
CB-MTE: Social Bot Detection via Multi-Source Heterogeneous Feature Fusion

Abstract
1. Introduction
- (1)
- Multi-source heterogeneous feature collaborative modeling
- (2)
- Hierarchical double fusion detection framework CB-MTE
- (3)
- Fine-grained evaluation system
2. Related Work
2.1. Social Bot Detection
2.2. Social Bot Detection Technology
2.2.1. Text Modeling
2.2.2. Graph Structure Embedding
2.2.3. Decision Classification
3. Framework and Methods
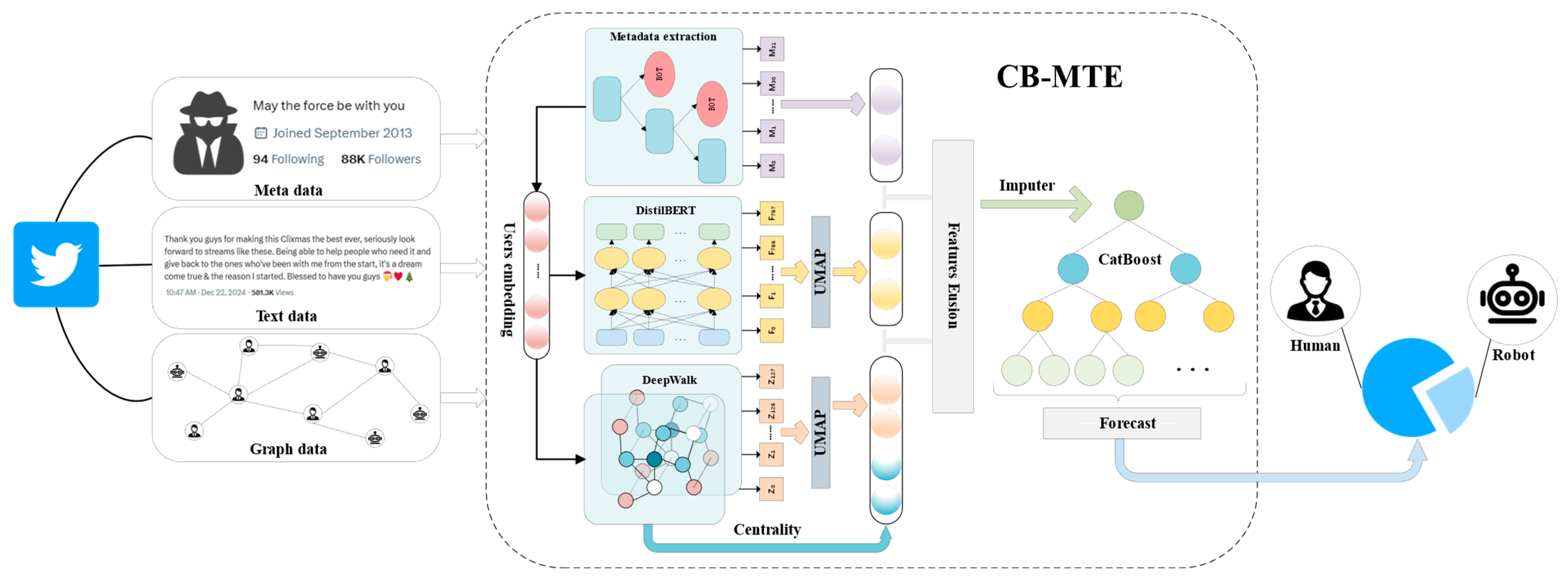
3.1. Framework Architecture
3.2. Metadata Feature Extraction
3.3. Text Feature Extraction
3.4. Feature Extraction of Graph Structure
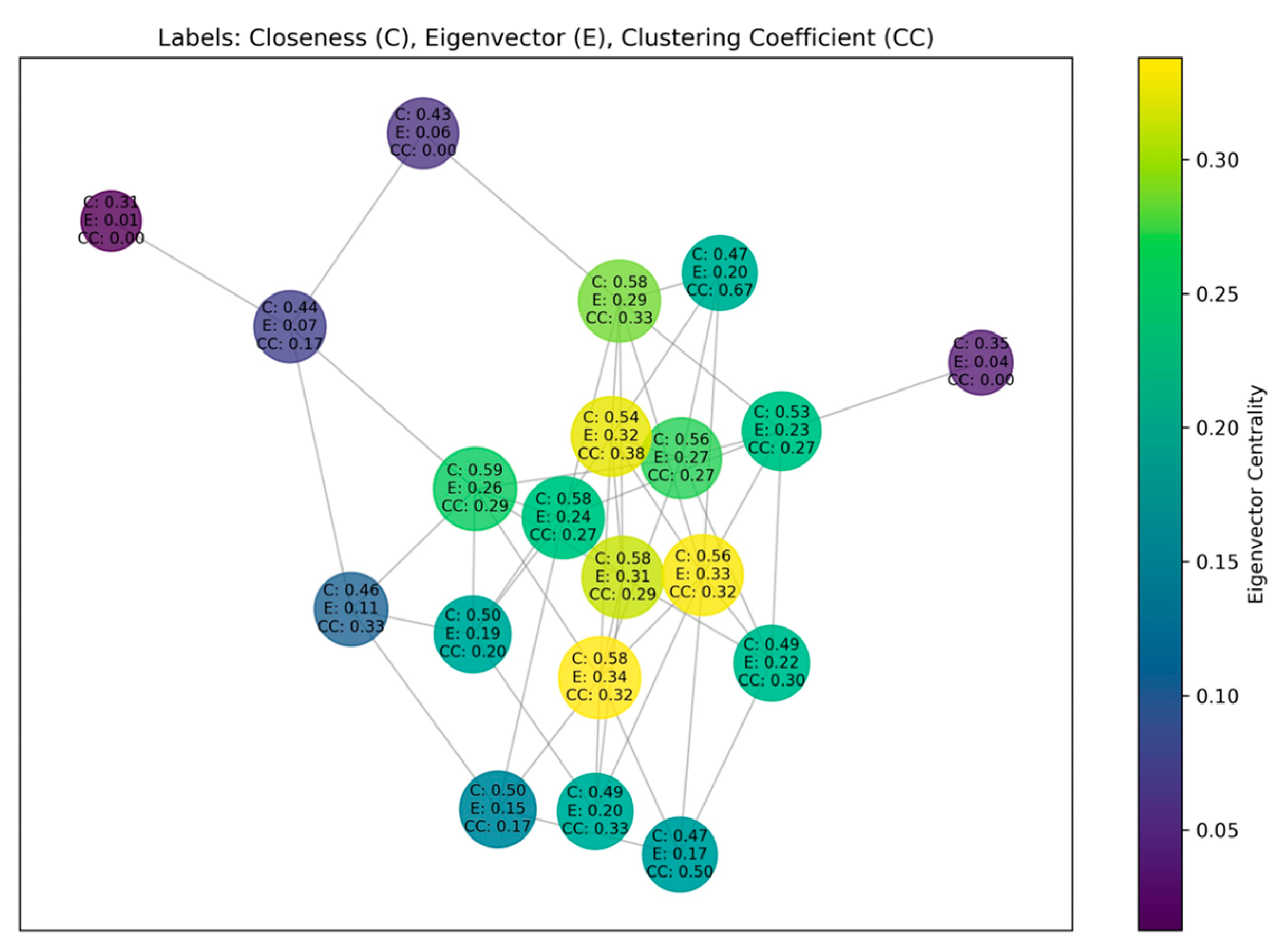
3.4.1. Global Location Extraction
3.4.2. Local Propagation Mode Learning
3.5. Feature Fusion
3.6. CatBoost Classification
3.7. Global Structure
| Algorithm 1: Bot detection via CB-MTE Framework | |
| input: Twitter bot detection dataset T = {u1, u2, …, un} | |
| output: Predicted labels (0: human, 1: bot) | |
| 1: | for each user in T do |
| 2: | metadata feature extraction: |
| 3: | textual feature extraction: ← Equations (1)–(4) |
| 4: | Compute structural features for user : |
| 5: | ← Equations (5)–(7) |
| 6: | graph feature extraction: |
| 7: | ← Equation (8) |
| 8: | Concatenate with DeepWalk embedding: |
| 9: | ← Equation (9) |
| 10: | Reduce dimensionality via UMAP: |
| 11: | ← Equations (10)–(14) |
| 12: | fused via vector concatenation: |
| 13: | predict label using CatBoost classifier: ← Equations (15)–(22) |
| 14: | end for |
4. Experimental Results and Analysis
4.1. Dataset Preparation
4.2. Experimental Setup
4.2.1. Data Preprocessing
4.2.2. Experimental Parameters
4.2.3. Baseline Method: We Compare CB-MTE with the Following Baselines
- BGSRD [41] combines BERT pre-training model and graph convolutional network (GCN) BGSRD model by constructing heterogeneous graphs that integrate text semantic and social relations and jointly training them.
- Botometer [42] uses more than 1000 features derived from user metadata, content, and interactions.
- BotRGCN [7] builds heterogeneous graphs from Twitter networks and employs graph convolutional networks for user representation learning and Twitter bot detection.
- SimpleHGN [43] achieves superior performance on the heterogeneous graph benchmark HGB by building a multi-graph neural network structure that fuses node features with heterogeneous information.
- Lee et al. [44] realize efficient bot detection across social media platforms by extracting statistical features from user metadata and using a lightweight logistic regression model.
- Deshmukh et al. [45] propose a social bot detection model that integrates GraphSage and BERT, enhancing detection accuracy by fusing graph structure and textual features, and demonstrates outstanding performance in experiments.
- RGT [46], which stands for Relational Graph Converter, models the inherent heterogeneity in the Twitter domain to improve Twitter bot detection.
- SGBot [47] extracts features from the user’s metadata and feeds them into a Random Forest classifier for scalable and generalizable bot recognition.
- T5 [48] achieve state-of-the-art performance across a range of Natural Language Processing tasks by unifying all NLP tasks into a text-to-text format, and by pre-training and fine-tuning on large amounts of unlabeled data.
- BotDGT [49] is a hybrid model combining GNNs and Transformers, enabling dynamicity-aware detection of evolving social bots.
4.2.4. Evaluation Indicators
4.3. Experimental Results and Comparative Analysis
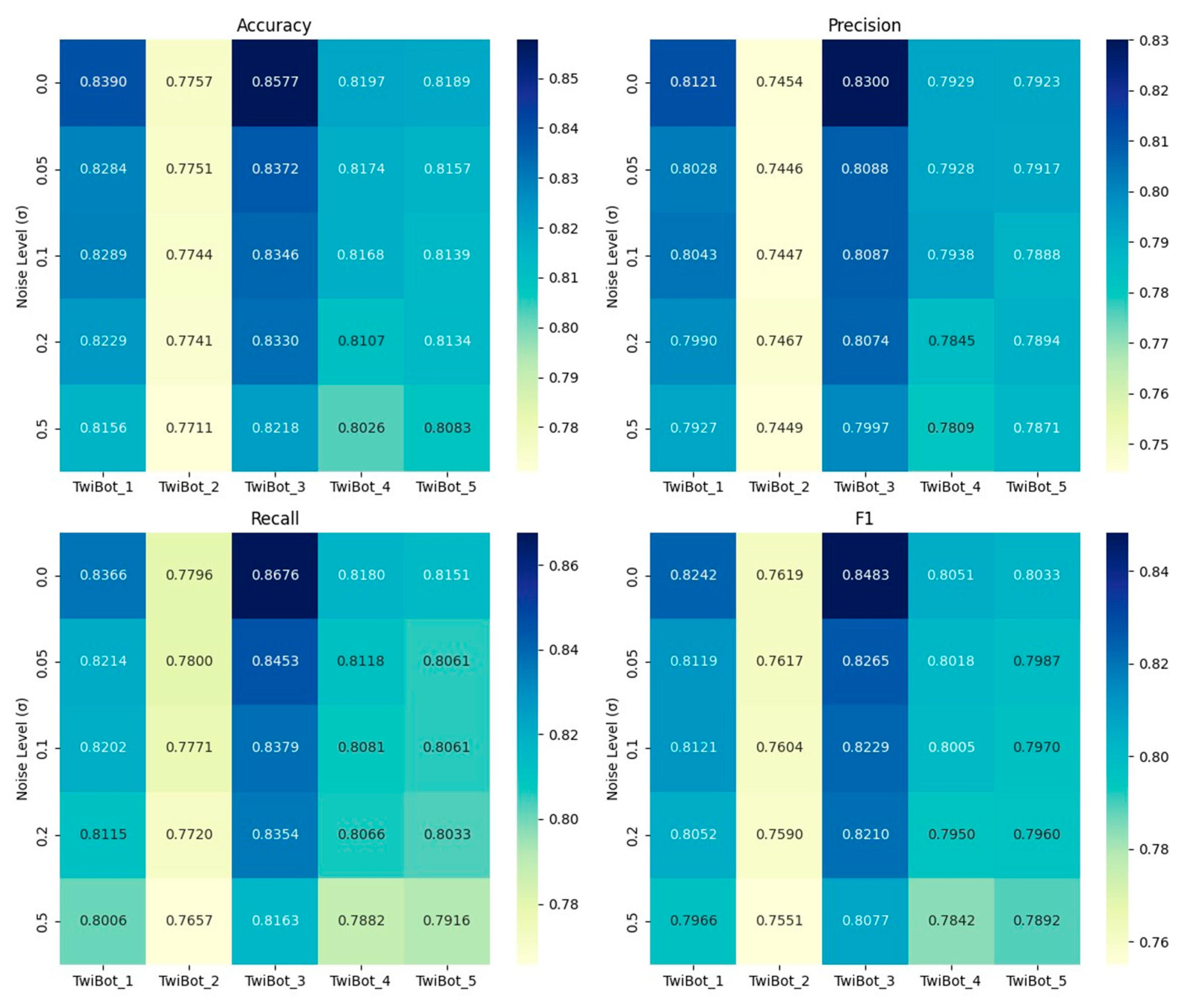
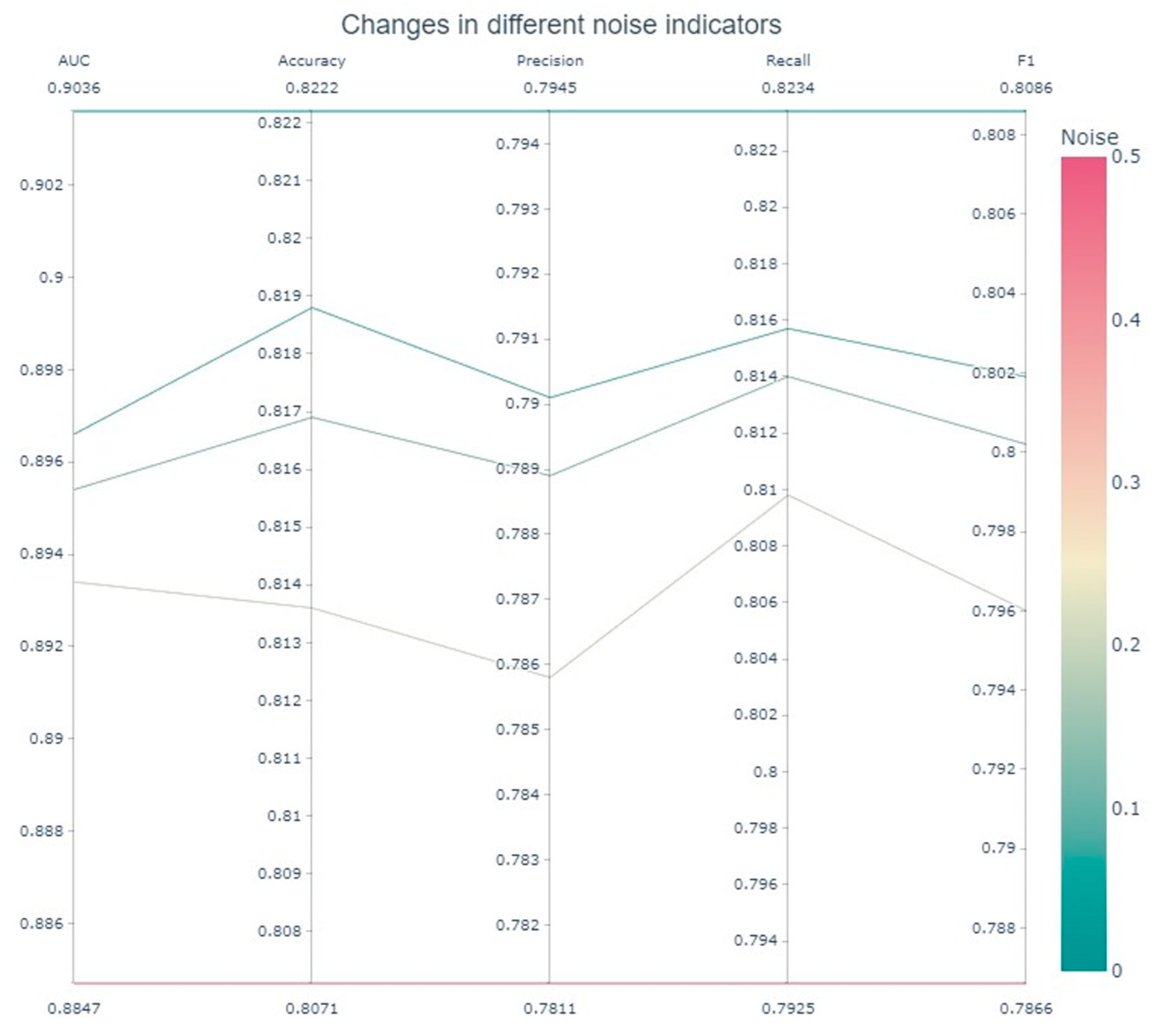
4.4. Robustness Experiment
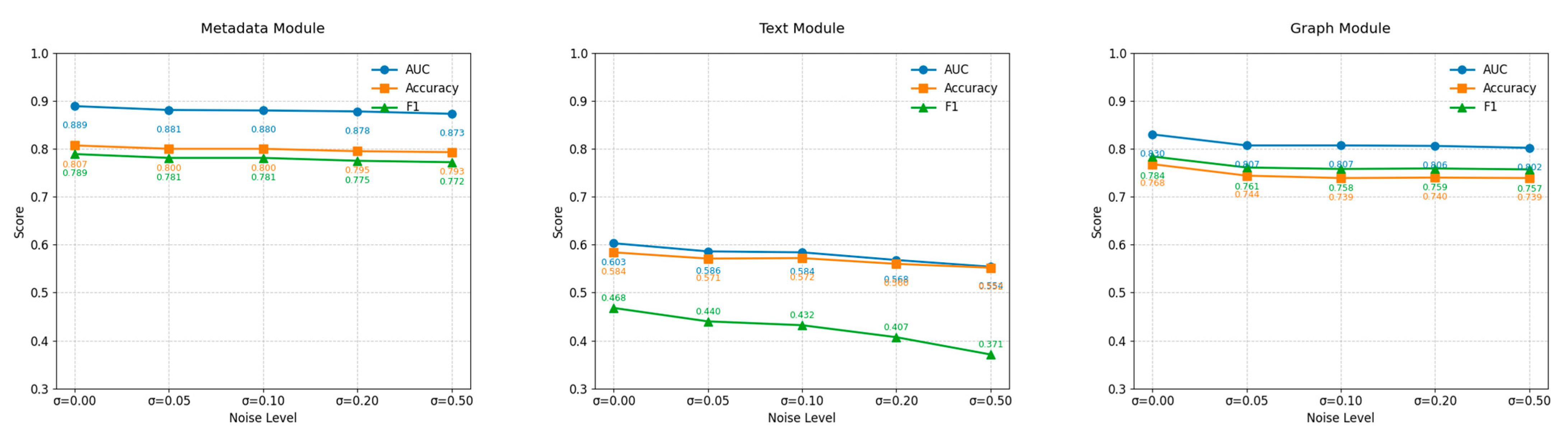
4.4.1. Noise Robustness Experiment
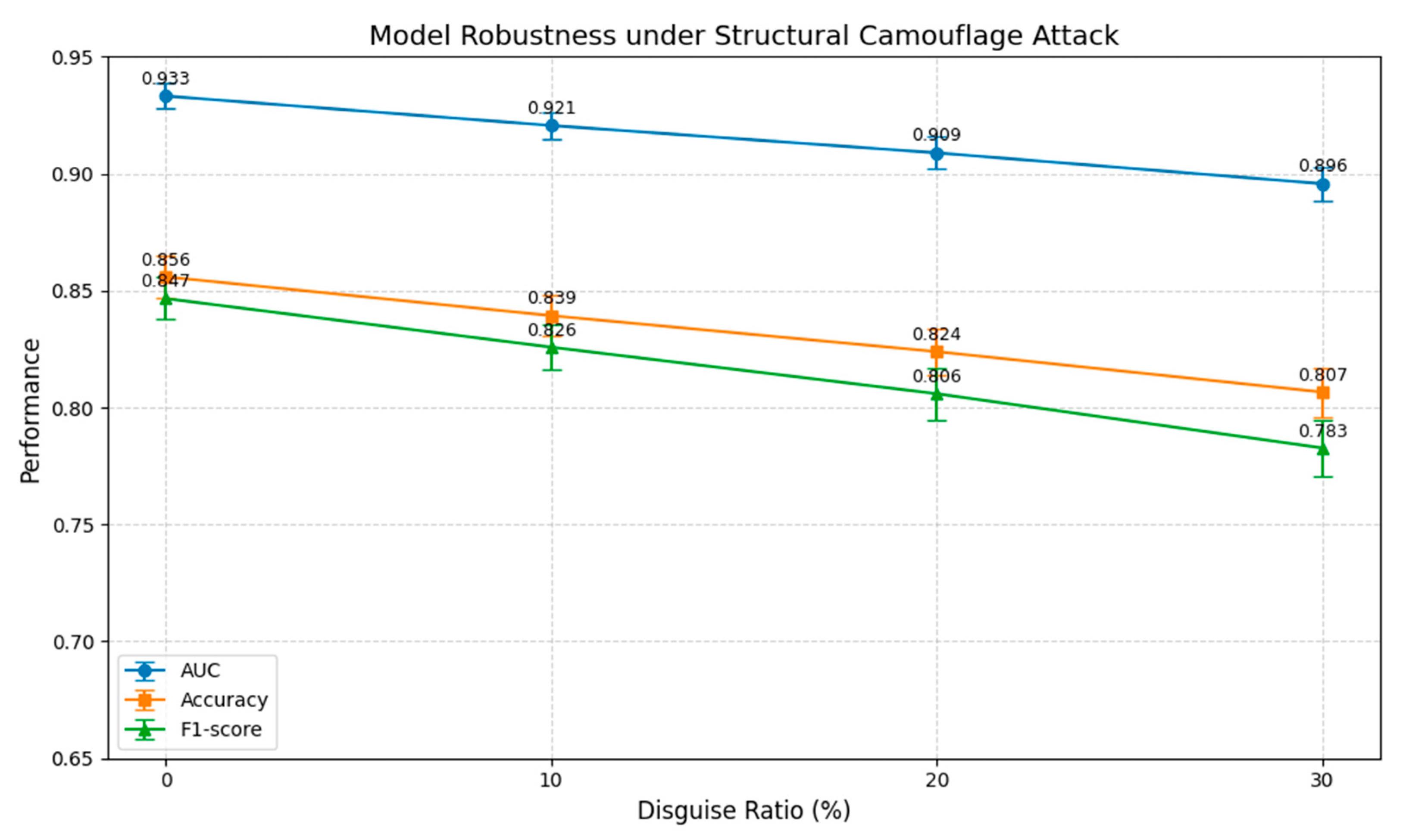
4.4.2. Robustness Testing of Structured Camouflage Attacks
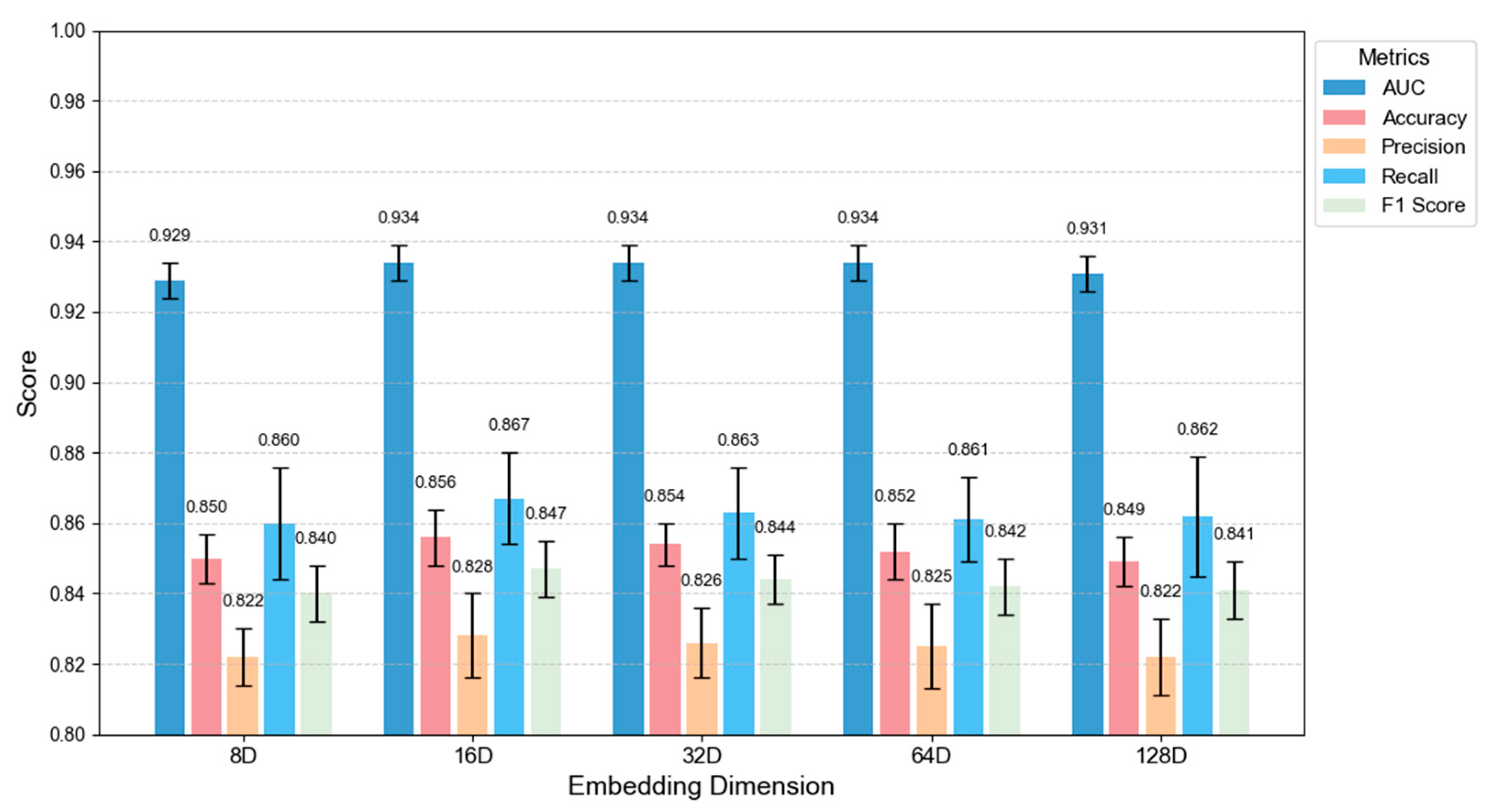
4.4.3. Dimensional Analysis
4.4.4. UMAP Hyperparameter Analysis
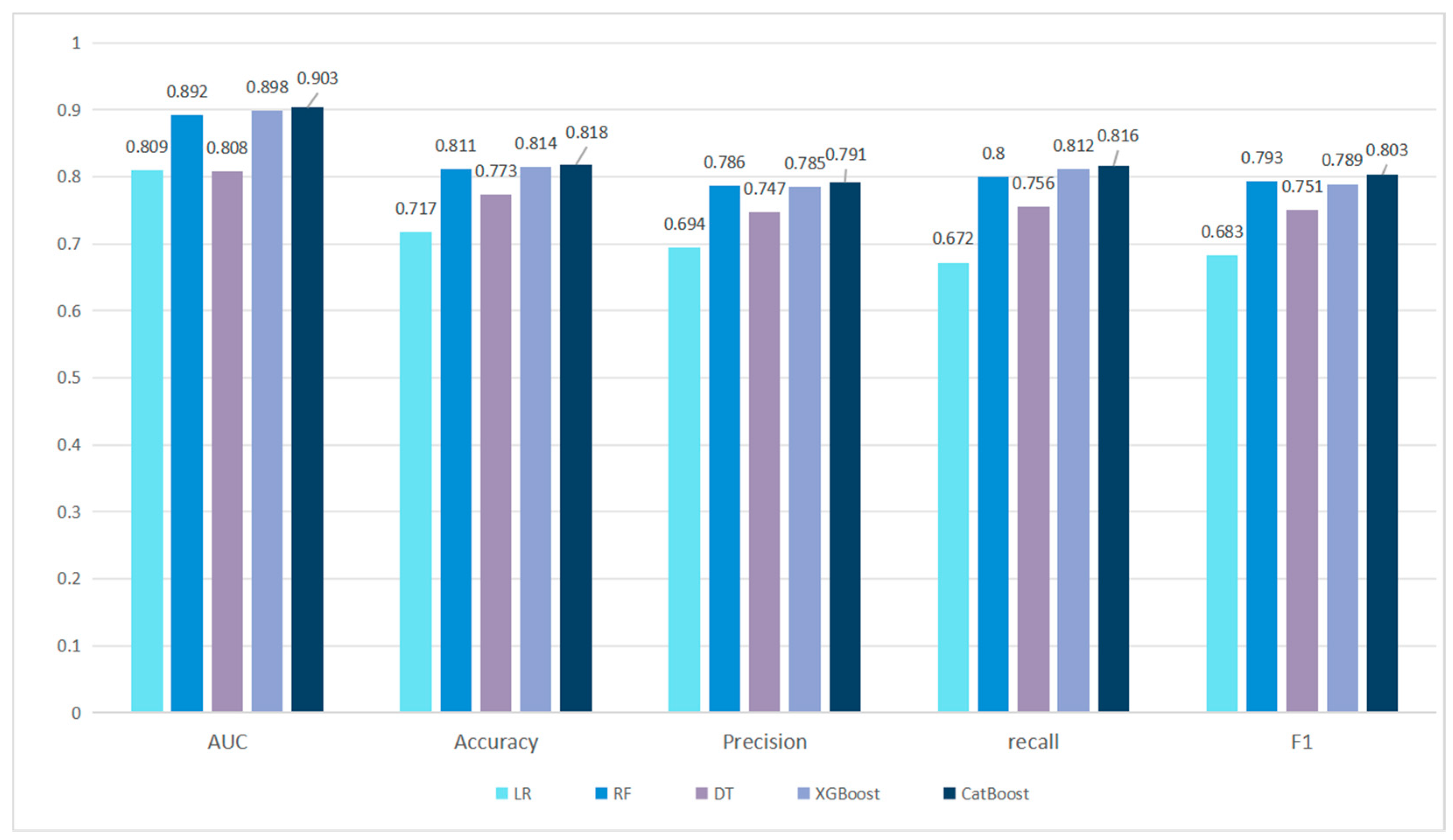
4.4.5. Classifier Selection
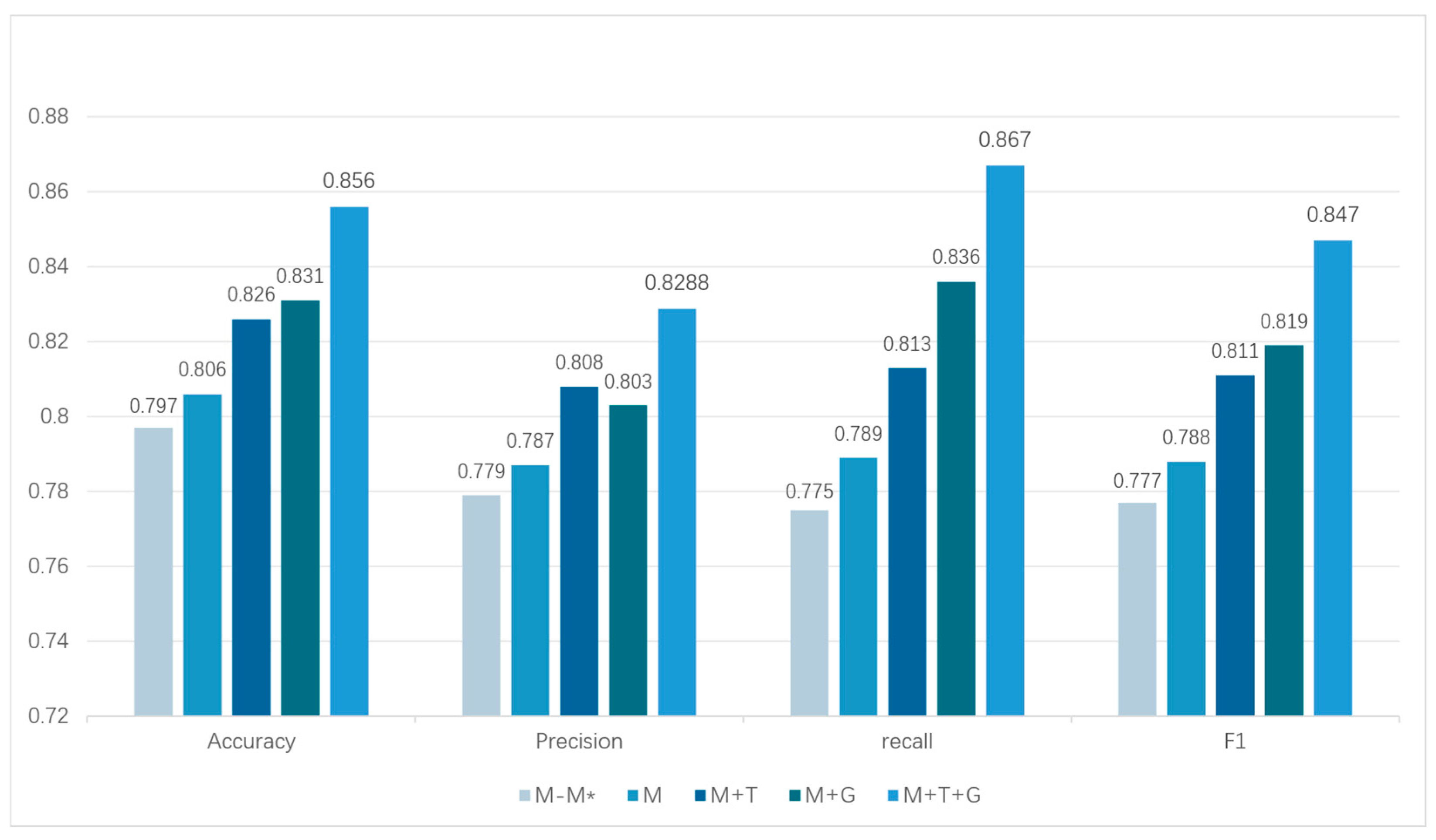
4.5. Ablation Experiment Design
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Martini, F.; Samula, P.; Keller, T.R.; Klinger, U. Bot, or not? Comparing three methods for detecting social bots in five political discourses. Big Data Soc. 2021, 8, 1–13. [Google Scholar] [CrossRef]
- Hagen, L.; Neely, S.; Keller, T.E.; Scharf, R.; Vasquez, F.E. Rise of the machines? Examining the influence of social bots on a political discussion network. Soc. Sci. Comput. Rev. 2022, 40, 264–287. [Google Scholar] [CrossRef]
- Shahid, W.; Li, Y.; Staples, D.; Amin, G.; Hakak, S.; Ghorbani, A. Are you a cyborg, bot or human?—A survey on detecting fake news spreaders. IEEE Access 2022, 10, 27069–27083. [Google Scholar] [CrossRef]
- Kantepe, M.; Ganiz, M.C. Preprocessing framework for Twitter bot detection. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 630–634. [Google Scholar]
- Ouni, S.; Fkih, F.; Omri, M.N. Bots and gender detection on Twitter using stylistic features. In Proceedings of the International Conference on Computational Collective Intelligence, Hammamet, Tunisia, 28–30 September 2022; Springer International Publishing: Cham, Switzerland, 2022; Volume 1653, pp. 650–660. [Google Scholar]
- Dukić, D.; Keča, D.; Stipić, D. Are you human? Detecting bots on Twitter Using BERT. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, NSW, Australia, 6–9 October 2020; pp. 631–636. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Luo, M. BotRGCN: Twitter bot detection with relational graph convolutional networks. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, New York, NY, USA, 8–11 November 2021; pp. 236–239. [Google Scholar]
- Peng, H.; Zhang, J.; Huang, X.; Hao, Z.; Li, A.; Yu, Z.; Yu, P.S. Unsupervised social bot detection via structural information theory. ACM Trans. Inf. Syst. 2024, 42, 1–42. [Google Scholar] [CrossRef]
- Aljabri, M.; Zagrouba, R.; Shaahid, A.; Alnasser, F.; Saleh, A.; Alomari, D.M. Machine learning-based social media bot detection: A comprehensive literature review. Soc. Netw. Anal. Min. 2023, 13, 20. [Google Scholar] [CrossRef]
- Wu, J.; Ye, X.; Mou, C. Botshape: A novel social bots detection approach via behavioral patterns. arXiv 2023, arXiv:2303.10214. [Google Scholar]
- Echeverra, J.; De Cristofaro, E.; Kourtellis, N.; Leontiadis, I.; Stringhini, G.; Zhou, S. LOBO: Evaluation of generalization deficiencies in Twitter bot classifiers. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 137–146. [Google Scholar]
- Alarfaj, F.K.; Ahmad, H.; Khan, H.U.; Alomair, A.M.; Almusallam, N.; Ahmed, M. Twitter bot detection using diverse content features and applying machine learning algorithms. Sustainability 2023, 15, 6662. [Google Scholar] [CrossRef]
- Abreu, J.V.F.; Ralha, C.G.; Gondim, J.J.C. Twitter bot detection with reduced feature set. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–10 November 2020; pp. 1–6. [Google Scholar]
- Wang, Y.; Wu, C.; Zheng, K.; Wang, X. Social bot detection using tweets similarity. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Singapore, 8–10 August 2018; Springer International Publishing: Cham, Switzerland, 2018; Volume 255, pp. 63–78. [Google Scholar]
- Kumar, S.; Garg, S.; Vats, Y.; Parihar, A.S. Content based bot detection using bot language model and bert embeddings. In Proceedings of the 2021 5th International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 24–25 May 2021; pp. 285–289. [Google Scholar]
- Yu, Z.; Bai, L.; Ye, O.; Cong, X. Social Bot Detection Method with Improved Graph Neural Networks. Comput. Mater. Contin. 2024, 78, 1773. [Google Scholar]
- Lin, H.; Chen, N.; Chen, Y.; Li, X.; Li, C. BotScout: A Social Bot Detection Algorithm Based on Semantics, Attributes and Neighborhoods. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; pp. 343–355. [Google Scholar]
- Lei, Z.; Wan, H.; Zhang, W.; Feng, S.; Chen, Z.; Li, J.; Zheng, Q.; Luo, M. BIC: Twitter Bot Detection with Text-Graph Interaction and Semantic Consistency. In Proceedings of the 2023 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 10326–10340. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Heidari, M.; Zad, S.; Hajibabaee, P.; Malekzadeh, M.; HekmatiAthar, S.; Uzuner, O.; Jones, J.H. Bert model for fake news detection based on social bot activities in the COVID-19 pandemic. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021; pp. 103–109. [Google Scholar]
- Anggrainingsih, R.; Hassan, G.M.; Datta, A. BERT based classification system for detecting rumours on Twitter. IEEE Trans. Comput. Soc. Syst. 2021; submitted. [Google Scholar]
- Heidari, M.; Jones, J.H. Using bert to extract topic-independent sentiment features for social media bot detection. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 542–547. [Google Scholar]
- Wang, W.; Wang, Q.; Zang, T.; Zhang, X.; Liu, L.; Yang, T.; Wang, Y. BotRGA: Neighborhood-Aware Twitter Bot Detection with Relational Graph Aggregation. In Proceedings of the International Conference on Computational Science, Seattle, WA, USA, 6–8 October; Springer Nature: Cham, Switzerland, 2024; Volume 14838, pp. 162–176. [Google Scholar]
- Sallah, A.; Agoujil, S.; Wani, M.A.; Hammad, M.; Maleh, Y.; El-Latif, A.A.A. Fine-tuned understanding: Enhancing social bot detection with transformer-based classification. IEEE Access 2024, 12, 118250–118269. [Google Scholar] [CrossRef]
- Sanh, V. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York City, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Ribeiro, L.F.R.; Saverese, P.H.P.; Figueiredo, D.R. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 385–394. [Google Scholar]
- Berriche, A.; Nair, M.; Yamani, K.M.; Adjal, M.; Bendaho, S.; Chenni, N.; Tayeb, F.; Bessedik, M. A Novel Hybrid Approach Combining Beam Search and DeepWalk for Community Detection in Social Networks. In Proceedings of the WEBIST, Rome, Italy, 15–17 November 2023; pp. 454–463. [Google Scholar]
- Leskovec, J. GraphSAGE: Inductive Representation Learning on Large Graphs; SNAP: Long Beach, CA, USA, 2017. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Advances in neural information processing systems. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31, pp. 1–11. [Google Scholar]
- Zhang, T.L.; Niu, Y.F.; Ma, R.; Zhao, M.; Song, D.; Liu, H. Spam detection using Catboost integration algorithm. In Proceedings of the Second International Conference on Statistics, Applied Mathematics, and Computing Science, Nanjing, China, 25–27 November 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12597, pp. 853–857. [Google Scholar]
- Ibrahim, A.A.; Ridwan, R.L.; Muhammed, M.M.; Abdulaziz, R.O.; Saheed, G.A. Comparison of the CatBoost classifier with other machine learning methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 738–748. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Zhang, J.; Luo, Y. Degree centrality, betweenness centrality, and closeness centrality in social network. In Proceedings of the 2017 2nd International Conference on Modelling, Simulation and Applied Mathematics (MSAM2017), Bangkok, Thailand, 26–27 March 2017; pp. 300–303. [Google Scholar]
- Bonacich, P. Some unique properties of eigenvector centrality. Soc. Netw. 2007, 29, 555–564. [Google Scholar] [CrossRef]
- Li, Y.; Shang, Y.; Yang, Y. Clustering coefficients of large networks. Inf. Sci. 2017, 382, 350–358. [Google Scholar] [CrossRef]
- Wang, X.; Chen, K.; Wang, K.; Wang, Z.; Zheng, K.; Zhang, J. FedKG: A knowledge distillation-based federated graph method for social bot detection. Sensors 2024, 24, 3481. [Google Scholar] [CrossRef]
- Dehghan, A.; Siuta, K.; Skorupka, A.; Dubey, A.; Betlen, A.; Miller, D.; Xu, W.; Kamiński, B.; Prałat, P. Detecting bots in social-networks using node and structural embeddings. J. Big Data 2023, 10, 119. [Google Scholar] [CrossRef]
- Feng, S.; Tan, Z.; Wan, H.; Wang, N.; Chen, Z.; Zhang, B.; Zheng, Q.; Zhang, W.; Lei, Z.; Yang, S.; et al. Twibot-22: Towards graph-based twitter bot detection. Adv. Neural Inf. Process. Syst. 2022, 35, 35254–35269. [Google Scholar]
- Guo, Q.; Xie, H.; Li, Y.; Ma, W.; Zhang, C. Social bots detection via fusing bert and graph convolutional networks. Symmetry 2021, 14, 30. [Google Scholar] [CrossRef]
- Yang, K.C.; Ferrara, E.; Menczer, F. Botometer 101: Social bot practicum for computational social scientists. J. Comput. Soc. Sci. 2022, 5, 1511–1528. [Google Scholar] [CrossRef] [PubMed]
- Lv, Q.; Ding, M.; Liu, Q.; Chen, Y.; Feng, W.; He, S.; Zhou, C.; Jiang, J.; Dong, Y.; Tang, J. Are we really making much progress? revisiting, benchmarking and refining heterogeneous graph neural networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1150–1160. [Google Scholar]
- Lee, K.; Eoff, B.; Caverlee, J. Seven months with the devils: A long-term study of content polluters on twitter. In Proceedings of the Fifth International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5, pp. 185–192. [Google Scholar]
- Deshmukh, A.; Moh, M.; Moh, T.S. Bot Detection in Social Media Using GraphSage and BERT. In Proceedings of the 2024 IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Bangkok, Thailand, 9–12 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 804–811. [Google Scholar]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 3977–3985. [Google Scholar]
- Yang, K.C.; Varol, O.; Hui, P.M.; Menczer, F. Scalable and generalizable social bot detection through data selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1096–1103. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- He, B.; Yang, Y.; Wu, Q.; Liu, H.; Yang, R.; Peng, H.; Wang, X.; Liao, Y.; Zhou, P. Dynamicity-aware social bot detection with dynamic graph transformers. In Proceedings of the IJCAI 2024, Jeju, Republic of Korea, 3–9 August 2024; pp. 5844–5852. [Google Scholar]
- Xu, Y.; Bao, R.; Zhang, L.; Wang, J.; Wang, S. Embodied intelligence in RO/RO logistic terminal: Autonomous intelligent transportation robot architecture. Sci. China Inf. Sci. 2025, 68, 150210. [Google Scholar] [CrossRef]
- Chen, Z.; Zhan, G.; Jiang, Z.; Zhang, W.; Rao, Z.; Wang, H.; Li, J. Adaptive impedance control for docking robot via Stewart parallel mechanism. ISA Trans. 2024, 155, 361–372. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature_Type | Symbol | Description |
|---|---|---|
| Account Attributes: Au | The total number of devices used by the user | |
| * | , (pi) | |
| Whether user verifies: V∈ {0, 1} | ||
| Profile character length | ||
| Nicknameccer length | ||
| Username character length | ||
| Behavior Attributes: Bu | Total number of tweets | |
| Ccol | Total of Favorites | |
| * | : active days) | |
| * | ||
| * | ||
| comment count) | ||
| tweet character count) | ||
| Content similarity of tweets | ||
| * | Single day tweet similarity | |
| : media count) | ||
| * | Tweet time distribution entropy | |
| Average number of tweets per month | ||
| Number of days since last tweet | ||
| ) | ||
| Social attributess: Su | Number of follows | |
| Number of followers | ||
| * | : mutual followers) | |
| * | ||
| * | ||
| likes) | ||
| * | ||
| TwiBot_1 | TwiBot_2 | TwiBot_3 | TwiBot_4 | TwiBot_5 | |
|---|---|---|---|---|---|
| Human | 5000 | 5000 | 5000 | 5000 | 5000 |
| Bot | 5000 | 5000 | 5000 | 5000 | 5000 |
| User | 10,000 | 10,000 | 10,000 | 10,000 | 10,000 |
| Tweet | 1,156,640 | 1,333,018 | 1,138,480 | 1,151,362 | 1,142,717 |
| Edge | 1,535,397 | 1,924,616 | 1,508,054 | 1,511,824 | 1,526,627 |
| Module | Parameter Name | Parameter Size |
|---|---|---|
| DistilBERT | Sequence length Lmax | 128 |
| DeepWalk | Number of random walks э | 100 |
| Random walk step λ(u) | 10 | |
| Window size δ(u) | 5 | |
| CatBoost | CatBoost learning rate η(c) | 0.03 |
| CatBoost iterative training times | 500 | |
| CatBoost tree depth | 6 | |
| UMAP | n_neighbors N(p) | 15 |
| min_dist M(p) | 0.1 | |
| n_components D(p) | 16 |
| TwiBot_1 | TwiBot_2 | TwiBot_3 | TwiBot_4 | TwiBot_5 | Average | |
|---|---|---|---|---|---|---|
| Accuracy | 0.8380 | 0.7770 | 0.8560 | 0.8180 | 0.8180 | 0.8214 |
| Precision | 0.8100 | 0.7450 | 0.8280 | 0.7880 | 0.7910 | 0.7924 |
| Recall | 0.8390 | 0.7850 | 0.8670 | 0.8200 | 0.8160 | 0.8254 |
| F1 | 0.8240 | 0.7640 | 0.8470 | 0.8040 | 0.8030 | 0.8084 |
| Model | TwiBot-22 | |||
|---|---|---|---|---|
| Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | |
| BGSRD [41] | 0.7188 | 0.2255 | 0.1990 | 0.2114 |
| Botometer [42] | 0.4987 | 0.3081 | 0.6980 | 0.4257 |
| BotRGCN [7] | 0.7966 | 0.7480 | 0.4680 | 0.5750 |
| SimpleHGN [43] | 0.7672 | 0.7257 | 0.3290 | 0.4544 |
| Lee et al. [44] | 0.7628 | 0.6723 | 0.1965 | 0.3041 |
| Deshmukh et al. [45] | 0.7462 | - | - | 0.5169 |
| RGT [46] | 0.7647 | 0.7503 | 0.3010 | 0.4294 |
| SGBot [47] | 0.7508 | 0.7311 | 0.2432 | 0.3659 |
| T5 [48] | 0.7205 | 0.6327 | 0.1209 | 0.2027 |
| BotDGT [49] | 0.7933 | 0.7242 | 0.4846 | 0.5815 |
| CB-MTE | 0.8214 | 0.7924 | 0.8254 | 0.8084 |
| Number | n_neighbors | min_dist | n_components | AUC | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|
| A | 5 | 0.1 | 16 | 0.9350 | 0.8550 | 0.8290 | 0.8630 | 0.8460 |
| B | 15 | 0.1 | 16 | 0.9340 | 0.8560 | 0.8270 | 0.8670 | 0.8470 |
| C | 30 | 0.1 | 16 | 0.9350 | 0.8570 | 0.8290 | 0.8670 | 0.8470 |
| D | 15 | 0.5 | 16 | 0.9350 | 0.8560 | 0.8270 | 0.8670 | 0.8460 |
| Ablation Settings | Representation |
|---|---|
| w/o graph & text & M* | M − M* |
| w/o graph & text | M |
| w/o graph | M + T |
| w/o text | M + G |
| CB-MTE | M + T + G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, M.; Xiao, Y.; Huang, T.; Lei, C.; Zhang, C. CB-MTE: Social Bot Detection via Multi-Source Heterogeneous Feature Fusion. Sensors 2025, 25, 3549. https://doi.org/10.3390/s25113549
Cheng M, Xiao Y, Huang T, Lei C, Zhang C. CB-MTE: Social Bot Detection via Multi-Source Heterogeneous Feature Fusion. Sensors. 2025; 25(11):3549. https://doi.org/10.3390/s25113549
Chicago/Turabian StyleCheng, Meng, Yuzhi Xiao, Tao Huang, Chao Lei, and Chuang Zhang. 2025. "CB-MTE: Social Bot Detection via Multi-Source Heterogeneous Feature Fusion" Sensors 25, no. 11: 3549. https://doi.org/10.3390/s25113549
APA StyleCheng, M., Xiao, Y., Huang, T., Lei, C., & Zhang, C. (2025). CB-MTE: Social Bot Detection via Multi-Source Heterogeneous Feature Fusion. Sensors, 25(11), 3549. https://doi.org/10.3390/s25113549