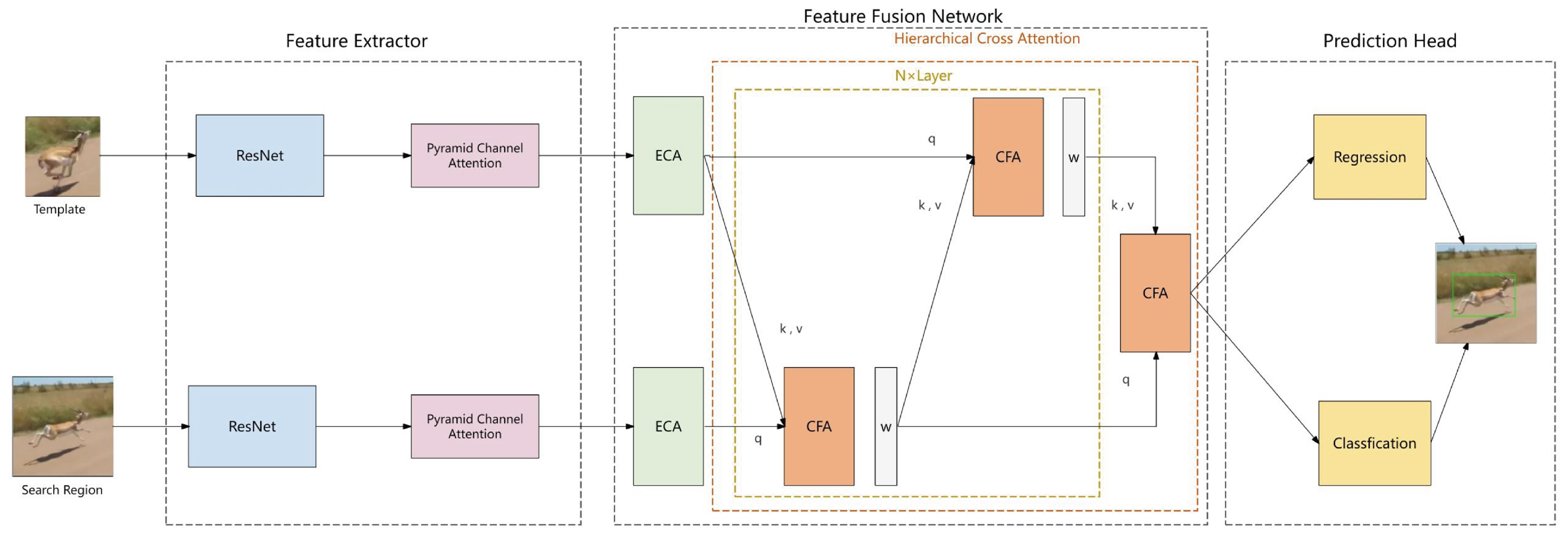
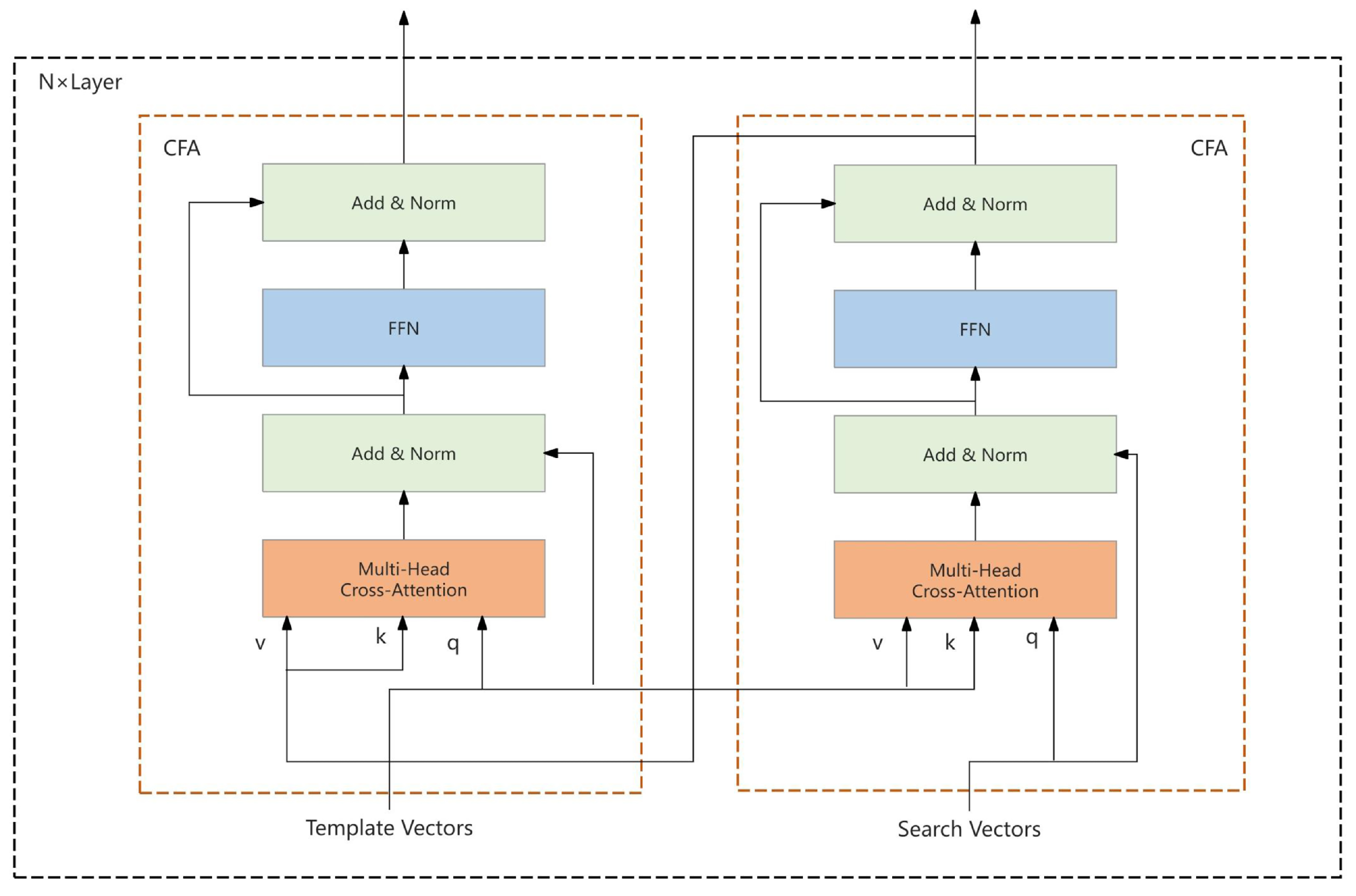
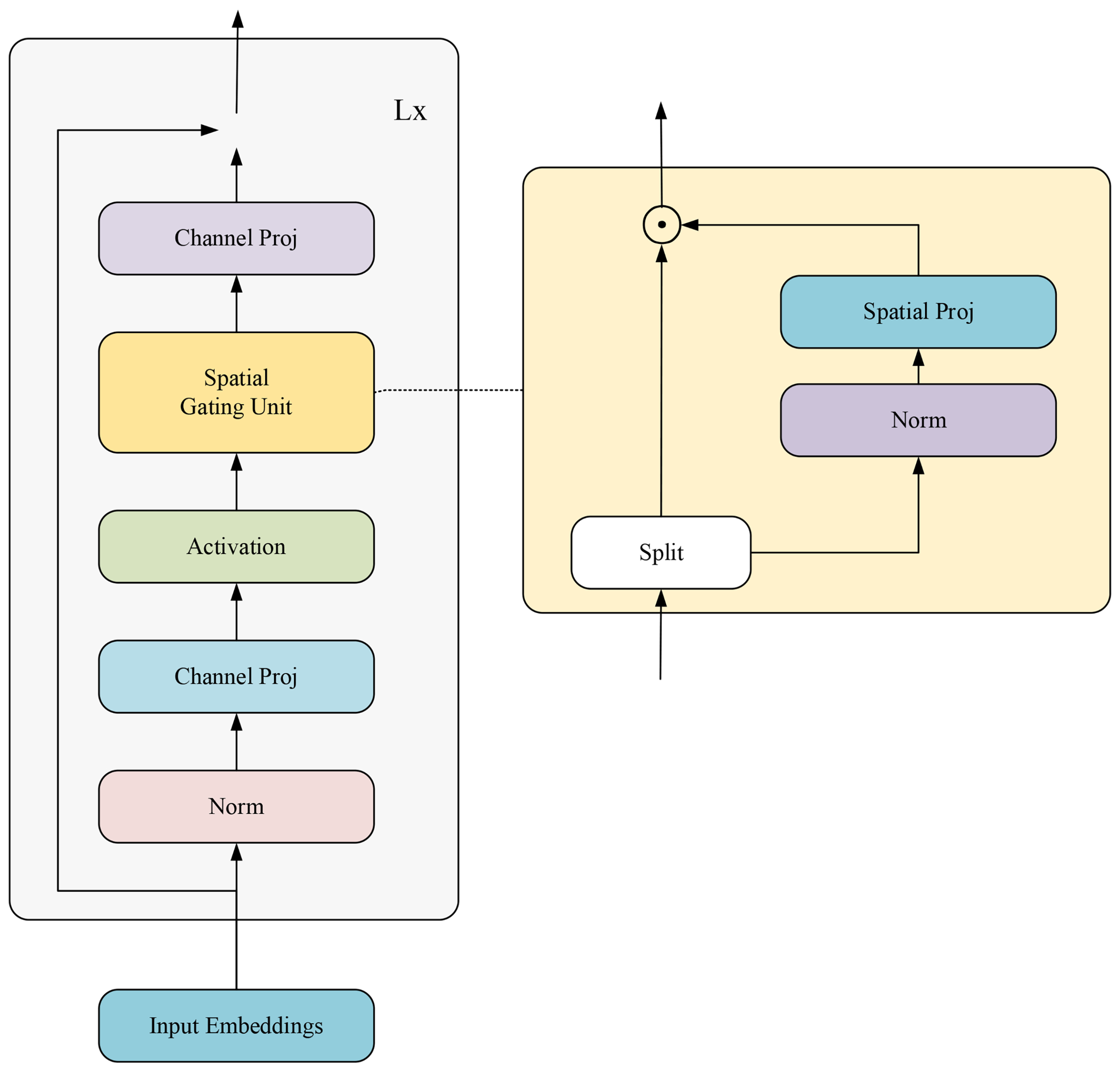
4.1. Experimental Parameters
The method proposed in this paper was validated through a series of experiments conducted on a high-performance server platform. The server was configured with the Linux operating system, equipped with an Intel® Xeon® (The manufacturer of the Intel® Xeon® processor is Intel Corporation, headquartered in Santa Clara, CA, USA) Platinum 8255C processor, and featured an NVIDIA Tesla V100SXM2 (The NVIDIA Tesla V100S SXM2 is manufactured by NVIDIA Corporation, headquartered in Santa Clara, CA, USA) graphics card with 32GB of video memory. The deep learning framework utilized for the experiments was PyTorch version 1.9.0, and the programming language used was Python version 3.8.10. This setup ensured the stability and efficiency of the experimental environment, providing a reliable foundation for the evaluation of the algorithm’s performance.
The GOT-10K [
3] was used for model training, with AdamW used as the optimizer. During the training phase, each batch consisted of 20 samples, and the entire training cycle included 40 epochs, with each epoch consisting of 1000 training pairs. To reduce the risk of overfitting, the dropout rate was set to 0.1 in the experiments. The initial learning rate for the feature extraction network was set to 0.00001, while the initial learning rates for the other structural parameters were set to 0.0001.
Regarding data processing, the model performed standardization on the input data, with the mean values set to 0.485, 0.456, and 0.406, and the standard deviations set to 0.229, 0.224, and 0.225. The search region factor was set to 4.0, and the template region factor was set to 2.0. The search feature size was set to 32, and the template feature size was set to 16. The center jitter factor was set to 3 for the search and 0 for the template, while the scale jitter factors were set to 0.25 and 0, respectively.
4.2. Ablation Experiment
To substantiate the effectiveness of the proposed modules, this section conducts an ablation study and performs an in-depth analysis on both the GOT-10k [
3] and OTB-100 [
4] datasets. Commencing with the GOT-10k dataset, the TransT method was employed as the reference baseline before progressively integrating the pyramid channel attention mechanism, hierarchical cross-attention mechanism, and advanced multi-layer perceptron (aMLP). After each module integration, a stringent performance evaluation was conducted to verify the accuracy of the experimental outcomes. The success rate (SR) and average overlap (AO) of the model were compared on the GOT-10k dataset, and the ablation study results are presented in
Table 1 and illustrated in
Figure 7.
Introducing the pyramid channel attention mechanism into the baseline TransT model resulted in an increase in the AO value from 0.572 to 0.593, an increase in the SR at an overlap threshold of 0.5 (SR0.5) from 0.690 to 0.711, and an increase in the SR at an overlap threshold of 0.75 (SR0.75) from 0.440 to 0.476. Following the integration of the hierarchical cross-attention mechanism, the AO further increased to 0.619, the SR0.5 to 0.723, and the SR0.75 to 0.527. Ultimately, upon integrating the aMLP, the AO reached 0.625, with the SR0.5 at 0.746 and the SR0.75 at 0.530. These results indicate that the integration of each component significantly contributes to the performance enhancement of the tracking model.
To further validate the correctness of the ablation study results obtained on the GOT-10k dataset, this study extended the experimental scope to the OTB-100 dataset. The ablation study on the OTB-100 aimed to further verify the specific tracking effects demonstrated in the ablation study. The results are detailed in
Table 2, with the success rate curves and precision rate curves depicted in
Figure 8 and
Figure 9, respectively.
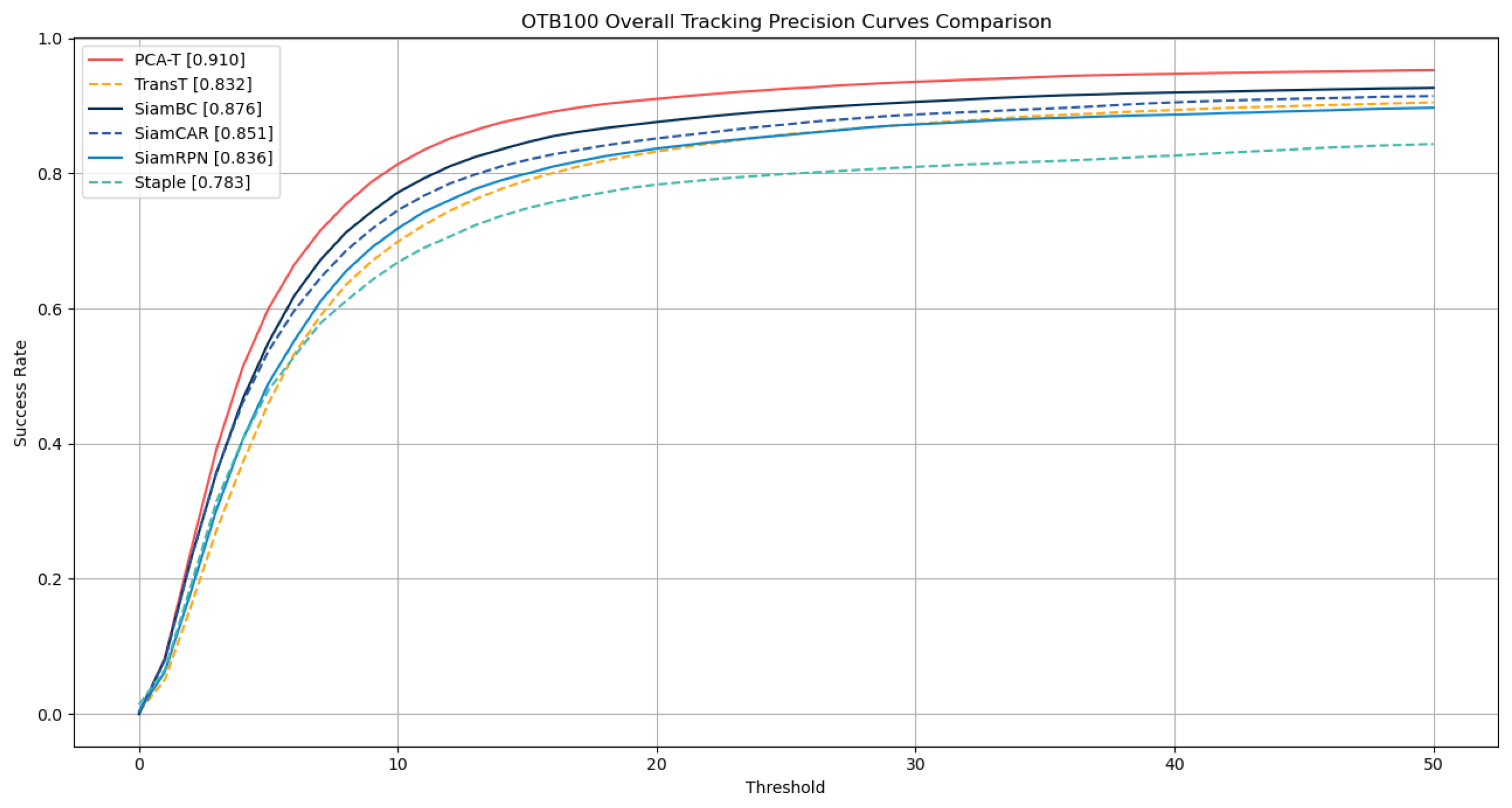
The experimental outcomes on the OTB-100 dataset corroborate the conclusions drawn from the GOT-10k dataset ablation study. The results demonstrate that the accuracy and precision of tracking were improved with the gradual integration of various enhancements in the baseline TransT model. Notably, when all enhancements were integrated into the TransT model, forming the improved proposed PCA-T model, the model achieved a success rate of 0.696 and a precision rate of 0.910, surpassing the performance of the other models in the ablation study. These results fully substantiate the effectiveness of the proposed method.
4.3. Quantitative Analysis
To thoroughly assess the performance of the proposed PCA-T model, this study conducted a comparative analysis between the PCA-T model and five contemporary models within the field of object tracking, including the transformer-based TransT model; the Siamese network-based SiamBC, SiamCAR, and SiamRPN models; and the correlation filter-based Staple model. The quantitative evaluation of the models was performed using the GOT-10k and OTB-100 datasets.
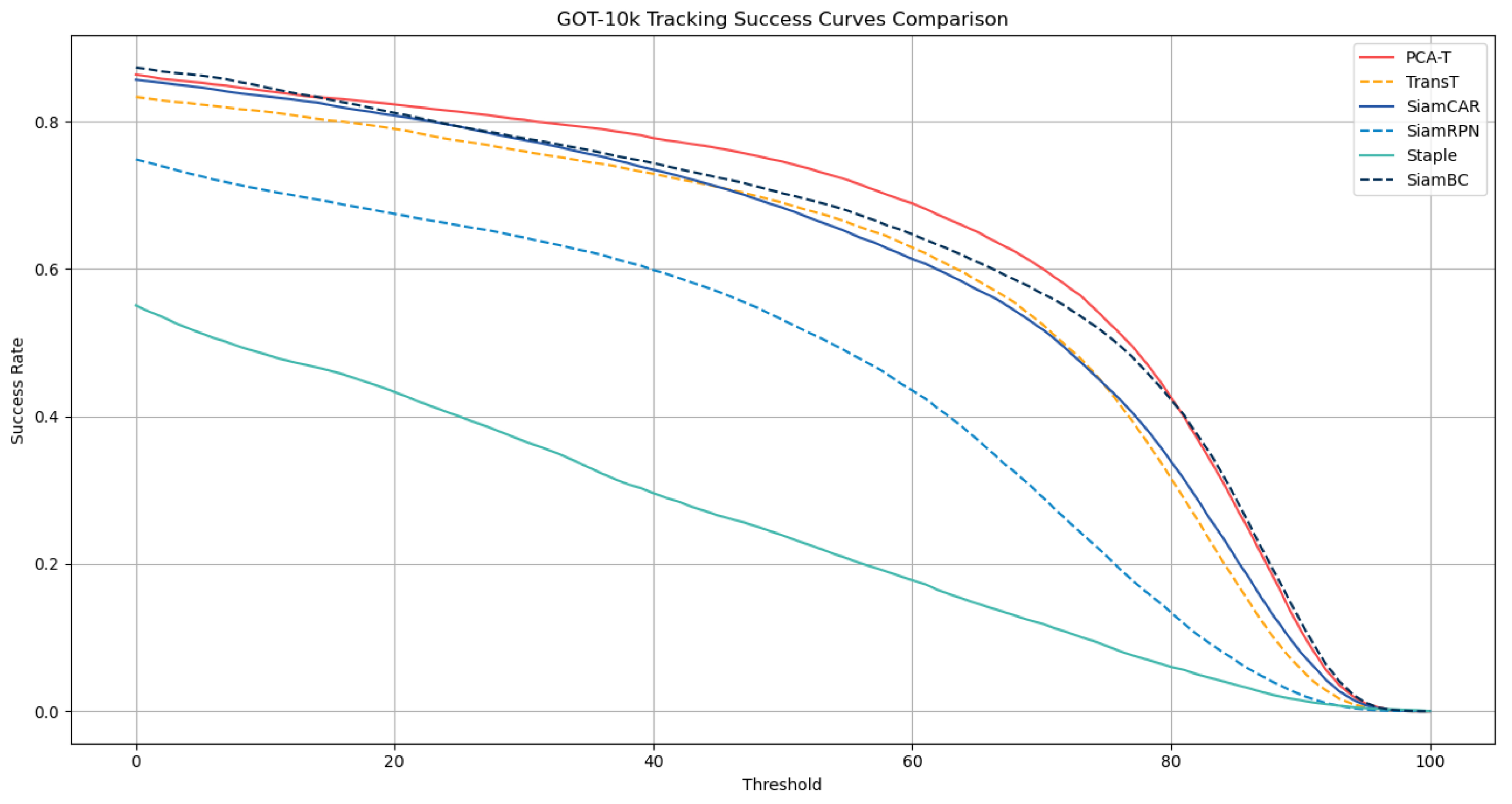
For the assessment of model performance on the GOT-10k dataset, this study employed three metrics: average overlap (AO), success rate (SR), and success rate curve (SRC). The average overlap refers to the mean of the overlap ratios between the target region and the ground truth across all frames. The success rate is the proportion of frames where the overlap ratio exceeds a certain threshold (e.g., 0.5 or 0.75) relative to the total number of frames. The success rate curve illustrates the variation in the success rate at different thresholds. The results of the PCA-T model in terms of average overlap and success rate compared to those of the other methods are presented in
Table 3, while the results of the success rate curves are depicted in
Figure 10.
The experimental results indicate that the enhanced PCA-T model outperformed the comparative models across three evaluation metrics: average overlap (AO), success rate (SR), and success rate curve (SRC). The model maintained a high success rate across various thresholds, demonstrating its robustness and accuracy.
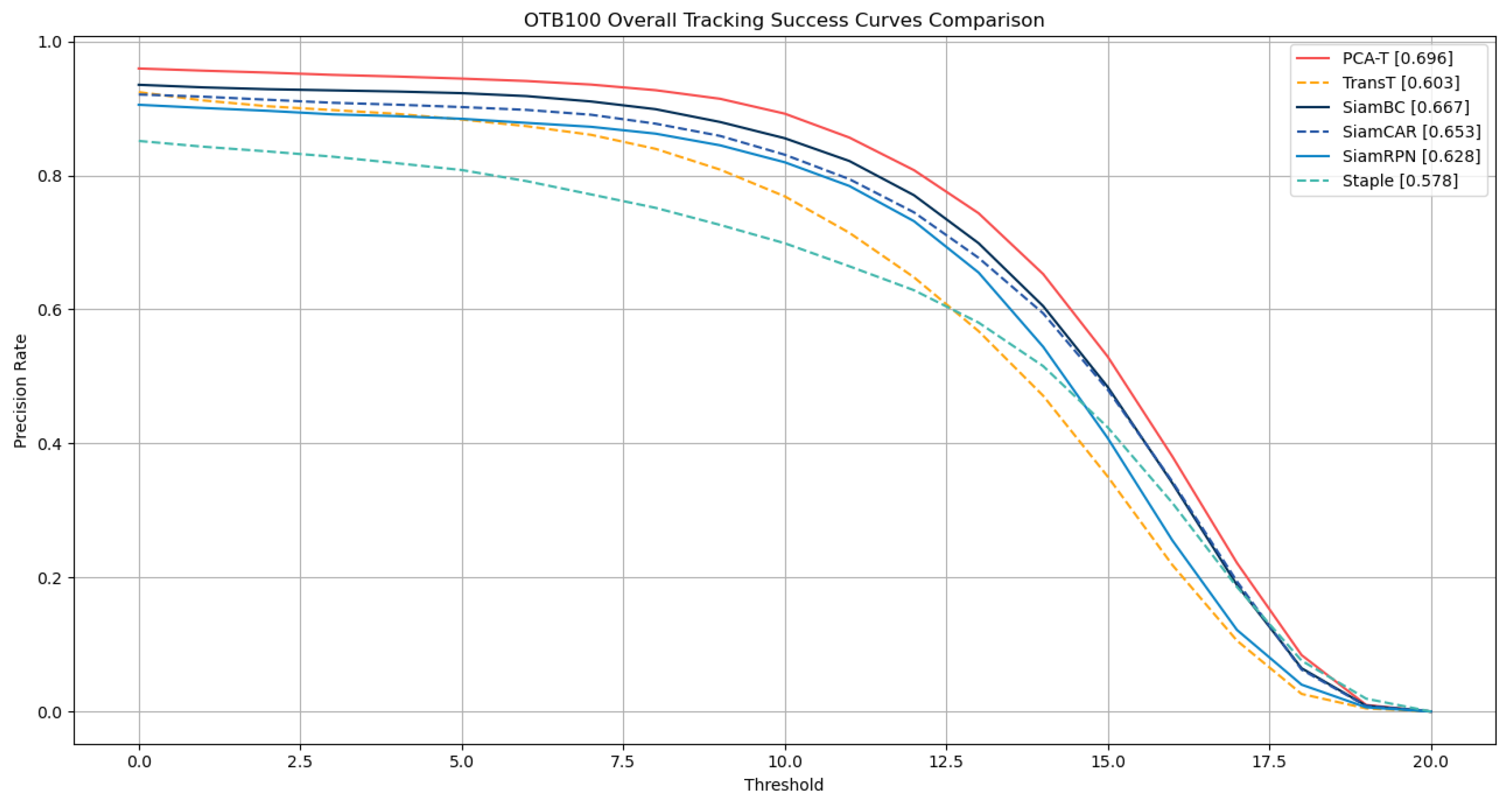
On the OTB-100 dataset, this study employed a one-pass evaluation (OPE) approach to quantify the performance of the tracking algorithms, selecting the success rate (SR) and precision rate (PR) as the metrics for assessment. The specific numerical results are summarized in
Table 4, while the success rate curves and precision rate curves are presented in
Figure 11 and
Figure 12, respectively.
The experimental results on the OTB-100 dataset demonstrate that the proposed PCA-T model outperformed five existing models in both the success rate and precision rate, further confirming the superior performance and significant advantages of the PCA-T model in addressing object tracking tasks.
Based on a comprehensive analysis of the experimental results on the OTB-100 dataset, this study further explored the specific performance of the proposed PCA-T model under various complex scenarios. Utilizing the 11 video attributes of the OTB-100 dataset, which include illumination changes, scale variations, occlusions, motion blur, and seven other distinct scene attributes, this study categorized these attributes and calculated the accuracy and precision performance of each model within each category. The success rate data are summarized in
Table 5, while the precision rate data are presented in
Table 6.
The experimental results revealed that the PCA-T model achieved exceptional tracking performance across multiple video attributes. Specifically, the PCA-T model achieved the best success rate performance in ten video attributes, including illumination variation (IV), scale variation (SV), occlusion (OCC), deformation (DEF), fast motion (FM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), background clutter (BC), and low resolution (LR). In the motion blur (MB) scenario, although the PCA-T model slightly underperformed compared to the SiamCAR model, the gap between the two was merely 0.014, indicating that the PCA-T model still maintained a high level of performance in this scenario.
In terms of precision, the PCA-T model demonstrated the best performance in scenarios such as illumination variation (IV), occlusion (OCC), background clutter (BC), and low resolution (LR), and also exhibited strong performance in scale variation (SV), deformation (DEF), in-plane rotation (IPR), and out-of-plane rotation (OPR), with data differences from the optimal model not exceeding 0.03. Although the PCA-T model’s performance was somewhat lacking in the fast motion (FM), motion blur (MB), and out-of-view (OV) scenarios, the overall gap from the optimal model remained less than 0.09.
These results indicate that the PCA-T model has a significant advantage in terms of the success rate and is capable of maintaining accurate target tracking and localization under various complex conditions, especially in challenging scenarios, such as illumination variation, occlusion, background clutter, and low resolution, where its performance was particularly outstanding. Moreover, despite a slight decrease in precision in certain extreme conditions, the overall precision performance of the PCA-T model remained good, indicating the model’s effectiveness in controlling the center error. Therefore, based on these results, it can be concluded that the PCA-T model demonstrates strong performance and broad applicability in video tracking tasks, making it a reliable choice with high success and precision rates in a variety of video tracking tasks.
In summary, the proposed PCA-T model underwent a rigorous quantitative evaluation of its performance in the field of object tracking and was validated on the widely recognized GOT-10k and OTB-100 datasets. The evaluation results showed that the PCA-T model outperformed comparative models in several key performance indicators, including the average overlap (AO), success rate (SR), and precision rate (PR), thereby achieving superior tracking performance.
Furthermore, a detailed attribute classification and performance comparison analysis of the video sequences in the OTB-100 dataset further confirmed the outstanding performance of the PCA-T model across a diverse range of tracking scenarios. Particularly in the handling of complex scenarios such as illumination variation, scale variation, and occlusion, the model showed significant robustness and accuracy. Although the performance of the PCA-T model in the motion blur scenario was slightly lower than that of the SiamCAR model, the overall performance of the PCA-T model still surpassed that of the comparative models in other scenarios.
Considering all factors, the overall performance advantages of the PCA-T model in object tracking tasks, particularly its robustness and accuracy in complex video scenarios, demonstrate its potential and value in practical applications. These findings provide new perspectives for the development of object tracking technology and lay a solid foundation for future research directions and application practices.
4.4. Qualitative Inorganic Analysis
In order to thoroughly investigate the performance of the proposed PCA-T model in various challenging and complex scenarios, we selected four representative video sequences from the OTB-100 dataset for keyframe tracking tests and conducted a comparative analysis with other tracking models, including TransT, SiamBC, SiamCAR, SiamRPN, and Staple.
The selected video sequences comprehensively cover typical tracking challenges, including illumination variations, scale changes, occlusions, deformations, and motion blur. These challenges were integrated into the tracking process to fully test the robustness of the model.
Table 7 provides a detailed list of the attributes and characteristics of the selected video sequences, while
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18,
Figure 19 and
Figure 20 present the tracking effects of each model for the selected video sequences through intuitive visualization, offering a visual reference for subsequent performance comparison and analysis.
In the experimental study of the “boy” video sequence, the keyframes at frames 320, 345, 397, and 602 were chosen for in-depth analysis. As depicted in
Figure 13 and
Figure 14, the target object underwent in-plane rotation in frames 320 and 345. Frame 397 featured an out-of-plane rotation due to a change in the camera’s perspective, and in frame 602, a change in the camera distance led to a scale variation in the target object. The experimental results indicate that the proposed PCA-T model demonstrated excellent tracking accuracy on the keyframes of the “boy” video sequence, effectively handling complex scenarios involving multiple attribute combinations such as scale changes, in-plane rotations, and out-of-plane rotations. This further confirms the model’s reliability in these specific scenarios and showcases its high efficiency in object tracking tasks.
In the in-depth analysis of the “biker” video sequence, the keyframes at frames 42, 65, 74, and 90 were meticulously examined. As shown in
Figure 15 and
Figure 16, the target experienced rapid motion in frames 65 and 74, resulting in significant motion blur. Additionally, in frames 74 and 90, the target underwent shape changes and rotations. The experimental results demonstrate that the PCA-T model proposed in this study can accurately locate and track the target object’s size changes even in challenging tracking situations such as rapid motion, motion blur, and rotation. In comparison, the comparative tracking models exhibited varying degrees of tracking drift and scale estimation errors in these scenarios. This finding further corroborates the significant effectiveness of the PCA-T model in addressing high-difficulty tracking tasks, such as rapid motion and motion blur.
In the experimental study of the “tiger1” video sequence, the keyframes at frames 31, 60, 90, and 215 were selected for in-depth comparative analysis. As illustrated in
Figure 17 and
Figure 18, the target’s mouth-opening and -closing movements in frames 31 and 90, along with the introduction of a new light source, led to significant changes in lighting conditions, which had a substantial impact on the target’s appearance features. In frames 60 and 215, parts of the target were occluded by vegetation, challenging its integrity. The experimental results show that the proposed tracking model was able to effectively stabilize the tracking of the target object’s position and size, while the other four tracking models exhibited varying degrees of drift or scaling errors. This phenomenon further confirms the superiority of the proposed model in handling complex scenarios such as deformations, lighting changes, and occlusions. The robust performance of the model provides an effective solution for object tracking tasks in video sequences, particularly when faced with changes in the target’s appearance and environmental interference.
In the experimental study of the “liquor” video sequence, the keyframes at frames 360, 728, 890, and 1504 were selected for in-depth comparative analysis. As shown in
Figure 19 and
Figure 20, background clutter was particularly prominent in frames 360 and 890, mainly due to the high color similarity and partial overlap between the tracking target and background objects. In frames 728 and 1504, the tracking target encountered significant occlusions and even completely left the field of view at certain moments, further increasing the complexity of the tracking task. Nevertheless, the PCA-T model exhibited excellent performance in handling these complex scenarios. Compared to other deep learning models, the PCA-T model was more effective in dealing with background clutter and situations where the target left the field of view. Although there were inevitable errors during the tracking process, overall, the model successfully completed the continuous tracking of the target. This result not only validates the effectiveness of the PCA-T model in dealing with such complex video sequences but also provides strong theoretical support and practical guidance for future applications in similar scenarios.
In summary, this study conducted a comprehensive performance evaluation of the PCA-T model by comparing it with five top tracking models and verifying its tracking capabilities in four video sequences (boy, biker, tiger1, and liquor) from the OTB-100 dataset. The experimental results show that the PCA-T model possesses significant performance advantages in handling various tracking challenges, such as illumination changes, scale changes, occlusions, deformations, and motion blur. Especially in keyframe analysis, the model can more accurately track the target object, maintaining stable tracking effects even when the target’s appearance features undergo significant changes or the camera conditions change drastically.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}