Figure 1.
The 3D layout of our convenience store environment: hand and gaze information indicate product engagement and customer interests.
Figure 1.
The 3D layout of our convenience store environment: hand and gaze information indicate product engagement and customer interests.
Figure 2.
Reconstruction of the retail environment. (a) Top-view layout of the room showing camera locations. (b) Final reconstructed model of the retail space, featuring shelves positioned according to real-world measurements and integrated camera placements derived from marker detection.
Figure 2.
Reconstruction of the retail environment. (a) Top-view layout of the room showing camera locations. (b) Final reconstructed model of the retail space, featuring shelves positioned according to real-world measurements and integrated camera placements derived from marker detection.
Figure 3.
Sample frames from the evaluation dataset showing subjects in motion capture suits performing various actions. These examples illustrate the different perspectives provided by the motion capture system and the installed cameras.
Figure 3.
Sample frames from the evaluation dataset showing subjects in motion capture suits performing various actions. These examples illustrate the different perspectives provided by the motion capture system and the installed cameras.
Figure 4.
Comparison of original and reconstructed 3D keypoints. This figure displays the reprojected 2D keypoints used to reconstruct the 3D keypoints alongside the original motion capture data.
Figure 4.
Comparison of original and reconstructed 3D keypoints. This figure displays the reprojected 2D keypoints used to reconstruct the 3D keypoints alongside the original motion capture data.
Figure 5.
Illustration of the stereo camera setup used to reconstruct a 3D point () from its 2D projections (), (), and () in three different cameras (a fisheye camera, Cam1, and Cam2). By applying the transformation matrices , , , we can triangulate and recover the 3D location of the point in the world coordinate system.
Figure 5.
Illustration of the stereo camera setup used to reconstruct a 3D point () from its 2D projections (), (), and () in three different cameras (a fisheye camera, Cam1, and Cam2). By applying the transformation matrices , , , we can triangulate and recover the 3D location of the point in the world coordinate system.
Figure 6.
Overview of the product engagement pipeline. The figure illustrates the process of capturing synchronized multi-view video streams to detect and track individuals, estimate human poses and gaze, and localize hand positions. These integrated steps enable the analysis of both visual attention and physical interactions with products in retail environments.
Figure 6.
Overview of the product engagement pipeline. The figure illustrates the process of capturing synchronized multi-view video streams to detect and track individuals, estimate human poses and gaze, and localize hand positions. These integrated steps enable the analysis of both visual attention and physical interactions with products in retail environments.
Figure 7.
Overview of the Transformer-based skeleton encoder for 3D gaze estimation. This model processes raw 3D skeleton keypoints by first projecting them through a linear layer with positional embeddings to form tokens that are input into a Transformer encoder. The encoder captures spatial relationships among the keypoints to generate a comprehensive skeletal representation. Dedicated regression streams then separately extract head and body features, which are fused to produce the final 3D gaze predictions. The Transformer’s hidden-layer dimension is set to 768 to match the embedding size of CLIP ViT-B-32’s projection head [
51], which ensures consistency with established Transformer-based encoder designs. By relying on structural pose information rather than raw RGB data, this approach remains robust against background and environmental variations.
Figure 7.
Overview of the Transformer-based skeleton encoder for 3D gaze estimation. This model processes raw 3D skeleton keypoints by first projecting them through a linear layer with positional embeddings to form tokens that are input into a Transformer encoder. The encoder captures spatial relationships among the keypoints to generate a comprehensive skeletal representation. Dedicated regression streams then separately extract head and body features, which are fused to produce the final 3D gaze predictions. The Transformer’s hidden-layer dimension is set to 768 to match the embedding size of CLIP ViT-B-32’s projection head [
51], which ensures consistency with established Transformer-based encoder designs. By relying on structural pose information rather than raw RGB data, this approach remains robust against background and environmental variations.
Figure 8.
Examples from the fine-tuning dataset. The figure displays sample frames captured by the fisheye and perspective cameras in our simulated retail setup, featuring participants wearing eye trackers and chest-mounted GoPro cameras.
Figure 8.
Examples from the fine-tuning dataset. The figure displays sample frames captured by the fisheye and perspective cameras in our simulated retail setup, featuring participants wearing eye trackers and chest-mounted GoPro cameras.
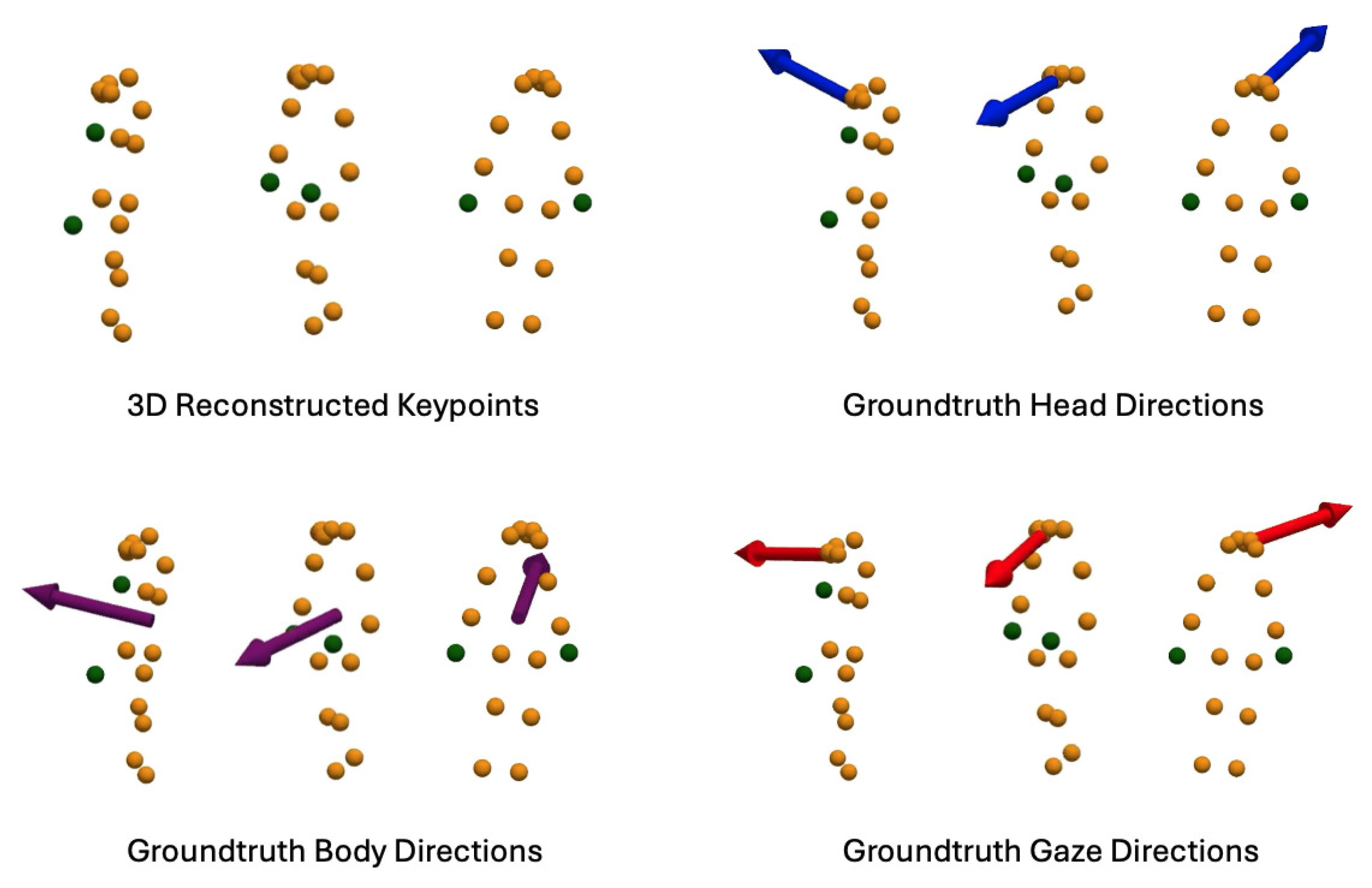
Figure 9.
Examples from the fine-tuning dataset for the Transformer-based skeleton encoder. This dataset comprises reconstructed 3D skeleton keypoints, ground truth head directions from the eye tracker’s world camera, ground truth body directions from the GoPro camera, and ground truth gaze directions from the eye tracker’s eye cameras.
Figure 9.
Examples from the fine-tuning dataset for the Transformer-based skeleton encoder. This dataset comprises reconstructed 3D skeleton keypoints, ground truth head directions from the eye tracker’s world camera, ground truth body directions from the GoPro camera, and ground truth gaze directions from the eye tracker’s eye cameras.
Figure 10.
Overview of the product engagement data collection setup. This figure displays the arrangement of eight product item categories (A–H) on the top of shelves within the experimental environment.
Figure 10.
Overview of the product engagement data collection setup. This figure displays the arrangement of eight product item categories (A–H) on the top of shelves within the experimental environment.
Figure 11.
Sample frames from the product engagement dataset captured in both perspective and fisheye views. This figure illustrates subjects interacting with products via gaze and hand actions within the simulated retail environment.
Figure 11.
Sample frames from the product engagement dataset captured in both perspective and fisheye views. This figure illustrates subjects interacting with products via gaze and hand actions within the simulated retail environment.
Figure 12.
Visualization of gaze points collected by the eye trackers (localized in world coordinates using AprilTag markers), overlaid on the scene. This figure demonstrates how gaze annotations correspond to product regions on the shelves and validates cases where the subject continues to gaze at a product after picking it up.
Figure 12.
Visualization of gaze points collected by the eye trackers (localized in world coordinates using AprilTag markers), overlaid on the scene. This figure demonstrates how gaze annotations correspond to product regions on the shelves and validates cases where the subject continues to gaze at a product after picking it up.
Figure 13.
Qualitative comparison of gaze estimation methods. Each column represents a different time frame t, while each row corresponds to a specific gaze estimation method. Orange dots indicate the subject’s 3D skeleton keypoints, red arrows denote the ground truth gaze direction, and green arrows represent the model’s predicted gaze direction.
Figure 13.
Qualitative comparison of gaze estimation methods. Each column represents a different time frame t, while each row corresponds to a specific gaze estimation method. Orange dots indicate the subject’s 3D skeleton keypoints, red arrows denote the ground truth gaze direction, and green arrows represent the model’s predicted gaze direction.
Figure 14.
Comparison of accuracy, balanced accuracy, and weighted F1 across three evaluation cases (label shelf, label product, and label both) for each camera configuration. Our method still struggles to detect engagement once a product is held, as reflected by lower scores in the “label” product and “label both” cases. The asterisk “*” denotes the configurations where a 15 cm distance compensation is applied to the wrist skeleton and hand location.
Figure 14.
Comparison of accuracy, balanced accuracy, and weighted F1 across three evaluation cases (label shelf, label product, and label both) for each camera configuration. Our method still struggles to detect engagement once a product is held, as reflected by lower scores in the “label” product and “label both” cases. The asterisk “*” denotes the configurations where a 15 cm distance compensation is applied to the wrist skeleton and hand location.
Figure 15.
Normalized confusion matrices for hand-object engagement (label shelf case) using a green color scale: darker greens indicate higher values, while lighter greens indicate lower values. (
a) All Cameras configuration. (
b) All Cameras* configuration. The higher diagonal values in (
b) indicate improved classification accuracy and fewer misclassifications for product labels; however, these matrices do not capture the false-positive detections observed in
Figure 16, as they only evaluate frames with a product ground truth annotation.
Figure 15.
Normalized confusion matrices for hand-object engagement (label shelf case) using a green color scale: darker greens indicate higher values, while lighter greens indicate lower values. (
a) All Cameras configuration. (
b) All Cameras* configuration. The higher diagonal values in (
b) indicate improved classification accuracy and fewer misclassifications for product labels; however, these matrices do not capture the false-positive detections observed in
Figure 16, as they only evaluate frames with a product ground truth annotation.
Figure 16.
Comparison of detected hand-object engagement versus ground truth for the label shelf case across four test videos. The orange dashed line indicates the predicted shelf labels, while the blue solid line represents the ground truth over consecutive frames. Plots (a,c,e,g) correspond to the All Cameras configuration, and plots (b,d,f,h) correspond to the All Cameras* configuration.
Figure 16.
Comparison of detected hand-object engagement versus ground truth for the label shelf case across four test videos. The orange dashed line indicates the predicted shelf labels, while the blue solid line represents the ground truth over consecutive frames. Plots (a,c,e,g) correspond to the All Cameras configuration, and plots (b,d,f,h) correspond to the All Cameras* configuration.
Figure 17.
Example frames from test videos illustrating false-positive hand-object engagement detections; (a) is from test video 1, frame 1400, where the false-positive detection occurs (“E”); (b) is from test video 2, frame 1080, where the false-positive detection occurs (“B”); (c) is from test video 3, frame 1300, where the false-positive detection occurs (“E”); and (d) is from test video 4, frame 1830, where the false-positive detection occurs (“H”).
Figure 17.
Example frames from test videos illustrating false-positive hand-object engagement detections; (a) is from test video 1, frame 1400, where the false-positive detection occurs (“E”); (b) is from test video 2, frame 1080, where the false-positive detection occurs (“B”); (c) is from test video 3, frame 1300, where the false-positive detection occurs (“E”); and (d) is from test video 4, frame 1830, where the false-positive detection occurs (“H”).
Figure 18.
Performance of gaze-object engagement detection across various camera configurations and labeling scenarios, evaluated by accuracy (blue), balanced accuracy (orange), and weighted F1 (green).
Figure 18.
Performance of gaze-object engagement detection across various camera configurations and labeling scenarios, evaluated by accuracy (blue), balanced accuracy (orange), and weighted F1 (green).
Figure 19.
Confusion matrices for gaze-object engagement classification using a blue color scale: darker blues indicate higher values, while lighter blues indicate lower values. Confusion matrices for four gaze estimation methods reveal challenges in accurately classifying gaze-object engagement, with frequent misclassifications evident from low diagonal values.
Figure 19.
Confusion matrices for gaze-object engagement classification using a blue color scale: darker blues indicate higher values, while lighter blues indicate lower values. Confusion matrices for four gaze estimation methods reveal challenges in accurately classifying gaze-object engagement, with frequent misclassifications evident from low diagonal values.
Figure 20.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 1.
Figure 20.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 1.
Figure 21.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 2.
Figure 21.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 2.
Figure 22.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 3.
Figure 22.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 3.
Figure 23.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 4.
Figure 23.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 4.
Figure 24.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 5.
Figure 24.
Comparison of ground truth (red) and predicted (blue) gaze directions for the label shelf case on test video 5.
Figure 25.
Example frame from test video 1 at frame 900 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 25.
Example frame from test video 1 at frame 900 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 26.
Example frame from test video 2 at frame 750 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 26.
Example frame from test video 2 at frame 750 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 27.
Example frame from test video 3 at frame 400 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 27.
Example frame from test video 3 at frame 400 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 28.
Example frame from test video 4 at frame 750 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 28.
Example frame from test video 4 at frame 750 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 29.
Example frame from test video 5 at frame 1530 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 29.
Example frame from test video 5 at frame 1530 illustrating gaze-object engagement detection using different gaze estimation methods. Red arrows are ground-truth gaze vectors; green arrows are model gaze estimates; blue arrows are head-keypoint gaze estimates.
Figure 30.
Predicted hand-object and gaze-object engagements across five test videos, illustrating brief physical interactions versus extended visual attention.
Figure 30.
Predicted hand-object and gaze-object engagements across five test videos, illustrating brief physical interactions versus extended visual attention.
Table 1.
Numerical summary of the dataset used for evaluating reconstructed 3D keypoints. For each action, the table lists the number of videos recorded from four modalities (Cam1, Cam2, fisheye, and MoCap), along with the number of synchronized frames and total 3D keypoints captured by the motion capture system.
Table 1.
Numerical summary of the dataset used for evaluating reconstructed 3D keypoints. For each action, the table lists the number of videos recorded from four modalities (Cam1, Cam2, fisheye, and MoCap), along with the number of synchronized frames and total 3D keypoints captured by the motion capture system.
| Actions | Side-View Cam 1 | Side-View Cam 2 | Fisheye | MoCap | #Sync Frames | #Keypoints |
|---|
| Pick Items | 15 videos | 15 videos | 15 videos | 15 videos | 2471 | 96,369 |
| Return Items | 15 videos | 15 videos | 15 videos | 15 videos | 2385 | 93,015 |
| Read Labels | 15 videos | 15 videos | 15 videos | 15 videos | 3826 | 149,214 |
| Put in Basket | 15 videos | 15 videos | 15 videos | 15 videos | 2225 | 86,775 |
| Check Watch | 15 videos | 15 videos | 15 videos | 15 videos | 3497 | 136,383 |
| Total | 75 videos | 75 videos | 75 videos | 75 videos | 14,404 | 561,756 |
Table 2.
Overview of the fine-tuning dataset. This table presents the number of videos and frames in the training, validation, and test sets for both perspective and fisheye views, summarizing the key details of the dataset used to fine-tune the gaze estimation model.
Table 2.
Overview of the fine-tuning dataset. This table presents the number of videos and frames in the training, validation, and test sets for both perspective and fisheye views, summarizing the key details of the dataset used to fine-tune the gaze estimation model.
| Category | Perspective View | Fisheye View |
|---|
| No. of videos | 476 videos | 104 videos |
| Train set | 350 videos, 1,684,922 frames | 64 videos, 223,779 frames |
| Validation set | 60 videos, 316,092 frames | 20 videos, 85,715 frames |
| Test set | 66 videos, 335,124 frames | 20 videos, 76,052 frames |
Table 3.
Summary of gaze and hand interaction cases. This table outlines the different scenarios in which subjects engaged with products, either by looking at them or picking them from the shelves.
Table 3.
Summary of gaze and hand interaction cases. This table outlines the different scenarios in which subjects engaged with products, either by looking at them or picking them from the shelves.
| Case | Gaze-Object | Hand-Object |
|---|
| 1 | A, B, C | D, E, F |
| 2 | E, F, G | B, C, D |
| 3 | B, C, D | A, E, F |
| 4 | A, C, E | F, G, H |
| 5 | E, G, H | A, B, C |
Table 4.
Detailed summary of the product engagement dataset. This table presents the number of videos and frames captured for the experiment, along with relevant metadata for each recording condition.
Table 4.
Detailed summary of the product engagement dataset. This table presents the number of videos and frames captured for the experiment, along with relevant metadata for each recording condition.
| | Perspective View | Fisheye View |
|---|
| No. of videos | 52 videos | 26 videos |
| Test set | 52 videos, 92,514 frames | 26 videos, 46,257 frames |
Table 5.
Evaluation of a 3D reconstruction of keypoints.
Table 5.
Evaluation of a 3D reconstruction of keypoints.
| Cameras | MSE (m2) | RMSE (mm) |
|---|
| All Cameras | 0.000524 | 22.89 |
| Cam1 & Fisheye | 0.000576 | 24.01 |
| Cam2 & Fisheye | 0.003501 | 59.17 |
| Cam1 & Cam2 | | |
Table 6.
Ablation study and inference time comparison of skeleton-to-gaze and D3DGaze models on the fine-tuning dataset. The table reports the 3D mean angular error (MAE) and inference speed in frames per second (FPS). Variants of the skeleton-to-gaze model are evaluated by removing the head or body loss component to assess their impact on performance.
Table 6.
Ablation study and inference time comparison of skeleton-to-gaze and D3DGaze models on the fine-tuning dataset. The table reports the 3D mean angular error (MAE) and inference speed in frames per second (FPS). Variants of the skeleton-to-gaze model are evaluated by removing the head or body loss component to assess their impact on performance.
| Method | 3D MAE (°) | Inference Time (FPS) |
|---|
| D3DGaze (NF) | 34.19 | 1476.51 |
| D3DGaze | 31.05 | 1482.31 |
| Skeleton-to-gaze (ours) | 29.83 | 2401.32 |
| Skeleton-to-gaze (w/o head loss) | 30.67 | 2460.25 |
| Skeleton-to-gaze (w/o body loss) | 31.74 | 2469.59 |
Table 7.
Evaluation of gaze estimation methods on the product engagement dataset.
Table 7.
Evaluation of gaze estimation methods on the product engagement dataset.
| Method | 3D MAE (°) | No. of Parameters |
|---|
| Head keypoints | 35.50 | - |
| Skeleton-to-gaze (ours) | 29.13 | 88.07 M |
| D3DGaze (NF) | 23.31 | 9.465 M |
| D3DGaze | 25.33 | 9.465 M |
Table 8.
Evaluation metrics (accuracy, balanced accuracy, and weighted F1) for hand-object engagement detection on 2440 “label shelf” frames. The “Cameras Used” column reflects various configurations.
Table 8.
Evaluation metrics (accuracy, balanced accuracy, and weighted F1) for hand-object engagement detection on 2440 “label shelf” frames. The “Cameras Used” column reflects various configurations.
| Cameras Used | Ground Truth | No. Frames | Accuracy | Balanced Accuracy | Weighted F1 |
|---|
| All Cameras | Label Shelf | 2440 | 0.7910 | 0.8126 | 0.8724 |
| All Cameras * | Label Shelf | 2440 | 0.8385 | 0.8550 | 0.8994 |
| Cam1,Cam2 | Label Shelf | 2440 | 0.5988 | 0.6055 | 0.6794 |
| Cam1,Cam2 * | Label Shelf | 2440 | 0.6824 | 0.6859 | 0.7196 |
| FisheyeCam2 | Label Shelf | 2440 | 0.5811 | 0.6010 | 0.6691 |
| FisheyeCam2 * | Label Shelf | 2440 | 0.6197 | 0.6351 | 0.6970 |
| FisheyeCam1 | Label Shelf | 2,440 | 0.7004 | 0.7275 | 0.8003 |
| FisheyeCam1 * | Label Shelf | 2440 | 0.7795 | 0.7946 | 0.8488 |
Table 9.
Evaluation of gaze-object engagement detection on the product engagement dataset.
Table 9.
Evaluation of gaze-object engagement detection on the product engagement dataset.
| Method | Cameras Used | Ground Truth | No. Frames | Accuracy | Balanced Accuracy | Weighted F1 |
|---|
| Head keypoints | All Cameras | Label Shelf | 27,702 | 0.1754 | 0.1825 | 0.2692 |
| Head keypoints | All Cameras | Label Product | 11,927 | 0.1836 | 0.2186 | 0.2681 |
| Head keypoints | All Cameras | Label Both | 35,812 | 0.1725 | 0.1458 | 0.2627 |
| D3DGaze (NF) | All Cameras | Label Shelf | 27,702 | 0.4799 | 0.4668 | 0.6225 |
| D3DGaze (NF) | All Cameras | Label Product | 11,927 | 0.3407 | 0.3419 | 0.4520 |
| D3DGaze (NF) | All Cameras | Label Both | 35,812 | 0.4361 | 0.3375 | 0.5718 |
| D3DGaze | All Cameras | Label Shelf | 27,702 | 0.5245 | 0.5167 | 0.6653 |
| D3DGaze | All Cameras | Label Product | 11,927 | 0.4213 | 0.4536 | 0.5464 |
| D3DGaze | All Cameras | Label Both | 35,812 | 0.4922 | 0.3871 | 0.6326 |
| Skeleton-to-gaze | All Cameras | Label Shelf | 27,702 | 0.5047 | 0.5019 | 0.6410 |
| Skeleton-to-gaze | All Cameras | Label Product | 11,927 | 0.4719 | 0.4846 | 0.5858 |
| Skeleton-to-gaze | All Cameras | Label Both | 35,812 | 0.5023 | 0.3989 | 0.6324 |

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}