CSSA-YOLO: Cross-Scale Spatiotemporal Attention Network for Fine-Grained Behavior Recognition in Classroom Environments


Abstract
1. Introduction
- Feature Extraction Enhancement: The Swin Transformer architecture is incorporated into the C2f module, which improves feature representation flexibility and cross-scale correlations through the window-based multi-head self-attention (W-MSA) mechanism.
- Background Interference Suppression: The Shuffle Attention (SA) module is embedded within the neck network, utilizing a channel segmentation and recombination strategy to focus dynamically on the target area and mitigate complex background noise.
- Loss Function Optimization: We replace the original YOLOv8 Complete-IoU (CIoU) loss with a dynamic focusing weight, Wise-IoU (WIoU). This enhances boundary box regression accuracy and accelerates network convergence through a gradient allocation mechanism based on detection quality.
- Empirical Validation: The proposed method increases precision by 2.3% in dense scenes over the baseline model, outperforming existing mainstream algorithms and offering a reliable basis for evaluating PBL-based teaching.
2. Related Work
- Illumination Variation: Dynamic lighting changes cause shifts in feature distribution.
- Dense Occlusion: In crowded environments, overlapping individuals create biases in local feature extraction.
- Small-Scale Behavior Recognition: The recognition of subtle actions, such as micro-gestures, remains particularly challenging.
2.1. Traditional Classroom Behavior Recognition Techniques
2.2. Deep-Learning-Based Classroom Behavior Recognition Methods
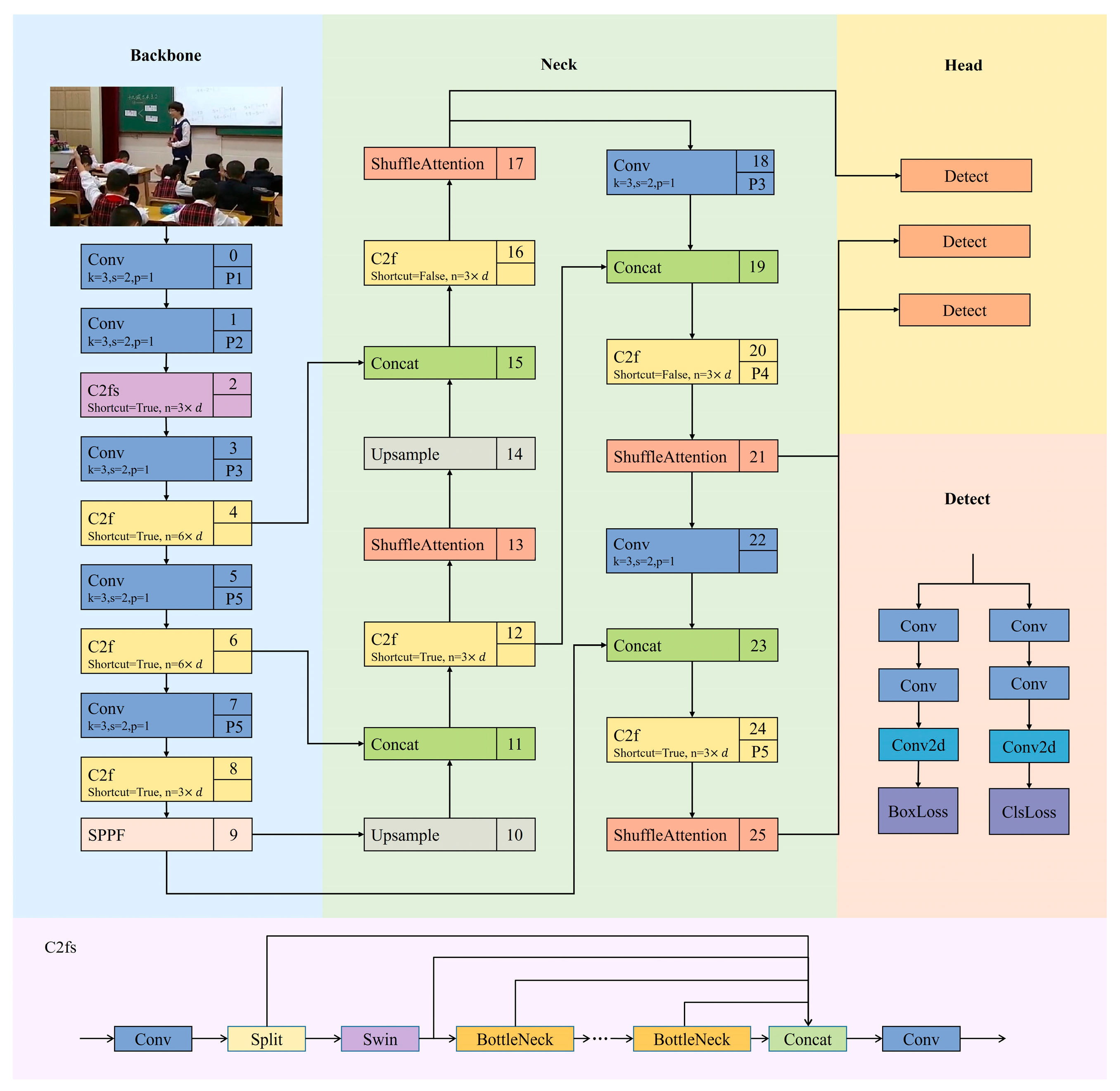
3. Methods
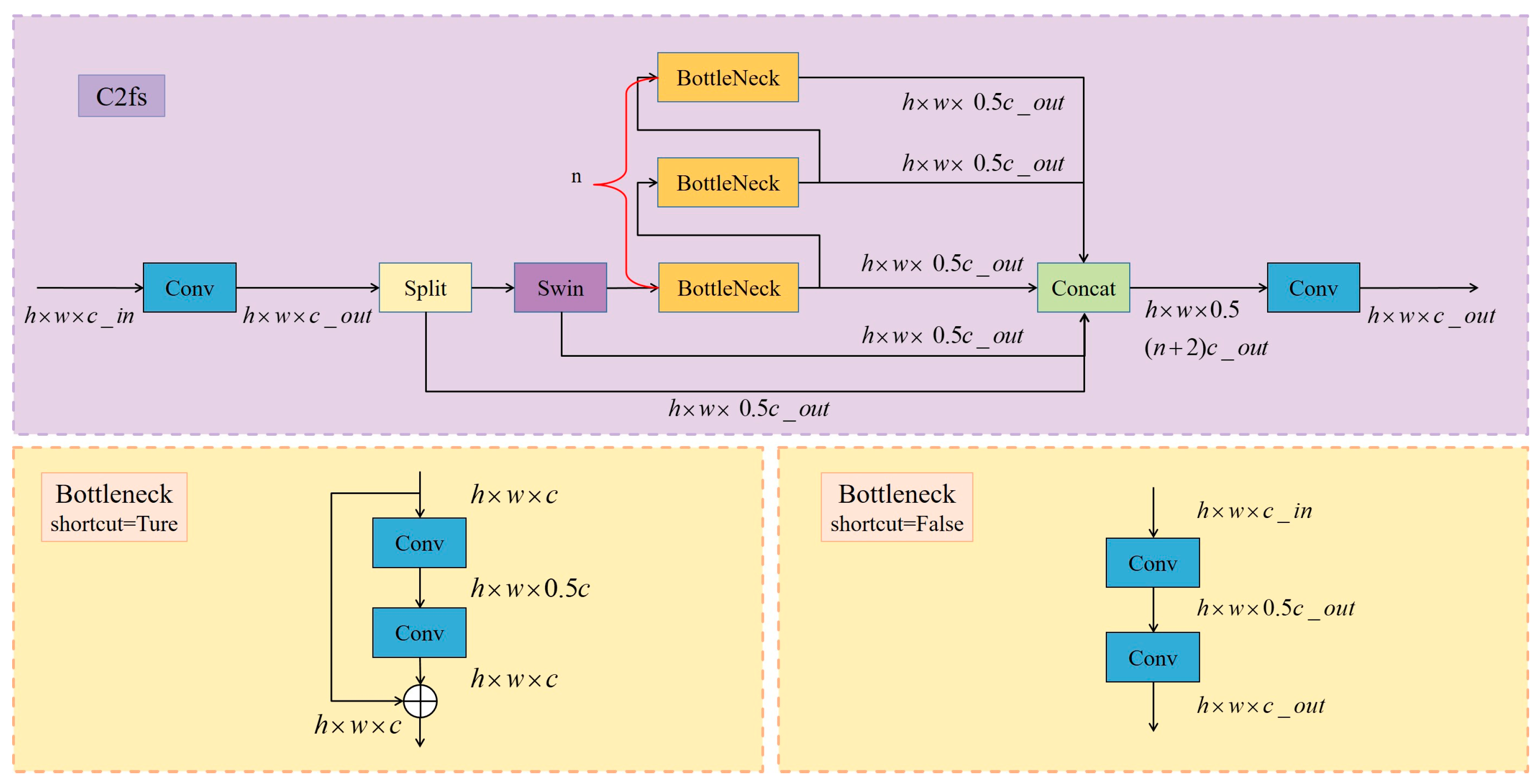
3.1. C2fs
- Preservation Path: One half of the channels bypasses further transformation, retaining raw, high-fidelity information.
- Refinement Path: The other half undergoes a Swin Transformer block to capture long-range dependencies, followed by cascaded Bottleneck modules for local feature enhancement.
| Algorithm 1. C2fs Module’s main learning algorithm |
| Input: Feature tensor Parameters: |
|
| Procedure: |
← List{} //Feature collection
a. Split features: {, } ← Split() //Spatial partition b. Swin-enhanced transformation: Process the first sub-feature using a Swin Transformer block with window size W ← SwinBlock(, W) //Window attention Process the second sub-feature via a bottleneck block ← Bottleneck() //See Algorithm 2 c. Feature fusion: ← Concat(,) ←
Output: |
| Algorithm 2. Shortcut-conditional Bottleneck |
| Input: Parameters:
|
| Procedure: |
← () //Spatial mixing
Y ← + (X) //Residual connection else: Y ←
Output: Y |
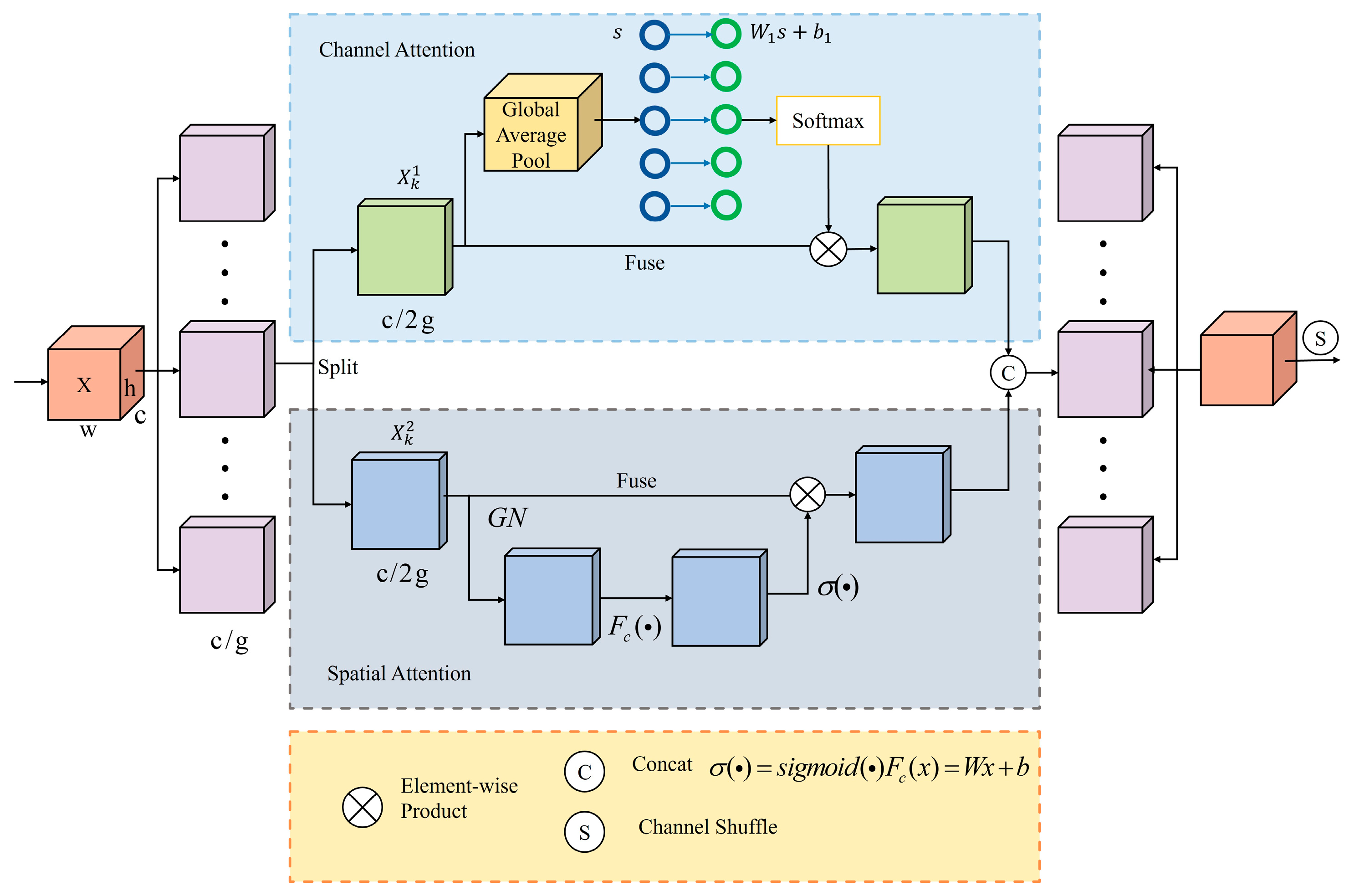
3.2. Shuffle Attention
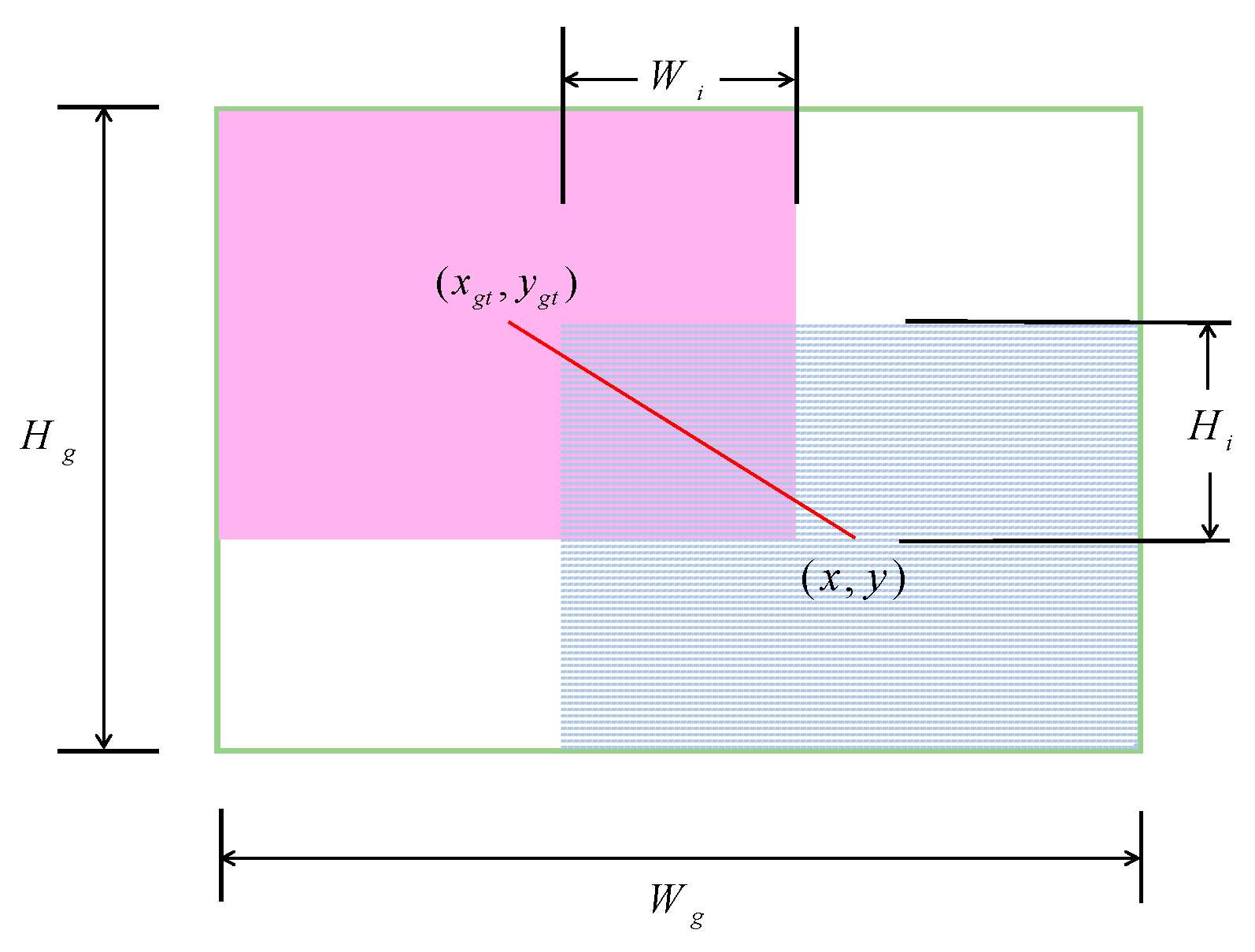
3.3. Bounding Box Regression Loss with a Dynamic Focusing Mechanism
4. Datasets and Experimental Setup
4.1. Datasets
- SCB03-S Classroom Scene Dataset: The SCB03-S dataset encompasses a wide range of classroom environments from kindergarten to high school, featuring small objects under challenging visual conditions. It comprises 5015 images with small objects and 25,810 detailed annotations, focusing on three behaviors: raising hands, reading, and writing. Most of the images in this dataset were originally captured in typical classroom settings, characterized by small target sizes and limited visual cues for distinguishing objects from background clutter, significantly increasing the difficulty of the detection task.
- Classroom Behavior Dataset: The Classroom Behavior Dataset is an open-source object detection collection specifically designed to recognize and classify student behaviors in classroom settings. It includes 4881 images and 12,631 annotations spanning four behavior categories: hand, read, sleep, and write. Images were sourced from various public platforms and capture diverse classroom environments from multiple angles and distances. This diversity provides a robust foundation for evaluating the performance and generalization capabilities of behavior-detection models.
4.2. Experimental Setup
4.3. Evaluation Indicators
- Precision: This metric assesses the ratio of predicted positive samples to all samples detected by the model.
- Recall represents the proportion of correctly predicted positive samples to the total number of positive samples, reflecting the model’s sensitivity.
- The average precision (AP) is equal to the area under the precision–recall curve. The relevant calculation formula is as follows:
- The mean average precision (mAP) is the result of the weighted average of the AP values for all sample classes. It is used to measure the model’s detection performance across all classes. The relevant calculation formula is as follows:
5. Experimental Results and Analysis
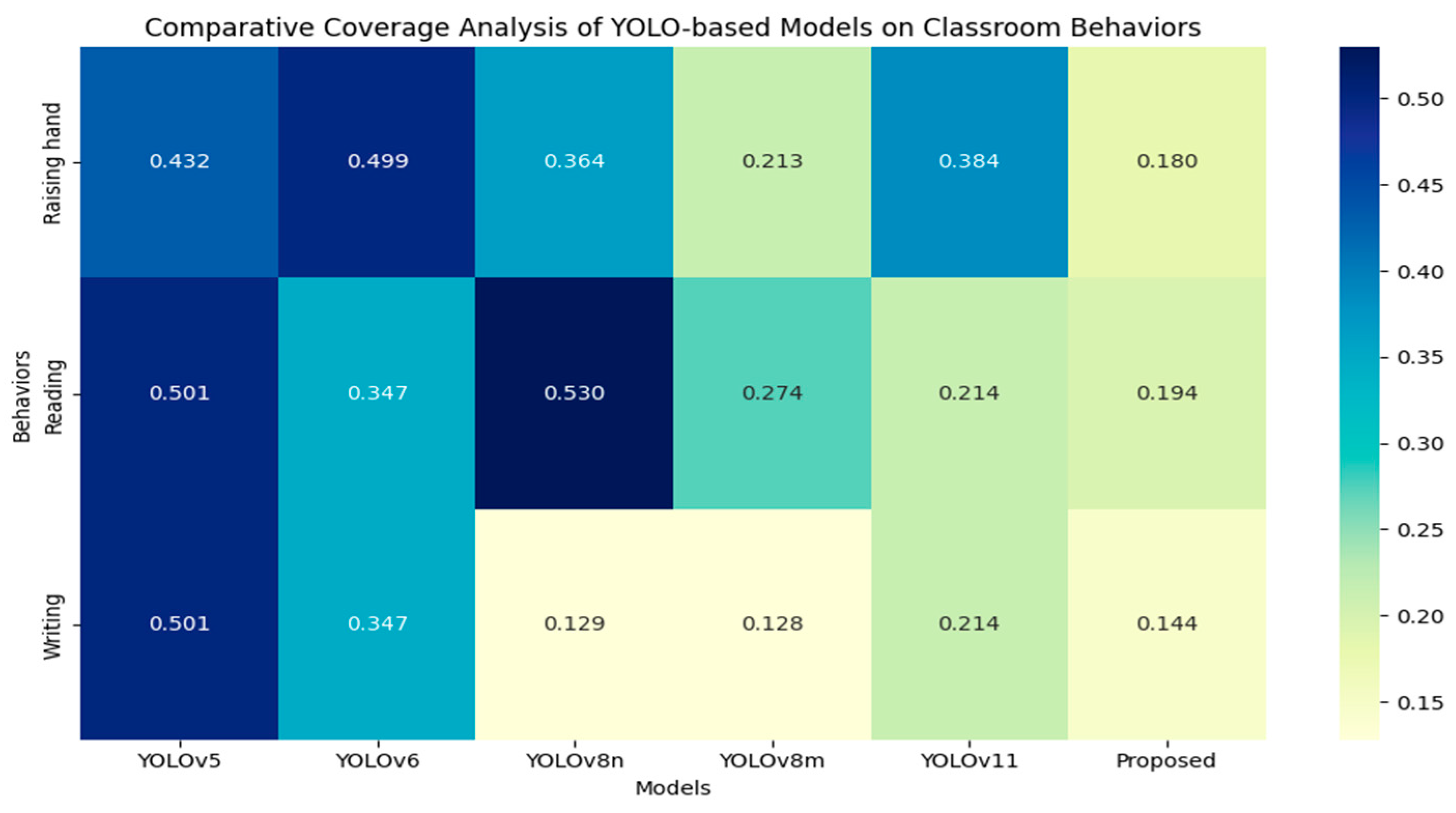
5.1. Comparative Experiments
5.2. Comparison of the Performance Between Shuffle Attention and Other Attention Networks
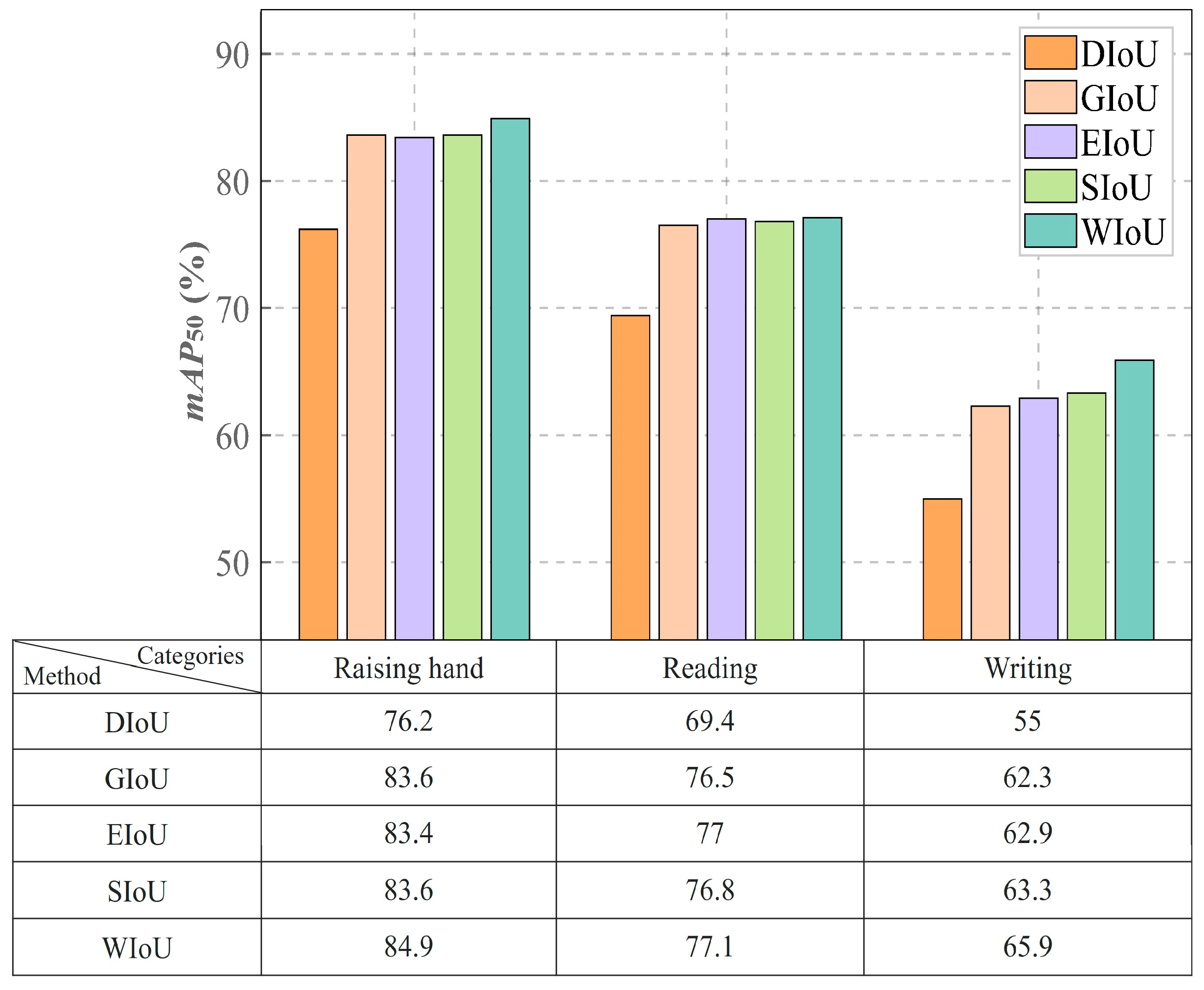
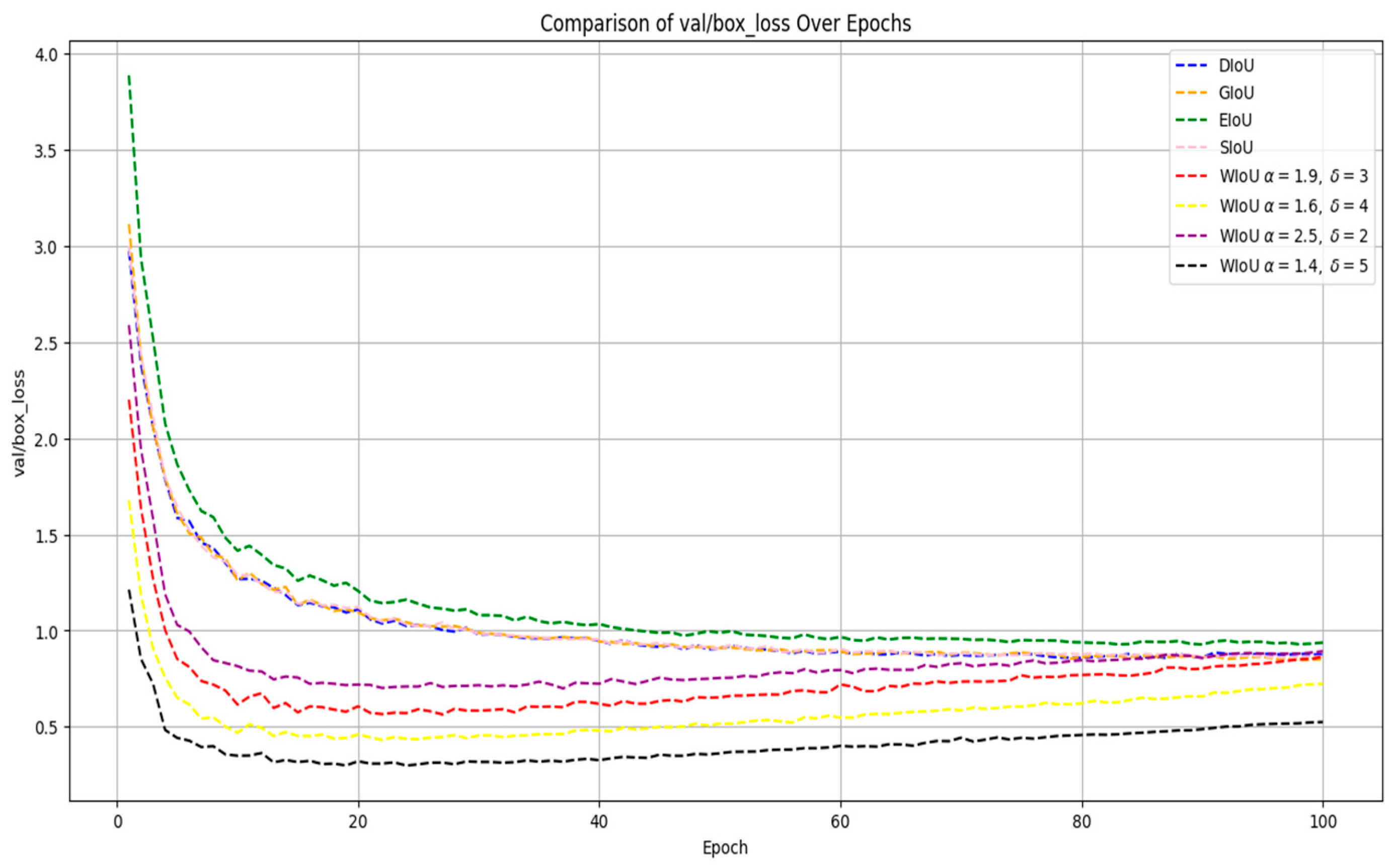
5.3. Comparison of the Performance of WIoU and Other Loss Functions
5.4. Ablation Experiments
5.5. Ablation Experiments of SA
5.6. Visual Presentation
5.7. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Crespí, P.; García-Ramos, J.M.; Queiruga-Dios, M. Project-based learning (PBL) and its impact on the development of interpersonal competences in higher education. J. New Approaches Edu. 2022, 11, 259–276. [Google Scholar] [CrossRef]
- Zhou, J.; Ran, F.; Li, G.; Peng, J.; Li, K.; Wang, Z. Classroom Learning Status Assessment Based on Deep Learning. Math. Probl. Eng. 2022, 2022, 7049458. [Google Scholar] [CrossRef]
- Hu, M.; Wei, Y.; Li, M.; Yao, H.; Deng, W.; Tong, M.; Liu, Q. Bimodal Learning Engagement Recognition from Videos in the Classroom. Sensors 2022, 22, 5932. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ding, Y.; Huang, X.; Li, W.; Long, L.; Ding, S. Smart Classrooms: How Sensors and AI Are Shaping Educational Paradigms. Sensors 2024, 24, 5487. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y. Deep Learning-based Student Learning Behavior Understanding Framework in Real Classroom Scene. In Proceedings of the 2023 International Conference on Machine Learning and Applications, Jacksonville, FL, USA, 15–17 December 2023; pp. 437–444. [Google Scholar]
- Lin, F.C.; Ngo, H.H.; Dow, C.R.; Lam, K.H.; Le, H.L. Student behavior recognition system for the classroom environment based on skeleton pose estimation and person detection. Sensors 2021, 21, 5314. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, J.; Sun, H.; Qi, M.; Kong, J. Analyzing students’ attention by gaze tracking and object detection in classroom teaching. Data Technol. Appl. 2023, 57, 643–667. [Google Scholar] [CrossRef]
- Vara Prasad, K.; Sai Kumar, D.; Mohith, T.; Sameer, M.; Lohith, K. Classroom Attendance Monitoring using Haar Cascade and KNN Algorithm. In Proceedings of the 2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things, Bengaluru, India, 4–6 January 2024; pp. 1624–1628. [Google Scholar]
- Poudyal, S.; Mohammadi-Aragh, M.J.; Ball, J.E. Hybrid Feature Extraction Model to Categorize Student Attention Pattern and Its Relationship with Learning. Electronics 2022, 11, 1476. [Google Scholar] [CrossRef]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Al Ka’bi, A. Proposed artificial intelligence algorithm and deep learning techniques for development of higher education. Int. J. Intell. Netw. 2023, 4, 68–73. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Y.; Tian, Y.; Qi, W. Construction of a hybrid teaching model system based on promoting deep learning. Comput. Intell. Neurosci. 2022, 2022, 4447530. [Google Scholar] [CrossRef]
- Bilous, N.; Malko, V.; Frohme, M.; Nechyporenko, A. Comparison of CNN-Based Architectures for Detection of Different Object Classes. AI 2024, 5, 2300–2320. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, D. Optimization of Student Behavior Detection Algorithm Based on Improved SSD Algorithm. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 5. [Google Scholar] [CrossRef]
- Chen, H.; Zhou, G.; Jiang, H. Student behavior detection in the classroom based on improved YOLOv8. Sensors 2023, 23, 8385. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Guan, J. Teacher-Student Behavior Recognition in Classroom Teaching Based on Improved YOLO-v4 and Internet of Things Technology. Electronics 2022, 11, 3998. [Google Scholar] [CrossRef]
- Albreiki, B.; Zaki, N.; Alashwal, H. A systematic literature review of student’ performance prediction using machine learning techniques. Educ. Sci. 2021, 11, 552. [Google Scholar] [CrossRef]
- Harikumar, P.; Alex, W.; Edwin, R.A.; Maximiliano, A.L.; Judith, F.A.; Khongdet, P. Classification and prediction of student performance data using various machine learning algorithms. Mater. Today Proc. 2023, 80, 3782–3785. [Google Scholar]
- Yang, W.; Li, M. Methods and key issues of classroom behavior recognition for students based on artificial intelligence. J. Intell. Fuzzy Syst. 2024, 40 (Suppl. S1), 105–117. [Google Scholar] [CrossRef]
- Ben Abdallah, T.; Elleuch, I.; Guermazi, R. Student behavior recognition in classroom using deep transfer learning with VGG-16. Procedia Comput. Sci. 2021, 192, 951–960. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, B.; Xu, L.; Huang, Y.; Xu, X.; Zhang, Q.; Jiang, Z.; Liu, Y. A benchmark and frequency compression method for infrared few-shot object detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5001711. [Google Scholar] [CrossRef]
- Zhang, R.; Cao, Z.; Huang, Y.; Yang, S.; Xu, L.; Xu, M. Visible-infrared person re-identification with real-world label noise. IEEE Trans. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 4857–4869. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, J.; Su, W. An improved method of identifying learner’s behaviors based on deep learning. J. Supercomput. 2022, 78, 12861–12872. [Google Scholar] [CrossRef]
- Lu, M.; Li, D.; Xu, F. Recognition of students’ abnormal behaviors in English learning and analysis of psychological stress based on deep learning. Front. Psychol. 2022, 13, 1025304. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Liu, F.; Wang, Y.; Guo, Y.; Xiao, L.; Zhu, L. A convolutional neural network (CNN) based approach for the recognition and evaluation of classroom teaching behavior. Sci. Program. 2021, 1, 6336773. [Google Scholar] [CrossRef]
- Xuan, Z. DRN-LSTM: A deep residual network based on long short-term memory network for students behaviour recognition in education. J. Eng. Appl. Sci. 2022, 26, 245–252. [Google Scholar]
- Jia, Q.; He, J. Student Behavior Recognition in Classroom Based on Deep Learning. Appl. Sci. 2024, 14, 7981. [Google Scholar] [CrossRef]
- Kavitha, A.; Shanmugapriya, K.; Swetha, L.G.; Varsana, J.; Varsha, N. Framework for Detecting Student Behaviour (Nail Biting, Sleep, and Yawn) Using Deep Learning Algorithm. In Proceedings of the 2024 2nd International Conference on Artificial Intelligence and Machine Learning Applications Theme: Healthcare and Internet of Things, San Francisco, CA, USA, 15–16 March 2024; pp. 1–6. [Google Scholar]
- Trabelsi, Z.; Alnajjar, F.; Parambil, M.M.A.; Gochoo, M.; Ali, L. Real-time attention monitoring system for classroom: A deep learning approach for student’s behavior recognition. Big Data Cogn. Comput. 2023, 7, 48. [Google Scholar] [CrossRef]
- Bao, D.; Su, W. Research on the Detection and Analysis of Students’ Classroom Behavioral Features Based on Deep CNNs. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 2375–4699. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Zeng, C.; Yao, J. Student learning behavior recognition incorporating data augmentation with learning feature representation in smart classrooms. Sensors 2023, 23, 8190. [Google Scholar] [CrossRef]
- Zhu, W.; Yang, Z. Csb-yolo: A rapid and efficient real-time algorithm for classroom student behavior detection. J. Real-Time Image Process. 2024, 21, 140. [Google Scholar] [CrossRef]
- Rui, J.; Lam, C.K.; Tan, T.; Sun, Y. DLW-YOLO: Improved YOLO for Student Behaviour Recognition. In Proceedings of the 2024 6th International Conference on Data-driven Optimization of Complex Systems (DOCS), Hangzhou, China, 16–18 August 2024; pp. 332–337. [Google Scholar]
- Du, S.; Pan, W.; Li, N.; Dai, S.; Xu, B.; Liu, H.; Xu, C.; Li, X. TSD-YOLO: Small traffic sign detection based on improved YOLO v8. IET Image Process. 2024, 18, 2884–2898. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Q.; Yang, Y. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1–5. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Tang, L.; Xie, T.; Yang, Y.; Wang, H. Classroom Behavior Detection Based on Improved YOLOv5 Algorithm Combining Multi-Scale Feature Fusion and Attention Mechanism. Appl. Sci. 2022, 12, 6790. [Google Scholar] [CrossRef]
- Sage, A.; Badura, P. Detection and Segmentation of Mouth Region in Stereo Stream Using YOLOv6 and DeepLab v3+ Models for Computer-Aided Speech Diagnosis in Children. Appl. Sci. 2024, 14, 7146. [Google Scholar] [CrossRef]
- Xiang, W.; Lei, H.; Ding, L.; Zhou, L. Real-Time Student Classroom Action Recognition: Based on Improved YOLOv8n. In Proceedings of the 3rd International Conference on Electronic Information Technology and Smart Agriculture (ICEITSA 2023), Association for Computing Machinery, New York, NY, USA, 8–10 December 2023; pp. 431–436. [Google Scholar]
- Santos Júnior, E.S.d.; Paixão, T.; Alvarez, A.B. Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images. Appl. Sci. 2025, 15, 3164. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–22 June 2025; pp. 1234–1243. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Chien, C.; Ju, R.; Chou, K.; Xieerke, E.; Chiang, J. YOLOv8-AM: YOLOv8 Based on Effective Attention Mechanisms for Pediatric Wrist Fracture Detection. IEEE Access 2025, 13, 52461–52477. [Google Scholar] [CrossRef]
- Xu, Q.; Wei, Y.; Gao, J.; Yao, H.; Liu, Q. ICAPD Framework and simAM-YOLOv8n for Student Cognitive Engagement Detection in Classroom. IEEE Access 2023, 11, 136063–136076. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5217–5226. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Yang, Z.; Wang, X.; Li, J. EIoU: An Improved Vehicle Detection Algorithm Based on VehicleNet Neural Network. J. Phys. Conf. Ser. 2021, 1924, 012001. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specifications |
|---|---|
| Operating System | Ubuntu 22.04 |
| Processor | 12 vCPU Intel® Xeon® Platinum 8352V @ 2.10 GHz (Intel Corporation, Santa Clara, CA, USA) |
| Graphics Card | NVIDIA GeForce RTX 4090 (24 GB) (NVIDIA Corporation, Santa Clara, CA, USA) |
| Component | Version |
|---|---|
| CUDA | 11.8 |
| Python | 3.10.8 |
| PyTorch | 2.1.2 |
| Hyperparameter Item | Value |
|---|---|
| Epoch | 100 |
| Image Size | 800 × 800 |
| Batch Size | 16 |
| Device | 0 |
| Initial Learning Rate | 0.01 |
| Optimizer | SGD |
| Momentum | 0.937 |
| Weight Decay | 0.0005 |
| Warmup Epochs | 3.0 |
| IoU Threshold (Train) | 0.20 |
| Confidence Threshold | 0.25 |
| Mosaic Augmentation | 1.0 |
| Dataset | Method | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) | #Param. (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| SCB03-S | SSD | 68.49 | 22.01 | 50.04 | 46.29 | 26.28 | 62.74 | 116.00 |
| YOLOv5 | 58.4 | 64.3 | 64.7 | 45.5 | 2.51 | 11.22 | 141.10 | |
| YOLOv6 | 62.2 | 65.4 | 67.2 | 48.5 | 4.24 | 18.55 | 197.92 | |
| YOLOv8n | 61.8 | 65.6 | 67.8 | 49.0 | 3.01 | 12.81 | 150.60 | |
| YOLOv8s | 66.4 | 68.5 | 72.1 | 54.3 | 11.14 | 44.77 | 94.15 | |
| YOLOv8m | 70.0 | 70.9 | 74.8 | 57.6 | 25.86 | 123.55 | 73.04 | |
| YOLOv10 | 68.0 | 68.5 | 73.0 | 55.7 | 99.97 | 16.49 | 52.43 | |
| YOLOv11 | 59.7 | 65.8 | 66.2 | 47.3 | 2.59 | 10.07 | 80.52 | |
| YOLOv12 | 54.8 | 61.8 | 59.6 | 41.6 | 2.52 | 9.34 | 37.16 | |
| YOLOv8-AM | 62.2 | 65.2 | 67.2 | 48.6 | 3.01 | 12.81 | 91.07 | |
| SimAM-YOLOv8 | 62.2 | 63.9 | 66.8 | 47.9 | 3.23 | 13.36 | 129.89 | |
| RT-DETR-L | 59.0 | 52.6 | 51.2 | 35.4 | 30.97 | 166.82 | 24.49 | |
| Proposed | 72.3 | 71.4 | 76 | 57.7 | 46.75 | 297 | 78.31 |
| Dataset | Method | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) | #Param. (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Classroom Behavior Dataset | YOLOv5 | 87.9 | 88.5 | 93.8 | 69.5 | 2.51 | 11.22 | 148.15 |
| YOLOv6 | 89.6 | 88.3 | 94.3 | 71.2 | 4.24 | 18.55 | 119.95 | |
| YOLOv8n | 88.8 | 89.9 | 94.3 | 71 | 3.01 | 12.82 | 112.29 | |
| YOLOv8s | 89.8 | 90.3 | 94.4 | 73.4 | 11.14 | 44.70 | 95.56 | |
| YOLOv8m | 90.1 | 89.4 | 94.6 | 75.8 | 25.86 | 123.56 | 108.67 | |
| YOLOv10n | 86.9 | 87.1 | 92.7 | 69.5 | 2.71 | 13.12 | 68.34 | |
| YOLOv11 | 88.8 | 88.5 | 93.7 | 70.4 | 2.59 | 10.07 | 113.42 | |
| Proposed | 90.5 | 90.0 | 94.7 | 74.0 | 43.69 | 293.19 | 95.58 |
| Dataset | Method | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) |
|---|---|---|---|---|---|
| SCB03-S | CBAM | 61.1 | 67.5 | 68.0 | 48.7 |
| CANet | 61.3 | 71.8 | 70.7 | 52.9 | |
| SENet | 66.7 | 70.7 | 73.0 | 54.3 | |
| Swin Transformer | 67.8 | 68.6 | 72.8 | 54.4 | |
| Shuffle Attention | 71.3 | 70.5 | 75.6 | 57.8 |
| Dataset | Method | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) |
|---|---|---|---|---|---|
| SCB03-S | YOLOv8m-DIoU | 63.8 | 62.5 | 66.9 | 47.9 |
| YOLOv8m-GIoU | 71.7 | 67.8 | 74.2 | 56.8 | |
| YOLOv8m-EIoU | 70.8 | 69.3 | 74.4 | 57.5 | |
| YOLOv8m-SIoU | 70.1 | 69.8 | 74.8 | 57.5 | |
| YOLOv8m-WIoU | 70.4 | 71 | 76 | 58.4 |
| Dataset | Method | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) |
|---|---|---|---|---|---|
| SCB03-S | YOLOv8m | 70.0 | 70.9 | 74.8 | 57.6 |
| YOLOv8m-WIoU (α = 2.5, δ = 2) | 70.4 | 71.5 | 76.1 | 58.5 | |
| YOLOv8m-WIoU (α = 1.9, δ = 3) | 70.4 | 71 | 76 | 58.4 | |
| YOLOv8m-WIoU (α = 1.6, δ = 4) | 68.8 | 73.3 | 76.4 | 58.5 | |
| YOLOv8m-WIoU (α = 1.4, δ = 5) | 71.3 | 71.4 | 76.2 | 58.5 |
| C2fs | SA | WIoU | Precision (%) | Recall (%) | mAP50 (%) | mAP50–95 (%) |
|---|---|---|---|---|---|---|
| 70.0 | 70.9 | 74.8 | 57.6 | |||
| √ | 67.4 | 72.3 | 75.4 | 58.2 | ||
| √ | 71.3 | 70.5 | 75.6 | 57.8 | ||
| √ | 70.4 | 71 | 76 | 58.4 | ||
| √ | √ | 71 | 70.3 | 75.1 | 57.6 | |
| √ | √ | 70.6 | 72.1 | 76.1 | 58.5 | |
| √ | √ | √ | 72.3 | 71.4 | 76 | 57.7 |
| Model | #Param. (M) | GFLOPs | FPS | Precision (%) |
|---|---|---|---|---|
| Baseline | 25.86 | 123.55 | 73.04 | 70.0 |
| Baseline + SA | 33.95 | 133.96 | 95.64 | 71.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Liu, X.; Guan, X.; Cheng, Y. CSSA-YOLO: Cross-Scale Spatiotemporal Attention Network for Fine-Grained Behavior Recognition in Classroom Environments. Sensors 2025, 25, 3132. https://doi.org/10.3390/s25103132
Zhou L, Liu X, Guan X, Cheng Y. CSSA-YOLO: Cross-Scale Spatiotemporal Attention Network for Fine-Grained Behavior Recognition in Classroom Environments. Sensors. 2025; 25(10):3132. https://doi.org/10.3390/s25103132
Chicago/Turabian StyleZhou, Liuchen, Xiangpeng Liu, Xiqiang Guan, and Yuhua Cheng. 2025. "CSSA-YOLO: Cross-Scale Spatiotemporal Attention Network for Fine-Grained Behavior Recognition in Classroom Environments" Sensors 25, no. 10: 3132. https://doi.org/10.3390/s25103132
APA StyleZhou, L., Liu, X., Guan, X., & Cheng, Y. (2025). CSSA-YOLO: Cross-Scale Spatiotemporal Attention Network for Fine-Grained Behavior Recognition in Classroom Environments. Sensors, 25(10), 3132. https://doi.org/10.3390/s25103132