1. Introduction
The transmission of digital videos over error-prone channels corrupts the bitstream, causing an unpleasant effect on objective video quality. Every time a video is delivered to an end user, it is first passed through various processing platforms to get encoded, compressed, digitized, quantized, decompressed, decoded, and transmitted through various communication channels. The quality of the video is a measure of the amount of deterioration in the video caused by any processing or transmission system when compared to the original video. It determines the extent to which the video has changed its originality after going through all of these processes. The appearance and motion of objects seem smooth in high-quality videos. Errors during transmission cause degradation in the smoothness, resulting in lower video quality.
There are three fundamental security services that can be compromised during the communication of data over a network due to malicious attacks and transmission errors. Confidentiality ensures the privacy and secrecy of data and guards against illegal access to data. Integrity refers to the completeness of transmitted data and guarantees that the authorized users have been given all of the relevant information. Availability ensures that the required data must be provided to the user at the requested time. When a video is transmitted over an error-prone network, its integrity may be affected, as the received video might be altered due the encountered errors, resulting in modified video contents. The proposed method provides an efficient technique for the detection and recovery of such errors to compensate the originality of the video. Furthermore, in advanced multimedia systems, ensuring data confidentiality and reliability has become increasingly crucial. As devices evolve to be faster and resource-constrained, it is vital to enhance their resistance to attacks without introducing additional hardware complexity or increasing the computational cost. Thus, our proposed framework ensures the confidentiality and integrity of the video against security threats and errors by merging encryption and decryption with error correction within the video coding process, reducing the complexity of joint schemes to enable efficient implementation.
Video quality can be measured either subjectively or objectively.
Subjective video quality is the assessment of video quality from the end user’s perspective. It is performed by asking a particular user their opinion about the quality of the video at the receiving end after passing through all of the processing stages. Subjective video quality assessment is highly dependent on the observer, the environment in which the observation is conducted, and the elements that are considered to deduce the results by the observer (user preferences in terms of color, brightness, display size, or resolution).
Objective video quality is the measure of quality degradation of the video as it goes through a number of processes, including encoding, compression, and transmission. Calculating the mean square error (MSE), signal-to-noise ratio (SNR), peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and video multimethod assessment fusion (VMAF) is a commonly used mathematical method to predict video quality [
1,
2]. Objective video quality evaluation techniques can be categorized as full reference (FR), reduced reference (RR), or no reference (NR) depending on the amount of information from the original video being used for comparison [
3]. FR techniques compare each and every pixel of the original and impaired videos, unaware of the processes applied in between. RR procedures use some of the characteristics from both of the videos for comparison. NR methods attempt to recover the impaired video without knowing anything about the original video [
4,
5,
6].
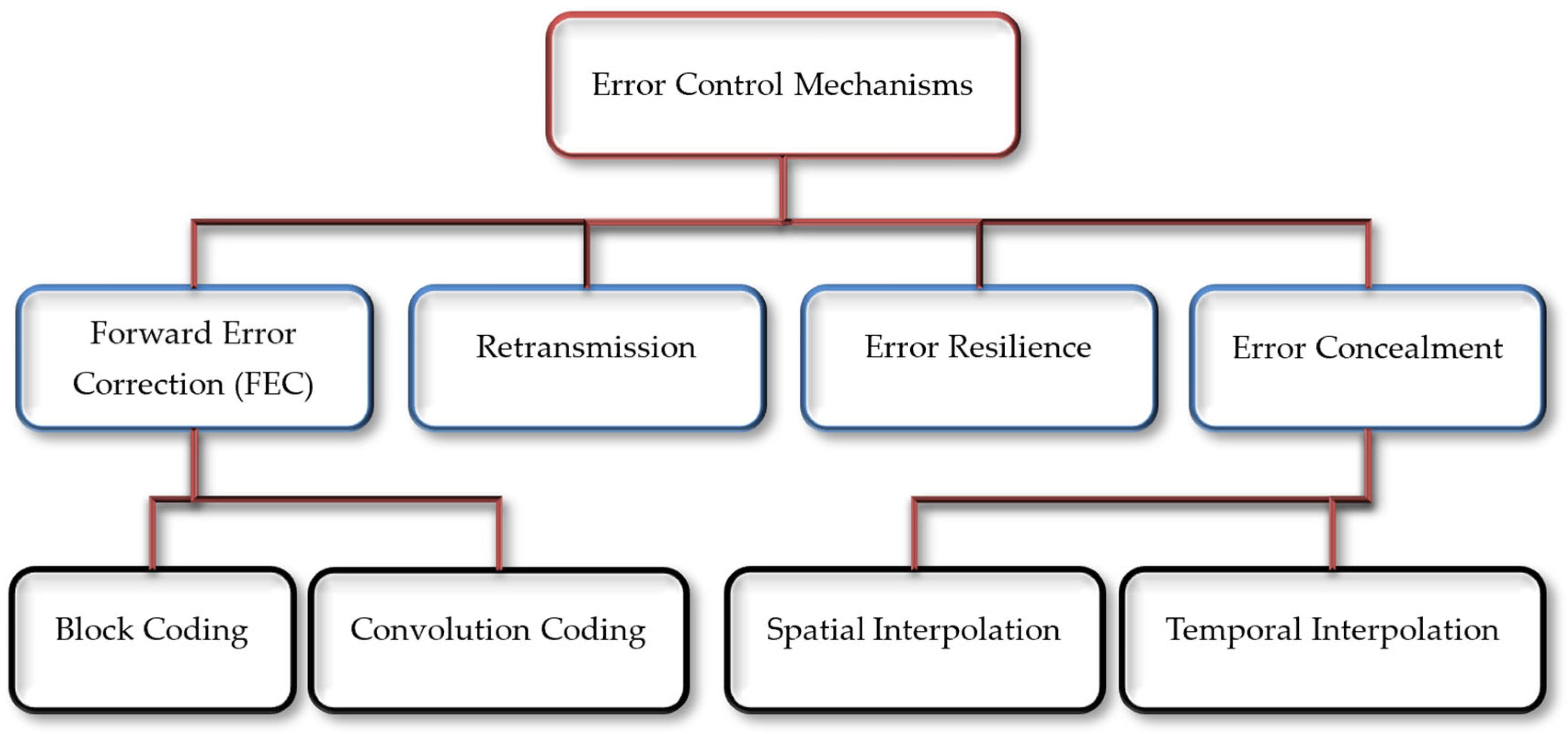
Error correcting codes (ECC) are used while encoding the data before transmission to identify any change that may occur during transmission. ECC for video applications can be categorized into four different mechanisms: forward error correction (FEC), retransmission, error resilience (ER), and error concealment (EC) [
7]. A hierarchical representation of error controlling schemes is shown in
Figure 1. FEC techniques add redundant bits to the original bitstream for error recovery. FEC can be carried out in two ways; block coding and convolution coding. Block codes work on the data in fixed-sized blocks, whereas convolution codes work on bitstreams of arbitrary size. In retransmission techniques, the receiving device sends an acknowledged signal to the transmitting device to acknowledge the received or lost packet and requests the sender to retransmit the data. It is applicable only when the number of errors is small, e.g., the automatic repeat request (ARQ) needs a backchannel between two communicating devices and takes additional time to retransmit the data, which makes it unsuitable for interactive real-time video transmission, broadcast, unicast, and multicast applications [
8,
9]. ER methods are used to prevent error propagation in a bitstream during transmission. EC provides methods for hiding the effects of errors or packet loss and presents the visual information in such a way that makes those errors unnoticeable by the user [
10]. Spatial interpolation regenerates the missing data in intra-coded frames using neighboring pixels, while temporal interpolation is used to reconstruct lost data in inter-coded frames using other reference frames [
11,
12].
An FEC technique is used in our work to recover errors that occur during transmission to avoid the need to retransmit the data. These errors may affect the quality, visibility, and completeness of information by causing blurriness, color alteration, false edges, jagged motion, flickering, and chrominance in the video sequence [
13]. It makes broadcasting, video streaming, and real-time applications more efficient. FEC is generally used for the transmission of video, audio, and other signals for which a transmission backchannel is not available and retransmission is not possible in case of error occurrence. Moreover, the huge size of video files will take a lot more time if retransmitted. So, FEC provides a better and time-saving mechanism to cover up the damage caused by these errors [
14]. Redundant bits are added to the data before transmission during the encoding process, which are used to indicate an error and provide a mechanism to find the location of the error for recovery while decoding the incoming data [
15].
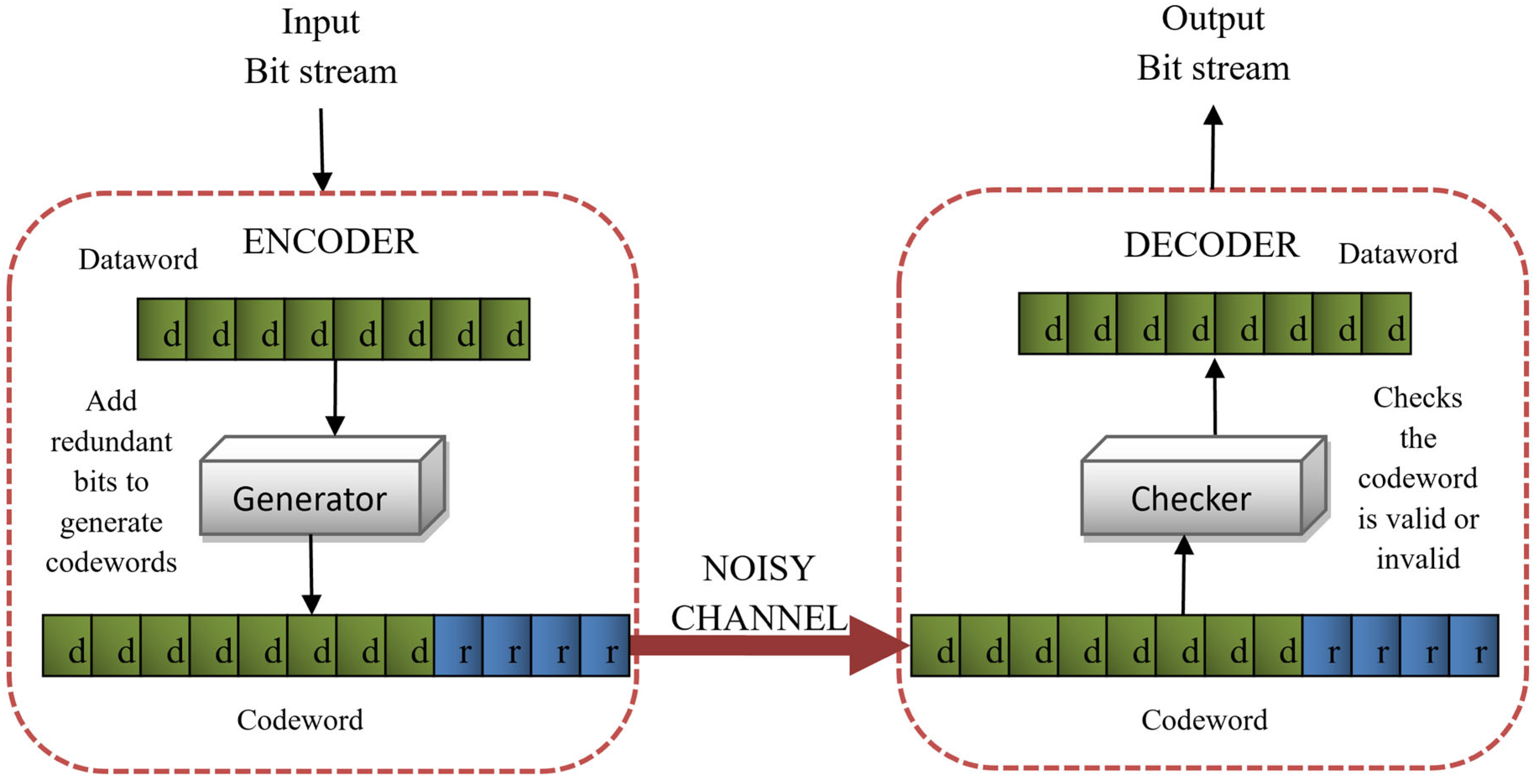
Figure 2 presents the general scheme we have adopted using the H.264/AVC video coding standard for FEC to reduce the effect of channel errors on objective video quality.
Secure transmission of multimedia content is crucial, as encrypting the entire video bitstream using encryption standards like the Advanced Encryption Standard (AES) is computationally complex, increasing latency and energy consumption due to pre-processing and post-processing operations. Selective encryption has emerged as an alternative that involves encrypting only the most sensitive and confidential contents of the video in compressed domain. This technique enables format compliance and preserves coding efficiency, providing a low-complexity solution for video transmission systems [
16,
17]. The integration of selective encryption with error correction within the video coding process aims at enhancing the overall robustness and efficiency of the proposed scheme. This joint approach provides enhanced security and improved reliability, as selective encryption ensures protection against access attacks, reducing the computational overhead while maintaining confidentiality, whereas FEC detects and corrects errors during transmission, ensuring video quality and integrity. This integrated framework reduces the overall complexity and computational requirements, and it protects against both security threats and transmission errors, including packet loss, data corruption, and unauthorized access. It ensures a higher quality of service (QoS), providing a better viewing experience for end users.
A variety of video codecs are used to implement compression techniques on huge-sized video to reduce the size during the encoding process before transmission. These codecs operate at the application layer (Layer 7) of the OSI model, which is responsible for providing services and interfaces so the application can communicate properly. Error correction at the application layer provides better support for real-time applications by maintaining a high quality of experience for users by minimizing the impact of transmission errors. In our work, the H.264/AVC codec encodes the video and reduces its size to accommodate the issues of limited bandwidth and storage capacity of the transmission channel [
18]. Selective encryption is preferred to encrypt only the selected elements of the video due to its large size, as this method facilitates processing and computational requirements while protecting the contents. Extra parity bits added by the FEC algorithm take more bandwidth than the actual data, but the video files are generally large in size, particularly the latest trend of FHD, UDH, and 4K videos, and require more time to retransmit in the case of any data loss or error. Thus, to compensate the quality of the video on the receiving side, an error correction mechanism is introduced in this work for reliable delivery of data.
The existing methods for error correction demand complex computations and require additional storage capacity and complex prediction methods. This method provides better error recovery with minimum computational cost and improved performance, reducing the effect of accidental disruptions on the perceptual quality of the video. It targets the challenges of ensuring reliable video transmission at the application layer, where the unique characteristics of video data and maintaining QoS necessitate FEC strategies for improved end-to-end reliability. The problem we aim to address is the degradation of video quality due to transmission errors that are not fully mitigated by the error correction mechanisms at lower layers.
The following research contributions are achieved through the proposed framework:
- 1:
Optimization of FEC Framework for Seamless Video Transmission System: This study proposes an FEC mechanism that robustly adjusts redundancy levels in response to real-time network conditions. This method minimizes the impact of packet loss and channel noise while optimizing bandwidth usage without requiring retransmissions.
- 2:
Improvement of Objective Video Quality Metrics: The proposed framework achieves measurable enhancements in PSNR and PSNR611 by integrating the proposed FEC framework with H.264/AVC video coding. The framework effectively addresses the challenges posed by variable video characteristics, such as motion, structure, and resolution.
- 3:
Integration of Selective Encryption and Error Correction within the Video Coding Process: The proposed technique combines the FEC mechanism with H.264/AVC syntax-based selective encryption and decryption algorithms using specific syntax elements of the video to ensure confidential and reliable video transmission system.
- 4:
Adaptiveness to Various Video Resolutions: This method is not limited to videos with a specific resolution and can be deployed on multiple video resolutions. Its working efficiency is tested on video sequences of CIF and HD resolution in our work and the results prove its adaptiveness to the resolution flexibility of videos.
- 5:
Effectiveness on Different Quality Perception Values on Video Quality: The proposed framework is implemented at different QP values to assess the effect on video quality. It shows that perception quality is inversely related to video quality.
The rest of this paper is structured as follows.
Section 2 reviews the related work on this topic.
Section 3 describes the materials and methods of the proposed framework.
Section 4 illustrates the results of the proposed framework on different test video sequences.
Section 5 provides a discussion and suggestions related to the outcomes of this work.
Section 6 concludes the paper by providing an overview of this work and its adaptiveness for quality enhancement due to error-prone channels in modern communication.
2. Related Work
A variety of solutions have been explored in the literature to mitigate video quality concerns over wireless networks. The integration of FEC techniques enables the receiver to detect and correct errors in real-time applications by embedding redundant bits into packets during transmission. It mitigates delay impacts, ensuring industrial wireless systems meet stringent latency and reliability requirements [
19]. Chen et al. [
15] proposed a novel RL-AFEC approach based on frame-level Reed–Solomon (RS) codes that can learn to optimize FEC paraments in real time to minimize latency and packet loss by automatically adjusting the redundancy rate for each frame. In [
17], the authors provide a survey on crypto-coding, joint encryption, and error correction techniques to simultaneously ensure the confidentiality and reliability of data transmission. They classify the joint schemes into three categories: joint encryption and channel coding (JECC), joint encryption and source coding (JESC), and joint encryption and network coding (JENC). JECC includes code-based encryption, lattice-based encryption, and hash-based encryption; JESC includes compressive sensing-based encryption and transform domain encryption; and JENC encompasses network coding-based encryption and secure network coding. Our proposed work is based on JESC transform domain encryption, which combines encryption and source coding to compress and encrypt data simultaneously using the H.264/AVC video codec.
Bagheri et al. [
20] proposed a novel joint encryption, channel coding, and modulation scheme, called the quasi-cyclic low-density parity check (QC-LDPC) lattice code, to provide improved security, better error correction, and efficient transmission over wireless networks. Their approach implements lattice-based encryption to offer semantic security, QC-LDPC codes for robust error correction, and a lattice-based modulation scheme for robust transmission. However, it requires complex computations and secure key management, which we have focused on to optimize in our work. A novel method that adapts to changing channel conditions using deep learning was designed in [
21]. This adaptive FEC approach was based on long short-term memory (LSTM) neural networks, employing frame-level RS coding to dynamically select appropriate redundancy levels to achieve higher VMAF scores, but it requires significant computational resources and a large training dataset to successfully implement, which may be difficult to obtain.
A combination of subjective and objective video quality assessments was conducted in [
22]. For subjective quality assessment, a user study with 40 participants was conducted, whereas various FR and NR quality metrics, including PSNR, SSIM, MS-SSIM, ST-RRED, FAST, and VMAF, were used for objective video quality assessment. The authors suggested the use of the H.264 codec over newer codecs such as HEVC, VP9, and AV1, as 91% of video streaming services utilize it and most browsers and devices do not provide full support for advanced standards. The joint-channel rate distortion (RD) optimization method presented in [
23] minimizes end-to-end distortion of video signals and optimizes bitrate allocation among different video frames using a combination of RS and convolutional codes. Although it protects video signals against channel errors, it is not suitable for scalable high-resolution videos and involves complex computations. In [
24,
25], the authors evaluated the performance of various video coding standards, including H.264/AVC, H.265, AV1, VP9, HEVC, and VVC, to check the similarity between original and compressed videos using a machine learning-based approach to predict optimal encoding paraments such as video sequence, resolution, and bitrate. Their work discussed several quality assessment metrics, such as PSNR
611, SSIM, and VMAF, and suggested the use of PSNR
611 objective video quality metrics over other methods. Context-adaptive binary arithmetic coding (CABAC) and context-adaptive variable-length coding (CAVLC), two H.264 codec entropy coders, were discussed to examine the comparative effect of channel errors on selectively encrypted videos in [
26]. They concluded that CAVLC was more susceptible to channel errors than CABAC in analyzing the combined effect of selective encryption and compression on video quality. Since all advanced and hybrid encoders support CABAC, this entropy encoder was selected for developing the proposed error correction technique in our work.
A selective encryption method for H.264/AVC videos based on CABAC is presented in [
27], involving zig-zag scanning followed by encryption of discrete cosine transform (DCT) coefficients, which significantly impacts the texture and content of videos during compression. The scrambling process efficiently provides confidentiality by rearranging macroblocks (MB) of data in a way that makes unauthorized access difficult. An H.264/AVC syntax-based selective encryption method utilizing multiple syntax elements, such as residual coefficients (RCs), transform coefficients (TCs), and motion vectors (MVs), to scramble video contents is presented in [
28]. Another selective encryption scheme using the CABAC encoder for VVC is proposed, which identifies TCs, MVs, intra-prediction, and inter-prediction modes as sensitive syntax elements. This scheme encodes syntax elements and selects encoded bins for encryption, which are then encrypted using a symmetric-key encryption algorithm [
16]. Selective encryption schemes can be categorized as syntax element-based, bitstream-based, and hybrid encryption. Syntax element-based encryption encrypts specific syntax elements; bitstream-based approaches encrypt the entire bitstream, including syntax and non-syntax elements; whereas hybrid approaches combine both of them to provide robust security. An H.265/HEVC-based hybrid scheme of symmetric-key selective encryption was proposed using the CABAC encoder, which targets sensitive syntax elements including the transform unit (TU), motion vector differences (MVDs), intra-prediction modes (IPMs), inter-prediction modes (InterPMs), and coding unit (CU) flags. The quality of encrypted frames is evaluated through PSNR and SSIM [
29]. In [
30], the authors proposed AES-CTR encryption built upon an improved CABAC algorithm to selectively encrypt syntax elements, including the suffixes of sign bits, absolute values of residuals of MVDs, DCT coefficients, and QPs. Their proposed approach encrypts specific parts of the video, ensuring sufficient protection from unauthorized access while maintaining format compliance, thus achieving a balance between security and efficiency, making it suitable for real-time applications. Similarly, a 4D hyperchaotic algorithm using the CFB mode of AES is implemented in [
31] for privacy protection of videos based on different syntax elements (IPM, MVD, residual coefficients, and delta QPs). PSNR and SSIM reference indicators are used to measure the perceived effect of the video.
A selective encryption scheme for H.264/AVC video content is proposed in [
32], encrypting only critical parts such as IPMs, MVDs, and RCs. It balances security and efficiency and ensures format compliance utilizing the chaos-based approach to offer reduced computational overhead. However, its security is dependent on the chaotic system and requires careful consideration of key management and security threats. In [
33], the authors review existing selective encryption schemes in HEVC and suggest a selective encryption method that generates encrypted bitstreams, records syntax elements, and reconstructs original elements to design a pseudo-key stream for decryption. Experimental analysis is conducted across various QPs to assess the effectiveness of the scheme. The authors in [
34] present a secure and efficient data hiding method in encrypted H.264/AVC bitstreams, using IPMs and MVDs to protect information related to texture and motion. An additional security layer is achieved through RCs. However, data hiding may lead to potential video quality degradation and additional computational complexity. Several schemes proposed in [
35] encrypt video content by scrambling the IPMs of intra-coded macroblocks. Exclusive OR (XOR) is used to offer data security. The authors of [
36] provide a review of existing and encryption techniques for H.264/AVC video encoders, which are categorized on the basis of the stages where the encryption is applied: before compression, through compression, and after compression. These encryption techniques are based on IPMs, residual data, MVDs based on XOR operation, transformation, and the entropy coding process.
The existing literature suggests numerous schemes of error recovery for enhancing video quality that involve complex mathematical computations and result in high computational cost. The method proposed in this work involves a bit-inversion mechanism that detects the error bit from the bitstream and flips it to recover the error and improve video quality at the receiving end. The proposed technique additionally merges the error recovery process with syntax-based encryption to preserve the confidentiality and integrity of videos for improved user experience.
3. Materials and Methods
In this study, we have incorporated the novel approach of forward error correction while crypto-encoding videos before transmission using the H.264/AVC encoder to recover the errors encountered during transmission, resulting in improved objective video quality. Additionally, the proposed work enhances transmission security by selectively encrypting videos using specific syntax elements to protect against unauthorized access. The details are described in subsequent subsections.
3.1. Encoding and H.264/AVC Syntax-Based Selective Encryption
Due to the huge size of videos, they must be compressed to reduce their size to accommodate bandwidth limitations. Video is a series of frames that rapidly change over a given time to illustrate moving objects. Video codecs arrange these video frames in groups, known as a group of pictures (GOP), which are compressed and encoded as independent sets of video frames. Each frame is composed of a set of slices, which are composed of macroblocks. These macroblocks are further divided into a number of blocks. Each macroblock is a 16 × 16 array of pixels. A block is represented by a matrix of 4 × 4 pixels, which is the smallest unit of compression system. The H.264 video codec has two forms of entropy coders, both of which perform lossless compression: context-adaptive binary arithmetic coding (CABAC) and context-adaptive variable-length coding (CAVLC). Both of these forms are context adaptive, which means that compression is dependent on the patterns of the coefficients that are extracted from the coefficient matrix formed after transform coding and quantization. As both of these entropy coders perform lossless coding, the resultant bitstream is very close to the original input stream. The purpose of this study was error recovery to improve the visual quality of the received videos that has been compromised during transmission. CAVLC is more sensitive to errors, whereas CABAC is not much affected by channel errors, which makes it a better choice for implementing the proposed FEC algorithm [
26].
There are multiple residual parameters of the H.264/AVC CABAC entropy coder, including TCs, MVDs, delta QPs, and the arithmetic signs of TCs and MVDs. We have used the sign bits of TCs and MVDs for XOR-based selective encryption at the final step of the encoding process in our suggested framework to preserve format compliance and security during transmission. The video frame is divided into 4 × 4 blocks. The bits within a 4 × 4 block are first shuffled and the TCs and MVDs are selected for applying XOR encryption on the encoded bitstream of the shuffled blocks using a 128-bit encryption key. Let
,
, and
k represent the ciphered MVDs, ciphered TCs, and the key, respectively, then the ciphertext is generated through the bitwise XOR encryption process
E, as follows:
The process is reversed on the receiving end by the decryption algorithm
D, where the symmetric key is XORed with the ciphered MVDs and TCs of each block after extraction of the encrypted MVDs and TCs to reconstruct the original bitstream by combining the decrypted blocks, as follows:
where
and
are the original MVDs and TCs after decryption used to reconstruct the original block.
3.2. Redundancy
The most basic concept in error control mechanisms is redundancy. When the digital data are transmitted in the network, a few redundant bits are added to the original data during the encoding process. These redundant bits are used to detect and correct the errors that have occurred during transmission. These additional bits are added on the sending side, which are then removed at the receiving side after the transmission is complete. Redundant bits are also known as parity bits or check bits. Parity bits add checksums in the data that enable the receiving device to check the occurrence of errors. A parity check counts the number of 1s in the dataword. There are two methods to add redundant bits on the basis of a parity check: even parity and odd parity. In even parity, the parity bit is assigned a value of 1 if the number of bits having 1s is odd; if the number of bits having 1s is even, then 0 is assigned to the parity bit. So the total number of 1s will be even to maintain even parity. In odd parity, if the number of 1s is even, the parity bit is set to 1 to make it odd; if the number of 1s is odd, 0 is assigned to make odd parity.
3.3. Block Coding
In our work, we used a block coding FEC method, which works on the macroblock of a video frame. In
block coding, the message is divided into blocks of fixed size called
datawords. A few redundant bits are added to each dataword to generate
codewords. Redundancies can be added by using different scenarios. It can either be added to the start of the message, at the end of the message, or somewhere in between [
19].
Figure 3 shows the basic mechanism of error detection in block coding.
Let d be the number of bits in a dataword and r be the number of added redundant bits, the resultant block of c-bits is called a codeword, where c = d + r. d-bits can represent 2d different datawords. Similarly, c-bits can represent 2c different combinations of codewords. Since c > d, the number of codewords would be greater than the number of datawords. For each dataword, there exists only one codeword, so there will be 2c − 2d extra codewords that are considered as invalid. A codeword is accepted on the receiving end only if it is a valid codeword, or else it is discarded by the decoder.
3.4. The Gilbert–Elliott Channel Model
We implemented the Gilbert–Elliott channel model in our work to model the noisy communication channel [
37]. This model is computationally efficient and produces an error burst to demonstrate the accurate effect of errors on an application without involving the physical processes [
38,
39,
40]. These errors may result in loss or alteration in packets, frames, or bits from the transmitted bitstreams [
41,
42].
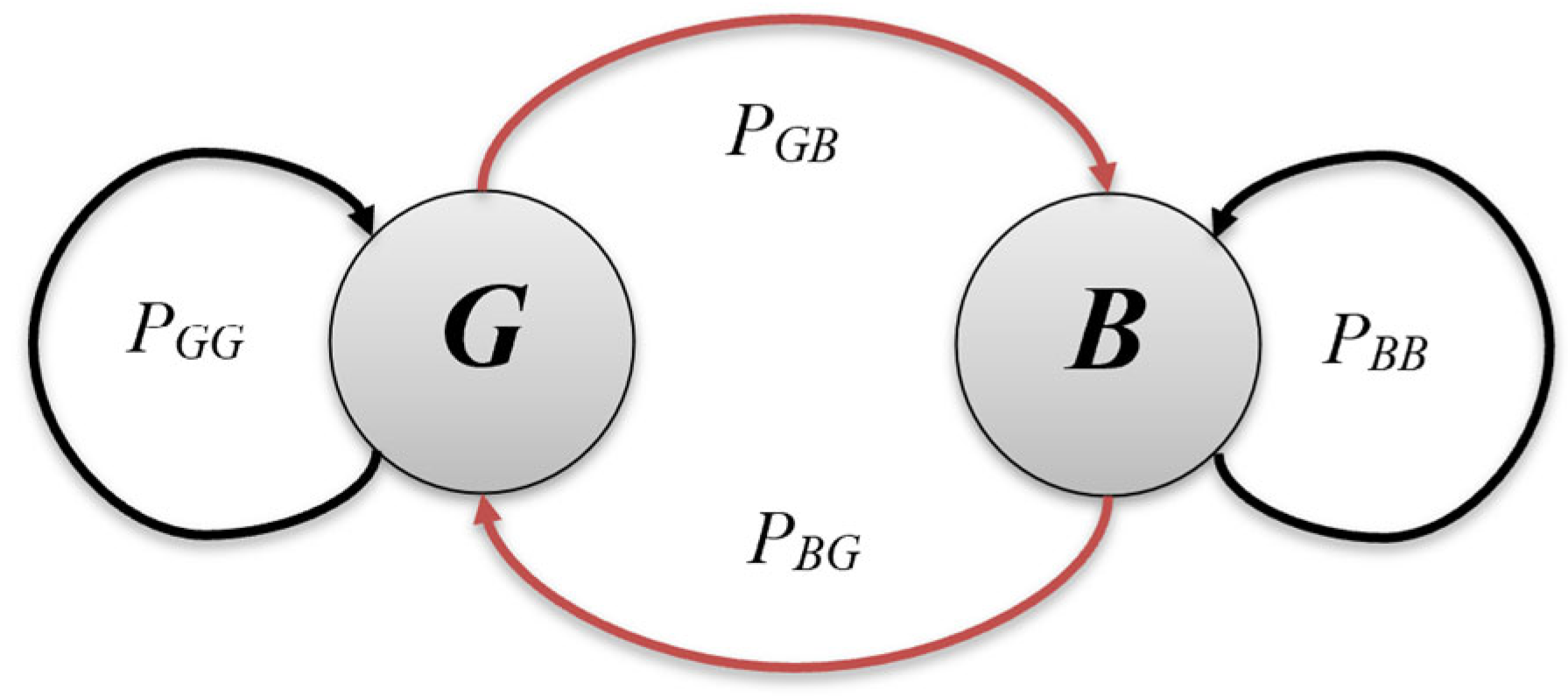
The Gilbert–Elliot (GE) channel model is a discrete time hidden Markov chain model that consists of two states, i.e., the good state and the bad state. Suppose that S = {G, B} is the state space of the wireless communication channel, where G and B are the good and the bad states, respectively. The probability of error occurrence in good state G, denoted by P(G), is relatively lower than the probability of error occurrence in bad state B, denoted by P(B). When the error occurrence in the good state does not happen, then P(G) will be 0, indicating the error-free transmission of bits through the channel, and P(B) will become 1, indicating the occurrence of error in the bad state. In order to generate fewer erroneous bits, it is assumed that P(G) > P(B), i.e., the good state is more likely to experience error bits than the bad state.
The probability of shifting from one state to the other state is known as
transition probability. Let
PGG be the probability that the next state is again a good state and
PBB be the probability that the next state is again a bad state.
PGG and
PBB are known as self-transition probabilities. Similarly,
PGB and
PBG denote cross-transition probabilities, i.e.,
PGB is the probability that the next state is bad state
B from the current state
G, whereas
PBG is the probability that the next state is a good state considering the present state
B. A state transition diagram of the GE channel model is given in
Figure 4.
The Gilbert–Elliot Model uses a two-state transition matrix of order two-by-two to determine the state transition probabilities. The two-state transition matrix determines the state transition probabilities and is represented by M in (5), as follows:
The sum of all probabilities from a particular state is always 1. Thus, from the state-transition diagram shown in
Figure 4, it is concluded that:
From (6), the self-transition probabilities (7) and cross-transition probabilities (8) can be calculated as follows:
The expected amount of time for which the channel remains in one state before moving to the other state (either in
G or
B) is known as the mean sojourn time of being in that state. There were only two states in our GE channel model; therefore, the mean sojourn times of good state
G and bad state
B are denoted by
TG and
TB, respectively. The mean state sojourn times
TG of state
G and
TB of state
B can be estimated by Equation (9), as follows:
The probability that the channel errors occur in steady state is known as the steady state probabilities, denoted by
PGG and
PBB depending on the steady state being
G or
B, respectively. Steady state means that the state of the channel remains unchanged. The probability of being in steady state
G (
PGG) and the probability of being in steady state
B (
PBB) are dependent on their mean sojourn times and are computed using (10):
The number of bit errors per unit time is known as the mean bit error rate (BER) (M
BER) and can be obtained by using the following equation:
It is assumed that
G state is error-free, meaning that
P(
G) = 0. All of the bits of the frame are likely to be transmitted correctly in the good state. The good state is considered error-free because it represents a period of time when the channel is in favorable condition with low error probability. This assumption allows the model to show a burst nature of the transmission channel by focusing on capturing the characteristics of the bad state where errors are more likely to occur. This simplification provides a reasonable approximation for communication system analysis [
43]. The probability of being in a good or bad state is dependent on
MBER [
44]. The GE model is used to introduce bit errors in transmitted bitstreams, assuming that the occurrence of bit errors is independent of each other. It calculates the steady state probability, transition probability, and bit error rate at each state. In our study, all of the bits in the frames that are in state
G are supposed to be transmitted without any error. This reduces the computational cost of the traditional GE model.
3.5. Error Detection and Correction
We proposed a block coding mechanism for error control that detects the single bit error in each block of transmitted data. Our aim was to maximize error recovery by dividing the frame into blocks of specific length and adding redundancies, as shown in
Figure 3. The
generating function in the encoder generates the codewords by adding parity bits to each macroblock of the video frame. The incoming bitstream is then compared to the list of valid codewords, which is already being sent to the decoder for detecting errors. The
checking function in the decoder performs this comparison. If the received codewords match the valid codewords, it means the data are error-free. Otherwise, an error has occurred that altered the bits during the transmission. Error detection simply indicates the presence of errors without revealing their quantity or location. Error correction is a bit complex, as it requires knowledge of both magnitude and location of errors. To correct any error, it is essential to know whether the data are transmitted error-free or are corrupted during transmission. Therefore, error detection precedes error correction, serving as a crucial step in ensuring data integrity.
3.6. Proposed Forward Error Correction Framework
Forward error correction is an error correcting technique in which the data are recovered from errors that occur during transmission. Unlike ARQ (automatic repeat request), when an error is detected, FEC restores the data that are affected by the channel errors without requesting retransmission from the sender. In FEC, redundant bits are added to the original bitstream by the FEC encoder. The decoder uses these redundant or additional bits to guess the original data in case the original bits are corrupted or lost during transmission. We inserted errors into YUV video sequences by implementing the GE channel error model with the help of the H.264/AVC CABAC entropy coder to test the working of our proposed FEC method, which can detect up to one error in each macroblock of the video frame. Each macroblock is a 16 × 16 array of pixels.
The proposed framework involves the following steps implemented, as shown in Algorithm 1, using the H.264/AVC CABAC entropy encoder to encrypt and then correctly guess and correct the errors that occurred due to a noisy channel to provide recovered data to the receiver. The H.264/AVC CABAC entropy coder was used via the JSVM software tool, developed by the Joint Video Team (JVT) of ITU-T and ISO/IEC, with contributions from Fraunhofer HHI, Berlin, Germany.
| Algorithm 1 Overall steps involved in proposed FEC algorithm |
| Step 1: | The original video frames are encoded by the H.264/AVC CABAC entropy coder before transmission to offer compression, encryption, and FEC. |
| Step 2: | Sign bits of MVDs and TC are selected from the residual data obtained from the entropy coder after compression, which are then extracted from the bitstream to apply H.264 syntax-based selective encryption using 128-bit key XORed with the selected syntax elements. |
| Step 3: | The encrypted bitstream of video data is encoded through our FEC algorithm at the sending device, which is then sent to the destination device through the noisy transmission channel simulated by the GE model. |
| Step 4: | The generating function of the FEC encoder divides the encrypted bitstream into d-bit data blocks, called datawords, and adds r = c − d parity bits to generate c-bits codewords, where r, c, and d represent parity bits, codewords, and datawords, respectively. |
| Step 5: | The crypto-encoded bitstreams of the codewords are transmitted over the noisy channel, which is employed using the Gilbert–Elliott model. |
| Step 6: | The checking function of the FEC decoder identifies the valid codewords after receiving the erroneous data at the receiving end. If the codeword is valid, its corresponding dataword is extracted. If the codeword is invalid, the algorithm tries to identify the location of the error by adding the position of the incorrect parity bit and flips the bit at that position. After correcting the possible error, the dataword is extracted from the codeword. |
| Step 7: | Ciphered MVD and TC is XORed using the symmetric key for decryption with the decoder. Decrypted blocks are then combined to regenerate the original blocks of the videos. |
The pseudocode of the
generating function performed at the sending end consists of the following steps listed in Algorithm 2.
| Algorithm 2 Pseudocode of generating function of proposed FEC performed at sender |
| INPUT: Video Frames |
| OUTPUT: H.264 encoded bitstream |
| 1: | Split the video bit stream into blocks of size d |
| 2: | for each block: |
| 3: | Generate codewords using bitstream, data block size d, and codeword length c |
| 4: | Calculate number if parity bits by r = c − d |
| 5: | for x = 0 to r − 1 |
| 6: | Insert parity bit rx at 2x position checks each alternate data bit and skips x data bit in the block to maintain even parity |
| 7: |
end for |
| 8: | end for |
Algorithm 3 lists the steps performed at the receiving end by the
checking function implemented by the decoder for error detection and correction.
| Algorithm 3 Pseudocode of checking function of proposed FEC framework performed at receiving end for error recovery |
| INPUT: H.264 encoded erroneous bitstream |
| OUTPUT: Recovered decoded video frames |
| 1: | Receive the codewords |
| 2: | if the codeword matches any valid codeword |
| 3: | Extract codewords by removing parity bits rx from position 2x (where x = 0, 1, 2, …) |
| 4: | Decode the dataword to obtain original video frames |
| 5: | else |
| 6: | Detect error |
| 7: | for each parity bit rx positioned at 2x (where x = 0, 1, 2, …) |
| 8: | Checks each alternate data bit and skips x data bit in the block to maintain even parity, i.e., number of 1s should be even, including the parity bit. |
| | if rx = expected-parity-bit then |
| | No error has occurred up to that parity bit |
| 9: | else if rx ! = expected parity bit (does not maintain even parity) then |
| 10: | Error has occurred |
| 11: | Add bit positions of all incorrect parity bits to obtain the position of error bit e |
| 12: |
if e = 0 then |
| 13: |
set e = 1 |
| 14: |
else |
| 15: |
set e = 0 |
| 16: |
end if |
| 17: |
end if |
| 18: |
end for |
| 19: | end if |
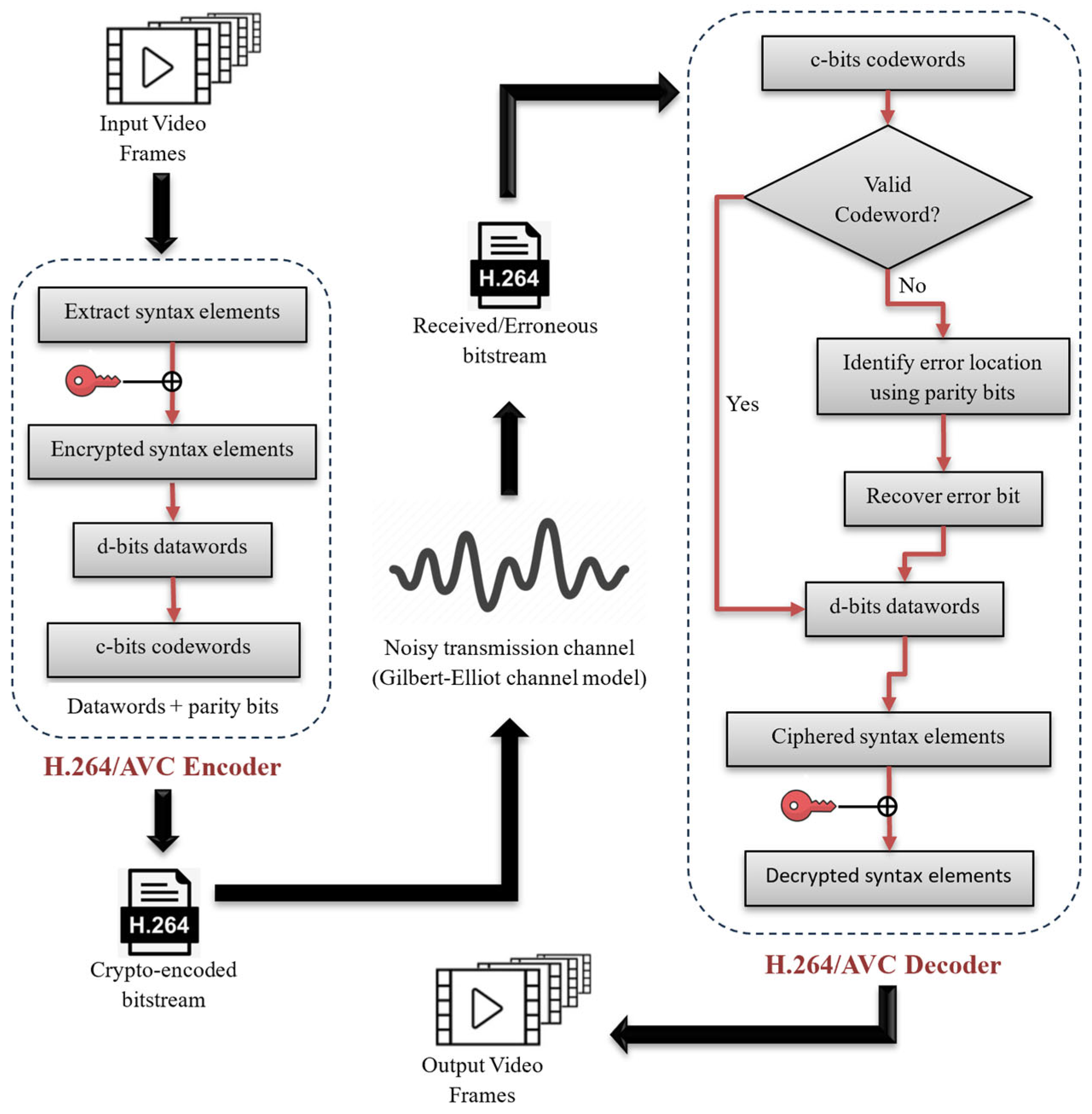
The proposed methodology for the enhancement of video quality using H.264/AVC syntax-based selective encryption and the FEC mechanism is shown in
Figure 5.
The state-of-the-art error correction techniques, including machine learning and deep learning approaches, offer high performance potential but exhibit higher computational overhead and require large training and validation sets. By contrast, our proposed FEC mechanism has a computational complexity of
O (
n) for encoding and
O (
n +
r) for decoding, where
n is the number of encoded bits and r is the number of redundant bits. This linear complexity makes our framework more efficient and straightforward to implement, without requiring extensive training data or complex model training. A comparative analysis of the computational complexities of these techniques is given in
Table 1.
4. Results
To demonstrate our proposed framework, the H.264/AVC encoder was used to simulate an error-prone channel model by inserting errors at multiple points. The videos were first compressed by the H.264/AVC encoder, offering lossless compression to overcome bandwidth limitations. Then, selective encryption of syntax elements (sign bits of MVD and TC) and the proposed FEC algorithm were implemented in H.264/AVC’s CABAC entropy coder during the encoding process. The decoding process was simulated using the H.264/AVC decoder, which decoded and corrected bit errors from the erroneous videos. The implementations were carried out on an HP Spectre x360 Intel Core i7 Processor with 16 GB RAM and a 64-bit operating system. Joint Scalable Video Model (JSVM) 9.19.14 was integrated in Visual Studio 2022 using C++ programming language to deploy the proposed method. As the aim of our work was to enhance the objective visual quality, the proposed scheme was applied on several test video sequences with different features, such as varying amounts of color pixels, texture, objects, and motion vectors. These results provided better visual quality when compared with the results obtained without using the FEC mechanism.
The proposed method was not designed for fixed video resolution and can be applied to videos with different resolutions. In our work, we compared the results on video sequences of two different video resolutions. The results were evaluated on Common Intermediate Format (CIF) (352 × 288) resolution on test video sequences MOBILE and FOOTBALL. For high-definition (HD) (1280 × 720) resolution, the results were assessed using VIDYO1 and FOUR PEOPLE video sequences. These test video sequences are publicly accessible in Derf’s collection. The frame rate was set to 30 fps, GOP size was 16, and subsampling was 4:2:0. H.264/AVC was used to encode and decode the CIF and HD test video sequences. The quality of the video sequences was evaluated through PSNR and PSNR611 quality assessment metrics.
Objective video quality can be measured using different evaluation parameters. Depending on the availability of the original video for the comparison, the evaluation methods are categorized as FR, RR, and NR assessment methods, as already described in
Section 1. We used the FR technique to evaluate the video quality after recovery from errors by calculating the peak signal-to-noise ratio (PSNR) values. It is the ratio between the original video signal and the signal after passing through a processing scheme. Let y be the number of bits per frame and (2
y − 1)
2 represents the range of values that a pixel can take, the PSNR is calculated as follows:
PNSR is the most promising predictor used for evaluating video quality and it is dependent on the mean square error (MSE). MSE specifies the amount of similarity between the original video and the encoded/impaired video [
45]. A smaller MSE value means there is less distortion in the processed video, resulting in a higher PSNR value. Therefore, a higher PSNR value means that the video has less distortion and better visual quality.
An advanced alternative to calculate the correlation of the perceived video quality introduced during the development of the HEVC coding standard is given below:
where
represents the luminance, whereas
and
refer to blue and red chrominance, respectively.
provides a combined score for luminance and chrominance assessment and relates better to subjective video quality as compared to classical PSNR [
24,
25]. When there is less distortion or noise, the PSNR
611 value will be higher, indicating that the quality of the processed video is nearly close to that of the original video. The results were evaluated at three different QP values (12, 34, and 48) to observe the effect of the FEC method through conventional PSNR and advanced PSNR
611 evaluation metrics on the video sequences. The comparative results with and without the proposed FEC are presented in
Figure 6,
Figure 7,
Figure 8 and
Figure 9. The results were compared for video sequences that were encoded without the proposed scheme, crypto-encoded, and decoded without incorporating FEC to analyze the efficiency of the presented scheme.
Figure 6a,
Figure 7a,
Figure 8a and
Figure 9a show the original video frame,
Figure 6b,
Figure 7b,
Figure 8b and
Figure 9b show the XOR encrypted frame,
Figure 6c–e,
Figure 7c–e,
Figure 8c–e and
Figure 9c–e show the encrypted video frames affected due to errors that occurred during transmission before decryption,
Figure 6f–h,
Figure 7f–h,
Figure 8f–h and
Figure 9f–h show the crypto-encoded encrypted frames,
Figure 6i–k,
Figure 7i–k,
Figure 8i–k and
Figure 9i–k show the video frames decrypted without FEC, and
Figure 6l–n,
Figure 7l–n,
Figure 8l–n and
Figure 9l–n show the recovered video frames decoded by the H.264/AVC decoder.
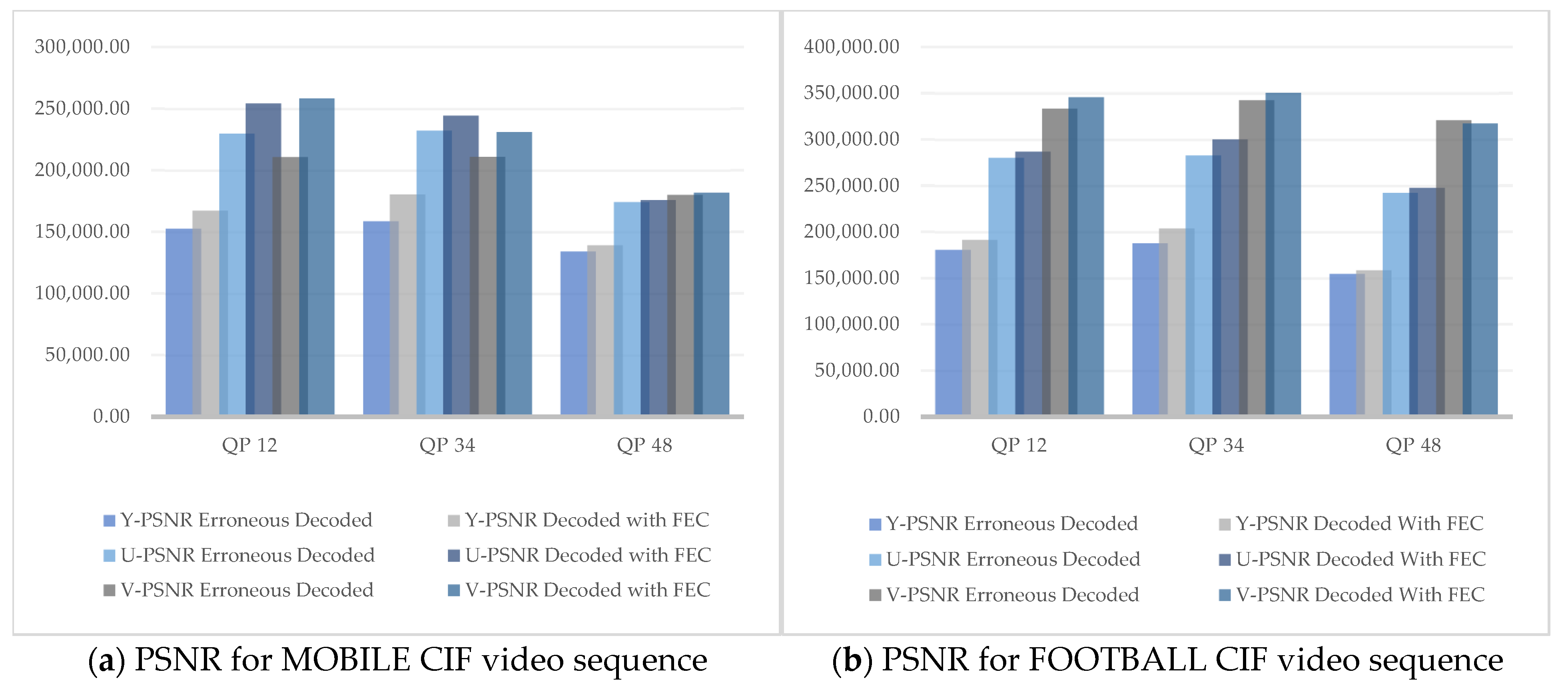
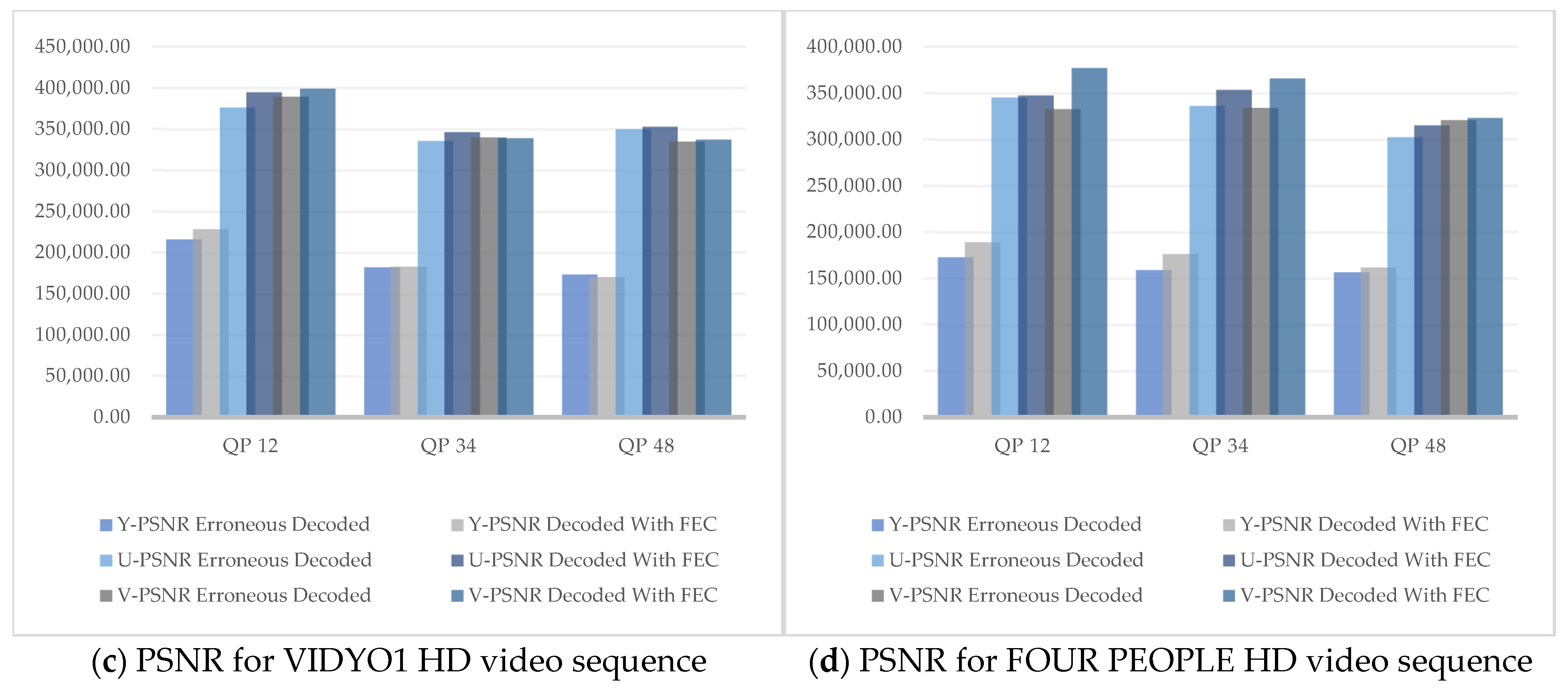
It was observed that the PNSR values in all Y, U, and V components increased in the recovered videos after being decoded using our technique as compared to the PSNR values of the decoded videos affected by the noisy channel. Similarly, the PSNR
611 values of the erroneous and recovered decoded video frames also exhibited a significant increase in the overall perceptual quality of the video. The PSNR and PSNR
611 values at different QP values of erroneous, crypto-encoded, decoded without the FEC method, and recovered using FEC test video sequences are summarized in
Table 2,
Table 3,
Table 4 and
Table 5.
It was observed from the results that the visual quality at QP 12 was better in terms of chrominance factors, whereas a clear increase in Y-PSNR (luminance component) was observed at QP 34. However, at QP 48 there was a minor increase in visual quality. This is because QP is inversely proportional to video quality. Thus, by increasing the QP, the video quality decreased. The overall increase in visual quality was best noticed at QP 34, as the human visual system is more sensitive to luminance as compared to chrominance.
Figure 10a–d illustrate the graphs of different PSNR values at QP 12, 34, and 48 of both the CIF and HD test video sequences.
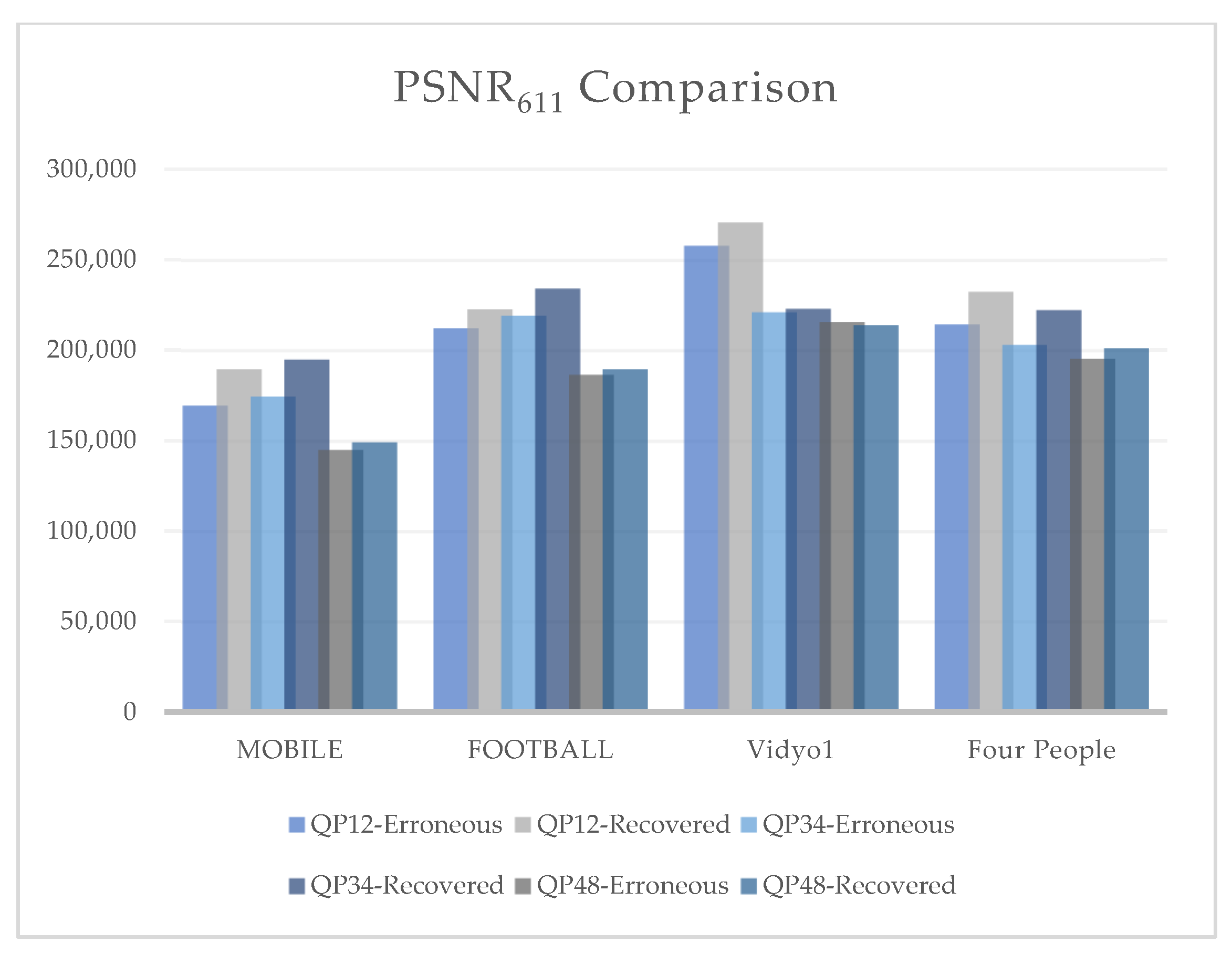
Figure 11 summarizes the effect of PSNR
611 on the erroneous and recovered videos of our four test sequences. PSNR
611 evaluates the combined effect of brightness and color components on the perceptual visual quality of the video. The results showed that the combined luma and chroma effect was best noticed at QP 34 for videos with lower resolution and better observed at QP 12 on videos with higher resolution. For the crypto-encoded video frames, the best results were observed at QP 34 irrespective of varying video resolution, as the algorithm’s encryption performance was better at smaller PSNR values. It is clearly observed from the graphs that the proposed FEC algorithm performed best at QP 34. A significant increase in Y-PSNR resulted in enhanced objective visual quality.
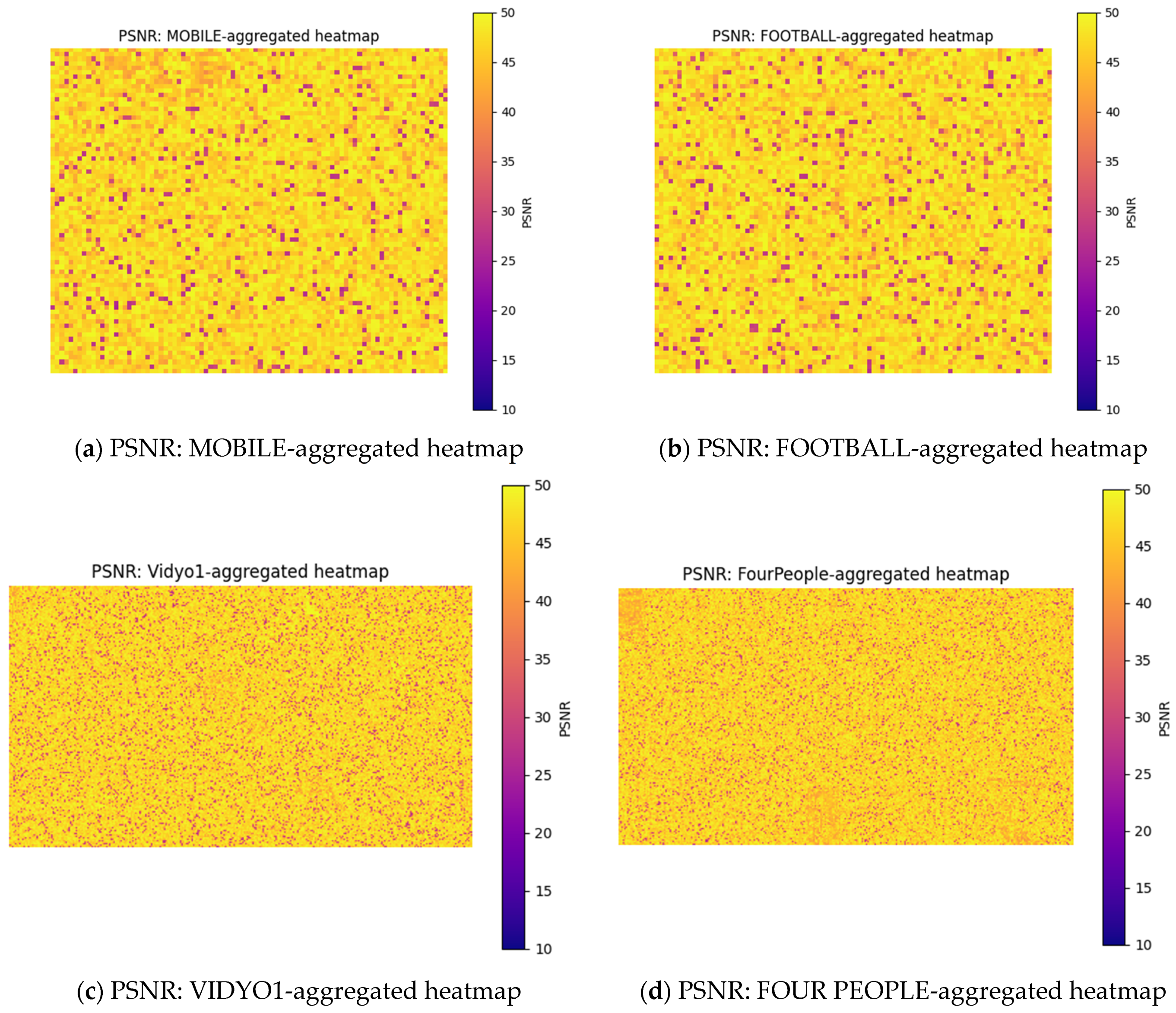
Figure 12 illustrates the aggregated heatmaps of these four video sequences at QP 34, where error correction was best observed.
Figure 12a shows that the average similarity of the recovered MOBILE video to the original video was around 88–92%.
Figure 12b shows that the reconstruction quality of the FOOTBALL video exhibited significant fluctuations due to the high motion and texture complexity inherent in its content. Despite high motion and complex texture, our approach yielded an estimated average similarity of 80–88%, indicating a reasonable level of error recovery.
Figure 12c exhibits high reconstruction quality with the consistently yellow heatmap, which indicated high similarity and less distortions, suggesting effective recovery due to lower motion. Its estimated similarity was around 88–95%.
Figure 12d presents the heatmap of the FOUR PEOPLE video. The uniform yellow tone with minimal dark areas indicated consistently high PSNR values and an estimated similarity of 87–92%. It suggested better error recovery and reconstruction quality, likely due to limited motion and simple scene complexity. These heatmaps demonstrate the effectiveness of our FEC approach for four videos with varying levels of motion and texture complexity, achieving an average similarity of 90–95%.
5. Discussion
In this work, we examined an FEC-based framework to enhance the objective video quality of videos that are affected by noisy transmission channels without compromising confidentiality. The foundation of this work was to devise a simple framework that provides improved visual quality to the viewer by incorporating forward error correction in the encoding process. The video is first compressed to accommodate bandwidth limitations due to its large size and then is selectively encrypted for privacy preservation and protection against unauthorized access. FEC is deployed on the encrypted bitstream during the encoding process, offering a joint crypto-encoding framework. It is observed in the results presented in the previous section that the proposed method can recover the errors and sufficiently supports quality enhancement.
The comparison of the recovered videos with the original videos was evaluated through the PSNR values of the Y, U, and V components of the videos to examine the results in terms of luminance and chrominance factors. PSNR611 was used to calculate the collective effect of luma and color components in both erroneous and recovered videos. The results suggested that the PNSR values in each component increased in the FEC decoded videos as compared to the PSNR values of the videos decoded without FEC. The Y component controls the luminance (brightness) and the other two components, U and V, are used to represent chrominance (color). Since the human eye is more sensitive to brightness as compared to color, the results suggested a significant improvement in the Y component. The smaller PSNR values of the encrypted videos showed the better performance of the encryption algorithm. The increased PSNR values meant that the recovered videos had reduced amounts of distortion and the visual quality was restored after decoding with the FEC method.
Moreover, it was observed that the application of this approach was not confined to a specific video resolution, as it provided improved outcomes on both CIF and HD test video sequences. The effect of PSNR also varied at different QPs on the test video sequences. Objective visual quality at QP 12 provided better outcomes in terms of color components, whereas a significant increase in luminance was observed at QP 34. As larger QP values preserve less detail in the quantization process, QP 48 provided a minor increase in the perceptual quality of the video. Therefore, it was clearly observed that increasing the QP provided less improvement in video quality as compared to smaller QP values. In summary, the results suggest that it is possible to employ our technique to achieve better objective video quality, avoiding the need for retransmission and complex computational cost.
There is a potential trade-off between error correction capability and bandwidth expansion, which depends on the number of redundant bits added to generate codewords using data bits. In the encoding scheme, r bits are added to d data bits to form a codeword having c bits. In our (15, 11) encoding scheme, the bandwidth expansion was = ((15 − 11)/11) × 100 = 36.36%. If we further reduce the block size, such as in a (7, 4) encoding scheme, the number of redundant bits will be increased in the original bitstream of data, resulting in a bandwidth expansion of 75%. By contrast, a larger block size such as (255, 247) will incorporate a smaller number of redundant bits in the original bitstream, resulting in lower bandwidth expansion but at the cost of reduced error correction efficiency, specifically, the bandwidth expansion in this case will be 3.24%. Although this approach provides flexibility to adjust the redundancy level according to the available resources, its limitation lies in the fact that choosing a large block size will not be as efficient if the channel is highly noisy and has larger errors. This trade-off between error correction capability and bandwidth expansion necessitates a careful balance between these competing factors, particularly in channels prone to burst errors.
The presented work uses a block coding FEC mechanism to enhance the visual quality of videos by recovering transmission errors. Methods for error recovery using convolution codes can be designed in the future. The proposed algorithm assists in preserving the integrity and confidentiality of transmitted videos by incorporating H.264 syntax-based encryption with the proposed FEC framework and can be tested in the future with other advanced encryption standards to evaluate its impact on encrypted videos. The performance of this work can be further examined on the basis of other quality assessment metrics. Compression efficiency and speed in H.264/AVC has reached the point where it can no longer be further enhanced. Therefore, several new video codecs have emerged to meet the increasing demands of multimedia technology, such as H.265, HEVC/H.265, AV1, and VVC. The effectiveness of this approach can further be evaluated on higher video resolutions (2K, 4K, 8K, etc.) [
46]. As our work has been implemented using the H.264/AVC CABAC entropy coder, it can be implemented in modern coding standard H.265 and HEVC for future multimedia transmission, which provides twice the compression as the H.264 coding standard [
47,
48]. The data reduction efficiency in H.265 is much higher in compressing videos and makes transmission of ultra-high-definition 4K or 8K videos easier [
49].
To provide better compression efficiency, reduce complexity, and improve scalability, scalable video coding (SVC) techniques, such as H.264/SVC and VP9, can be optimized to enable efficient video transmission over heterogeneous networks [
50]. It can be expanded to a scalable coding environment where the number of parity bits added is dependent on scalable bitstreams to offer variable quality demands for devices with varying resolutions. The cross-layer design and optimization of error correction mechanisms can be explored, where the application layer’s FEC strategy is informed by and coordinates with error correction mechanisms at lower layers. This would potentially lead to more efficient use of resources and improved overall system performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}