

Embedded Vision System for Thermal Face Detection Using Deep Learning

 ,
,  , , and
, , and
Abstract
1. Introduction
- We conducted an experimental evaluation of two state-of-the-art general object detection models, YOLOv8 and YOLO11, trained to detect faces in thermal images. Two of the largest available thermal face databases were used: the Terravic Facial IR database was used for the training, validation, and testing, and the Charlotte-ThermalFace database was used to test the models further.
- We performed an experimental evaluation of two different embedded system boards, the NVIDIA Jetson Orin Nano and the NVIDIA Jetson Xavier NX, executing the trained model in inference mode. Both embedded platforms detected faces in thermal images accurately in real time.
- The developed embedded vision system can improve the face detection performance of surveillance and security systems, overcoming the limitations imposed by varying illumination conditions.
2. Materials and Methods
2.1. Hardware Components
2.1.1. Thermal Sensors
2.1.2. Embedded System Boards
2.1.3. Embedded Vision System
2.2. Embedded Vision System Software Setup for Data Processing
2.2.1. Initial Embedded System Board Configuration
2.2.2. DNN Model Training, Validation, and Testing
- Random hue, saturation, and value augmentations range in HSV space (hsv_h = 0.015, hsv_s = 0.7, hsv_v = 0.4),
- Maximum translation augmentation as fraction of image size (translate = 0.1),
- Random scaling augmentation range (scale = 0.5),
- Probability of horizontal image flip (fliplr = 0.5),
- Probability of using mosaic augmentation, which combines 4 images (mosaic = 1.0),
- Randomly erases regions of the image (erasing = 0.4),
- Randomly crop regions of the image (crop_fraction = 1.0),
2.2.3. DNN Model in Inference Mode
3. Results
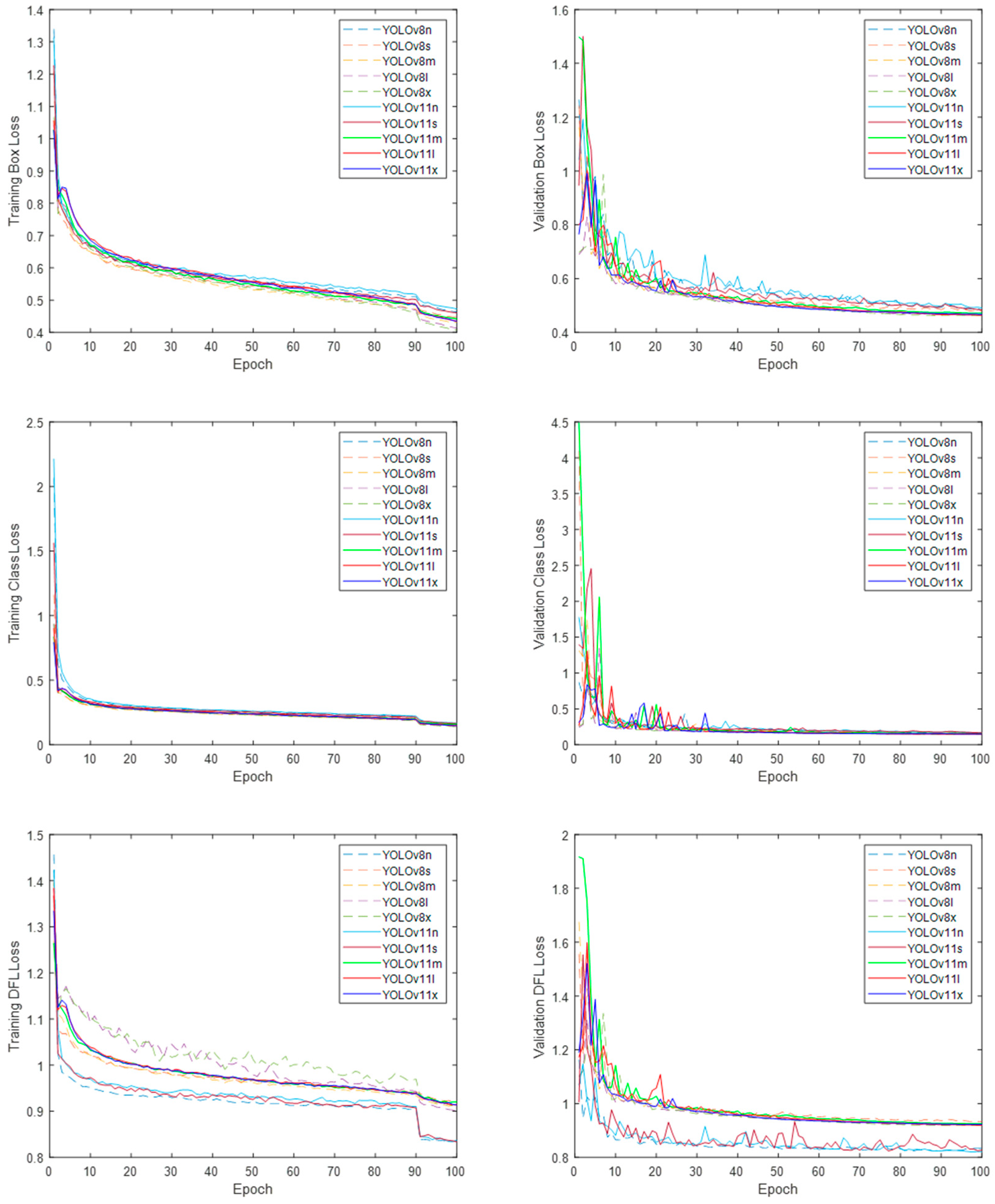
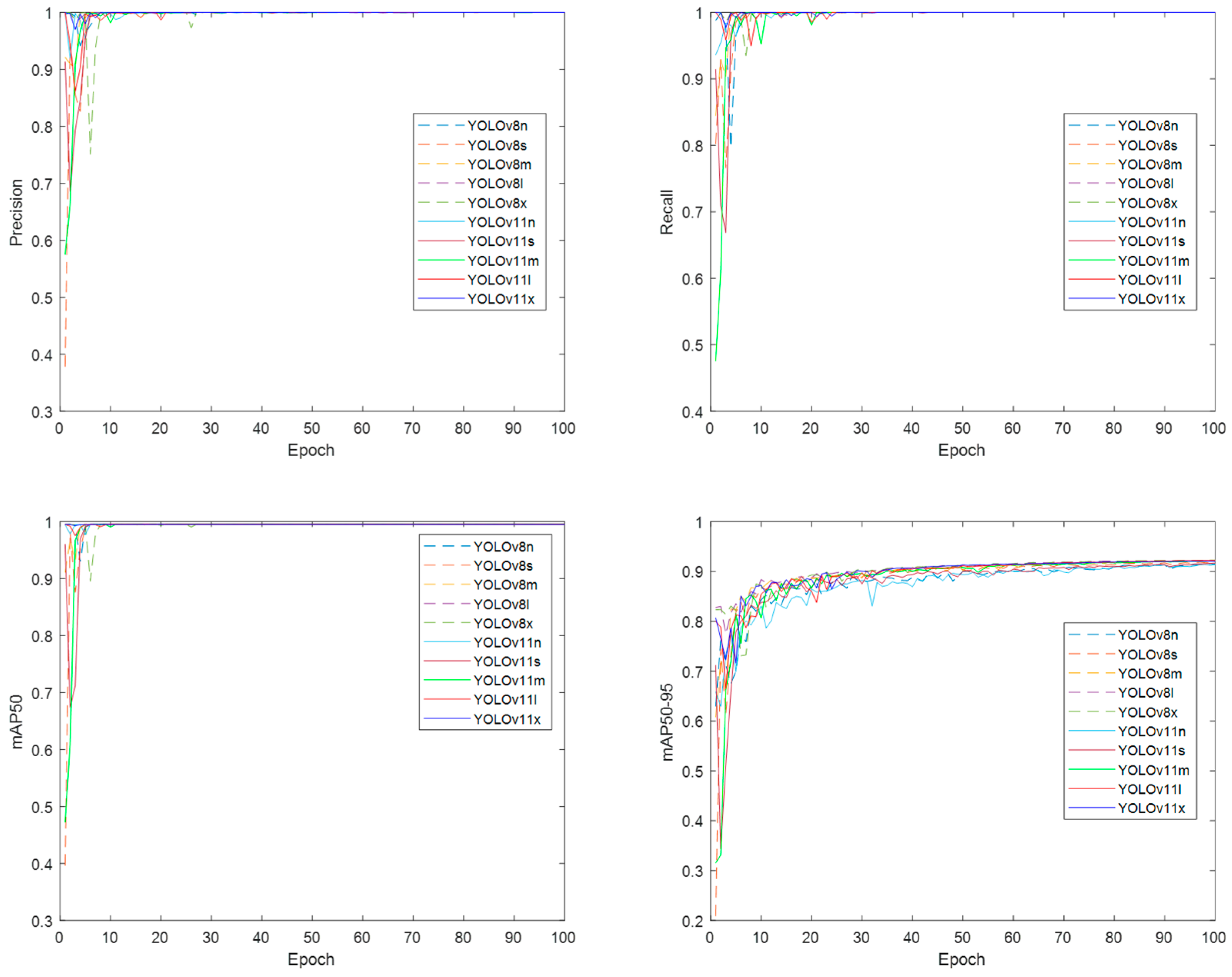
3.1. DNN Models Training
3.2. DNN Models Validation
3.3. DNN Models Testing
3.4. DNN Model Executed in Inference Mode
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| ML | Machine Learning |
| DL | Deep Learning |
| LWIR | Long-wave Infrared |
| HOG | Histogram of Oriented Gaussians |
| SVM | Support Vector Machine |
| LBP | Local Binary Pattern |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| TOPS | Tera Operations Per Second |
| GFLOPS | Giga Floating-point Operations Per Second |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| DLA | Deep Learning Accelerator |
| IoU | Intersection over Union |
| mAP | Mean Average Precision |
References
- Ribeiro, R.F.; Fernandes, J.M.; Neves, A.J. Face detection on infrared thermal image. In Proceedings of the Second International Conference on Advances in Signal, Image and Video Processing, SIGNAL 2017, Barcelona, Spain, 21–25 May 2017; Volume 45. [Google Scholar]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. J. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef]
- Manssor, S.A.F.; Sun, S.; Abdalmajed, M.; Ali, S.I. Real-time human detection in thermal infrared imaging at night using enhanced Tiny-yolov3 network. J. Real-Time Image Process. 2014, 19, 261–274. [Google Scholar] [CrossRef]
- Wong, W.Y.; Hui, J.H.; Desa, J.M.; Ishak, N.D.B.; Sulaiman, A.; Nor, Y.B.M. Face detection in thermal imaging using head curve geometry. In Proceedings of the 5th International Congress on Image and Signal Processing, Chongqing, China, 16–18 October 2012; pp. 881–884. [Google Scholar] [CrossRef]
- Wang, C.; Cao, R.; Wang, R. Learning discriminative topological structure information representation for 2D shape and social network classification via persistent homology. Knowl.-Based Syst. 2025, 311, 113125. [Google Scholar] [CrossRef]
- Kopaczka, M.; Breuer, L.; Schock, J.; Merhof, D. A Modular System for Detection, Tracking and Analysis of Human Faces in Thermal Infrared Recordings. Sensors 2019, 19, 4135. [Google Scholar] [CrossRef]
- Golchoubian, M.; Ghafurian, M.; Dautenhahn, K.; Azad, N.L. Pedestrian trajectory prediction in pedestrian-vehicle mixed environments: A systematic review. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11544–11567. [Google Scholar] [CrossRef]
- Shi, L.; Wang, L.; Zhou, S.; Hua, G. Trajectory unified transformer for pedestrian trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 9675–9684. [Google Scholar] [CrossRef]
- Wang, C.; He, S.; Wu, M.; Lam, S.K.; Tiwari, P.; Gao, X. Looking Clearer with Text: A Hierarchical Context Blending Network for Occluded Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2025, 20, 4296–4307. [Google Scholar] [CrossRef]
- Cao, Z.; Zhao, H.; Cao, S.; Pang, L. Face detection in the darkness using infrared imaging: A deep-learning-based study. Proc. SPIE Appl. Mach. Learn. 2021, 11843, 118430K. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Yang, H.C.; Wang, X.A. Cascade face detection based on histograms of oriented gradients and support vector machine. In Proceedings of the 2015 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Krakow, Poland, 4–6 November 2015; pp. 766–770. [Google Scholar] [CrossRef]
- Zhang, L.; Chu, R.; Xiang, S.; Liao, S.; Li, S.Z. Face detection based on multi-block lbp representation. In Proceedings of the 2007 International Conference on Biometrics (ICB 2007), Crystal City, VA, USA, 27–29 September 2007; pp. 11–18. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Deng, J.; Xie, X. Nested shallow CNN-cascade for face detection in the wild. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 165–172. [Google Scholar] [CrossRef]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S^3FD: Single shot scale-invariant face detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar] [CrossRef]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. FaceBoxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Forczmański, P. Performance evaluation of selected thermal imaging-based human face detectors. In Proceedings of the 10th International Conference on Computer Recognition Systems, CORES 2017, Polanica-Zdroj, Poland, 22–24 May 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 170–181. [Google Scholar]
- Ma, C.; Trung, N.T.; Uchiyama, H.; Nagahara, H.; Shimada, A.; Taniguchi, R.-I. Adapting Local Features for Face Detection in Thermal Images. Sensors 2017, 17, 2741. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, G.; Yeshurun, Y. Seeing people in the dark: Face recognition in infrared images. In Proceedings of the International Workshop on Biologically Motivated Computer Vision, Virtual, 21–22 February 2002; Springer: Cham, Switzerland, 2002; pp. 348–359. [Google Scholar]
- Reese, K.; Zheng, Y.; Elmaghraby, A. A comparison of face detection algorithms in visible and thermal spectrums. In Proceedings of the International Conference on Advances in Computer Science and Application, Amsterdam, The Netherlands, 7–8 June 2012; pp. 7–8. [Google Scholar]
- Kopaczka, M.; Nestler, J.; Merhof, D. Face detection in thermal infrared images: A comparison of algorithm and machine-learning-based approaches. In Advanced Concepts for Intelligent Vision Systems. ACIVS 2017. Lecture Notes in Computer Science; Blanc-Talon, J., Penne, R., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer: Cham, Switzerland, 2017; Volume 10617. [Google Scholar] [CrossRef]
- Silva, G.; Monteiro, R.; Ferreira, A.; Carvalho, P.; Corte-Real, L. Face Detection in Thermal Images with YOLOv3. In Advances in Visual Computing. ISVC 2019. Lecture Notes in Computer Science; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Ushizima, D., Sueda, S., Lin, X., Lu, A., Thalmann, D., Wang, C., et al., Eds.; Springer: Cham, Switzerland, 2019; Volume 11845. [Google Scholar] [CrossRef]
- Jetson Modules. NVIDIA. Available online: https://developer.nvidia.com/embedded/jetson-modules#tech_specs (accessed on 20 January 2025).
- NVIDIA TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 20 January 2025).
- Deep Learning Accelerator (DLA). NVIDIA. Available online: https://developer.nvidia.com/deep-learning-accelerator (accessed on 20 January 2025).
- NVIDIA cuDNN. Available online: https://developer.nvidia.com/cudnn (accessed on 20 January 2025).
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- YOLO11. Ultralytics. Available online: https://docs.ultralytics.com/models/yolo11 (accessed on 20 January 2025).
- Object Detection. Ultralytics. Available online: https://docs.ultralytics.com/tasks/detect/ (accessed on 20 January 2025).
- Hidayatullah, P.; Syakrani, N.; Sholahuddin, M.R.; Gelar, T.; Tubagus, R. YOLOv8 to YOLO11: A Comprehensive Architecture In-depth Comparative Review. arXiv 2025, arXiv:2501.13400. [Google Scholar]
- Miezianko, R. IEEE OTCBVS WS Series Bench—Terravic Research Infrared Database. Available online: http://vcipl-okstate.org/pbvs/bench/Data/04/download.html (accessed on 20 January 2025).
- Ashrafi, R.; Azarbayjani, M.; Tabkhi, H. Charlotte-thermalface: A fully annotated thermal infrared face dataset with various environmental conditions and distances. Infrared Phys. Technol. 2022, 124, 104209. [Google Scholar] [CrossRef]
- YOLO Performance Metrics. Ultralytics. Available online: https://docs.ultralytics.com/guides/yolo-performance-metrics/ (accessed on 20 January 2025).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | |
|---|---|
| Sensor Type | Uncooled Vox Microbolometer |
| Spectral Band | Longwave infrared 8 µm to 14 µm |
| Temperature Range | −10 °C to 140 °C |
| Sensitivity | <50 mK (0.050 °C) |
| Resolution | 160 × 120 |
| FPS | 9 fps |
| Communication Interface | I2C (Control) SPI (Video) USB (with PureThermal 2) |
| FOV | 57° Horizontal 71° Vertical |
| Specifications | ||
|---|---|---|
| NVIDIA Jetson Xavier NX | NVIDIA Jetson Orin Nano | |
| AI Performance | 21 TOPS | 67 TOPS |
| GPU | 384-core NVIDIA Volta™ architecture GPU with 48 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores |
| GPU Max Frequency | 1020 MHz | 1100 MHz |
| CPU | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5 MB L2 + 4 MB L3 | 6-core NVIDIA Carmel Arm®v8.2 64-bit CPU 6 MB L2 + 4 MB L3 |
| CPU Max Frequency | 1.7 GHz | 1.9 GHz |
| Memory | 8 GB 128-bit LPDDR5 102 GB/s | 8 GB 128-bit LPDDR4x 59.7 GB/s |
| Hyperparameter | Value |
|---|---|
| Learning Rate | 0.01 |
| Momentum | 0.937 |
| Weight Decay | 0.0005 |
| Warmup Epochs | 3 |
| Warmup Momentum | 0.8 |
| Warmup Bias Learning Rate | 0.1 |
| Model | Batch Size | GPU Memory | No. of Layers | Total Params | Gradients Computed | GFLOPS | Train Time/EPOCH | Val Time/EPOCH |
|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 19.7 Gb | 225 | 3,011,043 | 3,011,027 | 8.2 | 12 s | 6 s |
| YOLO v8s | 384 | 21 Gb | 225 | 11,135,987 | 11,135,971 | 28.6 | 20 s | 7 s |
| YOLOv8m | 216 | 21.4 Gb | 295 | 25,856,899 | 25,856,883 | 79.1 | 39 s | 9 s |
| YOLOv8l | 148 | 22.4 Gb | 365 | 43,630,611 | 43,630,595 | 165.4 | 60 s | 13 s |
| YOLOv8x | 120 | 22.1 Gb | 365 | 68,153,571 | 68,153,555 | 258.1 | 94 s | 20 s |
| YOLO11n | 640 | 21.3 Gb | 319 | 2,590,035 | 2,590,019 | 6.4 | 12 s | 6 s |
| YOLO11s | 384 | 23.5 Gb | 319 | 9,428,179 | 9,428,163 | 21.5 | 19 s | 7 s |
| YOLO11m | 176 | 22.4 Gb | 409 | 20,053,779 | 20,053,763 | 68.2 | 40 s | 8 s |
| YOLO11l | 128 | 21.1 Gb | 631 | 25,311,251 | 25,311,235 | 87.3 | 53 s | 9 s |
| YOLO11x | 90 | 22.7 Gb | 631 | 56,874,931 | 56,874,915 | 195.4 | 90 s | 12 s |
| Model | mAP50 | mAP50-95 | Inference Time |
|---|---|---|---|
| YOLOv8n | 0.995 | 0.915 | 0.2 ms |
| YOLOv8s | 0.995 | 0.919 | 0.2 ms |
| YOLOv8m | 0.995 | 0.921 | 1.3 ms |
| YOLOv8l | 0.995 | 0.922 | 1.93 ms |
| YOLOv8x | 0.995 | 0.923 | 2.9 ms |
| YOLO11n | 0.995 | 0.914 | 0.2 ms |
| YOLO11s | 0.995 | 0.916 | 0.2 ms |
| YOLO11m | 0.995 | 0.921 | 0.5 ms |
| YOLO11l | 0.995 | 0.922 | 0.7 ms |
| YOLO11x | 0.995 | 0.922 | 0.7 ms |
| Model | Average IoU | Samples with IoU < 0.8 | Inference Time |
|---|---|---|---|
| YOLOv8n | 0.93430 | 4 | 3.0 ms |
| YOLOv8s | 0.93542 | 4 | 3.8 ms |
| YOLOv8m | 0.93659 | 3 | 4.2 ms |
| YOLOv8l | 0.93718 | 5 | 5.3 ms |
| YOLOv8x | 0.937264 | 4 | 5.9 ms |
| YOLO11n | 0.93338 | 5 | 3.6 ms |
| YOLO11s | 0.93460 | 2 | 4.2 ms |
| YOLO11m | 0.93566 | 5 | 4.5 ms |
| YOLO11l | 0.93705 | 3 | 7.8 ms |
| YOLO11x | 0.93639 | 3 | 8.4 ms |
| Model | Average IoU | Samples with IoU < 0.8 | Inference Time |
|---|---|---|---|
| YOLOv8n | 0.628672 | 0.981206 | 2 ms |
| YOLOv8s | 0.628224 | 0.920296 | 4.3 ms |
| YOLOv8m | 0.616899 | 0.960196 | 20.3 ms |
| YOLOv8l | 0.617041 | 0.954895 | 40.4 ms |
| YOLOv8x | 0.624454 | 0.975424 | 71.1 ms |
| YOLO11n | 0.628049 | 0.979375 | 1.9 ms |
| YOLO11s | 0.639260 | 0.970605 | 3.3 ms |
| YOLO11m | 0.624533 | 0.959811 | 31.9 ms |
| YOLO11l | 0.623969 | 0.991326 | 41.3 ms |
| YOLO11x | 0.623335 | 0.977158 | 81.7 ms |
| CPU Time (Milliseconds) | ||||
|---|---|---|---|---|
| Jetson Xavier NX | Jetson Orin Nano | |||
| PyTorch | TensorRT-DLA | PyTorch | TensorRT-GPU | |
| Pre-processing | 1.0 | 1.0 | 0.78 | 0.78 |
| Inference | 0.46 | 0.44 | 0.19 | 0.17 |
| Post-processing | 40 | 13 | 26 | 7.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robledo-Vega, I.; Osuna-Tostado, S.; Rodríguez-Mata, A.E.; García-Mata, C.L.; Acosta-Cano, P.R.; Baray-Arana, R.E. Embedded Vision System for Thermal Face Detection Using Deep Learning. Sensors 2025, 25, 3126. https://doi.org/10.3390/s25103126
Robledo-Vega I, Osuna-Tostado S, Rodríguez-Mata AE, García-Mata CL, Acosta-Cano PR, Baray-Arana RE. Embedded Vision System for Thermal Face Detection Using Deep Learning. Sensors. 2025; 25(10):3126. https://doi.org/10.3390/s25103126
Chicago/Turabian StyleRobledo-Vega, Isidro, Scarllet Osuna-Tostado, Abraham Efraím Rodríguez-Mata, Carmen Leticia García-Mata, Pedro Rafael Acosta-Cano, and Rogelio Enrique Baray-Arana. 2025. "Embedded Vision System for Thermal Face Detection Using Deep Learning" Sensors 25, no. 10: 3126. https://doi.org/10.3390/s25103126
APA StyleRobledo-Vega, I., Osuna-Tostado, S., Rodríguez-Mata, A. E., García-Mata, C. L., Acosta-Cano, P. R., & Baray-Arana, R. E. (2025). Embedded Vision System for Thermal Face Detection Using Deep Learning. Sensors, 25(10), 3126. https://doi.org/10.3390/s25103126