
LSCD-Pose: A Feature Point Detection Model for Collaborative Perception in Airports


Abstract
1. Introduction
- We first developed a straightforward coordinate conversion method that transforms pixel coordinates into actual coordinates, enabling more precise detection of conflicts occurring on the apron.
- A new network architecture was designed by integrating StemBlock, PShuffle-Block, and DSConv. This combination significantly reduces the model’s parameter count and computational complexity while almost not affecting its accuracy.
- We proposed a novel dynamic detection head for YOLOv8-Pose, which, through the use of shared convolutions, achieves model lightweighting while enhancing the detection head’s positioning and classification capabilities.
2. Methodology
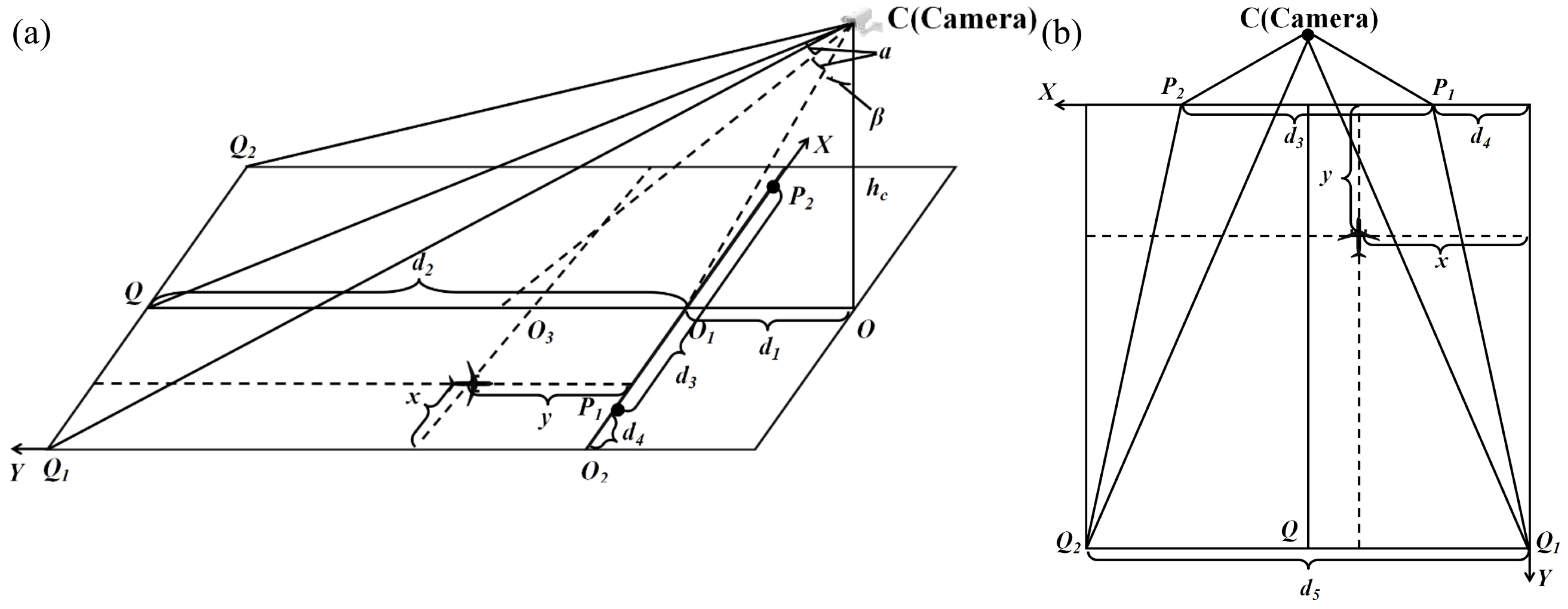
2.1. Problem Definition
2.2. Coordinate Conversion
2.3. Conflict Detection Model Based on Wingtip Keypoint Detection
- (1)
- Two stationary aircraft (Figure 2a): The detection system automatically identifies the target boxes and keypoints of each aircraft, displaying the static alert zones around their wingtips. It locates the pair of wingtips closest to each other. If these static alert zones overlap, the system immediately issues an alert signal; if they do not, no alert is triggered.
- (2)
- One or both aircraft in motion (Figure 2b,c): The system computes aircraft speed based on each aircraft’s motion trajectory. If the gap between wingtips (or between a wingtip and a horizontal stabilizer tip) is shorter than the sum of the minimum safe distance, the distance covered during the reaction time at the current speed, and the full stopping distance, no alert is triggered. Conversely, when wingtip distances fall below the combined reaction and total braking distances, an alert is issued.
3. LSCD-Pose Algorithm
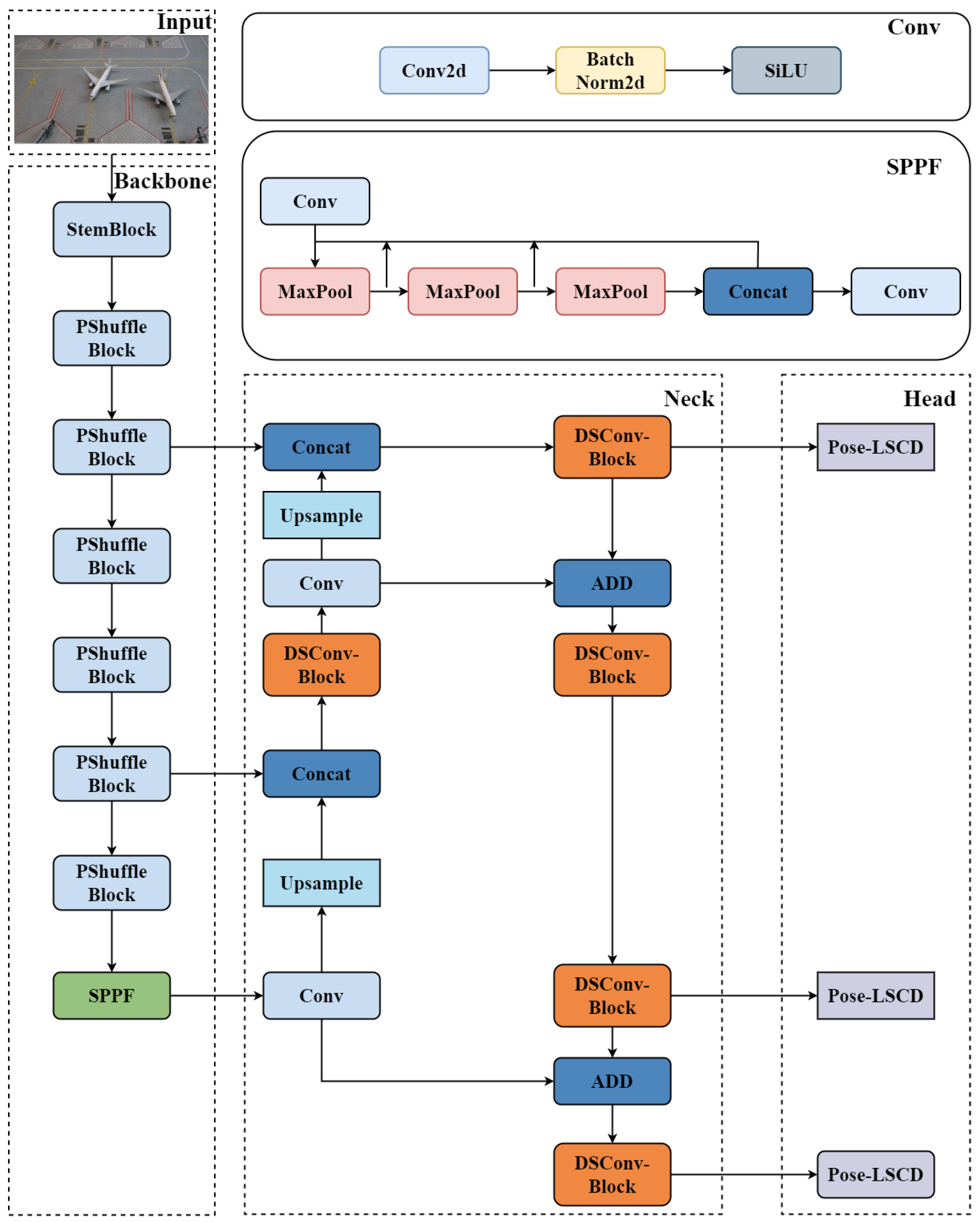
3.1. LSCD-Pose Algorithm
3.2. Pose Estimation Algorithm Based on YOLO
3.2.1. StemBlock
3.2.2. PShuffle-Block
3.2.3. DSConv
3.2.4. LSCD-Pose
4. Results and Analysis
4.1. Experimental Setup
4.2. Dataset and Evaluation Criteria
4.2.1. Dataset
4.2.2. Evaluation Criteria
- Mean Average Precision (mAP): Assesses the accuracy of the algorithm. Its calculation is given in Equation (26). In the experiments, all models exhibited saturated performance under the mAP@50 metric. Therefore, we adopted mAP@50–95 as the primary accuracy evaluation metric to provide a more comprehensive and discriminative assessment of detection performance.
- Frames Per Second (FPS): Reflects the speed of detection by counting the number of frames processed per second.
- Parameters: Indicates the total number of trainable parameters in the network.
- Giga FLOPs (GFLOPS): Represents the computational complexity in billions of floating-point operations per second.
- Detection Success Rate: Probability that the algorithm correctly detects the aircraft whenever it appears.
- Alert Success Rate: Probability of issuing a correct warning whenever a conflict scenario occurs.
- False Positive Rate (FP): Proportion of incorrect detections among all predicted positives.
- False Negative Rate (FN): Proportion of missed detections among all actual positives.
4.3. PShuffleNet vs. ShuffleNet: A Performance Comparison
4.4. Ablation Experiment
4.5. Performance Comparison of Different Keypoint Algorithms
4.6. The Impact of Different Road Surface Types and Braking Conditions on Performance
- Scenario 1: Wet road surface with non-anti-skid braking;
- Scenario 2: Dry road surface with non-anti-skid braking;
- Scenario 3: Wet road surface with anti-skid braking;
- Scenario 4: Dry road surface with anti-skid braking.
4.7. Visualization of Conflict Detection Model Results
5. Conclusions and Challenges
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ICAO. Procedures for Air Navigation Services (PANS)—Air Traffic Management (Doc 4444); Technical Report for International Civil Aviation Organization: Montreal, QC, Canada, 2016. [Google Scholar]
- Tomaszewska, J.; Krzysiak, P.; Zieja, M.; Woch, M. Statistical analysis of ground-related incidents at airports. Pr. Inst. Lotnictwa (Trans. Inst. Aviat.) 2018, 252, 83–93. [Google Scholar] [CrossRef]
- Jaroch, W. The Costs of Ground Damage. Aviation Pros, 13 October 2022. Available online: https://www.aviationpros.com/aircraft/maintenance-providers/article/21279424/the-costs-of-ground-damage (accessed on 10 March 2025).
- Market Research Future. Commercial Airport Radar System Market Research Report: Information by System Type, Radar Technology, Frequency, Application, Deployment Type, Region—Forecast till 2032. Market Research Future: Pune, India, 2023; Available online: https://www.marketresearchfuture.com/reports/commercial-airport-radar-system-market-12486 (accessed on 10 March 2025).
- Liu, W.; Pan, Y.; Fan, Y. A Reactive Deep Learning-Based Model for Quality Assessment in Airport Video Surveillance Systems. Electronics 2024, 13, 749. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Wang, J.; Meng, R.; Huang, Y.; Zhou, L.; Huo, L.; Qiao, Z.; Niu, C. Road defect detection based on improved YOLOv8s model. Sci. Rep. 2024, 14, 16758. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Zhang, Q.; Xing, J.; Cheng, M.; Yu, H.; Ren, Y.; Xiong, X. AdvSwap: Covert Adversarial Perturbation with High Frequency Info-swapping for Autonomous Driving Perception. In Proceedings of the 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC), Edmonton, Canada, 24–27 September 2024; pp. 1686–1693. [Google Scholar]
- Lyu, Z.; Zhang, Y. A novel temporal moment retrieval model for apron surveillance video. Comput. Electr. Eng. 2023, 107, 108616. [Google Scholar] [CrossRef]
- Zhou, W.; Cai, C.; Zheng, L.; Li, C.; Zeng, D. ASSD-YOLO: A small object detection method based on improved YOLOv7 for airport surface surveillance. Multimed Tools Appl. 2023, 83, 55527–55548. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, H.; Bai, X.; Cai, X.; Yu, H.; Ren, Y. Biomimetic Multi-UAV Swarm Exploration with U2U Communications Under Resource Constraints. IEEE Trans. Veh. Technol. 2025. [Google Scholar] [CrossRef]
- Tian, C.; Tian, S.; Kang, Y.; Wang, H.; Tie, J.; Xu, S. RASLS: Reinforcement Learning Active SLAM Approach with Layout Semantic. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Thai, P.; Alam, S.; Lilith, N.; Nguyen, B.T. A computer vision framework using Convolutional Neural Networks for airport-airside surveillance. Transp. Res. Part Emerg. Technol. 2022, 137, 103590. [Google Scholar] [CrossRef]
- Shen, C.; Hengel, A.V.D.; Dick, A. Probabilistic Multiple Cue Integration for Particle Filter Based Tracking; Technical Report 817; Department of Computer Science, University of Rochester: Rochester, NY, USA, 2003. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A Real-Time Object Detection System on Mobile Devices. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- International Civil Aviation Organization. Annex 14 to the Convention on International Civil Aviation: Aerodromes; ICAO: Montreal, QC, Canada, 2004. [Google Scholar]
- Binias, B.; Myszor, D.; Palus, H.; Cyran, K.A. Prediction of Pilot’s Reaction Time Based on EEG Signals. Front. Neuroinformatics 2020, 14, 6. [Google Scholar] [CrossRef] [PubMed]
- Federal Aviation Administration. Brakes and Braking Systems Certification Tests and Analysis. Advisory Circular AC 25.735-1; U.S. Department of Transportation, Federal Aviation Administration: Washington, DC, USA, 2002. Available online: https://www.faa.gov/regulations_policies/advisory_circulars/index.cfm/go/document.information/documentID/22664 (accessed on 11 March 2025).
- Wang, C.Y.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information; Springer: Cham, Switzerland, 2024. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO11. Software; Ultralytics: Los Angeles, CA, USA, 2024; Available online: https://github.com/ultralytics/ultralytics (accessed on 11 March 2025).
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 5693–5703. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 19–25 June 2021; pp. 10440–10450. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10096–10105. [Google Scholar]
- Jiang, T.; Lu, P.; Zhang, L.; Ma, N.; Han, R.; Lyu, C.; Li, Y.; Chen, K. Rtmpose: Real-time multi-person pose estimation based on mmpose. arXiv 2023, arXiv:2303.07399. [Google Scholar]
- Zhang, T.; Zhu, X.; Li, J.; Chen, H.; Li, Z. Research on conflict detection model for taxi-in process on the apron based on aircraft wingtip keypoint detection. IET Intell. Transp. Syst. 2023, 17, 878–896. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | mAP@50-95 | Module Size (M) | Para (M) | GFLOPs | FPS |
|---|---|---|---|---|---|
| None | 0.975 | 6.3 | 3.09 | 8.4 | 194.5 |
| +ShuffleNetv1 | 0.963 | 1.5 | 0.29 | 6.7 | 211.8 |
| +ShuffleNetv2 | 0.974 | 1.6 | 0.31 | 5.1 | 208.5 |
| +PShuffleNet | 0.977 | 1.6 | 0.33 | 4.7 | 217.1 |
| StemBlock | PShuffle- Block | DSConv- Block | LSCD- Pose | mAP@50-95 | Module Size | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| 0.975 | 6.3 | 3.09 | 8.4 | 194.5 | ||||
| √ | 0.933 | 6.2 | 3.09 | 2.2 | 388.8 | |||
| √ | 0.977 | 1.6 | 0.33 | 4.7 | 217.1 | |||
| √ | 0.974 | 3.9 | 1.84 | 6.3 | 290.7 | |||
| √ | 0.976 | 4.9 | 2.38 | 6.7 | 253.6 | |||
| √ | √ | 0.936 | 1.0 | 0.30 | 2.3 | 391.6 | ||
| √ | √ | 0.972 | 4.8 | 2.38 | 1.7 | 399.4 | ||
| √ | √ | √ | 0.903 | 0.8 | 0.20 | 1.2 | 419.2 | |
| √ | √ | √ | 0.941 | 0.7 | 0.18 | 1.6 | 366.2 | |
| √ | √ | √ | √ | 0.956 | 0.6 | 0.11 | 1.5 | 461.7 |
| Module | mAP50-95 | Module Size (M) | Para (M) | GFLOPs | FPS |
|---|---|---|---|---|---|
| YOLOv8n-Pose | 0.975 | 6.3 | 3.09 | 8.4 | 194.5 |
| YOLOv8s-Pose | 0.987 | 23.3 | 11.41 | 29.4 | 101.1 |
| YOLOv8m-Pose | 0.981 | 53.4 | 26.40 | 80.8 | 39.5 |
| YOLOv8l-Pose | 0.983 | 89.5 | 44.59 | 168.5 | 23.7 |
| YOLOv8x-Pose | 0.986 | 139.6 | 69.45 | 263.2 | 13.1 |
| YOLOv9u-Pose | 0.986 | 65.4 | 3.23 | 122.4 | 46.9 |
| YOLOv9c-Pose | 0.986 | 53.5 | 26.30 | 107.4 | 21.9 |
| YOLOv9e-Pose | 0.981 | 119.1 | 59.00 | 196.4 | 17.5 |
| Ours | 0.956 | 0.6 | 0.11 | 1.5 | 461.7 |
| Algorithms | mAP@50-95 | Module Size (M) | Para (M) | GFLOPs | FPS |
|---|---|---|---|---|---|
| YOLO-Pose | 0.947 | 3.9 | 14.35 | 20.40 | 69.52 |
| YOLOv7-Pose | 0.971 | 74.9 | 76.41 | 102.10 | 84.39 |
| YOLOv8-Pose | 0.975 | 6.3 | 3.09 | 8.40 | 194.5 |
| YOLOv9-Pose | 0.986 | 65.4 | 3.23 | 122.40 | 46.9 |
| YOLOv11-Pose [22] | 0.979 | 6.0 | 2.91 | 7.60 | 136.99 |
| YOLOv12-Pose [23] | 0.963 | 5.3 | 2.59 | 6.51 | 138.89 |
| ShuffleNetV1 [29] | 0.995 | 441.9 | 6.94 | 1.34 | 47.06 |
| ShuffleNetV2 [24] | 0.995 | 83.8 | 7.55 | 1.36 | 85.18 |
| HRNet [30] | 0.995 | 344.2 | 28.50 | 7.68 | 42.56 |
| LiteHRNet [31] | 0.997 | 23.6 | 1.76 | 0.43 | 50.86 |
| ResNet50 [32] | 0.989 | 408.9 | 34.00 | 5.44 | 5.64 |
| ResNetv1d50 [33] | 0.997 | 408.9 | 34.01 | 5.68 | 47.16 |
| ResNext50 [34] | 0.998 | 432.2 | 33.47 | 5.59 | 45.05 |
| SeresNet [35] | 0.995 | 441.9 | 36.53 | 5.45 | 44.31 |
| HRformer [36] | 0.997 | 522.9 | 43.21 | 14.10 | 11.5 |
| Srcnet [37] | 0.813 | 432.6 | 34.00 | 5.29 | 30.30 |
| RTMPose [38] | 0.995 | 212.4 | 13.17 | 1.90 | 275.85 |
| Ours | 0.956 | 0.6 | 0.11 | 1.50 | 461.7 |
| Pavement Surface/Brake Condition | Anti-Skid Brakes | Non-Anti-Skid Brakes |
|---|---|---|
| Dry pavement | : 0.94/: 0.8 | : 0.9/: 0.3 |
| Wet pavement | : 0.81/: 0.8 | : 0.81/: 0.3 |
| Aircraft Speed (m/s) | Detection Success Rate (%) | False Positives (%) | False Negatives (%) | Alert Success Rate (%) |
|---|---|---|---|---|
| Scene 1 (Single-Aircraft Motion) | ||||
| 0.5 | 99.13 | 1.02 | 0.51 | 98.51 |
| 1.0 | 98.77 | 1.39 | 0.80 | 98.21 |
| 1.5 | 98.02 | 1.51 | 1.03 | 97.80 |
| Scene 2 (Two-Aircraft Motion) | ||||
| 0.5 | 98.11 | 2.17 | 1.52 | 97.04 |
| 1.0 | 98.59 | 2.23 | 1.38 | 96.53 |
| 1.5 | 97.73 | 2.86 | 1.82 | 97.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, R.; Wang, J.; Huang, Y.; Xue, Z.; Hu, Y.; Li, B. LSCD-Pose: A Feature Point Detection Model for Collaborative Perception in Airports. Sensors 2025, 25, 3176. https://doi.org/10.3390/s25103176
Meng R, Wang J, Huang Y, Xue Z, Hu Y, Li B. LSCD-Pose: A Feature Point Detection Model for Collaborative Perception in Airports. Sensors. 2025; 25(10):3176. https://doi.org/10.3390/s25103176
Chicago/Turabian StyleMeng, Ruifeng, Jinlei Wang, Yuanhao Huang, Zhaofeng Xue, Yihao Hu, and Biao Li. 2025. "LSCD-Pose: A Feature Point Detection Model for Collaborative Perception in Airports" Sensors 25, no. 10: 3176. https://doi.org/10.3390/s25103176
APA StyleMeng, R., Wang, J., Huang, Y., Xue, Z., Hu, Y., & Li, B. (2025). LSCD-Pose: A Feature Point Detection Model for Collaborative Perception in Airports. Sensors, 25(10), 3176. https://doi.org/10.3390/s25103176