1. Introduction
An ADAS serves to provide drivers with warning information and assist in vehicle control when encountering driving risks. By enhancing drivers’ risk perception, it effectively reduces the likelihood and severity of collisions. This system operates by utilizing on-board sensors to collect driving-related data and predict whether selected risk indicators have surpassed a predefined threshold. However, by the time the warning system detects a risk, the vehicle has already been exposed to potential danger. Hence, the ability to accurately predict risks shortly before they manifest would allow for sufficient response time for the driver or safety systems. This aspect holds substantial importance for ensuring driving safety [
1].
The first step in predicting risks is to identify them. Driving risk encompasses both the probability and severity of a vehicle collision, which is evident through actual collisions or near-collisions. By utilizing real-time traffic data and analyzing and mining data prior to risk occurrences, risk identification can effectively prevent traffic accidents [
2]. Different data sources necessitate distinct risk identification methods. Currently, driving risks are primarily identified and predicted using two types of data sources: simulated driving data and natural driving data. Simulators enable the collection of driver behavior data in highly controlled environments, often utilized for researching specific scenarios and dangerous driving behaviors. Risk events can be artificially introduced in simulators [
3], although differences between the simulator and real-world scenarios can impact risk model parameters and thresholds. On the other hand, natural driving data overcome the limitations associated with data collection mentioned earlier. The data are collected through various sensors installed in the vehicle, providing a realistic representation of driving data disturbances and parameter variations during risk occurrences [
4]. However, natural driving data sets lack actual collision events, and obtaining a substantial number of real collision events is costly. Therefore, near-collision events are commonly employed to characterize risks, with many researchers employing surrogate safety measures (SSMs) to extract risk events.
SSMs play a crucial role in characterizing driving risk and enhancing the reliability and efficiency of warnings without relying on accident data. In 2008, the ANB20 (Safety, Data, and Analysis Committee) established the Alternative Safety Indicator Committee to facilitate and guide the development, application, validation, and implementation of alternative safety indicators.
In collision risk studies, researchers have adopted diverse methods to define risk, mainly focusing on acceleration, TTC, and its derivative indicators. Weng et al. [
5] chose the deceleration rate to avoid crash (DRAC) as a risk measure. Wang et al. [
6] regarded a situation as risky when the absolute value of longitudinal acceleration surpassed 1.5 or that of lateral acceleration exceeded 1.0. Naji et al. [
7] considered a scenario dangerous if the braking deceleration was less than −0.4 or the braking pressure went above 10.0 Mpa. Xue et al. [
8] used time headway (THW), time to collision (TTC), and margin to collision (MTC) for risk evaluation. There is also significant uncertainty regarding risk thresholds. For TTC, Ji et al. [
9] determined a 4.471-s threshold for severe conflicts between freight vehicles on mountainous two-lane roads. Minderhoud et al. [
10] suggested a typical TTC risk threshold range from 1.5 to 4.0 s. In Mobileye’s forward warning system, a warning is triggered when TTC falls below 2.7 s. To achieve a more comprehensive assessment, some scholars prefer to use a combination of indicators.
While risk identification contributes to improving driving safety to some extent, it can only identify risks when an event occurs, allowing for limited reaction time for the driver or safety assistance systems. Hence, it is essential to utilize short-term prediction methods to detect anomalies in on-board perception data during the period preceding a risk occurrence and provide early warnings in advance.
The short-term prediction of driving risk relies on timely and accurate identification of abnormal segments in on-board data prior to the occurrence of risks using predictive models. Currently, risk prediction models can be broadly categorized into statistical regression models and machine learning models.
Statistical regression models are typically based on historical statistical data and enable analysis and prediction. These models offer strong interpretability, providing valuable insights to traffic managers and drivers through model analysis. However, the predictive performance of these models is often limited. For example, Guo et al. [
11] used a negative binomial regression model to predict high-risk drivers and identify significant risk factors, highlighting the impact of age, personality, and serious accident rates on collisions and near-collisions. Yang et al. [
12] developed a Bayesian dynamic logistic regression model, where model parameters can be dynamically updated in real time based on collected traffic flow parameters and prior knowledge.
For instance, Chen et al. [
13] constructed a random forest model using a random oversampling strategy to predict rear-end accidents in tunnel entrance sections, achieving an AUC of 0.807. Li et al. [
14] developed a long short-term memory convolutional neural network (LSTM-CNN) model, combining CNN for extracting time-dependent features and LSTM for capturing temporal information changes, resulting in the highest AUC of 0.93 and the lowest false alarm rate of 12%. Shuangguan et al. [
15] utilized a multi-layer perceptron model to predict the accuracy of high-risk states occurring in the next 0.7 s during following conditions, achieving an accuracy rate of over 85%. The construction of a prediction model involves key technologies such as determining the prediction window length, addressing sample imbalance, and conducting feature selection. These factors are crucial to ensuring that the model achieves optimal performance.
On the other hand, machine learning algorithms have drawn much attention in driving risk prediction for their strong learning capabilities. Zhang et al. [
16] analyzed speed-related data of 56 ride-hailing drivers from Didi Chuxing. Their model with a modified loss function had 66.67% accuracy when using 10% of target data. Azadani et al. [
17] collected data from 10 subjects and compared multiple risk-recognition models. Temporal convolution performed best under various conditions. Hu et al. [
18] collected 9-D CAN bus signals from 20 subjects. Their integrated deep-learning model, combining improved networks and four data-enhancement methods, achieved 95.27% average accuracy. Using all enhancement methods, 3% of data could boost accuracy by 22.86%.
The length of the risk prediction window will significantly affect the prediction accuracy of the model. Weng et al. [
5] used floating car data to match collision data, extracted aggregated data from 5–10 and 10–15 min before the collision, and analyzed its impact on the collision; Kim et al. [
19] used DTG data to match collision events, extracting data within 1 min before the collision as dangerous traffic flow, and the five time periods 10–15 min before the collision were normal traffic flow; Lyu et al. [
20] extracted conflict events from vehicle trajectory data, taking the 30–60 s before the conflict as a positive sample, and the other 30 s as negative samples; Chen et al. [
21] conducted unsupervised learning through a three-layer L1/L2 NCAE (non-negativity-constrained deep autoencoder) network, and automatically updated the window size during the process of minimizing the objective function. The results showed that when the window size was 15 s, the original data information could be better preserved.
In conducting short-term risk prediction, a large number of positive and negative samples are needed for labeling and training. However, positive sample data labeled as risk are sparse. Therefore, risk prediction needs to undergo sample imbalance processing. Dealing with sample imbalance can be achieved at both the data and algorithm levels. At the data level, the most commonly used methods include undersampling, oversampling, and mixed sampling. Undersampling is to reduce the number of samples in most classes. The main methods include random downsampling and matched case controlled downsampling [
22], and ENN (Edited Nearest Neighbours). Oversampling refers to increasing the number of minority samples. The main methods include random oversampling, SMOTE (synthetic minor oversampling technique), and ADAYN (adaptive synthetic sampling), SVM-SMOTE, K-means SMOTE, etc., which are improved based on SMOTE. At the algorithmic level, it is possible to adjust the learning weight of samples, increase the punishment after classifying a few categories incorrectly, or select models that are not sensitive to sample imbalances. In the process of dealing with sample imbalances, using only one method to improve the performance of the model is very limited. Appropriate methods should be selected from different perspectives based on the characteristics of data and algorithms to combine. Risk prediction also requires selecting appropriate characteristic variables and eliminating irrelevant and redundant variables can help improve model efficiency and generalization ability. In summary, each key technology of risk prediction needs to be optimally adjusted based on specific data and needs, but currently, driving risk prediction algorithms often ignore or simplify some key points.
This study aims to enhance driving safety by utilizing vehicle sensor data for early and accurate prediction of driving risks. To achieve this, a natural driving dataset is constructed through on-road experiments and data processing techniques. The study proposes a comprehensive system for short-term prediction of driving risks, which includes methods such as threshold selection for driving risk indicators, extraction of driving risk events, optimization of prediction windows, feature selection, short-term model prediction, and analysis. The novelty of this study lies in several aspects. Firstly, Monte Carlo simulation methods are employed to precisely calibrate the threshold values of risk indicators, ensuring accurate assessment of driving risks. Additionally, variable sliding windows and machine learning methods are utilized to explore the patterns of risk evolution. By incorporating feature selection techniques, the prediction performance of the model is both simplified and enhanced. Moreover, the study examines the impact of different data sources on prediction accuracy. The structure of the paper is organized as follows:
Section 2 provides an introduction to the data source and the pre-processing methods employed in this study.
Section 3 describes the research methods used, emphasizing their alignment with the data features.
Section 4 presents the obtained results and provides an analysis of these findings. Finally,
Section 5 summarizes the key insights drawn from this study.
3. Materials and Methods
This study utilized a significant volume of natural driving data to extract risk events, which were then employed for training and validating the risk prediction model. Initially, the risk indicator threshold was calibrated using the Monte Carlo simulation method. Subsequently, the risk events were identified using the threshold method and further validated and scrutinized through on-site video analysis. The feature variables incorporated in the model encompass diverse aspects of the driving process, encompassing driver control parameters, vehicle operating state parameters, and driving environment. To analyze the impact of various factors such as prediction window lengths, lead lengths, and data sources on the prediction performance, four machine learning algorithms were employed.
The issue of sample imbalance was addressed by implementing the random undersampling method. Optimal features were selected using the LGBM-Boruta method, and model parameters were optimized through Bayesian tuning. The most effective model was chosen for short-term driving risk prediction, and the causal analysis was conducted based on the prediction results.
3.1. Driving Risk Identification Method
In this study, braking deceleration and TTCi were used as indicators of driving risk events and combined with the risk quantification method proposed by Shangguan [
15] to propose a risk indicator threshold calibration method based on Monte Carlo simulation. This method simulates the random deceleration of the front vehicle, and after the driver’s reaction time, the rear vehicle makes the maximum braking deceleration to determine whether a collision occurs. The random disturbance of the front vehicle follows a shifted gamma distribution
Ga (17.32, 0.13, 0.66) [
23], the driver’s reaction time follows a log-normal distribution
logN (0.92, 0.28) [
24], and the maximum braking deceleration of the rear vehicle follows a truncated normal distribution 4.23 ≤ N (8.45, 1.4) ≤ 12.68 [
25]. Through 10,000 simulations, the risk threshold is calibrated based on the simulation results. Risk events are subsequently extracted using the threshold method and verified through video analysis. The algorithm for extracting driving risk events is outlined in Algorithm 1.
Monte Carlo simulation is employed to estimate the probability of collision under car-following conditions, which serves as the basis for identifying preliminary driving risk states. As illustrated in
Figure 2, Driver #4 is taken as an example. For each frame of driving data, a simulation is conducted to calculate the corresponding collision probability. When the probability exceeds 0.5, the moment is labeled as a preliminary risk state. For each risk indicator under this state, the distribution of its values is analyzed: for indicators where higher values indicate greater risk, the 85th percentile is extracted; for indicators where lower values indicate greater risk, the 15th percentile is extracted. These percentile values are used as reference thresholds to assess whether a given indicator significantly contributes to the identified risk state.
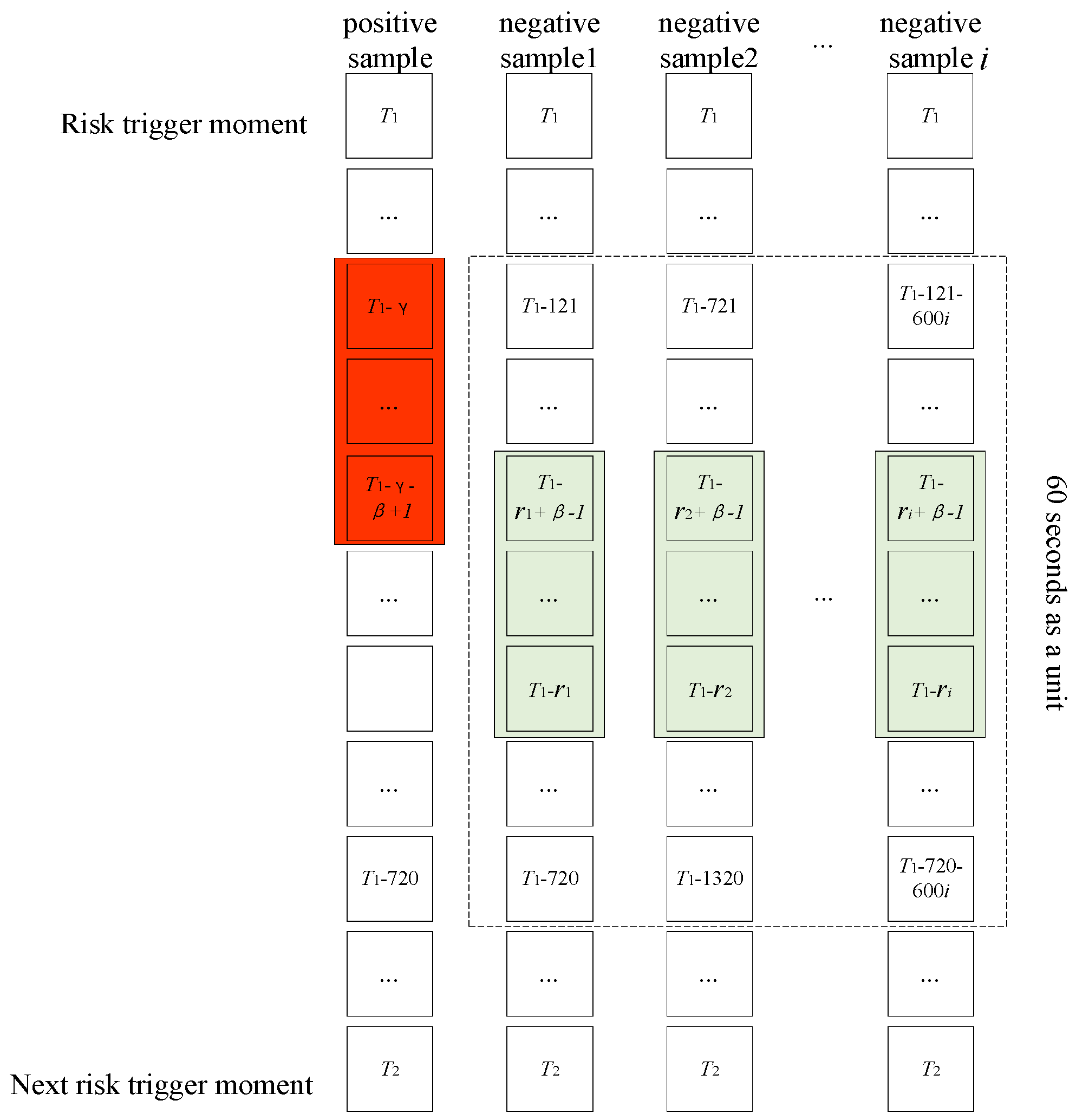
3.2. Variable Sliding Window and Negative Sample Downsampling Method
Risky driving data refers to the data collected within a specific time frame, specifically a few seconds before a risk event occurs. In this context, γ represents the lead length of the prediction window, while β denotes the length of the prediction window. The remaining time outside this window is categorized as normal driving data. To capture the evolving pattern of risks leading up to an event, a variable sliding window is utilized. This window adjusts its length based on the value, allowing for a comprehensive exploration of the data. Since there is a significant imbalance between risky and normal driving data, it is necessary to address this issue during dataset construction. To tackle the problem, random undersampling of negative samples is employed. Specifically, normal driving data are divided into fixed-length driving segments in sequential order. Prior to the maximum risk window width of each segment, a random number is generated. Subsequently, the data extracted from the window, which has a width of β units after the random number, are considered as negative samples. This approach effectively reduces the number of negative samples, while still retaining most of the information from the normal driving data. Consequently, it successfully resolves the challenge of data imbalance in risk prediction. Overall, this approach allows for a thorough analysis of risky driving data and normal driving data, while addressing the data imbalance issue, thus enhancing the accuracy of risk prediction.
The method described in
Figure 3 was implemented using a fixed length of 60 s. With this configuration, the ratio of positive to negative samples extracted was found to be 942:3533. This ratio adheres to the general model sample balance condition. A total of 676 datasets were generated for model input by extracting data with a step size of 0.2 s from prediction window lead length γ ∈ (1,6) s and prediction window length β ∈ (1,6) s.
| Algorithm 1 Risk status identification algorithm |
Input: vehicle speed , front vehicle speed , distance between two cars , reciprocal of TTC , braking deceleration
for to do
for to 10,000 do
if then
end
end
if then
end
end
for to do
if then
end
end
Output: Risk label (0,1) |
3.3. LightGBM-Boruta Feature Selection Method
A LightGBM-Boruta feature selection method is proposed. This method uses the feature importance output from the LightGBM model to screen out the feature set that is correlated with the dependent variable. To accomplish this, a shadow feature S is created to correspond with each real feature R. Subsequently, a new feature matrix [R, S] is formed, serving as the input for the LightGBM model. The feature importance of each feature is then calculated using the following procedure:
The entropy
Entropie(
D) of the sample set in a tree node is as follows:
If the number of times the sample set is divided according to feature A is n, the feature importance
ZA is as follows:
The shadow features are sorted based on their importance, and a percentile value is selected as the threshold for comparing the importance of real features. If the importance value of a real feature exceeds this threshold, it is considered significant and selected for further analysis. A two-sided test is then conducted to eliminate shadow features whose importance is significantly lower than the corresponding percentile. This process continues iteratively until all features have been marked with their respective importance. The specific algorithm flow chart is shown in
Figure 4.
3.4. Driving Risk Prediction Model
The short-term prediction model for driving risk aims to detect abnormal driving data shortly before a risk event occurs. It utilizes a classification model to identify segments of driving data that deviate from normal patterns. By employing data processing techniques mentioned earlier, such as combining natural driving data and employing various machine learning methods, namely logistic regression (LR), multilayer perceptron (MLP), extreme gradient boosting (XGBoost), and light gradient-boosting machine (LGBM), pre-classification is performed. These four classification algorithms, LR, MLP, XGBoost, and LGBM, were chosen based on their superior performance. The evaluation of the model’s performance includes accuracy rate, recall rate, precision rate, and F1 value as indicators.
- (1)
LR:
The LR algorithm is widely recognized as one of the most commonly used and traditional algorithms in machine learning. It offers several advantages, including a simple model structure, easy interpretability, and fast training speed. By incorporating a sigmoid function into the linear regression model, the algorithm maps the predicted results to values between 0 and 1, facilitating categorical determination.
- (2)
MLP:
MLP is a highly popular artificial neural network algorithm utilized in various domains. It comprises three layers: the input layer, hidden layer, and output layer [
26]. The input layer receives the necessary feature vectors, with each neuron fully connected to neurons in the preceding hidden layer. The hidden layer is so named due to its lack of direct interaction with the external environment. Neurons in both the hidden and output layers are fully interconnected, and the model’s prediction results are generated accordingly.
- (3)
XGBoost:
XGBoost, initially proposed by Dr. Chen, has emerged as a prominent integrated machine learning algorithm renowned for its exceptional characteristics and interpretability. Based on the CART (Classification and Regression Tree) model, XGBoost employs multiple CART trees in collaboration [
27]. The CART tree selects features and optimal splitting points by minimizing the Gini index, and it undergoes pruning to prevent overfitting. By adopting the concept of Gradient Tree Boosting, XGBoost enables ensemble learning of multiple CART trees. This entails calculating the negative gradient of the objective function to guide the optimization of submodels.
- (4)
LGBM:
LGBM shares fundamental principles with XGBoost and serves as an implementation of gradient-boosting decision trees. However, it distinguishes itself with its emphasis on being “lightweight,” achieving a faster runtime and reduced memory consumption. LGBM enhances the splitting point and leaf node growth strategies employed in the XGBoost algorithm. It organizes feature values by size and utilizes histograms to store continuous features in discrete bins, facilitating efficient search for optimal features and split points. LGBM offers two growth methods for leaf nodes: layer-by-layer and leaf-by-leaf [
28]. Unlike XGBoost’s layer-by-layer approach, LGBM’s leaf-by-leaf growth method identifies nodes with higher information gain for expansion, thereby enhancing prediction accuracy while preventing excessive model complexity. To control tree depth, LGBM employs a leaf-by-leaf growth algorithm with depth constraints.
3.5. SHAP
The SHAP method was improved by Shapley in 1953 in combination with cooperative game theory to solve the problem of revenue allocation after multiple players cooperate to complete tasks in a game. By leveraging cooperative game theory principles, SHAP offers a novel approach to measuring the impact of features on a model. This is accomplished by quantifying the changes in output resulting from the absence of specific features across all possible feature combinations. By leveraging cooperative game theory principles, SHAP offers a novel approach to measuring the impact of features on a model. This is accomplished by quantifying the changes in output resulting from the absence of specific features across all possible feature combinations. The prediction result of the model is obtained by adding the SHAP values, which can be expressed as follows:
where
is a bias term that typically predicts the mean for all samples.
represents the SHAP value of characteristic variable
i,
, and
M is the characteristic quantity. The characteristic variable
z for the selected analysis is 1; otherwise, it is 0.
S represents a subset of all feature variables set N except for i feature variables, represents the number of permutations and combinations before feature in the sequence, and and represent the predicted output and expected output of a given set of S except for the i characteristic variable, respectively.
5. Conclusions
This study presents a novel approach for short-term driving risk warning based on onboard sensing data. The key contribution of this paper is the introduction of a new method to calibrate the risk index threshold and determine the risk event identification method. The study incorporates various techniques such as a variable sliding window, negative sample undersampling, LGBM-Boruta feature selection, and classic machine learning to develop a short-term prediction system for driving risks. The main findings of the study are summarized as follows:
- (1)
The proposed risk event identification method establishes the risk thresholds for TTCi and braking deceleration as 0.86 s−1 and −2.6 m/s2, respectively.
- (2)
A combination of four machine learning methods and a variable sliding window approach is employed to explore the pattern of risk evolution. The study reveals that as the prediction window lead length increases, the prediction performance generally decreases, but the decline rate varies. The optimal prediction window lead length and prediction window length are determined as 1.6 s and 1.2 s, respectively, based on comprehensive considerations.
- (3)
The short-term driving risk prediction model utilizes the statistical Boruta method for feature selection. This technique effectively filters out irrelevant feature variables, simplifies the model’s input variables, and improves risk prediction performance.
- (4)
Among the models evaluated in this study, the LR model exhibits the highest accuracy at 89.17%, while the LGBM model achieves the best recall and F1 values at 90.20% and 87.90%, respectively. This method demonstrates its potential to meet the risk prediction requirements of future ADAS systems. The prediction performance varies depending on the data sources, with the following ranking in terms of effectiveness: surrounding information > driver manipulating information > vehicle attitude information. Notably, combining data from all three sources significantly enhances the prediction performance compared to individual data source predictions.
- (5)
SHAP analysis identifies VEL_Mean, GPD_Mean, and RTC_Max as the most influential features impacting short-term driving risk prediction. Some of these features also serve as crucial indicators for distinguishing different driving conditions. Future work can focus on dividing driving conditions initially and then conducting training and prediction specific to each condition, leading to improved prediction results.
In this study, we developed a high-grade roads dataset to verify the effectiveness of our risk prediction methodology using in-vehicle perception data under high-grade road conditions. When constructing the dataset, we incorporated various types of high-grade roads, including urban arterial roads, urban expressways, and freeways, and took different speed limits into account. The resulting dataset demonstrates good generalizability for the short-term risk prediction method based on in-vehicle perception data on high-grade roads. To further strengthen the credibility of the model’s performance, conducting tests in actual vehicles equipped with ADASs is advisable. Building on this, future research proposes to conduct experiments with a simulated or real warning system. These experiments aim to assess drivers’ reactions to the predicted risk, which will provide more practical insights into the effectiveness of our prediction method.
However, the applicability of this method in low-grade roads, areas with special road features (such as sharp curves, long and steep slopes), and intersections still needs to be verified. In future research, we intend to use datasets from other scenarios to test the effectiveness of this method. Based on these tests, our goal is to further enhance the method and develop an algorithm with greater generalization ability. Moreover, considering external factors such as pedestrian and cyclist behavior or dynamic changes in traffic can contribute to improving the accuracy of short-term risk prediction. In light of this, we plan to further refine the dataset, which will not only improve the prediction accuracy but also help us better understand how the method performs in different real-world situations. This continuous improvement process will enable us to develop a more robust and reliable risk prediction system.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}