

Enhancing Autonomous Driving in Urban Scenarios: A Hybrid Approach with Reinforcement Learning and Classical Control

 , , ,
, , ,  ,
,
Abstract
1. Introduction
- Contribution 1: This paper proposes a hybrid methodology that integrates multiple components: pre-processing of map information, high-level DM facilitated by the DRL module, and low-level control signals managed by a classic controller. Our approach not only solves individual complex urban scenarios but also handles concatenated scenarios. This contribution is an extension of the work previously published in the conference IV 2023 [9].
- Contribution 2: In this work, a novel low-level controller is developed. This includes a Linear–quadratic regulator (LQR) controller for trajectory tracking and a Model Predictive Control (MPC) controller for manoeuvre execution. The online integration of these two controllers results in a hybrid low-level control module that allows for the execution of high-level actions in a comfortable and safe manner.
- Contribution 3: This study also presents a RL framework developed within the Car Learning to Act (CARLA) simulator [10] to evaluate complete vehicle navigation with dynamics. Unique to this framework is the incorporation of evaluation metrics that extend beyond mere success rates to include the smoothness and comfort of the agent’s trajectory.
2. Related Works
2.1. Transformer-Based Reinforcement Learning
2.2. Attention-Based Deep Reinforcement Learning
2.3. Combining Machine Learning and Rule-Based Algorithms
2.4. Tactical Behaviour Planning
2.5. Discussion
- State Dimensionality and Pre-Processing: The architectures employing Transformer and Attention mechanisms are characterised by handling high state dimensionalities, utilising sophisticated pre-processing techniques to manage complex input data. Conversely, the Decision-Control, Tactical Behaviour, and our approach, with an emphasis on low state dimensionalities, leverage simpler pre-processing methods such as map data, aiming for computational efficiency and reduced complexity in data handling.
- Action and Control Signal: Transformer-based and Attention-based models provide low-level control commands, often resulting in sharper vehicle control. In contrast, our methodology, along with Decision Control and Tactical Behaviour, opt for high-level actions that yield smoother control signals, promoting more naturalistic and comfortable driving behaviours.
- Scenario Handling: The capacity to adapt to multiple, including concatenated, scenarios shows the versatility of DRL models in AD. Our approach, similar to Transformer-based and Attention-based models, supports a broad spectrum of driving situations, crucial for developing adaptable and dynamic AD systems.
- Computational Cost and Scalability: In terms of computational cost, both our proposal and Tactical Behaviour have lower costs and higher efficiency. Moreover, our model, together with the Transformer-based and the Attention-based models, show scalability, being easily transferable from one environment to another.
- Real Implementation: Among the reviewed architectures, only our approach and the Attention-based model have been validated in real-world settings, showcasing their reliability and applicability beyond simulated environments.
3. Background
3.1. Autonomous Driving
- Rule-Based Systems: Use a predefined set of rules to guide the vehicle’s decisions.
- Finite State Machines: Model the DM process as a series of states and transitions.
- Behaviour Trees: This approach structures the DM process in a tree-like hierarchy, allowing for modular and scalable systems.
- Machine Learning and Deep Learning: These techniques, where DL is a subset of ML, enable vehicles to learn from data and make decisions based on features extracted from data.
- Reinforcement Learning: is a subset of ML, characterised by its focus on training an agent through experiments to interact effectively with its environment.
3.2. Partially Observable Markov Decision Processes
- S is a finite set of states, representing the possible configurations of the environment.
- A is a finite set of actions available to the decision-maker or agent.
- is the state transition probability function and represents the probability of transitioning to state from state s after taking action a.
- is the reward function, associating a numerical reward (or cost) with each action taken in a given state.
- is a finite set of observations that the agent can perceive.
- is the observation function, defines the probability of observing o after taking action a and ending up in state .
3.3. Deep Reinforcement Learning
4. Methodology
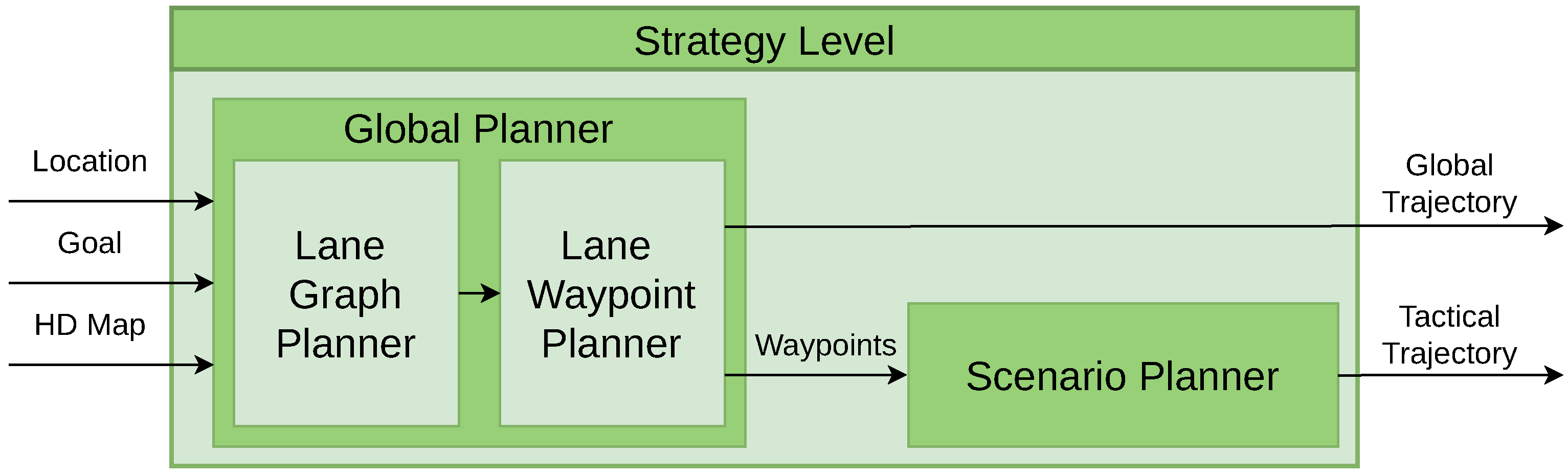
4.1. Strategy Level
- Global Trajectory: Consists of a sequence of waypoints that define the path to be followed by the vehicle from its starting point to the destination.
- Tactical Trajectory: Composed of scenario-specific waypoints, strategically positioned within the map. These waypoints mark the start and end of scenarios encountered along the route.
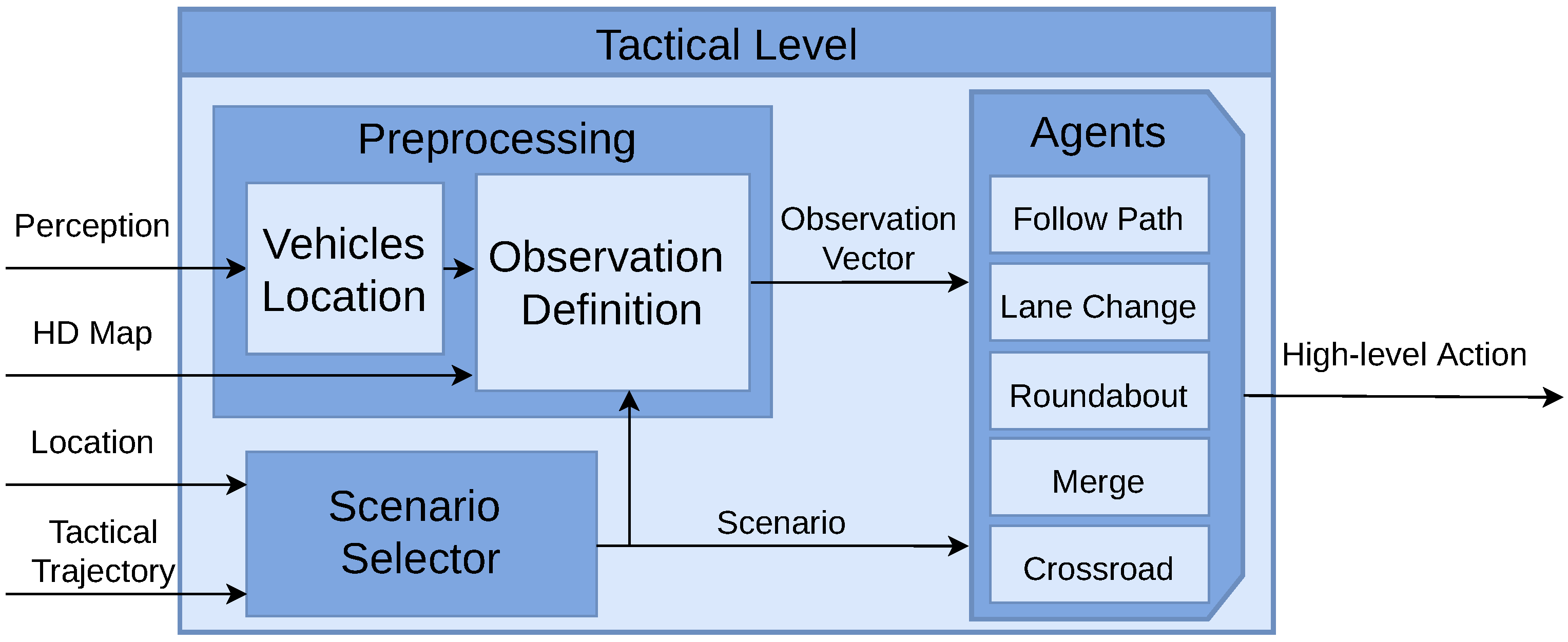
4.2. Tactical Level
- Scenario Selector: This module is in charge of selecting the agent to be executed. In the tactical trajectory, the locations where each use case starts and ends are stored. The “Follow Path” agent is activated by default. When the vehicle reaches one of these locations, the selector activates the corresponding agent. Once the end of the use case is reached, the “Follow Path” agent is activated again.
- Pre-Processing: Another task is the pre-processing of perception data, which involves transforming global locations and velocities of surrounding vehicles into an observation vector. This process starts by obtaining the global location of each vehicle, which is then mapped to a specific waypoint on the HD map. Subsequently, each waypoint is associated with a particular lane and road. This information, coupled with the current scenario as determined by the Scenario Selector, forms the basis for generating distinct observation vectors. Importantly, these vectors are scenario-specific, varying according to the different driving situations encountered.
- DRL Agents: In the proposed architecture, five distinct behaviours (use cases) can be executed. By default, the "Follow Path" behaviour is selected, where the operative level follows the global trajectory while maintaining a safe distance from the leading vehicle, and no active decisions are made. Upon the Scenario Selector choosing a specific scenario, one of the following agents is activated (Lane Change, Roundabout, Merge, Crossroad). These agents then take actions (drive, stop, turn left, turn right) based on the corresponding observation vector.
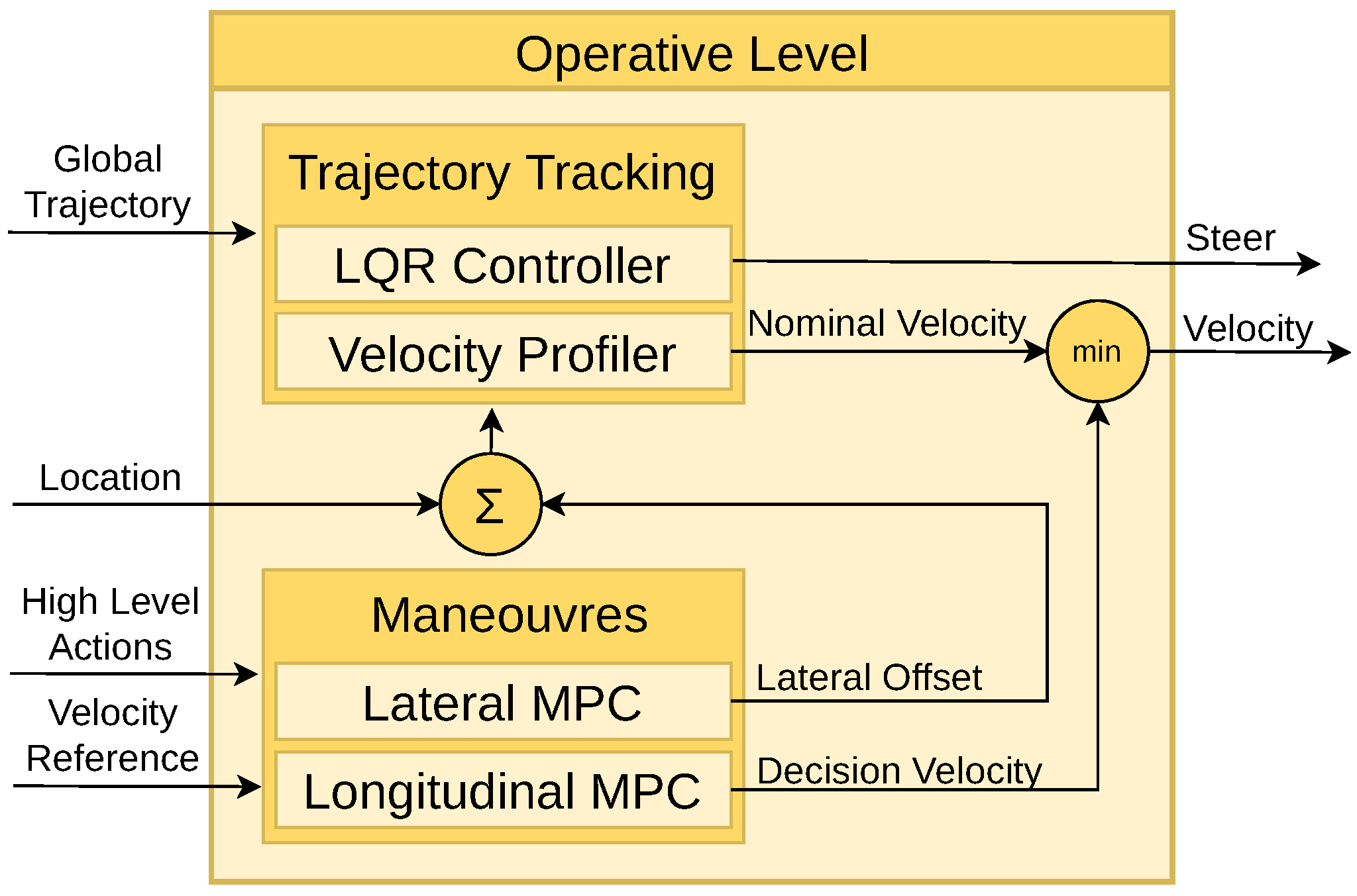
4.3. Operative Level
- Trajectory Tracking: Utilising the provided waypoints, a smooth trajectory is computed using the LQR controller. At each simulation time step, the lateral and orientation errors are calculated to generate a steering command aimed at minimising these errors. Moreover, a velocity command is derived based on the curvature radius of the trajectory. These steering and velocity commands constitute the nominal commands, enabling the vehicle to follow the predefined path accurately.
- Manoeuvres: In the operative level, manoeuvres modify the nominal commands based on the tactical level’s requirements, covering three primary tasks. Firstly, when a preceding vehicle is detected, the MPC controller adjusts the ego-vehicle’s velocity to adapt it to the ahead-vehicle velocity keeping a safe distance. Secondly, if a stop action is demanded by an agent, the decision velocity decreases smoothly, being the resulting command the minimum between this constrained velocity and the nominal velocity. Lastly, in the case of a lane change request (left or right), the MPC controller generates a lateral offset to modify the vehicle’s location, and the LQR controller generates a smooth steering signal to facilitate the lane change.
5. Experiments
- Features Extractor Module. In line with insights from our previous research, this work incorporates a feature extraction module, which has proven to enhance the convergence of training [50], comprising a dense Multi-Layer Perceptron (MLP) to process observations from the environment. Information about both adversarial and ego vehicles is separately processed through the feature extractor. The outputs are then concatenated into a single vector, serving as the input for the DRL algorithms.
- Deep Reinforcement Learning Algorithms. An actor–critic framework is adopted. Within this framework, one MLP functions as the actor, determining the actions to take, while a separate MLP serves as the critic, evaluating the action’s value.
5.1. POMDP Formulation
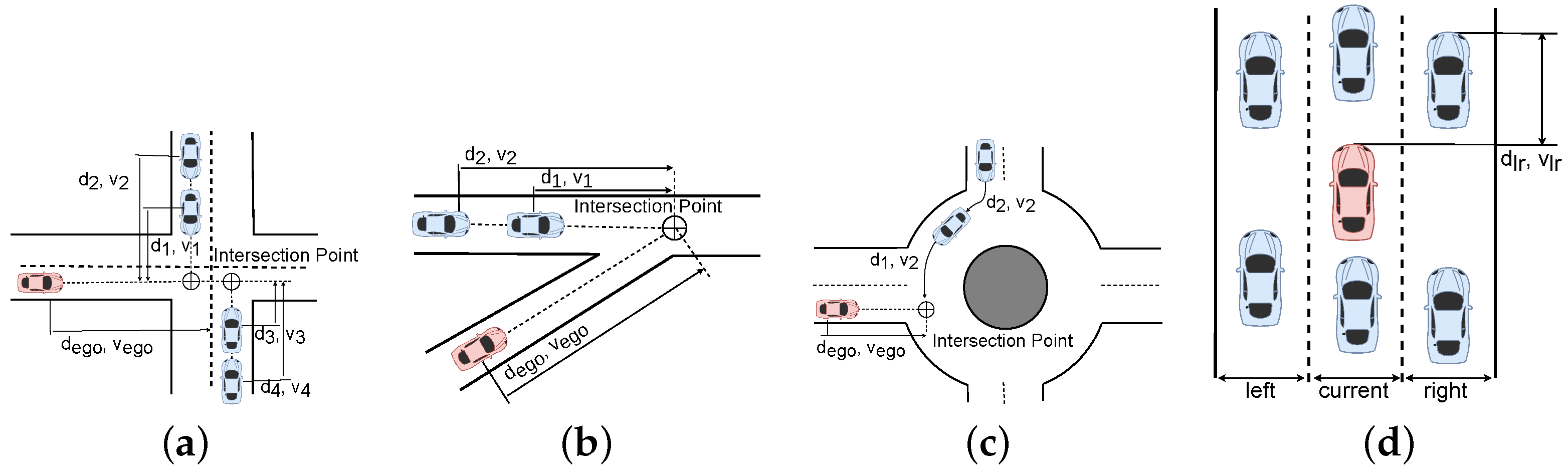
5.1.1. State
5.1.2. Observation
5.1.3. Action
5.1.4. Reward
- Reward based on the velocity: ;
- Reward for reaching the end of the road: ;
- Penalty for collisions: .
5.2. Evaluation Metrics
- Success Rate (%): This metric indicates the frequency of succeed episodes performed by the agent during simulation, providing a direct measure of safety.
- Average of 95th Percentile of Jerk (per episode, in m/s3): Jerk is the rate of acceleration changes. This metric reflects the smoothness of the driving, relating to passenger comfort.
- Average of Maximum Jerk (per episode, in m/s3): This metric measures the highest jerk experienced.
- Average of 95th Percentile of Acceleration (per episode, in m/s2): This metric provides insight into how aggressively the vehicle accelerates, impacting both comfort and efficiency.
- Average Time of Episode Completion (in seconds): It measures the duration taken to complete an episode, indicating the efficiency of the agent.
- Average Speed (in m/s): This metric assesses the agent’s ability to maintain a consistent and efficient speed throughout the episode.
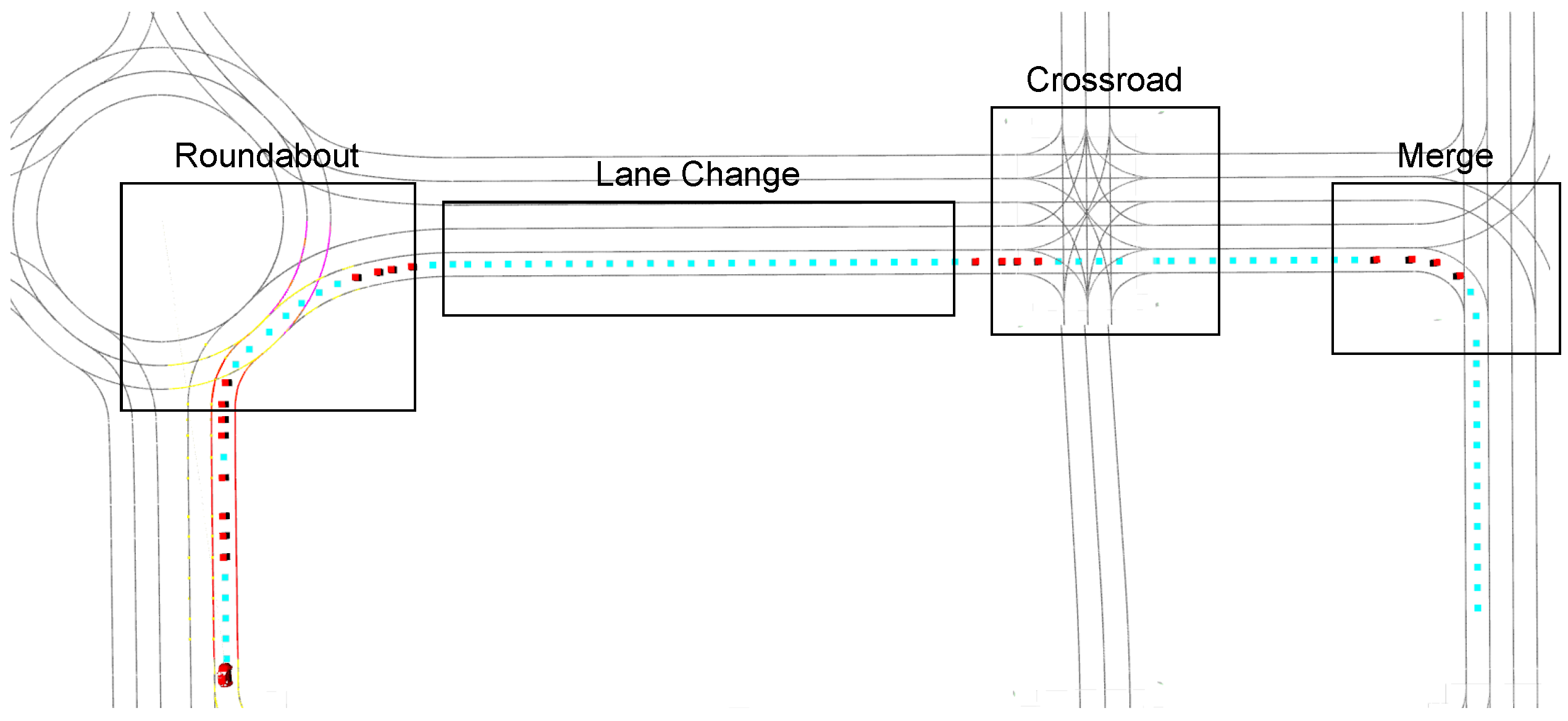
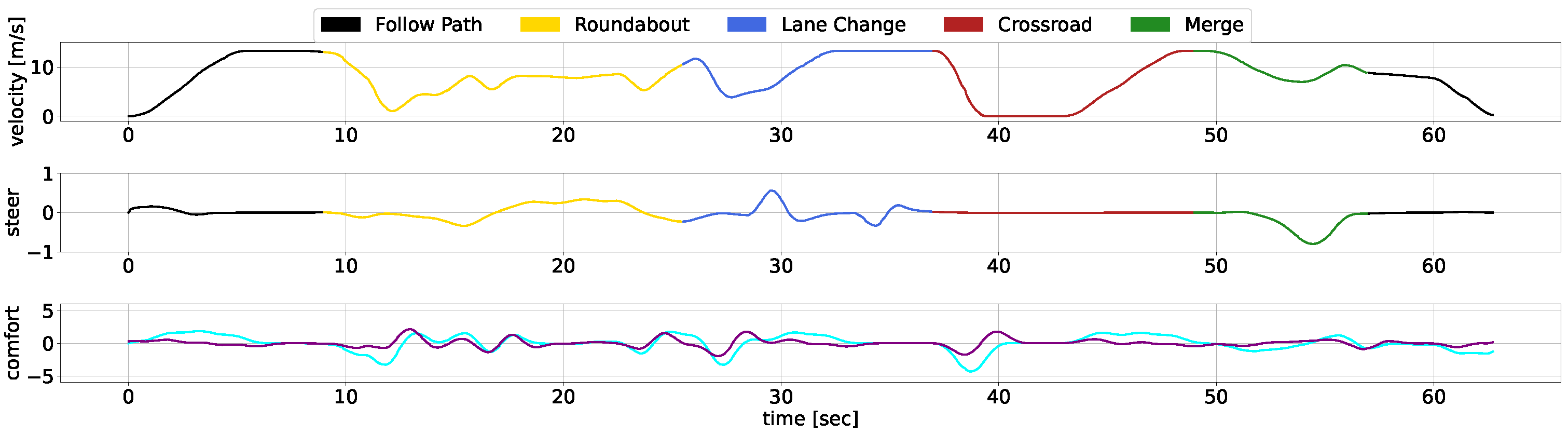
5.3. Concatenated Use Cases Scenario
5.4. Results
5.5. Influence of Realistic Sensors
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rosenzweig, J.; Bartl, M. A review and analysis of literature on autonomous driving. E-J. Mak. Innov. 2015, 1–57. [Google Scholar]
- Deichmann, J. Autonomous Driving’s Future: Convenient and Connected; McKinsey: New York, NY, USA, 2023. [Google Scholar]
- Wansley, M. The End of Accidents. UC Davis L. Rev. 2021, 55, 269. [Google Scholar]
- Hubmann, C.; Becker, M.; Althoff, D.; Lenz, D.; Stiller, C. Decision making for autonomous driving considering interaction and uncertain prediction of surrounding vehicles. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1671–1678. [Google Scholar]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep reinforcement learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5064–5078. [Google Scholar] [CrossRef] [PubMed]
- Moerland, T.M.; Broekens, J.; Jonker, C.M. Model-based Reinforcement Learning: A Survey. arXiv 2020, arXiv:2006.16712. [Google Scholar]
- Dinneweth, J.; Boubezoul, A.; Mandiau, R.; Espié, S. Multi-agent reinforcement learning for autonomous vehicles: A survey. Auton. Intell. Syst. 2022, 2, 27. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, L.; Yu, H.; Zhang, W.; Mei, Y.; Xiong, H. Hierarchical reinforcement learning for dynamic autonomous vehicle navigation at intelligent intersections. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 4852–4861. [Google Scholar]
- Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Arango, F.; Abdeselam, N.; Bergasa, L.M. Hybrid Decision Making for Autonomous Driving in Complex Urban Scenarios. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; Levine, S., Vanhoucke, V., Goldberg, K., Eds.; PMLR: New York, NY, USA, 2017; Volume 78, pp. 1–16. [Google Scholar]
- Tram, T.; Batkovic, I.; Ali, M.; Sjöberg, J. Learning when to Drive in Intersections by Combining Reinforcement Learning and Model Predictive Control. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3263–3268. [Google Scholar] [CrossRef]
- Agarwal, P.; Rahman, A.A.; St-Charles, P.L.; Prince, S.J.; Kahou, S.E. Transformers in reinforcement learning: A survey. arXiv 2023, arXiv:2307.05979. [Google Scholar]
- Huang, Z.; Liu, H.; Wu, J.; Huang, W.; Lv, C. Learning interaction-aware motion prediction model for decision-making in autonomous driving. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 4820–4826. [Google Scholar]
- Fu, J.; Shen, Y.; Jian, Z.; Chen, S.; Xin, J.; Zheng, N. InteractionNet: Joint Planning and Prediction for Autonomous Driving with Transformers. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 9332–9339. [Google Scholar]
- Liu, H.; Huang, Z.; Mo, X.; Lv, C. Augmenting Reinforcement Learning with Transformer-based Scene Representation Learning for Decision-making of Autonomous Driving. arXiv 2023, arXiv:2208.12263. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, C.; Palanisamy, P.; Mudalige, P.; Muelling, K.; Dolan, J.M. Attention-based hierarchical deep reinforcement learning for lane change behaviors in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1326–1334. [Google Scholar]
- Cao, D.; Zhao, J.; Hu, W.; Ding, F.; Huang, Q.; Chen, Z. Attention enabled multi-agent DRL for decentralized volt-VAR control of active distribution system using PV inverters and SVCs. IEEE Trans. Sustain. Energy 2021, 12, 1582–1592. [Google Scholar] [CrossRef]
- Seong, H.; Jung, C.; Lee, S.; Shim, D.H. Learning to Drive at Unsignalized Intersections using Attention-based Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 559–566. [Google Scholar] [CrossRef]
- Avilés, H.; Negrete, M.; Reyes, A.; Machucho, R.; Rivera, K.; de-la Garza, G.; Petrilli, A. Autonomous Behavior Selection For Self-driving Cars Using Probabilistic Logic Factored Markov Decision Processes. Appl. Artif. Intell. 2024, 38, 2304942. [Google Scholar] [CrossRef]
- Lu, J.; Alcan, G.; Kyrki, V. Integrating Expert Guidance for Efficient Learning of Safe Overtaking in Autonomous Driving Using Deep Reinforcement Learning. arXiv 2023, arXiv:2308.09456. [Google Scholar]
- Aksjonov, A.; Kyrki, V. A Safety-Critical Decision Making and Control Framework Combining Machine Learning and Rule-based Algorithms. arXiv 2022, arXiv:2201.12819. [Google Scholar] [CrossRef]
- Kassem, N.S.; Saad, S.F.; Elshaaer, Y.I. Behavior Planning for Autonomous Driving: Methodologies, Applications, and Future Orientation. MSA Eng. J. 2023, 2, 867–891. [Google Scholar] [CrossRef]
- Gong, X.; Wang, B.; Liang, S. Collision-Free Cooperative Motion Planning and Decision-Making for Connected and Automated Vehicles at Unsignalized Intersections. IEEE Trans. Syst. Man, Cybern. Syst. 2024, 54, 2744–2756. [Google Scholar] [CrossRef]
- Sefati, M.; Chandiramani, J.; Kreiskoether, K.; Kampker, A.; Baldi, S. Towards tactical behaviour planning under uncertainties for automated vehicles in urban scenarios. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- O’Kelly, M.; Sinha, A.; Namkoong, H.; Duchi, J.C.; Tedrake, R. Scalable End-to-End Autonomous Vehicle Testing via Rare-event Simulation. arXiv 2018, arXiv:1811.00145. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Kessler, T.; Bernhard, J.; Buechel, M.; Esterle, K.; Hart, P.; Malovetz, D.; Truong Le, M.; Diehl, F.; Brunner, T.; Knoll, A. Bridging the Gap between Open Source Software and Vehicle Hardware for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1612–1619. [Google Scholar] [CrossRef]
- Gómez-Huélamo, C.; Diaz-Diaz, A.; Araluce, J.; Ortiz, M.E.; Gutiérrez, R.; Arango, F.; Llamazares, Á.; Bergasa, L.M. How to build and validate a safe and reliable Autonomous Driving stack? A ROS based software modular architecture baseline. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 1282–1289. [Google Scholar]
- Liu, Q.; Li, X.; Yuan, S.; Li, Z. Decision-Making Technology for Autonomous Vehicles Learning-Based Methods, Applications and Future Outlook. arXiv 2021, arXiv:2107.01110. [Google Scholar] [CrossRef]
- Shani, G.; Pineau, J.; Kaplow, R. A survey of point-based POMDP solvers. Auton. Agents -Multi-Agent Syst. 2013, 27, 1–51. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: New York, NY, USA, 2015; Volume 37, pp. 1889–1897. [Google Scholar]
- Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Arango, F.; Bergasa, L.M. A Curriculum Approach to Bridge the Reality Gap in Autonomous Driving Decision-Making based on Deep Reinforcement Learning. TechRxiv 2024, registration in progress. [Google Scholar] [CrossRef]
- Diaz-Diaz, A.; Ocaña, M.; Llamazares, A.; Gómez-Huélamo, C.; Revenga, P.; Bergasa, L.M. HD maps: Exploiting OpenDRIVE potential for Path Planning and Map Monitoring. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022. [Google Scholar]
- Brezak, M.; Petrović, I. Real-time approximation of clothoids with bounded error for path planning applications. IEEE Trans. Robot. 2013, 30, 507–515. [Google Scholar] [CrossRef]
- McNaughton, M.; Urmson, C.; Dolan, J.M.; Lee, J.W. Motion planning for autonomous driving with a conformal spatiotemporal lattice. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 4889–4895. [Google Scholar]
- Lee, J.W.; Litkouhi, B. A unified framework of the automated lane centering/changing control for motion smoothness adaptation. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 282–287. [Google Scholar]
- Kano, H.; Fujioka, H. B-spline trajectory planning with curvature constraint. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 1963–1968. [Google Scholar]
- Magid, E.; Lavrenov, R.; Khasianov, A. Modified Spline-based Path Planning for Autonomous Ground Vehicle. In Proceedings of the ICINCO (2), Madrid, Spain, 26–28 July 2017; pp. 132–141. [Google Scholar]
- Samuel, M.; Hussein, M.; Mohamad, M.B. A review of some pure-pursuit based path tracking techniques for control of autonomous vehicle. Int. J. Comput. Appl. 2016, 135, 35–38. [Google Scholar] [CrossRef]
- Hoffmann, G.M.; Tomlin, C.J.; Montemerlo, M.; Thrun, S. Autonomous automobile trajectory tracking for off-road driving: Controller design, experimental validation and racing. In Proceedings of the 2007 American Control Conference 2007, New York, NY, USA, 9–13 July 2007; pp. 2296–2301. [Google Scholar]
- Gutiérrez, R.; López-Guillén, E.; Bergasa, L.M.; Barea, R.; Pérez, Ó.; Gómez-Huélamo, C.; Arango, F.; del Egido, J.; López-Fernández, J. A Waypoint Tracking Controller for Autonomous Road Vehicles Using ROS Framework. Sensors 2020, 20, 4062. [Google Scholar] [CrossRef] [PubMed]
- Gu, T.; Dolan, J.M.; Lee, J.W. On-Road Trajectory Planning for General Autonomous Driving with Enhanced Tunability. In Proceedings of the Intelligent Autonomous Systems 13, Kigali, Rwanda, 13–17 July 2016; pp. 247–261. [Google Scholar]
- Lim, W.; Lee, S.; Sunwoo, M.; Jo, K. Hierarchical Trajectory Planning of an Autonomous Car Based on the Integration of a Sampling and an Optimization Method. IEEE Trans. Intell. Transp. Syst. 2018, 19, 613–626. [Google Scholar] [CrossRef]
- Aoki, M.; Honda, K.; Okuda, H.; Suzuki, T. Comparative Study of Prediction Models for Model Predictive Path- Tracking Control in Wide Driving Speed Range. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1261–1267. [Google Scholar] [CrossRef]
- Hu, J.; Feng, Y.; Li, X.; Wang, H. A Model Predictive Control Based Path Tracker in Mixed-Domain. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1255–1260. [Google Scholar] [CrossRef]
- Frison, G.; Sørensen, H.H.B.; Dammann, B.; Jørgensen, J.B. High-performance small-scale solvers for linear Model Predictive Control. In Proceedings of the 2014 European Control Conference (ECC), Strasbourg, France, 24–27 June 2014; pp. 128–133. [Google Scholar] [CrossRef]
- Abdeselam, N.; Gutiérrez-Moreno, R.; López-Guillén, E.; Barea, R.; Montiel-Marín, S.; Bergasa, L.M. Hybrid MPC and Spline-based Controller for Lane Change Maneuvers in Autonomous Vehicles. In Proceedings of the 2023 IEEE International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 1–6. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Araluce, J.; Bergasa, L.M. Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator. Sensors 2022, 22, 8373. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. arXiv 2018, arXiv:1812.05784. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Transformer-Based | Attention + LSTM | Decision Control | Tactical Behaviour | Ours |
| Ref. | [15] | [18] | [21] | [24] | - |
| State Dimensionality | High | High | Low | Low | Low |
| Pre-Processing | Transformer | Attention | - | - | Map |
| Action | Low-level | Low-level | High-level | High-level | High-level |
| Control Signal | Sharp | Sharp | Smooth | Smooth | Smooth |
| Multiple Scenario | ✓ | ✓ | × | ✓ | ✓ |
| Concatenated Scenario | × | × | × | ✓ | ✓ |
| Computational Cost | High | High | High | Low | Low |
| Scalability | ✓ | ✓ | × | × | ✓ |
| Real Implementation | × | ✓ | × | × | ✓ |
| Aspect | End-to-End | Modular | Ego-Only | Connected |
| Key Advantage | Reduces intermediate errors. | Enhanced interpretability and allows for parallel development. | Operates independently. | Enhanced situational awareness. |
| Key Disadvantage | Lacks interpretability and is difficult to implement in safety-critical systems. | Risk of error propagation and suboptimal integration of subsystems. | Limited situational awareness and no access to external data. | Dependency on reliable network infrastructure and privacy concerns. |
| Integration Complexity | High. | Medium. | Low. | High. |
| Real-World Usage | Limited. | Used. | Used. | Used. |
| Scalability | High. | Moderate. | High. | High. |
| Metric | Ours | Autopilot | [29] |
| Success Rate [%] ↑ | 95.76 | 100 | 92.84 |
| 95th Percentile of Jerk (per episode, in m/s3) ↓ | 1.87 | 4.63 | 2.10 |
| Maximum Jerk (per episode, in m/s3) ↓ | 3.97 | 4.92 | 4.08 |
| 95th Percentile of Acceleration (per episode, in m/s2) ↓ | 2.13 | 2.98 | 1.88 |
| Time (s) ↓ | 76.85 | 140.23 | 88.43 |
| Speed (in m/s) ↑ | 6.60 | 2.75 | 4.74 |
| Metric | Obsevations | Day | Night | Rain | Fog |
| Success Rate [%] ↑ | GT | 95.76 | 95.12 | 94.13 | 95.63 |
| Sensors | 81.39 | 75.34 | 80.90 | 79.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Arango, F.; Sánchez-García, F.; Bergasa, L.M. Enhancing Autonomous Driving in Urban Scenarios: A Hybrid Approach with Reinforcement Learning and Classical Control. Sensors 2025, 25, 117. https://doi.org/10.3390/s25010117
Gutiérrez-Moreno R, Barea R, López-Guillén E, Arango F, Sánchez-García F, Bergasa LM. Enhancing Autonomous Driving in Urban Scenarios: A Hybrid Approach with Reinforcement Learning and Classical Control. Sensors. 2025; 25(1):117. https://doi.org/10.3390/s25010117
Chicago/Turabian StyleGutiérrez-Moreno, Rodrigo, Rafael Barea, Elena López-Guillén, Felipe Arango, Fabio Sánchez-García, and Luis M. Bergasa. 2025. "Enhancing Autonomous Driving in Urban Scenarios: A Hybrid Approach with Reinforcement Learning and Classical Control" Sensors 25, no. 1: 117. https://doi.org/10.3390/s25010117
APA StyleGutiérrez-Moreno, R., Barea, R., López-Guillén, E., Arango, F., Sánchez-García, F., & Bergasa, L. M. (2025). Enhancing Autonomous Driving in Urban Scenarios: A Hybrid Approach with Reinforcement Learning and Classical Control. Sensors, 25(1), 117. https://doi.org/10.3390/s25010117