Abstract
The accurate detection of surface bolt defects in railway steel truss bridges plays a vital role in maintaining structural integrity. Conventional manual inspection techniques require extensive labor and introduce subjective assessments, frequently yielding variable results across inspections. While UAV-based approaches have recently been developed, they still encounter significant technical obstacles, including small target recognition, background complexity, and computational limitations. To overcome these challenges, CSEANet is introduced—an improved YOLOv8-based framework tailored for bolt defect detection. Our approach introduces three innovations: (1) a sliding-window SAF preprocessing method that improves small target representation and reduces background noise, achieving a 0.404 mAP improvement compared with not using it; (2) a refined network architecture with BSBlock and MBConvBlock for efficient feature extraction with reduced redundancy; and (3) a novel BoltFusionFPN module to enhance multi-scale feature fusion. Experiments show that CSEANet achieves an mAP@50:95 of 0.952, confirming its suitability for UAV-based inspections in resource-constrained environments. This framework enables reliable, real-time bolt defect detection, supporting safer railway operations and infrastructure maintenance.
1. Introduction
The detection of bolt defects in railway steel truss bridges is crucial for ensuring structural safety and maintaining the stable operation of railway traffic. Railway authorities must inspect for bolt loosening, detachment, and corrosion in order to develop an appropriate maintenance plan. Currently, railway bolt inspection still relies mainly on manual checks and basic instruments. This approach is inefficient and subjective, making it difficult to ensure comprehensive and accurate assessments. Manual inspection suffers from limitations such as inspector fatigue, challenging working environments, and inadequate detection tools, which can lead to misjudgments and omissions. Additionally, the complexity of steel truss structures and the high-altitude nature of the work, combined with the limited range of inspection equipment, make manual methods dangerous, costly, and difficult to carry out. Therefore, it is essential to explore more efficient and automated inspection methods to enhance both inspection efficiency and accuracy.
In recent years, due to its flexibility, low cost, and remote control advantages, unmanned aerial vehicle (UAV) inspection technology has been applied in railway steel truss bridge inspection. UAVs can quickly fly over a large area to transcend the geographical location of bridges and take high-resolution image data, which can reduce the amount of work for manual inspections and improve data collection efficiency. Railway inspection UAV technology has made remarkable achievements in a variety of railway inspection scenarios [1,2,3,4,5,6]. Although there are obvious advantages of UAVs in data acquisition, the following challenges still exist in the task of detecting bolt defects in railway steel truss bridges: small target detection, interference from complex backgrounds and limited computational resources.
In the images captured by UAVs, bolts are extremely small targets, often occupying only a few pixels even in high-resolution imagery. This presents a major challenge for traditional object detection algorithms, which tend to lose critical features of small objects during the feature extraction process, resulting in decreased detection accuracy. Furthermore, the complex background of railway steel truss bridges—characterized by overlapping components, lattice structures, and variable lighting—can easily obscure small targets and introduce noise, leading to frequent false positives and missed detections. High-speed UAV movement can further amplify motion blur and lighting inconsistency, degrading the quality of image data. While anchor-based detection methods offer strong localization for larger objects, their performance significantly declines for small-scale objects due to limitations in anchor design and receptive field coverage. Although prior research has shown that region-based methods like Faster R-CNN can achieve high precision in detecting blurry and small-scale defects in GPS-denied environments [7], these models often require considerable computational resources, making them impractical for lightweight UAV platforms. Consequently, improving the accuracy and efficiency of small object detection has become an urgent need in UAV-based railway inspection scenarios.
Other than the challenges in small target detection, UAV-based inspection also faces practical limitations from both hardware and operational perspectives. On the one hand, UAVs are typically equipped with resource-constrained onboard devices, which makes it difficult to deploy high-precision detection algorithms that demand significant computational power. On the other hand, the reliance on licensed pilots increases operational costs and limits scalability, especially in complex or repetitive inspection tasks [8]. These factors have driven the development of autonomous UAV systems. Furthermore, to enhance flight safety in environments with unpredictable obstacles, recent studies have incorporated deep learning-based obstacle avoidance into autonomous UAV platforms [9]. Therefore, detection algorithms must not only achieve high accuracy but also be lightweight, real-time, and adaptable to autonomous UAV systems. Compared with traditional two-stage detection algorithms, traditional two-stage detection algorithms such as R-CNN and Fast R-CNN [10,11,12] have high detection accuracy but large computational complexity, which is unacceptable in UAV inspection application. While one-stage detection algorithms such as YOLO and SSD [13,14] can quickly predict the location and category of objects in an end-to-end manner and have fast inference compared with two-stage algorithms, there is still space for accuracy improvement for small target detection.
To increase the accuracy and efficiency of small target detection, researchers have proposed various improvement strategies, such as data augmentation [15,16], multi-scale feature learning [17], and Feature Pyramid Networks (FPNs) [18,19,20]. Furthermore, the introduction of attention mechanisms, such as channel attention (SE), spatial attention (CBAM), and coordinate attention (CA), has significantly enhanced the model’s ability to perceive key regions, improving both the accuracy and robustness of object detection [21,22,23].
In addition to boosting the detection accuracy, researchers also attempt to improve the computational efficiency by designing some lightweight methods. For instance, DSC [24] reduces the computational cost while maintaining certain feature extraction ability. Furthermore, GSConv [25] and Gold-YOLO [26] also optimize the feature pyramid structure to balance the multi-scale feature fusion efficiency and computational complexity by improving the model lightweighting. In recent years, anchor-free detection strategies have also gained significant attention [27,28], as they eliminate dependency on predefined anchor boxes, enhancing the model’s adaptability to small target detection and demonstrating potential applications in UAV-based inspection tasks. The integration of these optimization strategies provides new research directions for intelligent bolt defect detection in railway steel truss bridges while also advancing the application of computer vision in infrastructure inspection.
The YOLO series [29,30], particularly the YOLOv8 algorithm released in 2023 [31], has demonstrated high accuracy and speed in object detection tasks. However, YOLOv8 still exhibits certain limitations when dealing with complex backgrounds and small target detection, especially in scenarios where objects vary significantly in size or where background interference is substantial. In such cases, its performance may be inferior to some specialized small-object detection algorithms. Consequently, existing detection methods struggle to fully meet the requirements for bolt defect detection in railway steel truss bridges.
While previous studies have addressed some of these issues through targeted architectural or loss function improvements, they often focus on isolated components and fail to offer an integrated solution that simultaneously meets the demands of small target accuracy, real-time performance, and UAV-deployable efficiency. Moreover, most YOLO-based improvements do not explicitly consider the difficulty of cross-stage feature interaction in complex industrial scenes, nor do they account for deployment constraints of onboard UAV systems.
To bridge this gap, our study aims to move beyond isolated module enhancements and propose a system-level framework that integrates novel data preprocessing (SAF), optimized backbone design (BSBlock and MBConvBlock), and a refined neck structure (BoltFusionFPN) under a unified detection pipeline. This approach is designed to support real-world bolt defect detection under the constraints of high-resolution UAV imagery, limited onboard computation, and dense background interference. We believe this integration not only advances the technical performance but also provides a more generalizable and practical paradigm for future research in UAV-based infrastructure inspection.
The main contributions of this paper can be summarized as follows:
- To address the challenge of small target detection for bolts in large images captured by UAVs, we propose a sliding-window-based SAF (slice-assisted fine-tuning) preprocessing method. During the training phase, images are divided into overlapping patches, and these patches are processed and then combined to form a complete image. This reconstruction helps improve the feature representation of small objects by focusing the model’s attention on smaller, localized areas within the image, rather than on irrelevant background regions. In the inference phase, the patches are stitched back together without resizing, ensuring that small objects are not distorted by resampling. This method also helps eliminate redundant background information, making the model more efficient by concentrating on the relevant regions of the image, such as bolt defects. Additionally, by combining cross-stage data augmentation strategies, we expand the original set of 50 images to 1115 images, resulting in an improvement in the model mAP to 0.818 (a 97.1% increase compared to the non-sliced version).
- To balance lightweight design with high accuracy, we first replace the deep C2f module in the backbone network with BSBlock, a deep feature extraction module based on PConv and PWConv. Simultaneously, we introduce MBConvBlock, a shallow feature extraction module integrating MBConv and CBAM, to replace the shallow layers of the network. This optimization enhances texture feature extraction while reducing parameter redundancy.
- To address the issue of feature loss caused by PANet’s reliance on intermediate layer information transfer, we design a novel neck network, BoltFusionFPN. This network introduces the collection–distribution (GD) mechanism of Gold-YOLO, enabling the direct alignment of non-adjacent layer features. Combined with the channel shuffling operation of GSConv, it facilitates the dynamic fusion of multi-scale features.
The following part of this paper is organized as follows: Section 2 reviews related work, particularly focusing on algorithms improved from YOLO for small target detection. Section 3 provides details on the network structure of the CSEANet model and the related modules. Section 4 presents experimental results and performance evaluations. Finally, conclusions and future work are drawn in Section 5.
2. Related Works
Before the adoption of deep learning in bolt defect detection, several vision-based methods were developed to identify loosened bolts. For instance, one approach utilized the Hough transform combined with a support vector machine to extract geometric features—such as bolt head length and orientation—from smartphone images, achieving reliable quasi-real-time classification performance [32]. Another notable method applied the Viola–Jones algorithm to automatically localize bolts and calculate damage-sensitive features, which were subsequently fed into an SVM classifier to distinguish loosened from tight bolts [33]. These traditional methods demonstrated the feasibility of bolt detection using classical computer vision techniques. However, their effectiveness often depends heavily on controlled lighting, fixed viewpoints, and simple backgrounds, which limit their applicability in complex UAV-based inspection scenarios. Consequently, recent research has increasingly focused on deep learning models that offer greater robustness and automation under diverse conditions.
The first application of convolutional neural networks (CNNs) to bolt damage detection was presented in an autonomous inspection framework using region-based deep learning to identify multiple types of structural defects [34]. More broadly, deep-learning-based structural health monitoring has gained increasing attention, with key works addressing general SHM frameworks [35] and concrete crack detection using CNNs [36]. In recent years, the YOLO (You Only Look Once) series of algorithms have been extensively studied for small object detection tasks. Due to challenges such as insufficient feature representation, severe background interference, and complex scale variations, researchers have made improvements to YOLO in areas such as feature extraction, feature fusion, loss function optimization, and lightweight design to enhance detection accuracy and efficiency.
In terms of feature extraction, researchers have enhanced the representation capability of small objects by optimizing backbone network structures and incorporating efficient attention mechanisms. For instance, Li and Shen [37] applied super-resolution reconstruction techniques to make the features of low-resolution small objects clearer, thus enhancing detection accuracy. Su and Qin [38] introduced multi-level feature integrators and perceptual-enhanced convolution modules based on YOLOv8, making the feature representation of small objects more robust. Hui et al. [39] proposed a structural improvement based on Swin Transformer, further strengthening the feature extraction ability for small objects. Additionally, Zeng et al. [40] improved the feature aggregation capability of detection networks through the PC-C2f and ASD-FPN structures, significantly enhancing small object recognition.
In terms of feature fusion, optimizing multi-scale feature extraction and fusion strategies is key to improving small object detection capabilities. Some studies have enhanced the transmission and utilization efficiency of features across different scales by improving the feature pyramid structure (FPN) and adaptive fusion strategies. For example, Bi and Li [41] optimized the feature fusion structure of YOLOv8, improving detection performance for objects at different scales. Wang and Zhou [42] enhanced the model’s ability to capture small object features by introducing RepGhost and Normalized Attention Modules (NAMs). Li and Zheng [43] designed the RepNCSPELAN4 and C2FCBAM modules, strengthening the interaction between features at different levels, thus balancing detection accuracy and computational efficiency. Ma et al. [44] proposed DLW-YOLO, combining the SPPELAN and VoV-GSCSP frameworks, which effectively improved small object detection performance in complex environments.
In terms of loss function optimization, researchers have focused on alleviating the regression error bias caused by small object sizes during the training process. For example, Xu et al. [45] introduced a balanced Focal Loss based on YOLO, which made the model pay more attention to small objects and reduced false positives and false negatives in detection. Xu and Xiong [46] proposed EMA-YOLO, which improved the object localization loss and enhanced the detection stability of small objects, particularly in complex backgrounds. Zhong and Zhang [47] optimized YOLO’s loss function design by combining multi-order gated aggregation modules, further enhancing detection accuracy and robustness.
In terms of lightweight design, to reduce computational overhead and improve real-time performance, several studies have employed model compression, parameter optimization, and efficient computational units. For example, Betti and Tucci [48] proposed YOLO-S, which uses skip connections and lightweight structures, making the model suitable for resource-constrained scenarios while maintaining high detection accuracy. Xu [49] optimized YOLOv3 by combining auxiliary networks and attention mechanisms, reducing computational complexity while improving detection accuracy. Zhang and Meng [50] introduced MBAB-YOLO, which strikes a good balance between high-precision detection and real-time performance by using adaptive multi-receptive field focusing and hybrid attention modules. Huangfu et al. [51] proposed Ghost-YOLO v8, which integrates GhostConv and the SE mechanism, enabling the model to effectively capture small object features while maintaining efficient computational capabilities.
Additionally, some studies have further integrated specific structural optimizations to enhance detection performance. Hui [52] enacted SEB-YOLO using SPD-Conv and Bi-FPN structure to enhance semantic information extraction ability and enhance the accuracy of small object detection. Shin et al. [53] designed DCEF2-YOLO. Deformable convolutions and an efficient feature fusion structure are introduced into YOLO, and the model’s adaptability to small objects is enhanced. Xu and Dong [54] added an attention mechanism to a YOLO network. The method greatly improved the detection effect of small anomalous objects in complex backgrounds. Xia [55] proposed TTD-YOLO, which improves the network structure to provide more stable performance in multi-scale object detection. Wu [56] proposed SAW-YOLO, which further enhances detection performance by combining an optimized feature fusion module.
In summary, YOLO-based improvements have made significant progress in small object detection tasks. Researchers’ explorations in feature extraction, feature fusion, loss optimization, and lightweight design have continuously enhanced detection accuracy and computational efficiency. However, in the specific industrial scenario of detecting bolt defects on the surface of railway steel truss bridges, existing methods still face challenges such as insufficient cross-stage feature aggregation and the difficulty of balancing detection accuracy with real-time performance under UAV hardware constraints.
Most of these approaches focus on isolated module-level improvements and lack a unified framework tailored for UAV-based bolt inspection. To address these issues, this study proposes a Cross-Stage Enhanced Aggregation Network (CSEANet), which systematically integrates SAF-based preprocessing, lightweight feature extraction modules, and an optimized neck structure. This comprehensive design enhances feature representation and fusion, thereby improving detection accuracy while ensuring real-time performance for deployment in practical UAV inspection tasks.
3. Methodology
3.1. Framework Overview
We propose an improved object detection network, CSEANet, to enhance the accuracy and robustness of surface bolt defect detection in railway steel truss bridges. Traditional detection methods, including YOLOv8, often struggle with small object representation, ineffective feature fusion, and high computational cost.
To address these issues, CSEANet builds upon YOLOv8 with targeted structural improvements. It enhances the backbone and neck networks through the integration of MBConvBlock and BSBlock for better feature extraction and replaces PANet with the BoltFusionFPN module for more effective multi-scale fusion. Additionally, the SAF (slice-assisted fine-tuning) preprocessing strategy improves small object visibility and reduces background noise.
The standard YOLOv8 pipeline is shown in Figure 1 for comparison, while the overall architecture of our proposed CSEANet is illustrated in Figure 2. Compared with YOLOv8, CSEANet achieves better detection performance for small objects while maintaining high efficiency, making it well-suited for UAV-based bridge inspection tasks.
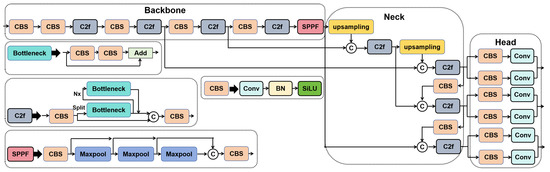
Figure 1.
The structure of YOLOV8.
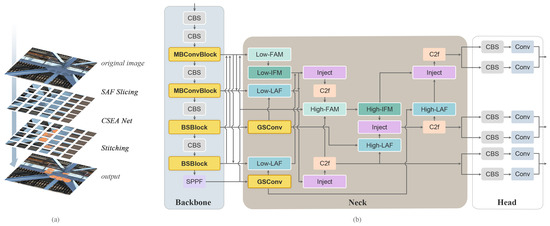
Figure 2.
Figure (a) shows the process image of surface bolt defect detection for railway steel truss bridges, and Figure (b) illustrates the structure of CSEANet.
3.2. SAF Slicing Preprocessing
The primary challenge in surface bolt defect detection on railway steel truss bridges is that the features of small objects are easily obscured by background noise in large images. As illustrated in Figure 3, the pixel area of a bolt constitutes only 0.10% of the entire image, representing a typical small object detection scenario. Directly inputting the original high-resolution image into a detection network, such as YOLOv8, often leads to the loss of small object features due to excessive downsampling in deeper layers. On the other hand, shallow networks struggle to extract deeper semantic information, making it difficult to achieve a balance between detecting both large and small objects.

Figure 3.
Schematic diagram of railway steel truss bridge collected during UAV patrol inspection. The part marked in green is a bolt.
To address this challenge, this study proposes the SAF (slice-assisted fine-tuning) strategy, which extracts local patches from the original image and adjusts them to a larger aspect ratio during the fine-tuning process. This approach combines two key mechanisms, local feature enhancement and global context retention, significantly improving the model’s ability to detect small objects. In our implementation, SAF slicing is applied consistently in both the training and inference phases. During training, each image is divided into overlapping patches of 640 × 640 pixels, and slicing is performed per image, not per category. During inference, the input image is similarly sliced into 666 × 500 patches, and all predictions are projected back to the full image, followed by a global non-maximum suppression (NMS) step to remove duplicate detections in overlapping regions.
The original image is shown as , where each image is divided into overlapping patches, . Then, the size of all patches is adjusted, and the enhanced image is obtained as . In both the training and inference phases, different SAF slicing preprocessing methods are applied to the dataset. Two images are randomly selected from the dataset as examples, as shown in Figure 4, Figure 5, Figure 6 and Figure 7. In the training process, we cut each original image into 64 overlapping patches and rebuild the dataset by resampling each patch into a 640 × 640-sized patch, while in the inference process, we cut each original image into overlapping patches of size 666 × 500 and no resampling is performed. After the inference is complete, the patches are stitched back together.
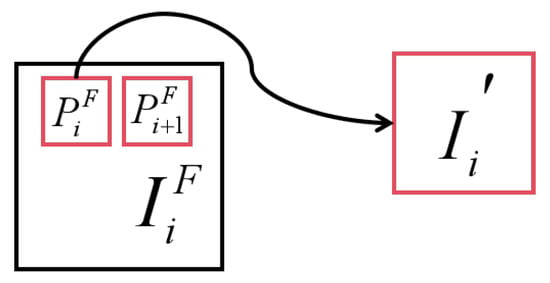
Figure 4.
Schematic diagram of SAF process.

Figure 5.
The structure of MBConvBlock.
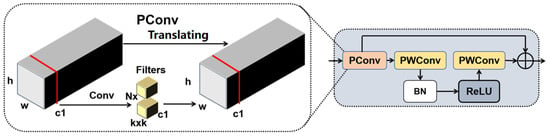
Figure 6.
The structure of BSBlock.

Figure 7.
The structure of GSConv.
3.3. Shallow Feature Extraction Module MBConvBlock Based on MBConv and CBAM
In object detection tasks, the backbone network plays a crucial role in multi-level feature extraction, with the quality of shallow features directly influencing the detection capability of small objects. However, the C2f (Cross-Stage Partial Fusion) module used in YOLOv8 primarily focuses on optimizing gradient flow and lacks a dedicated mechanism to enhance small-object features. Its bottleneck structure relies on a large receptive field for feature aggregation, which often leads to the loss of critical information in small object detection tasks. Additionally, C2f uses channel decomposition and fusion for information transfer but does not integrate a dedicated attention mechanism, preventing the model from effectively focusing on small object regions during the feature extraction process. This uniform approach to image information processing works relatively well for large object detection but struggles to precisely capture defect features in small object tasks, such as surface bolt defect detection in railway steel truss bridges, ultimately limiting detection accuracy.
To address the limitations of C2f in small object detection, this study introduces MBConvBlock in the first two C2f module positions of the backbone network. This replacement aims to enhance shallow feature extraction and improve the model’s sensitivity to small objects. The MBConv structure was originally derived from MobileNetV3 and later optimized in EfficientNet. It incorporates two key features: depthwise separable convolution and inverted residuals. These characteristics reduce computational costs while enhancing feature representation capabilities. However, directly applying the standard MBConv still presents certain limitations. To better meet the demands of small object detection, this study introduces targeted improvements. These include refining the attention mechanism and adjusting the activation functions.
In terms of attention mechanisms, this study introduces CBAM (convolutional block attention module) to replace the SE (Squeeze-and-Excitation) mechanism in the original MBConv. While SE performs channel-wise attention computation, it fails to capture spatial information. In contrast, CBAM combines both channel and spatial attention, enabling the network to focus more precisely on critical target regions while reducing attention to irrelevant background areas, thereby enhancing small object detection performance.
During the channel attention computation in CBAM, the input features are first processed through Global Average Pooling (GAP) and Max Pooling to extract channel information. The pooled features are then passed through two fully connected layers. Finally, the channel weights are generated using a Sigmoid activation function, as shown in Equation (1). This approach allows the model to more effectively focus on relevant channels and suppress less important ones, further improving detection performance, especially for small objects.
where and are fully connected layer parameters, is the ReLU activation function, and is the Sigmoid normalization function. The feature enhanced by the channel attention module then enters the spatial attention module, where a convolution is used to compute the spatial attention map. This allows the model to more precisely adjust the feature weights of small target regions, thereby improving detection accuracy.
Furthermore, to improve computational efficiency and enhance the stability of the model, this study replaces the Swish activation function in the MBConv structure with ReLU, whose specific formula is shown in Equation (2). While Swish has a higher computational complexity and can improve feature representation, it is not suitable for lightweight deployment scenarios. ReLU6, by limiting the range of activation values, helps reduce the risk of numerical overflow and improves computational efficiency. Its expression is as follows:
This adjustment not only reduces the computational load but also optimizes training stability, allowing the model to maintain stable performance even in environments with low computational resources. By using ReLU6, the model can effectively balance efficiency and accuracy, ensuring that it operates reliably under resource-constrained conditions without compromising its detection capability.
The overall process of the MBConvBlock is shown in Figure 5. The input feature first passes through a convolution layer for channel expansion, increasing the number of channels from C to , where is typically set to 4, thereby enhancing the feature representation capability. Next, depthwise separable convolution is used for feature extraction. Unlike standard convolution, this operation splits the computation into depthwise convolution (which operates on individual channels) and pointwise convolution (which fuses channel information). This approach significantly reduces computational cost while maintaining the feature representation ability. Additionally, to better capture small object features at different scales, the study employs or variable convolution kernels in the depthwise convolution, allowing the network to handle small objects of various sizes more effectively.
After feature extraction, the CBAM mechanism further optimizes the feature representation, allowing the network to dynamically adjust feature weights and focus more on the bolt defect areas, rather than distributing attention uniformly across the entire image. Finally, a convolution layer is used for channel compression, reducing the number of channels from back to the original dimension C, which helps decrease the computational cost. A dropout layer is also introduced at this stage to reduce the risk of overfitting and improve the model’s generalization ability. Overall, the integration of the MBConvBlock and CBAM structure enhances CSEANet’s ability to extract local features for small object detection tasks while reducing computational resource waste and improving overall detection performance.
3.4. Deep Feature Extraction Module BSBlock Based on PConv and PWConv
In object detection, above the deep layer of the backbone network, the deep network focuses on learning more global contextual information. Compared with shallow networks, deep networks learn more global information to enhance the discriminative ability of the model. However, more parameters will increase the training expense in deep networks. Furthermore, the problem of vanishing or exploding gradients may also appear due to the high computation cost of deep networks. Specifically, in the YOLOv8 backbone network, C2f serves as the core component for deep feature extraction. Although it has advantages in optimizing gradient flow, it faces two main issues: excessive computational redundancy and limited effectiveness in feature extraction.
The C2f module presents a significant computational burden. While its Bottleneck structure helps reduce channel redundancy, it still relies on large feature maps for processing, leading to a high number of parameters and floating-point operations (FLOPs). In high-resolution image tasks, such as bolt defect detection in railway steel truss bridges, the deep feature extraction stage requires handling extensive high-dimensional data. This heavy computational load greatly increases inference time, making it challenging for the model to maintain real-time performance. Moreover, the C2f structure prioritizes gradient propagation but does not fully leverage computational resources for effective feature selection. As a result, redundant information flows through the network, making it less efficient at capturing crucial target details. This limitation is especially problematic in small object detection, where weak deep feature representation can cause small targets to be overlooked, ultimately reducing detection accuracy.
To overcome these challenges, this study introduces the BSBlock (Bottleneck-Shuffle Block) into the deeper layers of the YOLOv8 backbone network as a replacement for the C2f module. This enhancement improves deep feature representation while significantly reducing computational overhead.
The structure of BSBlock is illustrated in Figure 6. First, the input feature undergoes processing through partial convolution (PConv), which reduces computational overhead while emphasizing key target features. This allows computational resources to focus on the critical regions of bolt defects. The computation of partial convolution can be expressed as shown in Equation (3):
where W represents the weight matrix, ⊙ denotes element-wise multiplication, and b is the bias term. Compared to standard convolution, PConv performs computations only on valid regions, allowing computational resources to focus on the critical areas of bolt defects while reducing unnecessary calculations.
To enhance the interaction and fusion of channel information, BSBlock employs two Pointwise Convolution (PWConv) layers, effectively utilizing the information from different feature channels to improve the completeness of feature representation. Additionally, to maintain consistency of feature information in deep networks and mitigate the vanishing gradient problem, BSBlock incorporates residual connections.
In the CSEANet architecture, BSBlock replaces the third and fourth C2f modules of the YOLOv8 backbone. This adjustment not only reduces the model’s parameter count and computational complexity, contributing to its lightweight design, but also strengthens the robustness of deep feature extraction. As a result, CSEANet can more accurately preserve critical small-object information in bolt defect detection tasks for railway steel truss bridges without being affected by background noise or computational redundancy.
3.5. The Neck Feature Pyramid Based on GSConv and Gold-YOLO: BoltFusionFPN
In object detection tasks, the neck network is responsible for fusing multi-level features from the backbone network at different scales to ensure the effective combination of deep semantic information and shallow detail information. However, in the original YOLOv8 structure, the PANet (Path Aggregation Network) is used as the neck network, primarily performing multi-scale feature fusion through lateral and context paths. While PANet demonstrates good performance in object detection tasks, its hierarchical information fusion strategy still has certain limitations when handling small object detection tasks.
As shown in the diagram, PANet employs a hierarchical information interaction strategy, where low-level features need to be passed up to higher levels, while high-level features gradually flow back to lower levels to achieve fusion of global and local information. However, this stepwise feature propagation mechanism leads to two main issues: First, non-adjacent layers find it difficult to directly interact, and critical information for small objects may be weakened or even lost during the stepwise transmission process. Second, this mechanism increases computational overhead, as additional feature transmission paths introduce information redundancy, negatively impacting inference efficiency. This is particularly evident in high-resolution image tasks, where the computational burden is further amplified. Specifically, in the task of detecting bolt defects in railway steel truss bridges, the detailed features of small objects are often distributed in the shallow layers, and PANet fails to efficiently align these critical pieces of information, limiting the detection accuracy for small objects.
To address the above issues, this paper reconstructs the neck network based on Gold-YOLO, which, through its gather-and-distribute (GD) mechanism, directly aligns features across non-adjacent layers. Building upon this, the paper adopts a multi-scale feature fusion approach, making feature integration more diverse and effectively mitigating the issue of small object features being overwhelmed in very deep networks. Following this, the GSConv module is placed after the deep feature extraction module in the backbone network, reducing the number of parameters while maintaining or improving accuracy and lowering computational costs. BoltFusionFPN, by replacing the neck network in YOLOv8, expands the model’s learning capacity and absorbs feature information from different network layers, significantly enhancing the model’s learning and generalization abilities. The following sections introduce the improved modules in detail.
(1) Gold-YOLO Mechanism
The Gold-YOLO mechanism consists of two parts: Low-GD (Low-Level Feature Collection) and High-GD (High-Level Feature Collection). Its overall architecture is shown in Figure 2. In the Low-GD section, Gold-YOLO performs feature scale alignment and channel information fusion through the Low-Level Feature Alignment Module (Low-FAM) and Low-Level Information Fusion Module (Low-IFM). This ensures that features from different layers are fully fused before entering the higher-level stages. The feature alignment process is mathematically formulated in Equation (4):
where represent features extracted from different layers of the Backbone. The AvgPool and UpSample operations are used to adjust the feature scales, ensuring that all feature maps are aligned to the same size. Subsequently, the fused features are processed through the to further optimize feature representation, enabling sufficient interaction between different channels. The features are then enhanced using the RepBlock module. Finally, a Split operation divides the features into two subsets, which are utilized for subsequent high-level information distribution, as illustrated in Figure 3.
In the High-Level Feature Collection (High-GD) stage, Gold-YOLO employs the Transformer mechanism for global relationship modeling, allowing high-level features to directly integrate key low-level information without relying on intermediate-layer feature propagation. Traditional PANet suffers from significant computational redundancy during the feature propagation process. Gold-YOLO optimizes high-level feature representation through a self-attention mechanism, enabling the efficient interaction of information across different scales. The computation is as follows.
In the High-Level Feature Collection (High-GD) stage, Gold-YOLO employs the Transformer mechanism for global relationship modeling, allowing high-level features to directly integrate key low-level information without relying on intermediate-layer propagation. As shown in Equation (5), the fused representation is generated by applying a Transformer encoder to the aligned low-level features :
The Transformer, through its global attention mechanism, allows high-level features to effectively complement low-level features without the need for gradual feedback. This mechanism enhances the model’s ability to perceive small target features while improving computational efficiency.
Furthermore, to further optimize the allocation of feature information, Gold-YOLO uses the Inject module for dynamic feature distribution, ensuring that high-level semantic features are accurately fed back to the shallow layers while also ensuring that shallow local features are effectively transmitted to the detection head after fusion. The Inject mechanism employs Local–Global Fusion, enabling the adaptive integration of the local features at the current scale, Xlocal, and the cross-scale global features, Xglobal.
(2) GSConv
To further alleviate the issue of excessive parameter size in the deeper layers of the original YOLOv8 feature extraction network, this paper places GSConv after the BSBlock module to bridge the deeper layers of the backbone network with the shallower layers of the neck network.
The network structure of GSConv is shown in Figure 7. It adopts a two-stage computational structure: first, standard convolution (Conv) is applied to the input features for initial downsampling, enhancing the feature representation capability; then, depthwise separable convolution (DWConv) is used to extract features from the convolved results, reducing computational complexity while preserving key spatial information. These two computational results are concatenated along the channel dimension and undergo a channel shuffle operation to enhance the interaction of information between channels, such that the final output has twice the number of channels as the concatenated input feature maps.
4. Experiment
4.1. Datasets and Parameter Setting
To evaluate the effectiveness and overall performance of the proposed architecture, this study constructs a dataset focused on the surface bolts of railway steel truss bridges. The dataset consists of raw images collected and preprocessed using the SAF slicing method. The image acquisition process is carried out by a DJI M30 UAV, which is equipped with a stabilized gimbal capable of four-degree-of-freedom rotation. The camera supports 16× hybrid optical zoom, ensuring stable and clear imaging of ground infrastructure from altitudes of up to 100 m, which meets the precise data collection requirements for railway steel truss bridge inspections.
The original dataset comprises 53 images, with 46 images designated for training and 7 images for validation. After SAF preprocessing, the dataset expands to a total of 1115 images, including 891 training images, 112 validation images, and 112 test images. As shown in Table 1 after SAF preprocessing, all images were resized to 640 × 640 pixels for consistency and effective training. The dataset composition is summarized below.

Table 1.
Summary of dataset composition after SAF slicing.
The input image dimensions vary depending on the model configuration. The dataset is labeled into three mutually exclusive categories: boltCorrosion (bolts showing visible rust, pitting, or surface material degradation), boltMissing (positions where the bolt is completely absent or visibly disconnected), and boltNormal (bolts with no apparent structural damage or corrosion).
In total, the dataset contains 10,221 instances of boltNormal, 3956 instances of boltCorrosion, and 34 instances of boltMissing, revealing a class imbalance that may impact detection performance on rare defect types. All annotations were manually verified by two certified railway bridge inspection experts to ensure consistency and reliability in the labeling process.
The experiments are conducted on a system running Ubuntu 18.04 with Python 3.8, PyTorch 1.7.1, CUDA 11.1, and cuDNN 8.0.4, utilizing an NVIDIA GeForce RTX 4090 GPU. More settings are shown in Table 2.
Table 2.
Training parameters.
4.2. Evaluation Metric
In object detection, several metrics are used to evaluate the accuracy of a model. True Positives (TPs) are the correctly detected objects, i.e., the objects that are correctly identified by the model. False Positives (FPs) are the incorrectly detected objects, i.e., the objects that the model incorrectly identifies as present. False Negatives (FNs) are the objects that the model fails to detect, i.e., the objects that are present but not identified by the model.
Precision (P) is the ratio of TPs to the sum of TPs and FPs. It indicates the accuracy of the positive predictions made by the model:
Recall (R) is the ratio of TPs to the sum of TPs and FNs. It measures the model’s ability to identify all relevant objects in the dataset:
Additionally, Mean Average Precision (mAP) is calculated by taking the average of the precision values at different recall levels for each class and then averaging the results across all classes. mAP combines both precision and recall, providing an overall measure of the model’s performance.
where is the Average Precision for class i and N is the number of object classes in the dataset.
4.3. Comparison Experiment on SAF Slicing Preprocessing
Before conducting the ablation experiments, we first evaluated the impact of SAF preprocessing by training the dataset before and after SAF slicing using the original YOLOv8s network and compared the performance differences. The evaluation metric used in this experiment is mean Average Precision (mAP), and the results are shown in Table 3.
Table 3.
Comparative experimental results of SAF preprocessing.
As observed in Table 3, without modifying the network structure or changing the overall pixel composition of the dataset, simply applying SAF slicing during training led to a substantial performance gain. This improvement can be attributed to the exclusion of irrelevant image regions: after slicing, patches without labeled targets are no longer passed through the network, effectively filtering out background noise. This reduces the burden on convolutional layers and enhances the network’s focus on meaningful features.
It is also important to note that SAF slicing is applied not only during training but also in the inference phase. During inference, each image is sliced into overlapping patches of 666 × 500 pixels, and detection results from all patches are concatenated back to the original image coordinates.
Next, an inference comparison of the algorithm’s schematic diagram is conducted. At this stage, the training weights obtained after SAF slicing preprocessing are uniformly used. However, during inference, two cases are handled separately: one without SAF slicing preprocessing and the other with SAF slicing preprocessing. The results are shown in Figure 8.

Figure 8.
Comparison of algorithm results (left) without, (Right) with SAF preprocessing.
The final inference example images provide an intuitive comparison of the differences before and after applying SAF slicing preprocessing during the inference stage. In the results without SAF preprocessing, as shown on the left side of Figure 8, the number of detected bolt targets is relatively low compared to the right side of Figure 8. Additionally, on the left side of Figure 8, the boltNormal” label in the lower right part is misclassified as boltCorrosion”. In contrast, detection results on the right side of Figure 8 show that the misclassification is resolved.
From the above experiment, it can be concluded that SAF slicing preprocessing effectively enhances both the detection precision and the accuracy of the algorithm, whether applied during the training or inference stage.
4.4. Ablation Study
After demonstrating that SAF slicing preprocessing effectively improves model performance on datasets with large image sizes and a high proportion of small objects, the ablation experiments on CSEANet were conducted using datasets that had been preprocessed with SAF slicing. For the inference example results, the images are first applied with SAF preprocessing, and concatenated back form the original image after the model inference. The results of the ablation studies are shown in Table 4, Table 5, Table 6 and Table 7.
Table 4.
Experimental results of model ablation with all labels.
Table 5.
Experimental results of model ablation with the boltCorrosion label.
Table 6.
Experimental results of model ablation with the boltMissing label.
Table 7.
Experimental results of model ablation with the boltNormal label.
The ablation experimental results indicate that, on average, across all labels, MBConvBlock significantly improves mAP, suggesting that, overall, the key to performance enhancement lies in the feature extraction capability of the shallow backbone network. When MBConvBlock + BSBlock were applied to modify the backbone network, or when only BoltFusionFPN was applied to modify the neck network, the overall mAP did not exceed 0.9. However, when both MBConvBlock and BSBlock were combined, the mAP reached 0.952, proving that both feature extraction capabilities and multi-level feature fusion were significantly improved.
For bolt corrosion detection, adding MBConvBlock, BSBlock, and BoltFusionFPN modules individually all improved mAP, but the combination of MBConvBlock and BSBlock resulted in a higher mAP than adding only BoltFusionFPN. This indicates that BoltFusionFPN still suffers from some information loss. For bolt missing detection, a significant mAP improvement was observed when MBConvBlock was added alone, indicating that missing bolt targets particularly benefit from enhanced shallow feature attention. Finally, for bolt normal detection, when all three modules were added, the mAP reached 0.945. Although this is slightly below the best result, it still represents a 2.9% improvement over the original YOLOv8, which demonstrates a significant enhancement in performance.
4.5. Comparative Experiment
To evaluate the performance of the proposed algorithm, we compared it with several mainstream object detection methods. Faster R-CNN [57] generates candidate regions through a Region Proposal Network (RPN), followed by a fully connected network for object classification and bounding box regression. It is well-suited for complex scenes. Cascade R-CNN [58] builds upon Faster R-CNN by utilizing a multi-stage detection strategy to refine detection results, particularly excelling in multi-scale and small object detection. RetinaNet [59] introduces the Focal Loss to address the class imbalance problem, demonstrating strong performance in highly imbalanced detection tasks. CenterNet [60] simplifies the detection process by regressing the center points and object sizes, enabling efficient target localization and classification, especially in real-time detection scenarios.
These methods employ different strategies to improve detection accuracy and speed, each with its own advantages and applicable scenarios. Comparing them with our proposed algorithm provides a comprehensive assessment of its performance in complex object detection tasks, and the results are shown in Table 8.
Table 8.
Performance comparison of different methods.
In this experiment, CSEANet demonstrated a significant improvement over other mainstream object detection algorithms, particularly in terms of accuracy. While traditional two-stage methods, such as Faster R-CNN, have long been recognized for their exceptional precision in small object detection tasks in complex scenarios, the single-stage model CSEANet, based on an improved YOLOv8, achieved a breakthrough in accuracy. This highlights the considerable potential of single-stage models in enhancing detection performance, particularly in terms of precision.
As a classical two-stage object detection method, Faster R-CNN generates candidate regions by a Region Proposal Network (RPN) and relies on a region-based convolutional neural network (R-CNN) for fine-grained classification and bounding box regression for each candidate region. Faster R-CNN shows good accuracy when dealing with larger objects. However, if the object is small (which means the background will be included in the ROI or the noise level is high), Faster R-CNN will always drop a lot of accuracy compared with R-CNN because the information will be lost, and lots of computation is wasted in the process of candidate box generation. However, Faster R-CNN is still used in most high-precision tasks because we can still use the information in region suggestions to guide the box to stay at the target.
In contrast, CSEANet adopts the single-stage detection framework of YOLOv8, retaining its excellent inference speed and real-time performance while incorporating innovative improvements such as the introduction of SAF slicing preprocessing, the optimization of the backbone network with MBConvBlock and CBAM modules, and multi-scale feature fusion through BoltFusionFPN. These advancements significantly enhance the accuracy of small object detection. Experimental results show that CSEANet achieves mAP@50 and mAP@75 scores of 0.998 and 0.922, respectively, far surpassing Faster R-CNN’s 0.486 and 0.174, as well as YOLOv8’s 0.868 and 0.808. This demonstrates the substantial improvements in both accuracy and small object detection performance provided by CSEANet.
CSEANet’s advantages are particularly prominent in small object detection. By utilizing SAF slicing preprocessing, CSEANet more effectively captures the features of small objects, reducing the interference from background noise and allowing small objects to be more clearly represented and detected. Furthermore, CSEANet employs MBConvBlock and CBAM modules in the backbone network to optimize shallow feature extraction, enabling the network to more precisely focus on small object regions and further enhancing detection performance. Additionally, by replacing the C2f module in YOLOv8 with BSBlock, CSEANet effectively reduces computational redundancy, improves feature extraction efficiency, and mitigates the common computational overhead issues found in Faster R-CNN and YOLOv8.
The success of CSEANet demonstrates the immense potential of single-stage detection frameworks in enhancing small object detection accuracy, especially when combined with lightweight strategies and optimized feature fusion techniques. Through innovative designs in the backbone and neck networks, CSEANet not only significantly outperforms traditional two-stage methods in detection accuracy but also overcomes the limitations of Faster R-CNN and similar methods in small object detection while maintaining high inference speed. Therefore, CSEANet provides an efficient and accurate solution for small object detection tasks in complex backgrounds.
4.6. Visualization
To further demonstrate the effectiveness of our proposed method, we present multiple representative detection results in Figure 9, derived from UAV-captured images of railway steel truss bridges. The selected examples reflect a range of inspection scenarios, including different camera angles and bolt regions with varying levels of spatial density—from sparse configurations to areas where bolts are densely packed.

Figure 9.
Final results of surface bolts defect detection for the railway steel truss bridge. The image demonstrates the detection of various defects, including bolt corrosion and missing bolts across different sections of the bridge.
As shown in Figure 9, CSEANet successfully detects and classifies surface bolts across different structural positions. The model accurately identifies bolts in both central and peripheral regions of the image, demonstrating strong spatial generalization. Moreover, all three defect categories—boltNormal, boltCorrosion, and boltMissing—are correctly recognized and clearly annotated with distinct bounding boxes. Even in visually complex areas, the model maintains high localization precision and category-level accuracy.
Each result in Figure 9 corresponds to outputs from the same trained model used in our quantitative evaluations (Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8), ensuring consistency between the visual evidence and reported metrics. These results confirm the model’s robustness and reliability under realistic UAV inspection conditions, offering strong qualitative support for its practical deployment.
5. Limitations and Weaknesses
Despite the promising results of CSEANet for detecting surface defects on bolted connections, several limitations must be acknowledged.
A key limitation is the model’s performance under varying environmental conditions, particularly lighting, shooting distances, and camera angles. These factors can significantly impact detection accuracy. While the system performs well under controlled conditions, real-world environments, especially those involving UAV-based inspections, introduce variability that can obscure bolt defects due to changes in lighting or perspectives.
Additionally, background noise in UAV imagery presents a challenge. The limited diversity in the dataset, particularly regarding background types, may reduce the system’s robustness in real-world applications where backgrounds are often more complex. Although the SAF preprocessing method improves performance, more diverse training data is necessary to enhance the model’s generalizability.
Furthermore, UAVs, while efficient, face challenges like camera calibration, flight stability, and image distortion, especially in hard-to-reach areas. These issues could affect the quality of imagery and, in turn, detection accuracy.
Finally, comparing this study with works like those of Jafari et al. (2025) [61] highlights that accounting for diverse bolt shapes and backgrounds remains a challenge. While our method is robust, incorporating more varied datasets would improve its applicability to a wider range of real-world conditions [62].
6. Conlusions
This paper addresses the challenge of detecting surface bolt defects in railway steel truss bridges using UAV-based vision systems. To improve detection accuracy and efficiency, we propose CSEANet, an enhanced YOLOv8-based framework that integrates SAF slicing for improved small object representation and structural optimizations—MBConvBlock, BSBlock, and BoltFusionFPN—for better feature extraction and multi-scale fusion.
Experimental results show that CSEANet achieves high performance (mAP@50:95 of 0.952) and real-time capability, outperforming baseline methods, particularly in small object scenarios. These results suggest strong potential for UAV-based deployment in real-world inspection tasks.
However, the current dataset is relatively small (53 original images before augmentation), which may limit the generalizability of the results. Although SAF preprocessing expands the training set and improves model robustness, future work will focus on collecting a larger, more diverse dataset and providing visual examples to better demonstrate data variability and detection effectiveness.
In addition, future research will explore adapting the method to detect other structural defects and deploying the model on embedded UAV platforms with limited computational resources, to further enhance its practical applicability in infrastructure inspection.
Author Contributions
Conceptualization, Y.C.; methodology, Y.S. and Z.Q.; software, Y.C.; validation, Y.C.; investigation, Z.Q.; resources, Z.W. and Y.G.; data curation, Z.Q.; writing—original draft preparation, Y.C. and Y.S.; visualization, Y.C.; supervision, Y.C. and Z.W.; project administration, Z.W.; funding acquisition, Z.W. and Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National College Student Innovation and Entrepreneurship Training Program, project number 2024100041987.
Data Availability Statement
The data presented in this study are not publicly available due to privacy and security considerations related to critical infrastructure information. Requests for data access may be considered on a case-by-case basis by contacting the corresponding authors.
Conflicts of Interest
Author Yifan Sun was employed by CRRC Qingdao Sifang Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Guo, F.; Qian, Y.; Wu, Y.; Leng, Z.; Yu, H. Automatic railroad track components inspection using real-time instance segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 362–377. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F.; Wang, Z.; Jia, L. Hybrid deep learning architecture for rail surface segmentation and surface defect detection. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 227–244. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Wang, Z.; Jia, L. A UAV-based visual inspection method for rail surface defects. Appl. Sci. 2018, 8, 1028. [Google Scholar] [CrossRef]
- Chen, P.; Wu, Y.; Qin, Y.; Yang, H.; Huang, Y. Rail fastener defect inspection based on UAV images: A comparative study. Proc. EITRT 2019, 640, 685–694. [Google Scholar]
- Sahebdivani, S.; Arefi, H.; Maboudi, M. Rail track detection and projection-based 3D modeling from UAV point cloud. Sensors 2020, 20, 5220. [Google Scholar] [CrossRef]
- Geng, Y.; Pan, F.; Jia, L.; Wang, Z.; Qin, Y.; Tong, L.; Li, S. UAV-LiDAR-based measuring framework for height and stagger of high-speed railway contact wire. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7587–7600. [Google Scholar] [CrossRef]
- Ali, R.; Kang, D.; Suh, G.; Cha, Y.-J. Real-time multiple damage mapping using autonomous UAV and deep faster region-based neural networks for GPS-denied structures. Autom. Constr. 2021, 130, 103831. [Google Scholar] [CrossRef]
- Kang, D.; Cha, Y.-J. Autonomous UAVs for structural health monitoring using deep learning and an ultrasonic beacon system with geo-tagging. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 885–902. [Google Scholar] [CrossRef]
- Waqas, A.; Kang, D.; Cha, Y.J. Deep learning-based obstacle-avoiding autonomous UAVs with fiducial marker-based localization for structural health monitoring. Struct. Health Monit. 2024, 23, 971–990. [Google Scholar] [CrossRef]
- Outay, F.; Mengash, H.A.; Adnan, M. Applications of unmanned aerial vehicle (UAV) in road safety, traffic and highway infrastructure management: Recent advances and challenges. Transp. Res. A Policy Pract. 2020, 141, 116–129. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Wu, J.; Kuang, Z.; Wang, L.; Zhang, W.; Wu, G. Context-aware RCNN: A baseline for action detection in videos. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 440–456. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A review of YOLO algorithm developments. Proc. Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zeng, F.; Liu, Y.; Ye, Y.; Zhou, J.; Liu, X. A detection method of edge coherent mode based on improved SSD. Fusion Eng. Des. 2022, 179, 113141. [Google Scholar] [CrossRef]
- Yao, J.; Xiao, S.; Tao, H.; Wen, G.; Zhang, L.; Meng, Y. Enhanced Deeplab Network for Infrared Small Target Detection. In Proceedings of the 2023 8th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 8–10 July 2023; pp. 924–929. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-time vehicle detection based on improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 3507014. [Google Scholar] [CrossRef]
- Lu, Z.; Peng, Y.; Ye, Z.; Jiang, P.; Zhou, T. Infrared small UAV target detection algorithm based on enhanced adaptive feature pyramid networks. IEEE Access 2022, 10, 115988–115995. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, G.; Cai, Z. Small target detection based on squared cross entropy and dense feature pyramid networks. IEEE Access 2021, 9, 55179–55190. [Google Scholar] [CrossRef]
- Li, Z.; He, Q.; Yang, W. E-FPN: An enhanced feature pyramid network for UAV scenarios detection. Vis. Comput. 2025, 41, 675–693. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zheng, X.; Zhang, S.; Li, X.; Li, G.; Li, X. Lightweight bridge crack detection method based on SegNet and bottleneck depth-separable convolution with residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Zhang, Y.; Zhang, H.; Huang, Q.; Han, Y.; Zhao, M. DsP-YOLO: An anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst. Appl. 2024, 241, 122669. [Google Scholar] [CrossRef]
- He, P.; Chen, W.; Pang, L.; Zhang, W.; Wang, Y.; Huang, W.; Han, Q.; Xu, X.; Qi, Y. The survey of one-stage anchor-free real-time object detection algorithms. Proc. SPIE 2024, 13001, 2. [Google Scholar] [CrossRef]
- Hussain, M. Yolov1 to v8: Unveiling each variant–a comprehensive review of yolo. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Vijayakumar, A.; Vairavasundaram, S. Yolo-based object detection models: A review and its applications. Multimed. Tools Appl. 2024, 83, 83535–83574. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Cha, Y.-J.; You, K.; Choi, W. Vision-based detection of loosened bolts using the Hough transform and support vector machines. Autom. Constr. 2016, 71, 181–188. [Google Scholar] [CrossRef]
- Ramana, L.; Choi, W.; Cha, Y.J. Fully automated vision-based loosened bolt detection using the Viola-Jones algorithm. Struct. Health Monit. 2019, 18, 422–434. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Ali, R.; Lewis, J.; Büyüköztürk, O. Deep learning-based structural health monitoring. Autom. Constr. 2024, 161, 105328. [Google Scholar] [CrossRef]
- Li, R.; Shen, Y. YOLOSR-IST: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and YOLO. Signal Process. 2023, 208, 108962. [Google Scholar] [CrossRef]
- Su, J.; Qin, Y.; Jia, Z.; Liang, B. MPE-YOLO: Enhanced small target detection in aerial imaging. Sci. Rep. 2024, 14, 17799. [Google Scholar] [CrossRef]
- Hui, Y.; Wang, J.; Li, B. STF-YOLO: A small target detection algorithm for UAV remote sensing images based on improved SwinTransformer and class weighted classification decoupling head. Measurement 2024, 224, 113936. [Google Scholar] [CrossRef]
- Zeng, M.; He, S.; Zeng, Q.; Niu, Y.; Zhang, R. PA-YOLO: Small Target Detection Algorithm with Enhanced Information Representation for UAV Aerial Photography. IEEE Sens. Lett. 2025, 9, 7500304. [Google Scholar] [CrossRef]
- Bi, J.; Li, K.; Zheng, X.; Zhang, G.; Lei, T. SPDC-YOLO: An Efficient Small Target Detection Network Based on Improved YOLOv8 for Drone Aerial Image. Remote Sens. 2025, 17, 685. [Google Scholar] [CrossRef]
- Wang, K.; Zhou, H.; Wu, H.; Yuan, G. RN-YOLO: A Small Target Detection Model for Aerial Remote-Sensing Images. Electronics 2024, 13, 2383. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, J.; Li, S.; Wang, C.; Zhang, Z.; Zhang, X. AID-YOLO: An Efficient and Lightweight Network Method for Small Target Detector in Aerial Images. Electronics 2024, 13, 3564. [Google Scholar] [CrossRef]
- Ma, Q.; Zhao, W.; Liu, Y.; Liu, Z. DLW-YOLO: An Efficient Algorithm for Small Target Detection. J. Electron. Imaging 2025, 34, 013039. [Google Scholar] [CrossRef]
- Xu, J.; Hu, X.; Zhang, Y.; Li, Z. BHE-YOLO: Effective Small Target Detector for Aluminum Surface Defect Detection. Adv. Theory Simul. 2023, 7, 2300563. [Google Scholar] [CrossRef]
- Xu, D.; Xiong, H.; Liao, Y.; Wang, H.; Yuan, Z.; Yin, H. EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8. Sensors 2024, 24, 3783. [Google Scholar] [CrossRef]
- Zhong, J.; Zhang, J. MIR-YOLO: Remote Sensing Small Target Detection Network Based on Visible-Infrared Dual Modality. Digit. Signal Process. 2025, 162, 105158. [Google Scholar] [CrossRef]
- Betti, A.; Tucci, M. YOLO-S: A Lightweight and Accurate YOLO-like Network for Small Target Detection in Aerial Imagery. Sensors 2023, 23, 1865. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Lin, R.; Yue, H.; Huang, H.; Yang, Y.; Yao, Z. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2020, 8, 27574–27583. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Y.; Yu, X.; Bi, H.; Chen, Z.; Li, H. MBAB-YOLO: A Modified Lightweight Architecture for Real-Time Small Target Detection. IEEE Access 2023, 11, 78384–78401. [Google Scholar] [CrossRef]
- Huangfu, Z.; Li, S.; Yan, L. Ghost-YOLO v8: An Attention-Guided Enhanced Small Target Detection Algorithm for Floating Litter on Water Surfaces. Comput. Mater. Contin. 2024, 80, 3713–3731. [Google Scholar] [CrossRef]
- Hui, Y.; You, S.; Hu, X.; Yang, P.; Zhao, J. SEB-YOLO: An Improved YOLOv5 Model for Remote Sensing Small Target Detection. Sensors 2024, 24, 2193. [Google Scholar] [CrossRef]
- Shin, Y.; Shin, H.; Ok, J.; Back, M.; Youn, J.; Kim, S. DCEF2-YOLO: Aerial Detection YOLO with Deformable Convolution–Efficient Feature Fusion for Small Target Detection. Remote Sens. 2024, 16, 1071. [Google Scholar] [CrossRef]
- Xu, C.; Dong, Z.; Zhong, S.; Chen, Y.; Pan, S.; Wu, M. Fusion network for small target detection based on YOLO and attention mechanism. Optoelectron. Lett. 2024, 20, 372–378. [Google Scholar] [CrossRef]
- Xia, W.; Li, P.; Huang, H.; Li, Q.; Yang, T.; Li, Z. TTD-YOLO: A Real-Time Traffic Target Detection Algorithm Based on YOLOV5. IEEE Access 2024, 12, 66419–66431. [Google Scholar] [CrossRef]
- Wu, X.; Liang, J.; Yang, Y.; Li, Z.; Jia, X.; Pu, H.; Zhu, P. SAW-YOLO: A Multi-Scale YOLO for Small Target Citrus Pests Detection. Agronomy 2024, 14, 1571. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar] [CrossRef]
- Jafari, F.; Dorafshan, S. Condition assessment of bolted connections in steel structures using deep learning. Innov. Infrastruct. Solut. 2025, 10, 65. [Google Scholar] [CrossRef]
- Jafari, F.; Dorafshan, S.; Kaabouch, N. Segmentation of fatigue cracks in ancillary steel structures using deep learning convolutional neural networks. In Proceedings of the 2023 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Seattle, WA, USA, 28–30 June 2023; pp. 872–877. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).