
Multi-Granularity Aggregation with Spatiotemporal Consistency for Video-Based Person Re-Identification


Abstract
1. Introduction
2. Related Work
2.1. Video-Based Person ReID
2.2. Attention for Person ReID
2.3. Spatiotemporal Aggregation
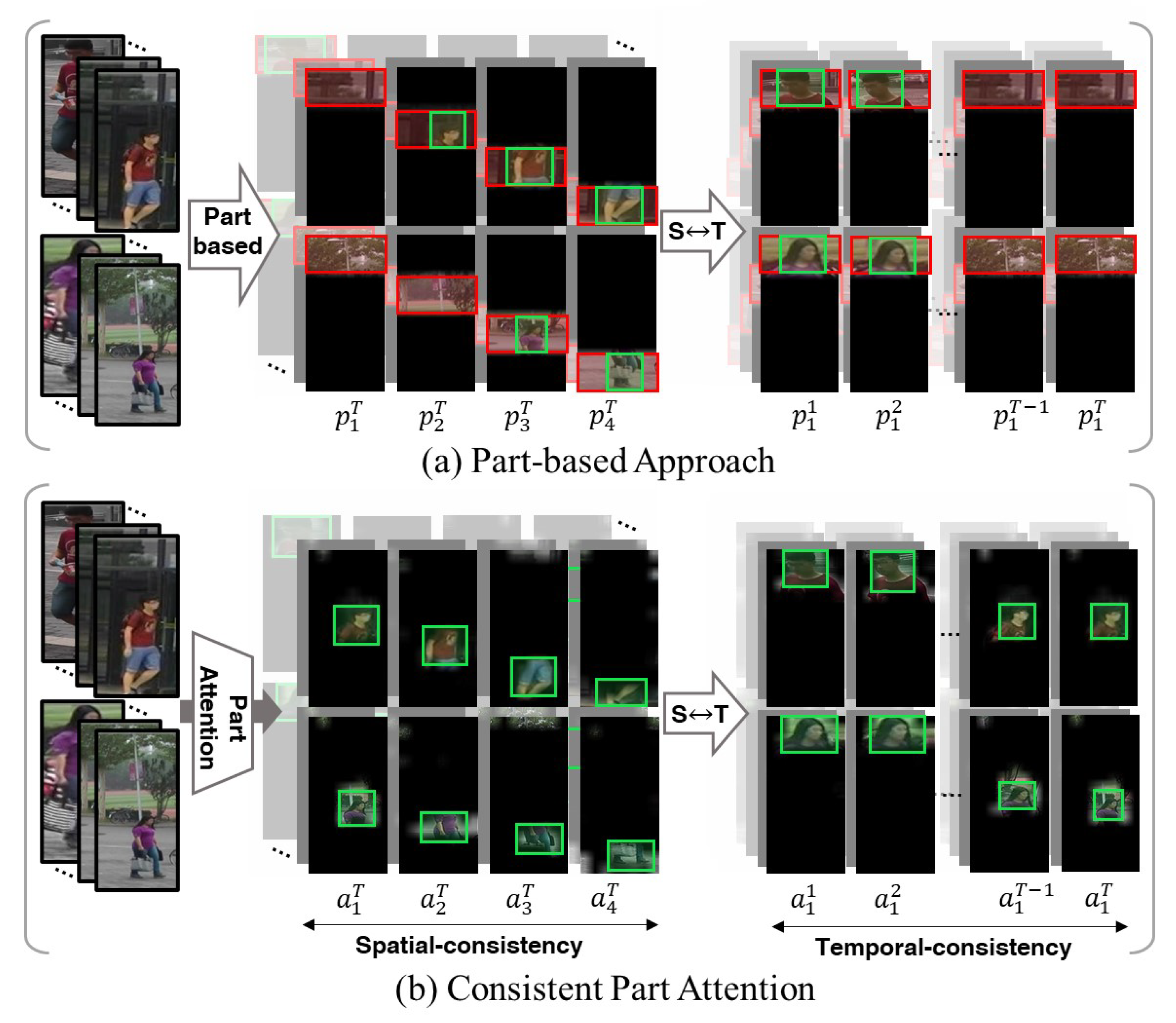
3. Methodologies
3.1. Overview
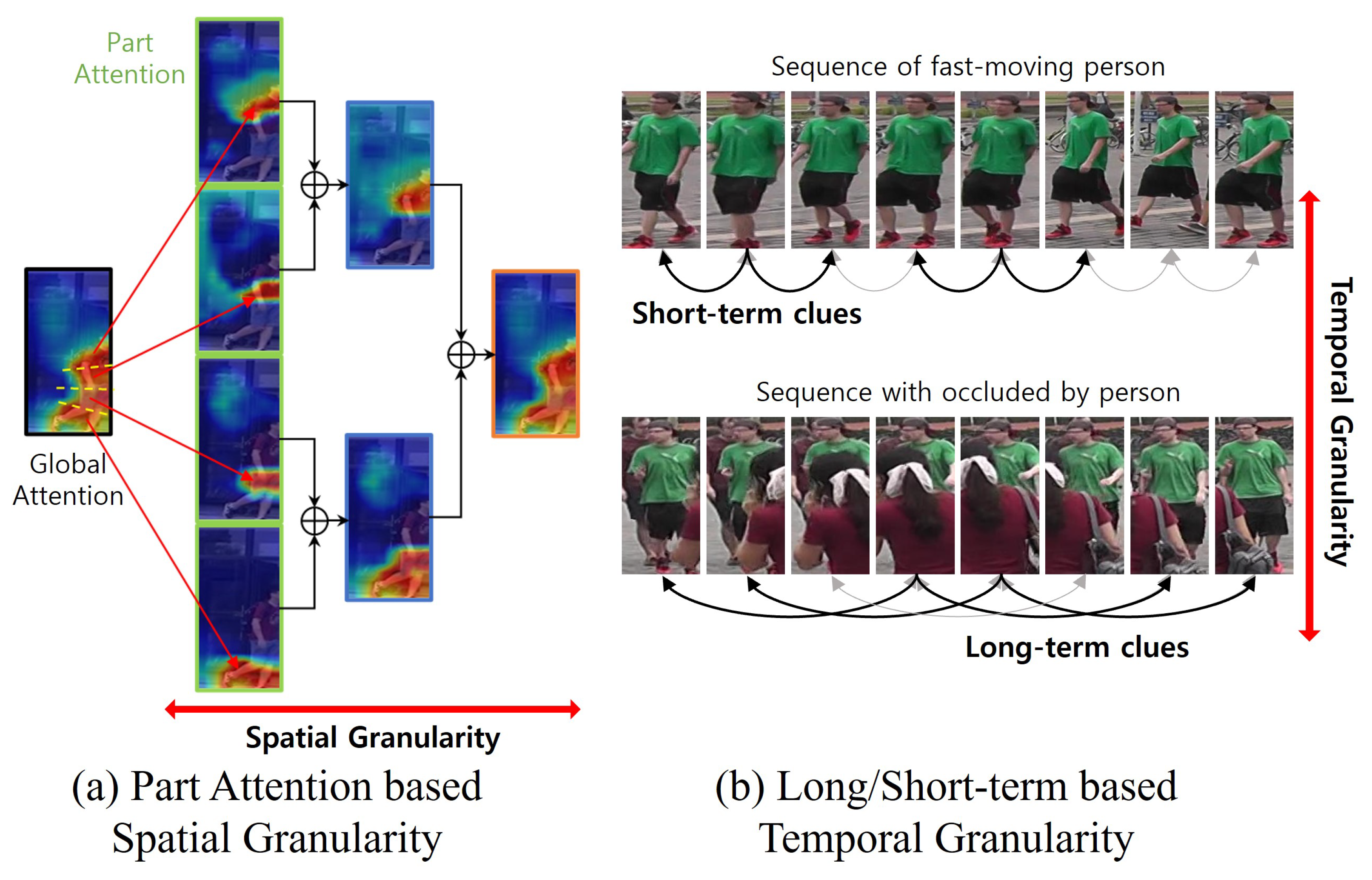
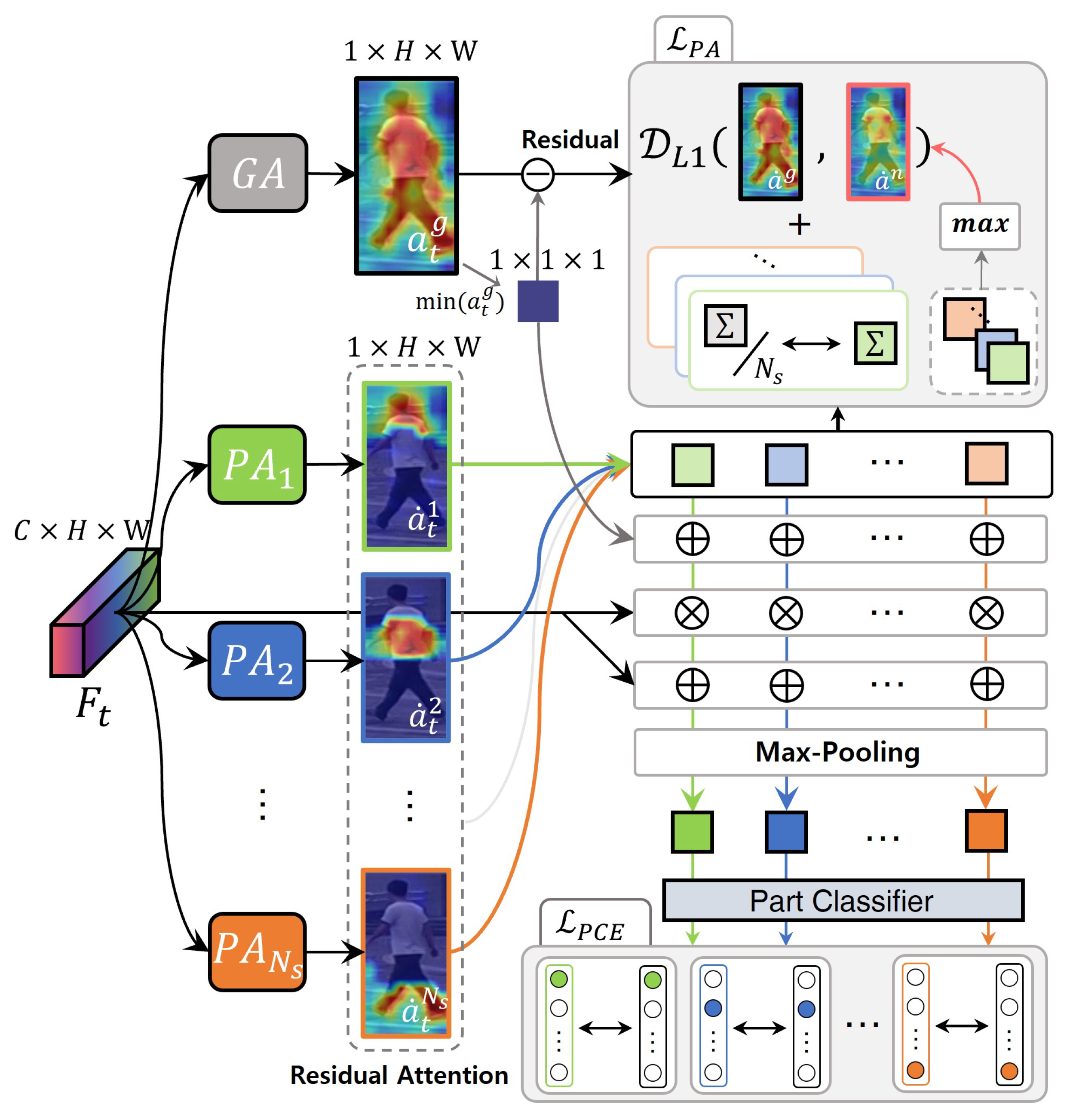
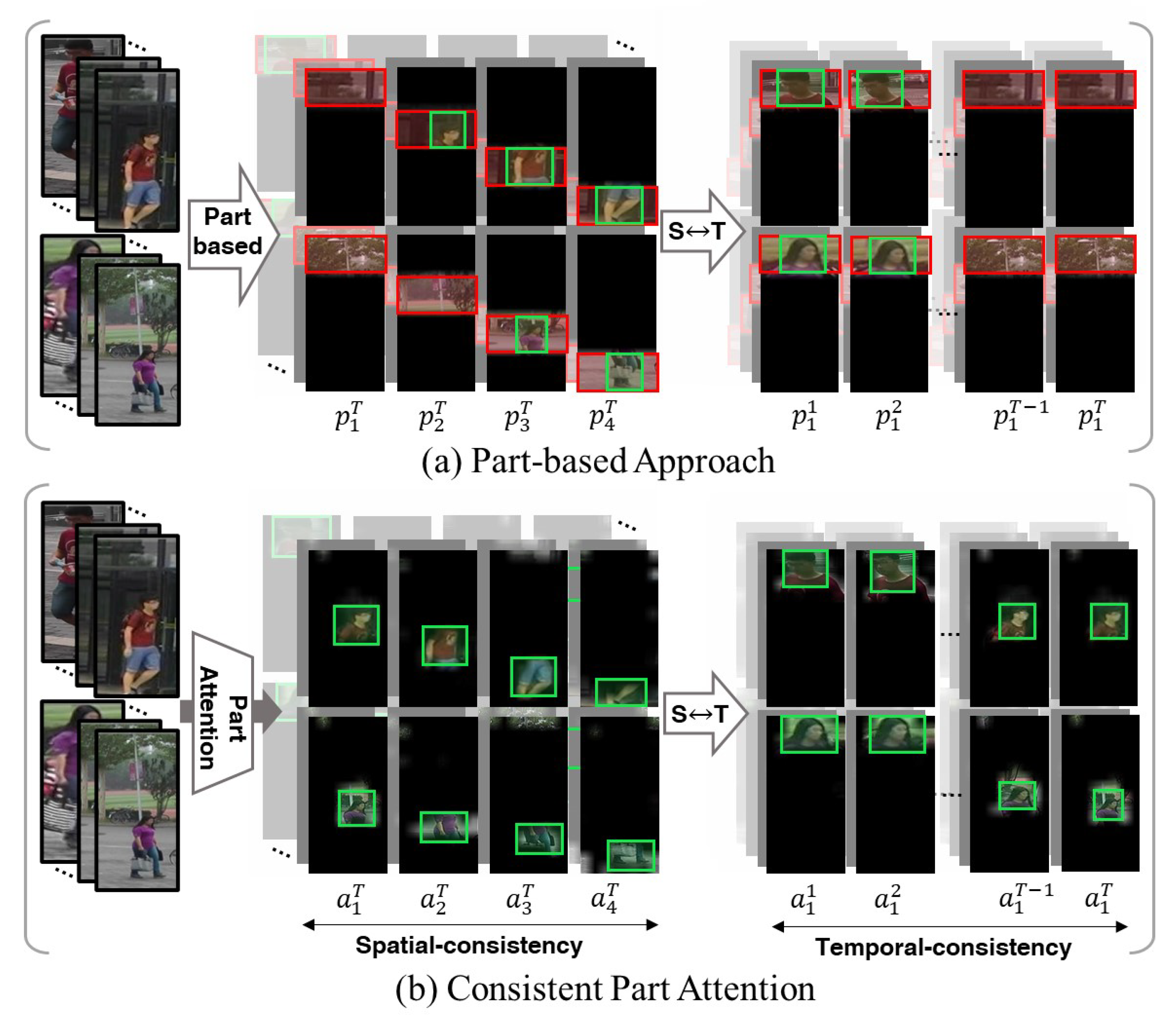
3.2. Spatiotemporally Consistent Part Attention
3.3. Multi-Granularity Feature Augmentation
3.4. Spatiotemporal Multi-Granularity Aggregation
4. Experiments
4.1. Datasets and Evaluation Metric
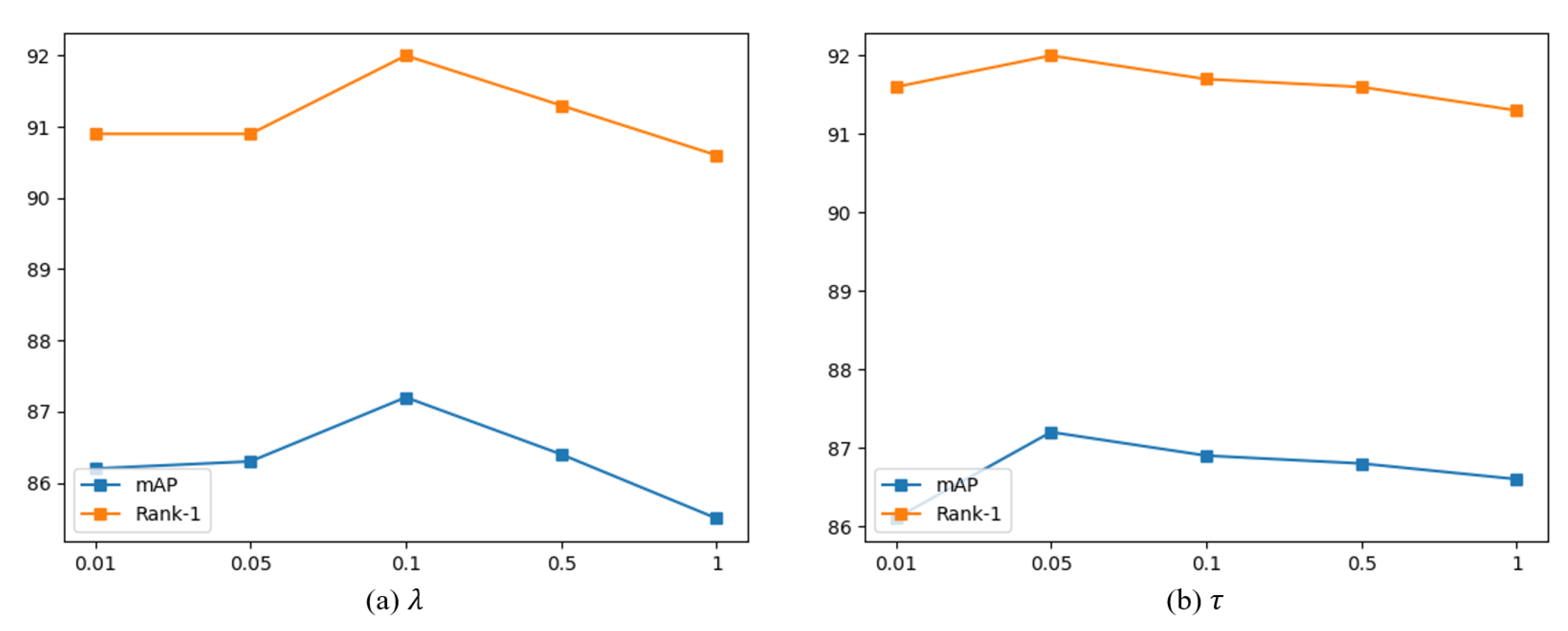
4.2. Implementation Details
4.3. Ablation Study
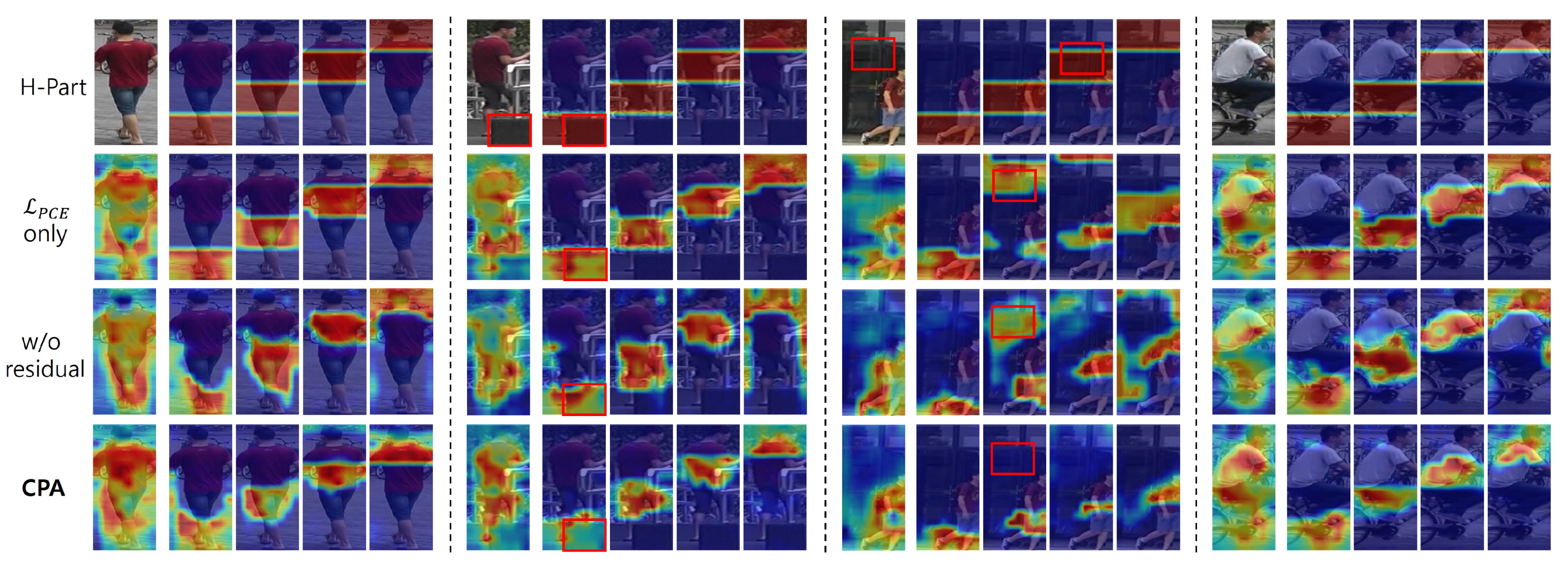
4.3.1. The Influence of CPA
4.3.2. Comparison of Part-Based and CPA Models
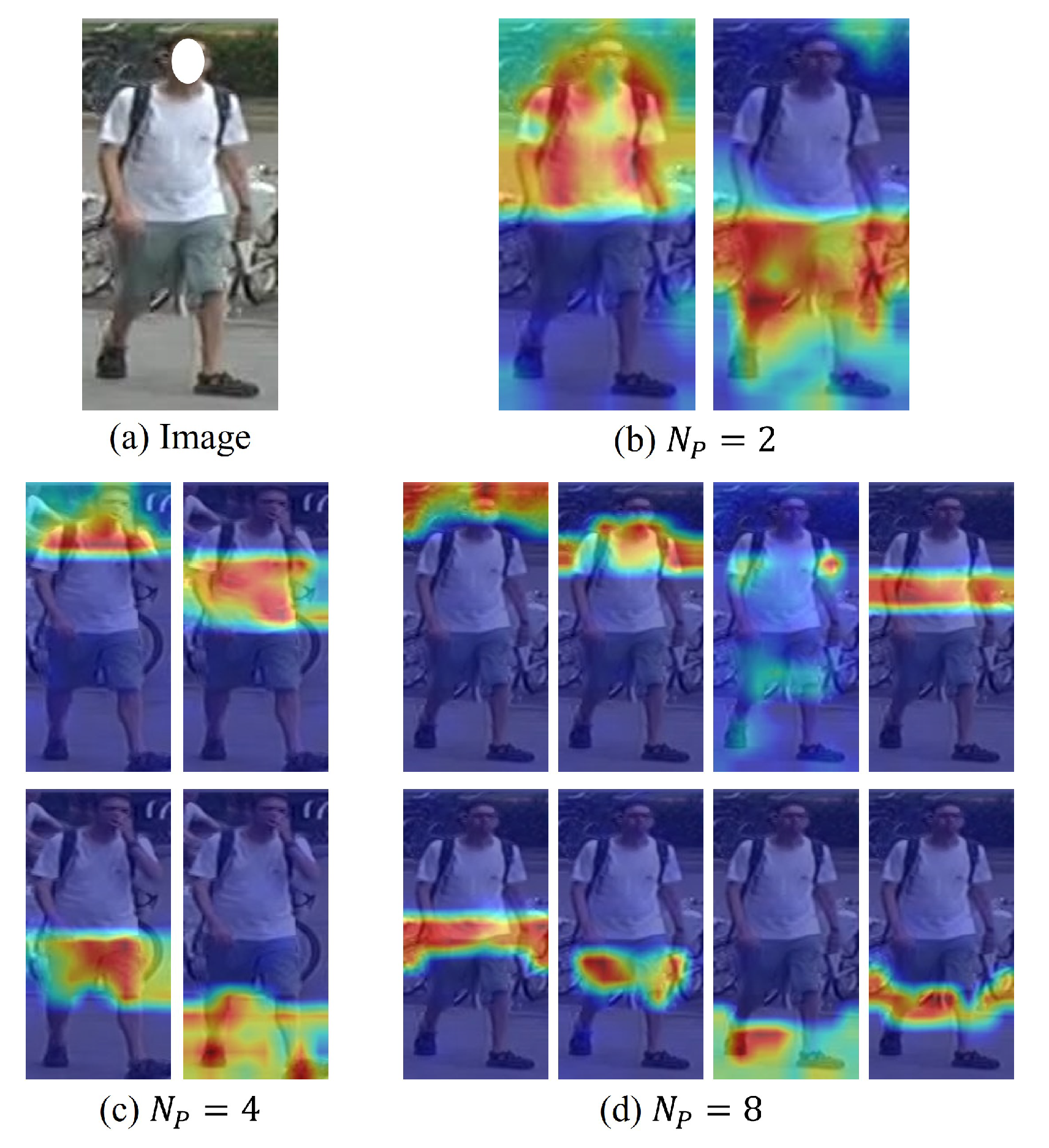
4.3.3. The Influence of Granularity
4.3.4. Effectiveness of ST-MGA
4.4. Comparison and Visualization
4.4.1. Comparison with the State of the Art
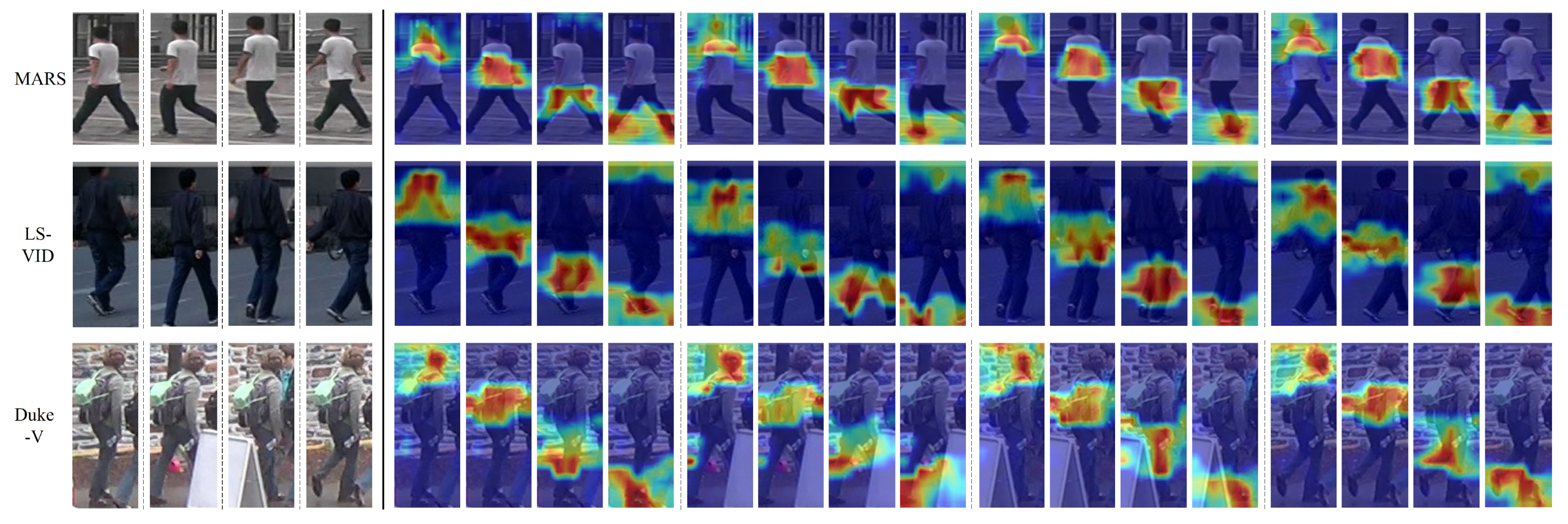
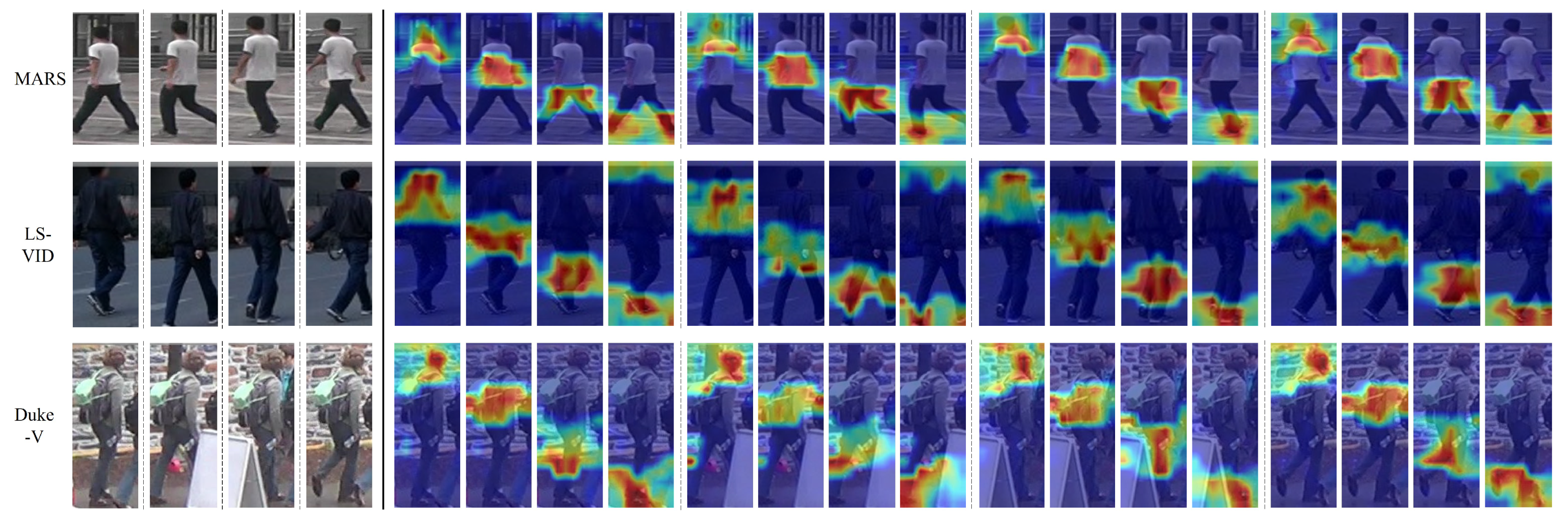
4.4.2. Visualization Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, K.; Ma, B.; Zhang, W.; Huang, R. A spatio-temporal appearance representation for viceo-based pedestrian re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3810–3818. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VI 14. Springer: Cham, Switzerland, 2016; pp. 868–884. [Google Scholar]
- Liu, Z.; Wang, Y.; Li, A. Hierarchical integration of rich features for video-based person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3646–3659. [Google Scholar] [CrossRef]
- Kim, M.; Cho, M.; Lee, S. Feature Disentanglement Learning with Switching and Aggregation for Video-based Person Re-Identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 1603–1612. [Google Scholar]
- Chen, D.; Li, H.; Xiao, T.; Yi, S.; Wang, X. Video person re-identification with competitive snippet-similarity aggregation and co-attentive snippet embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1169–1178. [Google Scholar]
- McLaughlin, N.; Del Rincon, J.M.; Miller, P. Recurrent convolutional network for video-based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1325–1334. [Google Scholar]
- Fu, Y.; Wang, X.; Wei, Y.; Huang, T. Sta: Spatial-temporal attention for large-scale video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8287–8294. [Google Scholar]
- Xu, S.; Cheng, Y.; Gu, K.; Yang, Y.; Chang, S.; Zhou, P. Jointly attentive spatial-temporal pooling networks for video-based person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4733–4742. [Google Scholar]
- Liu, Y.; Yan, J.; Ouyang, W. Quality aware network for set to set recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5790–5799. [Google Scholar]
- Gao, J.; Nevatia, R. Revisiting temporal modeling for video-based person reid. arXiv 2018, arXiv:1805.02104. [Google Scholar]
- Li, S.; Bak, S.; Carr, P.; Wang, X. Diversity regularized spatiotemporal attention for video-based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 369–378. [Google Scholar]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X.S. Attribute-driven feature disentangling and temporal aggregation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4913–4922. [Google Scholar]
- Liu, Y.; Yuan, Z.; Zhou, W.; Li, H. Spatial and temporal mutual promotion for video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8786–8793. [Google Scholar]
- Yang, J.; Zheng, W.S.; Yang, Q.; Chen, Y.C.; Tian, Q. Spatial-temporal graph convolutional network for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3289–3299. [Google Scholar]
- Yan, Y.; Qin, J.; Chen, J.; Liu, L.; Zhu, F.; Tai, Y.; Shao, L. Learning multi-granular hypergraphs for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2899–2908. [Google Scholar]
- Wu, Y.; Bourahla, O.E.F.; Li, X.; Wu, F.; Tian, Q.; Zhou, X. Adaptive graph representation learning for video person re-identification. IEEE Trans. Image Process. 2020, 29, 8821–8830. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.T.; Wu, C.W.; Wang, Y.C.F.; Chien, S.Y. Spatially and temporally efficient non-local attention network for video-based person re-identification. arXiv 2019, arXiv:1908.01683. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Temporal complementary learning for video person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Cham, Switzerland, 2020; pp. 388–405. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Huang, R.; Shan, S. Bicnet-tks: Learning efficient spatial-temporal representation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2014–2023. [Google Scholar]
- Tao, H.; Duan, Q.; An, J. An Adaptive Interference Removal Framework for Video Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5148–5159. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Multi-granularity reference-aided attentive feature aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10407–10416. [Google Scholar]
- Li, J.; Wang, J.; Tian, Q.; Gao, W.; Zhang, S. Global-local temporal representations for video person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3958–3967. [Google Scholar]
- Li, J.; Zhang, S.; Huang, T. Multi-scale 3d convolution network for video based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8618–8625. [Google Scholar]
- Li, X.; Zhou, W.; Zhou, Y.; Li, H. Relation-guided spatial attention and temporal refinement for video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11434–11441. [Google Scholar]
- Chen, Z.; Zhou, Z.; Huang, J.; Zhang, P.; Li, B. Frame-guided region-aligned representation for video person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10591–10598. [Google Scholar]
- Zhao, J.; Qi, F.; Ren, G.; Xu, L. Phd learning: Learning with pompeiu-hausdorff distances for video-based vehicle re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2225–2235. [Google Scholar]
- Gu, X.; Chang, H.; Ma, B.; Zhang, H.; Chen, X. Appearance-preserving 3d convolution for video-based person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Cham, Switzerland, 2020; pp. 228–243. [Google Scholar]
- Chen, G.; Rao, Y.; Lu, J.; Zhou, J. Temporal coherence or temporal motion: Which is more critical for video-based person re-identification? In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Cham, Switzerland, 2020; pp. 660–676. [Google Scholar]
- Jiang, X.; Qiao, Y.; Yan, J.; Li, Q.; Zheng, W.; Chen, D. SSN3D: Self-separated network to align parts for 3D convolution in video person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1691–1699. [Google Scholar]
- Eom, C.; Lee, G.; Lee, J.; Ham, B. Video-based person re-identification with spatial and temporal memory networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12036–12045. [Google Scholar]
- Aich, A.; Zheng, M.; Karanam, S.; Chen, T.; Roy-Chowdhury, A.K.; Wu, Z. Spatio-temporal representation factorization for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 152–162. [Google Scholar]
- Bai, S.; Ma, B.; Chang, H.; Huang, R.; Chen, X. Salient-to-broad transition for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7339–7348. [Google Scholar]
- Wu, J.; He, L.; Liu, W.; Yang, Y.; Lei, Z.; Mei, T.; Li, S.Z. CAViT: Contextual Alignment Vision Transformer for Video Object Re-identification. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 549–566. [Google Scholar]
- Bai, S.; Ma, B.; Chang, H.; Huang, R.; Shan, S.; Chen, X. SANet: Statistic attention network for video-based person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3866–3879. [Google Scholar] [CrossRef]
- Wang, Z.; He, L.; Tu, X.; Zhao, J.; Gao, X.; Shen, S.; Feng, J. Robust video-based person re-identification by hierarchical mining. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 8179–8191. [Google Scholar] [CrossRef]
- Chen, C.; Ye, M.; Qi, M.; Wu, J.; Liu, Y.; Jiang, J. Saliency and granularity: Discovering temporal coherence for video-based person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6100–6112. [Google Scholar] [CrossRef]
- Pan, H.; Liu, Q.; Chen, Y.; He, Y.; Zheng, Y.; Zheng, F.; He, Z. Pose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7183–7196. [Google Scholar] [CrossRef]
- He, T.; Jin, X.; Shen, X.; Huang, J.; Chen, Z.; Hua, X.S. Dense interaction learning for video-based person re-identification supplementary materials. Identities 2021, 1, 300. [Google Scholar]
- Zhou, Z.; Huang, Y.; Wang, W.; Wang, L.; Tan, T. See the forest for the trees: Joint spatial and temporal recurrent neural networks for video-based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4747–4756. [Google Scholar]
- Liao, X.; He, L.; Yang, Z.; Zhang, C. Video-based person re-identification via 3d convolutional networks and non-local attention. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part VI 14. Springer: Cham, Switzerland, 2019; pp. 620–634. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Song, G.; Leng, B.; Liu, Y.; Hetang, C.; Cai, S. Region-based quality estimation network for large-scale person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chen, B.; Deng, W.; Hu, J. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 371–381. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 365–381. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3219–3228. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Chen, H.; Zhao, Y.; Wang, S. Person Re-Identification Based on Contour Information Embedding. Sensors 2023, 23, 774. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3186–3195. [Google Scholar]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. Abd-net: Attentive but diverse person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8351–8361. [Google Scholar]
- Kim, M.; Cho, M.; Lee, H.; Cho, S.; Lee, S. Occluded person re-identification via relational adaptive feature correction learning. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2719–2723. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Si, J.; Zhang, H.; Li, C.G.; Kuen, J.; Kong, X.; Kot, A.C.; Wang, G. Dual attention matching network for context-aware feature sequence based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5363–5372. [Google Scholar]
- Liu, J.; Zha, Z.J.; Wu, W.; Zheng, K.; Sun, Q. Spatial-temporal correlation and topology learning for person re-identification in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4370–4379. [Google Scholar]
- Tao, H.; Lu, M.; Hu, Z.; Xin, Z.; Wang, J. Attention-aggregated attribute-aware network with redundancy reduction convolution for video-based industrial smoke emission recognition. IEEE Trans. Ind. Inform. 2022, 18, 7653–7664. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Wang, Y.; Zhang, P.; Gao, S.; Geng, X.; Lu, H.; Wang, D. Pyramid spatial-temporal aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12026–12035. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Wu, Y.; Lin, Y.; Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5177–5186. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Densely semantically aligned person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 667–676. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 20 February 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Source | Methodology |
|---|---|---|
| M3D [28] | AAAI’19 | Proposed multi-scale 3D-convolution layer to refine the temporal features |
| STA [7] | AAAI’19 | Proposed spatial–temporal attention approach to fully exploit discriminative parts |
| GLTR [27] | ICCV’19 | Proposed global–local temporal representation to exploit multi-scale temporal cues |
| RGSA [29] | AAAI’20 | Designed relation-guided spatial-attention module to explore discriminative regions |
| FGRA [30] | AAAI’20 | Proposed frame-guided region-aligned model to extract well-aligned part features |
| MG-RAFA [26] | CVPR’20 | Suggested attentive feature aggregation with multi-granularity information |
| PhD [31] | CVPR’20 | Proposed Pompeiu–Hausdorff distance learning to alleviate the data noise problem |
| STGCN [14] | CVPR’20 | Jointly optimized two GCN branches in spatial and temporal dimensions for complementary information |
| MGH [15] | CVPR’20 | Designed a multi-granular hypergraph structure to increase representational capacities |
| TCLNet [18] | ECCV’20 | Introduced a temporal-saliency-erasing module to focus on diverse part information |
| AP3D [32] | ECCV’20 | Proposed appearance-preserving 3D-convolution to align the adjacent features at the pixel level |
| AFA [33] | ECCV’20 | Proposed adversarial feature augmentation, which highlights the temporal coherence features |
| SSN3D [34] | AAAI’21 | Designed a self-separated network to seek out the same parts in different frames |
| BiCnet-TKS [19] | CVPR’21 | Used multiple parallel and diverse attention modules to discover diverse body parts |
| STMN [35] | ICCV’21 | Leveraged spatial and temporal memories to refine frame-/sequence-level representations |
| STRF [36] | ICCV’21 | Proposed spatiotemporal representation factorization for learning discriminative features |
| SINet [37] | CVPR’22 | Designed SINet to enlarge attention regions for consecutive frames gradually |
| CAVIT [38] | ECCV’22 | Used a contextual alignment vision transformer for spatiotemporal interaction |
| SANet [39] | TCSVT’22 | Introduced the SA block, which can capture long-range and high-order information |
| HMN [40] | TCSVT’22 | Designed hierarchical mining network which can mine as many characteristics |
| SGMN [41] | TCSVT’22 | Designed a saliency- and granularity-mining network for discovering temporal coherence |
| BIC+LGCN [42] | TCSVT’23 | Used a branch architecture to separately learn appearance features and human pose |
| IRNet-V [20] | TCSVT’23 | Proposed an interference-removal framework for removing various interferences |
| Notations | Descriptions |
|---|---|
| Input video | |
| T | Length of |
| F | Output feature from backbone |
| A | Set of part attentions from CPA |
| Set of residual part attentions in CPA | |
| P | Set of part-attentive features |
| Set of augmented part attentions from MA-PA | |
| Set of augmented spatial attentive features after MA-PA | |
| Temporal attention value in LS-TA | |
| Set of augmented multi-granular features after LS-TA | |
| Global averaged feature from backbone | |
| Temporal aggregated feature from T-MGA | |
| Final complementary video feature from S-MGA |
| MARS | Duke-V | LS-VID | |
|---|---|---|---|
| # Identities | 1261 | 1404 | 3772 |
| # of Videos | 20,751 | 4832 | 14,943 |
| # of Cameras | 6 | 8 | 15 |
| B-Box | DPM | manual | FRCNN |
| mAP | Rank-1 | Rank-5 | Rank-10 | |||
|---|---|---|---|---|---|---|
| 85.2 | 89.1 | 86.7 | 97.5 | |||
| ✓ | 85.5 | 89.9 | 96.9 | 97.7 | ||
| ✓ | ✓ | 85.6 | 90.1 | 96.9 | 97.9 | |
| ✓ | ✓ | ✓ | 86.8 | 90.9 | 97.4 | 98.0 |
| Model | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|
| Baseline | 85.2 | 89.1 | 86.7 | 97.5 |
| Part 4 | 85.5 | 89.9 | 96.9 | 97.7 |
| Part 8 | 85.6 | 90.1 | 96.9 | 97.9 |
| CPA 2 | 86.5 | 90.7 | 97.0 | 97.8 |
| CPA 4 | 86.7 | 91.4 | 97.0 | 97.9 |
| CPA 8 | 86.7 | 91.6 | 97.1 | 98.1 |
| Spatial | Temporal | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|---|
| - | - | 85.2 | 89.1 | 86.7 | 97.5 |
| 1, 2 | 1 | 86.5 | 90.7 | 97.0 | 97.8 |
| 1, 2, 4 | 1 | 86.7 | 91.1 | 97.5 | 98.0 |
| 1, 2, 4, 8 | 1 | 86.7 | 91.9 | 97.2 | 97.8 |
| 1, 2, 4 | 1, 3 | 86.8 | 90.6 | 97.2 | 97.9 |
| 1, 2, 4 | 1, 3, 5 | 87.2 | 92.0 | 97.3 | 98.1 |
| 1, 2, 4, 8 | 1, 3 | 87.0 | 90.9 | 97.4 | 98.1 |
| 1, 2, 4, 8 | 1, 3, 5 | 86.9 | 91.2 | 97.4 | 98.0 |
| Part | Scale | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|---|
| 86.3 | 90.5 | 97.1 | 97.8 | ||
| ✓ | 87.2 | 91.0 | 97.3 | 98.1 | |
| ✓ | 87.0 | 90.9 | 97.3 | 98.1 | |
| ✓ | ✓ | 87.2 | 92.0 | 97.3 | 98.0 |
| Model | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|
| Baseline | 85.2 | 89.1 | 86.7 | 97.5 |
| P-MGA | 85.9 | 90.5 | 96.5 | 97.6 |
| S-MGA | 86.9 | 90.9 | 97.2 | 98.1 |
| T-MGA | 86.1 | 90.8 | 97.0 | 97.8 |
| T-MGA | 86.0 | 90.9 | 96.9 | 97.8 |
| S-MGA | 87.2 | 91.5 | 97.3 | 98.1 |
| T-MGA | 87.2 | 92.0 | 97.3 | 98.0 |
| Method | MARS | Duke-V | LS-VID | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank1 | Rank5 | mAP | Rank-1 | Rank-5 | mAP | Rank-1 | Rank-5 | |
| M3D [28] | 74.1 | 84.4 | - | - | - | - | 40.1 | 57.7 | - |
| STA [7] | 80.8 | 86.3 | 95.7 | 94.9 | 96.2 | 99.3 | - | - | - |
| GLTR [27] | 78.5 | 87.0 | 95.8 | 93.7 | 96.3 | 99.3 | 44.3 | 63.1 | 77.2 |
| RGSA [29] | 84.0 | 89.4 | - | 95.8 | 97.2 | - | - | - | - |
| FGRA [30] | 81.2 | 87.3 | 96.0 | - | - | - | - | - | - |
| MG-RAFA [26] | 85.8 | 90.0 | 86.7 | - | - | - | - | - | - |
| PhD [31] | 85.8 | 90.0 | 96.7 | - | - | - | - | - | - |
| STGCN [14] | 83.7 | 90.0 | 86.4 | 95.7 | 97.3 | 99.3 | - | - | - |
| MGH [15] | 85.8 | 90.0 | 96.7 | - | - | - | - | - | - |
| TCLNet [18] | 85.8 | 89.8 | - | 96.2 | 96.9 | - | - | - | - |
| AP3D [32] | 85.1 | 90.1 | - | 95.6 | 96.3 | - | - | - | |
| AFA [33] | 82.9 | 90.2 | 96.6 | 95.4 | 97.2 | 99.4 | - | - | - |
| SSN3D [34] | 86.2 | 90.1 | 96.6 | 96.3 | 96.8 | 98.8 | - | - | - |
| BiCnet-TKS [19] | 86.0 | 90.2 | - | 96.1 | 96.3 | - | 75.1 | 84.6 | - |
| STMN [35] | 84.5 | 90.5 | - | 95.9 | 97.0 | 69.2 | 82.1 | - | |
| STRF [36] | 86.1 | 90.3 | - | 96.4 | 97.4 | - | - | - | - |
| SINet [37] | 86.2 | 91.0 | - | - | - | - | 79.6 | 87.4 | - |
| CAVIT [38] | 87.2 | 90.8 | - | - | - | - | 79.2 | 89.2 | - |
| SANet [39] | 86.0 | 91.2 | 97.1 | 96.7 | 97.7 | 99.9 | - | - | - |
| HMN [40] | 82.6 | 88.5 | 96.2 | 96.1 | 96.3 | - | - | - | - |
| SGMN [41] | 85.4 | 90.8 | - | 96.3 | 96.9 | - | - | - | - |
| BIC+LGCN [42] | 86.5 | 91.1 | 97.2 | 96.5 | 97.1 | 98.8 | - | - | - |
| IRNet-V [20] | 87.0 | 92.5 | - | - | - | - | 80.5 | 89.4 | - |
| ST-MGA (ours) | 87.2 | 92.0 | 97.3 | 96.8 | 97.6 | 99.9 | 79.3 | 88.5 | 96.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.S.; Kim, M.; Jang, S.; Bae, H.B.; Lee, S. Multi-Granularity Aggregation with Spatiotemporal Consistency for Video-Based Person Re-Identification. Sensors 2024, 24, 2229. https://doi.org/10.3390/s24072229
Lee HS, Kim M, Jang S, Bae HB, Lee S. Multi-Granularity Aggregation with Spatiotemporal Consistency for Video-Based Person Re-Identification. Sensors. 2024; 24(7):2229. https://doi.org/10.3390/s24072229
Chicago/Turabian StyleLee, Hean Sung, Minjung Kim, Sungjun Jang, Han Byeol Bae, and Sangyoun Lee. 2024. "Multi-Granularity Aggregation with Spatiotemporal Consistency for Video-Based Person Re-Identification" Sensors 24, no. 7: 2229. https://doi.org/10.3390/s24072229
APA StyleLee, H. S., Kim, M., Jang, S., Bae, H. B., & Lee, S. (2024). Multi-Granularity Aggregation with Spatiotemporal Consistency for Video-Based Person Re-Identification. Sensors, 24(7), 2229. https://doi.org/10.3390/s24072229