
Person Recognition via Gait: A Review of Covariate Impact and Challenges


Abstract
1. Introduction
- This research discovers and investigates numerous gait recognition techniques under different covariates conditions, including both traditional approaches and advanced machine learning approaches, while underlining their respective limitations.
- It describes data repositories used for gait recognition, along with their limitations and challenges.
- It outlines common evaluation metrics usually employed as standard practice and specifies which metrics are most effective for addressing different covariates.
- It also provides an in-depth analysis of gait identification methods, examining their performance across various datasets, along with their advantages and disadvantages.
- It also outlines the theoretical modeling of covariate impacts on the gait identification system, addressing real-world applications and deployment challenges in existing surveillance methods and actionable future research recommendations.
2. Materials and Methods
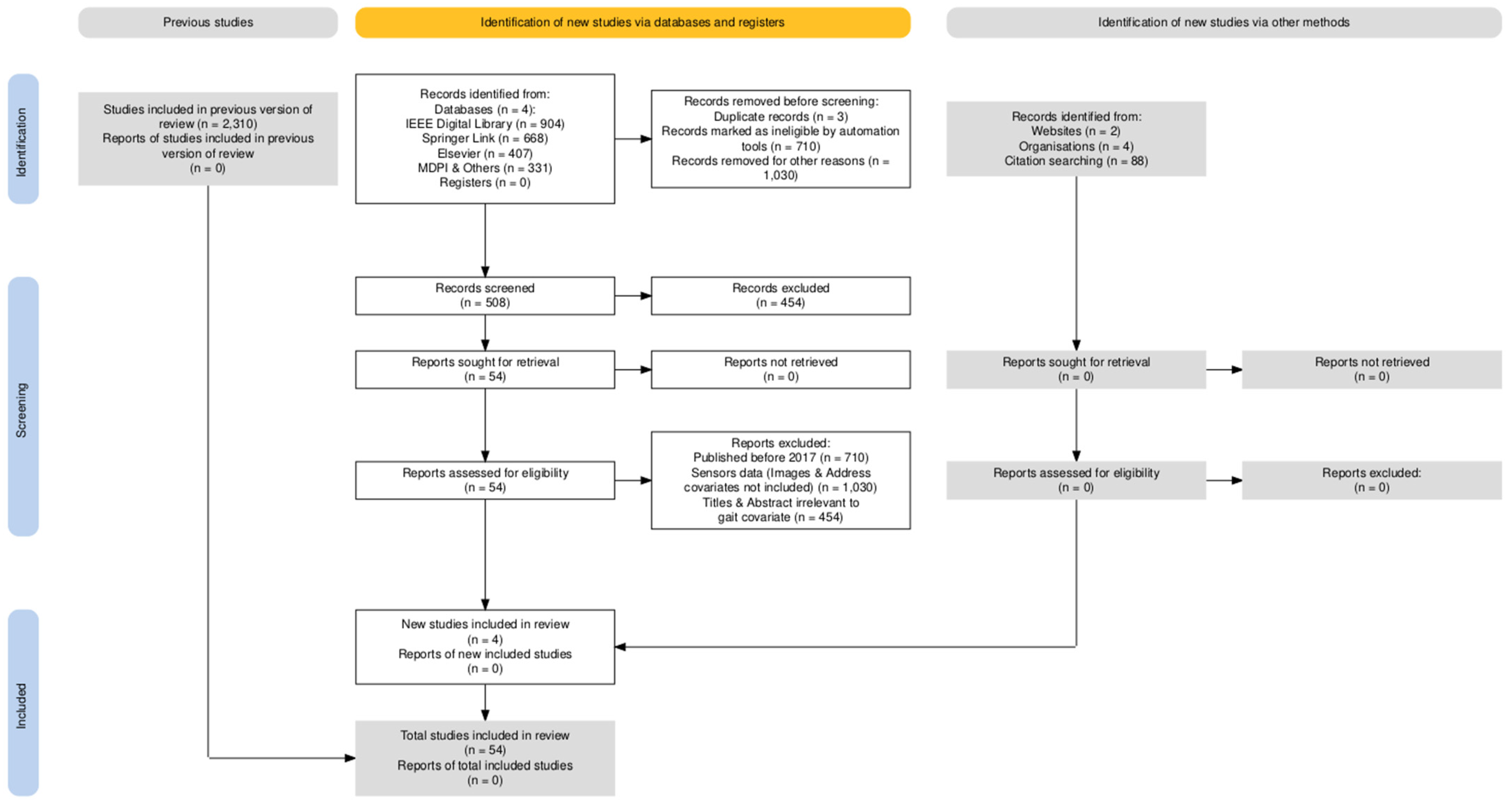
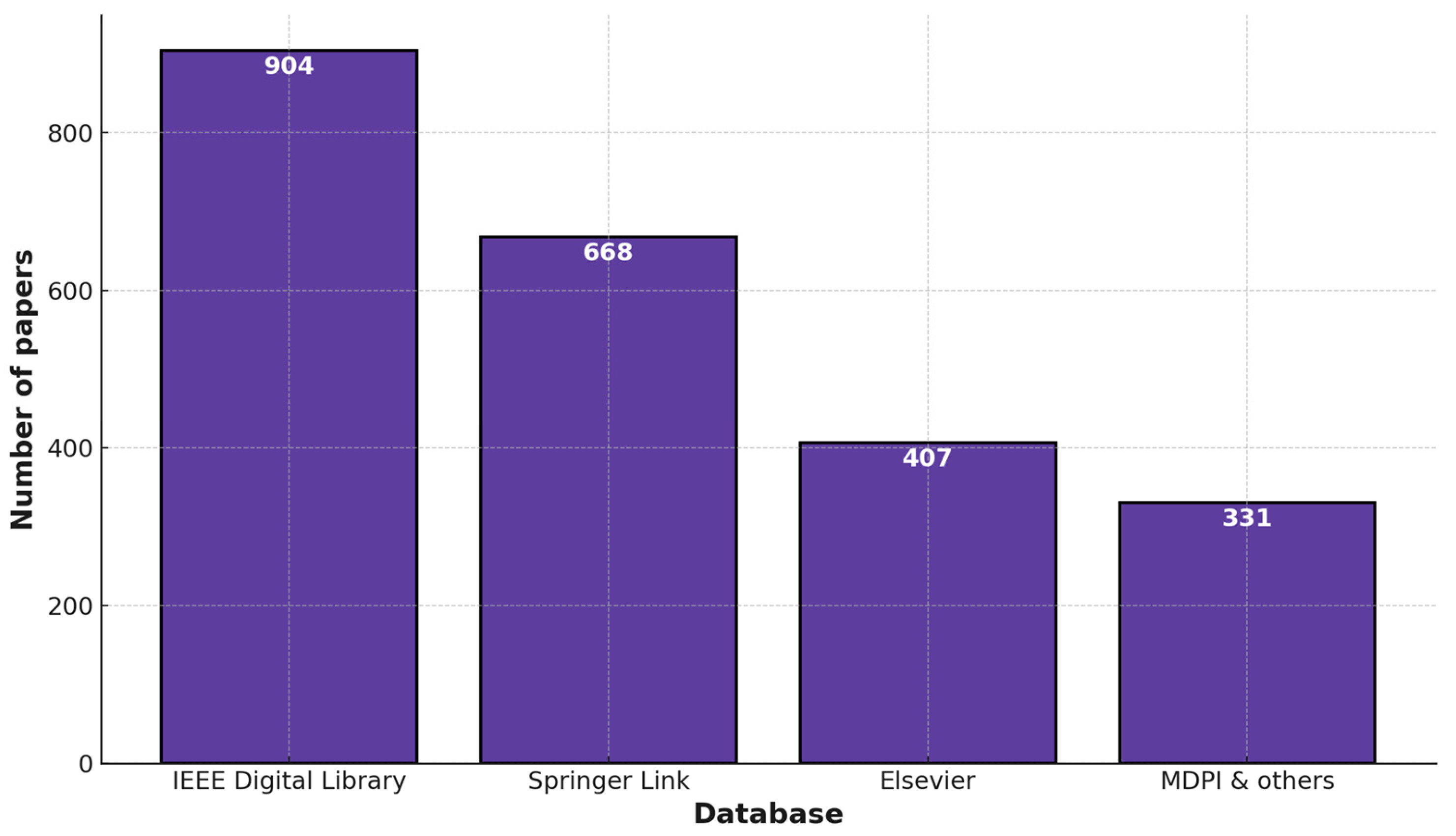
2.1. Search Databases
2.2. Filtering Criteria
2.3. Eligibility Criteria
2.4. Inclusion Criteria
2.5. Data Analysis
2.5.1. Year-Wise Evaluation
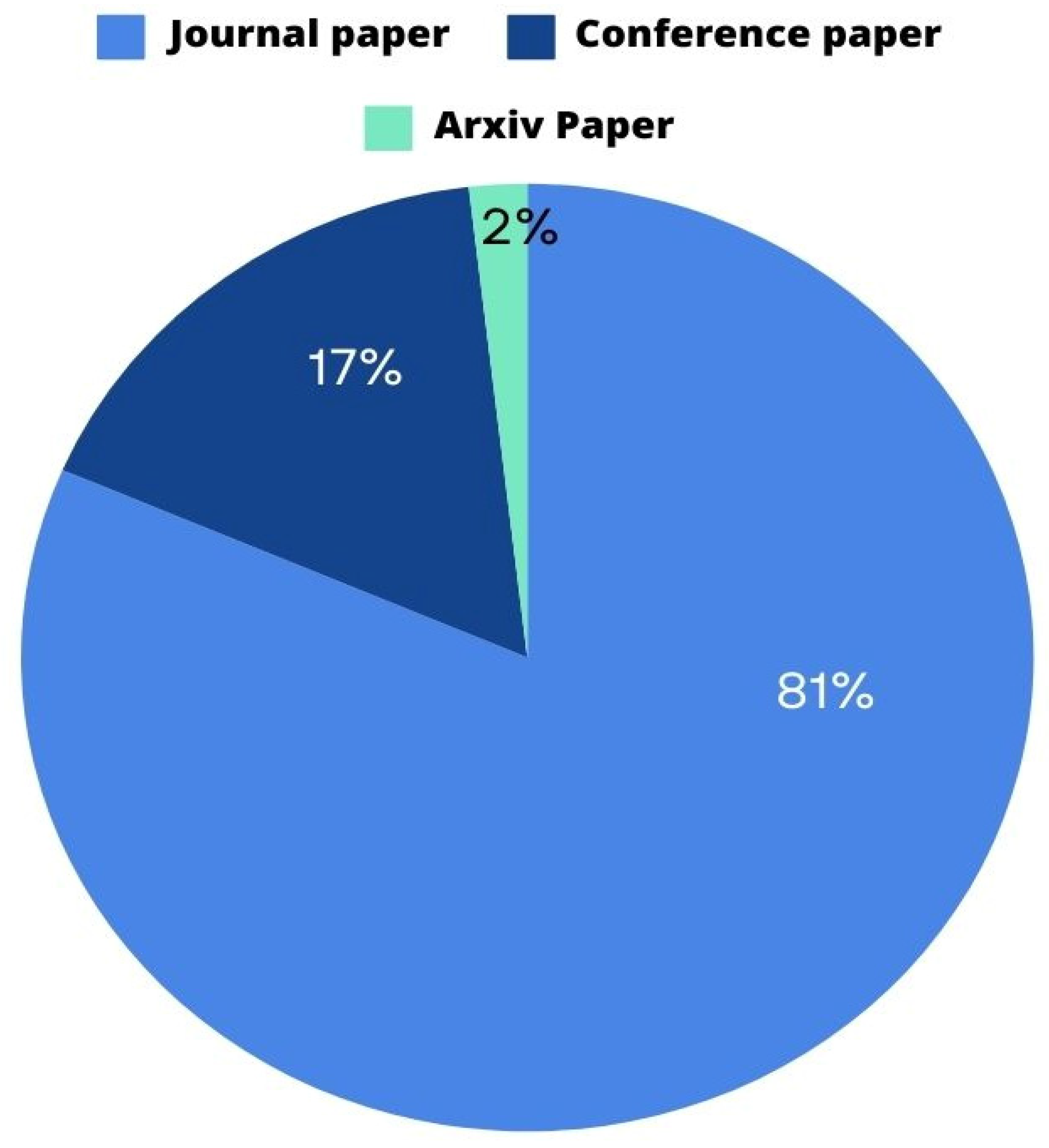
2.5.2. Type of Selected Articles
2.6. Source Database
Limitations of Existing Datasets and Recommendations
2.7. Evaluation Metrics
2.7.1. Sensitivity
2.7.2. False Positive Rate
2.7.3. Precision
2.7.4. F1-Score
2.7.5. Receiver Operating Characteristic
2.7.6. Area Under the ROC Curve
2.7.7. Equal Error Rate (EER)
2.7.8. Cumulative Matching Characteristic (CMC)
2.7.9. Rank-1 Accuracy
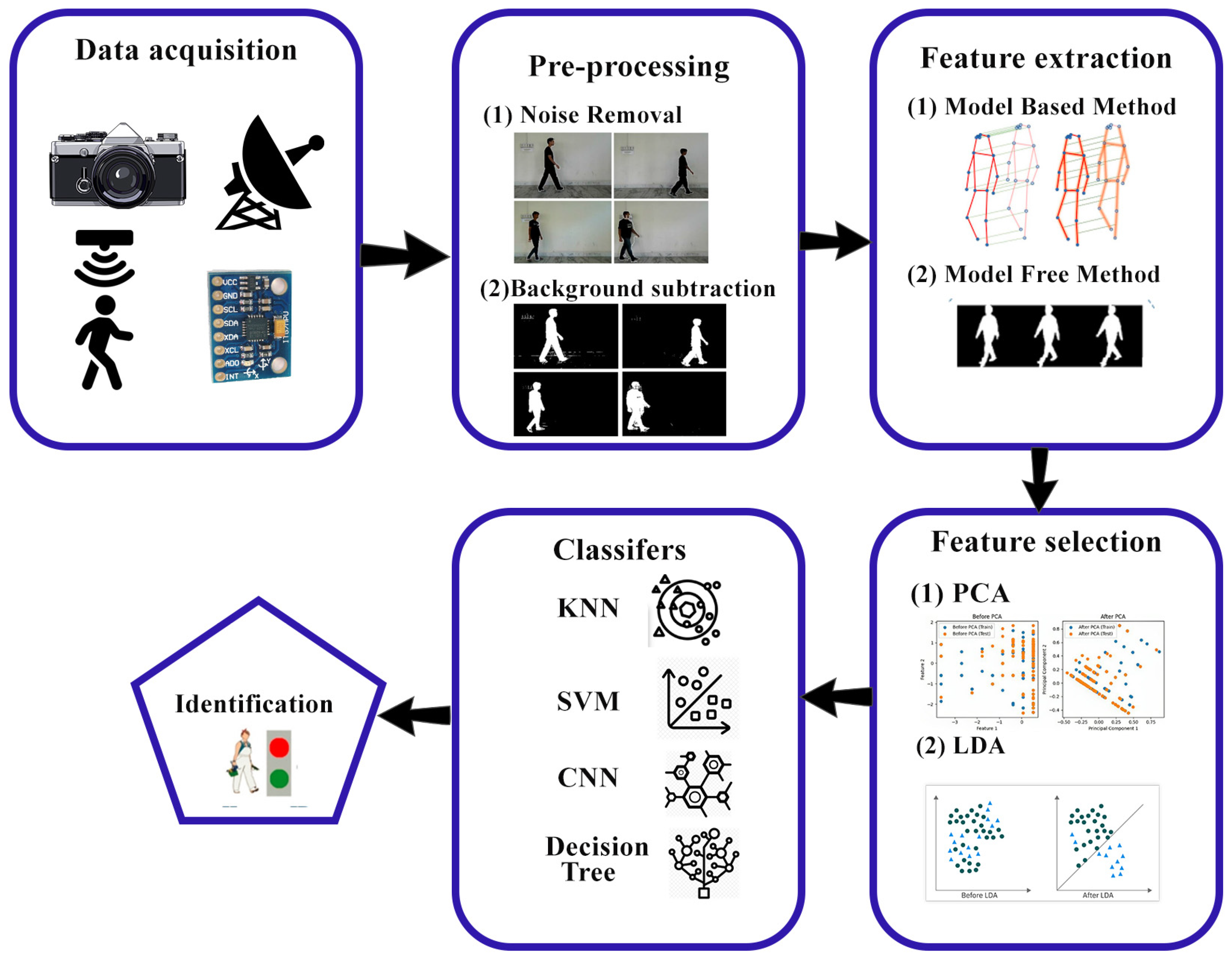
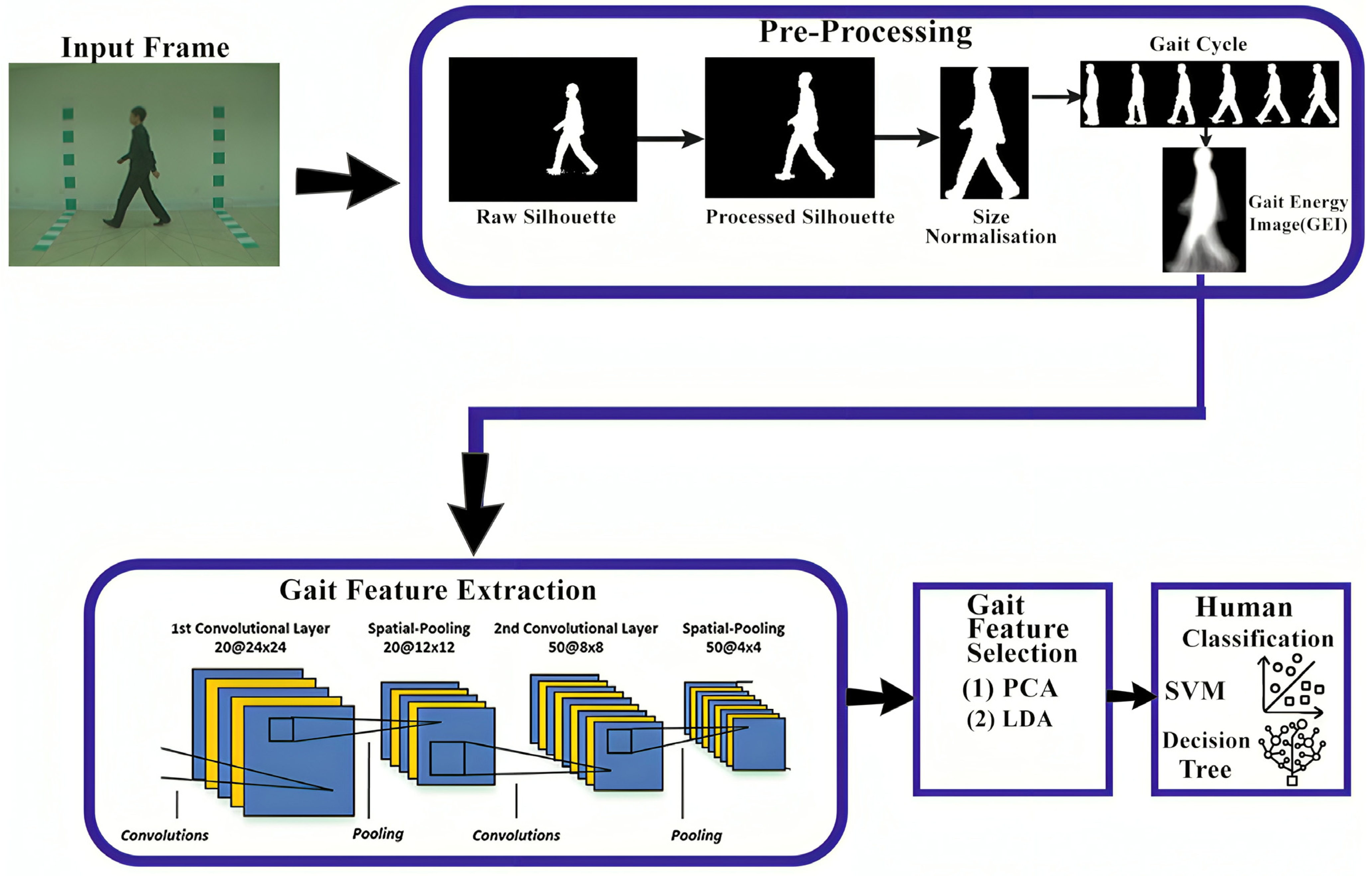
2.8. Gait Recognition Under Different Covariates
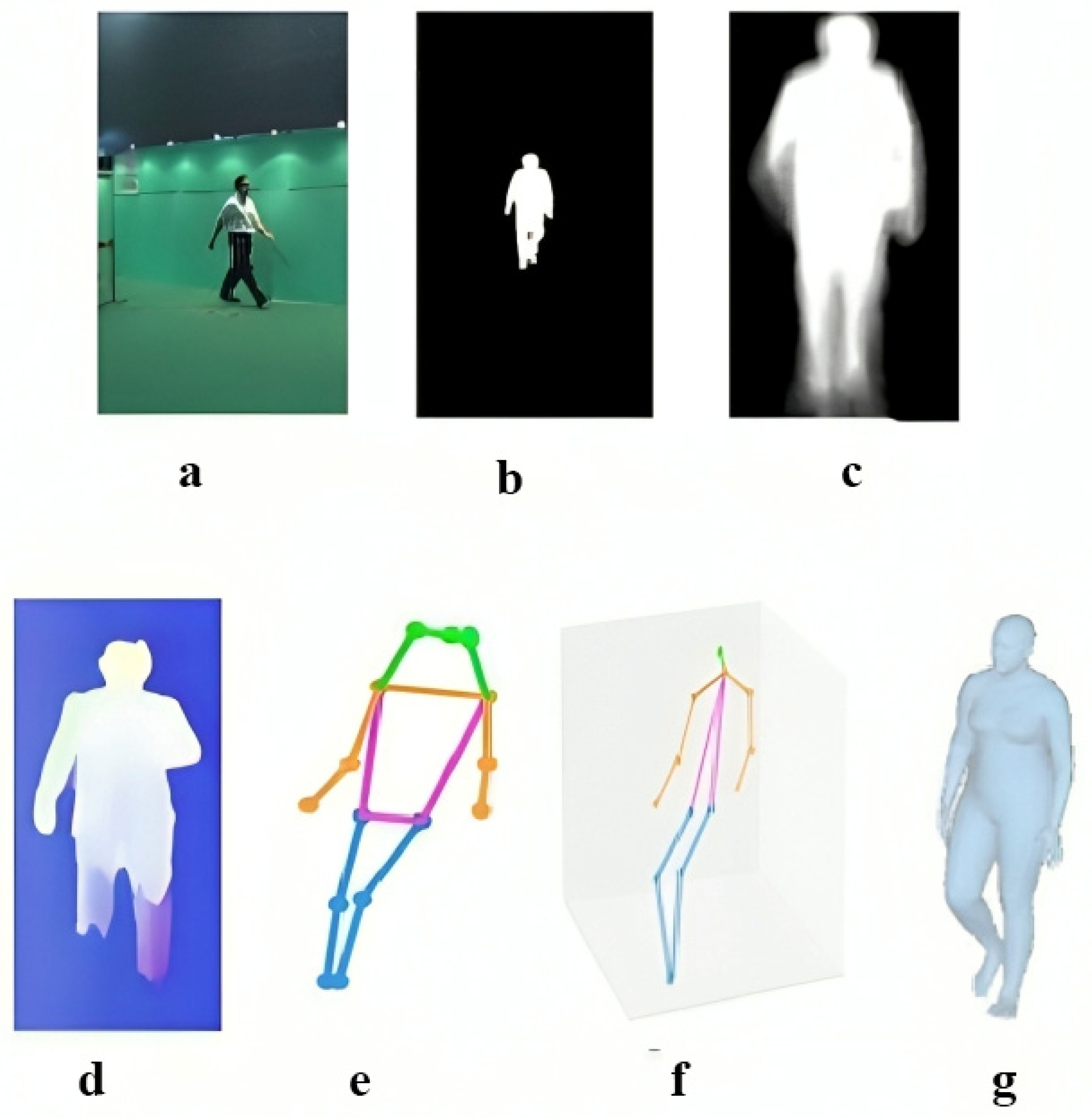
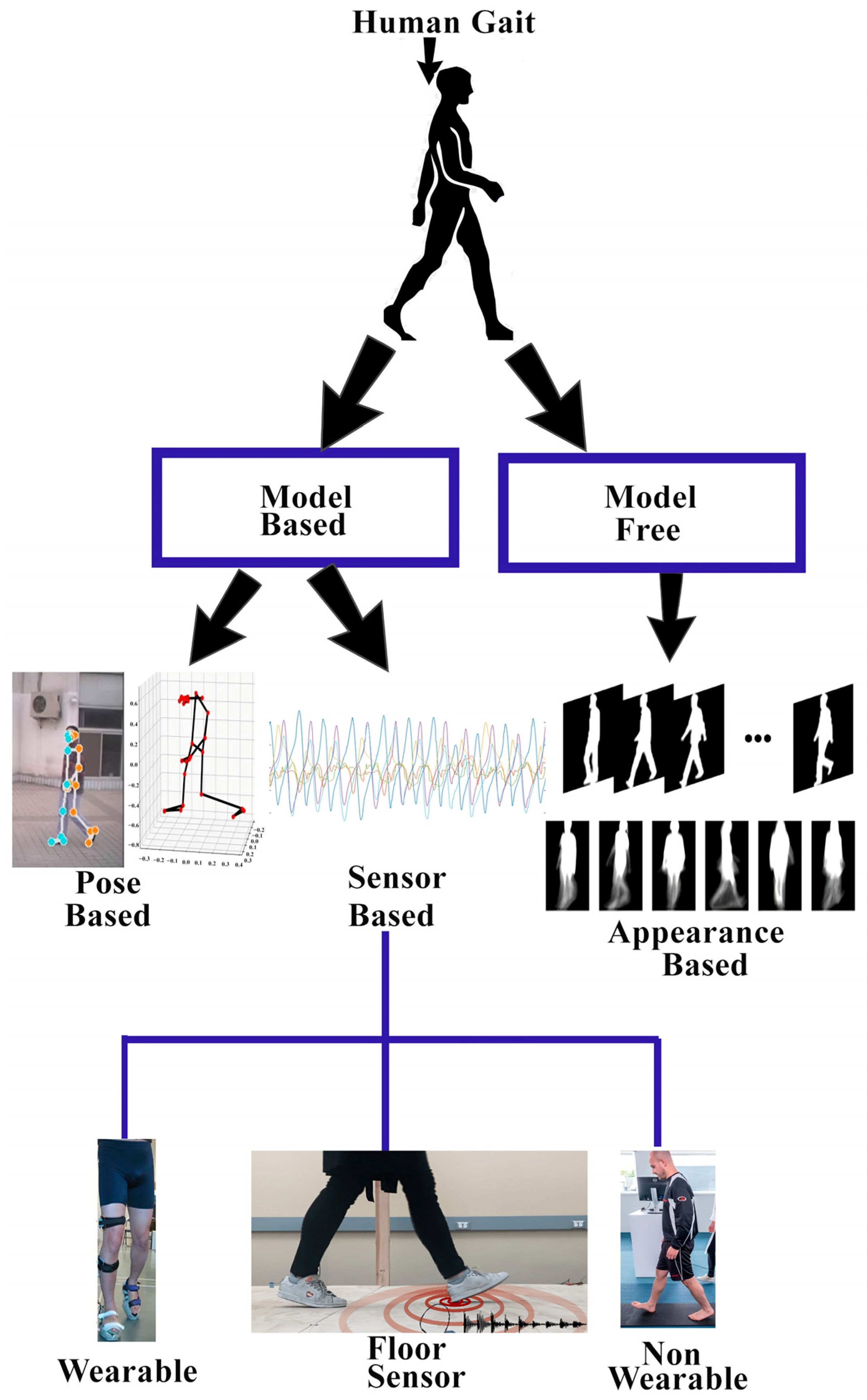
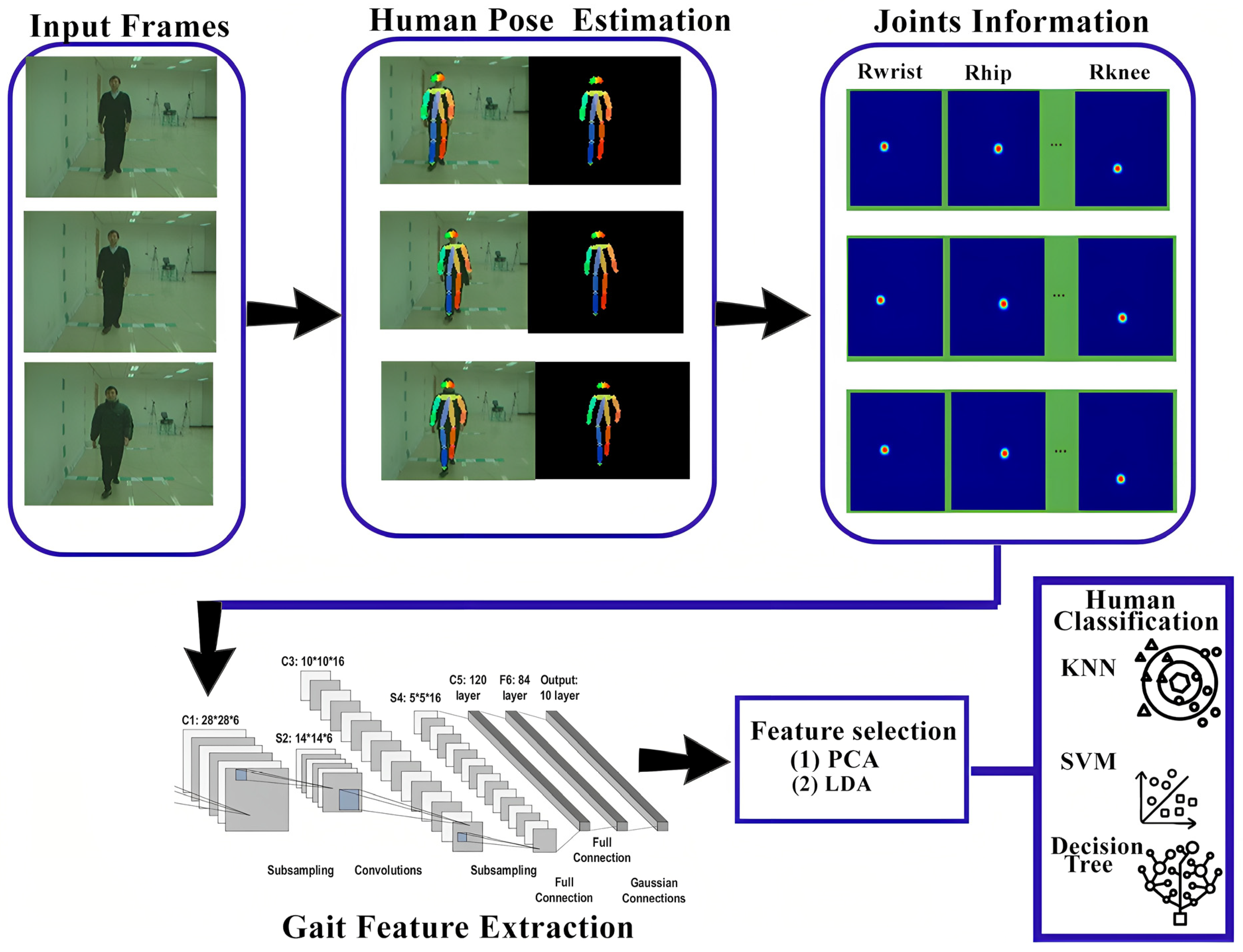
2.8.1. Model-Based Techniques
2.8.2. Model-Free Techniques
2.8.3. Fusion Model
3. Results
3.1. Comparison with Traditional Baselines
3.2. Inconsistencies in Prior Findings and the Need for Standardized Benchmarks
3.2.1. Experimental Circumstances Impacting Performance Comparisons
3.2.2. Inconsistent Accuracy Rates
3.2.3. Future Benchmarks for Equitable Comparisons
3.3. Quantitative Covariate Impact and Model Robustness Comparison
3.3.1. Creation of New Datasets
3.3.2. Integration of Multimodal Biometrics
3.4. Theoretical Modeling of Covariate Impacts on Gait Recognition
3.4.1. Influence of View Angles
3.4.2. Impact of Clothing Variations
3.4.3. Influence of Walking Speed
3.4.4. Combining Covariate Factors
4. Conclusions and Future Research
4.1. Real-World Applications and Deployment Challenges
4.1.1. Surveillance Conditions
4.1.2. Ethical and Privacy Concerns
4.1.3. Scalability Issues
4.1.4. Learning Challenges
4.2. Integration into Existing Surveillance Systems
4.2.1. Technical Integration
4.2.2. Challenges in Integration
4.2.3. Deployment Challenges
4.2.4. Practical Deployment Scenarios
4.3. Actionable Future Research Recommendations
4.3.1. Handling Low-Light Conditions
4.3.2. Addressing Occlusions
4.3.3. Datasets Needed for Low-Light and Occlusion Handling
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Makhdoomi, N.A.; Gunawan, T.S.; Habaebi, M.H. Human gait recognition and classification using similarity index for various conditions. IOP Conf. Ser. Mater. Sci. Eng. 2013, 53, 012069. [Google Scholar] [CrossRef]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. A survey of behavioral biometric gait recognition: Current success and future perspectives. Arch. Comput. Meth. Eng. 2021, 28, 107–148. [Google Scholar] [CrossRef]
- Shirke, S.; Pawar, S.S.; Shah, K. Literature review: Model-free human gait recognition. In Proceedings of the 2014 4th International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 7–9 April 2014; pp. 891–895. [Google Scholar]
- Wang, J.; She, M.; Nahavandi, S.; Kouzani, A. A review of vision-based gait recognition methods for human identification. In Proceedings of the 2010 Digital Image Computing: Techniques and Applications (DICTA 2010), Sydney, Australia, 1–3 December 2010; pp. 320–327. [Google Scholar] [CrossRef]
- Wan, C.; Wang, L.; Phoha, V.V. A survey on gait recognition. ACM Comput. Surv. 2019, 51, 1–35. [Google Scholar] [CrossRef]
- Kale, A.; Sundaresan, A.; Rajagopalan, A.N.; Cuntoor, N.P.; Roy-Chowdhury, A.K.; Kruger, V.; Chellappa, R. Identification of humans using gait. IEEE Trans. Image Process. 2004, 13, 1163–1173. [Google Scholar] [CrossRef]
- Kusakunniran, W. Review of gait recognition approaches and their challenges on view changes. IET Biom. 2020, 9, 238–250. [Google Scholar] [CrossRef]
- Huang, X.; Wang, X.; He, B.; He, S.; Liu, W.; Feng, B. Star: Spatio-temporal augmented relation network for gait recognition. IEEE Trans. Biom. Behav. Identity Sci. 2022, 5, 115–125. [Google Scholar] [CrossRef]
- Li, H.; Qiu, Y.; Zhao, H.; Zhan, J.; Chen, R.; Wei, T.; Huang, Z. GaitSlice: A gait recognition model based on spatio-temporal slice features. Pattern Recognit. 2022, 124, 108453. [Google Scholar] [CrossRef]
- Hou, S.; Liu, X.; Cao, C.; Huang, Y. Set residual network for silhouette-based gait recognition. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 384–393. [Google Scholar] [CrossRef]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette analysis-based gait recognition for human identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Parashar, A.; Parashar, A.; Shekhawat, R.S. A robust covariate-invariant gait recognition based on pose features. IET Biom. 2022, 11, 601–613. [Google Scholar] [CrossRef]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y. Multi-view large population gait database with human meshes and its performance evaluation. IEEE Trans. Biom. Behav. Identity Sci. 2022, 4, 234–248. [Google Scholar] [CrossRef]
- Khan, M.A.; Arshad, H.; Damaševičius, R.; Alqahtani, A.; Alsubai, S.; Binbusayyis, A.; Nam, Y.; Kang, B.-G. Human gait analysis: A sequential framework of lightweight deep learning and improved moth-flame optimization algorithm. Comput. Intell. Neurosci. 2022, 2022, 8238375. [Google Scholar] [CrossRef] [PubMed]
- Haddaway, N.R.; Page, M.J.; Pritchard, C.C.; McGuinness, L.A. PRISMA2020: An R package and Shiny app for producing PRISMA 2020-compliant flow diagrams, with interactivity for optimised digital transparency and Open Synthesis. Campbell Syst. Rev. 2022, 18, e1230. [Google Scholar] [CrossRef] [PubMed]
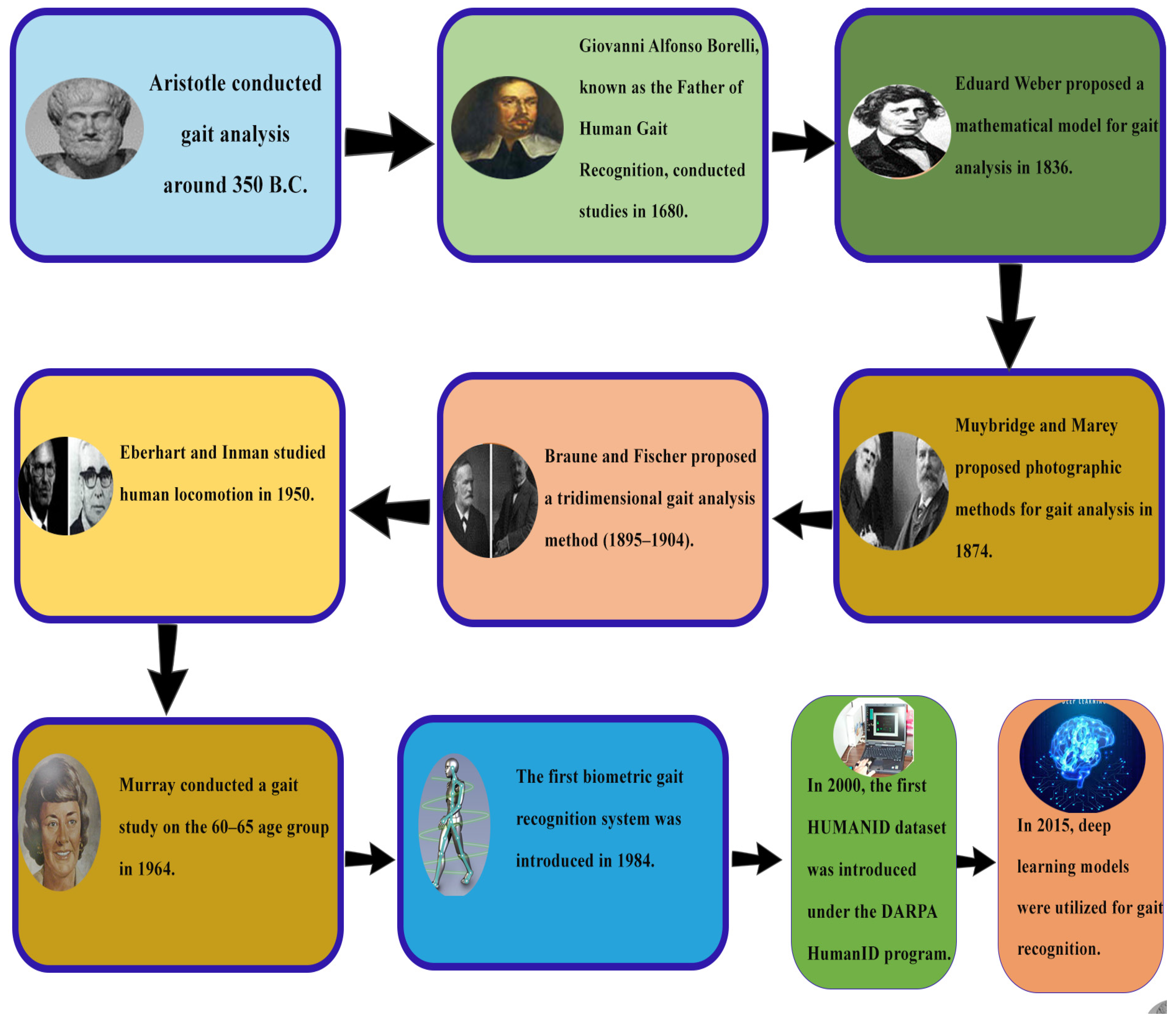
- Provencher, M.T.; Abdu, W.A. Historical Perspective: Giovanni Alfonso Borelli: “Father of Spinal Biomechanics”. Spine 2000, 25, 131. [Google Scholar] [CrossRef]
- Kumar, P.; Mukherjee, S.; Saini, R.; Kaushik, P.; Roy, P.P.; Dogra, D.P. Multimodal gait recognition with inertial sensor data and video using evolutionary algorithm. IEEE Trans. Fuzzy Syst. 2018, 27, 956–965. [Google Scholar] [CrossRef]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-based gait recognition: A survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- Connor, P.; Ross, A. Biometric recognition by gait: A survey of modalities and features. Comput. Vis. Image Underst. 2018, 167, 1–27. [Google Scholar] [CrossRef]
- Giorgi, G.; Martinelli, F.; Saracino, A.; Sheikhalishahi, M. Try walking in my shoes, if you can: Accurate gait recognition through deep learning. In Computer Safety, Reliability, and Security: SAFECOMP 2017 Workshops, ASSURE, DECSoS, SASSUR, TELERISE, and TIPS, Trento, Italy, 12 September 2017; Proceedings 36; Springer International Publishing: Cham, Switzerland, 2017; pp. 384–395. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Horst, F.; Lapuschkin, S.; Samek, W.; Müller, K.R.; Schöllhorn, W.I. Explaining the unique nature of individual gait patterns with deep learning. Sci. Rep. 2019, 9, 2391. [Google Scholar] [CrossRef]
- Hofmann, M.; Geiger, J.; Bachmann, S.; Schuller, B.; Rigoll, G. The TUM Gait from Audio, Image and Depth (GAID) database: Multimodal recognition of subjects and traits. J. Vis. Commun. Image Represent. 2014, 25, 195–206. [Google Scholar] [CrossRef]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Tan, D.; Huang, K.; Yu, S.; Tan, T. Efficient night gait recognition based on template matching. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 1000–1003. [Google Scholar]
- Song, C.; Huang, Y.; Wang, W.; Wang, L. CASIA-E: A large comprehensive dataset for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2801–2815. [Google Scholar] [CrossRef] [PubMed]
- Iwama, H.; Okumura, M.; Makihara, Y.; Yagi, Y. The OU-ISIR gait database comprising the large population dataset and performance evaluation of gait recognition. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1511–1521. [Google Scholar] [CrossRef]
- Makihara, Y.; Mannami, H.; Tsuji, A.; Hossain, M.A.; Sugiura, K.; Mori, A.; Yagi, Y. The OU-ISIR gait database comprising the treadmill dataset. IPSJ Trans. Comput. Vis. Appl. 2012, 4, 53–62. [Google Scholar] [CrossRef]
- Xu, C.; Makihara, Y.; Ogi, G.; Li, X.; Yagi, Y.; Lu, J. The OU-ISIR gait database comprising the large population dataset with age and performance evaluation of age estimation. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 24. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Ngo, T.T.; Makihara, Y.; Takemura, N.; Li, X.; Muramatsu, D.; Yagi, Y. The ou-isir large population gait database with real-life carried object and its performance evaluation. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 5. [Google Scholar] [CrossRef]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 4. [Google Scholar] [CrossRef]
- An, W.; Yu, S.; Makihara, Y.; Wu, X.; Xu, C.; Yu, Y.; Liao, R.; Yagi, Y. Performance evaluation of model-based gait on multi-view very large population database with pose sequences. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 421–430. [Google Scholar] [CrossRef]
- Sarkar, S.; Phillips, P.J.; Liu, Z.; Vega, I.R.; Grother, P.; Bowyer, K.W. The humanid gait challenge problem: Data sets, performance, and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 162–177. [Google Scholar] [CrossRef]
- Seely, R.D.; Samangooei, S.; Lee, M.; Carter, J.N.; Nixon, M.S. The university of southampton multi-biometric tunnel and introducing a novel 3d gait dataset. In Proceedings of the 2008 IEEE Second International Conference on Biometrics: Theory, Applications and Systems, Washington, DC, USA, 29 September–1 October 2008; pp. 1–6. [Google Scholar]
- Shutler, J.D.; Grant, M.G.; Nixon, M.S.; Carter, J.N. On a large sequence-based human gait database. In Applications and Science in Soft Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 339–346. [Google Scholar]
- Khan, M.H.; Li, F.; Farid, M.S.; Grzegorzek, M. Gait recognition using motion trajectory analysis. In Proceedings of the 10th International Conference on Computer Recognition Systems CORES 2017, Polanica Zdroj, Poland, 22–24 May 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 73–82. [Google Scholar]
- Pan, H.; Chen, Y.; Xu, T.; He, Y.; He, Z. Toward complete-view and high-level pose-based gait recognition. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2104–2118. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Liao, R.; Li, Z.; Bhattacharyya, S.S.; York, G. Posemapgait: A model-based gait recognition method with pose estimation maps and graph convolutional networks. Neurocomputing 2022, 501, 514–528. [Google Scholar] [CrossRef]
- Luo, J.; Tjahjadi, T. Gait recognition and understanding based on hierarchical temporal memory using 3D gait semantic folding. Sensors 2020, 20, 1646. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wang, Z. End-to-End Model-Based Gait Recognition with Matching Module Based on Graph Neural Networks. In Proceedings of the 2023 6th International Symposium on Autonomous Systems (ISAS), Nanjing, China, 23–25 June 2023; pp. 1–7. [Google Scholar]
- Choi, S.; Kim, J.; Kim, W.; Kim, C. Skeleton-based gait recognition via robust frame-level matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2577–2592. [Google Scholar] [CrossRef]
- Gao, S.; Yun, J.; Zhao, Y.; Liu, L. Gait-D: Skeleton-based gait feature decomposition for gait recognition. IET Comput. Vis. 2022, 16, 111–125. [Google Scholar] [CrossRef]
- Wang, L.; Chen, J.; Chen, Z.; Liu, Y.; Yang, H. Multi-stream part-fused graph convolutional networks for skeleton-based gait recognition. Connect. Sci. 2022, 34, 652–669. [Google Scholar] [CrossRef]
- Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Gaitgraph: Graph convolutional network for skeleton-based gait recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2314–2318. [Google Scholar]
- Hasan, M.M.; Mustafa, H.A. Learning view-invariant features using stacked autoencoder for skeleton-based gait recognition. IET Comput. Vis. 2021, 15, 527–545. [Google Scholar] [CrossRef]
- Pundir, A.; Sharma, M.; Pundir, A.; Saini, D.; Ouahada, K.; Bharany, S.; Rehman, A.U.; Hamam, H. Enhancing gait recognition by multimodal fusion of mobilenetv1 and xception features via PCA for OaA-SVM classification. Sci. Rep. 2024, 14, 17155. [Google Scholar] [CrossRef]
- Mehmood, A.; Amin, J.; Sharif, M.; Kadry, S.; Kim, J. Stacked-gait: A human gait recognition scheme based on stacked autoencoders. PLoS ONE 2024, 19, e0310887. [Google Scholar] [CrossRef]
- Shopon, M.; Bari, A.H.; Gavrilova, M.L. Residual connection-based graph convolutional neural networks for gait recognition. Vis. Comput. 2021, 37, 2713–2724. [Google Scholar] [CrossRef]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 316–322. [Google Scholar] [CrossRef]
- Asif, M.; Tiwana, M.I.; Khan, U.S.; Ahmad, M.W.; Qureshi, W.S.; Iqbal, J. Human gait recognition subject to different covariate factors in a multi-view environment. Results Eng. 2022, 15, 100556. [Google Scholar] [CrossRef]
- Bukhari, M.; Bajwa, K.B.; Gillani, S.; Maqsood, M.; Durrani, M.Y.; Mehmood, I.; Ugail, H.; Rho, S. An efficient gait recognition method for known and unknown covariate conditions. IEEE Access 2020, 9, 6465–6477. [Google Scholar] [CrossRef]
- Junaid, I.; Ari, S. Gait recognition under different covariate conditions using deep learning technique. In Proceedings of the 2022 IEEE International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 11–15 July 2022; pp. 1–5. [Google Scholar]
- Amin, J.; Anjum, M.A.; Sharif, M.; Kadry, S.; Nam, Y.; Wang, S. Convolutional Bi-LSTM based human gait recognition using video sequences. Comput. Mater. Contin. 2021, 68, 2693–2709. [Google Scholar] [CrossRef]
- Yujie, Z.; Lecai, C.; Wu, Z.; Cheng, K.; Wu, D.; Tang, K. Research on gait recognition algorithm based on deep learning. In Proceedings of the 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021; pp. 405–409. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A. Gait recognition for person re-identification. J. Supercomput. 2021, 77, 3653–3672. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Ali, M.; Alqahtani, A. Gait-CNN-ViT: Multi-model gait recognition with convolutional neural networks and vision transformer. Sensors 2023, 23, 3809. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Muthu, K.S. Gait-vit: Gait recognition with vision transformer. Sensors 2022, 22, 7362. [Google Scholar] [CrossRef]
- Osorio Quero, C.; Durini, D.; Rangel-Magdaleno, J.; Martinez-Carranza, J.; Ramos-Garcia, R. Enhancing 3D human pose estimation with NIR single-pixel imaging and time-of-flight technology: A deep learning approach. J. Opt. Soc. Am. A 2024, 41, 414–423. [Google Scholar] [CrossRef]
- Castro, F.M.; Delgado-Escaño, R.; Hernández-García, R.; Marín-Jiménez, M.J.; Guil, N. AttenGait: Gait recognition with attention and rich modalities. Pattern Recognit. 2024, 148, 110171. [Google Scholar] [CrossRef]
- Yousef, R.N.; Khalil, A.T.; Samra, A.S.; Ata, M.M. Proposed methodology for gait recognition using generative adversarial network with different feature selectors. Neural Comput. Appl. 2024, 36, 1641–1663. [Google Scholar] [CrossRef]
- Nithyakani, P.; Ferni Ukrit, M. Deep multi-convolutional stacked capsule network fostered human gait recognition from enhanced gait energy image. Signal Image Video Process. 2024, 18, 1375–1382. [Google Scholar] [CrossRef]
- Khan, M.A.; Arshad, H.; Khan, W.Z.; Alhaisoni, M.; Tariq, U.; Hussein, H.S.; Alshazly, H.; Osman, L.; Elashry, A. HGRBOL2: Human gait recognition for biometric application using Bayesian optimization and extreme learning machine. Future Gener. Comput. Syst. 2023, 143, 337–348. [Google Scholar] [CrossRef]
- Meng, C.; He, X.; Tan, Z.; Luan, L. Gait recognition based on 3D human body reconstruction and multi-granular feature fusion. J. Supercomput. 2023, 79, 12106–12125. [Google Scholar] [CrossRef]
- Lu, X.; Li, X.; Sheng, W.; Ge, S.S. Long-term person re-identification based on appearance and gait feature fusion under covariate changes. Processes 2022, 10, 770. [Google Scholar] [CrossRef]
- Yao, L.; Kusakunniran, W.; Wu, Q.; Zhang, J.; Tang, Z.; Yang, W. Robust gait recognition using hybrid descriptors based on skeleton gait energy image. Pattern Recognit. Lett. 2021, 150, 289–296. [Google Scholar]
- Yousef, R.N.; Khalil, A.T.; Samra, A.S.; Ata, M.M. Model-based and model-free deep features fusion for high performed human gait recognition. J. Supercomput. 2023, 79, 12815–12852. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, R.; Xue, W.; Yang, M.; Shiraishi, M.; Awai, S.; Maruyama, Y.; Yoshioka, T.; Konno, T. Effective Fusion Method on Silhouette and Pose for Gait Recognition. IEEE Access 2023, 11, 102623–102634. [Google Scholar] [CrossRef]
- Jawed, B.; Khalifa, O.O.; Bhuiyan, S.S.N. Human gait recognition system. In Proceedings of the 2018 7th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 19–20 September 2018; pp. 89–92. [Google Scholar]
- Golingay, L.A.T.; Lacaba, A.A.; Palma, R.K.R.; Par, J.P.; Tabanera, V.J.; Valenzuela, R.V.; Anacan, R.; Villanueva, M. Gait Recognition of Human Walking thru Gait Analysis. In Proceedings of the 2022 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems (ICETSIS), Virtual, 22–23 June 2022; pp. 233–240. [Google Scholar]
- Nahar, S.; Chaudhary, C.; Kathiriya, S. A Model Free Gait Recognition using Random Forest Method. Procedia Comput. Sci. 2024, 235, 1608–1614. [Google Scholar] [CrossRef]
- Güner Şahan, P.; Şahin, S.; Kaya Gülağız, F. A survey of appearance-based approaches for human gait recognition: Techniques, challenges, and future directions. J. Supercomput. 2024, 80, 18392–18429. [Google Scholar] [CrossRef]
- Fan, C.; Liang, J.; Shen, C.; Hou, S.; Huang, Y.; Yu, S. Opengait: Revisiting gait recognition towards better practicality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9707–9716. [Google Scholar]
- Fan, C.; Hou, S.; Huang, Y.; Yu, S. Exploring deep models for practical gait recognition. arXiv 2023, arXiv:2303.03301. [Google Scholar]
- Ur Rehman, A.; Belhaouari, S.B.; Kabir, M.A.; Khan, A. On the use of deep learning for video classification. Appl. Sci. 2023, 13, 2007. [Google Scholar] [CrossRef]
- Darwish, S.M. Design of adaptive biometric gait recognition algorithm with free walking directions. IET Biom. 2017, 6, 53–60. [Google Scholar] [CrossRef]
- Sivarathinabala, M.; Abirami, S.; Baskaran, R. Abnormal gait recognition using exemplar based algorithm in healthcare applications. Int. J. Commun. Syst. 2020, 33, e4348. [Google Scholar]
- Chen, W.; Li, J.; Zhu, S.; Zhang, X.; Men, Y.; Wu, H. Gait recognition for lower limb exoskeletons based on in-teractive information fusion. Appl. Bionics Biomech. 2022, 2022, 9933018. [Google Scholar] [CrossRef] [PubMed]
- Wen, J.; Wang, X. Gait recognition based on sparse linear subspace. IET Image Process. 2021, 15, 2761–2769. [Google Scholar] [CrossRef]
- Qi, Y.J.; Kong, Y.P.; Zhang, Q. A Cross-View Gait Recognition Method Using Two-Way Similarity Learning. Math. Probl. Eng. 2022, 2022, 2674425. [Google Scholar] [CrossRef]
- Ali, B.; Bukhari, M.; Maqsood, M.; Moon, J.; Hwang, E.; Rho, S. An end-to-end gait recognition system for covariate conditions using custom kernel CNN. Heliyon 2024, 10, e32934. [Google Scholar] [CrossRef]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y. End-to-end model-based gait recognition using synchronized multi-view pose constraint. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4106–4115. [Google Scholar]
- Marín-Jiménez, M.J.; Castro, F.M.; Delgado-Escaño, R.; Kalogeiton, V.; Guil, N. UGaitNet: Multimodal gait recognition with missing input modalities. IEEE Trans. Inf. Forensics Secur. 2021, 16, 5452–5462. [Google Scholar] [CrossRef]
- Su, J.; Zhao, Y.; Li, X. Deep metric learning based on center-ranked loss for gait recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4077–4081. [Google Scholar]
- Fendri, E.; Chtourou, I.; Hammami, M. Gait-based person re-identification under covariate factors. Pattern Anal. Appl. 2019, 22, 1629–1642. [Google Scholar] [CrossRef]
- Wang, J.; Hou, S.; Guo, X.; Huang, Y.; Huang, Y.; Zhang, T.; Wang, L. GaitC3I: Robust Cross-Covariate Gait Recognition via Causal Intervention. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Publication Year | No. of Sequences | No. of Subjects | Images/Videos per Subject (Frames) | Covariate Factors | Image Resolution | Data Type | Frames per Second (FPS) |
|---|---|---|---|---|---|---|---|---|
| Tum Gait [23] | 2012 | 3370 | 305 | Multiple | Normal walk, Backpack, long coat, coating shoes | 640 × 480 | RGB, Depth, Audio | 30 |
| CASIA A [11] | 2001 | 19,139 | 20 | Multiple | Normal walk with three view angles: 0°, 45°, and 90° | 352 × 240 | RGB | 25 |
| CASIA B [24] | 2005 | 13,680 | 124 | Not Specified | Normal walk, carrying backpack, wearing jacket or coat, and 11 view angles from 0° to 180° | 320 × 240 | RGB, Silhouette | 25 |
| CASIA C [25] | 2005 | 1530 | 153 | More than 300 | Slow walking, Normal walking, regular walking, and fast walking with bag carrying | 320 × 240 | Infrared, Silhouette | 25 |
| CASIA E [26] | 2022 | 778,752 | 1000 | Multiple | Clothing conditions, carrying conditions, walking styles, and 26 different view angles | 1920 × 1080 | Silhouette | 25 |
| OU-ISIR [27] | 2009 | 37,531 | 4016 | 1876 | Normal walking with four angles: 55°, 65°, 75°, and 85° | 64 × 64 | Silhouette | 30 |
| OU-ISIR treadmill [28] | 2007 | 8728 | 302 | 2182 | 25 different view angles, 32 clothing combinations, different walking speeds from 2 km/h to 10 km/h and gait fluctuations | 88 × 128 | Silhouette | 60 |
| OU-ISIR speed transition [29] | 2013 | 306 | 34 | Not Specified | Different walking speeds from 1 km/h to 5 km/h | 88 × 128 | Silhouette | 60 |
| OU-LP Age [30] | 2017 | 187,584 | 63,846 | Not Specified | Only males and females aged 2 to 90 years old | 640 × 480 | Silhouette, GEI | 30 |
| OU-LP Bag [31] | 2018 | 63,846 | 2070 | Not Specified | Carried objects of seven different types | 1280 × 980 | Silhouette, GEI | 25 |
| OU-MVLP [32] | 2016 | 259,013 | 10,307 | 35,840 | 14 view angles range from 0° to 270° with normal walk | 1280 × 980 | Silhouette, GEI | 25 |
| OU-MVLP Pose [33] | 2017 | 259,013 | 10,307 | 35,840 | 14 view angles with normal walking speed | 1280 × 980 | 2D Skeleton | 25 |
| USF [34] | 2002 | Not Specified | 122 | Not Specified | 32 possible conditions and two viewpoints. | 720 × 480 | RGB | 30 |
| Southampton Gait [13] | 2002 | 1870 | 122 | Not Specified | 6 primary covariate conditions include clothing, carrying, walking speed, and view angles | 80 × 80 | RGB | 25 |
| OU-MVLP Mesh [35] | 2022 | Not Specified | 10,307 | Not Specified | Normal Walking from 11 different view angles | 1280 × 980 | 3D Human Mesh | 25 |
| SOTON [36] | 2002 | 2128 | 115 | Not Specified | Normal Walking speed | Not Specified | Silhouette, RGB | 25 |
| Covariate Condition | Rank-1 Accuracy | EER | F1-Score | Precision | Sensitivity | CMC | AUC |
|---|---|---|---|---|---|---|---|
| View Angles | Decreases with angle variations. It fails to account for side/rear views. | Balance False Acceptance Rate and False Rejection Rate and handle angle variations effectively. | Handles angle variations more effectively compared to Rank-1. | Decreases with angle variations, as it may misidentify. | Sensitivity decreases if the model is not trained on diverse angles. | Effective for evaluating how the system ranks the correct person even with angle differences (top-k). | Effective for evaluating model performance across different view angles. |
| Clothing Variations | Decreases with clothing change, especially with unseen clothing. | Sensitive to clothing variations. Shows the balance of FAR and FRR. | Helps balance between misidentifications and missed matches. | Decreases when clothing changes, due to misidentification. | Decreases as different clothes may confuse the system. | Helpful for ranking the correct person in top-k positions despite clothing changes. | Effective in assessing model performance despite clothing differences. |
| Occlusions | Decreases as occlusions block important features, leading to lower accuracy. | Sensitive to occlusions, as it balances false acceptances and rejections. | Decreases if occluded parts of the body lead to missed matches. | Decreases when occlusions lead to false positives. | Decreases if the system misses identifying an occluded person. | Useful for evaluating the correct ranking even with occlusions. | Useful in evaluating the process of how well the model handles occlusions while distinguishing between subjects. |
| Lighting Conditions | Decreases in low light, as gait features may be harder to extract. | Sensitive to lighting, as the model can struggle to differentiate people in poor light. | Effective when there are lighting variations, as it captures performance across various conditions. | Decreases under poor lighting due to poor image quality. | Decreases when lighting makes features less visible, leading to missed identification. | Useful in showing how often the correct person appears in top-k despite poor lighting. | Effective for analyzing how well the model distinguishes individuals in low-light conditions. |
| Walking Speed | Decreases if the speed is faster or slower than training data. | Sensitive to speed variations, particularly if the system was not trained at different speeds. | Can balance precision and recall even with varying speeds. | Affected by speed changes, especially at extreme speeds. | Decreases when the walking speed varies significantly from the training data. | Useful for evaluating how well the system ranks the correct person despite speed differences. | Effective for determining how well the model distinguishes gait at various speeds. |
| Ref | Dataset | Technique | Number of Covariates | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Qi et al. [22] | CASIA B | ResNet50 and LSTM | Clothing variation and view angles from 0 degree to 180 degrees. | Lightweight model, and the computational time of the model is very low. | The study depends on the pose estimation technique, which gives errors on low-resolution videos. The accuracy of the model with normal walking is 73%, but when covariates such as clothing variation, carrying conditions, and view angle are introduced, the model’s accuracy decreases to 49%. Furthermore, the model is trained on only one CASIA B dataset and does not handle speed variations and lighting condition issues. |
| Pan et al. [37] | CASIA A and CASIA B | LUGAN and GCN | The covariates addressed in the research include view angles from the CASIA A dataset (0° to 45°) and different clothing variations, along with hand carry and view angles from the CASIA B dataset. | The LUGAN method reduces the cross-view variance by generating multi-view poses from a single view input, and the integration of the hypergraph convolution module makes the model learn multi-scale features, from the joint level to the body level. | The limitations of the research include computational complexity. The LUGAN technique, along with the pose estimation and hypergraph convolution methods, requires high computational resources. The pose estimation model in the research is a 2D pose method, which does not fully capture body joint information and complex body movements. |
| Liao et al. [38] | CASIA B | OpenPose and CNN | View angles from the CASIA B dataset range from 0° to 180°, along with clothing variation and hand carry. | The 3D pose estimation method works very well on low-resolution data, and the pose estimation model effectively extracts dynamic motion patterns by using handcrafted and CNN methods. | The accuracy of the methods depends on 3D poses. If the poses are not correctly identified, it will have a negative impact on the model. Although the 3D pose estimation model is efficient, the 2D to 3D pose conversion is computationally expensive. The model only captures information from 14 joints, which is considered limited and does not fully capture the complex dynamic walking patterns. |
| Liao et al. [39] | MoBo and CASIA B | GaitMap-CNN and GCN | The covariates covered in this research include the MOBO dataset with view angles from 0° to 315°, and the CASIA B dataset with clothing variation, bag carrying, and view angles from 0° to 180°. | Pose estimation maps contain richer information about the human body compared to traditional skeleton-based methods and are much less sensitive to variations in human shape. The fusion of heatmap evaluation features and pose features creates more discriminative gait features. | The recognition accuracy of PoseMAPGait is very low compared to other models, and using the graph convolutional neural network and pose estimation model makes the model resource-intensive for real-time applications. The model’s accuracy decreases on small datasets or datasets with a limited number of subjects. |
| Luo et al. [40] | CMU MOBO and CASIA B | Hierarchical Temporal Memory (HTM) and Gait semantic folding | The covariates included from the CMU MoBo dataset, which contain different walking speeds such as slow, normal, and fast, as well as carrying objects like ball carrying. Additionally, the CASIA B dataset is used, which contains view angles and clothing variation. | With the integration of Hierarchical Temporal Memory, the model can learn temporal features more effectively and efficiently even if the input frames are noisy or contain changing environments. Memory-based methods such as Hierarchical Temporal Memory can be learned from new input data, which enables the model to perform well on unknown covariates. | The combination of 3D model estimation, semantic folding, and Hierarchical Temporal Memory is computationally expensive, and the model struggles with small datasets that have a limited number of subjects. |
| Xu et al. [41] | GREW | Graph Convolutional Neural Network (GCN) | View angles and clothing variation. | The model uses a GCN, which creates a relationship between human joints and bones and helps the model accurately capture the spatial and temporal information from the sequences. The model is simplistic compared to other techniques, as it directly embeds 3D skeleton information into graph networks by eliminating the preprocessing steps. The performance of the model on large datasets, such as Grew, is very good. | The model is heavily dependent on 3D pose data, and any error in the pose will negatively affect the entire method. Additionally, the model is computationally intensive due to the use of 3D data, graph convolutions, and embedding networks. The model heavily depended on large datasets for training but struggled on datasets with limited subjects and data. |
| Choi et al. [42] | UPCVgait and UPCVgaitK2 | Centroid-Based Skeleton Alignment and weighted majority voting | The covariates included in this research are view angles and different walking speeds. | The method reduces the error when estimating the position of the joints by aligning the skeleton with the help of the centroid of torso joints, providing better alignment under occlusion. The computational cost is reduced by dividing gait cycles into small patches or phases, and Weighted Majority Voting improves the accuracy rate of the model. | The dual-stage linear matching and quality-adjusted cost matrix introduce complexity and computational overhead, making the method unsuitable for real-time applications and large databases. The method only includes simple gait patterns, and when complex gait patterns are introduced, the method struggles with accuracy. Due to the high frame rate, the method is slow. |
| Gao et al. [43] | CASIA B | ST-GCN and Canonical Polyadic Decomposition | The covariates included in the research are 11 view angles from 0° to 180°, along with clothing variation and carrying a bag. | The method includes spatial–temporal graph convolutional networks (for spatial and temporal feature extraction, which improves the performance of the model). The addition of Canonical Polyadic Decomposition extracts more robust features and removes redundant features, which makes the model select the most appropriate gait features. | The model extracts spatial and temporal information effectively, but the complexity of the model increases when extracting temporal features from short and incomplete sequences. The CPD removes redundant information from the gait sequences, but the process of decomposing the features can lead to model overfitting. Additionally, the CPD decomposition is computationally expensive. |
| Wang et al. [44] | CASIA A, CASIA B, and OU-MVLP | Autoencoders and LSTM | The covariates utilized in the research are from the CASIA A dataset, which contains 3 view angles: 0°, 45°, and 90°. Other covariates include view angles from 0° to 180° from the CASIA B dataset, along with clothing variation and carrying conditions. Additional covariates are from the OU-MVLP dataset, which contains view angles from 0° to 270°. | The method uses stacked autoencoders, which convert skeleton joint coordinates from any arbitrary view to a canonical view without the need for prior knowledge of the view angle. This allows the model to work better with different view angles. By using LSTM with the autoencoder, the model is capable of preserving both spatial and temporal information, which is essential for accurate gait identification. | The stacked autoencoder with multiple layers is computationally expensive on large datasets, and the model requires a large number of resources. The normalization process in the preprocessing phase, which adjusts the subject’s skeleton size for camera proximity, creates complexity in the model and affects the accuracy as well. |
| Teepe et al. [45] | CASIA B | MobileNetV1, Xception, and PCA | The covariates included in the research are from the CASIA B dataset, which includes view angles from 0° to 180°, along with clothing variation and carrying conditions. | The combination of features from two deep learning methods, MobileNetV1 and Xception, enhances the gait recognition accuracy, and the use of PCA increases the computational efficiency of the method. The model achieves high accuracy rates on the CASIA B dataset with an accuracy of 98.77%. | The OAM-SVM classifier may struggle with noisy and undisturbed data, and the use of multiple kernels increases the complexity of the model. As a result, the accuracy of the model drops at large angles, such as 126° and 180°. The use of multiple models, such as MobileNetV1 and Xception, followed by PCA, decreases the computational cost of the system. However, there is limited data, as the model is trained and tested on only 50 individuals from the CASIA B dataset. |
| Ref | Dataset | Technique | Number of Covariates | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Khan et al. [14] | Tum Gait and CASIA B | VGG19 and MobileNet-V2 | The covariates included in the research are clothing variation, coated shoes, and backpacks from the TUM Gait dataset, as well as view angles and clothing variation from the CASIA B dataset. | The lightweight deep learning models VGG19 and MobileNet-V2 are utilized, which are very efficient. The Moth Flame Optimization technique is used for the best feature selection, which increases the accuracy of the model and decreases computational time. By using transfer learning techniques to fine-tune VGG19 and MobileNet-V2, the computational costs of the model during training are reduced. | The framework consists of multiple stages, such as pretraining, feature extraction, feature fusion, optimization, and classification, which makes the model more complex and takes longer to implement. Discriminant Canonical Correlation Analysis combines the features of VGG19 and MobileNet-V2, which improves the model accuracy, but it is a time-consuming process when dealing with large datasets. |
| Asif et al. [51] | CASIA B | CNN and Histogram of Oriented Gradients | The covariates included in the research are from the CASIA B dataset, which includes clothing variation and view angles from 0° to 180°. | The method is effective in multi-view environments, which is very important for real-time applications, and handles the covariate factors efficiently. The Histogram of Oriented Gradients technique is used for feature extraction, which extracts important gait patterns, even under challenging conditions. | This method depends on gait energy images, which are not ideal for low-resolution videos or partially occluded frames. The model performs well on coats, but variations in clothing decrease the model’s accuracy. |
| Amin et al. [54] | CASIA A, CASIA B, and CASIA C | BiLSTM and YOLOv2 | The covariates included in the research are different walking speeds, such as slow walking, normal walking, and fast walking, from the CASIA C dataset, along with 3 view angles (0°, 15°, and 45°) from the CASIA A dataset, and clothing variation, carrying a bag, and view angles from 0° to 180° from the CASIA B dataset. | The Bi-LSTM with the addition of multiple convolutional layers helps the model capture temporal and spatial features, which makes the model more accurate for gait recognition. The addition of YOLOv2 with SqueezeNet architecture makes the localization of the model faster in real-time applications. | The use of Conv-BiLSTM along with YOLO creates complexity while training the model, as it requires high computational resources, especially on large datasets. The model shows high accuracy in some classes, such as clothing wear and slow walk, but the performance decreases on classes like normal walk and carrying a bag, which causes the model to overfit on some specific classes. |
| Yujie et al. [55] | CMU Mobo | CNN and LSTM | The research includes the covariates from the CMU MoBo dataset, which includes normal walking, backpack walking, walking in a coat, and ball-holding. | The use of CNN and LSTM to extract spatiotemporal features of human gait makes the model robust for variations in movement and conditions. The LSTM parameters are optimized, which improves the accuracy of the model in challenging conditions like clothing, occlusion, and carrying objects. The CNN model ResNet34 is used for spatial feature extraction, which includes residual blocks that help the model learn more robust features. | Deep learning models based on CNN and LSTM require large computational resources for training the model on large datasets, and the model’s performance is dependent on the quality of the input frames. If the input frames are noisy, the performance of the model decreases. Deep learning models overfit small datasets, as they require large datasets for training the model. |
| Elharrouss et al. [56] | CASIA B, OU-ISIR, and OU-MVLP | Background modeling and CNN | The research covers large covariates: view angles from the OU-MVLP dataset, which range from 0° to 270°, along with clothing variation and view angles from the CASIA B dataset, where the view angle range is from 0° to 180°. The OU-ISIR dataset contains different view angles. | The model uses a background subtraction method for human silhouette extraction, which enhances the accuracy of the gait recognition process. The dual-stage CNN method initially calculates the angle of the input frames, which then becomes the input for the gait recognition model to handle covariates effectively. | The accuracy of the model depends on the correct estimation of the view angle. If the view angle is not estimated correctly, it leads to decreased recognition accuracy. The model requires detailed background modeling to calculate the human silhouette, and the dual CNN network with multiple layers makes the system complex and slower. |
| Mogan et al. [57] | CASIA B, OU-ISIR, and OU-LP | DenseNet 201, VGG 16, and Vision Transformer | The covariates included in the research are from the CASIA B dataset, which contains 11 view angles, clothing variation, and carrying objects; the OU-ISIR dataset with view angles; and the OU-LP dataset with 4 view angles: 55°, 65°, 75°, and 85°. | The combination of three deep learning models, such as DenseNet 201, VGG 16, and Vision Transformer, allows the model to extract more accurate and robust gait features. The introduction of an ensemble learning module combines every deep learning model output to increase accuracy and reduce variance, resulting in more accurate gait recognition in challenging conditions like in noise and occlusion. | The research heavily depends on pretrained models, which means it relies on their generalization ability. If the model is not fine-tuned properly, the system’s performance degrades. Another disadvantage of the research is that, due to the multiple layers of model integration, fine-tuning, and fusion, the system becomes complex and time-consuming. |
| Mogan et al. [58] | CASIA B and OU-ISIR | Vision Transformer | The covariates are view angles, clothing variation, and carrying objects. | The research utilized the Gait-ViT technique, which includes a self-attention block that focuses on important gait features while suppressing the impact of occlusion and noise. The Vision Transformer has the ability to encode both local and global information with the help of multi-head self-attention and residual connections. | The Gait-ViT technique requires high computational resources to handle high-resolution images and large datasets. The model requires a high input size of 64 × 64, which increases computational time and memory usage. Additionally, the model has a single convolutional layer, which cannot extract deep gait features. |
| Castro et al. [60] | CASIA B and Grew | AttenGait | The covariates are view angles from 0° to 180°, along with clothing variation. | The model known as AttenGait utilizes three trainable attention mechanisms: Attention Conv, Spatial Attention HPP, and Temporal Attention HPP, which allow the model to extract the most important regions from the gait data. AttenGait uses optical flow and grayscale images as input, which contain richer data and provide useful features of gait. | The use of three attention mechanisms along with multiple convolutional layers makes the system computationally expensive. The model is heavily dependent on optical flow or rich modalities; the unavailability of such modalities decreases the accuracy of the model. Additionally, optical flow and these modalities contain richer features compared to the human silhouette, which raises privacy concerns in some applications. |
| Yousef et al. [61] | CASIA B and OU-ISIR | GANs, AlexNet, Inception, VGG16, VGG19, ResNet, and Xception | The covariates are 11 different view angles, along with clothing variation and carrying objects. | The research utilized GANs for data augmentation, which balances the dataset by normalizing the frames and enables the model to train on difficult covariate conditions. Deep learning models such as AlexNet, Inception, VGG, ResNet, and Xception extract the most useful gait features and improve the model accuracy. Important gait features are selected by utilizing methods such as Particle Swarm Optimization and Grey Wolf Optimization. | The method is computationally expensive, as GANs are used for data generation, different deep learning models are used for feature extraction, and advanced feature techniques are also utilized. The GANs training is very important; if there is any noise during training, it will affect the accuracy of the entire system. The model is complex and requires high training time for large datasets. |
| Nithyakani et al. [62] | CASIA B | Multi-Convolutional Stacked Capsule Network | The research includes covariates such as clothing variation, normal walking, and carrying objects. | The Multi-Convolutional Stacked Capsule Network extracts gait features more efficiently by using multiple convolutional layers, stacked capsule networks, and the inception network, which makes the model extract gait features without reducing dimensionality. The inclusion of CLAHEF during the preprocessing phase removes noise within the input frame and increases the accuracy rate. The model’s computational time is reduced by 51.136% to 59.04% compared to other models. | During preprocessing, CLAHEF is introduced to enhance image quality by reducing noise, but it makes the model more complex. If not performed optimally, it can cause over-enhancement, which distorts the gait features. With the use of multiple deep learning techniques, the model requires high computational resources for training. |
| Ref | Dataset | Technique | Number of Covariates | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Yao et al. [66] | CASIA B | SGEI and CNN | The covariates included in the research are clothing variation, normal walking, walking with carrying conditions, and view angles from 0° to 180°. | The paper combines model-based and model-free techniques, and this combination makes the model work effectively on clothing variations and view angles. The Skeleton Gait Energy Image helps in extracting body features that are less susceptible to clothing changes, while the gait energy image captures spatial information, which works better under normal walking conditions. | The research consists of a complex multi-stage architecture, which is computationally expensive for training on large datasets. The accuracy of the model is heavily dependent on the accurate extraction of pose information from the input frames; any inaccuracies in detection cause degradation in the performance of the model. |
| Lu et al. [65] | CASIA B | Mediapipe and CNN | The covariates included in the research are view angles from 0° to 180° and clothing variation. | The use of fusion techniques increases the model’s performance under various covariate conditions, and the model achieves high accuracy, with 99.6% on the CASIA A dataset and 99.8% on the CASIA B dataset. During the preprocessing phase, silhouette extraction and histogram equalization enhance the quality of input frames, enabling the extraction of better gait features and making the model applicable for real-time applications. | The model depends on high-quality RGB videos for extracting accurate human poses, and the availability of high-quality videos is not feasible in low-light conditions. The use of RGB data as input limits the model’s functionality to only depth or infrared data. The multi-stage model, combining both model-based and model-free methods, increases the computational complexity of the model. |
| Zhao et al. [68] | Sonton-small, OUMVLP, and CASIA B | GCN and GaitGL | The covariates addressed in the research are view angles from 0° to 180° from CASIA B, 0° to 270° from OU-MVLP, as well as clothing variation and walking speed. | The use of Compact Bilinear Pooling extracts high-level gait features and decreases the computational complexity of the model. The scale normalization method ensures that each gait feature is comparable, which increases the effectiveness and accuracy of the model. | During model training, careful hyperparameter tuning is required. This makes it difficult to apply in situations with limited data or time for model development. In the feature extraction process, GaitGL and GaitGraph are used, but they have limited capability to extract high-level gait features. |
| Ref | Publication Year | Methodology | Dataset | Results | Limitations |
|---|---|---|---|---|---|
| M.A. Khan et al. [14] | 2022 | Pretrained fMobileNet-V2 and VGG 19 | Tum gait and CASIA B | Accuracy in simple cases is above 90%, but on different clothing accuracy decreases to 83%. | Feature extraction is time-consuming and depends on some pretrained models, which can be less effective in some gait recognition problems. The model has not been tested in real-world conditions, and only a few covariates are covered. |
| M. Asif et al. [51] | 2022 | HOG for feature extraction and SVM for classification | CASIA B | Accuracy on coat wearing is 87%, and overall accuracy is 83%. | Experiments were performed using only one view angle (90 degrees); the other angles were not discussed. |
| M. Bukhari et al. [52] | 2020 | LDA for dimensionality reduction, along with CNN and HOG | OU_ISIR | The accuracy under normal walking conditions is 97%, but it decreases on carrying bags or wearing a coat. | The method removes the covariate-affected parts of the body, which also leads to the removal of useful information from the image. Additionally, the research does not focus on view angles. |
| J. Amin et al. [12] | 2021 | ResNet-18 and BiLSTM to extract features, along with YOLO | CASIA A, B, and C | The accuracy on the normal walking class and walking with a bag is low. | The model depends on selected features, and some useful features are ignored, leading to a decrease in accuracy at low-quality resolution. |
| R. Liao et al. [47] | 2022 | Pose estimation using CNN, and gait features extracted with STGCN | MOBO and CASIA B | The accuracy is low for carrying a bag (58% and 39%) and wearing a coat (41%), as well as for carrying a ball. | During pose estimation, only a few joints are covered, and these joints are not normalized. Additionally, the method does not focus on view angles. |
| R. Liao et al. [54] | 2020 | 3D poses and spatiotemporal features extracted through CNN | CASIA B and CASIA E | The accuracy is low for carrying a bag and wearing a coat, with rates of 42% and 31%, respectively. | The method can detect the pose of a human when facing the camera but cannot estimate the correct pose when the human is not camera-facing or when parts of the body are occluded. |
| O. Elharrouss et al. [56] | 2021 | Angle estimation and gait verification performed using CNN with a SoftMax classifier | OU-MVLP, OU-ISIR, and CASIA B | The average accuracy across different view angles, from 0 degrees to 270 degrees, is approximately 85%. | The research does not contain detailed covariate conditions or, rather, includes only the view angles; the research does not include control environmental factors such as temperature and lighting during the experiment. |
| J.N. Mogan et al. [57] | 2023 | Fine-tuned DenseNet-201 and VGG-16, combined with Vision Transformer for gait recognition | OU-ISIR D, OU-ISIR Large Population, and CASIA B | The overall accuracy of the model is excellent on the CASIA dataset, which is about more than 90%. | The research does not provide detailed knowledge of the covariates or view angles on which it works, and the research methodology does not include any techniques to handle low-light or occluded frames. |
| Y.J. Qi et al. [80] | 2022 | Model-based approach LSTM and residual network 50 to extract spatial and temporal features from images | CASIA B and OU-ISIR | The overall accuracy of the model is low compared to other models, with 73% view angles from 36° to 144°. | The research contains only one covariate, normal walking, and covers view angles from 36° to 144°. Many view angles are missing, and wearing conditions and walking speed are not included. |
| M.M. Hasan et al. [46] | 2021 | Stacked auto encoders for feature extraction, along with a SoftMax classifier | CASIA A and CASIA B | Focused on CASIA B view angles and three covariates’ conditions, achieving an average accuracy of almost 50%. | The research did not focus on walking speeds, viewing angles greater than 180 degrees, and different lighting and weather conditions. |
| A. Mehmood et al. [48] | 2024 | Feature extraction using stacked encoder with KNN, BG trees, and SVM classifiers | CASIA B | Only six view angles are in the study, from 0 to 90 degrees. The result on these view angles is 98 percent accuracy. | Only a few angles are utilized. Different walking speeds and clothing variations are not discussed. |
| F.M. Castro et al. [60] | 2024 | AttenGait technique to learn deep gait features | GREW and CASIA B | 92 percent average accuracy on the CASIA B dataset and 89 percent on the GREW dataset. | The model only extracts local spatial features; when there is a change in position or shape, the model is unable to handle it, and there is also a high computational cost. |
| R.N. Yousef et al. [61] | 2024 | GANs with pretrained convolutional neural networks | CASIA B and OU-ISIR | Simple method with 99% accuracy; no covariates and view angles are discussed. | No covariates are discussed, such as view angle, speed variations, and clothing variations, and there is also training instability in the method. |
| P. Nithyakani et al. [62] | 2024 | Deep stacked multi-convolutional capsule network | CASIA B | Accuracy on normal walking is good, but it decreases when walking with a coat or walking with a bag. | Only 3 wearing conditions are discussed; view angles, walking speed, and low lighting conditions are not discussed, and the computational time is very high. |
| M.A. Khan et al. [63] | 2023 | CNNs and Bayesian Network | CASIA B and CASIA C | The average accuracy on different view angles of the CASIA B dataset is 86 percent, and on the CASIA C dataset, it is 91 percent. | Due to the fusion of the features, the computational time is very high, and the view angles are only discussed from 0 to 180 degrees. |
| C. Meng et al. [64] | 2023 | The fusion strategy, integrated with the reconstruction of the human body | CASIA B and Outdoor gait | The accuracy of the outdoor gait dataset is 80%, while the CASIA B dataset also achieves an accuracy of 80%. | The model faces the issue of scalability and does not discuss different views and walking speeds. |
| X. Huang et al. [8] | 2022 | The STAR technique for human gait feature extraction | CASIA B and OU-MVLP | The accuracy of the model on CASIA B is 87%, and 89% on the OU-MVLP dataset. | The accuracy of the model is quite low compared to other models, and no discussion is provided on clothing variation or walking speed. |
| L. Yao et al. [66] | 2021 | Two branches of Multi-stage CNN | CASIA B | The accuracy is very low across different view angles, ranging from 0 degrees to 180 degrees. | The model’s accuracy is very low on the CASIA B dataset, and other covariates are not discussed in the research. Only a few view angles are considered. |
| M. Shopon et al. [49] | 2021 | Graph Convolutional Neural Network with OpenPose model | CASIA B | The average accuracy of the model on normal walking, walking with a bag, and walking with a coat is 91%. | The research does not perform experiments on low-quality data, and different walking speeds and view angles are not discussed. |
| M.H. Khan et al. [36] | 2018 | Codebook method, along with Fisher vector encoding and SVM | CASIA A and Tum gait | The ACR is 97% on the TUM Gait dataset and 100% on the CASIA A dataset. | In this research, handcrafted features are utilized, which are not important features. However, only a few covariates are addressed in the TUM Gait dataset, and factors such as view angles, walking speeds, and low-resolution data are not discussed. |
| Method Type | Technique | Dataset | Covariates Handled | Accuracy (%) | Remarks |
|---|---|---|---|---|---|
| Traditional | PCA + LDA + k-NN | CASIA Gait | Minimal | 90% | High under clean conditions |
| Traditional | KSOM + View Transformation | CASIA B | Clothing, View Angle | 57% | Low performance under covariates |
| Traditional | GEI + 2D Pose + LSTM | CASIA B | Clothing, View | 68% | Moderate improvement using pose |
| Traditional | 3D Pose + ResNet + LSTM | CASIA B | View, Pose | 38% | Struggles with intra-class variation |
| Traditional | Static + Dynamic Feature Fusion + k-NN | Kinect Skeleton | View Angles | 60% | Low generalization |
| Traditional | CNN (3 Conv Layers) + SVM | OU-ISIR Treadmill B | Clothing | 94% (Normal), 60% (Heavy Clothing) | Sensitive to clothing changes |
| Deep Learning | MobileNet-V2 + VGG19 + DCA | CASIA B, TUM Gait | Clothing, View Angle | 90% | Transfer learning improves robustness |
| Deep Learning | DenseNet + Vision Transformer | OU-ISIR, CASIA B | View Angle | 92% | High performance across datasets |
| Deep Learning | ResNet + BiLSTM | CASIA A/B/C | Clothing | 89% | Robust spatiotemporal learning |
| Deep Learning | EfficientNet + Bayesian Fusion | CASIA B/C | View Angle | 86–91% | High accuracy: computational cost noted |
| Study | Covariate Factor | Normal Walking Accuracy (%) | Changed Condition Accuracy (%) |
|---|---|---|---|
| Ali et al. [81] | Clothing variation, Walking speed | 90.33 | 87 (heavy coat), 93 (fast walking), 94 (slow walking) |
| Liao et al. [38] | Walking with backpack, Hand carry | 63.0 | 42 (backpack), 31 (hand carry) |
| Li et al. [82] | Walking with bag, Hand carry | 98.0 | 93 (walking with bag), 80 (walking with hand carry) |
| Marín-Jiménez et al. [83] | Backpack, Coated shoes | 82.0 | 68 (backpack), 76 (coated shoes) |
| Su et al. [84] | View angles | 99.0 | 74 (CASIA B 0–180°), 57 (OU-MVLP 0–255°) |
| Bukhari et al. [52] | Clothing variation, Walking speed | 97.0 | 95 (coat), 91 (with bag), 83 (fast walking), 85 (slow walking) |
| Fendri et al. [85] | Carrying shoulder bag, Backpack, Handbag, Wearing coat | 89.0 | 79 (shoulder bag), 73 (backpack), 65 (handbag), 73 (coat) |
| Junaid et al. [53] | Wearing Coat, Walking speed variations | 98 | 81 (CASIA B walking with bag), 88 (CASIA C) |
| Ali et al. [83] | Hand carry and long coat | 95 | 83 (walking with bag), 58 (walking with long coat) |
| Wang et al. [86] | View angles, Clothing variations, and Carrying conditions | 89 on Grew and 98 on CASIA B | 69 (Gait 3D view angles and loathing variations), 89 (CASIA B clothing variations) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mughal, A.B.; Khan, R.U.; Bermak, A.; Rehman, A.u. Person Recognition via Gait: A Review of Covariate Impact and Challenges. Sensors 2025, 25, 3471. https://doi.org/10.3390/s25113471
Mughal AB, Khan RU, Bermak A, Rehman Au. Person Recognition via Gait: A Review of Covariate Impact and Challenges. Sensors. 2025; 25(11):3471. https://doi.org/10.3390/s25113471
Chicago/Turabian StyleMughal, Abdul Basit, Rafi Ullah Khan, Amine Bermak, and Atiq ur Rehman. 2025. "Person Recognition via Gait: A Review of Covariate Impact and Challenges" Sensors 25, no. 11: 3471. https://doi.org/10.3390/s25113471
APA StyleMughal, A. B., Khan, R. U., Bermak, A., & Rehman, A. u. (2025). Person Recognition via Gait: A Review of Covariate Impact and Challenges. Sensors, 25(11), 3471. https://doi.org/10.3390/s25113471