1. Introduction
With the rapid development of technologies such as the Internet of Things (IoT) and autonomous driving, the number of sensors used to capture images, audio, and other information has increased dramatically. The vast amounts of raw data collected by these sensors contain a significant amount of unstructured and redundant information, leading to severe challenges in energy consumption, response time, data storage, and communication bandwidth during subsequent information processing [
1]. To alleviate the data transmission burden on sensor nodes, deploying certain image processing tasks at the near-sensor edge can significantly reduce latency and redundant data storage in the sensing-to-computation process, thereby improving system real-time performance and energy efficiency [
2]. Meanwhile, convolutional neural networks (CNNs) have been widely applied in critical fields such as indoor positioning [
3], intrusion detection [
4], malware identification [
5], edge computing, and artificial intelligence [
6]. These application scenarios impose stringent requirements on computational efficiency and hardware costs, particularly when deployed on resource-constrained edge devices. However, neural networks typically require complex circuit structures to perform a large number of multiplication and addition operations, which demand extensive logic gates and hardware resources in traditional binary computing paradigms [
7]. Consequently, executing neural networks using binary computing results in high power consumption, posing a significant challenge for mobile and edge computing devices.
To address the performance and energy efficiency challenges of neural network computation architectures, it is essential to explore new information processing paradigms beyond traditional high-precision digital computing. Stochastic Computing (SC) is a fault-tolerant computing paradigm that utilizes a Stochastic Number Generator (SNG) to produce bit streams encoded in a stochastic manner. Using simple logic gates, SC performs operations such as multiplication and summation, with precision improving as the bit stream length increases [
8]. Stochastic bit streams are sequences where each bit carries equal weight, and binary numbers can be mapped to stochastic bit streams using either unipolar or bipolar encoding methods [
9], as shown in
Figure 1a. In the unipolar encoding scheme, the probability of each bit being set to “1” is proportional to the represented value a. In the bipolar scheme, the bit stream represents values within the range [−1,1], where the probability of each bit being set to “1” is proportional to (a + 1)/2. A bit stream of length n contains several “1”s ranging from [0,n], allowing it to represent n + 1 different values. Since the bipolar scheme enables the representation of both positive and negative values, it is more suitable for neural networks.
Compared to binary computing, stochastic computing offers the following advantages in neural network applications:
(1) Stochastic computing performs complex arithmetic operations using simple logic gates, reducing the required number of logic components, thereby simplifying hardware design and lowering computational power consumption and hardware costs [
10]. For example, multiplication, which is a complex operation in traditional binary computing, can be implemented with a single AND gate in stochastic computing, while addition can be represented using a multiplexer (MUX), as shown in
Figure 1b. Simple circuits are particularly important for battery-powered mobile and edge computing devices.
(2) Since each bit in a stochastic bit stream has the same weight, it has high fault tolerance, and single-bit errors do not significantly impact the overall result as in binary computing [
11].
(3) When using bipolar encoding, the input and output values of stochastic computing are both within the range [−1, 1], avoiding the need for additional normalization operations.
However, traditional stochastic computing-based neural networks have certain limitations. First, stochastic computing requires long bit streams to maintain computational accuracy, resulting in prolonged computational delays. Second, most existing stochastic computing methods rely on a large number of pseudo-random number generators to produce stochastic bit streams, which severely restricts circuit area and energy efficiency [
12]. Additionally, when using bipolar encoding, traditional stochastic computing exhibits low multiplication accuracy for near-zero data, which contradicts the sparsity characteristic of neural networks [
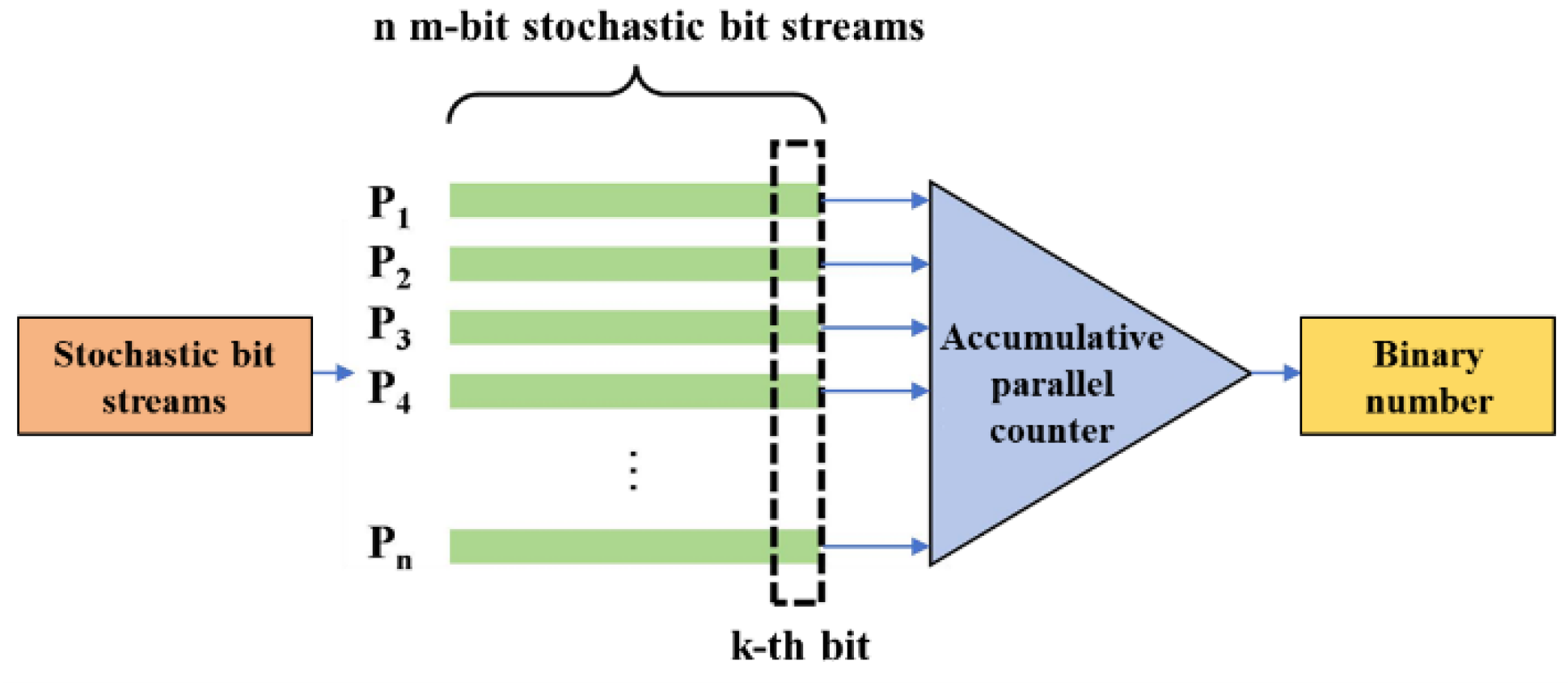
13]. Furthermore, neural networks frequently use Accumulative Parallel Counters (APC) for stochastic addition, as shown in
Figure 2 [
14]. APC is an electronic counter used for counting and accumulating the number of occurrences of events. Based on the principle of parallel counting, it can process multiple input signals simultaneously, enabling efficient and rapid accumulation. In stochastic addition, APC obtains the sum of the k-th bit from n m-bit stochastic bit streams using a parallel counter, stores the result in a register, and ultimately accumulates all bits from the n m-bit stochastic bit streams to produce a binary-form sum. However, using APC for addition introduces additional stochastic computing and binary conversion circuitry, significantly increasing circuit area. Finally, due to the distribution characteristics of convolutional kernels in neural networks, representing them with short-bit streams remains challenging.
To address these issues, this paper proposes a convolutional neural network hardware optimization design based on deterministic encoding. By converting image sensor output signals into deterministically encoded bit streams, the first convolutional layer of the network achieves low-cost and high-energy-efficiency multiply–accumulate operations with shorter bit streams. Additionally, a co-optimization of the network training process is conducted for the hybrid convolutional neural network combining deterministic and binary encoding. The optimized network achieves superior image classification performance even with extremely short bit streams, significantly reducing system latency and energy consumption.
This paper proposes a hardware optimization design for convolutional neural networks that leverages a hybrid deterministic and binary encoding scheme, achieving high energy efficiency and low cost through the use of an extremely short bitstream. Additionally, a co-optimization training algorithm for the first convolutional layer is developed, which supports 2-bit deterministic encoding while maintaining a recognition accuracy of 99%.
The remainder of this paper is organized as follows:
Section 2 provides a review of related work on stochastic computing and its applications in neural networks.
Section 3 describes the proposed method in detail, including the near-sensor deterministic encoding approach and the hybrid encoding neural network design.
Section 4 presents the experimental results and analysis, demonstrating the effectiveness of the proposed method in terms of hardware efficiency and fault tolerance. Finally,
Section 5 concludes the paper and outlines future research directions.
2. Related Work
Stochastic computing, due to its neuron-like information encoding method, can significantly reduce hardware requirements and energy consumption in neural network systems. Currently, stochastic computing has been successfully applied to various neural networks, achieving progress in multiple aspects. Zhe Li et al. [
15] proposed a joint optimization method for components in deep stochastic convolutional neural networks to ensure high computational accuracy. By modifying the original network structure to simplify stochastic computing hardware design, the optimized feature extraction block improved computation accuracy by 42.22% compared to the non-optimized version, and the network’s test error rate was reduced to 3.48% from 27.83%. Mohamad Hasani Sadi et al. [
16] introduced an efficient deep convolutional neural network inference framework based on stochastic computing. They designed a novel approximate parallel counter using multiplexers (MUX) to reduce input data and improved the stochastic Rectified Linear Unit (ReLU) activation function, making it more closely resemble the actual ReLU function while being compatible with APC-based adders. Additionally, they proposed a new method to implement the Softmax function in the stochastic domain with minimal resources, reducing hardware area, delay, and power consumption. These optimizations reduced hardware area overhead by approximately 17% and path delay by about 18% when implementing the LeNet-5 network. Sunny Bodiwala et al. [
17] proposed an efficient deep neural network accelerator based on stochastic computing, optimizing its activation function. This work developed an improved stochastic computing neuron architecture for deep neural network training and implementation. By integrating stochastic computing, the method significantly reduced hardware occupation while maintaining high scalability. Experimental results showed that this approach improved classification accuracy on the Modified National Institute of Standards and Technology database (MNIST) by 9.47% compared to traditional binary computing methods. This research provides an effective solution for deploying complex deep-learning models on resource-constrained devices. M. Nobari et al. [
18] proposed an efficient Field-Programmable Gate Array (FPGA)-based implementation of deep neural networks using stochastic computing, addressing the slow convergence speed and high hardware resource consumption of traditional SC methods. By limiting stochastic bit stream length and establishing precise synchronization among processing units, convergence time was significantly reduced. Additionally, the study proposed a novel probability estimator architecture that eliminated feedback loops in traditional probability estimators, improving convergence speed and accuracy. Implemented on the Xilinx FPGA Virtex-7 chip using Verilog hardware description language, experimental results demonstrated that this method reduced hardware resource utilization by over 82%, lowered power consumption, and increased deep neural network accuracy by 2%. This research provides an effective solution for implementing efficient deep-learning models on resource-constrained hardware platforms. Junxiu Liu et al. [
19] proposed a stochastic computing-based hardware spiking neural network system for implementing pairwise spike-timing-dependent plasticity. By leveraging stochastic computing technology, the study simplified multipliers, adders, and subtractors in traditional hardware spiking neural networks, significantly reducing hardware resource consumption. Experimental results showed that, compared to existing technologies, this system reduced hardware resource consumption by 58.0%, with register usage decreasing by 65.6%. Tianmu Li et al. [
20] introduced a new method called range-extended stochastic computing to improve the accuracy and efficiency of stochastic computing in neural network accelerators. By enhancing OR-gate-based stochastic computing accumulation functions, this method increased computational precision while maintaining performance advantages, achieving a 2-fold reduction in bit stream length at the same precision and improving energy efficiency by 3.6 times compared to traditional binary addition. Furthermore, the study proposed an optimized training method that incorporated bit stream computation simulation, activation calibration, and error injection, accelerating the training speed of range-extended stochastic computing neural networks by 22 times, making training on large datasets such as ImageNet feasible. Huiyi Gu et al. [
21] proposed a novel computing-in-memory architecture based on magnetic random-access memory for Bayesian neural networks using stochastic computing. This architecture aimed to address the high computational complexity and extensive sampling operations required for deploying traditional Bayesian neural networks on edge devices. By performing computations directly within memory and leveraging the unique properties of magnetic random-access memory, an efficient computing-in-memory approach was realized. Neural network parameters were represented as bit streams, and by redesigning the computing-in-memory architecture, reliance on complex peripheral circuits was reduced. Additionally, a real-time Gaussian random number generator was designed using the random switching properties of magnetic random-access memory, further improving energy efficiency. Evaluations using Cadence Virtuoso Analog Design Environment showed that, while maintaining accuracy, this architecture reduced energy consumption by over 93.6% compared to traditional FPGA-based von Neumann architectures. This work offers an effective solution for deploying Bayesian neural networks on resource-constrained edge devices. K. Chen et al. [
22] proposed a stochastic computing-based artificial neural network architecture design incorporating a novel unscaled adder and input data preprocessing method to enhance hardware reliability and computational accuracy. The adder combined a T-Flipflop adder and a finite-state machine linear gain unit, eliminating scaling effects in stochastic computing and generating accurate sums. Experimental results indicated that compared to traditional neural network designs, this architecture reduced power consumption and area costs by 48–81% and 51–92%, respectively. This research provides an effective solution for achieving high-reliability, high-accuracy neural networks in edge computing scenarios with resource constraints.
Table 1 presents the main contributions and data comparisons of the aforementioned references.
In summary, a series of studies have demonstrated that the stochastic computing paradigm can significantly reduce the hardware requirements and energy consumption of neural network systems, presenting broad development prospects. However, all the aforementioned studies face a common challenge: achieving high computational accuracy with stochastic computing typically requires long bit streams. This means that complex computations involve processing a large volume of bit stream data, leading to increased computational latency and resource consumption. Additionally, stochastic computing relies on a substantial number of random number generators to produce stochastic bit streams, which occupy extra hardware resources and increase circuit area and complexity.
To verify the relationship between the accuracy of stochastic computing multiplications and additions and the length of the bit stream,
Figure 3 presents a 5 × 5 convolution kernel using both unipolar and bipolar encoding methods for multiplication, with accumulation performed via APC adder circuits. The results are compared with the binary results (all binary values used in this paper are full-precision binary). As shown in the figure, the accuracy of multiplication–accumulation computations depends on the length of the input stochastic bit stream—longer bit streams yield more accurate results. Under the same bit stream length, unipolar stochastic computing exhibits a lower standard deviation from binary computation results than bipolar stochastic computing. This is because bipolar stochastic computing represents values in the range of [−1, 1], doubling the range of unipolar stochastic computing [0, 1], but at the cost of reduced resolution, leading to lower accuracy compared to unipolar encoding of the same length.
While increasing the bit stream length improves computational accuracy, it also introduces significant computational latency and energy consumption issues. To address bit stream correlation problems, J. Alspector et al. [
23] attempted to generate uncorrelated bit streams using multiple pseudo-random sources, but their approach still required substantial hardware resources. Gschwind, Michael et al. [
24] reduced the number of required random sources by encoding one of the stochastic bit streams deterministically during multiplication; however, their method still consumed considerable hardware resources. Therefore, how to leverage the advantages of low-cost stochastic computing circuits in hardware neural networks while reducing the cost and energy consumption of input bit stream generation and achieving high computational accuracy with shorter input bit streams are the key to the edge-side high-efficiency neural network circuit design in this paper.
5. Conclusions and Outlook
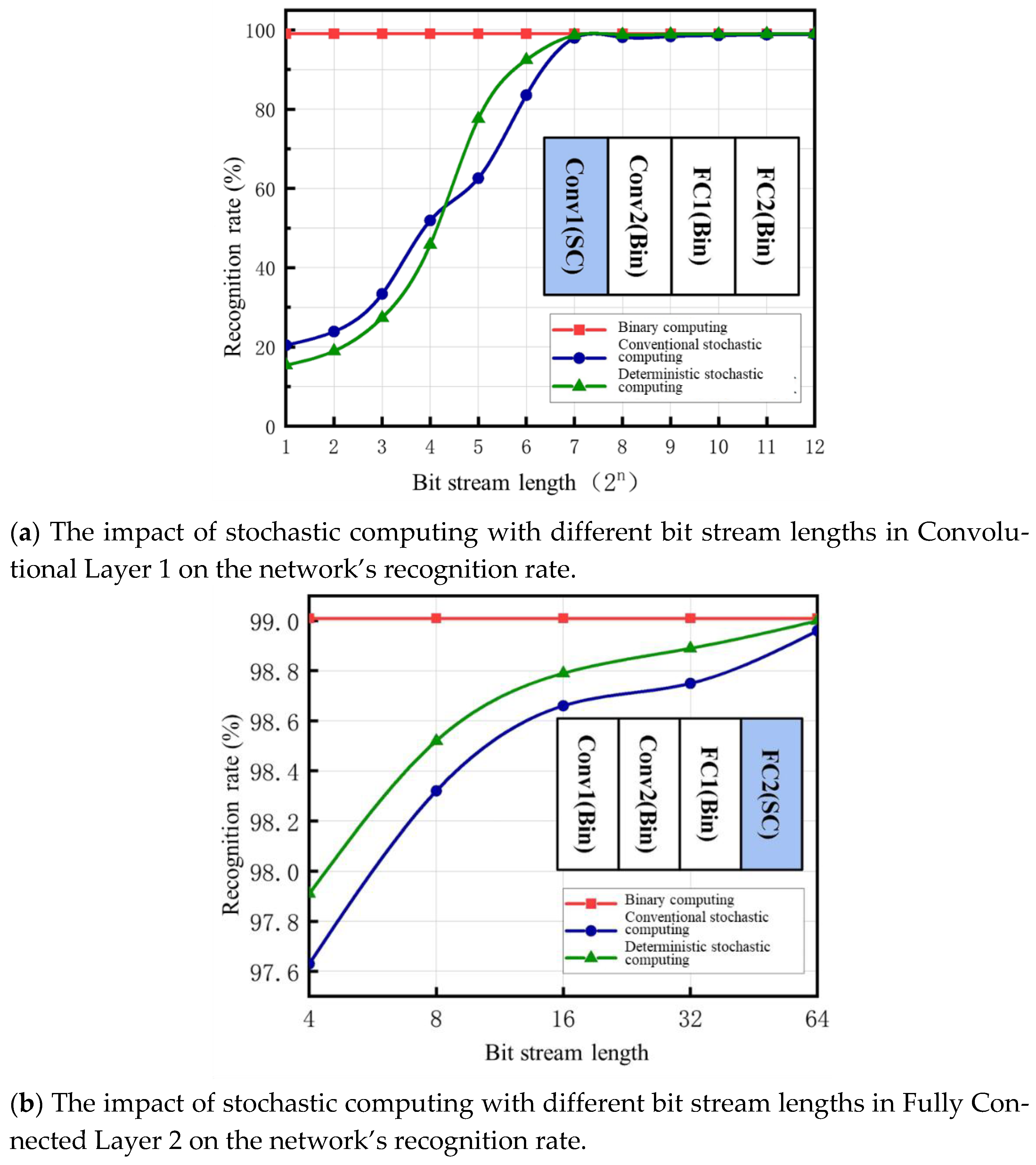
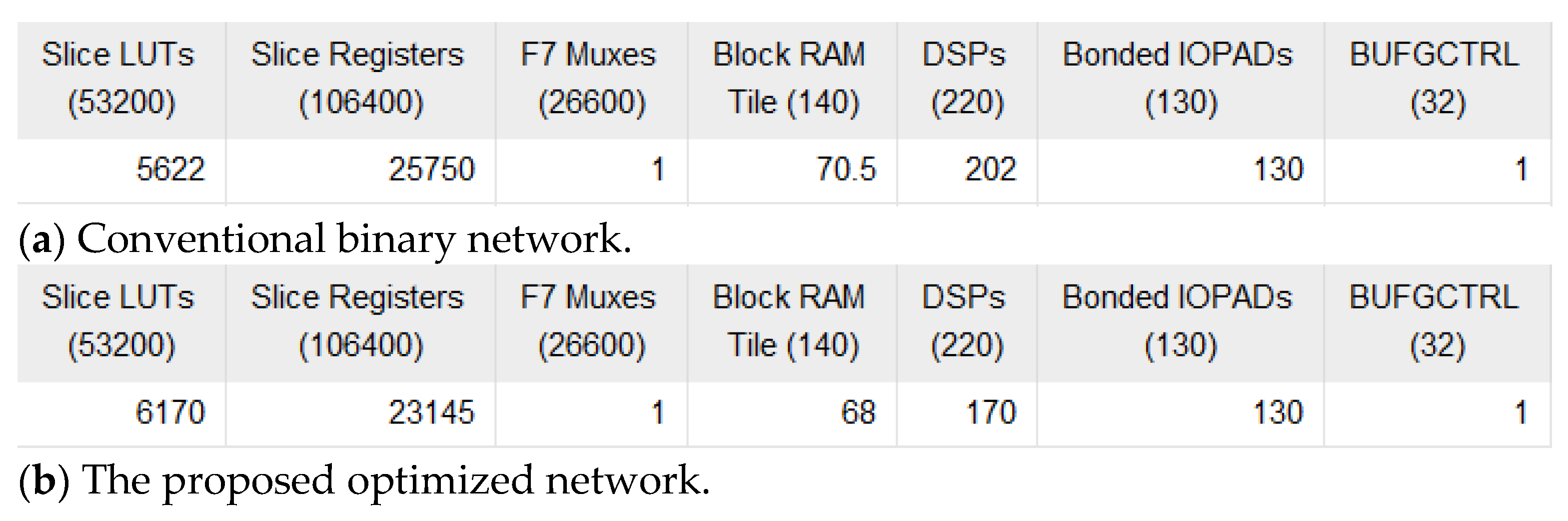
In summary, this study significantly enhances the efficiency of stochastic computing in convolutional neural networks for image classification through an innovative encoding approach, improved input data processing, and collaborative optimization of the network training process. The proposed method enables low-cost, high-efficiency convolutional operations under short bit stream inputs, achieving high recognition performance with minimal bit stream length while significantly reducing system latency and power consumption. Compared to traditional stochastic computing networks, the proposed design shortens the bit stream length by 64 times without compromising recognition accuracy, achieving a 99% recognition rate with a 2-bit input. Compared to the conventional 2-bit stochastic computing approach, the proposed design reduces area by 44.98%, power consumption by 60.47%, and improves energy efficiency by 12 times. Compared to the traditional 256-bit stochastic computing scheme, the area is reduced by 82.87%, while energy efficiency increases by 1947 times. Compared to conventional binary designs, the proposed method reduces area by 73.56%, power consumption by 57.38%, and improves energy efficiency by 3.7 times. These comparative results demonstrate that the proposed design offers significant advantages for tasks such as image classification in near-sensor and edge computing environments, providing an effective solution for high-efficiency, low-cost hardware neural networks.
For future research, the applicability of this method could be further explored in more complex scenarios: First, for large-scale datasets like ImageNet, the input RGB data could be preprocessed into single-channel grayscale images and represented with extended bitstream length. This adaptation would theoretically enable our co-optimization approach to be applied to ImageNet-compatible architectures such as AlexNet. Second, in speech recognition applications, the short-time Fourier transform (STFT) spectrum of speech signals can be directly encoded into PWM-type deterministic bitstreams. Leveraging the inherent sparsity of speech spectra, the weights of the first convolutional layer can be constrained to binary values (−1/1) while appropriately increasing bitstream length to achieve speech recognition functionality. Comprehensive evaluation of hardware costs and reliability in practical deployments will facilitate the application of this method in broader edge computing scenarios.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}