An Improved Method for Enhancing the Accuracy and Speed of Dynamic Object Detection Based on YOLOv8s

Abstract
1. Introduction
- (1)
- The proposed method introduces a Focused Linear Attention mechanism into the YOLOv8s network to improve dynamic object detection accuracy; this module focuses on key features more effectively.
- (2)
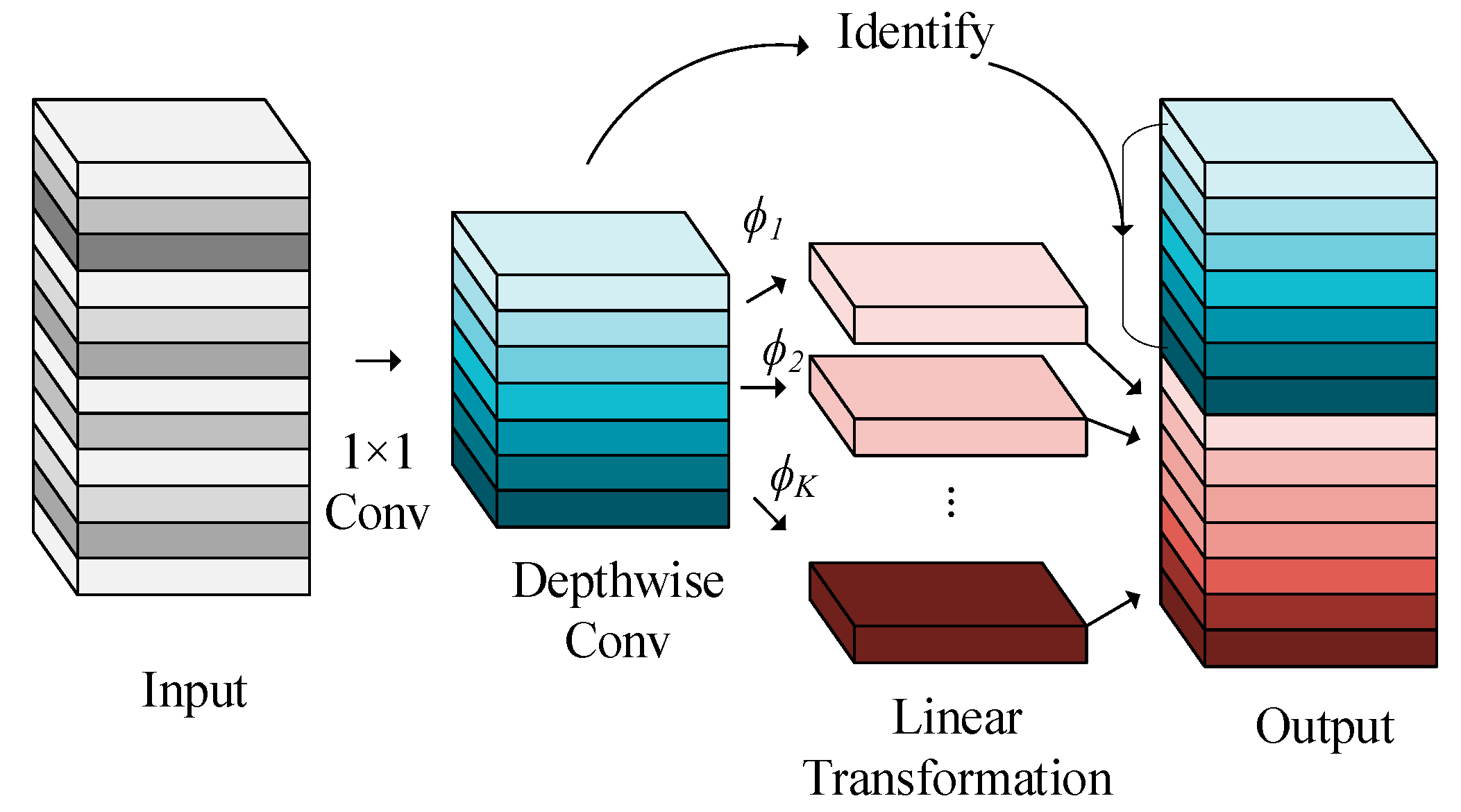
- Inspired by the Ghost module, the proposed method introduces Ghost convolution to replace the original convolution, reducing computational load. The model is further lightweighted on the basis of the optimized computational efficiency of the Focused Linear Attention mechanism.
- (3)
- The proposed method uses VariFocal Loss as the classification loss function to optimize the network’s loss function, addressing the problem of imbalance between positive and negative samples caused by sample unevenness.
2. Related Work
2.1. Frame Difference-Based Methods
2.2. Optical Flow-Based Methods
2.3. Deep Learning-Based Methods
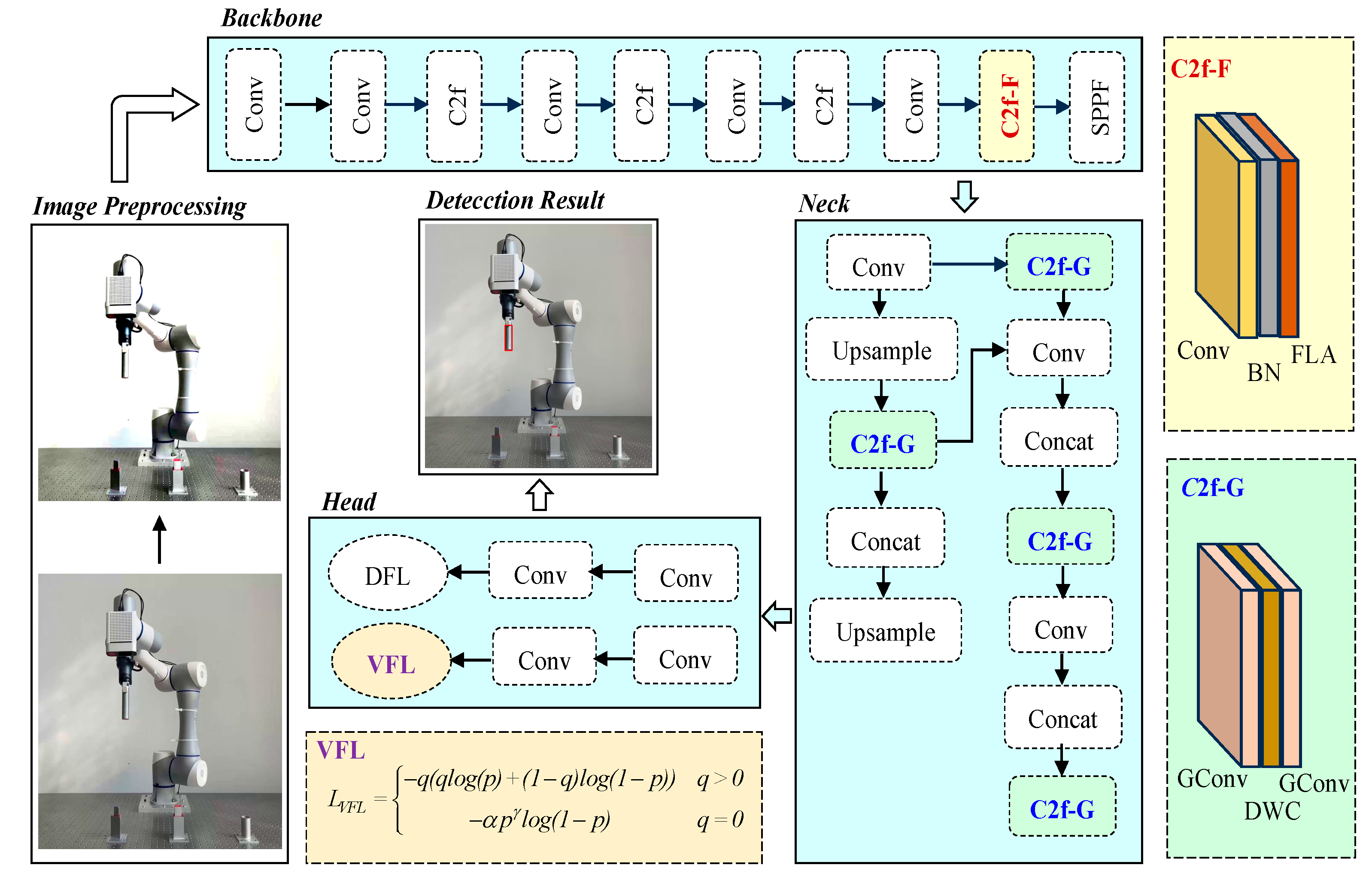
3. Proposed Method
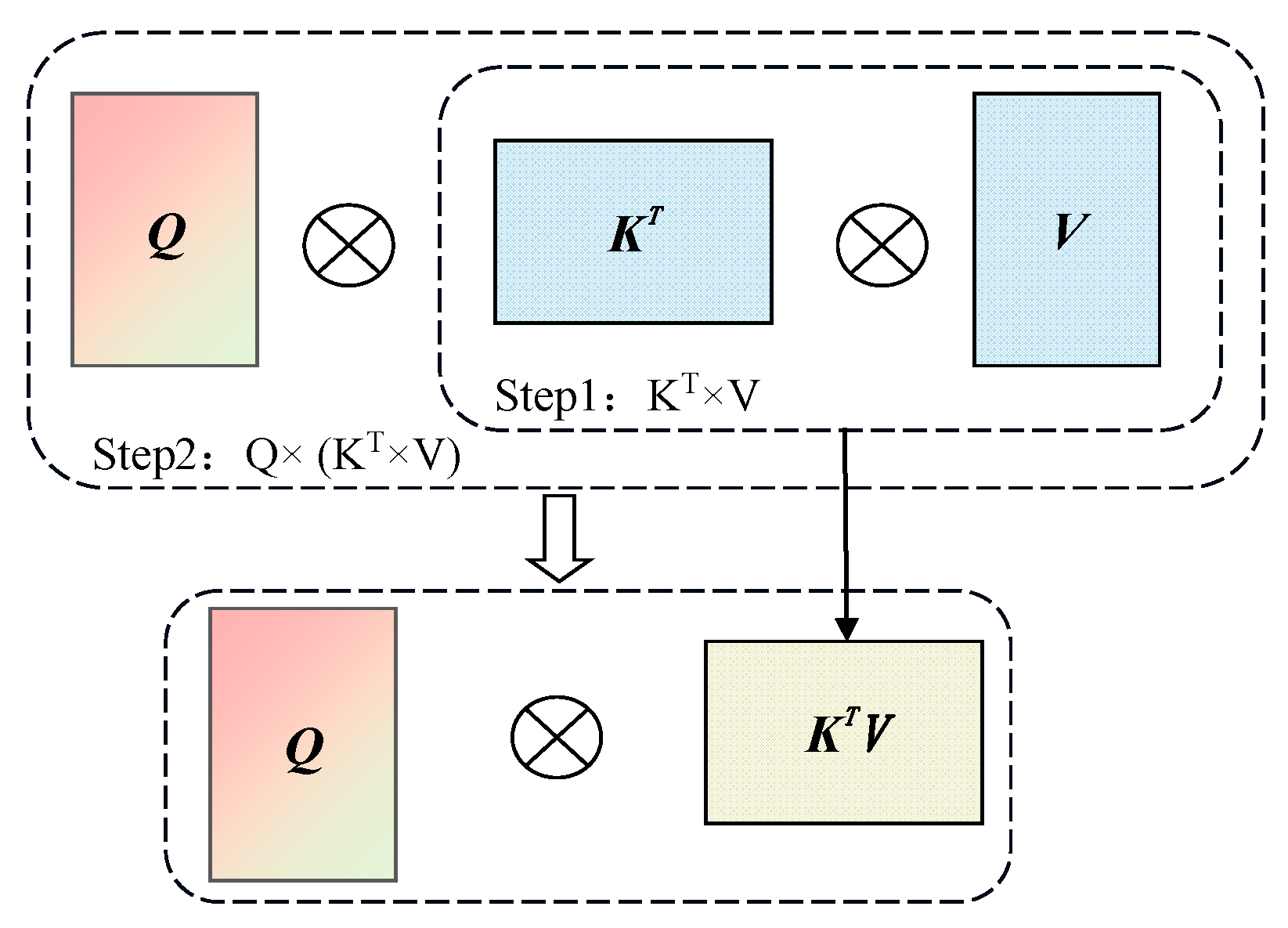
3.1. Improved YOLOv8s Backbone with C2f-F
3.2. Improved YOLOv8s Neck with C2f-G
3.3. Loss Function
3.4. Experimental Study
3.4.1. Datasets
3.4.2. Experimental Setup
3.4.3. Evaluation Metrics
4. Experimental Results
4.1. Ablation Study
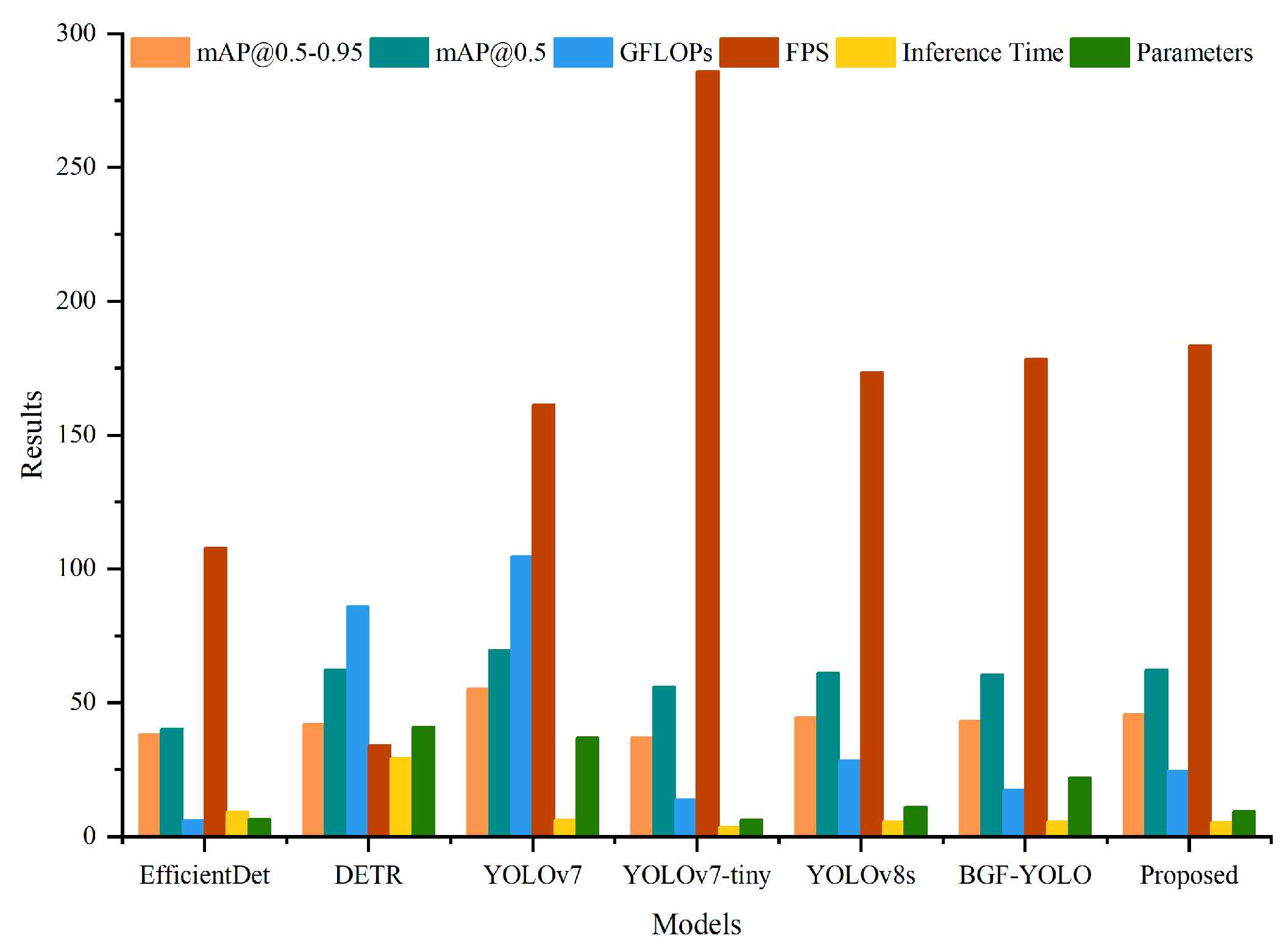
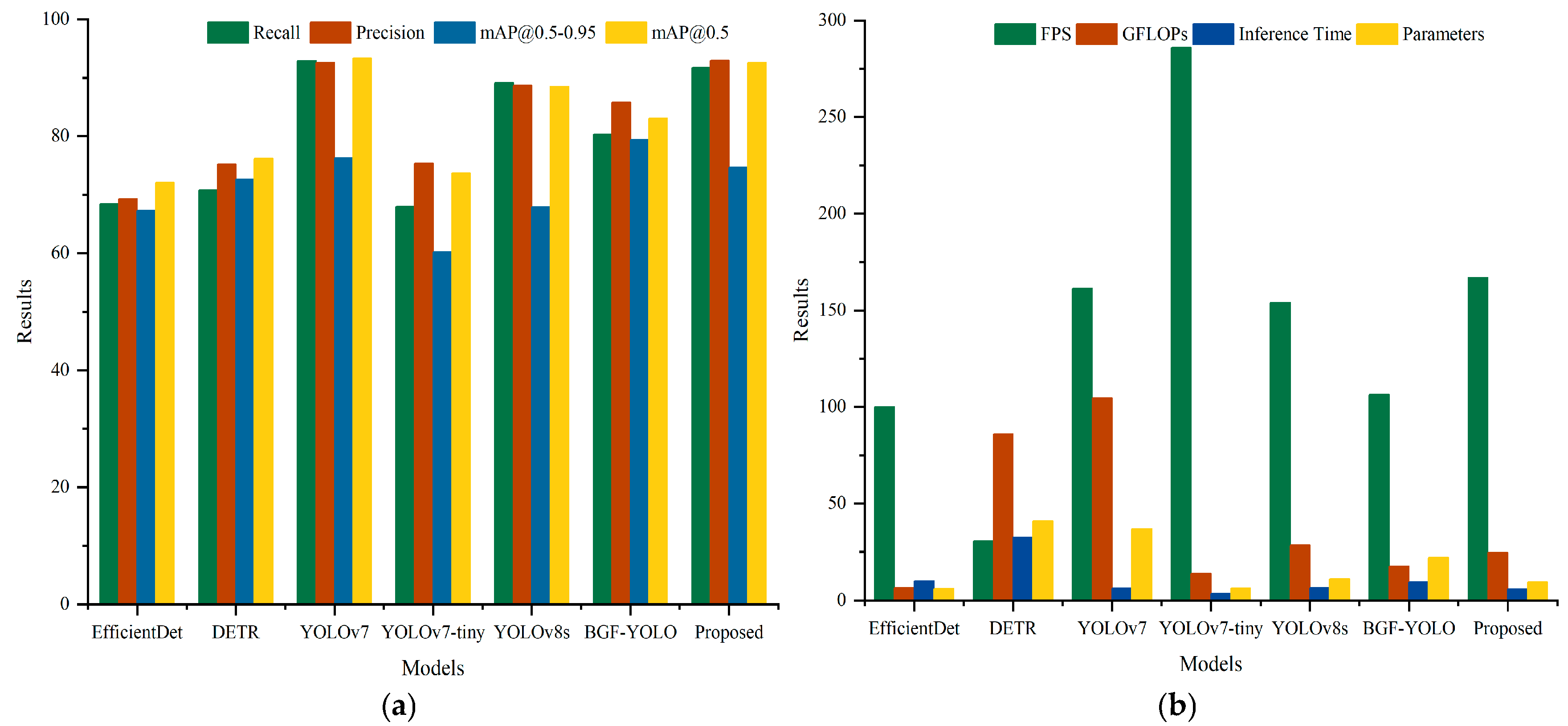
4.2. Comparative Experiments on Public Datasets
4.3. Comparative Experiments on the Custom Dataset
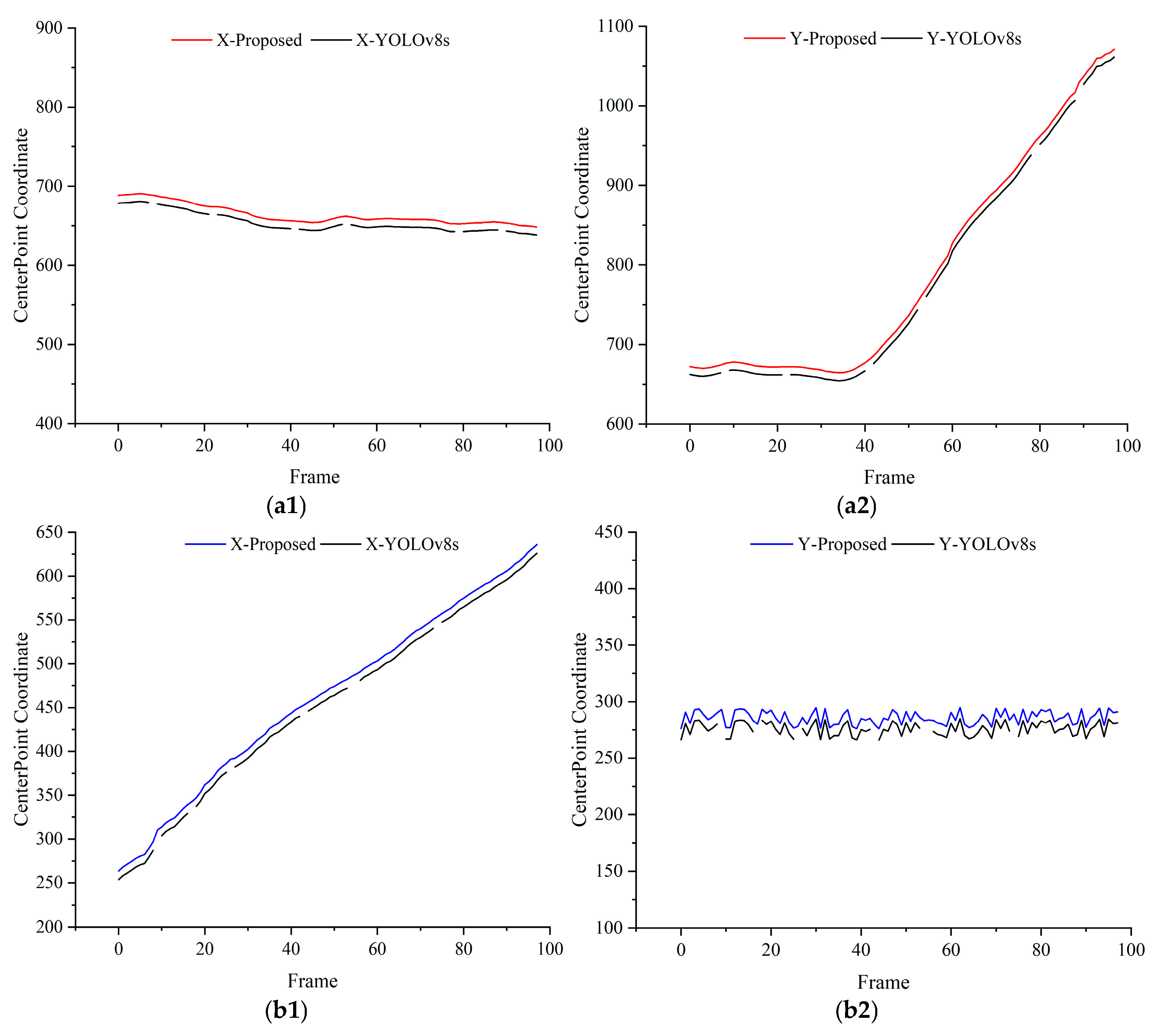
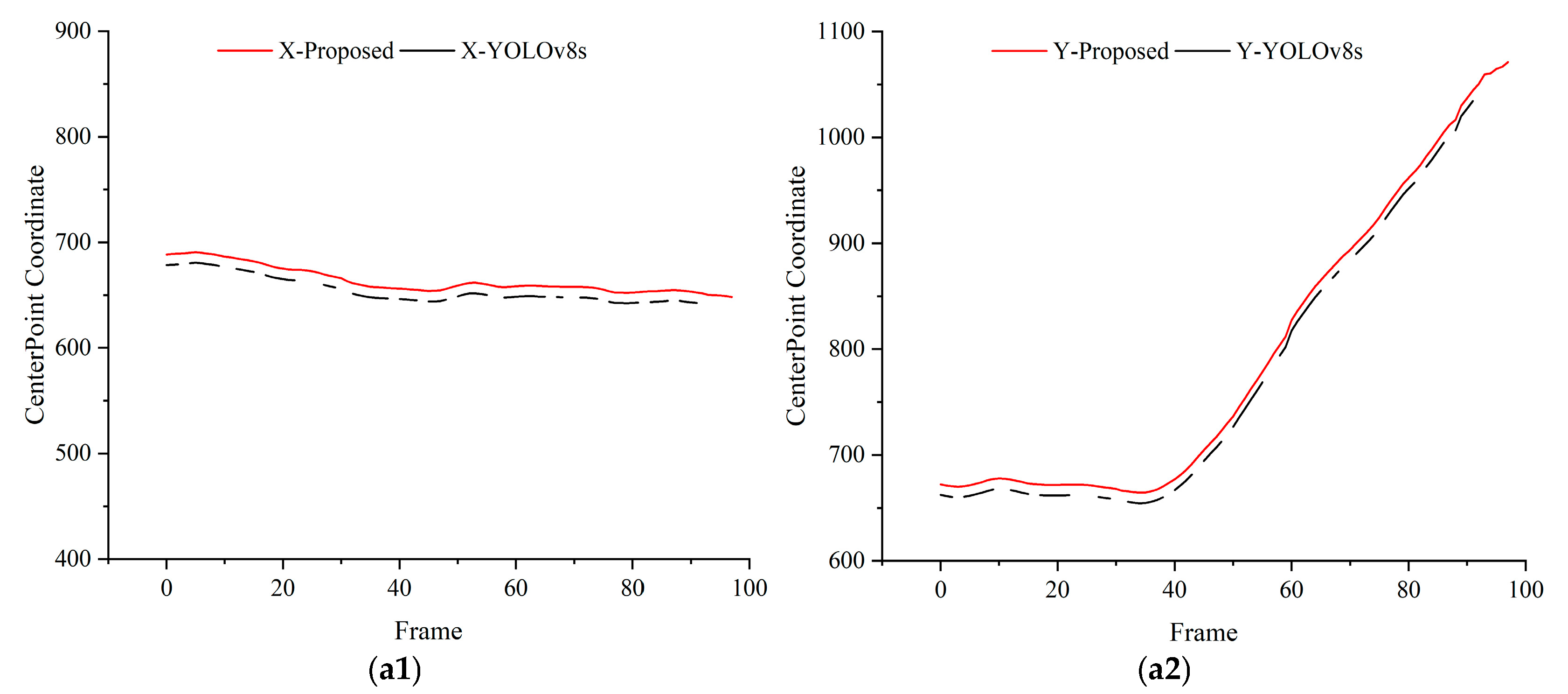
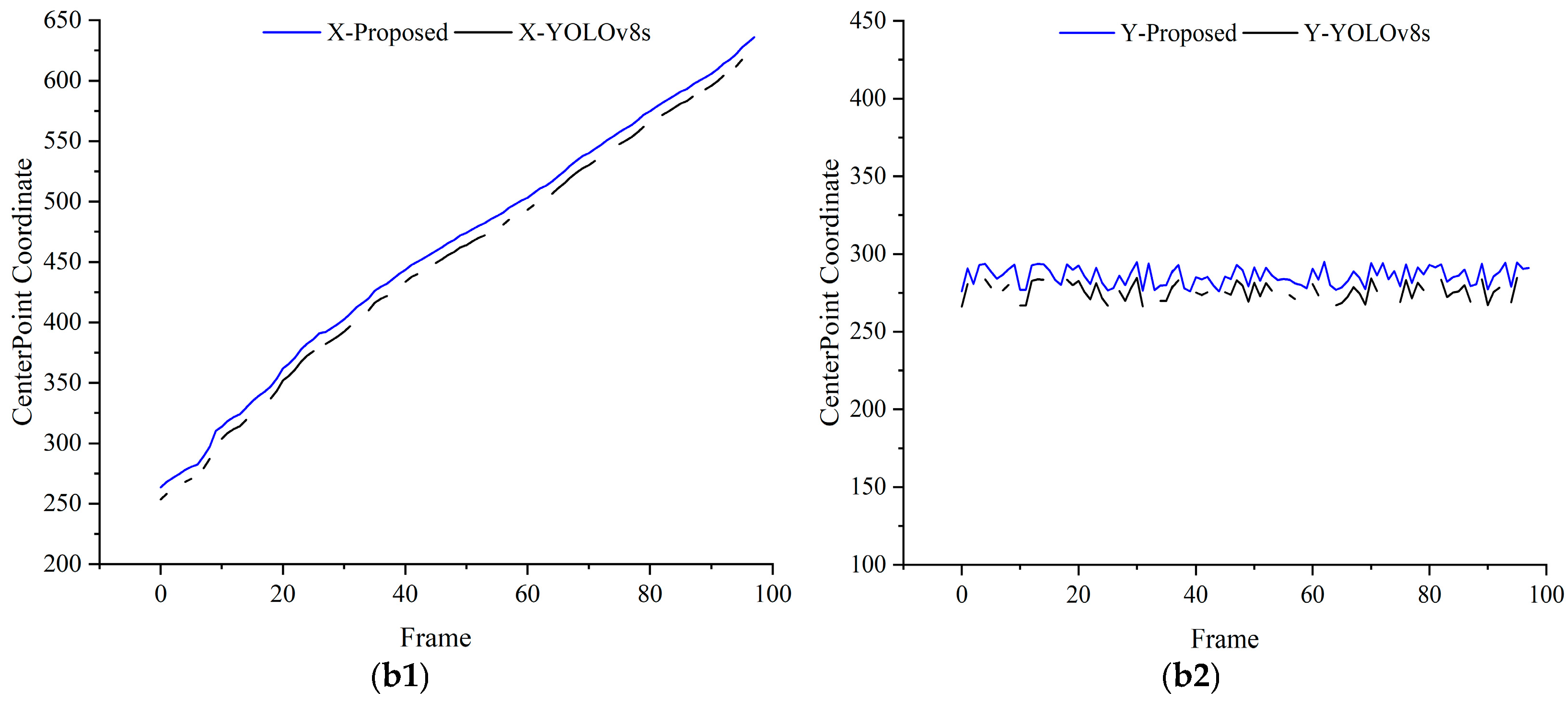
4.4. Validation Experiments for Dynamic Object Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human-Computer Interaction. IEEE Trans. Ind. Inf. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Dos Reis, D.H.; Welfer, D.; Cuadros, M.A.; Gamarra, D.F. Object Recognition Software Using RGBD Kinect Images and the YOLO Algorithm for Mobile Robot Navigation. In Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2020; pp. 255–263. [Google Scholar]
- Wang, C.; Moqurrab, S.A.; Yoo, J. Face Recognition of Remote Teaching Video Image Based on Improved Frame Difference Method. Mobile Netw. Appl. 2023, 28, 995–1006. [Google Scholar] [CrossRef]
- Liu, Y.; Fu, Y.; Zhuan, Y.; He, X. High Dynamic Range Real-Time 3D Measurement Based on Fourier Transform Profilometry. Opt. Laser Technol. 2021, 138, 106833. [Google Scholar] [CrossRef]
- Hu, M.; Chen, Y.; Hu, H.; He, Z. Single Frame Digital Phase-Shift Fringe Projection Profilometry Based on Symmetry Transform. Opt. Eng. 2024, 63, 104106. [Google Scholar] [CrossRef]
- Zhong, M.; Hu, Z.; Duan, P.; Hu, X. Modulation Measurement Profilometry Based on One-Dimensional Frequency-Guided S-Transform. J. Phys. Conf. Ser. 2024, 2872, 012035. [Google Scholar] [CrossRef]
- Dai, M.; Peng, K.; Luo, M.; Huang, Y. Dynamic Phase Measuring Profilometry for Rigid Objects Based on Simulated Annealing. Appl. Opt. 2020, 59, 389–395. [Google Scholar] [CrossRef]
- Wang, Y.; Abd Rahman, A.H.; Nor Rashid, F.’A.; Razali, M.K.M. Tackling Heterogeneous Light Detection and Ranging-Camera Alignment Challenges in Dynamic Environments: A Review for Object Detection. Sensors 2024, 24, 7855. [Google Scholar] [CrossRef] [PubMed]
- Tan, Q.; Du, Z.; Chen, S. Moving Target Detection Based on Background Modeling and Frame Difference. Procedia Comput. Sci. 2023, 221, 585–592. [Google Scholar] [CrossRef]
- Alfarano, A.; Maiano, L.; Papa, L.; Amerini, I. Estimating Optical Flow: A Comprehensive Review of the State of the Art. Comput. Vis. Image Underst. 2024, 2024, 104160. [Google Scholar] [CrossRef]
- Gude, G.N.M.R.; Karthikeyan, P.R. Frame Differencing, a Single Gaussian, and Modified GMM for Foreground Object Detection on Camera Jitter Movies in Comparison to F-Score Measurement. J. Surv. Fish. Sci. 2023, 10, 621–631. [Google Scholar]
- Saxena, S.; Herrmann, C.; Hur, J.; Kar, A.; Norouzi, M.; Sun, D.; Fleet, D.J. The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation. Adv. Neural Inf. Process. Syst. 2024, 36, 39443–39469. [Google Scholar]
- Liu, S.; Wang, Y.; Yu, Q.; Liu, Y. A Driver Fatigue Detection Algorithm Based on Dynamic Tracking of Small Facial Targets Using YOLOv7. IEICE Trans. Inf. Syst. 2023, 106, 1881–1890. [Google Scholar] [CrossRef]
- Cao, Z.; Liao, T.; Song, W.; Yang, F. Detecting the Shuttlecock for a Badminton Robot: A YOLO-Based Approach. Expert Syst. Appl. 2021, 164, 113833. [Google Scholar] [CrossRef]
- An, Y.; Li, Z.; Li, Y.; Zhang, K.; Zhu, Z.; Chai, Y. Few-Shot Learning-Based Fault Diagnosis Using Prototypical Contrastive-Based Domain Adaptation under Variable Working Conditions. IEEE Sens. J. 2024, 24, 25019–25029. [Google Scholar] [CrossRef]
- Li, J.; Wei, R.; Zhang, Q.; Shi, R.; Jiang, B. Research on Real-Time Roundup and Dynamic Allocation Methods for Multi-Dynamic Target Unmanned Aerial Vehicles. Sensors 2024, 24, 6565. [Google Scholar] [CrossRef]
- Schmid, L.; Andersson, O.; Sulser, A.; Pfreundschuh, P.; Siegwart, R. Dynablox: Real-Time Detection of Diverse Dynamic Objects in Complex Environments. IEEE Robot. Autom. Lett. 2023, 8, 6259–6266. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO; GitHub: San Francisco, CA, USA, 2023. [Google Scholar]
- Yin, Q.; Lu, W.; Li, B.; Huang, J. Dynamic Difference Learning with Spatio–Temporal Correlation for Deepfake Video Detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4046–4058. [Google Scholar] [CrossRef]
- Delibaşoğlu, İ. Moving Object Detection Method with Motion Regions Tracking in Background Subtraction. Signal Image Video Process. 2023, 17, 2415–2423. [Google Scholar] [CrossRef]
- Zhang, Q.L.; Li, S.L.; Duan, J.G.; Liu, R.; Hu, J. Moving Object Detection Method Based on the Fusion of Online Moving Window Robust Principal Component Analysis and Frame Difference Method. Neural Process. Lett. 2024, 56, 55–68. [Google Scholar] [CrossRef]
- Yang, B.; Xie, H.; Li, H.; Liu, Q. Unsupervised Optical Flow Estimation Based on Improved Feature Pyramid. Neural Process. Lett. 2020, 52, 1601–1612. [Google Scholar] [CrossRef]
- Hu, B.; Luo, J.; Gao, J.; Fan, T.; Zhao, J. A Robust Semi-Direct 3D SLAM for Mobile Robots Based on Dense Optical Flow in Dynamic Scenes. Biomimetics 2023, 8, 371. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Zhang, Z.; Yu, X.; Zhao, X.; Yan, Z. A Novel Moving Object Detection Algorithm Based on Robust Image Feature Threshold Segmentation with Improved Optical Flow Estimation. Appl. Sci. 2023, 13, 4854. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Chen, L.; Zhang, R.; Ma, Y. BGF-YOLO: Enhanced YOLOv8 with Multiscale Attentional Feature Fusion for Brain Tumor Detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Marrakech, Morocco, 8–12 October 2024; Springer: Cham, Switzerland, 2024; pp. 35–45. [Google Scholar]
- An, Q.; Chen, X.; Zhang, J.; Shi, R.; Yang, Y.; Huang, W. A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing. Sensors 2022, 22, 2929. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, Q.; Li, Y.; Wang, Z. A Dynamic Detection Method for Railway Slope Falling Rocks Based on the Gaussian Mixture Model Segmentation Algorithm. Appl. Sci. 2024, 14, 4454. [Google Scholar] [CrossRef]
- Zhao, L.; Qiu, S.; Chen, Y. Enhanced Water Surface Object Detection with Dynamic Task-Aligned Sample Assignment and Attention Mechanisms. Sensors 2024, 24, 3104. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Category | Training | Validation | Test | Total |
|---|---|---|---|---|
| Front of the cylindrical | 600 | 129 | 129 | 858 |
| Side of the cylindrical | 1056 | 226 | 226 | 1508 |
| Front of the cubic | 602 | 129 | 129 | 860 |
| Side of the cubic | 1136 | 243 | 243 | 1622 |
| Front of the triangular prism | 597 | 128 | 127 | 852 |
| Side of the triangular prism | 1074 | 230 | 230 | 1534 |
| Name | Specific Information |
|---|---|
| processor | AMD EPYC 9654 |
| GPU | NVIDIA GTX4060 (NVIDIA Corporation, Santa Clara, CA, USA) |
| Cuda | 11.8 |
| cuDNN | 8.7.0 |
| Python3 | 3.7 |
| PyTorch | 2.1.0 |
| No. | C2f-G | C2f-F | VFL | mAP@0.5 | GFLOPs | FPS | Inference Time | Parameters (Million) |
|---|---|---|---|---|---|---|---|---|
| 1 | 88.5 | 28.4 | 154.1 | 6.5 | 11.1 | |||
| 2 | √ | 86.8 | 24.4 | 173.8 | 5.7 | 8.3 | ||
| 3 | √ | 91.7 | 27.6 | 157.2 | 6.3 | 10.8 | ||
| 4 | √ | 90.6 | 28.4 | 154.3 | 6.5 | 11.1 | ||
| 5 | √ | √ | 91.1 | 24.9 | 167.0 | 5.9 | 9.4 | |
| 6 | √ | √ | 92.9 | 27.7 | 157.2 | 6.3 | 10.8 | |
| 7 | √ | √ | √ | 92.6 | 24.6 | 166.9 | 5.9 | 9.4 |
| Network | mAP@0.5–0.95 | mAP@0.5 | GFLOPs | FPS | Inference Time | Parameters (Million) |
|---|---|---|---|---|---|---|
| EfficientDet | 38.3 | 40.2 | 6.6 | 107.8 | 9.3 | 6.1 |
| DETR | 42 | 62.4 | 86.0 | 34.1 | 29.3 | 41.0 |
| YOLOv7 | 55.2 | 69.7 | 104.7 | 161.4 | 6.2 | 36.9 |
| YOLOv7-tiny | 37.2 | 56.0 | 13.8 | 286.0 | 3.5 | 6.2 |
| YOLOv8s | 44.6 | 61.2 | 28.4 | 173.3 | 5.8 | 11.2 |
| BGF-YOLO | 43.2 | 60.5 | 17.4 | 178.4 | 5.6 | 22.0 |
| Proposed | 45.3 | 62.2 | 24.6 | 183.6 | 5.4 | 9.4 |
| Network | Recall | Precision | mAP@0.5–0.95 | mAP@0.5 | FPS | GFLOPs | Inference Time | Parameters (Million) |
|---|---|---|---|---|---|---|---|---|
| EfficientDet | 68.4 | 69.3 | 67.3 | 72.1 | 100.1 | 6.6 | 9.9 | 6.1 |
| DETR | 70.8 | 75.2 | 72.6 | 76.2 | 30.7 | 86.0 | 32.5 | 41.0 |
| YOLOv7 | 92.9 | 92.6 | 76.3 | 93.3 | 161.4 | 104.7 | 6.2 | 36.9 |
| YOLOv7-tiny | 68.0 | 75.4 | 60.2 | 73.7 | 286.0 | 13.8 | 3.5 | 6.2 |
| YOLOv8s | 89.1 | 88.7 | 67.9 | 88.5 | 154.1 | 28.4 | 6.5 | 11.2 |
| BGF-YOLO | 80.3 | 85.8 | 79.4 | 83.1 | 106.4 | 17.4 | 9.4 | 22.0 |
| Proposed | 91.7 | 93.0 | 74.7 | 92.6 | 166.9 | 24.6 | 5.9 | 9.4 |
| Network | Front of Assembly (1) | Side of Assembly (1) | Front of Assembly (2) | Side of Assembly (2) |
|---|---|---|---|---|
| EfficientDet |  |  |  |  |
| DETR |  |  |  |  |
| YOLOv7 |  |  |  |  |
| YOLOv7-tiny |  |  |  |  |
| YOLOv8s |  |  |  |  |
| BGF-YOLO |  |  |  |  |
| Proposed |  |  |  |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhang, E.; Ding, Q.; Liao, W.; Wu, Z. An Improved Method for Enhancing the Accuracy and Speed of Dynamic Object Detection Based on YOLOv8s. Sensors 2025, 25, 85. https://doi.org/10.3390/s25010085
Liu Z, Zhang E, Ding Q, Liao W, Wu Z. An Improved Method for Enhancing the Accuracy and Speed of Dynamic Object Detection Based on YOLOv8s. Sensors. 2025; 25(1):85. https://doi.org/10.3390/s25010085
Chicago/Turabian StyleLiu, Zhiguo, Enzheng Zhang, Qian Ding, Weijie Liao, and Zixiang Wu. 2025. "An Improved Method for Enhancing the Accuracy and Speed of Dynamic Object Detection Based on YOLOv8s" Sensors 25, no. 1: 85. https://doi.org/10.3390/s25010085
APA StyleLiu, Z., Zhang, E., Ding, Q., Liao, W., & Wu, Z. (2025). An Improved Method for Enhancing the Accuracy and Speed of Dynamic Object Detection Based on YOLOv8s. Sensors, 25(1), 85. https://doi.org/10.3390/s25010085