The YOLO algorithm, proposed by Joseph Redmon et al. [
13] in 2016, has been optimized over the years to enhance the detection accuracy and computational efficiency of the algorithm. Despite the YOLO series [
39,
40,
41] has maintained a leading position in the real-time target detection field and demonstrated excellent performance in several application scenarios, there still exist limitations. Firstly, YOLOv5 still has much space for optimization in the balance between real-time and detection accuracy. Secondly, YOLOv5 is not sufficiently robust when dealing with targets that have significant aspect ratio variations, image distortions, and occluded targets; thus, there is the problem of missed detection. Finally, the model has limited adaptability to complex scenarios and is susceptible to background noise and complex lighting conditions, leading to unstable detection results. The YOLOv5 detection results are shown in
Figure 1.
To address the above issues, the following strategies are proposed in this study as a countermeasure.
Firstly, to address the problems of YOLOv5 in terms of balancing real-time and detection accuracy as well as the missing detection of targets with significant aspect ratio variations and image distortions, FPNet is proposed using FasterNet [
42] integrated with Dynamic Serpentine Convolution (DSConv) and replaced with the original backbone network, which ensures the detection accuracy of the model while reducing the number of model parameters and the amount of floating-point operations, as well as using adaptive variation to accurately extract structural features of targets with significant aspect ratio variations or image distortions. Subsequently, to address the issues of insufficiently robust processing when handling occluded targets and limited adaptability for complex scenarios, the SimAM [
43] attention mechanism is embedded in the backbone network and the large target detection head, and the C3-SFC module is proposed to enhance the feature extraction capability. Finally, an adaptive loss function based on a dynamic non-monotonic focusing mechanism,
Inner–WiseIoU, is proposed to enhance the fitting and generalization ability of the anchor box. The proposed YOLOv5-FPNet is shown in
Figure 2.
3.1. Design of FPNet
Chen et al. [
42] highlighted a major problem with lightweight neural networks: While numerous lightweight models have successfully reduced the number of parameters, most of them still rely on frequent memory accesses, which lengthens the execution time of the model. Comparatively, models that have reduced the frequency of memory accesses, such as MicroNet [
44], exhibit the problem of relying on inefficient fragmented computation, which contradicts the intended purpose of lightweight designs.
To address this problem, Chen et al. [
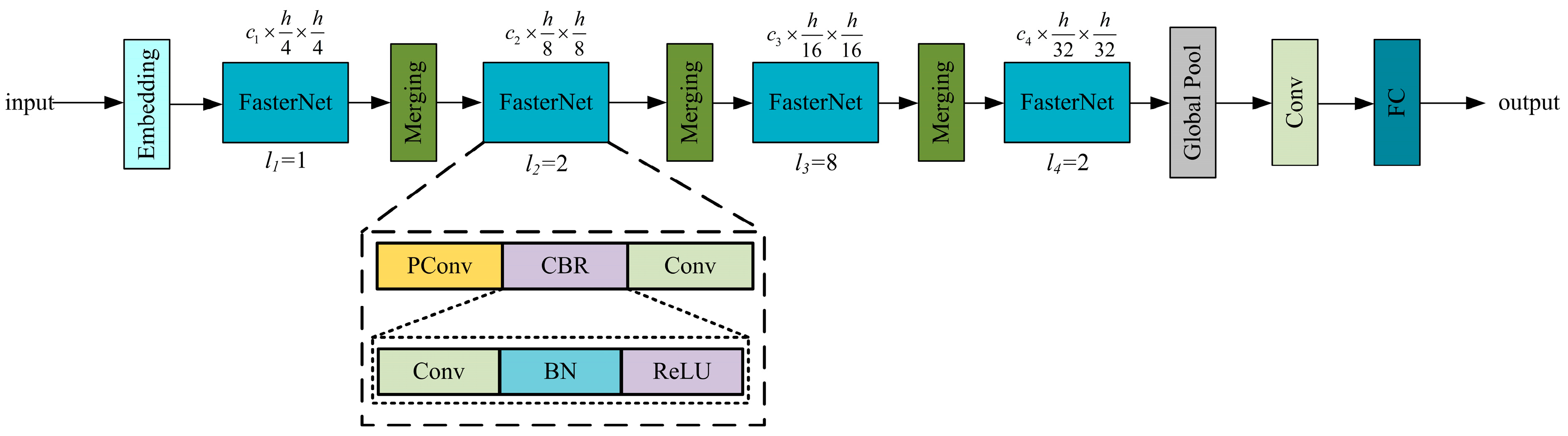
42] proposed FasterNet, which avoids unnecessary redundant operations, achieves a better balance between accuracy and real-time performance, and demonstrates great potential in edge device applications. A schematic diagram of the FasterNet structure is shown in
Figure 3.
However, when FasterNet was applied as a backbone for the experiment, the problem of missed detection of significant targets was observed. Missed targets are often caused by image distortion, resulting from the lens effect of the camera. This means that straight objects at the edge of the image may appear curved. Image distortion is a common occurrence during image acquisition, as shown in
Figure 4.
To address the above issues, this study adds deformable convolution kernels [
45,
46] based on FasterNet. The Dynamic Snake Convolution (DSConv) proposed by Qi et al. [
47] is used to improve the model’s ability to handle object shapes and details.
DSConv has demonstrated excellent performance in recognizing tubular objects because the flexibility of its convolutional kernel allows it to “stravaig” around the target object, efficiently adapting and accurately capturing the features of the tubular structure. Thus, the model’s performance, in terms of complex scenes and deformed objects, is improved.
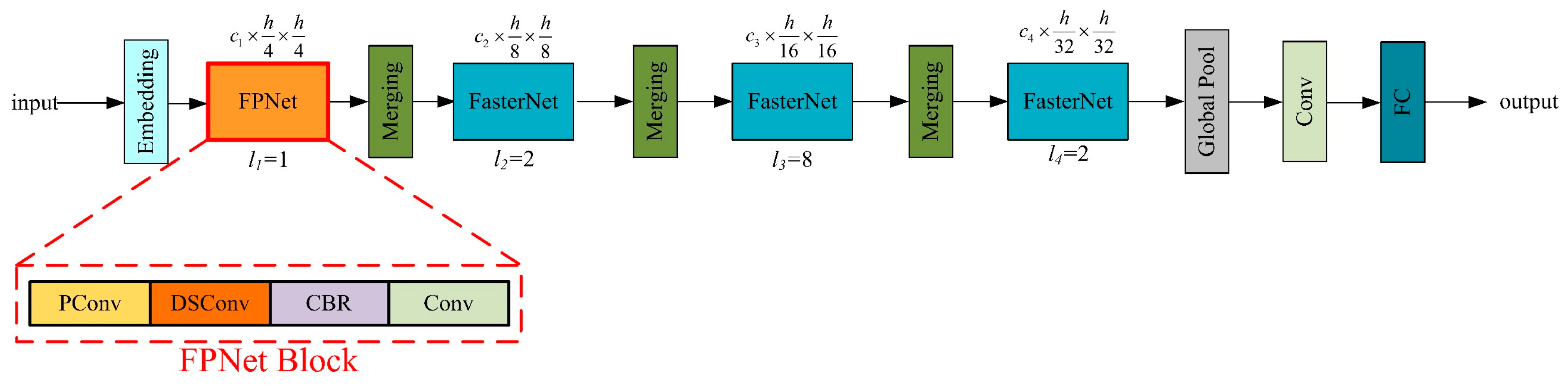
The structure of the proposed FPNet network after the addition of DSConv to FasterNet is shown in
Figure 5.
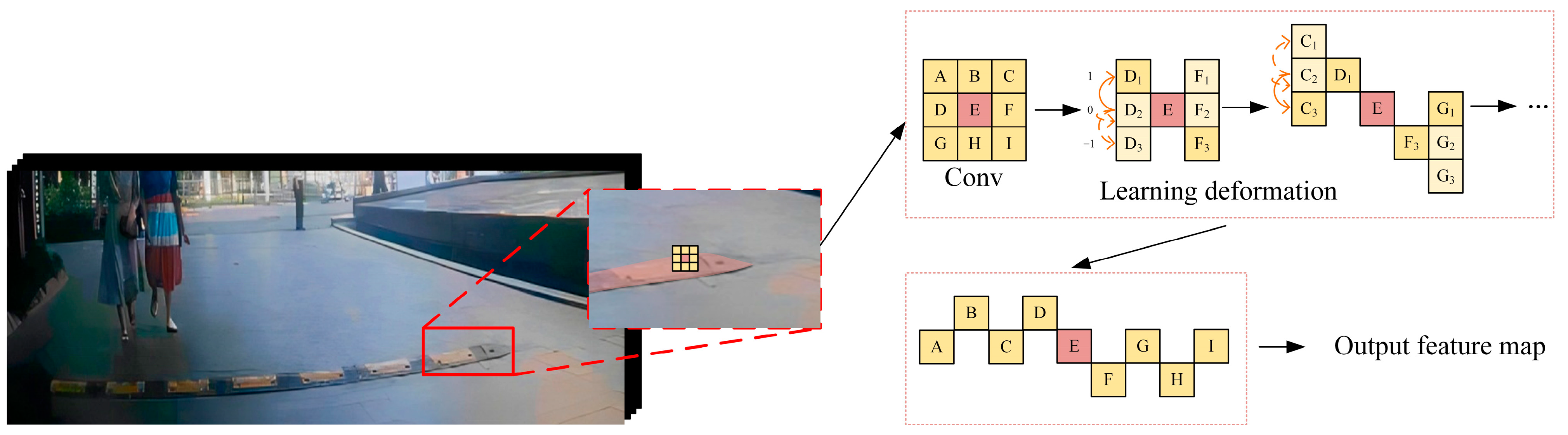
The deformation mechanism of DSConv is shown in
Figure 6.
The deformation rule of DSConv along the
x-axis is as follows:
The deformation rule along the
y-axis is as follows:
The offset Δ is typically a fraction, and the implementation of bilinear interpolation is as follows:
where
K denotes the position of the fraction in Equations (1) and (2),
K’ denotes all the enumerated integral spatial positions, and
B denotes the bilinear interpolation kernel. The bilinear interpolation kernel is divided into two one-dimensional kernels:
The deformation of the
x-axis and
y-axis coordinates is illustrated in a schematic diagram shown in
Figure 7.
Under the assumption that the range of values on the
x-axis is [
i − 4,
i + 4] and the range of values on the
y-axis is [
j − 4,
j + 4], the sensibility field of DSConv in this range of values is shown in
Figure 8.
Figure 8 shows that after coordinate deformation on the
x- and
y-axis, DSConv is able to obtain a receptive field that can cover an area of 9 × 9 for better perception of key features.
In order to fully evaluate the performance of DSConv, this thesis implemented a convolutional kernel performance comparison experiment. The experiment involved constructing a simple neural network model to which DSConv was applied. In order to establish the effectiveness and superiority of DSConv, the experiment specifically compared it to the currently dominant convolutional kernel. The detailed results of the experiment are collated and presented in
Table 1, and these data provide a quantitative basis for evaluating the performance of DSConv across different aspects.
According to the data given in
Table 1, DSConv has smaller parameters and almost the same FPS compared to the traditional Conv2d convolution kernel. Thus, DSConv achieves a good balance between accuracy and computation.
In summary, FPNet successfully solves the target loss problem due to image radial distortion and significantly improves the overall performance of the backbone in speed bump detection by introducing the deformation mechanism of DSConv into FasterNet.
3.3. Attention Mechanism
This study introduces the Simulation Attention Module (SimAM) proposed by Yang et al. [
43] to address the problem of lighting conditions and background noise affecting model detection accuracy in road target detection tasks. The purpose of SimAM is to enhance the ability of neural network models to concentrate on crucial areas in an image. This attention mechanism enables the network to more accurately identify and process important features of the target, thereby improving the accuracy and reliability of detection under complex environmental conditions.
SimAM achieves higher efficiency and smaller attention weights by utilizing the linear separability between neurons, without introducing additional parameters. The mechanism identifies key neurons and prioritizes them for attention, resulting in efficient feature map extraction. The principle of operating SimAM is illustrated in
Figure 10.
In this study, SimAM is embedded in the backbone network and the large target detection head in YOLOv5-FPNet to enhance target detection performance.
The theoretical basis of SimAM is derived from neuroscience and uses an energy function to define the linear separability between a neuron
t and every other neuron in the same channel except
t. This approach successfully differentiates the relative importance of neurons and implements an effective attention mechanism. Equation (5) determines the energy function for each neuron:
where
t represents the target neuron in a single channel of the input feature, and
xi represents other neurons in the same channel.
and
denote the results after
t and
xi undergo linear transformation, where
i indicates the spatial dimension index. The weight and bias of the linear transformation for the target neuron
t are represented using
and
, respectively.
λ is identified as a hyperparameter, and
M indicates the total number of neurons in a single channel.
and
can be obtained from the following equation:
By minimizing Equation (5), the equation is made equivalent to the linear separability between the target neuron
t and other neurons in the same channel. To simplify Equation (5),
yt and
y0 are marked using binary notation, and a regularization matrix is added to Equation (5), resulting in the final energy function, as shown in Equation (8):
The linear transformation weight
wt and the linear transformation bias for neuron
t are determined using Equations (6) and (7), respectively.
where
μt represents the mean of all neurons excluding neuron
t, and
σt2 represents the variance of all neurons excluding neuron
t.
The mean
μt of all neurons excluding neuron
t and the variance
σt2 of all neurons excluding neuron
t can be determined using Equations (8) and (9), respectively.
Assuming all pixels in a single channel follow the same distribution, the mean and variance of all neurons are calculated based on this assumption. These values are then reused across all neurons in that channel, significantly reducing the floating-point operation volume. The minimum energy
et* is determined using the following formula:
where
represents the variance including neuron
t, and
represents the mean including neuron
t; these values can be determined using the subsequent equations:
Utilizing Equation (13), it is understood that the value of the energy function is inversely correlated with the linear separability between neuron t and other neurons. This indicates that linear separability increases as the energy function value decreases. The design of the SimAM attention mechanism is guided by the energy function et*, thus effectively avoiding unnecessary heuristics and adjustments. By computing for individual neurons and integrating the concept of linear separability into the entire model, a significant enhancement in the model’s learning capability is achieved.
3.4. Inner–WiseIoU
Intersection over Union (IoU) is used to measure the similarity between predicted bounding boxes and actual annotations, with a primary focus on the amount of region overlap between predictions and actual conditions.
Most existing works, such as
GIoU [
51],
CIoU [
52],
DIoU [
52],
EIoU [
53], and
SIoU [
54], assume that instances in training data are of high quality and focus on enhancing the fitting ability of Bounding Box Regression (BBR) loss. However, indiscriminately strengthening BBR on low-quality instances can lead to a decline in localization performance, as some researchers have discovered. In 2023, Tong et al. [
55] built upon the static focusing mechanism (FM) proposed in
Focal-EIoU [
53] and introduced a loss function with a dynamic non-monotonic focusing mechanism called
Wise–IoU (
WIoU).
Since training data often include low-quality samples, this can result in a higher penalty for such samples, which can have a negative impact on the model’s ability to generalize. A well-designed loss function is expected to reduce the penalty on geometric factors and enhance the model’s generalization ability by minimizing interference from training interventions when there is a high degree of overlap between anchor boxes and target boxes.
To achieve this, a distance attention mechanism is introduced, and
WIoUv1 is designed with a dual-layer attention mechanism, as shown in Equation (16):
where
x and
y represent the center coordinates of the bounding box,
xgt and
ygt denote the characteristics of the target box, and
Wg and
Hg refer to the dimensions of the smallest enclosing box.
To prevent the generation of gradients that impede convergence in RWIoUv1, Wg and Hg are separated from the calculation in the image in WIoU, as represented using the * operation. This effectively eliminates factors that hinder convergence, and new metrics are not introduced with this method. This approach is particularly effective when handling non-overlapping bounding boxes.
Tong et al. [
55] further provide the monotonic focusing mechanism coefficient
for
WIoU for the monotonic focusing mechanism in focal loss, which can be defined using the following equation:
Additionally, Equation (16) is supplemented with the coefficients of the monotonic focusing mechanism to obtain the propagation gradient of the
WIoU, as shown in Equation (18):
It is worth noting that
=
r ∈ [0, 1], where
r represents the gradient gain. As
LIoU decreases, the gradient gain
r gradually decreases, resulting in the slower convergence of the anchor frame in the later stages of training. For the above reason, the
LIoU normalization factor is introduced, as shown in Equation (19):
where
represents the exponential running average with momentum
m. The purpose of the introduction of the normalization factor is to retain gradient gain
r at a high level, thus solving the problem of the slow convergence of the anchor frame in the later stages of training.
Furthermore, as all of the abovementioned
WIoU utilize a static monotonic focusing mechanism, it is possible to induce anomalies in the anchor boxes. During training, researchers often prefer the bounding box to return to a standard quality sample anchor box. Therefore, for anchor boxes with significant outliers, a smaller gradient gain should be assigned to prevent low-quality sample anchor boxes from having a substantial impact on the gradient. Thus, the researchers developed the non-monotonic focusing coefficient
τ and used it in Equation (16) to derive Equation (20):
where if
τ =
δ, then
r = 1. The anchor box achieves the maximum gradient gain when the anomaly of the anchor box satisfies
τ as a set constant value. The quality classification criterion of the anchor frame changes dynamically due to the dynamic nature of
x. This enables
WIoUv3 to adopt the most appropriate gradient gain allocation strategy for the current context at any moment, effectively optimizing the performance of the neural network model in local operation.
It is important to note that
WIoU remains a BBR-based method. While
IoU-based BBR methods aim to facilitate iterative convergence of the model by introducing new loss terms, they may overlook the inherent limitations of the
IoU loss function itself. Although the
IoU loss can effectively characterize the state of bounding box regression in theory, it does not adaptively adjust to different detectors and detection tasks, and its generalization ability is relatively limited in practice. To address these issues, Zhang et al. [
56] proposed
Inner–IoU in 2023.
Inner–IoU is designed to compensate for the weak convergence and slow convergence rates prevalent in loss functions widely utilized in various detection tasks. It introduces a scaling factor to control the proportional size of auxiliary bounding boxes, thus addressing the problem of weak generalization capabilities inherent in existing methods.
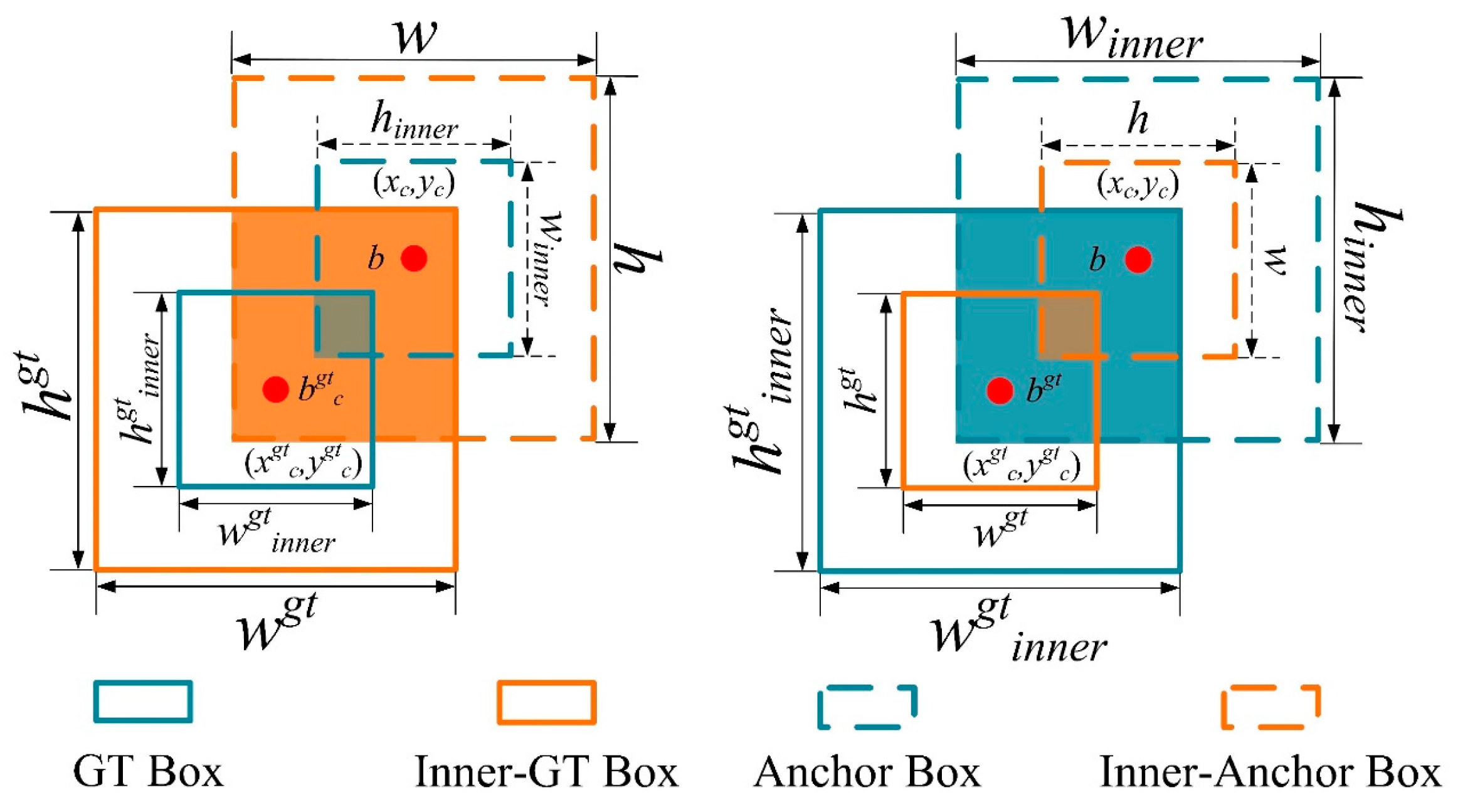
The operating mechanism of
Inner–IoU is illustrated in a schematic diagram shown in
Figure 11.
In
Figure 11,
bgt represents the center point of the annotated data box, and
b represents the center point of the anchor box. The coordinates of the center points for the annotated data box and the Inner annotated data box are (
xgtc,ygtc), and the coordinates for the anchor box and Inner anchor box are (
xc,yc).
wgt and
hgt represent the width and height of the annotated data box, respectively, while
w and
h represent the width and height of the anchor box.
The calculation formula for
Inner–IoU is presented in Equations (21)–(27):
where the variable
ratio represents the scaling factor, with
ratio ∈ [0.5, 1.5]; “inter” refers to the intersection between the Inner anchor box and the Inner annotated data box; and “union” denotes the intersection of the anchor box and the annotated data box minus “inter”.
It is important to note that, although Inner–IoU addresses the limitations in generalization capabilities of traditional IoU and can accelerate the convergence speed of high-quality instance anchor boxes, the issue of slowed convergence speed for anchor boxes due to low-quality instances still arises in the later stages of training. Furthermore, it has been observed through experimentation that the strengths and weaknesses of Inner–IoU and WIoU are complementary. Consequently, Inner–IoU and WIoU are combined in this study to form Inner–WIoU, which integrates the advantages of both to further enhance the fitting capability of anchor boxes in neural network models.
The calculation formula for
Inner–WIoU is presented in the following equation:
The experimental results presented in
Section 4.4 prove that
Inner–WIoU, compared to the currently latest applied
WIoU, exhibits superior generalization capabilities and faster convergence speed.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}