

Closing the Domain Gap: Can Pseudo-Labels from Synthetic UAV Data Enable Real-World Flood Segmentation?



Abstract

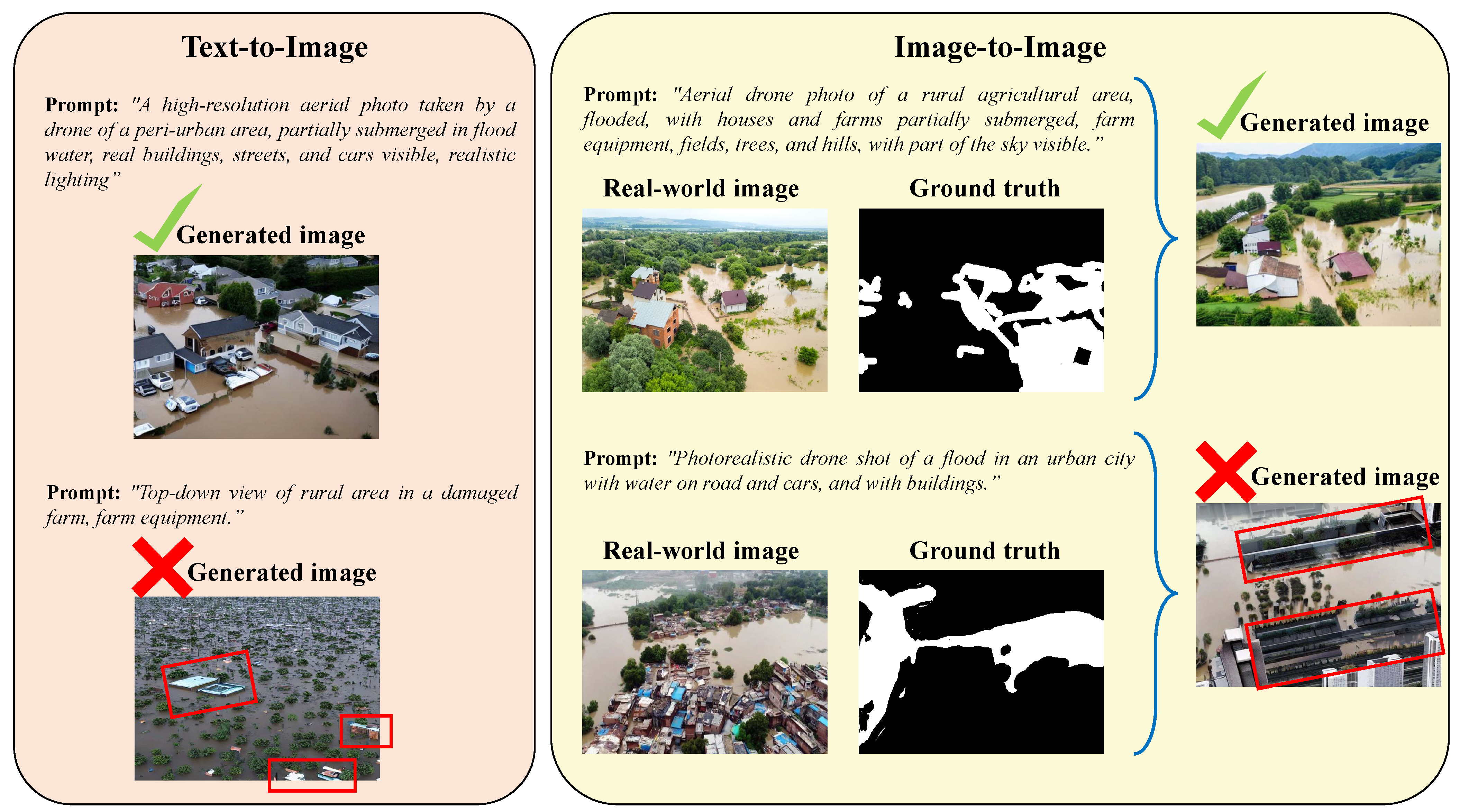
1. Introduction
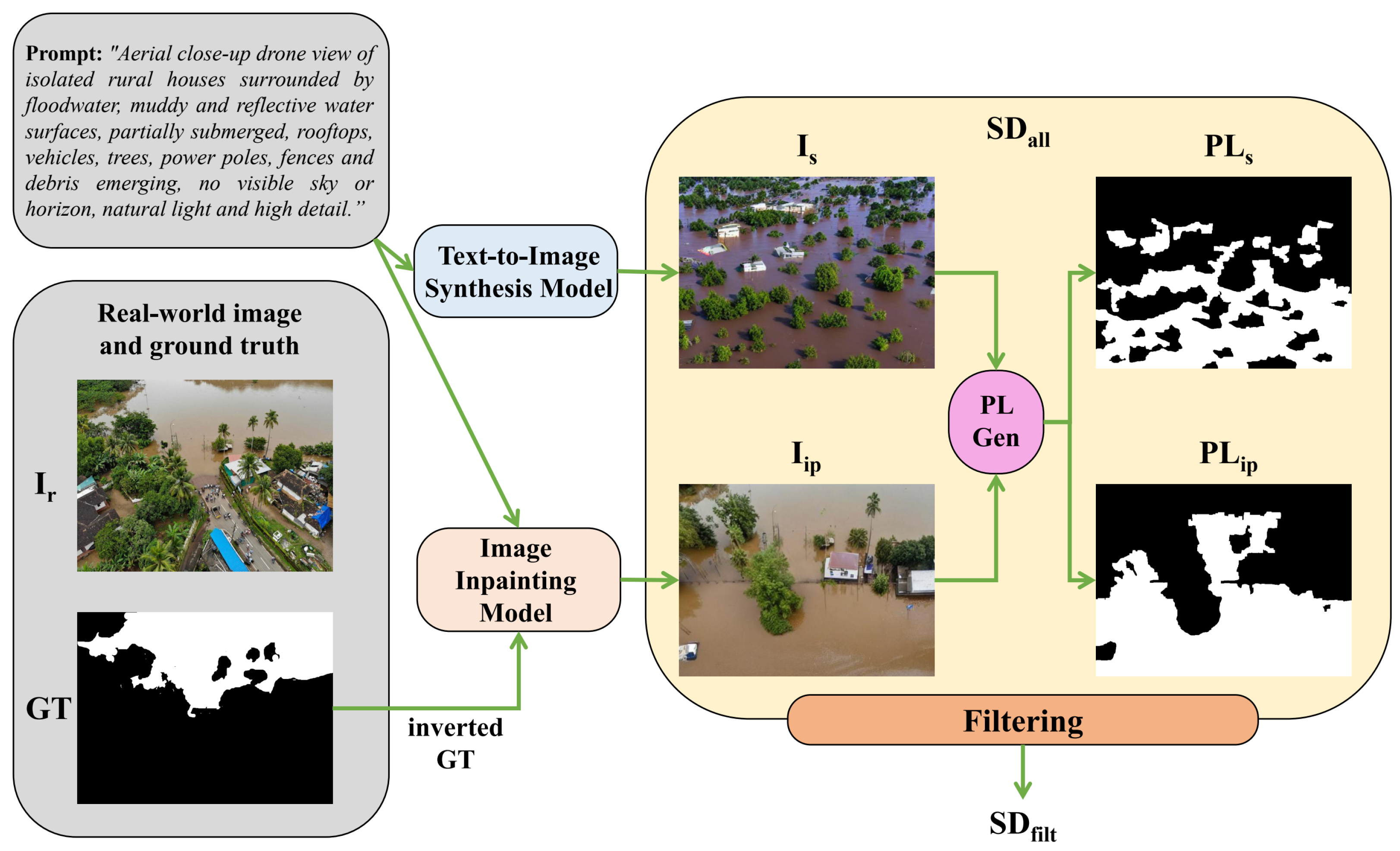
- We introduce, to the best of our knowledge, the first scalable pipeline for the unsupervised generation of synthetic aerial flood imagery, utilizing text-to-image diffusion models guided by semantically enriched prompts. To enable segmentation training without the need for manual annotation, we integrate an unsupervised pseudo-labeling approach [18], which automatically produces segmentation masks by exploiting the distinct color characteristics of floodwater and surrounding background elements.
- We demonstrate through extensive experiments with state-of-the-art flood segmentation models that models trained solely on filtered synthetic data achieve a performance close to real-data-trained models, with minor performance drops, and introduce an approach to combine real and synthetic data in order to boost performance.
- We systematically examine how the structure and semantics of text prompts affect the quality and realism of the generated flood imagery, identifying factors that influence scene consistency and visual fidelity.
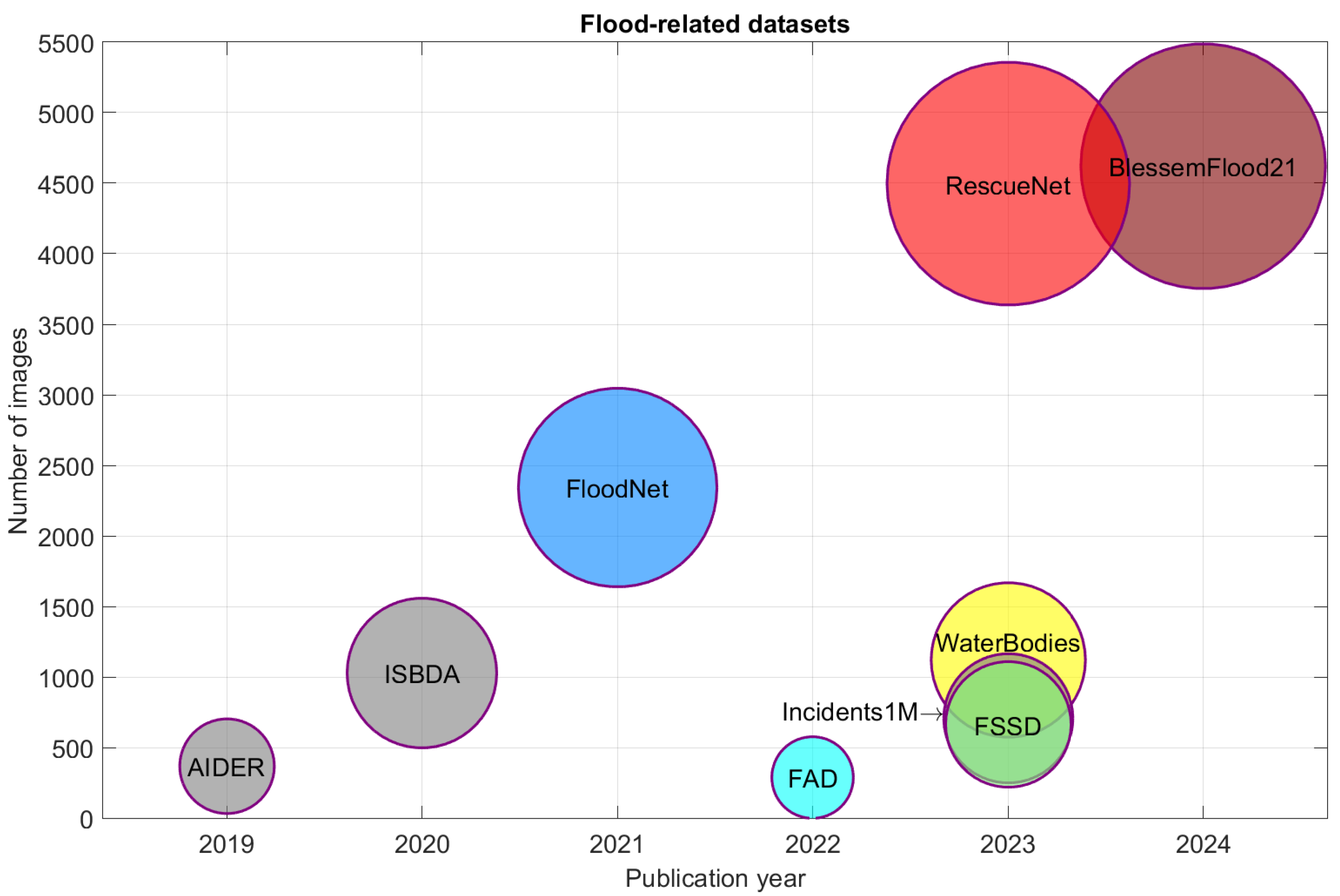
2. Related Work
3. Synthetic Dataset Generation Methodology
3.1. Text-to-Image Synthesis Component
- Rural vs. urban/peri-urban environment: The images were conditioned to represent either a rural or urban/peri-urban landscape.
- Sky presence: The synthesized images either included or excluded visible sky regions.
- Flooded and non-flooded buildings: We controlled the number of flooded buildings in the generated images to ensure a diverse range of flooding scenarios.
- “Aerial view of a flooded urban area with high-rise buildings and streets underwater."
- “Drone footage of a rural landscape with scattered houses, some affected by flooding, others dry.”
- “Low-altitude remotely sensed image depicting an urban neighborhood with partially submerged homes and roads.”
- “UAV view of a countryside area with a river overflow flooding nearby fields and farmhouses.”
3.2. Image Inpainting from Segmentation Masks Component
3.3. Post-Generation Filtering for Enhanced Dataset Fidelity
4. Experimental Setup
4.1. Datasets and Methods
4.2. Training Protocol
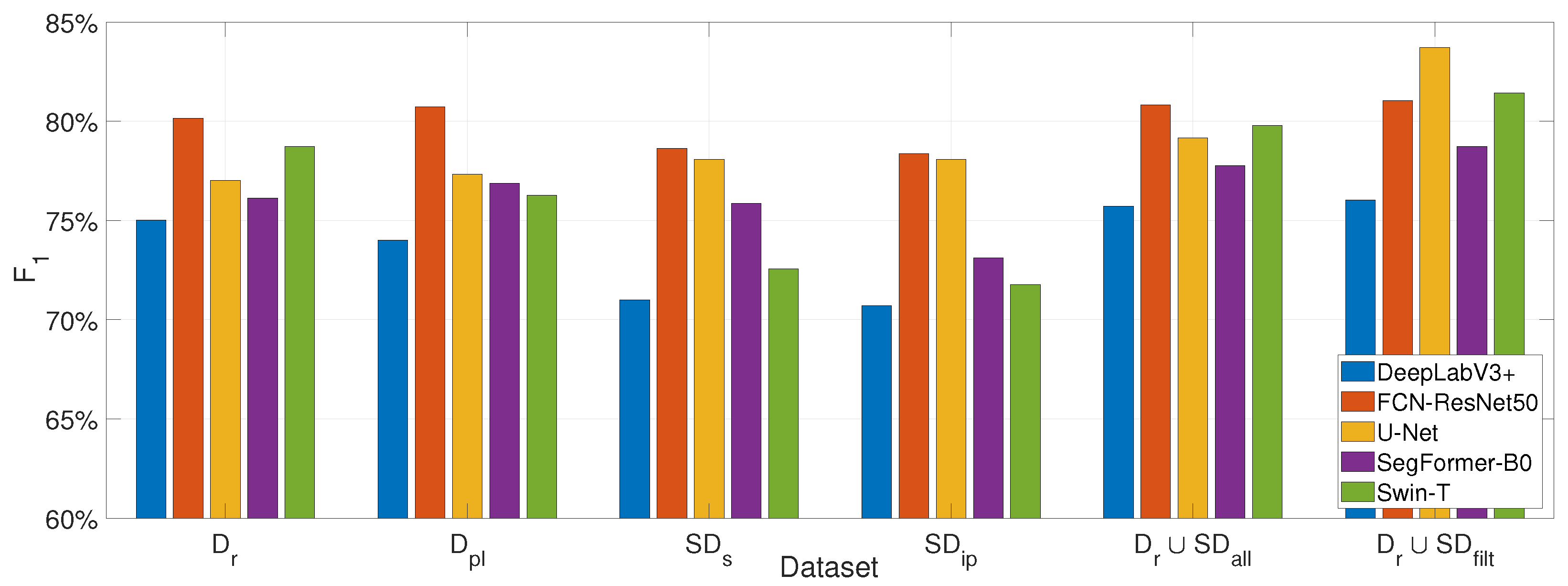
5. Experimental Results
5.1. Impact of Synthetic Data on Model Performance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 79.48 | 60.03 | 67.39 | 84.62 | 75.03 |
| Dpl | 78.03 | 58.75 | 65.04 | 85.85 | 74.01 |
| SDs | 76.48 | 55.02 | 64.47 | 78.97 | 70.99 |
| SDip | 74.54 | 54.70 | 60.85 | 84.42 | 70.72 |
| Dr ∪ SDall | 79.21 | 60.94 | 65.89 | 89.02 | 75.73 |
| Dr ∪ SDfilt | 79.55 | 61.34 | 66.34 | 89.06 | 76.04 |
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 83.60 | 66.90 | 71.65 | 90.98 | 80.16 |
| Dpl | 83.64 | 67.67 | 70.72 | 94.00 | 80.72 |
| SDs | 81.35 | 64.80 | 67.48 | 94.22 | 78.64 |
| SDip | 81.28 | 64.44 | 67.65 | 93.14 | 78.38 |
| Dr ∪ SDall | 83.74 | 67.82 | 70.84 | 94.09 | 80.83 |
| Dr ∪ SDfilt | 84.22 | 68.12 | 72.08 | 92.54 | 81.04 |
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 81.03 | 62.62 | 68.95 | 87.21 | 77.01 |
| Dpl | 80.33 | 63.04 | 66.65 | 92.07 | 77.33 |
| SDs | 81.45 | 64.04 | 68.56 | 90.68 | 78.08 |
| SDip | 81.11 | 64.04 | 67.63 | 92.34 | 78.08 |
| Dr ∪ SDall | 81.91 | 65.52 | 68.21 | 94.32 | 79.17 |
| Dr ∪ SDfilt | 86.97 | 72.00 | 76.85 | 91.94 | 83.72 |
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 78.40 | 61.47 | 63.70 | 94.61 | 76.14 |
| Dpl | 79.43 | 62.43 | 65.10 | 93.84 | 76.87 |
| SDs | 79.03 | 61.12 | 65.30 | 90.52 | 75.87 |
| SDip | 74.34 | 57.63 | 59.17 | 95.68 | 73.12 |
| Dr ∪ SDall | 80.13 | 63.61 | 65.66 | 95.33 | 77.76 |
| Dr ∪ SDfilt | 81.22 | 64.96 | 66.99 | 95.48 | 78.74 |
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 81.85 | 64.93 | 68.69 | 92.22 | 78.74 |
| Dpl | 81.24 | 61.66 | 70.72 | 82.80 | 76.28 |
| SDs | 78.67 | 56.94 | 68.27 | 77.43 | 72.57 |
| SDip | 77.11 | 55.98 | 65.16 | 79.90 | 71.78 |
| Dr ∪ SDall | 83.53 | 66.39 | 72.11 | 89.32 | 79.80 |
| Dr ∪ SDfilt | 84.88 | 68.69 | 73.66 | 91.06 | 81.44 |
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset (290 Images) | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 81.03 | 62.62 | 68.95 | 87.21 | 77.01 |
| 50% Dr ∪ 25% SDs ∪ 25% SDip | 81.28 | 64.30 | 67.82 | 92.53 | 78.27 |
5.2. Real and Synthetic Dataset Similarity, Role of Prompt Semantics in Dataset Quality
5.3. Ablation on Filtering Threshold
| Method | Thresh. Par. (k) | Filt. Imgs | Test Metrics | ||||
|---|---|---|---|---|---|---|---|
| Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) | |||
| DeepLabV3 | - | 0/580 | 79.21 | 60.94 | 65.89 | 89.02 | 75.73 |
| DeepLabV3 | 3 | 3/580 | 79.11 | 60.76 | 65.82 | 88.77 | 75.59 |
| DeepLabV3 | 2 | 23/580 | 78.68 | 59.69 | 65.73 | 86.67 | 74.76 |
| DeepLabV3 | 1.5 | 53/580 | 79.55 | 61.34 | 66.34 | 89.06 | 76.04 |
| FCN-ResNet50 | - | 0/580 | 83.74 | 67.82 | 70.84 | 94.09 | 80.83 |
| FCN-ResNet50 | 3 | 3/580 | 83.56 | 67.64 | 70.51 | 94.32 | 80.70 |
| FCN-ResNet50 | 2 | 23/580 | 82.85 | 66.90 | 69.27 | 95.14 | 80.17 |
| FCN-ResNet50 | 1.5 | 53/580 | 84.22 | 68.12 | 72.08 | 92.54 | 81.04 |
| U-Net | - | 0/580 | 81.91 | 65.52 | 68.21 | 94.32 | 79.17 |
| U-Net | 3 | 3/580 | 84.67 | 68.82 | 72.67 | 92.85 | 81.53 |
| U-Net | 2 | 23/580 | 87.57 | 72.83 | 78.17 | 91.42 | 84.28 |
| U-Net | 1.5 | 53/580 | 86.97 | 72.00 | 76.85 | 91.94 | 83.72 |
| SegFormer-B0 | - | 0/580 | 80.13 | 63.61 | 65.66 | 95.33 | 77.76 |
| SegFormer-B0 | 3 | 3/580 | 80.64 | 64.23 | 66.26 | 95.45 | 78.22 |
| SegFormer-B0 | 2 | 23/580 | 80.92 | 64.36 | 66.83 | 94.57 | 78.32 |
| SegFormer-B0 | 1.5 | 53/580 | 81.22 | 64.96 | 66.99 | 95.48 | 78.74 |
| Swin-T | - | 0/580 | 83.53 | 66.39 | 72.11 | 89.32 | 79.80 |
| Swin-T | 3 | 3/580 | 82.12 | 64.13 | 70.42 | 87.78 | 78.15 |
| Swin-T | 2 | 23/580 | 81.98 | 64.28 | 69.83 | 89.00 | 78.26 |
| Swin-T | 1.5 | 53/580 | 84.88 | 68.69 | 73.66 | 91.06 | 81.44 |
5.4. Qualitative Segmentation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADNet | Attentive Decoder Network |
| AI | Artificial Intelligence |
| ASPP | Atrous Spatial Pyramid Pooling |
| BiT | Bitemporal image Transformer |
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| DELTA | Deep Earth Learning, Tools, and Analysis |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| ENet | Efficient Neural Network |
| FAD | Flood Area Dataset |
| FCN | Fully Convolutional Network |
| FSSD | Flood Semantic Segmentation Dataset |
| GAN | Generative Adversarial Network |
| IoU | Intersection over Union |
| ML | Machine Learning |
| MMD | Maximum Mean Discrepancy |
| MRF | Markov Random Field |
| NDWI | Normalized Difference Water Index |
| PCA | Principal Component Analysis |
| PR | Pattern Recognition |
| ResNet | Residual Network |
| SAM | Segment Anything Model |
| SAR | Synthetic Aperture Radar |
| SegFormer | Segmentation Transformer |
| SSSS | Semi-Supervised Semantic Segmentation |
| UAV | Unmanned Aerial Vehicle |
| UPerNet | Unified Perceptual Parsing Network |
| VAE | Variational Autoencoder |
| WSSS | Weakly Supervised Semantic Segmentation |
References
- Ritchie, H.; Rosado, P. Natural Disasters. 2022. Available online: https://ourworldindata.org/natural-disasters (accessed on 16 April 2025).
- Algiriyage, N.; Prasanna, R.; Stock, K.; Doyle, E.E.; Johnston, D. Multi-source multimodal data and deep learning for disaster response: A systematic review. SN Comput. Sci. 2022, 3, 92. [Google Scholar] [CrossRef] [PubMed]
- Linardos, V.; Drakaki, M.; Tzionas, P.; Karnavas, Y.L. Machine learning in disaster management: Recent developments in methods and applications. Mach. Learn. Knowl. Extr. 2022, 4, 446–473. [Google Scholar] [CrossRef]
- Albahri, A.; Khaleel, Y.L.; Habeeb, M.A.; Ismael, R.D.; Hameed, Q.A.; Deveci, M.; Homod, R.Z.; Albahri, O.; Alamoodi, A.; Alzubaidi, L. A systematic review of trustworthy artificial intelligence applications in natural disasters. Comput. Electr. Eng. 2024, 118, 109409. [Google Scholar] [CrossRef]
- Bacharidis, K.; Moirogiorgou, K.; Koukiou, G.; Giakos, G.; Zervakis, M. Stereo System for Remote Monitoring of River Flows. Multimed. Tools Appl. 2018, 77, 9535–9566. [Google Scholar] [CrossRef]
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Deep learning methods for flood mapping: A review of existing applications and future research directions. Hydrol. Earth Syst. Sci. 2022, 26, 4345–4378. [Google Scholar] [CrossRef]
- Kyrkou, C.; Theocharides, T. Deep-Learning-Based Aerial Image Classification for Emergency Response Applications Using Unmanned Aerial Vehicles. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 517–525. [Google Scholar]
- Zhu, X.; Liang, J.; Hauptmann, A. MSNet: A Multilevel Instance Segmentation Network for Natural Disaster Damage Assessment in Aerial Videos. arXiv 2020, arXiv:2006.16479. [Google Scholar]
- Zhu, X.; Liang, J.; Hauptmann, A. Msnet: A multilevel instance segmentation network for natural disaster damage assessment in aerial videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 2023–2032. [Google Scholar]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Karim, F.; Sharma, K.; Barman, N.R. Flood Area Segmentation. Available online: https://www.kaggle.com/datasets/faizalkarim/flood-area-segmentation (accessed on 6 January 2025).
- Hänsch, R.; Arndt, J.; Lunga, D.; Gibb, M.; Pedelose, T.; Boedihardjo, A.; Petrie, D.; Bacastow, T.M. Spacenet 8-the detection of flooded roads and buildings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1472–1480. [Google Scholar]
- Yang, L. Flood Semantic Segmentation Dataset. Available online: https://www.kaggle.com/datasets/lihuayang111265/flood-semantic-segmentation-dataset (accessed on 6 January 2025).
- Wieland, M.; Martinis, S.; Kiefl, R.; Gstaiger, V. Semantic segmentation of water bodies in very high-resolution satellite and aerial images. Remote Sens. Environ. 2023, 287, 113452. [Google Scholar] [CrossRef]
- Weber, E.; Papadopoulos, D.P.; Lapedriza, A.; Ofli, F.; Imran, M.; Torralba, A. Incidents1M: A large-scale dataset of images with natural disasters, damage, and incidents. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4768–4781. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Murphy, R. RescueNet: A high resolution UAV semantic segmentation dataset for natural disaster damage assessment. Sci. Data 2023, 10, 913. [Google Scholar] [CrossRef]
- Polushko, V.; Jenal, A.; Bongartz, J.; Weber, I.; Hatic, D.; Rösch, R.; März, T.; Rauhut, M.; Weinmann, A. BlessemFlood21: A High-Resolution Georeferenced Dataset for Advanced Analysis of River Flood Scenarios; IEEE Access: New York, NY, USA, 2024. [Google Scholar]
- Simantiris, G.; Panagiotakis, C. Unsupervised Color-Based Flood Segmentation in UAV Imagery. Remote Sens. 2024, 16, 2126. [Google Scholar] [CrossRef]
- Dong, Z.; Liang, Z.; Wang, G.; Amankwah, S.O.Y.; Feng, D.; Wei, X.; Duan, Z. Mapping inundation extents in Poyang Lake area using Sentinel-1 data and transformer-based change detection method. J. Hydrol. 2023, 620, 129455. [Google Scholar] [CrossRef]
- Drakonakis, G.I.; Tsagkatakis, G.; Fotiadou, K.; Tsakalides, P. OmbriaNet—Supervised flood mapping via convolutional neural networks using multitemporal sentinel-1 and sentinel-2 data fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2341–2356. [Google Scholar] [CrossRef]
- Hertel, V.; Chow, C.; Wani, O.; Wieland, M.; Martinis, S. Probabilistic SAR-based water segmentation with adapted Bayesian convolutional neural network. Remote Sens. Environ. 2023, 285, 113388. [Google Scholar] [CrossRef]
- Li, Z.; Demir, I. U-net-based semantic classification for flood extent extraction using SAR imagery and GEE platform: A case study for 2019 central US flooding. Sci. Total Environ. 2023, 869, 161757. [Google Scholar] [CrossRef] [PubMed]
- Hänsch, R.; Arndt, J.; Lunga, D.; Pedelose, T.; Boedihardjo, A.; Pfefferkorn, J.; Petrie, D.; Bacastow, T.M. SpaceNet 8: Winning Approaches to Multi-Class Feature Segmentation from Satellite Imagery for Flood Disasters. In Proceedings of the IGARSS 2023–2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 1241–1244. [Google Scholar]
- Shastry, A.; Carter, E.; Coltin, B.; Sleeter, R.; McMichael, S.; Eggleston, J. Mapping floods from remote sensing data and quantifying the effects of surface obstruction by clouds and vegetation. Remote Sens. Environ. 2023, 291, 113556. [Google Scholar] [CrossRef]
- Chouhan, A.; Chutia, D.; Aggarwal, S.P. Attentive decoder network for flood analysis using sentinel 1 images. In Proceedings of the 2023 International Conference on Communication, Circuits, and Systems (IC3S), Bhubaneswar, India, 26–28 May 2023; pp. 1–5. [Google Scholar]
- nthizami, N.S.; Ma’sum, M.A.; Alhamidi, M.R.; Gamal, A.; Ardhianto, R.; Kurnianingsih; Jatmiko, W. Flood video segmentation on remotely sensed UAV using improved Efficient Neural Network. ICT Express 2022, 8, 347–351. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Şener, A.; Doğan, G.; Ergen, B. A novel convolutional neural network model with hybrid attentional atrous convolution module for detecting the areas affected by the flood. Earth Sci. Inform. 2024, 17, 193–209. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Shi, L.; Yang, K.; Chen, Y.; Chen, G. An Interactive Prompt Based Network for Urban Floods Area Segmentation Using UAV Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 935–948. [Google Scholar] [CrossRef]
- Landuyt, L.; Verhoest, N.E.; Van Coillie, F.M. Flood mapping in vegetated areas using an unsupervised clustering approach on sentinel-1 and-2 imagery. Remote Sens. 2020, 12, 3611. [Google Scholar] [CrossRef]
- Ibrahim, N.; Sharun, S.; Osman, M.; Mohamed, S.; Abdullah, S. The application of UAV images in flood detection using image segmentation techniques. Indones. J. Electr. Eng. Comput. Sci 2021, 23, 1219. [Google Scholar] [CrossRef]
- Bauer-Marschallinger, B.; Cao, S.; Tupas, M.E.; Roth, F.; Navacchi, C.; Melzer, T.; Freeman, V.; Wagner, W. Satellite-Based Flood Mapping through Bayesian Inference from a Sentinel-1 SAR Datacube. Remote Sens. 2022, 14, 3673. [Google Scholar] [CrossRef]
- McCormack, T.; Campanyà, J.; Naughton, O. A methodology for mapping annual flood extent using multi-temporal Sentinel-1 imagery. Remote Sens. Environ. 2022, 282, 113273. [Google Scholar] [CrossRef]
- Trombini, M.; Solarna, D.; Moser, G.; Dellepiane, S. A goal-driven unsupervised image segmentation method combining graph-based processing and Markov random fields. Pattern Recognit. 2023, 134, 109082. [Google Scholar] [CrossRef]
- Simantiris, G.; Panagiotakis, C. Unsupervised Deep Learning for Flood Segmentation in UAV imagery. In Proceedings of the 13th IAPR Workshop on Pattern Recognition in Remote Sensing, Kolkata, India, 1–4 December 2024. [Google Scholar]
- Ran, L.; Li, Y.; Liang, G.; Zhang, Y. Pseudo Labeling Methods for Semi-Supervised Semantic Segmentation: A Review and Future Perspectives. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 3054–3080. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, Y.; Zhu, G.; Zhou, E.; Zhou, Y.; Zhou, Y.; Zhu, C. Enhanced Pseudo-Label Generation With Self-Supervised Training for Weakly- Supervised Semantic Segmentation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7017–7028. [Google Scholar] [CrossRef]
- Lu, X.; Jiang, Z.; Zhang, H. Weakly Supervised Remote Sensing Image Semantic Segmentation With Pseudo-Label Noise Suppression. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5406912. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. Pseudoseg: Designing pseudo labels for semantic segmentation. arXiv 2020, arXiv:2010.09713. [Google Scholar]
- Paul, S.; Ganju, S. Flood segmentation on sentinel-1 SAR imagery with semi-supervised learning. arXiv 2021, arXiv:2107.08369. [Google Scholar]
- Li, J.; Meng, Y.; Li, Y.; Cui, Q.; Yang, X.; Tao, C.; Wang, Z.; Li, L.; Zhang, W. Accurate water extraction using remote sensing imagery based on normalized difference water index and unsupervised deep learning. J. Hydrol. 2022, 612, 128202. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Zhang, Y.; Liao, C. An efficient urban flood mapping framework towards disaster response driven by weakly supervised semantic segmentation with decoupled training samples. ISPRS J. Photogramm. Remote Sens. 2024, 207, 338–358. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Savitha, G.; Girisha, S.; Sughosh, P.; Shetty, D.K.; Mymbilly Balakrishnan, J.; Paul, R.; Naik, N. Consistency Regularization for Semi-Supervised Semantic Segmentation of Flood Regions From SAR Images. IEEE Access 2025, 13, 9642–9653. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Batzolis, G.; Stanczuk, J.; Schönlieb, C.B.; Etmann, C. Conditional image generation with score-based diffusion models. arXiv 2021, arXiv:2111.13606. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Wang, T.; Zhang, T.; Zhang, B.; Ouyang, H.; Chen, D.; Chen, Q.; Wen, F. Pretraining is all you need for image-to-image translation. arXiv 2022, arXiv:2205.12952. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Müller-Franzes, G.; Niehues, J.M.; Khader, F.; Arasteh, S.T.; Haarburger, C.; Kuhl, C.; Wang, T.; Han, T.; Nolte, T.; Nebelung, S.; et al. A multimodal comparison of latent denoising diffusion probabilistic models and generative adversarial networks for medical image synthesis. Sci. Rep. 2023, 13, 12098. [Google Scholar] [CrossRef] [PubMed]
- Vivekananthan, S. Comparative analysis of generative models: Enhancing image synthesis with vaes, gans, and stable diffusion. arXiv 2024, arXiv:2408.08751. [Google Scholar]
- Sarfraz, S.; Sharma, V.; Stiefelhagen, R. Efficient parameter-free clustering using first neighbor relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8934–8943. [Google Scholar]
- Zotou, P.; Bacharidis, K.; Argyros, A. Leveraging FINCH and K-means for Enhanced Cluster- Based Instance Selection. In Proceedings of the 18th European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18. Springer: Berlin/Heidelberg, Germany; pp. 234–241. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simantiris, G.; Bacharidis, K.; Panagiotakis, C. Closing the Domain Gap: Can Pseudo-Labels from Synthetic UAV Data Enable Real-World Flood Segmentation? Sensors 2025, 25, 3586. https://doi.org/10.3390/s25123586
Simantiris G, Bacharidis K, Panagiotakis C. Closing the Domain Gap: Can Pseudo-Labels from Synthetic UAV Data Enable Real-World Flood Segmentation? Sensors. 2025; 25(12):3586. https://doi.org/10.3390/s25123586
Chicago/Turabian StyleSimantiris, Georgios, Konstantinos Bacharidis, and Costas Panagiotakis. 2025. "Closing the Domain Gap: Can Pseudo-Labels from Synthetic UAV Data Enable Real-World Flood Segmentation?" Sensors 25, no. 12: 3586. https://doi.org/10.3390/s25123586
APA StyleSimantiris, G., Bacharidis, K., & Panagiotakis, C. (2025). Closing the Domain Gap: Can Pseudo-Labels from Synthetic UAV Data Enable Real-World Flood Segmentation? Sensors, 25(12), 3586. https://doi.org/10.3390/s25123586