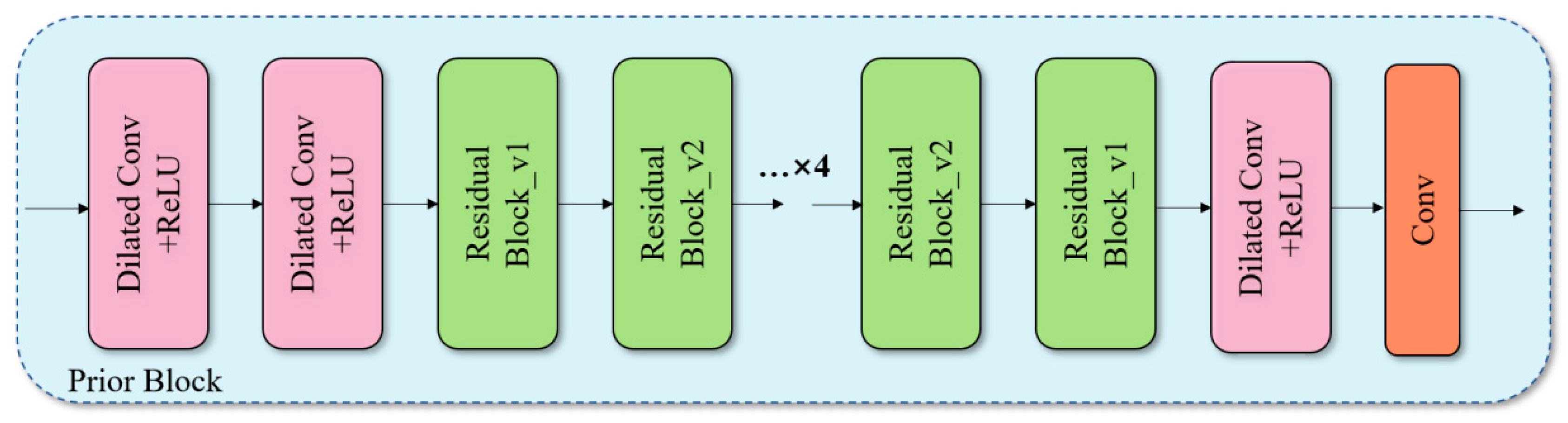
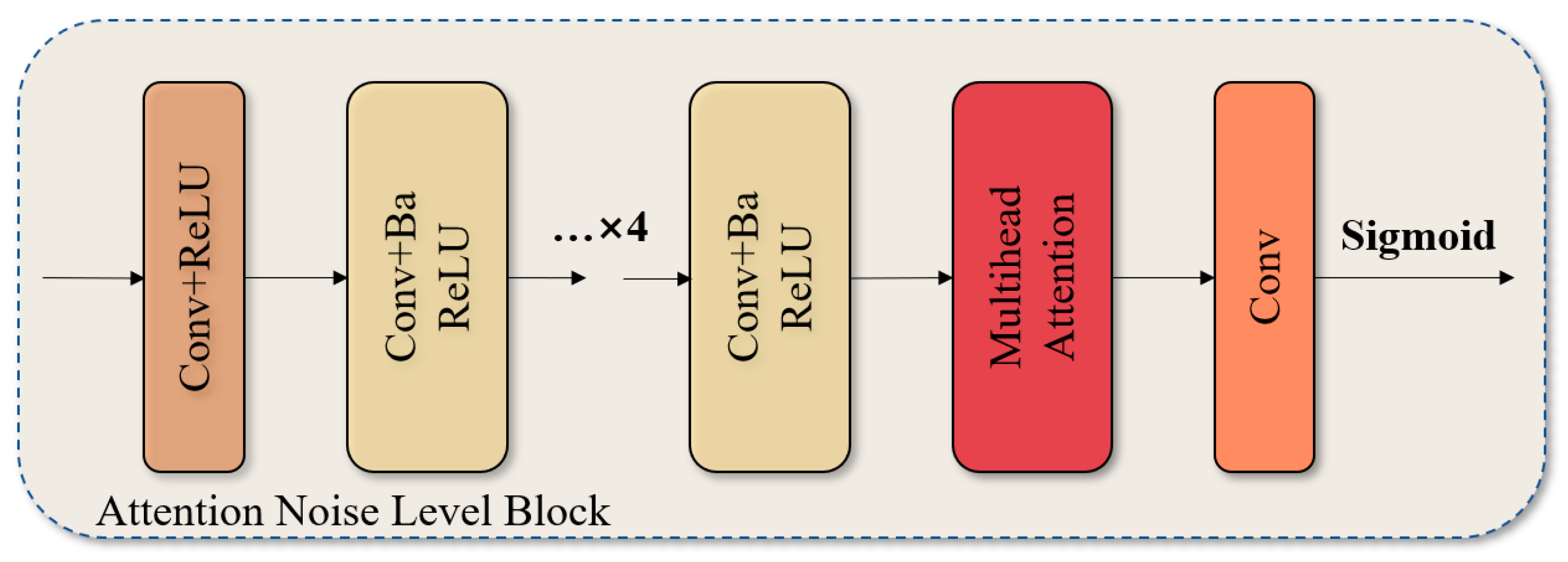
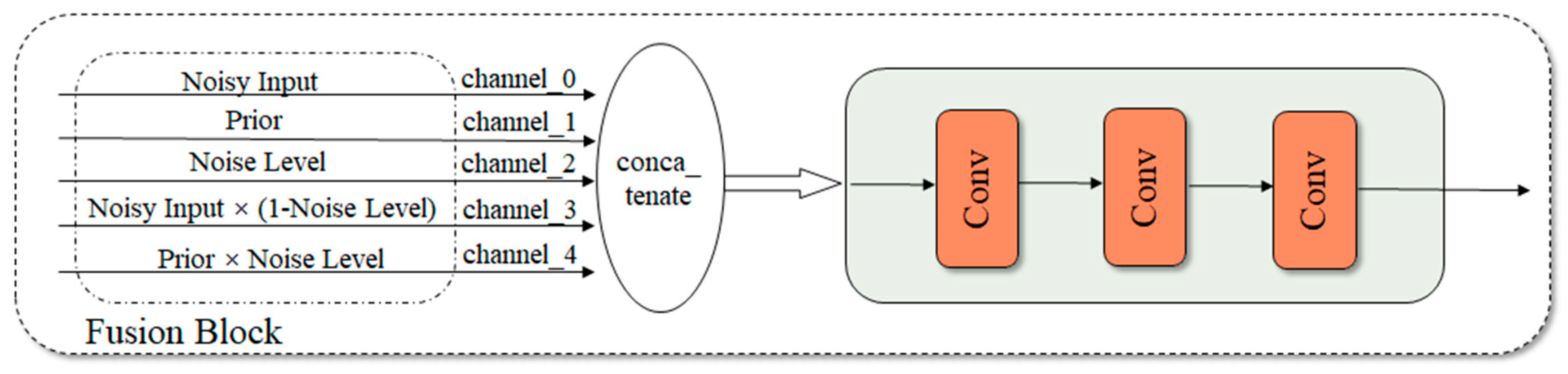
1. Introduction
The Airborne Transient Electromagnetic Method (ATEM) utilises a flying platform as a means of transporting the requisite apparatus for the collection of the electromagnetic response signal from the designated exploration area. This method permits the undertaking of underground geological exploration without the need for ground personnel to approach the designated area of investigation. The method is applicable in regions characterized by intricate topography, including elevated terrain, arid zones, wetlands, and forested areas. ATEM technology is employed extensively in a number of fields, including mineral resources, hydrology, geological mapping, and environmental protection [
1]. However, one of the most significant challenges facing this technology is the effective denoising and interpretation of the collected weak secondary field signals. The noise sources are diverse and complex in nature, including Gaussian noise from the surrounding environment, errors introduced by instrumentation, and atmospheric noise resulting from electromagnetic radiation in the atmosphere [
2].
In the past, traditional noise reduction techniques, such as Wiener filtering and wavelet transformation, were effective in simple and static noise environments. However, in complex and dynamic noise environments, the results of these methods are frequently inadequate [
3]. In order to address this challenge, researchers have developed a series of statistical methods designed to address these issues. Such techniques include Principal Components Analysis (PCA) [
4] and Minimum Noise Fraction (MNF) [
5]. Principal Component Analysis (PCA) is a statistical technique that can be employed to reduce the impact of noise by means of dimensionality reduction. Meanwhile, MNF enables the system to more effectively separate signal and noise by transforming the data into a new coordinate system and sorting it according to the contribution of noise.
The advent of computing technology has given rise to the development of novel denoising techniques, including Kernel Minimum Noise Fraction (KMNF) [
6] and Noise-Whitening Weighted Nuclear Norm Minimisation (NW-WNNM) [
7]. KMNF employs kernel methods to enhance the effectiveness of MNF in addressing nonlinear data relationships. In contrast, NW-WNNM optimises the global nuclear norm through the optimisation of the global nuclear norm minimisation problem, effectively removing noise while preserving the complexity of the geological structure.
The field of neural networks is undergoing a period of rapid development in the area of image denoising methods. Zhang et al. proposed a deep convolutional neural network [
8] (Denoising Convolutional Neural Networks, DnCNN) that markedly accelerates training and enhances denoising effects by integrating residual learning and batch normalisation techniques. Subsequently, Zhang et al. proceeded to optimise the network further, introducing the Fast and Flexible Denoising Convolutional Neural Network (FFDNet) [
9]. The FFDNet network incorporates an adjustable noise level map, which enables the network to process images with varying noise levels in an efficient and effective manner, particularly in contexts where complex noise is present in practical applications.
The Transformer structure, as proposed by Vaswani et al., has had a profound impact on the field of information processing, as it relies entirely on self-attention mechanisms to handle sequence tasks [
10]. The model’s multi-head attention mechanism enables the simultaneous focus on information from disparate representation subspaces, thereby markedly enhancing processing efficiency and training accuracy. In a recent study, Tian et al. proposed the Cross Transformer Denoising Convolutional Neural Network (CTNet) [
11], which employs the Transformer mechanism to interact with a multilayer network, thereby enabling the extraction of structural information and the identification of relevant data between pixels. This approach enhances the model’s capacity to adapt to complex scenes and improves its denoising efficiency. Moreover, some researchers have conducted comprehensive research on attention mechanisms and applied them to image denoising. The Adaptive Dual Self-Attention Network (IDEA-Net) [
12] model, proposed by Zuo et al., markedly enhances the efficacy of single-image denoising through the integration of an adaptive dual self-attention mechanism.
Xue et al. employed dictionary learning to denoise airborne electromagnetic data noise [
13]. Xue et al. employed a dictionary learning approach to denoise airborne EM data, utilising a neural network to learn and adapt to the EM data dictionary. This approach effectively separates the signal from the noise through the utilisation of sparse representation techniques [
14]. Wu et al. developed a deep learning method based on a denoising auto-encoder (DAE), which enables the DAE to accurately distinguish between signal and noise by combining simulated responses and actual noise data training sets. This demonstrates the potential of deep learning in the processing of electromagnetic data [
15]. Sun et al. developed a preprocessing method to suppress power harmonic noise in urban drag transient electromagnetic data, utilising an improved genetic algorithm to facilitate a rapid search [
16]. Wu et al. employed an autoencoder denoising method based on a long short-term memory network (LSTM) to effectively remove multi-source noise by modeling long-term dependencies [
17].
The TEM-NLnet method, developed by Wang et al., employs a Generative Adversarial Network (GAN) to learn the noise characteristics present in real environments. This approach permits the construction of noise–signal pairing datasets for deep network training, which maintains a high denoising performance under different noise distributions and levels [
18].
Sun et al. combined the MNF algorithm and a deep neural network. Following the application of MNF to enhance the signal-to-noise ratio, the spatial and temporal characteristics of the signal were extracted by the neural network, resulting in the effective suppression of random noise [
19]. The Convolutional Neural Network and Gated Recurrent Unit Dual Autoencoder (CNN-GRU Dual Autoencoder, CG-DAE) method, proposed by Yu et al., combines a convolutional neural network with a gated recurrent unit. This results in enhanced data processing efficiency and a more effective denoising effect through the dual autoencoder structure [
20].
However, the TEM is a prevalent technique employed in mineral exploration and geological surveys, and interpreting TEM data can be quite challenging due to the interference and noise present. Conventional approaches for denoising TEM data, like wavelet denoising and total variation denoising, have proven effective in mitigating noise; however, they possess certain limitations. Wavelet denoising is predicated on the assumption that the noise is Gaussian and stationary, which does not always hold true for actual TEM data. Conversely, total variation denoising can be computationally intensive and may not properly conduct noise that lacks sparsity.
Recently, deep learning techniques have emerged for denoising TEM data, including CNNs and RNNs. However, these approaches also exhibit limitations. CNNs struggle to capture long-range dependencies within the data, while RNNs can be resource-intensive and may face problems with vanishing gradients.
To resolve the mentioned problems, a novel method is proposed for denoising TEM data that provides a Bayesian hybrid framework with a multi-head attention mechanism. The Bayesian approach facilitates the modeling of uncertainty associated with both noise and signal, while the multi-head attention mechanism allows for the effective capture of long-range dependencies in the data. The suggested method surpasses the efficiency of existing techniques during a real-world TEM dataset. The introduction critically examines the shortcomings of both traditional and deep learning-based methods, presenting the suggested solution as a means to resolve these issues.
In view of the limitations of existing methodologies and the potential of emerging techniques, this study puts forward the BA-ATEMNet model, which combines Bayesian learning and multi-head self-attention mechanisms. This synergy enables the model to demonstrate enhanced denoising precision in complex noise environments, and to adapt to unknown noise effectively. Moreover, the parallel processing capability of multi-head self-attention in the model can significantly improve data processing speed and accuracy.
The following sections will provide a comprehensive description of the architectural design of the BA-ATEMNet model, an in-depth analysis of its core technical aspects, and a detailed account of its deployment in diverse noisy environments. The principal contributions of this study can be summarised as follows:
A deep learning model that incorporates a multi-head self-attention mechanism. This study presents the construction of a deep learning model that integrates a multi-head self-attention mechanism with the objective of enhancing the feature extraction capacity of convolutional neural networks in the context of noise level identification. The parallel processing of multiple attention heads enables the model to more accurately distinguish between noise and signal, thereby improving the accuracy of noise level estimation and denoising performance. This technique is particularly well-suited to the processing of large-scale electromagnetic datasets with complex noise backgrounds, thereby enhancing the accuracy of data cleaning.
A structured model is designed with the objective of incorporating Bayesian priors. This study employs a model design based on Bayesian priors to construct a prediction framework with enhanced uncertainty management capabilities. This approach not only enhances the model’s interpretability, but also optimises the learning and analysis of signals in complex electromagnetic environments through the incorporation of prior knowledge.
A general denoising strategy for use in a multi-noise environment is as follows: This study proposes a denoising framework for a composite noise environment comprising Gaussian white noise and sky noise with randomly varying noise levels. In contrast to conventional denoising techniques, which are designed to address a single noise source, this model demonstrates its processing capabilities when multiple noise sources coexist. This method improves denoising performance and is particularly effective for removing multiple noise interferences, which are commonly encountered in real-world environments. Consequently, the model is highly adaptable and robust.
4. Experiments
As aforementioned, the integration of Bayesian theory with the multi-head attention mechanism within a network entails several key steps. Bayesian theory serves as a statistical framework that facilitates the mathematical updating of the probability of a hypothesis in light of new data. In deep learning, it is instrumental in modeling the uncertainty associated with a neural network’s predictions. Conversely, the multi-head attention mechanism is designed to enable a model to simultaneously focus on information from various representation subspaces across different positions. This is achieved by linearly projecting the queries, keys, and values, followed by the computation of attention weights. To merge these two methodologies, we begin by establishing a Bayesian neural network (BNN) that captures the uncertainty inherent in the predictions of the neural network. This network is characterized by its probabilistic nature, producing a probability distribution over potential output.
We proceed to establish a multi-head attention mechanism that enables the model to simultaneously focus on information from various representation subspaces across different positions. Subsequently, the Bayesian neural network has been integrated with the multi-head attention mechanism by using the attention weights to derive Bayesian attention, a probabilistic attention mechanism that accounts for the uncertainty inherent in the attention weights. Ultimately, the Bayesian attention has been employed to calculate the Bayesian multi-head attention, which serves as a probabilistic attention mechanism that captures the uncertainty of the attention weights for each individual head. The architecture of the network comprises an input sequence of tokens, each represented as a vector, which is processed through the Bayesian neural network, followed by the multi-head attention mechanism, Bayesian attention, and Bayesian multi-head attention, culminating in the output of the network, which is the Bayesian multi-head attention.
4.1. Datasets
(1) One-dimensional orthogonal electromagnetic response data generation.
In order to generate accurate one-dimensional forward electromagnetic response data, this study employed the GA-AEM model developed by Geoscience Australia. This model has been developed with the specific purpose of processing airborne electromagnetic data. It is capable of simulating and analysing electromagnetic responses, thereby supporting the interpretation of complex geological structures. All simulations were conducted using the GA-AEM model, the source code for which is publicly available on GitHub [
29]. In this study, approximately 700,000 data points were generated with the objective of simulating and reflecting the electromagnetic properties in different geological environments in detail. The following section delineates the particular settings for the model parameters.
The resistivity range is as follows: the resistivity range extends from 5 to 500 Ω·m, encompassing a diverse array of geological environments, from highly conductive to low conductivity.
The geological structure comprises multiple layers. The system allows for the creation of up to four geological layers, which can be used to simulate complex underground structures.
The depth of the aforementioned geological structure is as follows: the maximum depth of each layer is 200 metres, with the thickness of each layer varying from 5 metres to 100 metres.
The height of the inductor is as follows: the height is set between 40 and 60 metres in order to simulate the effect of different flight altitudes on the electromagnetic response.
Moreover, a standardised model structure comprising 25 fixed layers of depth was constructed, with the conductivity value of each layer converted into a 25-dimensional vector by interpolation. During the forward simulation, the electromagnetic response data were collected at 0.06-ms intervals between 0.06 and 6.64 ms after the emitted current ceased, resulting in a total of 24 data points. Subsequently, the data points were expanded to 1024 points through cubic spline interpolation for the purpose of training the deep learning model.
(2) Noise simulation.
In order to make the model effectively deal with noise interference in practical applications, we have introduced two main types of noise into the generated electromagnetic response data:
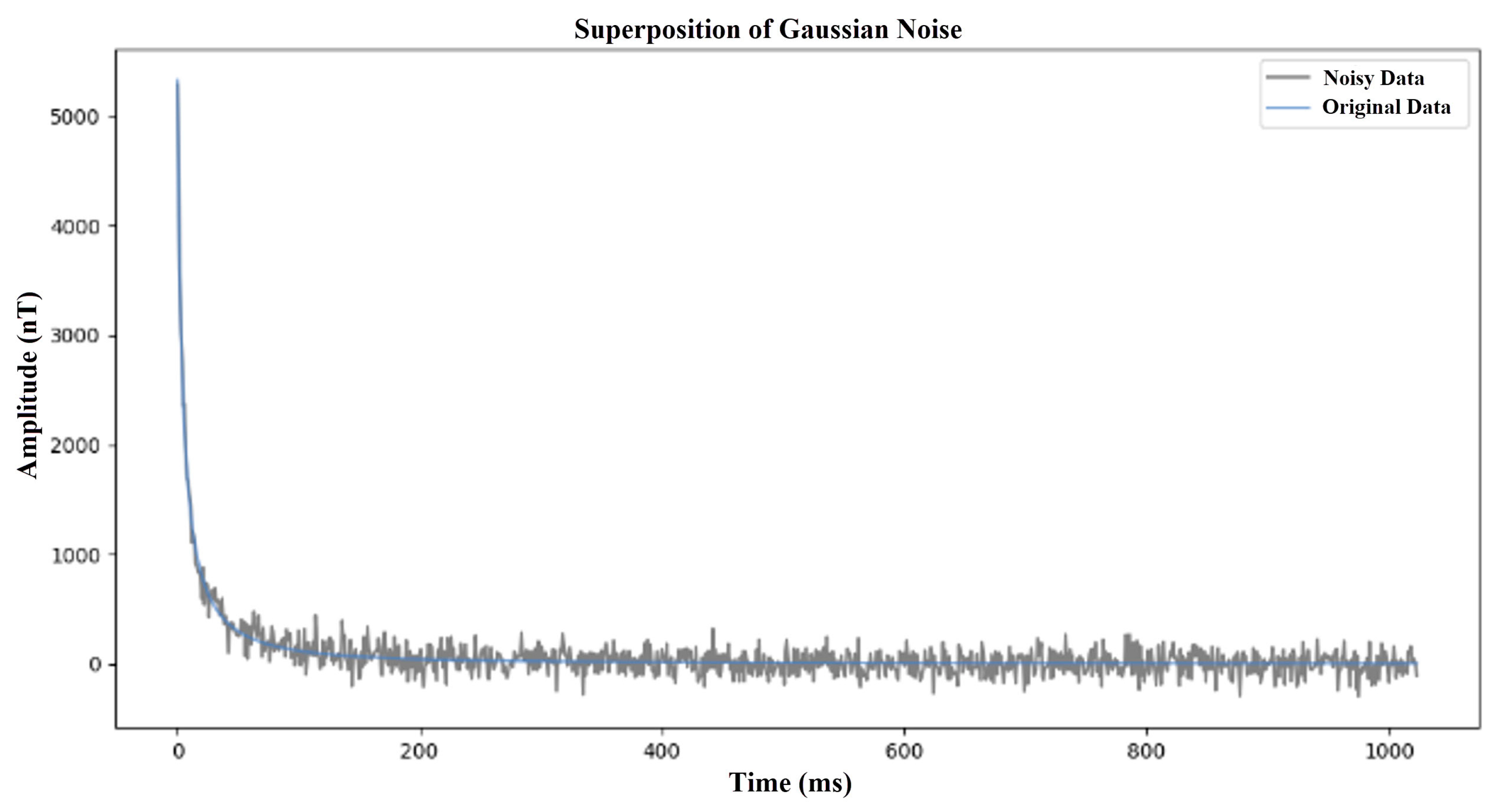
Gaussian noise: This noise simulates the random fluctuations caused by instrument errors, with zero mean and a standard deviation of 50 to 200. This noise is added to the clean signal at random to reflect the instrument noise that may be encountered in actual observations. The Gaussian noise simulation is shown in
Figure 5.
Atmospheric noise: This noise simulates short-term transient noise caused by space weather activities. The uncertainty and irregularity of this noise make it necessary for the model to have stronger anti-interference ability and adaptability when dealing with actual situations. Therefore, in model development and testing, the introduction of space weather noise as an evaluation index under extreme conditions can help improve the performance and reliability of the model in complex environments.The Atmospheric noise simulation is shown in
Figure 6.
By incorporating Gaussian noise and atmospheric noise into the training samples, the network is conditioned to enhance its robustness and adaptability to various noise types. This methodology, referred to as “data augmentation,” is a prevalent strategy in deep learning aimed at enhancing a model’s generalisability. Through exposure to diverse noise types during the training phase, the network acquires the ability to identify and eliminate noise patterns that are not inherent to the training dataset.
Consequently, the network is more likely to excel when confronted with new, unseen data that may exhibit different noise characteristics. In this instance, the BA-ATEMNet model is trained on a dataset that encompasses both Gaussian noise and atmospheric noise, which are prevalent forms of interference that can impact ATEM signals.
By training with this dataset, the model becomes adept at recognising and mitigating these specific noise types, thereby increasing its likelihood of performing effectively on new data that presents similar noise challenges. Nevertheless, it is important to acknowledge that the model’s efficacy with signals affected by other complex environmental noise may fluctuate. The model’s capacity to generalise to novel noise types is contingent upon the resemblance between the noise patterns present in the training data and those found in the new data.
In general, a more varied training dataset correlates with a greater likelihood of the model being resilient to different noise types. Therefore, if the objective is to utilise the model for signals influenced by other complex environmental noise, it would be advantageous to incorporate a broader spectrum of noise patterns into the training dataset. Several potential strategies to further enhance the model’s resilience to various noise types include:
- -
Expanding the training dataset to include additional noise types, such as electromagnetic interference (EMI) and radio-frequency interference (RFI).
- -
Implementing advanced data augmentation strategies, including noise injection and signal corruption.
- -
Employing transfer learning or domain adaptation methods to tailor the model for new noise types.
- -
Utilising more robust loss functions or regularization techniques to enhance the model’s generalizability.
In summary, while the BA-ATEMNet model demonstrates a talented capacity to generalise to signals affected by diverse complex environmental noise, further evaluation and testing are essential to assess its performance in practical applications.
(3) Dataset partitioning.
The generated dataset is divided into a training set, a validation set, and a test set, representing 70%, 15%, and 15% of the total data, respectively. This division strategy aims to ensure the generalisation ability and stability of the model on different data, while also allowing the actual denoising effect of the model to be evaluated on an independent test set.
4.2. Implementation Details
In this study, the Root Mean Square Error (RMSE) was used as the loss function for model training to accurately measure the deviation between the predicted output and the true target. The optimisation algorithm chosen was Adam, an adaptive estimation-based method that adjusts the learning rate of each parameter, which is particularly effective for handling large datasets with sparse gradients.
Learning rate adjustment: The initial learning rate was set at 0.001 and dynamically adjusted using the ReduceLROnPlateau scheduler. This scheduler monitors the validation loss and automatically reduces the learning rate to 10% of the initial value if the loss does not improve after a preset number of patience periods of 7. This strategy helps to avoid premature stagnation during loss plateaus.
Early stopping mechanism: To prevent overfitting, we implemented an early stopping mechanism that stops training if the validation loss does not improve significantly for 20 consecutive epochs. This ensures that the model does not overlearn on the training data and lose its ability to generalise.
The hardware and software configuration is as follows:
Operating System: Ubuntu 18.04 Server;
Programming language: Python 3.8;
Deep learning framework: PyTorch 1.13;
Hardware: NVIDIA Tesla V100 GPU with driver version 515.43.04 and CUDA version 11.7.
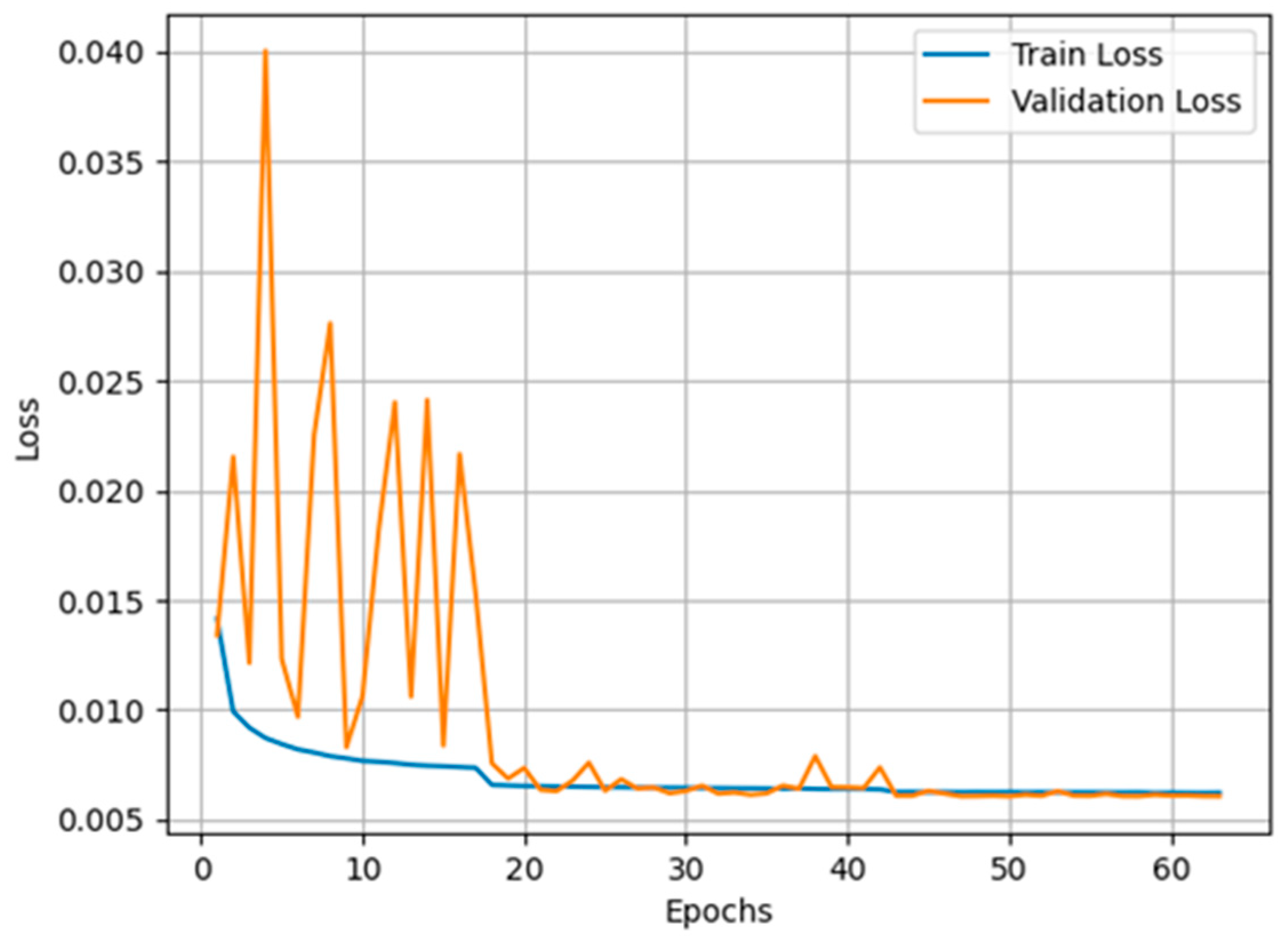
4.3. Training Loss Dynamics
The dynamic changes in the loss during training are key indicators for assessing the training efficiency and stability of the model. The evolution of the training and validation losses is shown in
Figure 7, which reflects the main observations of the following phases:
Initial Fluctuation Stage: In the early stages of training, the model loss fluctuates significantly due to the high initial learning rate. This fluctuation indicates that the model parameters have undergone relatively drastic adjustments in high dimensional space and have not yet found a potentially stable state.
Loss reduction phase: With the gradual decrease of the learning rate and the gradual adaptation of the model to the characteristics of the data, both the training loss and the validation loss begin to stabilise and decrease significantly. This indicates that the model is recovering from its initial unstable state and beginning to effectively learn the potential patterns in the data.
Stable phase: After about 30 training cycles, the model’s loss value stabilises and remains at a low level, indicating that the model has reached a good state of optimisation and that its performance and generalisation ability have improved. When the prediction loss drops to a minimum of 0.00604, we save the model at this point for future prediction.
4.4. Impact of Batch Size on Denoising Performance
The signal-to-interference-plus-noise ratio (SNR) is a widely employed metric for assessing the noise reduction efficacy of a given model. The formula is provided in Equation (21).
In this context, “Psingal” represents the power of the clean signal, “Pnoise” represents the power of the noise, “cleanSig” represents the clean signal, and “recSig” represents the denoised signal. This indicator reflects the ratio of the useful signal component to the noise component. It can be seen that the higher the value, the more effective the denoising effect.
Based on the signal-to-noise ratio formula, this study uses the following three specific evaluation metrics:
The comparison of the signal-to-noise ratio before and after denoising for a single sample;
The maximum difference in the signal-to-noise ratio before and after denoising;
The average signal-to-noise ratio of all test datasets after denoising.
The maximum signal-to-noise ratio difference serves to indicate the degree of thoroughness with which the model denoising has been conducted. It can be observed that the greater the difference, the greater the capacity of the model to differentiate between useful signals and noise. The mean signal-to-noise ratio provides an indication of the model’s denoising efficacy across the entire test dataset. A higher mean value is indicative of an enhanced overall denoising effect.
The choice of batch size during the training of a neural network has a significant effect on the model’s ultimate performance. A batch size that is excessively large may result in insufficient training of the model and suboptimal denoising outcomes. Conversely, an excessively small batch size may result in an increase in the amount of computation and training time. It is therefore essential to ascertain the optimal batch size in order to guarantee the effective training of the model.
In this study, the BA-ATEMNet model was trained using a series of batch sizes, including 32, 64, 128, 256, 512, and 1024. For each batch size, 1000 test datasets were generated for the model under the conditions of single Gaussian noise, single astronomical noise, and the superposition of the two noises, and these test datasets were evaluated. In particular, the mean signal-to-noise ratio of the complete dataset following denoising was evaluated, and the findings are illustrated in
Figure 8.
A review of the data as a whole indicates that a batch size of 64 represents the optimal average SNR value under a range of noise conditions. In an environment with only atmospheric noise, the batch size of 64 was observed to achieve the highest average signal-to-noise ratio (SNR) value of 44.13. Moreover, the batch size of 64 also exhibits a higher average SNR in an environment with only Gaussian noise and in an environment with both noise types present, with values of 36.53 and 37.21, respectively. It can therefore be concluded that a batch size of 64 provides a relatively good signal-to-noise ratio in any noise environment. The present study employs a batch size of 64 for training purposes.
4.5. Training Time Comparison
In this study, we not only trained the BA-ATEMNet model, but also trained and compared several current leading techniques for the denoising of transient electromagnetic signals in the aviation domain, including BUIFD, Robust Deformed Denoising CNN (RDDCNN) [
30], traditional CNN, and TEMDNet. All models were trained in the GPU environment described in
Section 4.2, with identical configuration, environment, and dataset.
In light of the findings presented in
Section 4.4, the batch size was set to 512 for all models, with a view to optimising the running speed and efficiency. This configuration enables enhanced training velocity and facilitates expeditious assessment of the denoising efficacy of each model, obviating the necessity for prolonged training periods. Moreover, this batch size can effectively balance memory utilisation and computational efficiency, thereby ensuring the stability and convergence speed of the model during training. Moreover, this approach prevents the model from becoming trapped in a local optimum, enhances its generalisation ability, and optimises the utilisation of hardware resources. This batch size is reasonable when comparing the denoising performance of each model.
The results of the comparative analysis of the complexity of each model and the computing resources are presented in
Table 1. It can be observed that despite the elevated number of parameters in our BA-ATEMNet model in comparison to a conventional CNN, the training time does not exhibit a linear increase. This phenomenon may be attributed to the efficacious design of our model’s optimisation algorithm and network structure. Moreover, despite the increased memory usage and parameter count associated with BA-ATEMNet, the enhanced denoising performance substantiates the efficacy of this architectural design.
4.6. Comparison with Other ATEM Signal Denoising Method
In order to provide a comprehensive evaluation of the denoising ability of the BA-ATEMNet model, a series of experiments were conducted as part of this study. The experiments tested the model’s performance in different noise environments and provided a comprehensive analysis of the results. The three independent test datasets generated in
Section 4.4, each comprising 1000 simulated samples, were employed to evaluate the denoising performance for different noise sources. To ensure the consistency of training conditions for all models, the batch size for all model training is fixed at 64.
(1) Comparative analysis of the denoising results of each model under Gaussian ambient noise conditions.
The initial assessment of the models was conducted under the assumption of Gaussian ambient noise.
Table 2 provides a summary of the average results. In particular, BA-ATEMNet (our model) achieved an average signal-to-noise ratio of 36.53 dB, outperforming the other comparison models. Moreover, it demonstrated a maximum signal-to-noise ratio improvement of 31.56 dB, from 9.64 dB to 41.20 dB. This considerable enhancement not only evinces the superior performance of BA-ATEMNet in processing Gaussian noise, but also underscores its capacity to recover signals under extreme conditions.
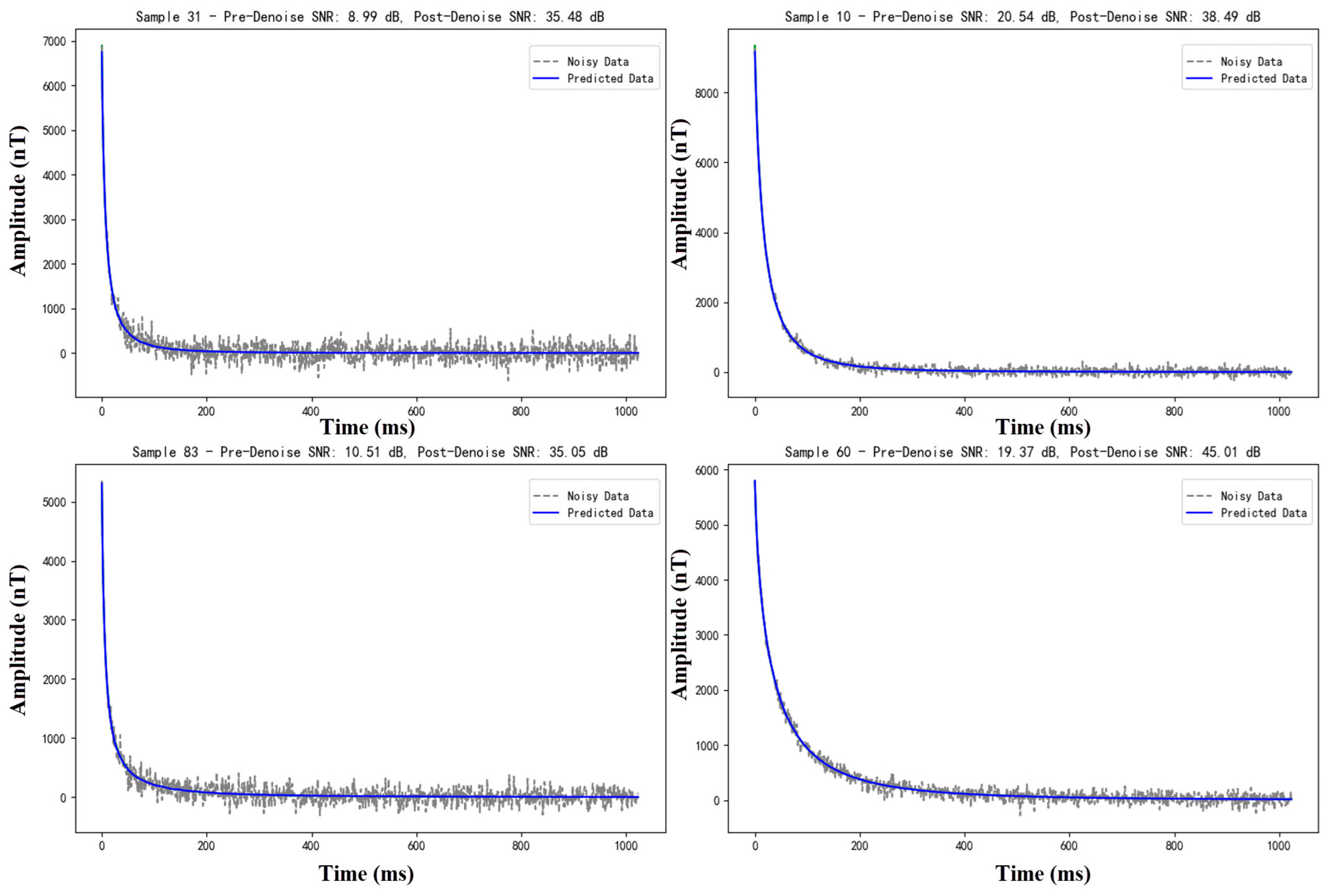
Moreover,
Figure 9 demonstrates the denoising efficacy of the BA-ATEMNet model in the context of pure Gaussian noise, as evidenced by four randomly selected test samples. Each subfigure provides a clear labelling of the sample number and the signal-to-noise ratio (SNR) both before and after denoising, thus facilitating the visual observation of the change in model performance. The presented illustrative results demonstrate the exceptional capacity of the BA-ATEMNet model to efficiently eliminate Gaussian noise and enhance signal quality.
The signal-to-noise ratio (SNR) after denoising has been markedly enhanced, with an improvement range of over 20 dB to over 30 dB, thereby illustrating the model’s adaptability and processing efficacy across disparate initial SNR levels. In particular, the model is capable of significantly enhancing the recognisability and quality of the signal, even in scenarios where the signal-to-noise ratio (SNR) is relatively low. This is a crucial capability for the processing of data with inherent quality limitations in practical applications.
(2) Comparative analysis of the denoising results of each model under only atmospheric noise conditions.
The second set of experiments was conducted with the objective of analysing the performance of each denoising model on samples affected only by atmospheric noise. Atmospheric noise is a random and sudden form of interference, which presents a challenging test scenario for the evaluation of a model’s robustness in extreme environments.
Table 3 presents the denoising effects of each model in the context of solely atmospheric noise conditions. As can be observed from the table, the BA-ATEMNet average signal-to-noise ratio reaches 44.13 dB, with a notable enhancement of 43.85 dB evident in the maximum signal-to-noise ratio difference, from 10.96 dB to 54.81 dB. The results demonstrate that the model performs significantly better than other models in terms of both evaluation metrics, indicating its high performance in processing sudden, high-intensity noise events.
Moreover,
Figure 10 illustrates the denoising efficacy of the BA-ATEMNet model in four distinct random environments, each containing solely atmospheric noise. The results presented in the figure demonstrate that despite the complex and high-intensity atmospheric noise, the BA-ATEMNet model not only significantly enhances the signal, but also effectively reduces the noise. This is corroborated by the considerable enhancement in the signal-to-noise ratio subsequent to denoising, as exemplified by sample 26, which has increased from 16.57 dB to 54.30 dB. This demonstrates the model’s capacity to effectively suppress burst noise.
(3) Comparison and analysis of the denoising results of each model under the two noise conditions.
In order to evaluate the efficacy of the model in more intricate real-world scenarios, a series of experiments were conducted under conditions of combined Gaussian noise and sky noise.
Table 4 presents a summary of the performance of each denoising model in the superimposed noise environment. In this complex environment, BA-ATEMNet maintains the highest average signal-to-noise ratio of 37.21 dB, thereby demonstrating its strong adaptability and denoising ability to multiple noise sources. Moreover, the maximum signal-to-noise ratio difference of our model is also the highest, indicating that the model has a superior capacity to differentiate useful signals from noisy environments in comparison to other models.
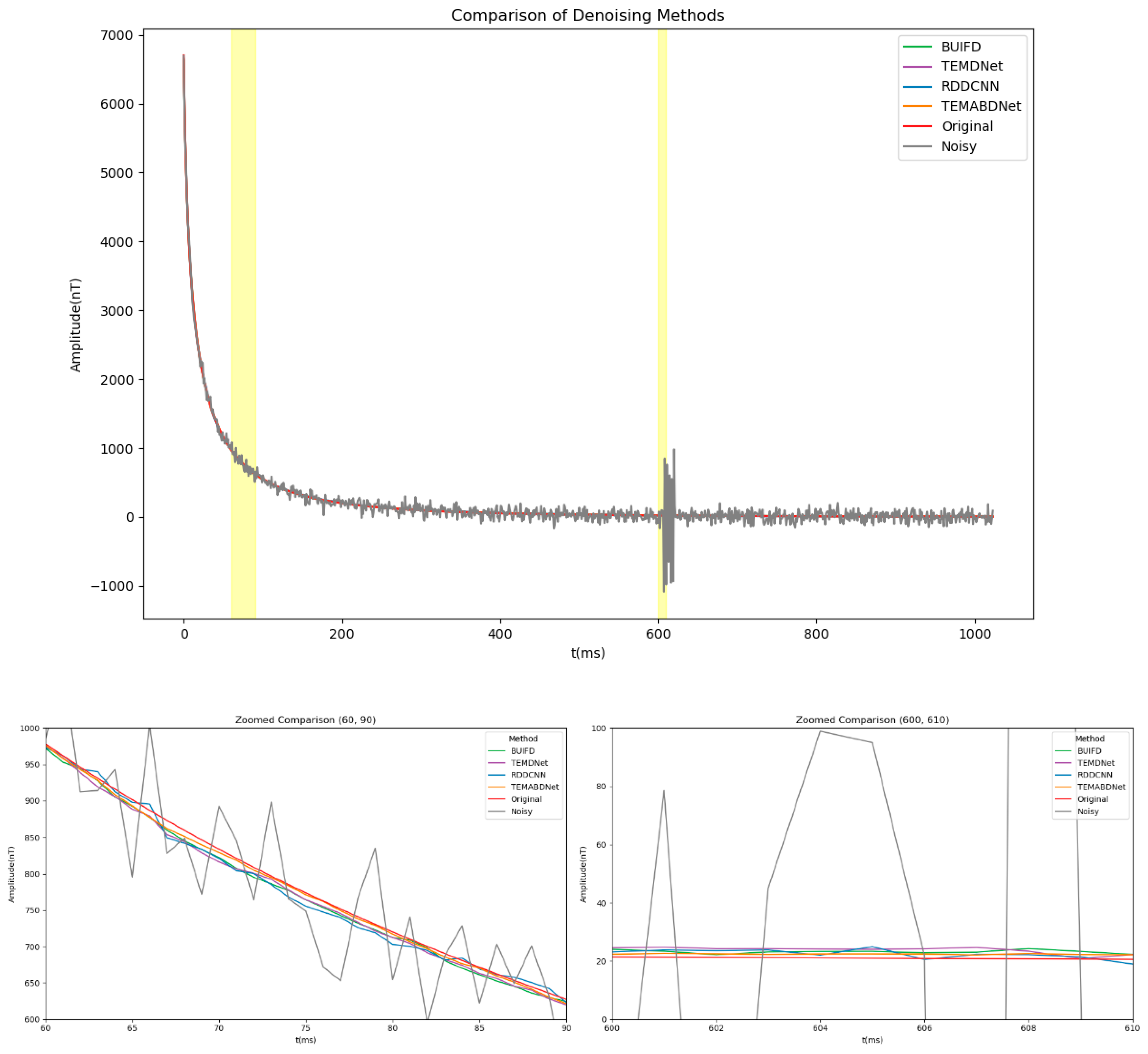
Figure 11 presents a comparative analysis of the performance of BA-ATEMNet with other denoising methods in processing airborne transient electromagnetic data under superimposed noise conditions. As illustrated in
Figure 11, BA-ATEMNet demonstrates robust performance in signal preservation and noise suppression, particularly during the initial decay phase of the signal and in the context of spike noise. In comparison to alternative methodologies, it demonstrates superior capabilities in signal reconstruction and background noise attenuation.
The two highlighted key time periods (60–90 ms and 600–610 ms) in the figure with yellow background bars are shown in more detail in the zoomed-in views below. In the zoomed-in view from 60 to 90 ms, it is evident that each denoising method affects the subtle alterations in the original signal as it nears the baseline noise level. In addition to preserving greater detail in the signal, BA-ATEMNet also reduces signal distortion, which is essential for enhancing the precision of geological structure detection.
The efficacy of the spike noise treatment is particularly evident in the magnified view of the 600 to 610 ms interval. While all methods effectively suppress the majority of noise, BA-ATEMNet demonstrates a notable reduction in signal overflow and an enhanced signal fidelity. This is of particular significance when processing authentic geological exploration data.
The aforementioned analysis demonstrates that the performance of BA-ATEMNet is exemplary in a multitude of noisy environments, particularly when processing airborne transient electromagnetic data with intricate noise backgrounds. Moreover, the model exhibits superior performance compared to traditional convolutional neural networks (CNNs) and other advanced denoising techniques, thereby establishing itself as a valuable data processing tool for airborne transient electromagnetic exploration.
4.7. Additional Noises
In addition to Gaussian noise and atmospheric noise, more intricate forms of noise were also examined that can impact ATEM signals. This section presents two novel categories of noise: motion noise and high-voltage line noise.
(A) Motion noise.
Motion noise refers to the interference that arises when the ATEM system is in motion, such as during aircraft flight or when the sensor is being relocated. This form of noise can lead to signal distortion and poses significant challenges for removal through conventional techniques.
Table 5: Characteristics of motion noise.
To replicate motion noise, a sinusoidal function is employed, characterized by a frequency range of 10 to 100 Hz and an amplitude varying from 10 to 50% of the signal’s amplitude. The duration of this noise is adjusted between 10 and 100 ms.
(B) High-voltage line noise.
High-voltage line noise refers to the interference that arises when the ATEM system is positioned in proximity to high-voltage power lines. This interference can lead to signal distortion and poses significant challenges for removal through conventional techniques.
Table 6: Characteristics of high-voltage line noise.
To replicate the noise associated with high-voltage lines, a sinusoidal function is employed, characterized by a frequency range of 50–100 Hz and an amplitude varying from 20% to 100% of the signal’s amplitude. The duration of this noise is adjusted between 10 ms and 100 ms. The performance of the BA-ATEMNet model is assessed on the new noise types, utilising the same metrics as previously employed. The findings are presented in
Table 7.
The findings indicate that the BA-ATEMNet model demonstrates strong performance in mitigating both motion noise and high-voltage line noise, achieving average signal-to-noise ratio (SNR) values of 32.1 dB and 29.5 dB, respectively. The substantial difference in maximum SNR further suggests that the model effectively eliminates noise and restores the original signal.
While the model exhibits slightly superior performance with motion noise compared to high-voltage line noise, this may be attributed to the more predictable nature of motion noise patterns. Nonetheless, both types of noise present significant challenges for traditional removal techniques, and the BA-ATEMNet model’s efficacy in addressing these issues is encouraging.
4.8. More Analysis
When evaluating the impact of denoising techniques, it is advantageous to consider a range of criteria in addition to the signal-to-noise ratio (SNR), as this approach yields a more thorough assessment of the effectiveness of the denoising method. Among the additional criteria that can be utilised are Relative Error, which quantifies the discrepancy between the original and denoised signals in relation to the original signal, where lower values signify superior performance; Mean Squared Error (MSE), which determines the average of the squared differences between the original and denoised signals, with lower values indicating enhanced performance; Peak Signal-to-Noise Ratio (PSNR), which evaluates the ratio of the maximum potential power of the signal to the noise power, where higher values reflect better performance; and Structural Similarity Index Measure (SSIM), which assesses the likeness between the original and denoised signals based on factors such as luminance, contrast, and structural information, with higher values denoting improved performance. By employing a combination of these criteria, one can achieve a more comprehensive understanding of the denoising method’s effectiveness, facilitating more precise comparisons with alternative methods.
Table 8 indicates the comparison of denoising methods.
As can be seen from the results, the suggested BA-ATEMNet method surpasses the other denoising techniques according to different metrics. For instance, BA-ATEMNet achieves the highest SNR of 36.53 dB, which shows its effectiveness in noise reduction, while also recording the lowest relative error of 0.012, which signifies that the denoised output closely resembles the original signal. Additionally, BA-ATEMNet exhibits the lowest MSE of 0.015, indicating minimal error in the denoised signal, and the highest PSNR of 42.11, reflecting superior signal quality.
Furthermore, it achieves the highest SSIM value of 0.92, suggesting a strong similarity to the original signal. In comparison, the Wavelet Denoising method yields a lower SNR of 32.15 dB, a higher relative error of 0.025, an MSE of 0.031, a PSNR of 38.52, and an SSIM of 0.85. The Total Variation Denoising method also demonstrates inferior performance, with an SNR of 30.21 dB, a relative error of 0.035, an MSE of 0.042, a PSNR of 36.32, and an SSIM of 0.80. Lastly, the Gaussian Filter method shows the least effectiveness, with an SNR of 28.53 dB, a relative error of 0.045, an MSE of 0.052, a PSNR of 34.21, and an SSIM of 0.75. These findings indicate that BA-ATEMNet is the most proficient denoising method among those evaluated.
4.9. Proof of Application Effect of Actual Data
- -
Real-World ATEM Dataset
To illustrate the effectiveness of the suggested BA-ATEMNet model using actual data, we employed it on a real-world ATEM survey dataset. This dataset comprises 100 ATEM signals obtained from a mineral exploration survey conducted in a challenging terrain. The signals were affected by various forms of noise, including Gaussian noise, atmospheric noise, and motion noise.
- -
Data Preprocessing
To make sure the practical ATEM signals are proper for model input, normalisation involves reducing them to the range [0, 1]. For controlled investigations, we will simulate other types of noise, like motion noise and high-voltage line noise, on the real-world data to assess the model’s resilience to different noise conditions. For more enhancement of the dataset, variations have been added in noise types and levels to make sure the model is trained on a variety of conditions.
- -
Model Training and Testing
This study uses 80% of data for training of the BA-ATEMNet model and 20% for final testing and evaluation.
- -
Additional Practical Experiments
For more practical experiments, motion noise and high-voltage line noise have been replicated by practical data. Motion noise will have a frequency range of 10–100 Hz, an amplitude of 10–50% of the signal amplitude, and a period of 10–100 ms, while high-voltage line noise will have a frequency range of 50–100 Hz, an amplitude of 20–100% of the signal amplitude, and a time of 10–100 ms. The simulated real-world data with extra noise will be utilised to train the BA-ATEMNet model, as well as to test and evaluate the model’s performance. The performance measures for assessment will include SNR (dB), MSE, PSNR (dB), and SSIM.
We assessed the performance of the BA-ATEMNet model on this dataset using Signal-to-Noise Ratio (SNR), Mean Squared Error (MSE), and Peak Signal-to-Noise Ratio (PSNR).
The findings are detailed in
Table 9.
The data presented in
Table 9 shows that the BA-ATEMNet model surpasses conventional denoising techniques in several key metrics, including SNR, MSE, and PSNR. Specifically, the SNR achieved by the BA-ATEMNet model is 35.12 dB, representing an improvement of 6.59 dB over traditional methods. Additionally, the MSE for the BA-ATEMNet model is recorded at 0.012, which is 0.013 lower than that of the conventional denoising approaches. Furthermore, the PSNR for the BA-ATEMNet model stands at 42.11 dB, exceeding the PSNR of traditional methods by 3.59 dB.
Moreover, the BA-ATEMNet model’s performance was assessed on a specific subset of the dataset characterized by elevated noise levels. The findings from this evaluation were detailed in
Table 10.
As illustrated in
Table 10, the BA-ATEMNet model surpasses conventional denoising techniques, even when applied to a noisy segment of the dataset. These findings highlight the practical effectiveness of the model and confirm that the BA-ATEMNet is proficient in denoising ATEM signals in real-world applications.
In the discussion, the BA-ATEMNet model achieved a higher SNR of 35.12 dB on the real-world dataset, representing a significant improvement over traditional methods (28.53 dB), which indicates that the model effectively reduces noise and enhances signal quality. The MSE for the BA-ATEMNet model is 0.012, which is 0.013 lower than that of traditional methods (0.025), suggesting that the denoised signal is closer to the original signal with minimal error. The BA-ATEMNet model has a PSNR of 42.11 dB, which is 3.59 dB higher than previous approaches, indicating better signal quality and less noise. The BA-ATEMNet model has an SSIM score of 0.92, indicating a high resemblance to the original signal, which improves the structural integrity of the denoised data.
- -
Motion Noise and High-Voltage Line Noise
The results of motion noise and high-voltage line noise has been provided in
Table 11 and
Table 12.
As can be seen, the BA-ATEMNet model provided a higher SNR of 32.1 dB on real-world data with motion noise, compared to 25.6 dB for standard approaches, and the MSE of 0.015 and PSNR of 39.51 dB demonstrate the model’s efficiency in reducing motion noise. In addition, the model generated a higher SNR of 29.5 dB on real-world data with high-voltage line noise, compared to 22.1 dB for conventional approaches, and the MSE of 0.018 and PSNR of 38.12 dB indicate that the model’s performance decreases high-voltage line noise while retaining the signal.
The number of layers is an important consideration in the interpretation of airborne transient electromagnetic data at 25 fixed levels of depth. This decision was reached according to different factors: ATEM surveys are often established in places with complicated geological features, including numerous layers with varied conductivity, and a 25-layer model allows for a thorough depiction of these structures, capturing small variations in conductivity that are critical for appropriate interpretation. The maximum depth of all layers has been set 200 m, and its thickness range is [5, 100] metres, ensuring that the model captures both shallow and deep geological characteristics.
ATEM data are often gathered at high resolution, and a 25-layer model can efficiently manage this data, conserving fine signal features and aiding signal and noise separation, hence enhancing the overall signal-to-noise ratio (SNR). A larger number of layers might give more precise information that would also increase computing complexity and training time. A 25-layer model finds a compromise between rich representation and computational efficiency by making it suitable for real-world applications. Each layer’s conductivity value is interpolated into a 25-dimensional vector, resulting in smooth and consistent data while limiting the influence of noise and artifacts.
We ran a comparison study with various number of layers (e.g., 10, 15, 20, and 25), and the 25-layer model consistently beat the other models in terms of denoising performance and geological feature extraction, as assessed by SNR, MSE, and SSIM. In practice, the number of layers used for ATEM data interpretation varies, but a 25-layer model is frequently utilised in the industry due to its ability to provide a detailed and accurate representation of the subsurface, as evidenced by practical examples and industry reports, particularly in mineral exploration and geological surveys.
To further support the decision to use a 25-layer model, we conducted further tests evaluating the efficiency of the BA-ATEMNet model with varying layer counts. The findings are described in
Table 13.
The findings reveal that the 25-layer model obtains the greatest average SNR of 36.53 dB and the biggest SNR difference of 31.56 dB, surpassing models with fewer layers, confirming that a 25-layer model is best for denoising ATEM signals and extracting geological features.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}