what is known as a Street Canyon (see, e.g., [
12]), i.e., a narrow street between tall buildings. For many real situations, it can be a very representative model of the problem for receivers on a street with a medium to high density of sources emitting near ground level.
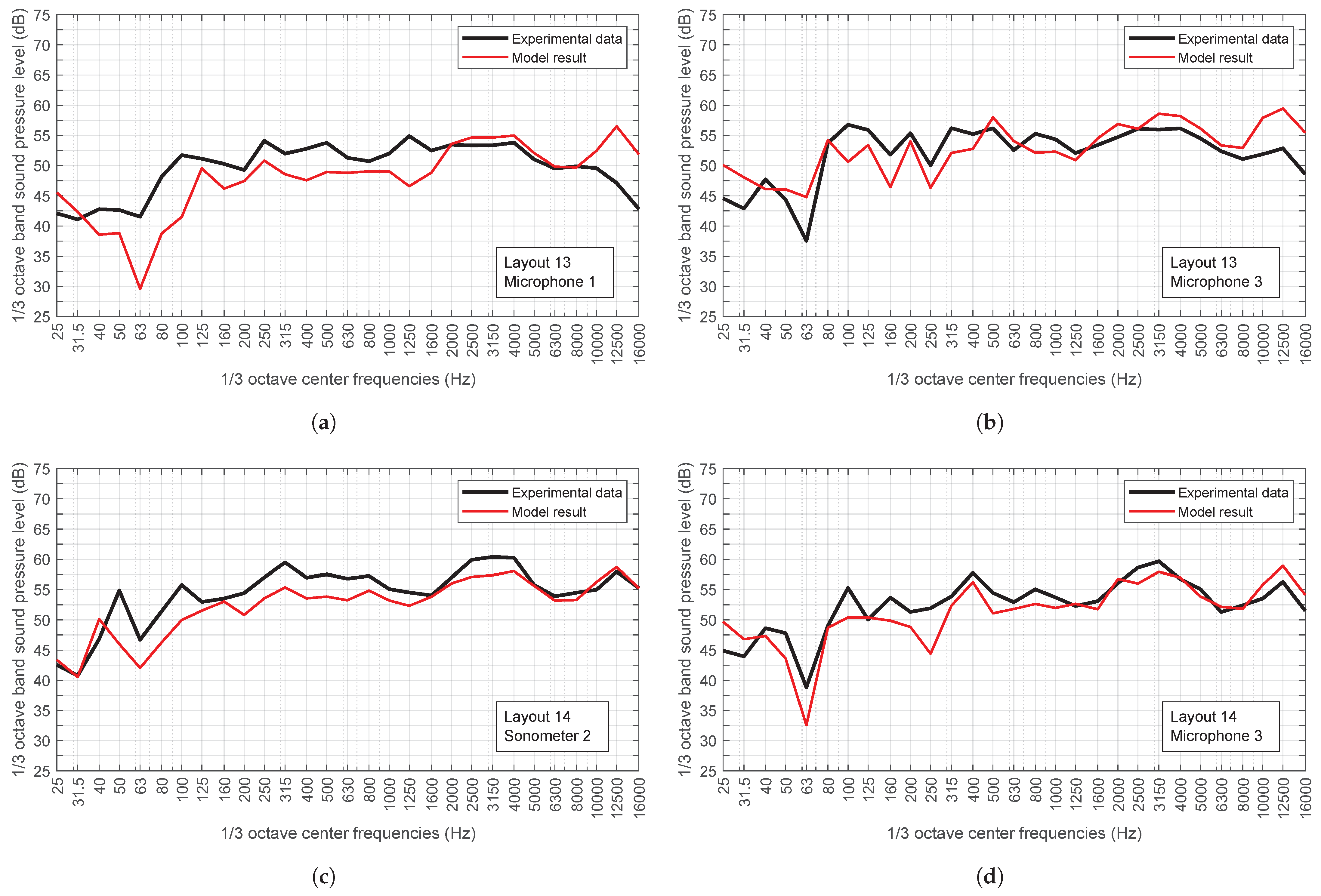
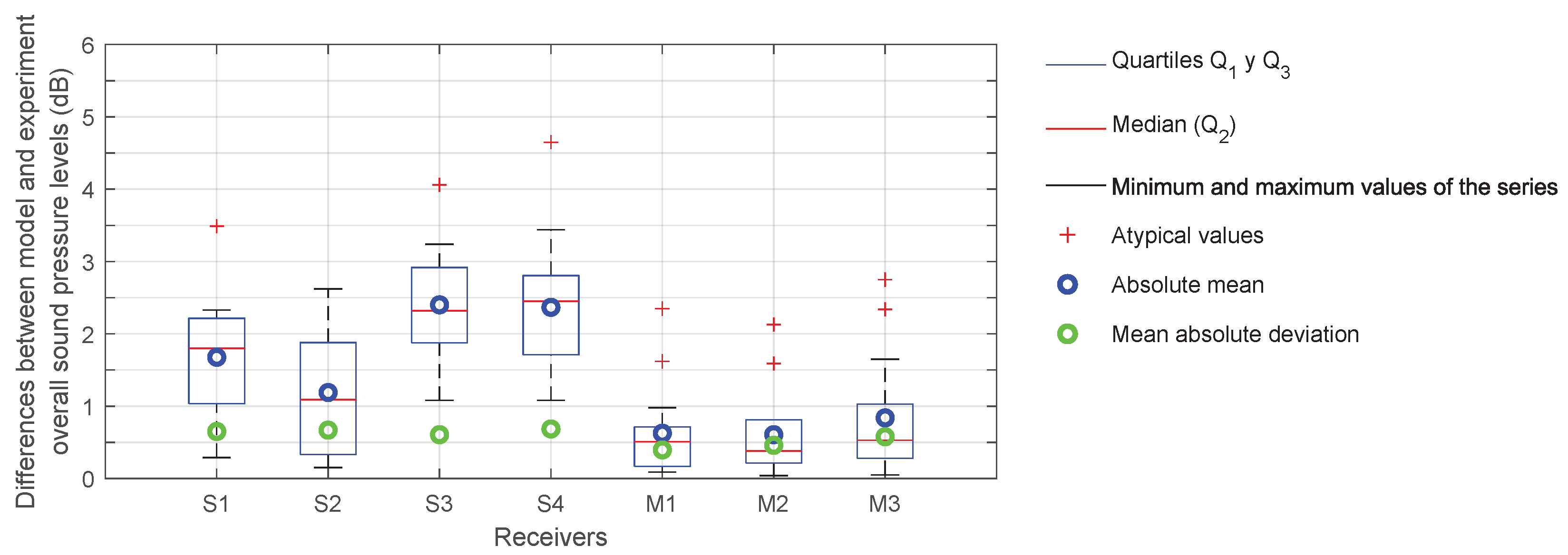
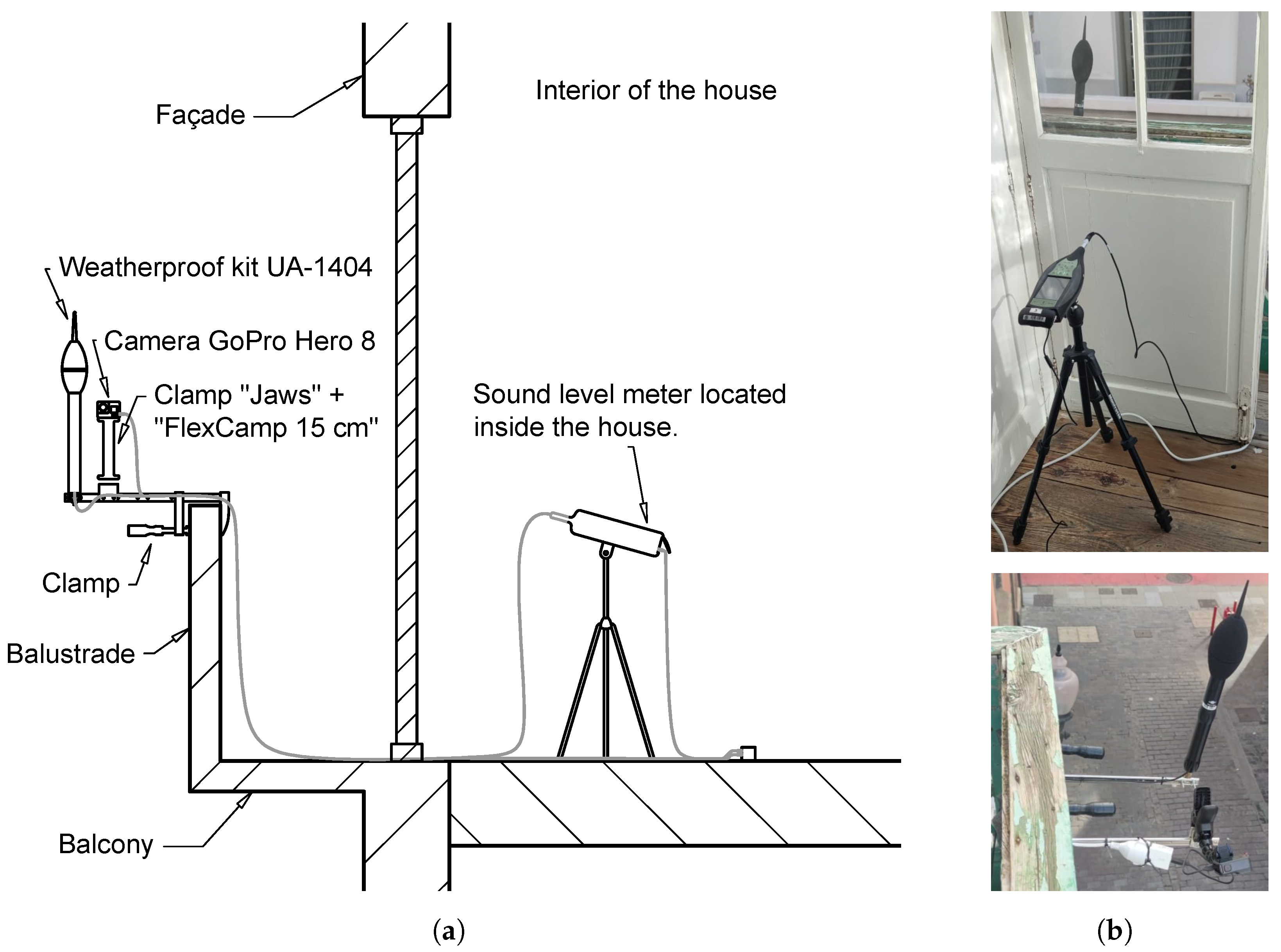
To verify this predictive model, several procedures for experimental data collection have been developed, both in controlled environments and in real scenarios using high-end commercial sound level meters and low-cost microphones to record sound pressure levels. Experimental measurements in controlled environments will be useful to calibrate the capabilities of the developed numerical model. In this case, the sources will consist of loudspeakers emitting noise of known intensity characteristics. To take measurements in real scenarios, two streets were selected in the city of Las Palmas de Gran Canaria (Canary Islands, Spain), where the geometry can be approximated to a Street Canyon and where the concentration of people is high and variable throughout the week. For this purpose, outdoor kits were manufactured that can be anchored to the façades and collect data over long periods of time. These kits consist of a microphone (connected to a sound level meter inside), an RGB-D camera and an anemometer. Self-developed software was used to process the recorded results (sound and image).
In the literature, contributions in line with this proposal are scarce. In relation to the problem that arises and also proposing indirect strategies to obtain estimates of noise levels, the work of Ballesteros et al. [
1] should be quoted. The authors present regression models for estimating the noise level produced by leisure activities in some streets of Madrid and Cuenca (Spain), using the number and type of businesses as variables. Likewise, the work of Genaro et al. [
13] is very relevant as it studies the use of ANNs to model the noise in twelve streets of the city of Granada (Spain), produced mainly by road traffic. More recently, another interesting contribution in line with the study of crowd density and its influence on the noise level in urban areas is that of Meng and Kang [
14], who study the influence of crowd density on the noise level in pedestrian streets where commercial activities take place, by measuring noise levels and taking photographs on streets in the city of Harbin (China). To determine the number of people per square metre, they used the photographs taken and a questionnaire seeking to study the frequency of visits to the commercial area that was given to pedestrians whilst measurements were being taken. They use a technique based on dividing the study area into grids to position pedestrians with respect to the measuring device. Along the same lines and which may also be of interest, there is another contribution by Meng et al. [
15] in which the effect of street markets on noise levels and acoustic perception is studied based on crowd density and street market zoning. Again, to determine the number of people per square metre, they use photographs. Finally, a fairly novel application is that of Elvas et al. [
16]. In this publication, night-time urban noise patterns in the city of Lisboa (Portugal) are analysed, and different areas are identified using GPS data from mobile phones.
However, the tools proposed to be developed in this line of work have a double objective: (1) to permit the evaluation of the acoustic levels based only on the visual information recorded by the cameras and whether these levels exceed the quality limits established by law or not, and (2) more importantly, to be used as simulation software that allows the incorporation and evaluation of some corrective measures.
The structure of this paper is as follows:
Section 2 provides a description of the mathematical problem posed, as well as the hypotheses considered. It also describes the mathematical basis of the model developed, the expression that solves the problem posed, the convergence accelerator that allows results to be obtained in an acceptable time, the mathematical modelling of the human voice spectrum and its intensity level adjustment. The Artificial Neural Network used to obtain crowd density from images is described in
Section 3. Finally, the two experiments carried out for the verification of the developed model are described in detail in
Section 4, which also describes the processing of the data collected during the experiments, their comparison with the values provided by the model and the results obtained.
2. Description of the Mathematical Model
2.1. Model Assumptions
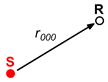
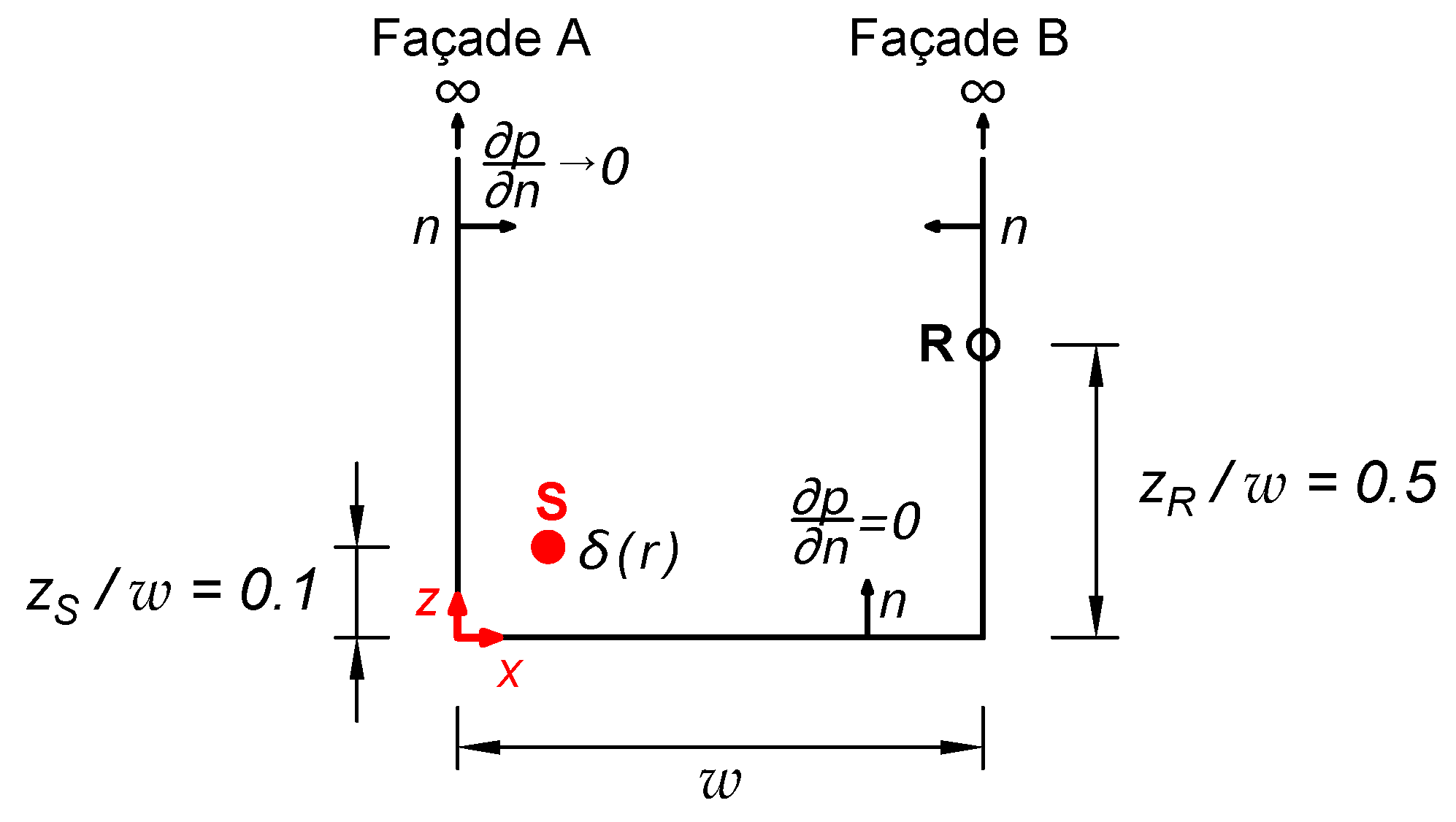
The problem that arises is to determine the sound pressure at a series of points (receivers) generated, in a real case, by people emitting sounds in a pedestrian street bounded by two vertical and parallel façades. In the mathematical model, people are represented by point sources emitting sounds with a spectrum similar to that of human speech in a domain bounded by three reflective boundaries (Street Canyon). The street has infinite height and length, and is of known width.
Figure 1 shows a representation of the real scenario posed in the problem.
The assumptions considered in the proposed mathematical model are listed below:
All surfaces, both façades and floors, are considered to be perfectly reflective surfaces.
Noise sources are considered omnidirectional. The Dirac delta function is used to model them mathematically. represents the intensity of the source; it is a function of frequency and shall be calibrated from a reference spectrum to be established for this purpose.
The sound propagation medium (air) shall be treated as a perfectly elastic and compressible continuous medium with negligible viscosity and isotropic behaviour.
The problem of acoustic wave propagation in environments not far from the noise source is studied. Thus, the propagation medium can be considered homogeneous.
The effects of wind on sound propagation are neglected (air at rest).
The disturbances produced by the sound propagation are small enough for the changes in pressure and density to be minimal compared with the values at rest.
The physical and mathematical formulation of the problem is approached from harmonic elastodynamics. As will be seen, in order to model a spectrum equivalent to that of a person talking, the spectrum of a theoretical A-weighted pink noise is used, to which the intensity level is adjusted as a function of the crowd density by means of a regression curve.
2.2. Basic Equations
The description of the mathematical model will begin by posing the wave equation in the frequency domain, which describes the propagation of acoustic waves in three dimensions. The wave equation can be stated in terms of any of the acoustic variables: pressure, density and displacement or velocity. For this work, pressure is taken as the dependent variable. Thus, the equation governing the propagation of harmonic acoustic waves is (Helmholtz equation).
where
∇ is the divergence operator in 3D problems: ;
p is the sound pressure at any point;
The constant
is defined as the wave number. Where, in turn,
is the angular frequency,
f is the frequency in Hz and
c represents the wave propagation speed. It will depend on the thermodynamic characteristics of the medium (temperature, pressure and density) and define the elastic properties of the fluid. For a temperature of 20 °C,
c will have a value of 343.5 m/s [
17];
The Dirac delta function is related to the presence of internal harmonic point pressure sources with a time variation of the type of .
To integrate and obtain a solution to the governing Equation (
1), it is necessary to impose boundary conditions. In the proposed model, façades and ground are considered perfectly reflecting, which can be described mathematically in terms of the pressure flux on those boundaries as follows:
The solution must verify the equation governing the propagation of acoustic waves in a homogeneous, non-viscous and linear medium in the frequency domain (
1) and also fulfil the conditions imposed on the boundaries of the domain under study (
2).
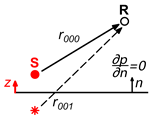
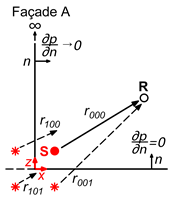
Back to the problem at hand, the sound pressure at any point
in a Street Canyon model caused by a source at a point
inside the model (Green Function) can be calculated using the image source method (
Figure 2).
The succession of image sources becomes infinite, but it allows us to obtain a solution to the Street Canyon model by which the sound pressure at any point between the façades can be written as follows (see, e.g., [
18]):
being:
obtaining
,
and
from:
where
w is the width of the Street Canyon and
the number of virtual image sources in the horizontal direction placed in such a way that the zero pressure flux (
2) on both façades and on the street ground can be verified simultaneously.
Other more straightforward solutions that can be particularised from Equation (
3) and that will be employed in other sections of the paper are as follows:
Solution for a free-field model, where no reflective surfaces are present:
![Sensors 25 03604 i001]() | | (6) |
![Sensors 25 03604 i002]() | | (7) |
![Sensors 25 03604 i003]() | | (8) |
2.3. Convergence Accelerator
The generated series for the Street Canyon solution has a very slow (sublinear) convergence speed, so accelerator algorithms are used to reduce the computation time of
to a manageable time. The Aitken–Shanks
algorithm is applied [
19,
20]. This procedure makes it possible to transform the original series into an equivalent series with a higher convergence speed. For the problem under consideration, when compared with other series acceleration techniques (see, e.g., [
21]), this transformation was chosen because it leads to a very simple algorithm with an acceptable precision and computational cost. As is well known, the Aitken–Shanks transformation can be applied successively and an almost linear convergence can be achieved.
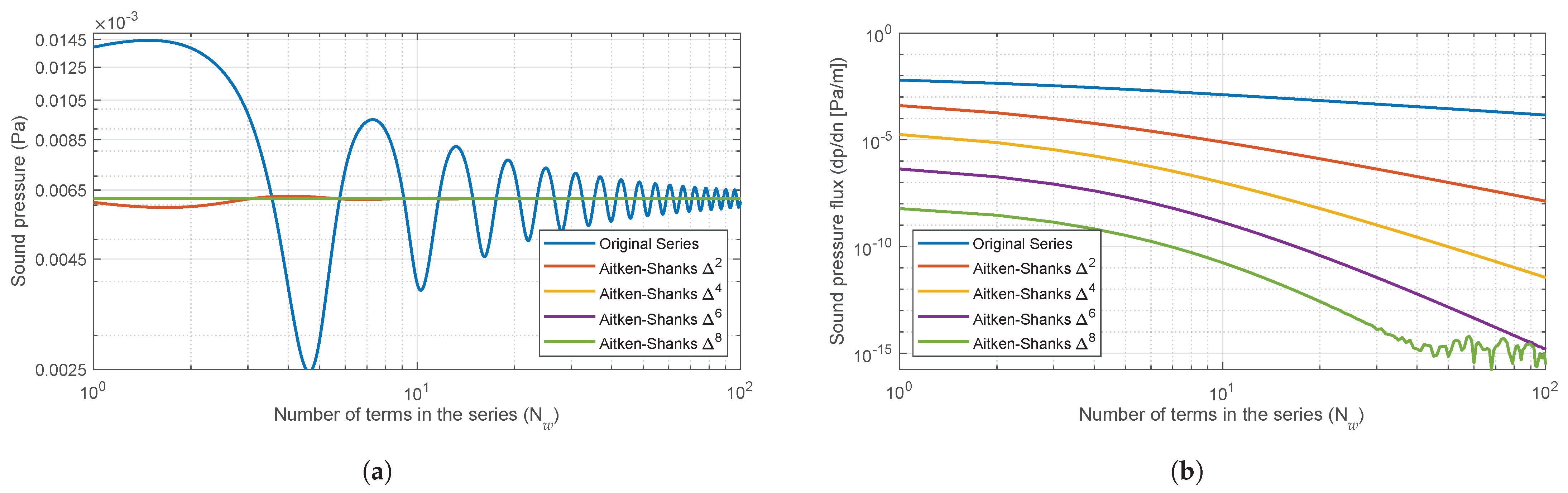
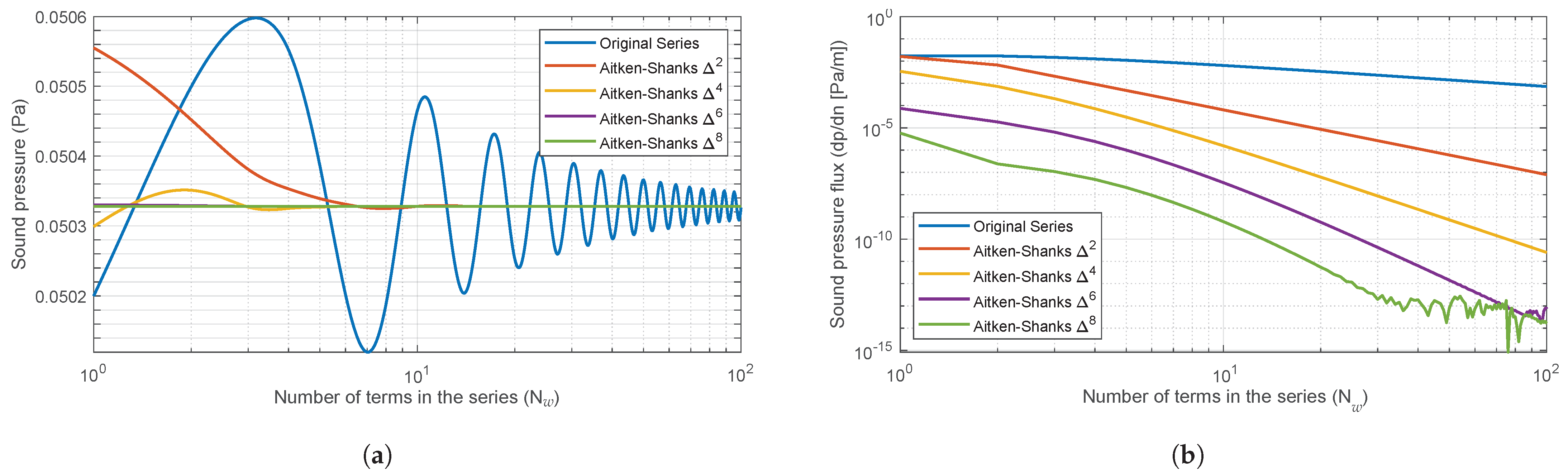
To determine the order of the transform and the number of terms
of the optimal series, an exhaustive study of the Aitken–Shanks method
,
,
and
was carried out for a wide range of
w values (
is the wavelength) and relative positions of source and receiver, as can be seen in
Figure 3. To visualise the behaviour of these transforms, some of the results for two values of
w are shown in terms of the sound pressure and its Normal derivative at the façade contour (
Figure 4 and
Figure 5), which must have a value of zero.
It can be observed that as the frequency increases, the transforms become increasingly unstable with a decreasing number of terms in the series. In order to prevent the convergence of the model from becoming unstable, 50 terms of the Aitken–Shanks series transformation will be used. This approach ensures that the model converges in a perfectly admissible time frame and that the resulting errors are consistently smaller than .
2.4. Calibration of Model Point Sources and Procedure to Obtain Sound Pressure Level
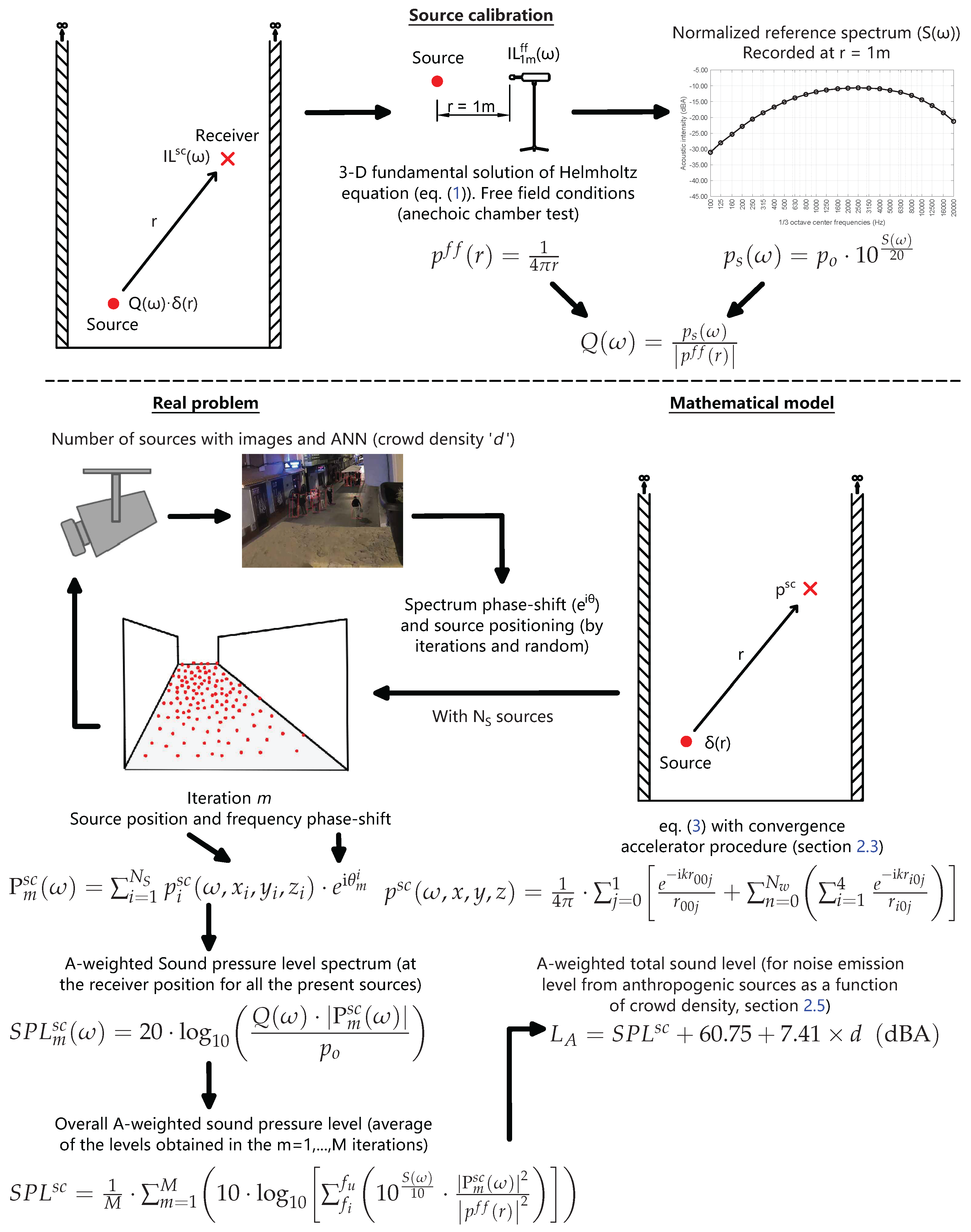
This section describes the mathematical procedure used to calibrate the noise spectrum of the sources within the model and to obtain the sound level at any point from that reference spectrum. To enhance comprehension of the procedure,
Figure 6 graphically describes the calibration process and the calculation of the final sound level.
In the figure,
represents the reference spectrum employed, recorded in decibels (dBA), at a distance of 1 m from the source and with free-field conditions. It is necessary to obtain it in terms of sound pressure
, with the reference pressure for this conversion being the human hearing threshold (
Pa). The calibration factor, denoted here by
and calculated under free-field conditions, Equation (
6) for the general case (fundamental solution), can obviously be calculated with other boundary conditions that will depend on the experimental constraints under which the reference spectrum available for the problem to be simulated can be recorded.
For a given degree of crowd density (the number of point sources), the sound pressure level at the observation point (the receiver) is obtained by combining the sound pressure values, calculated for each source from this calibration and the corresponding Green Function . The value obtained is subjected to slight variation depending on the precise position of each source in relation to the receiver and the phase shift between the spectra emitted by each, with these effects being more pronounced for a smaller number of sources. It is important to note that the number of sources is calculated from crowd density data obtained from images captured at regular intervals. Given that the exact position of each source in a given area is uncertain and changes with time, the determination of the noise level using this model is performed via the calculation of the mean value from a Monte Carlo simulation. The simulation involves random positioning of the sources within the occupied area and incorporates random phase shifting between the noise spectra of each source. The sound spectrum level recorded at the observation point for the calculation iteration m, in terms of spectral density and in dBA, is designated as . The normalised average equivalent sound pressure level is denoted by , and it represents the average of the combinations of sound pressure levels obtained for each frequency and for each iteration in the usual way. The initial and final frequencies of the frequency range, designated by and , respectively, are also employed in this context.
2.5. Definition of Anthropogenic Noise Spectrum
A significant source of uncertainty in attempting to solve the proposed problem is the identification of the emission spectrum exhibited by individuals during conversation or leisure activities. One of the most frequently utilised standards is the ANSI S3.5-1997 [
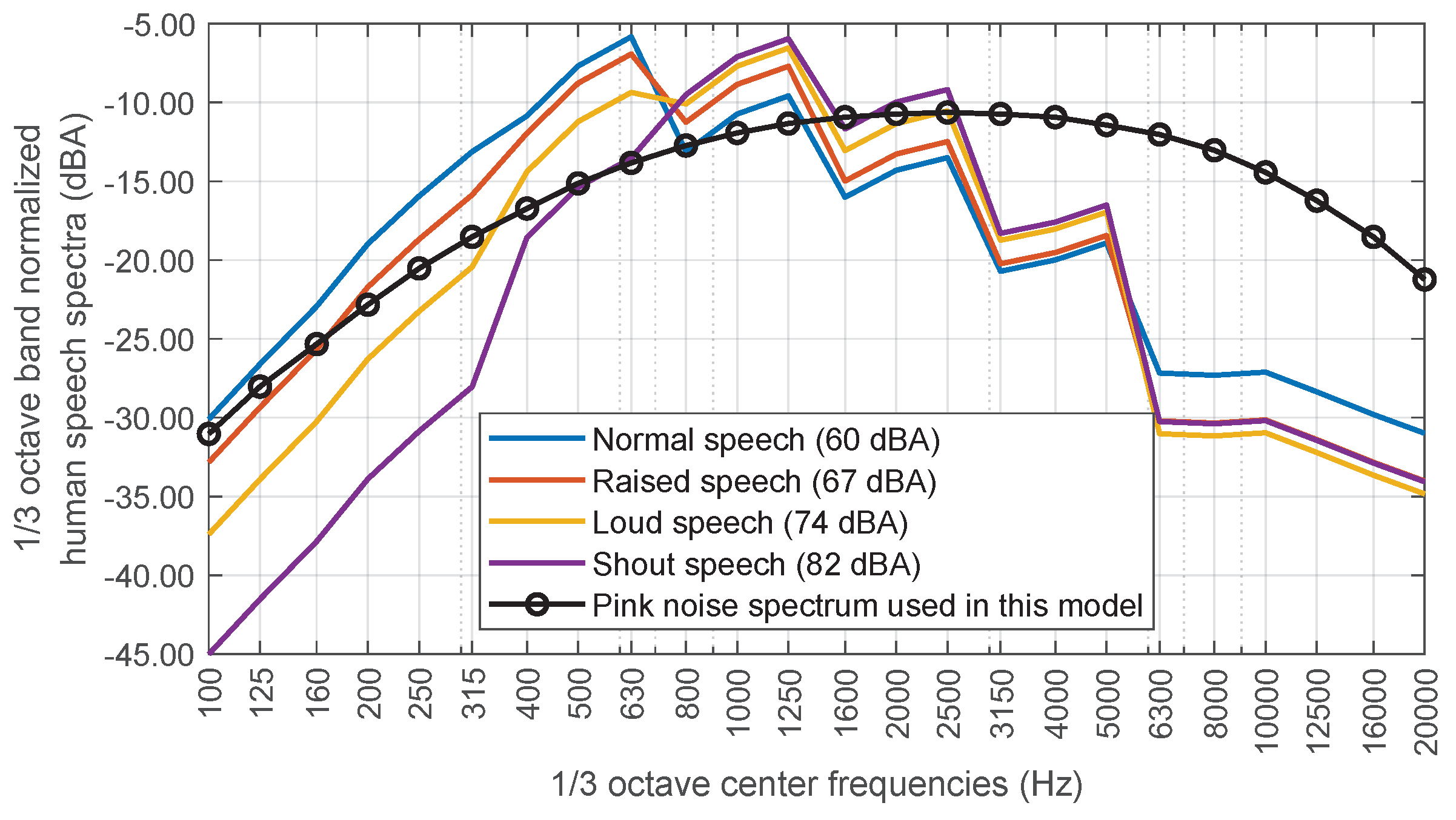
22] that provides a series of standardised spectra that simulate the sound emitted by people during a conversation with four levels of acoustic intensity: “Normal”, “Raised”, “Loud” and “Shout”.
However, for the sake of simplicity, a theoretical A-weighted pink noise spectrum is used to represent the frequency content of the human voice. The original ANSI spectra are given in SPL [dB] for octave frequencies. Thus, in order to compare the proposed spectrum to the ANSI spectra, the latter must be interpolated at one-third octave frequencies and then the A-weighting applied. In
Figure 7, the A-weighted spectrum used and the modified ANSI spectra are shown, where all of them have been normalised to 0 dBA. It is shown that they are reasonably similar.
The key question at this point, and one of the major uncertainties of the proposed model, is to quantify the sound intensity level of the sources in order to reproduce a real anthropogenic noise problem. As already advanced in the previous section, the source sound intensity level was established in this study as usual: a single source emitting in a free field and measured at 1 m. In the literature, the existing information about human sound sources does not go beyond the spectra and sound levels provided by the usual application standards for different discrete speech levels of a single human voice: Normal (60 dBA), Raised (67 dBA), Loud (74 dBA) and Shout (82 dBA). When people are involved in a social activity, the speech level of each person is difficult to establish. Each person decides to speak at a given speech level depending on the context. Somehow, each person adapts the speak level to the environment in order to convey an intelligible message by considering aspects such as the number of listeners (which are silent), distance to listeners, background type and level of noise, the type of social activity (leisure, academic, work, etcetera), age, culture, language and so on. The number of factors affecting the speech level is large, difficult to establish and difficult to quantify, mainly because, in the end, it is a social activity. In this work, the authors are only concerned with leisure activities on pedestrian Street Canyons, where people are relatively homogenous as sound sources and two factors affecting the sources are relatively easy to measure: the surface area and the number of people in this surface area.
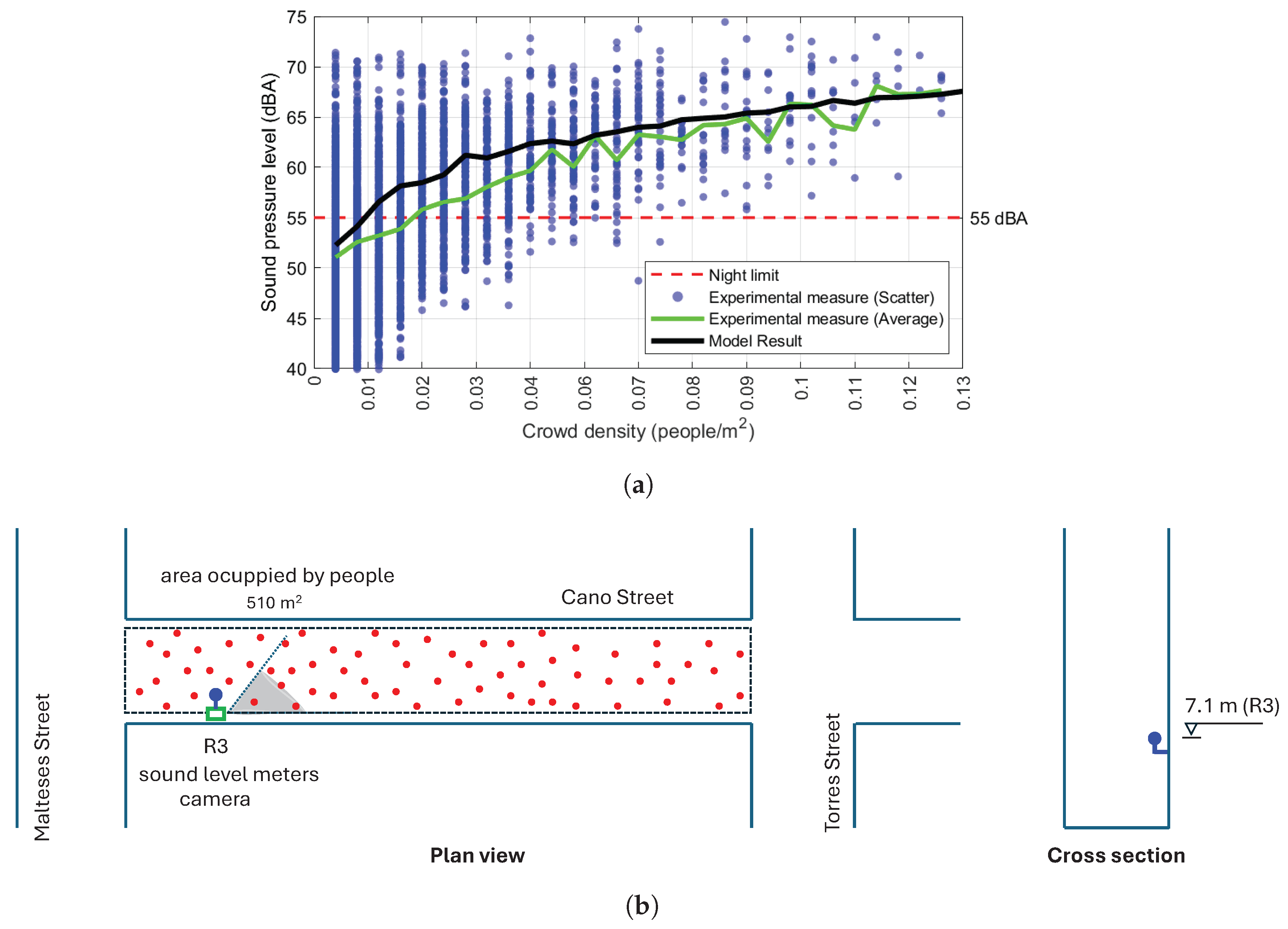
Taking all of this into account, the following working hypothesis is proposed: the sound intensity level of a human source is a function of the density of the people in the street. It is reasonable to think that people, to make their conversation intelligible, raise the level of their speech some decibels above the background sound level, which can be related to the density of people as long as all the people are involved in the same activity.
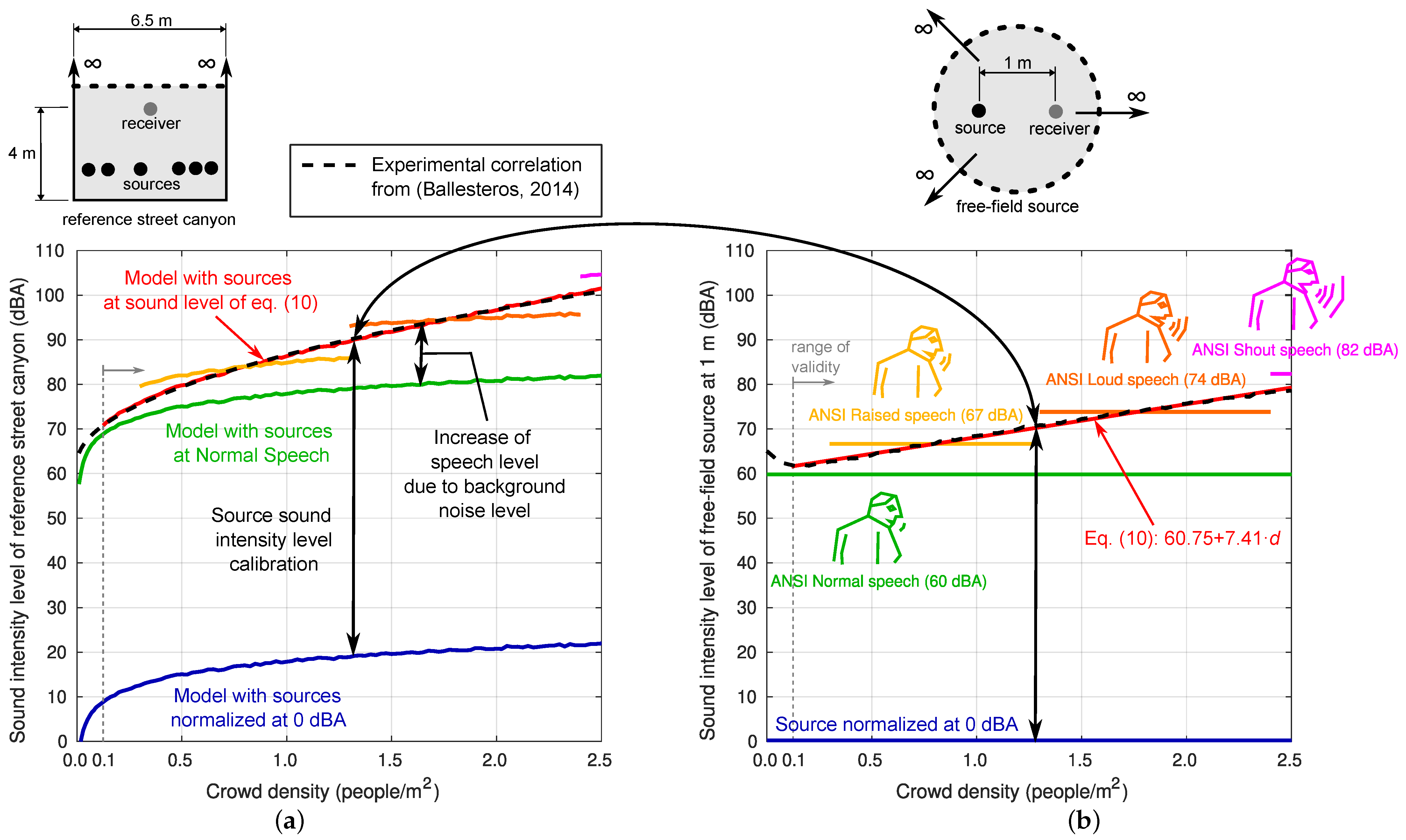
In this work, a simple fitting procedure is proposed by solving the inverse problem using experimental information available in a few published papers. In this sense, some results presented by Ballesteros et al. [
1] are very well adapted to this task. These authors present a regression equation on experimental data that allows obtaining the sound level from the crowd density in a wide range of values of this variable and in a street that can be well adapted to the Street Canyon model proposed. This regression equation is as follows (
Figure 8a):
where
is the continuous equivalent sound level in dBA and
d is the density of people per square metre. These authors clarify that this regression curve was obtained from data taken experimentally in a specific street in the city of Cuenca, Spain (Dr. Galindez Street) with a significant number of leisure places. The dimensions of this street (
w = 6.5 m) and the height of the receiver for which the measurement is taken (
h = 4.0 m) are known.
The procedure is explained graphically in the
Figure 8. On the left-hand side of the figure, results concerning the reference Street Canyon of 6.5 m width are shown. Different relationships between the sound intensity level (dBA) measured at 4 m height produced by a variable density of people per square metre are shown. For now, note only that the black dashed line corresponds to the reference correlation experimentally obtained in Ballesteros et al. [
1]. This empirical correlation contains a statistical measure of all the factors described above regarding the human sound sources behaviour, and also the sound propagation phenomena within the urban canyon (the street width and receiver and sources position).
On the right-hand side of the figure, different theoretical sound intensity levels of an A-weighted pink noise sound source in free-field conditions at 1 m,
, are shown. The blue line shows a source normalised at 0 dBA, with no dependency of the crowd density. The blue line on the left-hand side of the figure shows results with the reference Street Canyon model if such a source is used. For these results, at each crowd density level, the average of 30 iterations performed by randomly distributing the sources in the occupied zone and including a random phase-shifted value in their emission spectra is taken. The observed dependency between the sound intensity level and the crowd density is only due to the number and position of sources. An increase in the sound intensity level of each source in, e.g., 10 dBA, implies an increase in the same value of the sound intensity level measured at the receiver for all crowd densities. An increase of 60 dBA of the sound intensity level of each source leads to the green lines shown on the right-hand and left-hand sides of the figure. In this case, the sound intensity level of each source is similar to the ANSI Normal speech. It is observed that the prediction of the model if all sources are emitting at “ANSI normal speech” for all crowd densities greatly differs from the experimental results. Experimental results can be explained by the model only if the sound intensity level of each source linearly increases as the crowd density increases. By fitting the difference between Ballesteros et al.’s [
1] correlation (the black dashed lines) and the model prediction with 0 dBA sources (the blue solid line), the following linear regression with a coefficient of determination
is obtained:
which is valid for
people/m
2. This type of source (the red solid line) now responds to the crowd density (the background noise) by linearly increasing the sound intensity level, and the experimental results are accurately predicted by the model. It is an interesting, simple, consistent and practical conclusion that can generally be applied to characterise the behaviour of anthropogenic sources in problems of this type.
In any case, before concluding, it is important to point out that, although in this model all sources are omnidirectional, in reality this is not entirely true in the problem we are studying. For “normal” speech levels and frequencies below 1 kHz, a person can be regarded as a practically omnidirectional source in all three dimensions [
23,
24]. At overall sound pressure levels, the vertical plane (2D) does exhibit some degree of directionality, though the differences are less than 10 dBA [
25]. In the horizontal plane, however, there is minimal directionality. At higher levels (“loud speech”), there appears to be a slight increase in the directionality of the sound, as evidenced by the findings of [
23,
25].
2.6. Effect of Trapped Modes of Street Canyon Model in the Intensity Noise Level Prediction
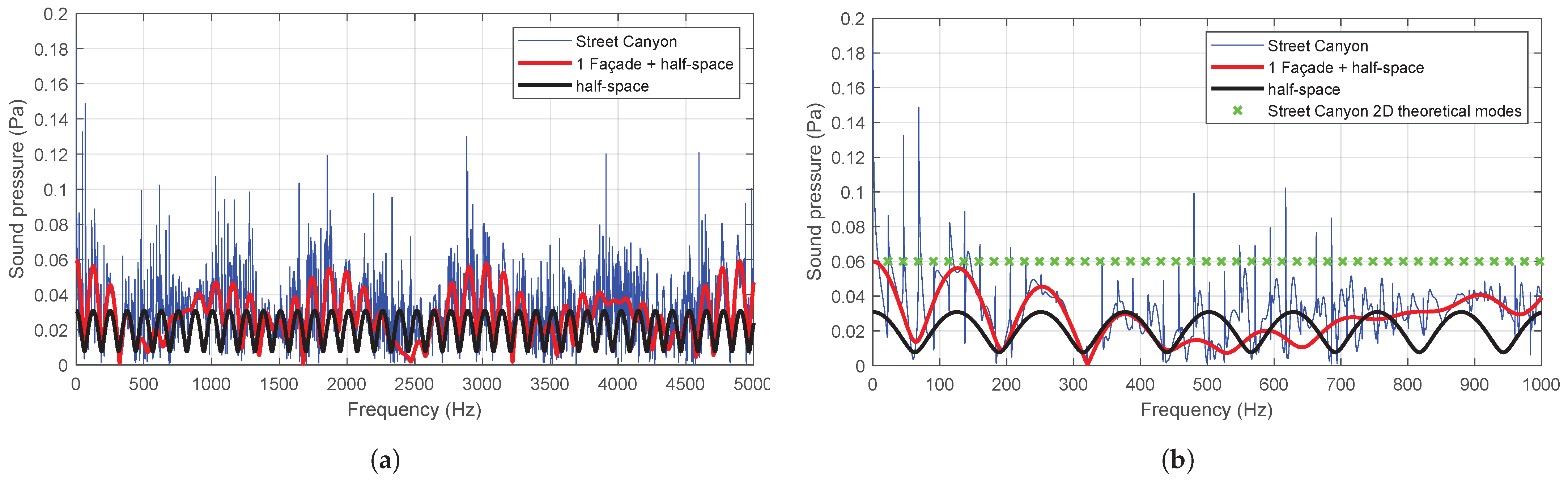
In this problem, the classical effect of the existence of natural frequencies and eigenmodes is observed as a consequence of the presence of reflective surfaces. These discrete modes represent an acoustic resonance and are often called “trapped modes” [
26], and it is therefore necessary to analyse the extent to which these modes can alter the calculation of the overall sound pressure level, bearing in mind that it is usual to calculate it on the basis of one-third octave bands spectra. In this way, the behaviour in each band can be characterised through its characteristic frequency. However, this approach inevitably entails a loss of information. Therefore, the aforementioned spectrum will be employed as the emission spectrum of the sources in a spectral density analysis with the numerical model, using a bandwidth of 1 Hz. Furthermore, this procedure allows for the acquisition of the spectrum in one-third octave bands, and to use their centre frequencies as characteristics of the model response. This enables the full range of information and responses to be captured in each vibration mode. The occurrence of these natural frequencies is illustrated in
Figure 9. It should be noted that
Figure 9b, which has been magnified for clarity, illustrates the horizontal theoretical modes of a Street Canyon (
n·c/
2·w).
However, the presence of multiple sources, the randomness of their arrangement, the use of phase-shifted frequencies between them and the evaluation over a high number of computational iterations result in very similar average responses.
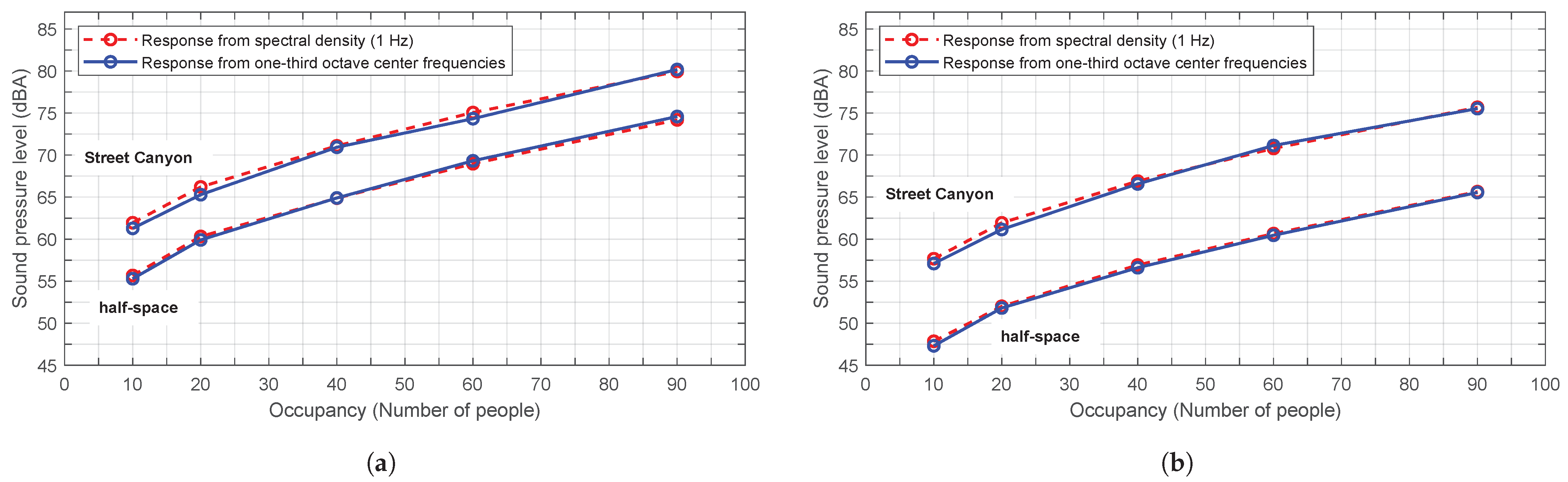
Figure 10 illustrates the response of the numerical model to the simulation of a street of
m width, with two receivers placed in different positions at a height of 5 m and 15 m, respectively. The sound pressure level is obtained for 10, 20, 40, 60 and 90 people distributed in a
m
2 area, using spectral density and one-third octave bands for both the Street Canyon model and the half-space model. The results presented here are the average of 10 computational iterations, each with a random arrangement and phase shift.
It can be inferred that the specific treatment of this problem, in averages, does not significantly differ whether it is conducted in one-third octave bands or from the spectral density, and trapped modes are of little relevance.
3. Crowd Density Estimation from Computer Vision
An ANN capable of detecting people in images [
27] is employed to obtain the crowd density. The system is fed with images captured by a network of cameras that periodically photograph the areas under study.
The ANN used in this work, the Ultralytics YOLOv8 model [
28], is based in the original single stage detector architectures described by Joseph Redmon and Ali Farhadi at the University of Washington [
29,
30,
31]. It is a real-time image segmentation and object detection model based on deep learning and computer vision. Among the object detection architectures compared, it demonstrates a high level of performance and exhibits considerable versatility with respect to the hardware platform and operating system employed. We adopted the pre-trained medium model for the detection of people in images.
About the general performance of the YOLOv8 object detection model, in the case of the class “person”, the mean average precision from Intersection over Union (IoU) thresholds of 0.5 to 0.95 (mAP50-95) on the Ultralytics COCO validation dataset [
32] exceeds 70% [
33]. The IoU parameter is a metric used to quantify the accuracy with which a predicted boundary, such as a bounding box in object detection, matches the real boundary of an object. In essence, the IoU measures the degree of overlap between the predicted and true areas, providing a simple but effective metric for evaluating the performance of localisation algorithms [
34].
In low-light conditions, the performance of the YOLO architecture, even without adaptation, maintains mAP values close to 70% (see, e.g., [
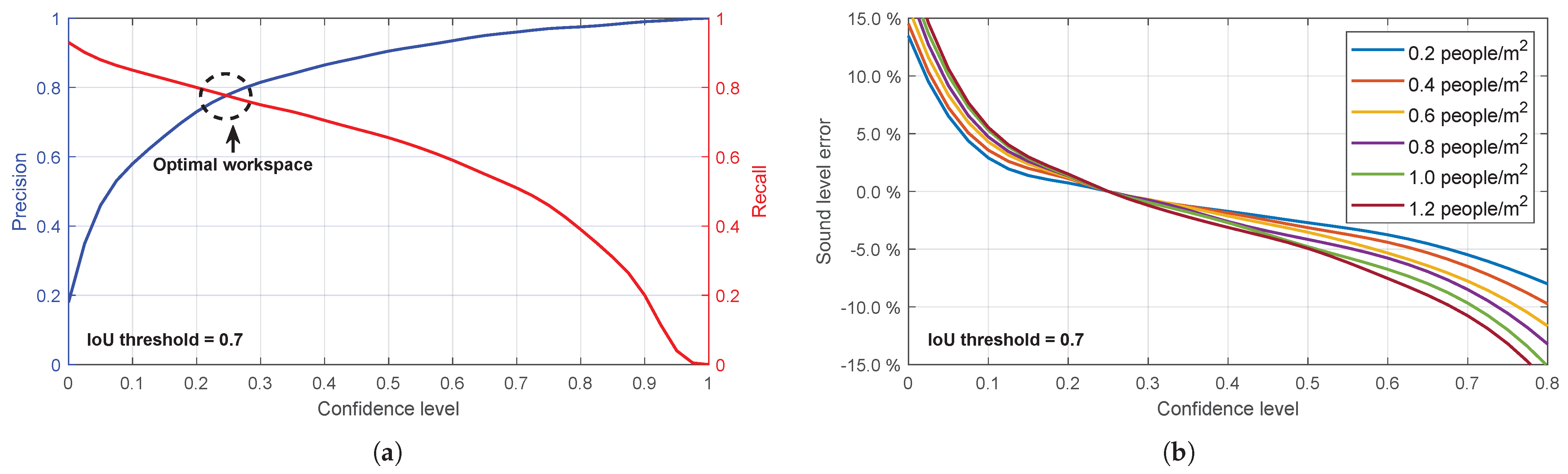
35]). These metrics, while informative, are obtained for varying confidence thresholds. However, for practical use as intended, it is necessary to determine the most appropriate value for this parameter. For this purpose, precision–recall curves for different confidence levels are extracted from YOLO (
Figure 11a).
It is easy to see that the confidence level value that reports people counting closest to the real value should be between 0.2 and 0.3. In this interval, False Negatives and False Positives in the verification process eventually compensate each other. However, in this work, a series of tests are performed in each scenario, and the conclusion is that a confidence level of about 0.2, although apparently somewhat low, is the best to adjust the response of this ANN. The number of images analysed for this task exceeds three hundred, randomly selected from the images captured during the measurement campaign on Sargento Llagas Street, in which the images were captured with a one-minute time step. Throughout this process, the default value of IoU = 0.7 is adopted.
At this point, it is also interesting to analyse the influence that eventually errors in the detection of people have on the response of the proposed acoustic model.
Figure 11b aims to show this sensitivity as a function of the confidence threshold used by the detection tool. It represents the error made in the sound intensity level reported by the numerical acoustic model for different values of the crowd density predicted by YOLOv8 and the one that eventually exists in reality depending on this confidence threshold. The difference between both values will be higher for confidence levels outside the mentioned interval (0.2–0.3), but always within a margin of less than 15% even in the most extreme assumptions. This is an interesting fact that allows us to calibrate the utility margins of the procedure for this application.
Figure 12 illustrates an example of the manner in which the network presents the outcomes of the people detection process. In the processed images, the labels indicating the results of the detection process (the classification of the detected object and confidence level) were deactivated. In addition to the images displaying the detected persons, the network returns a text file for each processed image, wherein all the information necessary to calculate the parameters characterizing the crowd is displayed: the number of people, position in image coordinates (the bounding box) and density according to each occupied area.
In line with the proposal made in this paper and also using YOLO, at this point, it is worth mentioning the work published by Fredianelli et al. [
36], which orients this tool to the recognition and counting of vehicles according to the requirements of the CNOSSOS-EU noise assessment model. Regarding the previous experience of the group in the use of this software, the YOLO people detector (specifically YOLOv8) has already been used by some of the authors of this paper integrated with the ByteTrack people tracker [
37] to detect individuals in challenging scenarios, such as trail races, in re-identification tasks [
38,
39]. In these scenarios, people detection is particularly challenging due to cluttered backgrounds and difficult lighting conditions, including night-time illumination.
5. Conclusions and Future Research Directions
This paper proposes a strategy designed to predict the level of noise produced by crowds of people that is not based on direct measurement using sound level meters, but on an indirect procedure that makes use of computer vision and artificial intelligence techniques. This proposal is based on the development and verification of two interconnected tools: (1) a procedure that uses images to determine the density and distribution of the crowd in pedestrian streets, and (2) a numerical model that uses this information and the urban geometry to efficiently calculate the noise level at any point in the analysis area. If this were possible with an infrastructure that in many cases already exists for another use (security systems and cameras), it would also be possible to obtain an estimate of the level of noise pollution in a given area of the city. In particular, it presents the basis of this strategy and an initial mathematical model to address the problem in a simplified real situation. All the essential aspects of the procedure are described, as well as an experimental validation at two levels that allows us to limit some of the uncertainties inherent to this phenomenon: (1) a laboratory validation using noise sources with controlled emission spectra, and (2) validation in a real situation of anthropogenic noise in two streets of the city of Las Palmas de Gran Canaria, Canary Islands, Spain. The main conclusions that the reader can draw from this work at this stage are the following: (1) the proposed procedure is simple and the tools and models are easily accessible, and (2) although the results are very preliminary, the experimental validation allows the conclusion to be reached that this strategy is able to satisfy the proposed objective with a more than acceptable accuracy in a situation where the main source of noise is of anthropogenic origin. It is true that it is necessary to extend the measurement campaign to other streets and at other times in order to validate the behaviour of the model (image processing and noise evaluation) at higher occupancy levels.
As for future research directions, these are mainly related to the development and evolution of the mathematical model of acoustic propagation:
Incorporate boundary conditions into the Street Canyon model to simulate the absorptive capacity of the façades or the diffuse nature of the acoustic field in their vicinity resulting from successive diffractions/reflections produced by the façade elements [
12].
Represent the acoustic field infiltrating the interior of homes through open (or half-open) windows in the façades. In this case, it is proposed to generalise the presented solution of the Street Canyon to the interior problem and to couple both regions in a 3D code based on the Boundary Element Method (BEM) previously developed by some of the authors (MultiFEBE, [
45]).
Extend the numerical model to represent a significant part of the affected urban grid, including all streets (crowd-occupied or not) and their actual geometry. Performing this task by proposing a completely realistic frequency domain 3D numerical model is virtually unfeasible (the frequency range analysed, the speed of sound propagation in air and the dimensions of the area to be treated). Using the BEM as a numerical strategy, the authors propose to develop a dimensionally simpler model using 2.5D techniques that reduce the problem to two dimensions without losing its 3D character (see, e.g., [
46]).
In line with previous work by the authors [
47], investigating the effectiveness of acoustic screens for this problem, from simple temporary and mobile solutions (see, e.g., [
48]) to elements permanently installed on windows and façades of affected buildings [
49].
All these tasks include the experimental validation of the resulting models as they are developed. From them, it will be possible to progressively adjust an increasingly accurate tool that permits the determination, in real time, of noise pollution levels from image processing alone. In addition to this use as a tool for noise level assessment in the direction initially proposed in this work, it is also intended that these numerical models, by themselves, will be useful as a versatile and general analysis software for the study of the problem. Therefore, it is also the aim of this work to make all the results and models available in open access for interested researchers.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}