
Enhanced Rail Surface Defect Segmentation Using Polarization Imaging and Dual-Stream Feature Fusion

Abstract
:1. Introduction
- We introduce a dual-stream network architecture that integrates light-intensity and polarization images for enhanced defect detection on rail surfaces. This architecture independently extracts and combines features from both modalities, improving contrast and detail visibility in low-contrast and complex environments.
- Our approach incorporates polarization imaging into a DL framework, utilizing polarization-specific data to significantly enhance the detection of small-scale and low-contrast defects. This integration extends the capabilities of traditional RGB-based defect detection systems.
- We utilize a pruned MobileNetV3 backbone enhanced with coordinate attention for efficient feature extraction, complemented by the Convolutional Block Attention Module for focused feature refinement. This combination optimizes the model for high accuracy and efficiency, making it suitable for real-time industrial applications.
- Extensive experiments on real-world ratio surface defect segmentation datasets demonstrate the effectiveness and superiority of our proposed method.
2. Related Work
2.1. Deep Learning in Defect Detection
2.2. Polarization Imaging
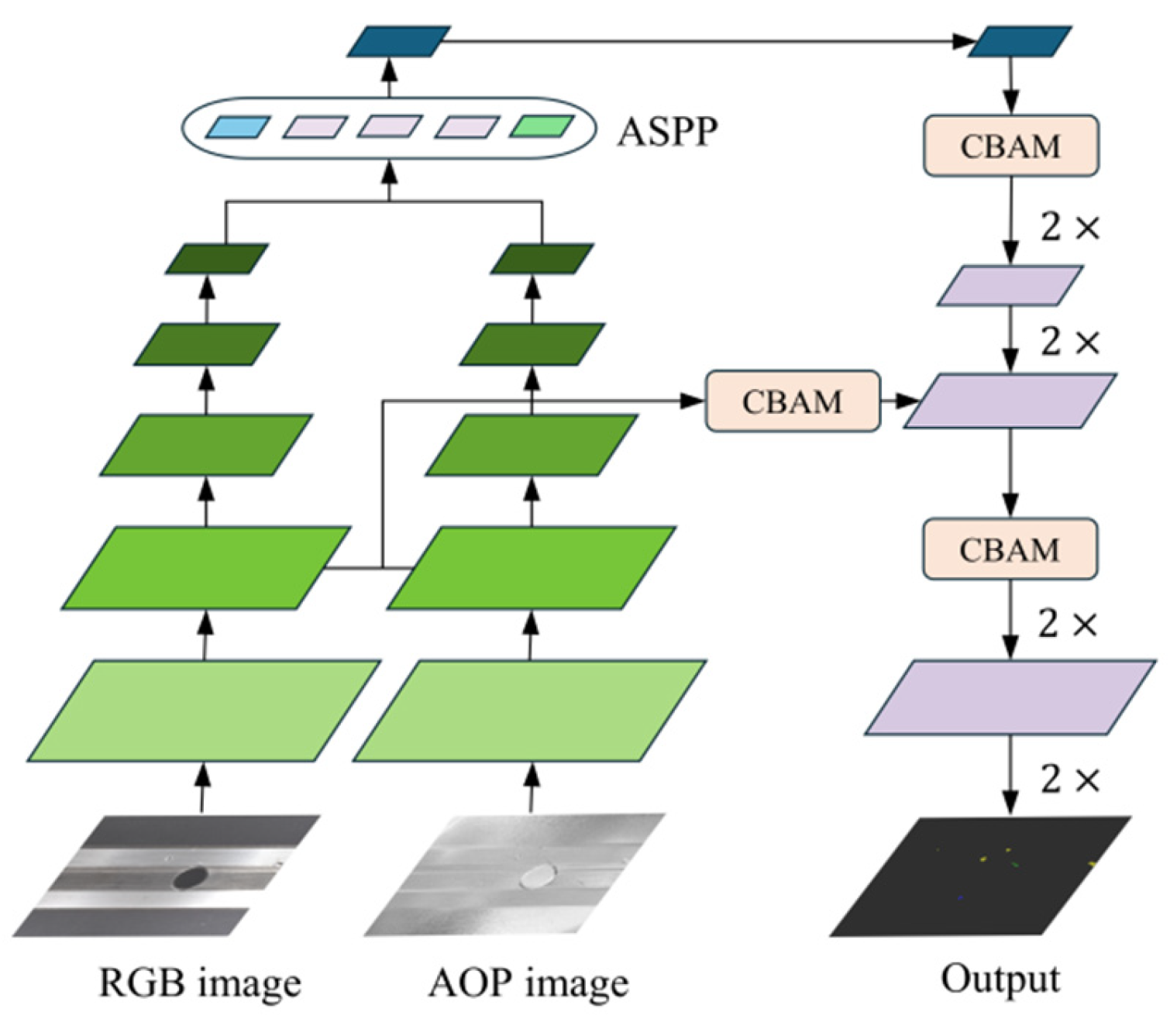
3. Improvement of the DeepLabv3+ Network
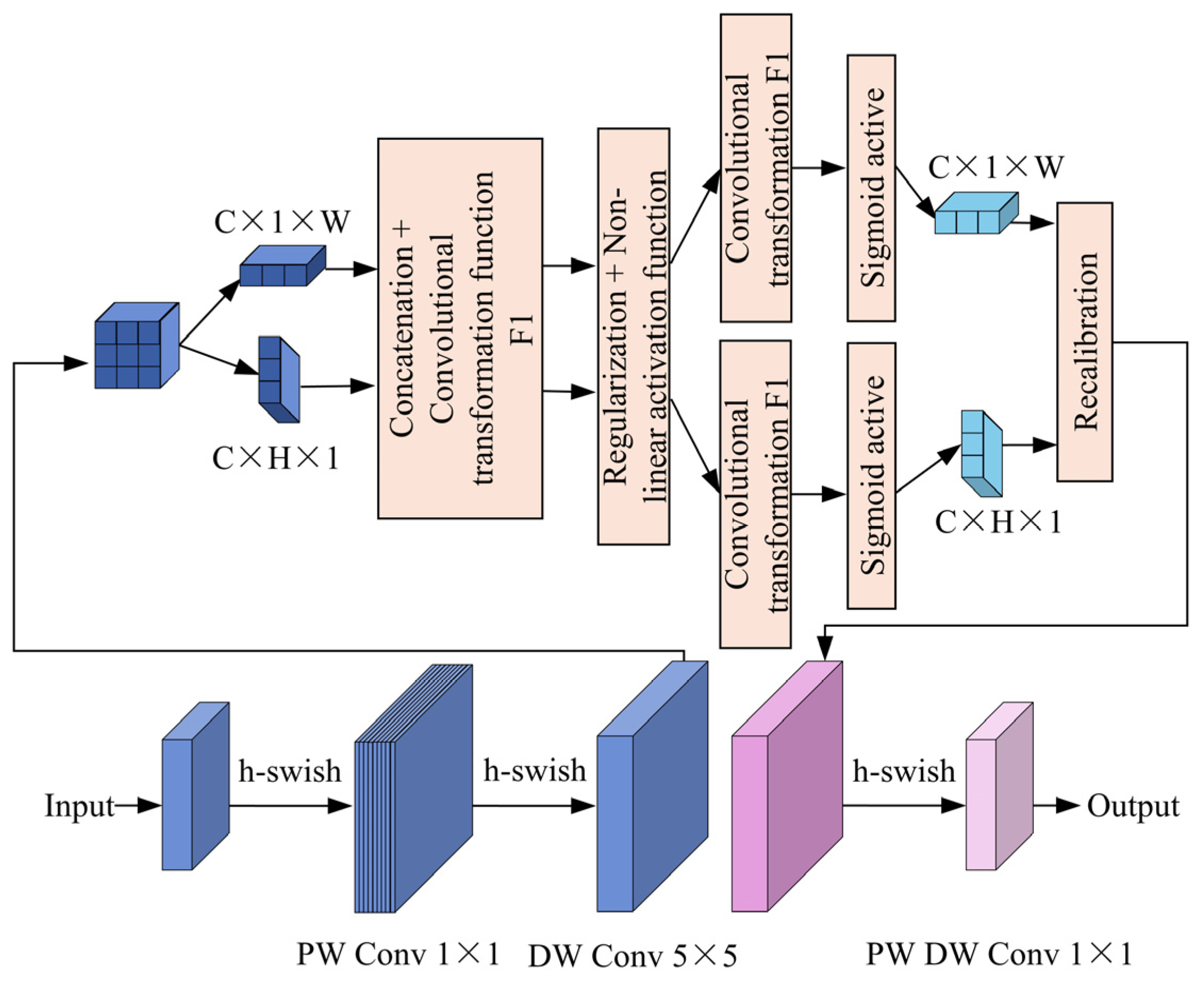
3.1. MobileNetV3-CA Backbone Module
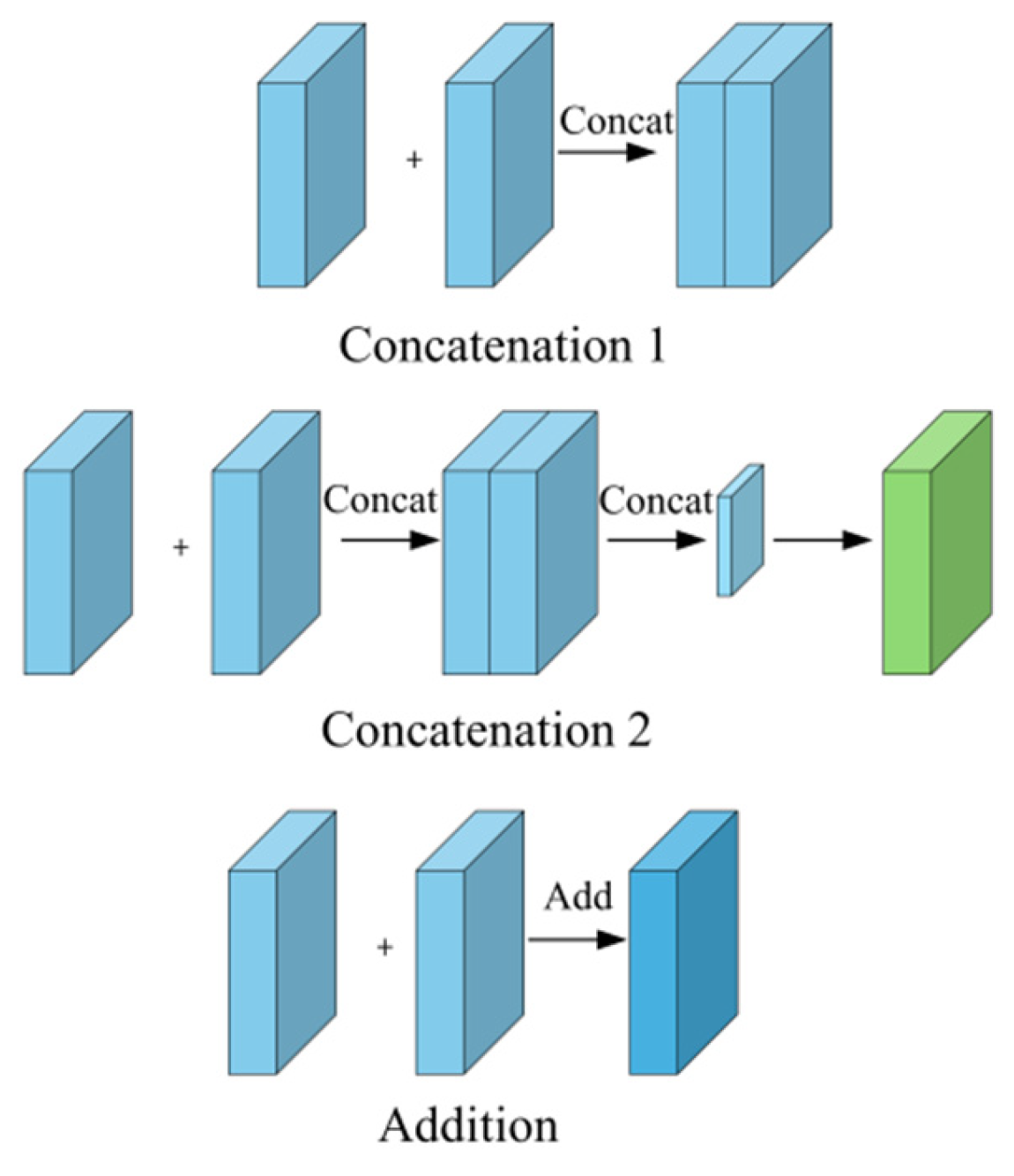
3.2. Dual-Stream Feature Fusion Module
3.3. CBAM Decoder
4. Experiment and Result Analysis
4.1. Experimental Environment
4.2. Dataset
4.2.1. RGB Dataset
4.2.2. Polarization Defect Dataset
4.3. Evaluation Metrics
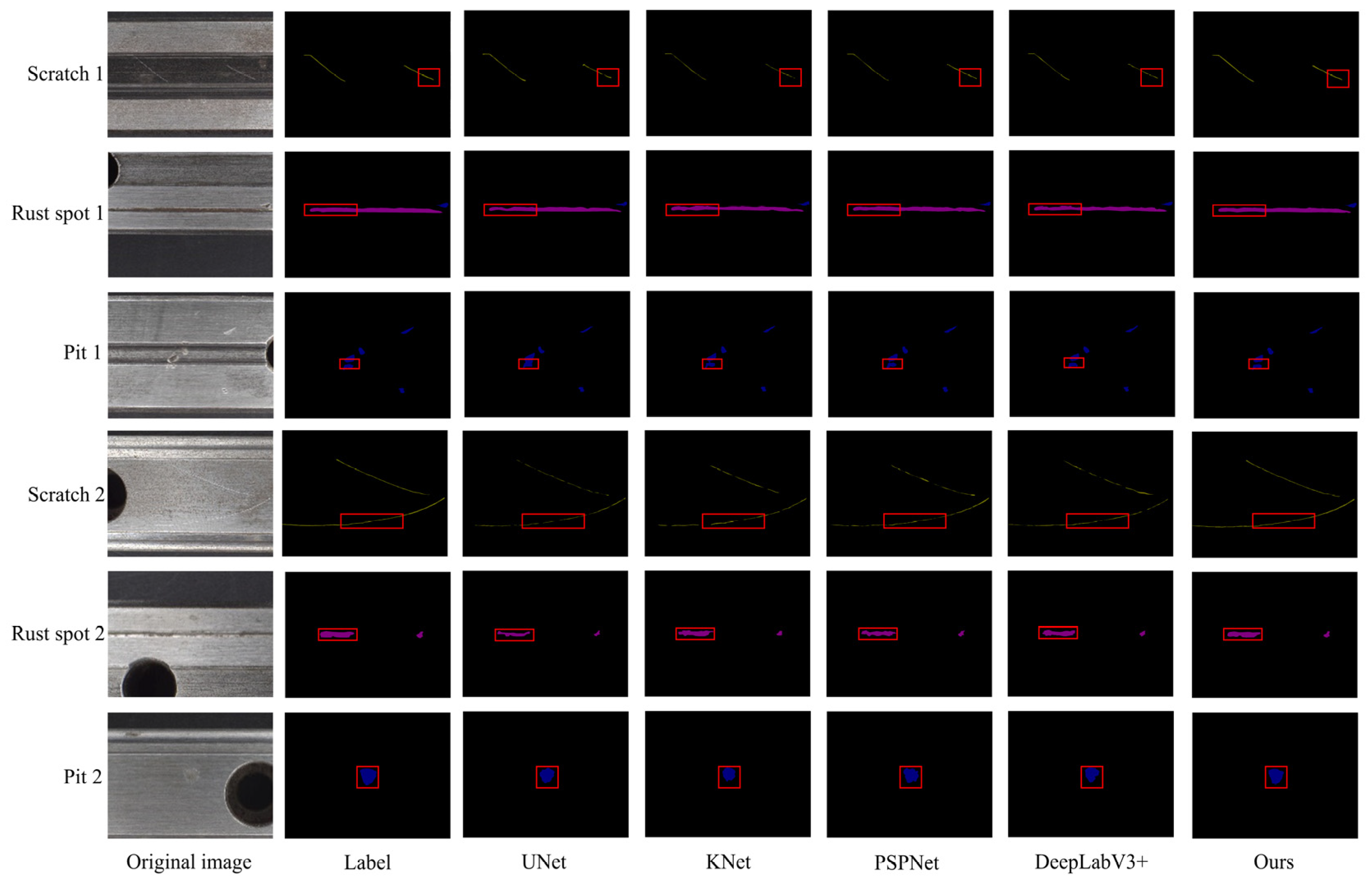
4.4. Performance Comparison
4.5. Ablation Experiment
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, Y.B.; Kong, W.B.; Chen, X. Survey of steel surface defect detection research. Softw. Guide 2024, 23, 203–211. [Google Scholar]
- Yu, Z.; Wu, X.; Gu, X. Fully convolutional networks for surface defect inspection in industrial environment. In Computer Vision Systems: 11th International Conference, ICVS 2017, Shenzhen, China, 10–13 July 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2007; pp. 417–426. [Google Scholar]
- Gang, S.; Liu, B.S.; Guo, X.W. Improved lightweight steel surface defect detection algorithm based on YOLOv8. Electron. Meas. Technol. 2025, 24, 74–82. [Google Scholar]
- Li, Z.; Li, J.; Dai, W. A two-stage multiscale residual attention network for light guide plate defect detection. IEEE Access 2021, 9, 2780–2792. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F.; Wang, Z.; Jia, L. Hybrid deep learning architecture for rail surface segmentation and surface defect detection. Comput.-Aided Civ. Infrastruct. Eng. 2021, 37, 227–244. [Google Scholar] [CrossRef]
- Hao, J.; Jia, M. Detection and recognition method of small defects in workpiece surface. J. Southeast Univ. 2014, 44, 735–739. [Google Scholar]
- Ding, Y.; Ye, J.; Barbalata, C.; Oubre, J.; Lemoine, C.; Agostinho, J.; Palardy, G. Next-generation perception system for automated defects detection in composite laminates via polarized computational imaging. arXiv 2021, arXiv:2108.10819. [Google Scholar]
- Deng, H.; Cheng, J.; Liu, T.; Cheng, B.; Zhao, K. Research on flaw detection of transparent materials based on polarization images. In Proceedings of the 2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), IEEE, Weihai, China, 14–16 October 2020. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Online, 6 October 2018. [Google Scholar]
- Song, Z.; Huang, X.; Ji, C.; Zhang, Y.; Chao, Z.; Peng, Y. Cross-domain fine grained strip steel defect detection method based on semi-supervised learning and Multi-head Self Attention coordination. Comput. Electr. Eng. 2025, 121, 109916. [Google Scholar] [CrossRef]
- Han, Y.; Li, X.; Cui, G.; Song, J.; Zhou, F.; Wang, Y. Multi-defect detection and classification for aluminum alloys with enhanced YOLOv8. PLoS ONE 2025, 20, e0316817. [Google Scholar] [CrossRef]
- Peng, J.; Shao, H.; Xiao, Y.; Cai, B.; Liu, B. Industrial surface defect detection and localization using multi-scale information focusing and enhancement GANomaly. Expert Syst. Appl. 2024, 238, 122361. [Google Scholar] [CrossRef]
- Peng, X.; Kong, L. Detection and characterization of defects in additive manufacturing by polarization-based imaging system. Chin. J. Mech. Eng. 2023, 36, 110. [Google Scholar] [CrossRef]
- Du, J.; Zhang, R.; Gao, R.; Nan, L.; Bao, Y. RSDNet: A new multiscale rail surface defect detection model. Sensors 2024, 24, 3579. [Google Scholar] [CrossRef] [PubMed]
- Bai, S.; Yang, L.; Liu, Y. A vision-based nondestructive detection network for rail surface defects. Neural Comput. Appl. 2024, 36, 12845–12864. [Google Scholar] [CrossRef]
- Chao, C.; Mu, X.; Guo, Z.; Sun, Y.; Tian, X.; Yong, F. IAMF-YOLO: Metal Surface Defect Detection Based on Improved YOLOv8. IEEE Trans. Instrum. Meas. 2025, 74, 5016817. [Google Scholar] [CrossRef]
- Han, L.; Li, N.; Li, J.; Gao, B.; Niu, D. SA-FPN: Scale-aware attention-guided feature pyramid network for small object detection on surface defect detection of steel strips. Measurement 2025, 249, 117019. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y.; Chang, D.; Du, J. SS-FDPNet: A Self-supervised Denoising Network for Radiographic Images of Ship Welds. IEEE Sens. J. 2025, 25, 14235–14251. [Google Scholar] [CrossRef]
- Safari, K.; Rodriguez Vila, B.; Pierce, D.M. Automated Detection of Microcracks Within Second Harmonic Generation Images of Cartilage Using Deep Learning. J. Orthop. Research. 2025, 43, 1101–1112. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, J.; Li, C. CPIFuse: Toward realistic color and enhanced textures in color polarization image fusion. Inf. Fusion 2025, 120, 103111. [Google Scholar] [CrossRef]
- Lu, Y.; Tian, J.; Su, Y.; Liu, J.; Hao, C.; Yue, C.; Yang, X. Polarization-aware Low-light Image Enhancement for Nighttime Intelligent Vehicles. IEEE Trans. Intell. Veh. 2024, 1–14. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, P.; Wang, N.; Liu, T. A lightweight theory-driven network and its validation on public fully polarized ship detection dataset. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3755–3767. [Google Scholar] [CrossRef]
- Kong, F.; Fan, X.; Guo, X.; Deng, X.; Chen, X.; Guo, Y. Design of an Imaging Polarized Skylight Compass Using Mechanical Rotation. IEEE Sens. J. 2024, 24, 37809–37821. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Online, 6 October 2018; pp. 3–19. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Ta, M. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G.; Gang, S.; Enhua, W. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Perazzi, F.; McWilliams, B.; Sorkine-Hornung, A.; Sorkine-Hornung, O.; Schroers, C. A fully progressive approach to single-image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 864–873. [Google Scholar]
- Zhou, Y.; Xu, Y.; Du, Y.; Wen, Q.; He, S. Pro-pulse: Learning progressive encoders of latent semantics in gans for photo upsampling. IEEE Trans. Image Process. 2022, 31, 1230–1242. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Kwon, H.; Kim, Y.; Hwang, S.J. Platypus: Progressive local surface estimator for arbitrary-scale point cloud upsampling. Proc. AAAI Conf. Artif. Intell. 2025, 39, 4239–4247. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2025. [Google Scholar]
- Xu, S.; Yuan, H.; Shi, Q.; Qi, L.; Wang, J.; Yang, Y.; Yang, M.H. Rap-Sam: Towards Real-Time Rap-sam: Towards real-time all-purpose segment anything. arXiv 2024, arXiv:2401.10228. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect Type | Number of Data |
|---|---|
| Pits | 215 |
| Rust spots | 145 |
| Scratches | 360 |
| Total | 720 |
| Dataset | Original Data | Augmented Data | Training Data | Test Data |
|---|---|---|---|---|
| RGB | 720 | 2160 | 1728 | 432 |
| Polarization | 720 | 2160 | 1728 | 432 |
| Model | IoU of Each Defect Label | mIoU | m-Pre | m-Re | Flops (GB) | Param (M) | F1 | FPS | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Background | Scratch | Rust Spot | Pit | ||||||||
| UNet | 99.56 | 67.45 | 76.86 | 90.33 | 83.55 | 90.14 | 91.94 | 182.93 | 24.89 | 91.03 | 18.76 |
| KNet | 99.66 | 69.26 | 77.63 | 94.93 | 85.37 | 91.04 | 91.69 | 281.28 | 69.76 | 91.36 | 24.61 |
| PSPNet | 99.56 | 63.76 | 72.54 | 87.46 | 80.83 | 90.46 | 87.74 | 18.8 | 105.38 | 89.08 | 13.12 |
| DeepLabV3+ | 99.63 | 68.53 | 77.21 | 89.19 | 83.64 | 90.32 | 90.58 | 67.54 | 41.21 | 90.47 | 16.64 |
| Ours | 99.86 | 72.64 | 78.31 | 96.97 | 86.87 | 91.53 | 93.14 | 38.54 | 28.21 | 92.33 | 29.63 |
| Experiment No. | M1 | M2 | M3 | mIoU (%) | mF1 (%) | Flops (GB) | Params (M) | FPS |
|---|---|---|---|---|---|---|---|---|
| 1 | 83.64 | 90.72 | 67.54 | 41.21 | 16.64 | |||
| 2 | ✓ | 83.79 (+0.15) | 91.29 (+0.57) | 19.61 | 17.82 | 21.34 | ||
| 3 | ✓ | 86.39 (+2.75) | 91.36 (+0.64) | 167.23 | 74.71 | 10.38 | ||
| 4 | ✓ | 85.07 (+1.43) | 91.57 (+0.85) | 73.22 | 46.29 | 13.25 | ||
| 5 | ✓ | ✓ | 86.57 (+2.93) | 91.87 (+1.15) | 35.83 | 23.22 | 23.23 | |
| 6 | ✓ | ✓ | 85.48 (+1.84) | 92.05 (+1.33) | 21.22 | 22.80 | 24.72 | |
| 7 | ✓ | ✓ | ✓ | 86.87 (+3.23) | 92.33 (+1.61) | 38.54 | 28.21 | 29.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Y.; Chen, J.; Wu, P.; Zhong, H.; Deng, Z.; Sun, D. Enhanced Rail Surface Defect Segmentation Using Polarization Imaging and Dual-Stream Feature Fusion. Sensors 2025, 25, 3546. https://doi.org/10.3390/s25113546
Pan Y, Chen J, Wu P, Zhong H, Deng Z, Sun D. Enhanced Rail Surface Defect Segmentation Using Polarization Imaging and Dual-Stream Feature Fusion. Sensors. 2025; 25(11):3546. https://doi.org/10.3390/s25113546
Chicago/Turabian StylePan, Yucheng, Jiasi Chen, Peiwen Wu, Hongsheng Zhong, Zihao Deng, and Daozong Sun. 2025. "Enhanced Rail Surface Defect Segmentation Using Polarization Imaging and Dual-Stream Feature Fusion" Sensors 25, no. 11: 3546. https://doi.org/10.3390/s25113546
APA StylePan, Y., Chen, J., Wu, P., Zhong, H., Deng, Z., & Sun, D. (2025). Enhanced Rail Surface Defect Segmentation Using Polarization Imaging and Dual-Stream Feature Fusion. Sensors, 25(11), 3546. https://doi.org/10.3390/s25113546