

AS-TBR: An Intrusion Detection Model for Smart Grid Advanced Metering Infrastructure
Abstract
1. Introduction
- To address the issue of class imbalance in network traffic data, the Adaptive Synthetic Sampling (ADASYN) technique is introduced. By dynamically sampling minority class instances, the model’s performance in detecting minority class samples is improved, enhancing the robustness of intrusion detection.
- The Transformer encoder is employed to capture global temporal dependencies, leveraging the self-attention mechanism to dynamically adjust the weights of critical features, thereby further improving the detection accuracy and response speed of the model.
- A spatiotemporal feature extraction module combining BiGRU and ResNet is designed. BiGRU is used to model bidirectional temporal features, while ResNet is utilized to extract deep spatial features, enhancing the model’s ability to recognize complex attack patterns.
2. Related Work
3. Proposed Method
3.1. ADASYN
3.2. Transformer Encoder
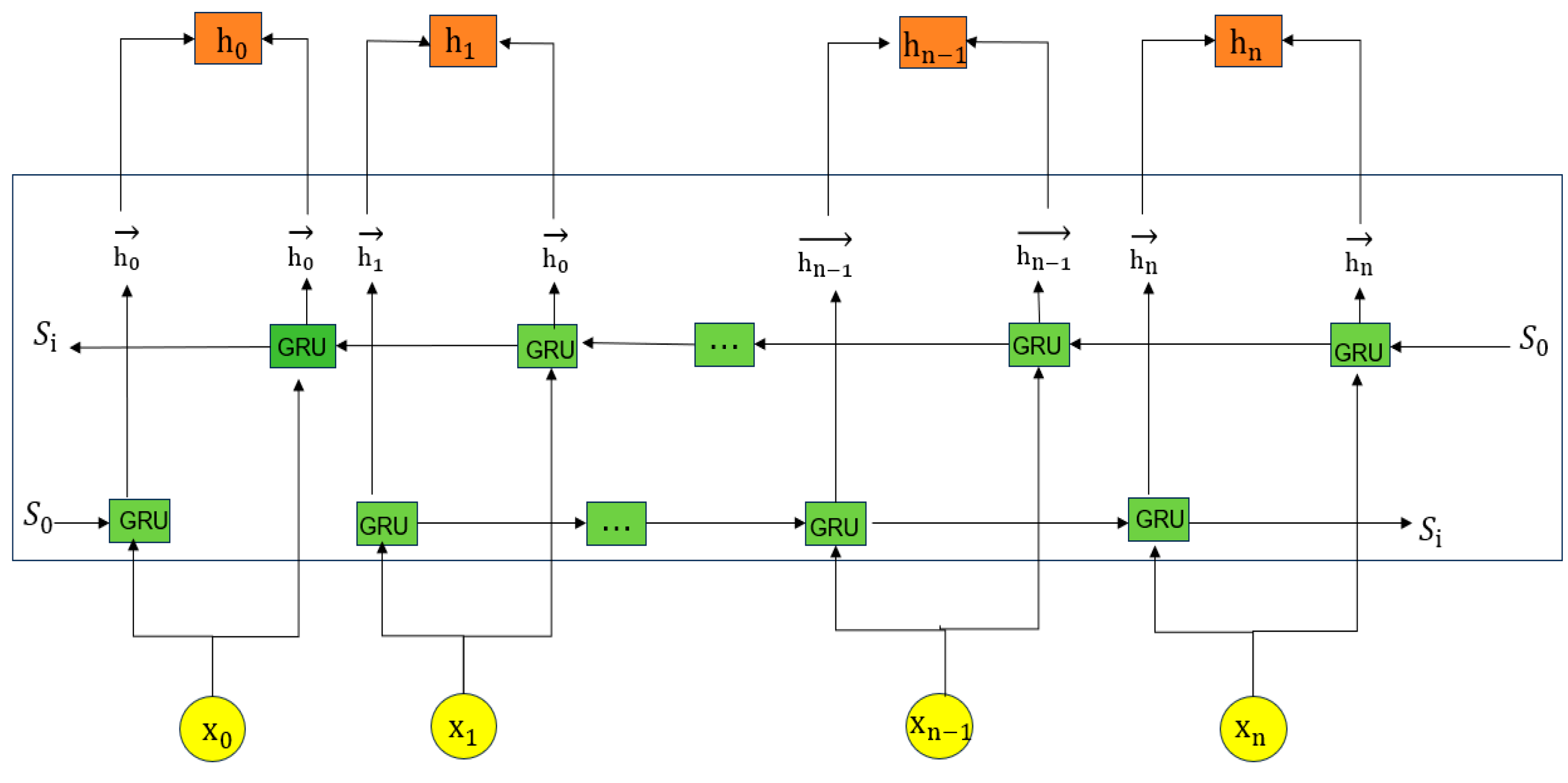
3.3. BiGRU
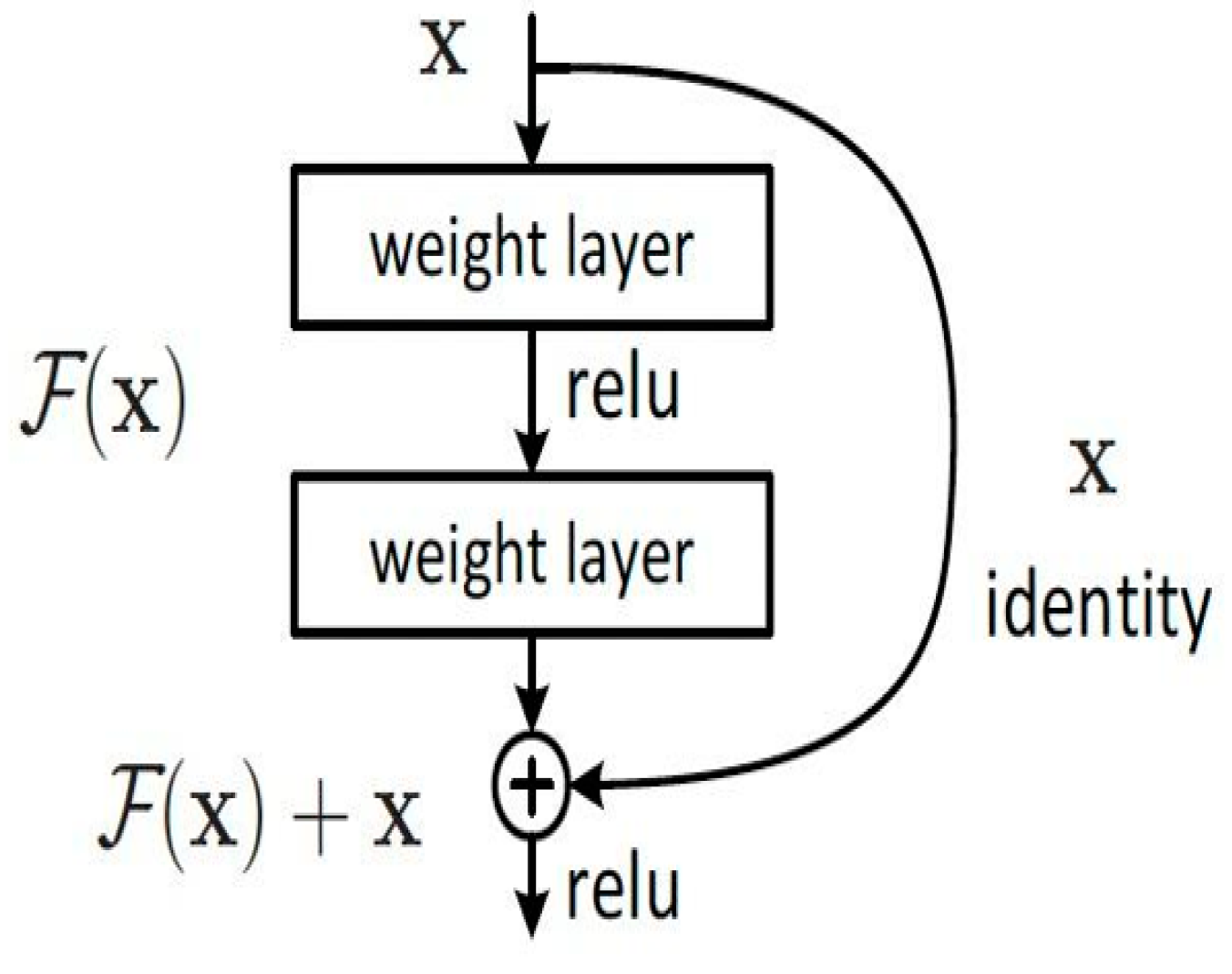
3.4. Residual Network
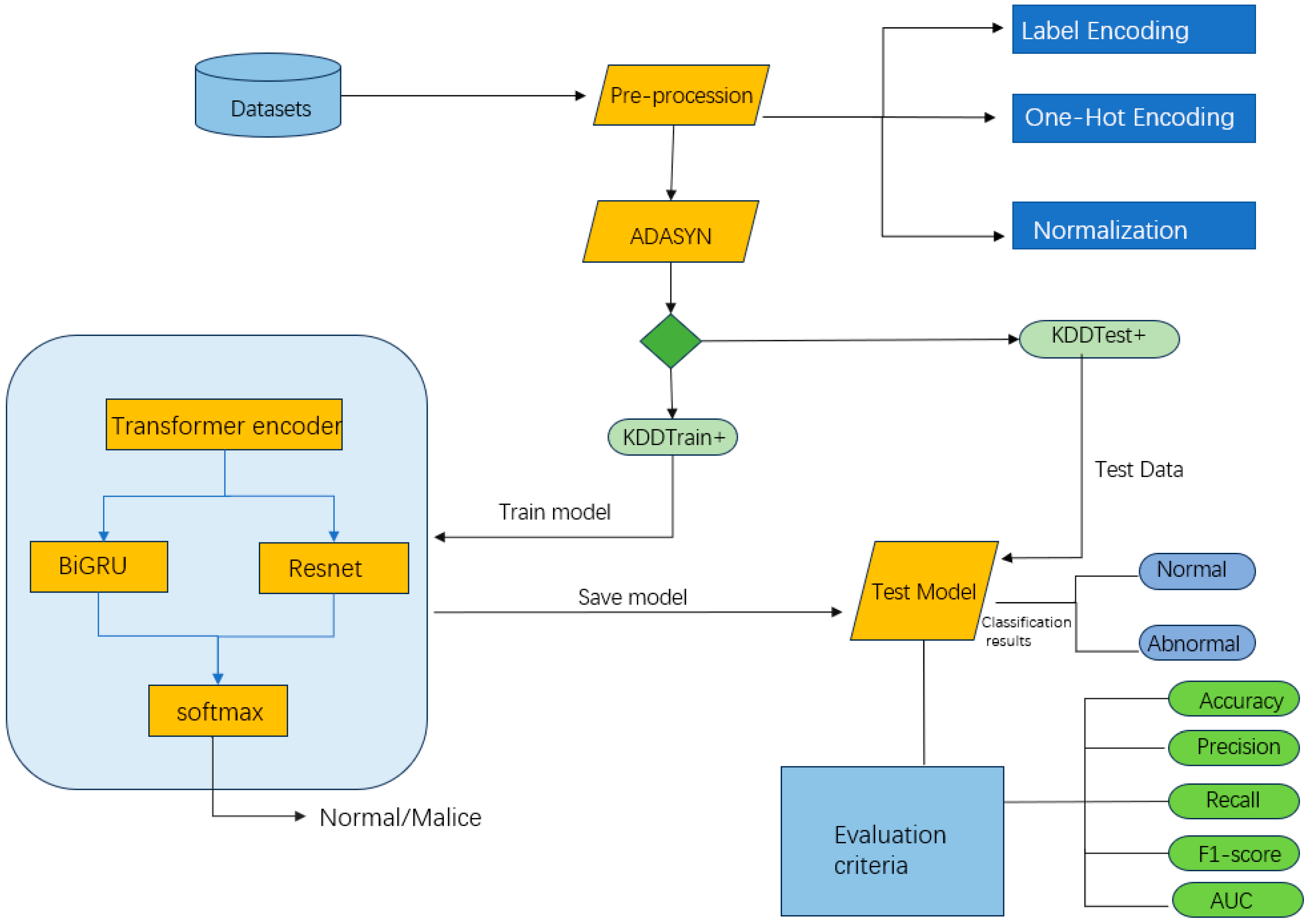
3.5. AS-TBR Intrusion Detection Model
4. Experimental Setup and Preparation
4.1. Dataset
4.2. Experimental Environment and Parameter Settings
4.3. Data Preprocessing
- (1)
- Numericalization
- (2)
- Normalization
4.4. Data Balancing
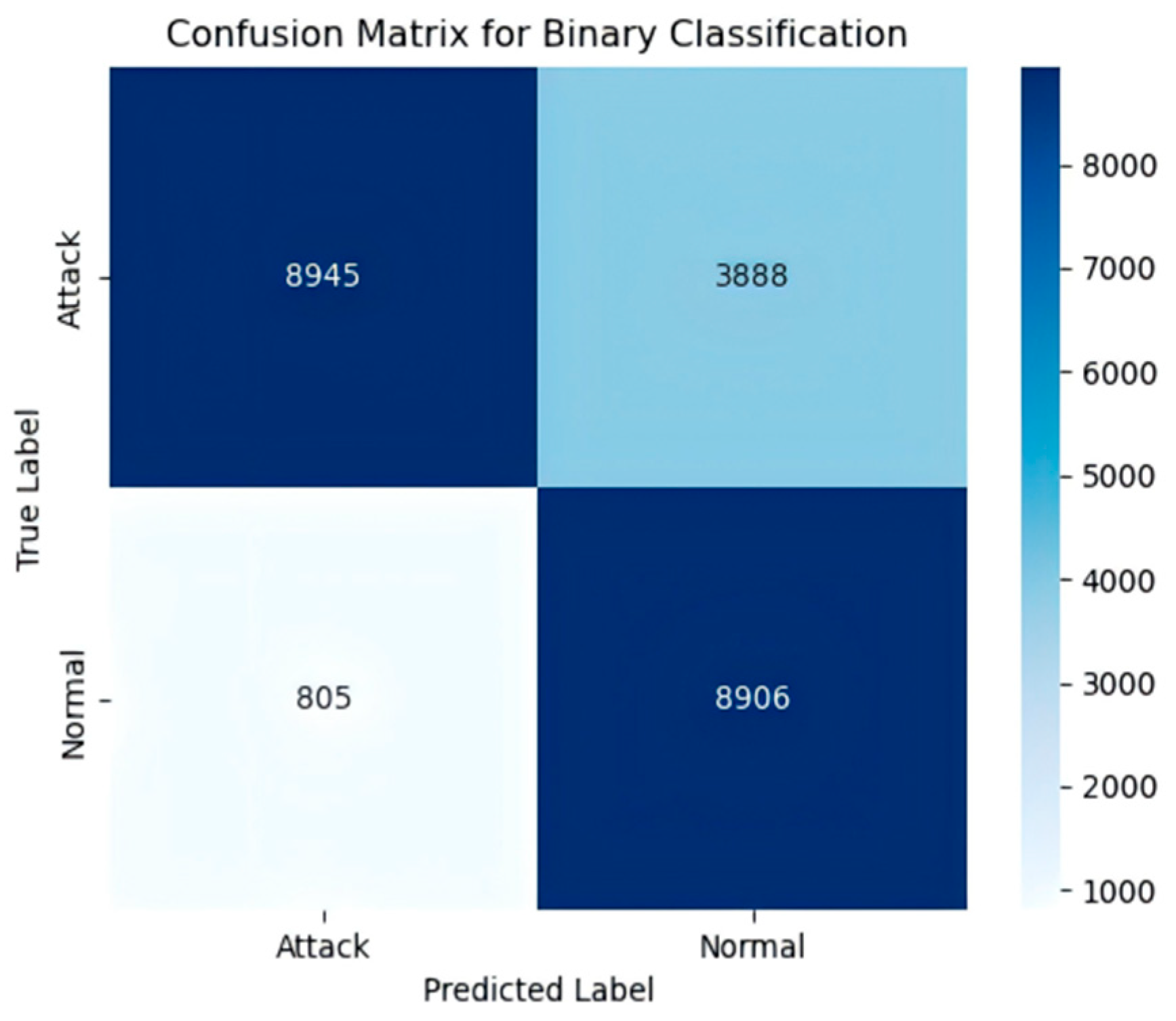
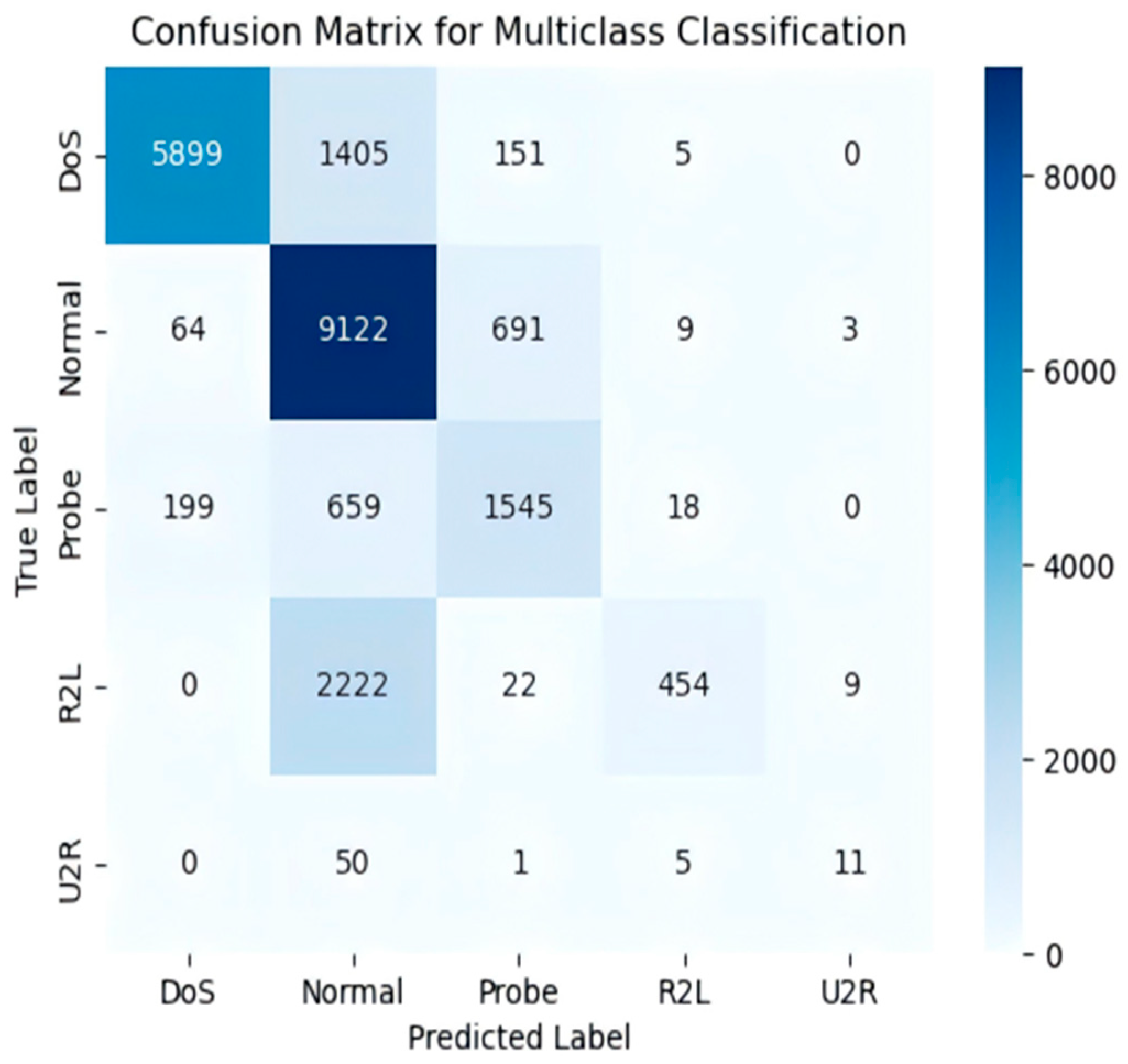
4.5. Evaluation Metrics
- (1)
- Accuracy
- (2)
- Precision
- (3)
- Recall
- (4)
- F1-Score
- (5)
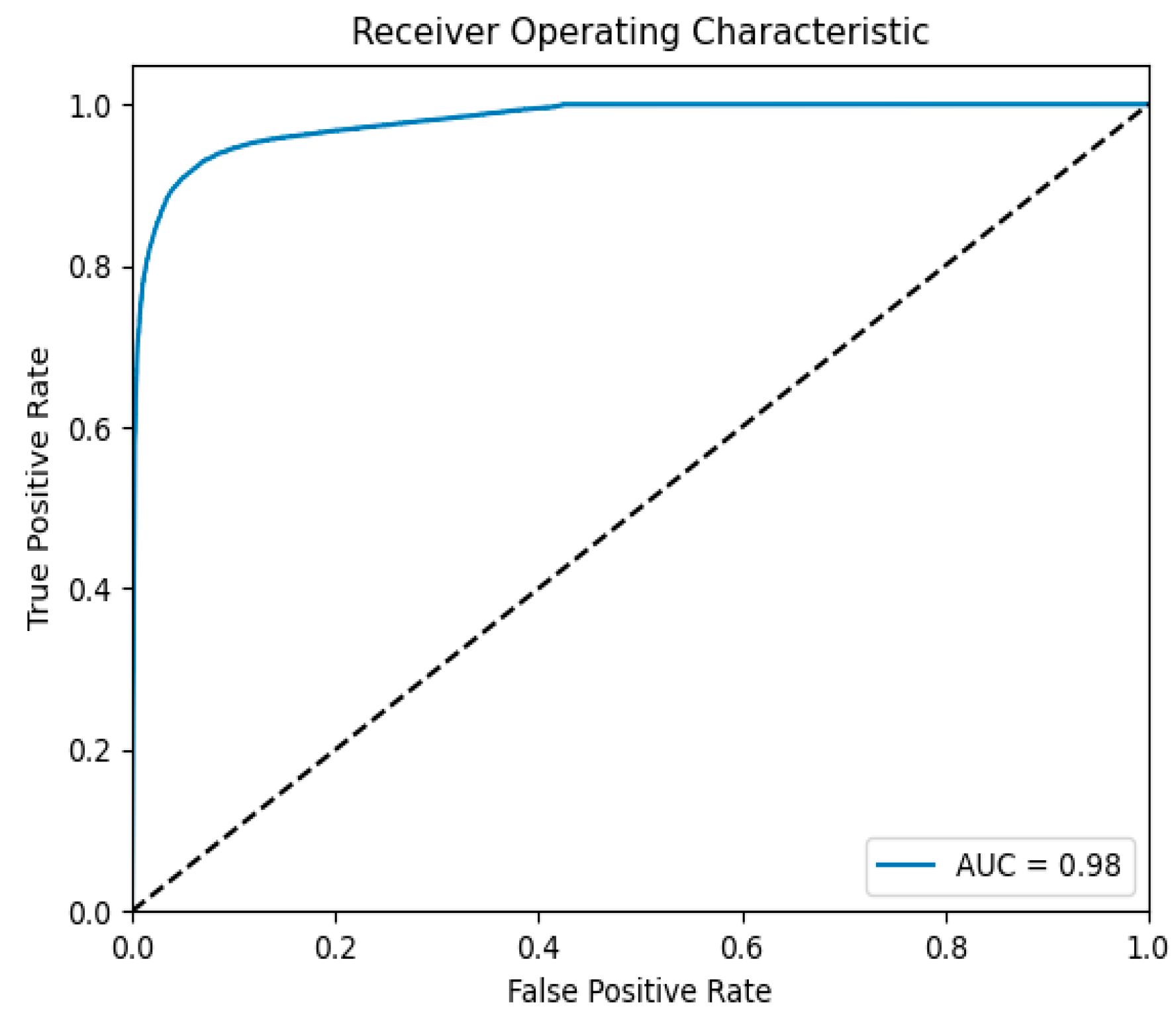
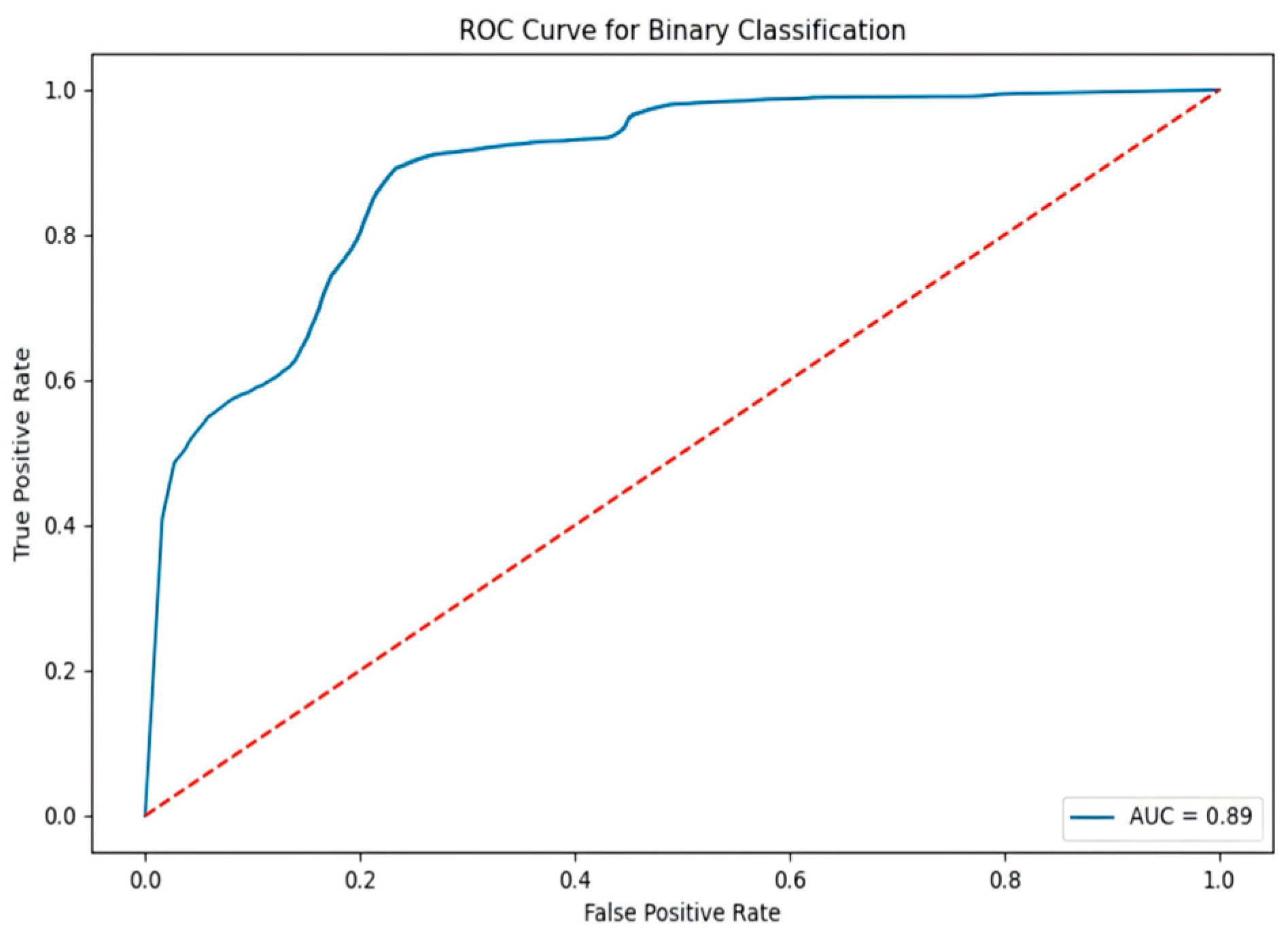
- ROC Curve and AUC Value
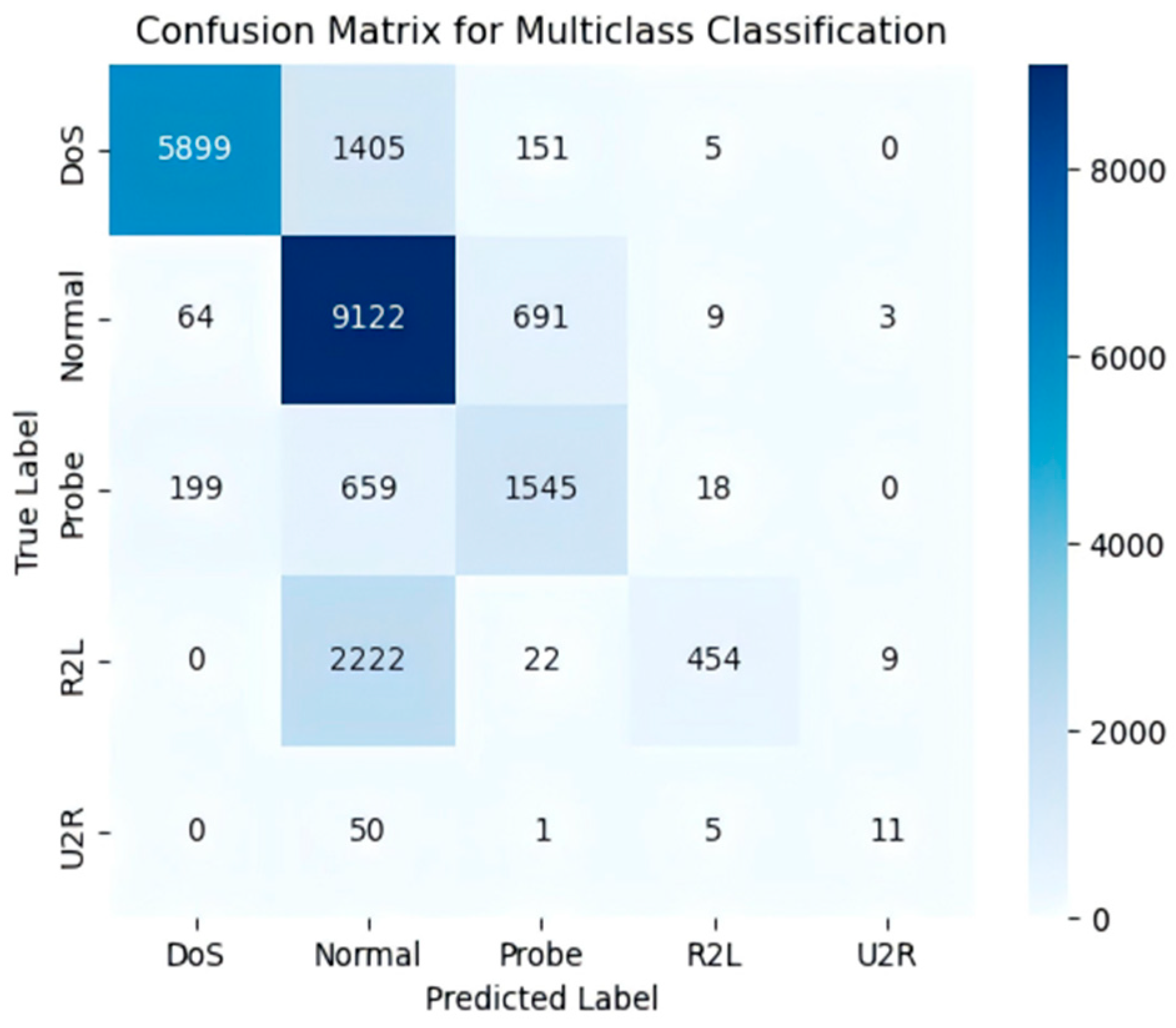
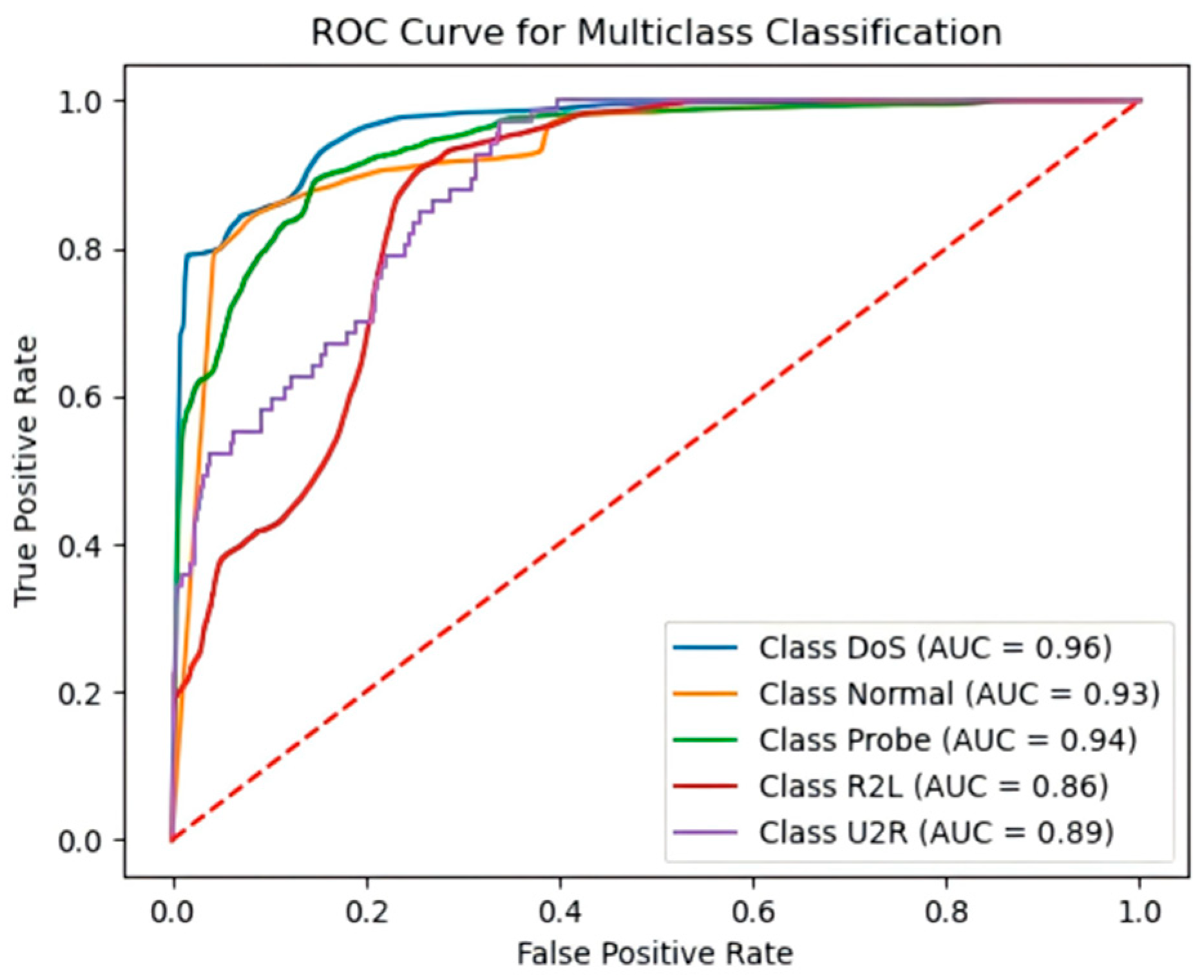
4.6. Model Performance
4.7. Comparison Between the Proposed Model and Other Models
4.8. Ablation Experiment
| Model | Accuracy |
| Transformer + BiGRU + Resnet | 93.00% |
| BiGRU + Resnet | 75.55% |
| Transformer + Resnet | 84.60% |
| Transformer + BiGRU | 89.50% |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liang, H.; Liu, D.; Zeng, X.; Ye, C. An Intrusion Detection Method for Advanced Metering Infrastructure System Based on Federated Learning. J. Mod. Power Syst. Clean Energy 2023, 11, 927–937. [Google Scholar] [CrossRef]
- Raja, D.J.S.; Sriranjani, R.; Arulmozhi, P.; Hemavathi, N. Unified Random Forest and Hybrid Bat Optimization Based Man-in-the-Middle Attack Detection in Advanced Metering Infrastructure. IEEE Trans. Instrum. Meas. 2024, 73, 2523812. [Google Scholar]
- Satilmiş, H.; Akleylek, S.; Tok, Z.Y. A Systematic Literature Review on Host-Based Intrusion Detection Systems. IEEE Access 2024, 12, 27237–27266. [Google Scholar] [CrossRef]
- Dou, Z.; Chen, X.; Zhu, L.; Zheng, X.; Chen, X.; Xue, J.; Niwayama, S.; Ni, Y.; Xu, G. Enhanced Stereodivergent Evolution of Carboxylesterase for Efficient Kinetic Resolution of Near-Symmetric Esters Through Machine Learning. Nat. Commun. 2024, 15, 9057. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Lu, S. An Effective Intrusion Detection Approach Using SVM with Naïve Bayes Feature Embedding. Comput. Secur. 2021, 103, 102158. [Google Scholar] [CrossRef]
- Chin, Y.S.; Tan, C.K.; Tan, W.N.; Gan, M.T.; Bakar, A.H. Energy Theft and Defective Meters Detection in AMI Using Linear Regression. In Proceedings of the 2017 IEEE International Conference on Environment and Electrical Engineering and 2017 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Milan, Italy, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Madhavi, M.; Nethravathi, D.R. Gradient Boosted Decision Tree (GBDT) and Grey Wolf Optimization (GWO) Based Intrusion Detection Model. J. Theor. Appl. Inf. Technol. 2022, 100, 4937–4951. [Google Scholar]
- Wu, K.; Chen, Z.; Li, W. A Novel Intrusion Detection Model for a Massive Network Using Convolutional Neural Networks. IEEE Access 2018, 6, 50850–50859. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A Bidirectional LSTM Deep Learning Approach for Intrusion Detection. Expert Syst. Appl. 2021, 185, 115524. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An Intrusion Detection System Using a Deep Neural Network with Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Li, L.; Hu, M.; Ren, F.; Xu, H. Temporal Attention Based TCN-BiGRU Model for Energy Time Series Forecasting. In Proceedings of the 2021 IEEE International Conference on Computer Science, Artificial Intelligence and Electronic Engineering (CSAIEE), Virtual, 20–22 August 2021; pp. 187–193. [Google Scholar]
- Giuseppina, A.; Annalisa, A.; Luca, R.D. GAN augmentation to deal with imbalance in imaging-based intrusion detection. Future Gener. Comput. Syst. 2021, 123, 108–127. [Google Scholar]
- Yao, R.; Wang, N.; Liu, Z.; Chen, P.; Ma, D.; Sheng, X. Intrusion detection system in the smart distribution network: A feature engineering based AE-Light-GBM approach. Energy Rep. 2021, 7, 353–361. [Google Scholar] [CrossRef]
- Sathish, N.; Valarmathi, K. Detection of Intrusion Behavior in Cloud Applications Using Pearson’s Chi-Squared Distribution and Decision Tree Classifiers. Pattern Recognit. Lett. 2022, 162, 15–21. [Google Scholar]
- Zhu, L.; Zhou, X.; Zhang, C. Rapid Identification of High-Quality Marine Shale Gas Reservoirs Based on the Oversampling Method and Random Forest Algorithm. Artif. Intell. Geosci. 2021, 2, 76–81. [Google Scholar] [CrossRef]
- Manimurugan, S. IoT-Fog-cloud model for anomaly detection using improved naïve Bayes and principal component analysis. J. Ambient. Intell. Humaniz. Comput. 2021, 1–10. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, W.; Wang, A.; Wu, H. Network intrusion detection combined hybrid sampling with deep hierarchical network. IEEE Access 2020, 8, 32464–32476. [Google Scholar] [CrossRef]
- Sathya, R.; Thangarajan, R. Efficient anomaly detection and mitigation in software defined networking environment. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 479–484. [Google Scholar]
- Gupta, N.; Jindal, V.; Bedi, P. LIO-IDS: Handling class imbalance using LSTM and improved one-vs-one technique in intrusion detection system. Comput. Netw. 2021, 192, 108076. [Google Scholar] [CrossRef]
- Huang, S.; Lei, K. IGAN-IDS: An imbalanced generative adversarial network towards intrusion detection system in ad-hoc networks. Ad Hoc Netw. 2020, 105, 102177. [Google Scholar] [CrossRef]
- Cai, Y.; Liao, G. Network intrusion detection based on improved denoising autoencoder model. Comput. Technol. Dev. 2023, 33, 119–124. [Google Scholar]
- Chouhan, N.; Khan, A. Network anomaly detection using channel boosted and residual learning based deep convolutional neural network. Appl. Soft Comput. 2019, 83, 105612. [Google Scholar] [CrossRef]
- Geiger, A.; Liu, D.; Alnegheimish, S.; Cuesta-Infante, A.; Veeramachaneni, K. Tad GAN: Time series anomaly detection using generative adversarial networks. In Proceedings of the IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE Press: Piscataway, NJ, USA, 2020; pp. 33–43. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Version |
|---|---|
| Batch Size | 32 |
| Epochs | 100 |
| Hidden Dim | 128 |
| Criterion | BCELoss |
| Optimizer | Adam |
| Learning Rate | 0.001 |
| Category | Precision | Recall | F1-Score |
|---|---|---|---|
| Attack | 0.95 | 0.92 | 0.93 |
| Normal | 0.91 | 0.94 | 0.92 |
| Accuracy | 0.93 | ||
| Macro avg | 0.93 | 0.93 | 0.93 |
| Weighted avg | 0.93 | 0.93 | 0.93 |
| Category | Precision | Recall | F1-Score |
|---|---|---|---|
| Attack | 0.92 | 0.70 | 0.79 |
| Normal | 0.70 | 0.92 | 0.79 |
| Accuracy | 0.80 | ||
| Macro avg | 0.81 | 0.81 | 0.79 |
| Weighted avg | 0.81 | 0.79 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, H.; Fan, Y.; Zhang, Y. AS-TBR: An Intrusion Detection Model for Smart Grid Advanced Metering Infrastructure. Sensors 2025, 25, 3155. https://doi.org/10.3390/s25103155
Ma H, Fan Y, Zhang Y. AS-TBR: An Intrusion Detection Model for Smart Grid Advanced Metering Infrastructure. Sensors. 2025; 25(10):3155. https://doi.org/10.3390/s25103155
Chicago/Turabian StyleMa, Hao, Yifan Fan, and Yiying Zhang. 2025. "AS-TBR: An Intrusion Detection Model for Smart Grid Advanced Metering Infrastructure" Sensors 25, no. 10: 3155. https://doi.org/10.3390/s25103155
APA StyleMa, H., Fan, Y., & Zhang, Y. (2025). AS-TBR: An Intrusion Detection Model for Smart Grid Advanced Metering Infrastructure. Sensors, 25(10), 3155. https://doi.org/10.3390/s25103155