1. Introduction
In recent years, localization technologies have become essential for a variety of applications, including navigation, tracking, and environmental perception. Accurate indoor localization is particularly crucial, as people spend a significant amount of time in indoor environments such as shopping centers, airports, and offices. Common indoor localization technologies, such as RFID [
1], UWB [
2], Wi-Fi positioning [
3,
4], Bluetooth positioning [
5], infrared positioning [
6], ultrasonic positioning [
7], vision-based positioning [
8], INS [
9,
10], geomagnetic positioning [
11], and Zigbee positioning [
12], each possess unique application scenarios and performance characteristics. However, many of these technologies necessitate additional hardware deployment. In contrast, Inertial Measurement Unit (IMU) technology, as an integrated component on modern smartphones, offers extensive application potential in GPS-limited scenarios by capturing high-precision motion states without the need for additional hardware. Depending on the implementation techniques, IMU localization can be categorized into traditional and deep learning-based approaches.
Traditional IMU localization typically employs methods such as step counting and zero-velocity updates to mitigate errors. Step counting involves monitoring gait information during walking or running to estimate position and distance by counting the number of steps taken. Zero-velocity updating identifies moments when the object is stationary and utilizes these instances to correct the velocity drift errors in the inertial navigation system (INS). Wang et al. [
13] investigated the impact of IMU installation locations on the accuracy of pedestrian inertial navigation systems assisted by zero-velocity update techniques. Another approach involves using filters to combine IMU measurements with prior information to estimate position and velocity in real time, thereby correcting errors. The Kalman filter, a common example, effectively integrates the acceleration and angular velocity data from IMUs through its recursive data fusion algorithm. References [
14,
15,
16,
17] have investigated the use of filtering techniques in combination with IMU data to enhance the accuracy and robustness of navigation and positioning systems. Fusing IMU data with other sensor data is also a viable solution. For example, GPS provides globally accurate position information. When combined with IMU data, it can eliminate cumulative errors and reduce dependence on closed-loop systems. Magnetometers can measure the Earth’s magnetic field to assist the IMU in calibrating yaw angles, thereby reducing long-term accumulated errors and improving positioning accuracy. Eckenhoff et al. [
18] proposed a multi-IMU, multi-camera visual-inertial navigation system named MIMC-VINS, which integrates information from all sensors.
Deep learning-based IMU localization leverages advanced machine learning techniques [
19,
20] to reduce errors in trajectory estimation from IMU data. Replacing traditional step prediction and zero-velocity prediction methods with neural networks is a viable approach. The advantage of this method lies in its ability to utilize deep learning models to learn and infer inertial odometry directly from raw IMU data, thereby simultaneously addressing errors in dynamic motion. This enhances the overall performance and reliability of the positioning system. Wagstaff et al. [
21] and Brossard et al. [
22] proposed methods to enhance the accuracy of zero-velocity aided inertial navigation systems by replacing the standard zero-velocity detector with a Long Short-Term Memory (LSTM) neural network. Neural networks can also be employed to dynamically adjust the parameters of filters to effectively mitigate the error issues associated with IMU localization. Brossard et al. [
23] utilized deep neural networks to dynamically tune the noise parameters of filters, thereby enabling real-time determination of the most suitable covariance noise matrix.
Learning position transformations directly from IMU data is a method that warrants attention. Chen et al. [
24,
25] proposed a deep neural network framework that employs an LSTM model to learn position transformations from IMU data, thereby constructing an inertial odometry system. The LSTM model is capable of effectively modeling the temporal dynamics of human motion, thereby making it suitable for inertial navigation tasks. However, the sequential nature of LSTMs restricts their parallelization capabilities, leading to slower training speeds when dealing with very long sequences. Herath et al. [
26] developed a ResNet-based deep learning architecture that focuses on extracting position information from IMU data to construct an inertial odometry system. However, ResNet itself may not fully capture the temporal dependencies crucial for inertial navigation, as it is primarily designed for extracting spatial features. Recently, the Transformer architecture [
27] has emerged as a powerful alternative for sequence modeling. Unlike RNNs, the Transformer relies entirely on attention mechanisms to capture global dependencies between input and output. This allows for significantly more parallelization during training and can lead to superior performance in tasks such as machine translation. The Transformer’s ability to handle long-range dependencies and its efficiency in training make it a promising candidate for improving IMU localization [
28].
This paper addresses the challenge of accurate indoor localization by proposing a novel two-stage network-based IMU localization model, named ResNet–Transformer Integrated Network for Inertial Measurement Units (ResT-IMUs). Unlike the two-stage methods in [
29,
30], which focus on switching between different localization techniques or fusing multiple sensor modalities, this method leverages deep learning techniques, combining ResNet and Transformer architectures to process IMU sensor data, learn human walking patterns, predict movement velocity, and calculate the trajectory of a target within an indoor environment. Specifically, the first stage of ResT-IMU predicts the instantaneous velocity from IMU data using a ResNet-based velocity branch model, while the second stage refines the estimation of the motion direction using a Transformer-based orientation branch model. The main contributions of this paper are as follows:
This paper applies the Transformer architecture to motion trajectory prediction using IMU data. By leveraging the self-attention mechanism of the Transformer, it captures long-term dependencies in the IMU data. This not only improves the accuracy of the predictions but also enhances the model’s adaptability to complex dynamic environments.
This paper proposes an innovative two-stage prediction framework. The model first predicts the instantaneous velocity and subsequently refines the estimation of the motion direction based on the predicted velocity. This staged approach enables the model to focus on specific prediction tasks at each stage, thereby enhancing the overall prediction accuracy and reliability.
The model adaptively adjusts the size of the data window for direction prediction based on the predicted velocity. This dynamic adjustment mechanism enables the model to more flexibly handle different motion states, particularly during periods of drastic velocity changes, thereby allowing it to quickly focus on the most relevant data intervals. Additionally, velocity information is incorporated into the loss function for direction prediction, thereby making the loss calculation dependent not only on the accuracy of direction but also on the matching degree of velocity.
The structure of this paper is organized as follows:
Section 2 introduces the proposed ResT-IMU model.
Section 3 presents the experimental results. Finally, the paper concludes and discusses future work in
Section 4.
2. Improved ResT-IMU Model
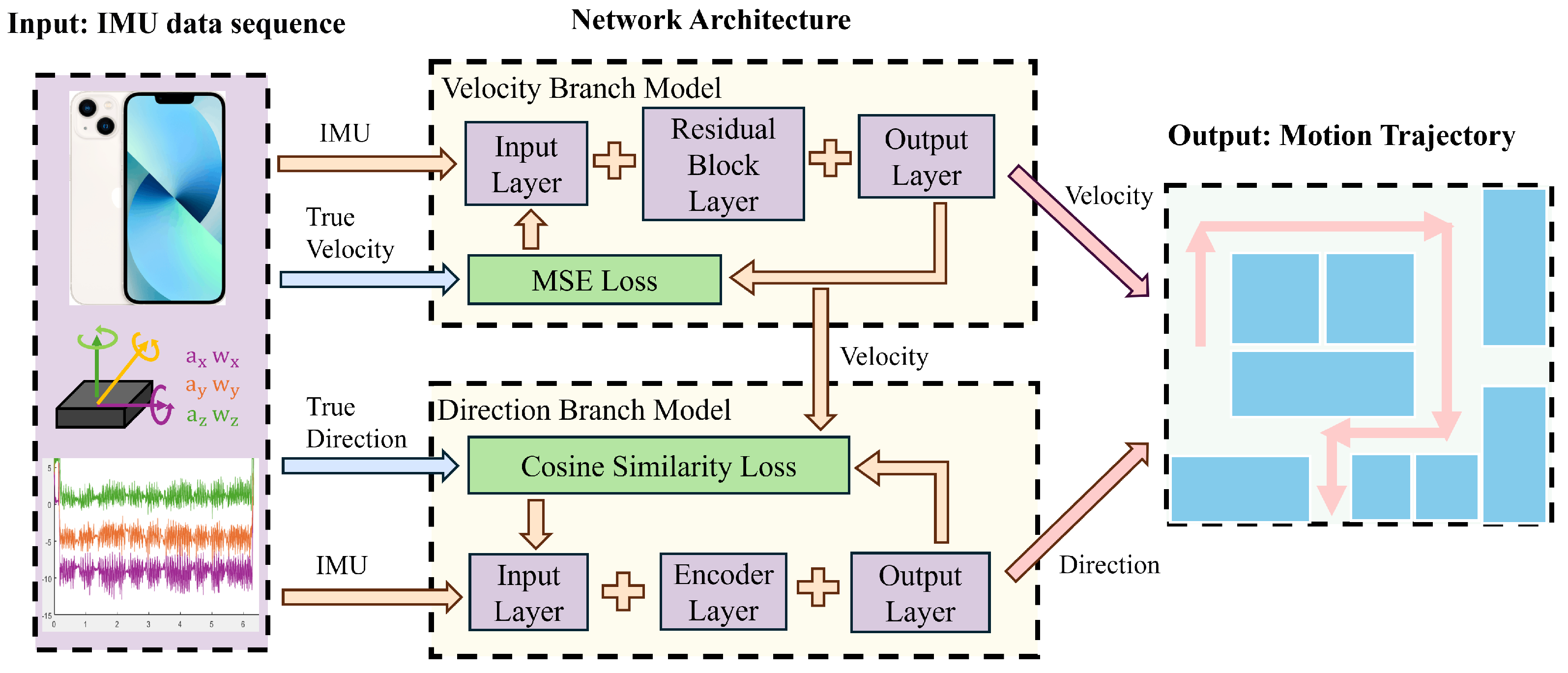
The architecture of the proposed ResT-IMU model is depicted in
Figure 1. It takes the IMU acceleration and angular velocity, collected via a smartphone, as input. For the velocity branch, it employs a ResNet-based architecture to calculate velocity, thereby leveraging ResNet’s strong spatial feature extraction capabilities. For the direction branch, it uses a Transformer-based architecture to calculate direction, thereby taking advantage of the Transformer’s ability to handle long-range dependencies. This design integrates the strengths of existing techniques to address their limitations and enhance the accuracy of trajectory calculation.
The model architecture comprises two main components: the velocity branch model and the direction branch model. The core of the velocity branch model is the ResNet network. First, it maps the acceleration and angular velocity data from the IMU from the input space to the feature space, thereby generating high-dimensional feature vectors. Then, the output layer maps these high-dimensional feature vectors to the output space. The network parameters are optimized using the MSE loss function, resulting in the generation of the velocity sequence as the final output of this branch. The core of the direction branch model is the encoder structure within the Transformer network. The encoder receives input vectors that have been processed through an embedding layer and augmented with positional information. It captures the temporal sequence features of the data using the self-attention mechanism. The output layer then maps the high-dimensional feature vectors to the output space. In the cosine similarity loss function, the network parameters are optimized by incorporating the input data and the velocity information from the velocity branch model. This results in the generation of the direction sequence. By combining the velocity sequence and the direction sequence, the final trajectory of motion is computed.
2.1. Data Preparation
The model in this paper was trained using the iIMU-TD dataset, which comprises a total of 2.41 h and 10.4 km of data, collected in both indoor and outdoor experimental environments. The dataset was captured using two smartphones. One smartphone, equipped with an IMU sensor, was used to capture the triaxial acceleration and triaxial angular velocity data during the experiments. The other smartphone used in the experiments was ASUS_A002A, which integrates Tango technology developed by Google. This technology provides localization tags for the trajectory through visual recognition, as shown in
Figure 2. During the experiments, the data collector placed the Tango-enabled smartphone on the chest to record a more accurate trajectory. The other smartphone was held in hand in a manner that simulates everyday use, to collect IMU data at a sampling rate of 200 Hz. After the experiments, the raw IMU data were preprocessed through filtering and other operations and then saved for subsequent analysis and use.
In the experiments, the IMU data record dynamic information in the device coordinate system, rather than in the global coordinate system. To predict the trajectory of motion, these data must be transformed into the global coordinate system, as shown in the following Equations (1) and (2):
In the equations,
and
represent the acceleration and angular velocity vectors in the Tango device coordinate system at time
i, while
and
represent the acceleration and angular velocity vectors in the IMU device coordinate system at time
i.
is the rotation matrix that transforms from the IMU device coordinate system to the Tango device coordinate system at time
i. The quaternion representation of this rotation matrix is given by the following Equation (
3):
In the equation, represents the quaternion that transforms from the IMU device coordinate system to the Tango device coordinate system at time i. and respectively represent the initial attitudes of the IMU and Tango devices in their own coordinate systems. represents the initial rotation quaternion from the IMU device coordinate system to the Tango device coordinate system, which is determined by fixing the initial relative attitude of the two devices.
2.2. Velocity Branch Model
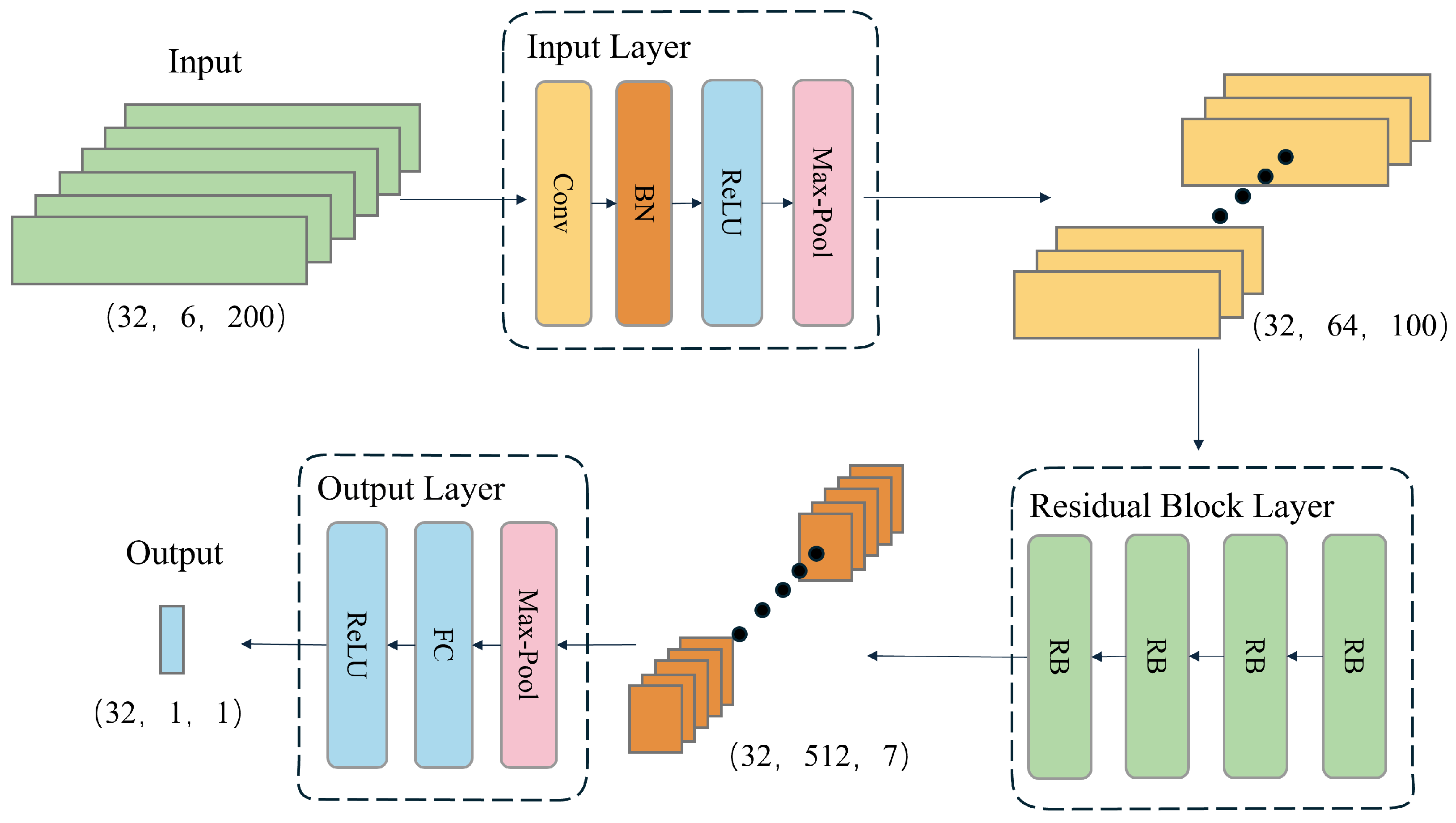
The velocity branch model is designed to predict the magnitude of instantaneous velocity from IMU data. Its architecture is depicted in
Figure 3 and comprises three main components: the input module, the residual group module, and the output module. The input module first preprocesses the raw data collected by the IMU sensors. The data then flow through multiple residual blocks, which extract features by learning patterns in the data while mitigating the vanishing gradient problem using residual connections. Finally, the output module maps the extracted features to the predicted instantaneous velocity through global average pooling and a linear layer, thereby achieving accurate velocity estimation.
The velocity branch model employs a time window of 200 data points as input, based on the data collected by the IMU sensors, to predict the instantaneous velocity of the last frame in the sequence. To adapt to the characteristics of IMU data, which are one-dimensional sequences, the model utilizes one-dimensional convolutional layers and pooling layers. These layers are specifically designed to process one-dimensional data efficiently. Additionally, a ReLU activation function is added to the output layer to ensure that the predicted velocity values are non-negative, which is essential for regression tasks involving speed magnitude. These modifications not only enhance the model’s suitability for handling long sequences of IMU data but also reduce the parameter count, making the model more efficient and better suited for processing extensive data sequences. With a stride of 10 for step-by-step prediction, the model can transform an IMU data sequence of length N into a velocity magnitude sequence of length . By applying this model, a series of discrete velocity values can be estimated from continuous IMU measurements, where each velocity value represents the speed magnitude of the last frame in a window of 200 data points.
2.2.1. Input Layer
The input layer performs preliminary processing on the input data and extracts initial features. A one-dimensional convolutional layer with a kernel size of 7 increases the number of input data channels from 6 to 64. Subsequently, a batch normalization layer normalizes the output of the convolutional layer, which accelerates training and enhances model stability. The normalized data are then activated by the ReLU activation function to introduce non-linearity. Finally, a max-pooling layer reduces the temporal dimension of the features by half while preserving important features.
2.2.2. Residual Block Layer
The model comprises four residual blocks. The number of output channels in each residual block increases according to the residual rules. After passing through the four residual blocks, the number of channels increases from 64 to 512. The addition of convolutional layers with a stride of 2 in the residual blocks reduces the temporal dimension from 100 to 7. This enables the model to extract more advanced features while removing redundant information, enhancing the model’s generalization ability.
2.2.3. Output Layer
The output layer maps the output features from the residual group to the final output space. The global average pooling layer compresses the temporal dimension of the features to 1, yielding the global average value for each channel. Subsequently, the fully connected layer regresses the 512-dimensional features to produce the final velocity prediction.
2.2.4. Loss Function
To objectively evaluate the model’s performance in the velocity prediction task, the MSE is adopted as the primary metric for quantifying the error. MSE is a widely used measure for comparing the differences between model predictions and actual observations, especially in continuous numerical prediction tasks such as velocity estimation. The formula for calculating the velocity loss using MSE is shown in the following Equation (
4):
In the equation, n denotes the number of samples, represents the predicted velocity value for the i-th sample by the model, and is the corresponding actual velocity value. The smaller the value of MSE, the higher the prediction accuracy of the model, indicating a smaller difference between the predicted values and the actual values.
2.3. Direction Branch Model
The direction branch model is designed to predict the instantaneous direction vector from IMU data, taking into account the velocity magnitude predicted by the velocity branch model. The velocity magnitude is used not only for the dynamic adjustment of the data window but also in the loss function calculation. The model’s architecture, depicted in
Figure 4, includes an input embedding layer, a positional encoding layer, an encoder layer, a fully connected layer, and an activation function. The embedding layer transforms the input into a higher-dimensional vector form, while the positional encoding layer adds a positional vector to each position. The encoder layer processes the input data through a multi-layer structure, with each head in the multi-head attention mechanism module performing self-attention computations, enabling the model to focus on the internal information of the sequence data. The fully connected layer converts the encoder’s output into a predicted direction vector, and the activation function introduces non-linearity to enhance the model’s expressive power. The proposed framework incorporates several novel modifications. Specifically, the decoder component of the Transformer architecture is omitted, as the objective is to derive an average velocity rather than predict a sequence of velocities within a window. This modification significantly enhances computational efficiency. Building on the insights from [
31], a ConvLayer is integrated after each encoder layer to mitigate computational overhead and augment the model’s capacity to handle long sequence data. Ultimately, a linear layer and L2 normalization are appended after the encoder to generate the unit vector of velocity.
The direction branch model also employs a time window of 200 data points as input, based on the data collected by the IMU sensors, to predict the direction vector of the last frame in the sequence. Unlike the velocity branch model, it incorporates the velocity magnitude sequence to aid in direction prediction. Specifically, it discards certain data points based on the velocity magnitude, thereby dynamically adjusting the size of the window. With a stride of 10 for step-by-step prediction, the model can transform an IMU data sequence of length N into a direction vector sequence of length . Finally, by combining the velocity magnitude sequence, a complete velocity vector sequence is formed. By applying this model, a series of discrete velocity vectors can be estimated from continuous IMU measurements, where each velocity vector represents the velocity of the last frame in a window of 200 data points.
2.3.1. Embedding Layer
The embedding layer employs a convolutional layer with a kernel size of 3 to increase the number of input channels from 6 to 64, capturing local features within the time series and thereby enhancing the model’s expressive capability.
2.3.2. Positional Encoding
The role of positional encoding is to provide the model with positional information for each time step, thereby enabling the model to capture the sequential order of the series. The calculation formula is shown as follows:
where
is the position in the sequence,
i is the dimension, and
is the dimensionality of the embedding.
2.3.3. Encoder Layer
The encoder consists of multiple encoder layers, each of which contains an attention layer that performs self-attention operations on the input sequence to extract the dependencies within the time series. The multi-head attention mechanism module in each encoder layer has multiple heads, each of which executes the self-attention mechanism to focus on different parts of the sequence data. The calculation is shown in the following Equation (
6):
where
Q,
K, and
V are the query, key, and value matrices, respectively, and
is the dimension of the key vectors. The fully connected layer transforms the output of the encoder into the predicted direction vector, and the activation function introduces non-linearity, thereby enhancing the model’s expressive capability.
2.3.4. Adaptive Window Adjustment
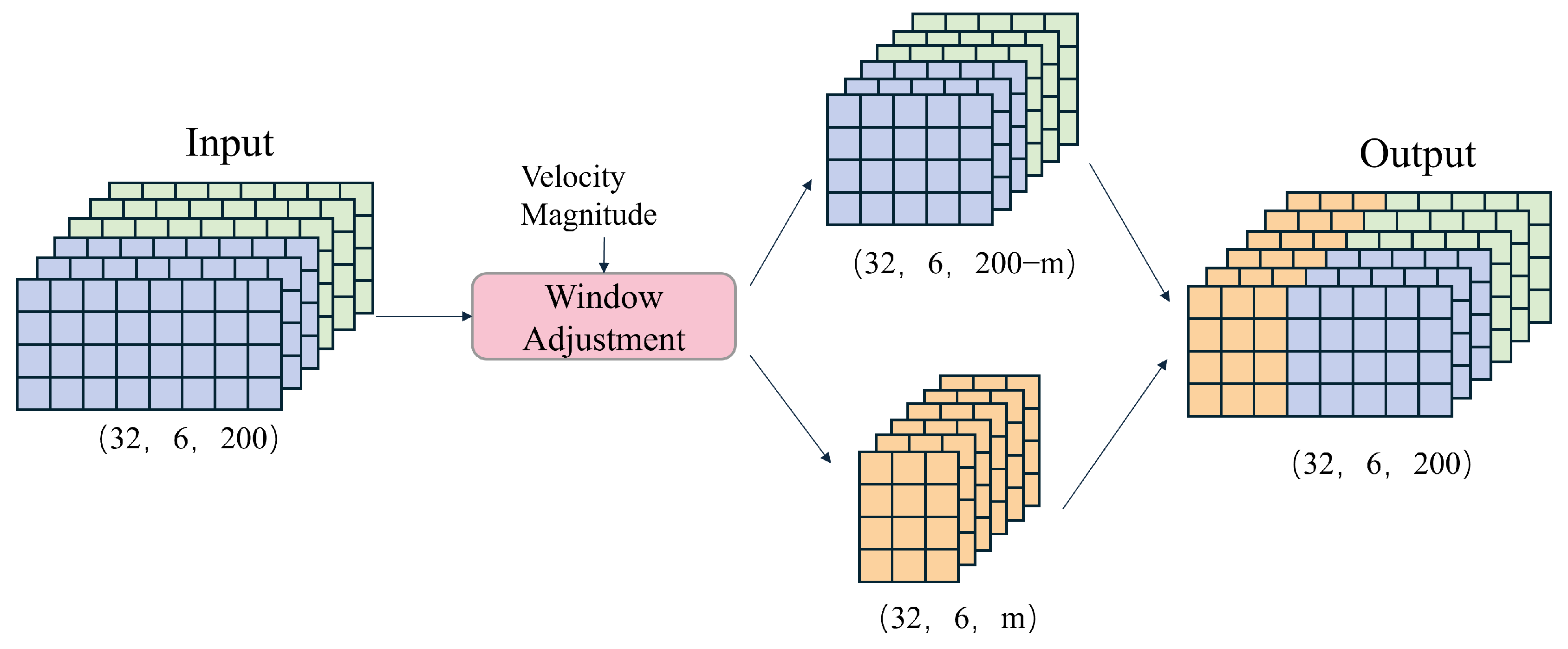
This paper proposes a dynamic window adjustment strategy, illustrated in
Figure 5, to enhance the accuracy of velocity prediction based on IMU data. This strategy dynamically adjusts the size of the data window based on the predicted velocity magnitudes, thereby optimizing computational efficiency and prediction accuracy.
The core idea of this strategy is to utilize the velocity prediction results from the preceding branch model to adjust the size of the data window in the direction branch model, thereby better capturing the motion features and enhancing prediction accuracy. The predicted velocities from the velocity branch model are first stored locally. Then, in the direction branch model, the size of the data window used for velocity direction prediction is dynamically adjusted based on the magnitude of velocity. This process is implemented through the following Equation (
7):
In the equation,
and
represent the data of the j-th frame within a 200-frame window, m denotes the adjustment node, and its calculation is shown in the following Equation (
8):
In the equation,
v represents the velocity magnitude corresponding to the window.
The adjustment method takes the predicted velocity magnitude and the window data for direction prediction as inputs and outputs of the modified window data. Essentially, it does not change the window size but sets the values of the first m data points in the window to zero. The value of m increases with the velocity magnitude. This is because higher velocities are more likely to result in velocity changes, reducing the correlation between the current velocity and previous data points.
2.3.5. Loss Function
For the direction branch model, this paper proposes a composite loss function that integrates cosine similarity and the magnitude of the velocity vector to optimize the network’s prediction accuracy of the velocity vector direction, especially at higher speeds. The construction of this loss function is based on the following theoretical foundation: during high-speed motion, deviations in direction prediction can significantly impact the accuracy of the trajectory. Therefore, the objective of this function is to enable the network to focus more on reducing directional prediction errors for samples with higher velocity values during the training process, as shown in the following Equation (
9):
By multiplying the cosine similarity with the velocity magnitude, the model ensures that both the direction and magnitude of the velocity are considered during training. Let x be the predicted velocity direction vector and y be the true velocity direction vector. The cosine similarity is calculated as shown in the following Equation (
10):
4. Conclusions
This paper presents a novel two-stage motion trajectory prediction model, ResT-IMU, which effectively enhances the accuracy and robustness of IMU-based localization. The proposed method leverages the self-attention mechanism of the Transformer architecture to capture temporal sequence features in IMU data, first predicting instantaneous velocity and then refining the estimation of motion direction based on the predicted velocity. The ResT-IMU model introduces a two-stage prediction framework that separates the prediction of instantaneous velocity and motion direction, allowing the model to focus on specific prediction tasks at each stage and thereby improving overall prediction accuracy and reliability. By combining ResNet for velocity prediction and Transformer for direction prediction, the model captures both spatial and temporal dependencies in IMU data, significantly improving trajectory prediction accuracy. The model also dynamically adjusts the size of the data window for direction prediction based on the predicted velocity, enabling it to handle different motion states more flexibly, especially during periods of drastic velocity changes.
Experimental results on the RoNIN and iIMU-TD datasets demonstrate that ResT-IMU outperforms existing models in both ATE and RTE. On the iIMU-TD dataset, ResT-IMU achieves an ATE of 3.08 and an RTE of 3.89, outperforming ResNet (ATE: 3.27, RTE: 3.73), LSTM (ATE: 3.87, RTE: 4.37), Encoder (ATE: 3.77, RTE: 3.95), IMUNet (ATE: 3.69, RTE: 3.91), and ResMixer (ATE: 3.21, RTE: 3.71). On the RoNIN dataset, ResT-IMU achieves an ATE of 3.64 and an RTE of 2.60, outperforming ResNet (ATE: 3.84, RTE: 2.72), LSTM (ATE: 4.22, RTE: 2.73), Encoder (ATE: 3.80, RTE: 2.78), IMUNet (ATE: 3.96, RTE: 2.93), and ResMixer (ATE: 3.76, RTE: 2.63). These results highlight the superior performance of ResT-IMU in reducing both ATE and RTE, thereby improving the overall accuracy of trajectory prediction.
Additional experiments on the TLIO dataset verify the model’s generalization ability in other application scenarios, with ResT-IMU achieving nearly 2 m errors in both absolute and relative terms, outperforming other neural network methods. Future research will focus on further optimizing the IMU-based localization algorithm, exploring more efficient network structures and training strategies to improve localization accuracy and model generalization ability, and reducing the algorithm’s power consumption to extend the device’s battery life while maintaining localization accuracy.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}