The exploration of supplementing or replacing the white cane for BVI people can be traced back to the 1940s [
8]. Ifukube et al. imitated the echolocation system of bats to detect small obstacles positioned in front of the user as early as 1991 [
9]. The size constraint poses difficulties for users who wear the device for extended periods, and the ultrasonic sensor hardware used was also less reliable and durable at the time. Ran et al. introduced a wearable assistance system called “Drishti”, which facilitated dynamic interactions and adaptability to different environments [
10]. However, the precision provided by the original equipment manufacturer’s ultrasound sensor was only 22 cm [
10], which hardly meets the requirements for reliable real-time obstacle avoidance. “NavBelt” utilised eight ultrasonic sensors arranged on the abdomen to scan obstacles within a range of 120° [
11]. The signals captured were subsequently processed via robotic obstacle avoidance algorithms [
11]. A limitation of this system is its inability to reliably detect obstacles located above the user’s head. A navigation system that incorporated a memory function with an integral accelerometer was proposed to compute and record walking distance as a form of guidance [
12]. The system included two vibrators and two ultrasonic sensors mounted on the user’s shoulders for obstacle detection, along with an additional ultrasonic sensor integrated into the white cane [
12]. To complete the initial navigation route, it required the BVI user to carry a cane with a sighted individual accompanying them. This approach encountered challenges in effectively managing cumulative tracking errors, often causing a failure after a certain period of operation. The performance of ultrasonic sensor hardware has been increasing over the past few decades, which possesses high sensitivity and penetration capabilities, making them suitable for sensor-based solutions. Gao and colleagues developed a wearable virtual cane network with four ultrasonic sensors placed on the wrists, waist, and ankle of the user, respectively [
13]. It is reported that the system can detect obstacles as small as 1 cm
located 0.7 m away [
13]. Bouteraa provided a glass-framed assistive device supported by three ultrasonic sensors and a hand band equipped with a LiDAR sensor in a recent study [
14]. It shows that the average walking time and the number of collisions are reduced compared to the conventional white cane used in their experiments, due to the integrated fuzzy decision support system [
14]. However, the participants did collide with some small harmless obstacles during the validation experiment [
14]. Both of the aforementioned studies incorporated the device with the upper limb, but the natural arm swing during walking was not considered.
A number of state-of-the-art techniques have gradually been integrated into developing wayfinding and mobile navigation assistance for BVI people with advancements in technologies such as edge computing, smart sensors, and AI. Related researchers and engineers attempted AR technology [
15], RFID [
16], and cloud systems [
17,
18,
19] to develop an intelligent and commercially viable navigation mechanism or system. Nevertheless, these techniques often require significant computational or external support, such as 5G connectivity or e-tags, which can pose challenges in terms of resource requirements and dependence on external infrastructure. These challenges are reflected in network availability, latency, data loss or corruption, scalability, and congestion. For example, network outages or signal interference can disrupt the smooth functioning of navigation that depends on continuous communication. Timely data exchange is crucial in obstacle detection applications, where even a small delay in network communication can lead to serious consequences.
With the rapid proliferation of deep learning-based computer vision models, vision sensors have become increasingly popular in various systems. Those equipped with depth detection capabilities, RGB-D cameras, are the most popular. They relied on structured light or time of flight to circumvent the weaknesses of purely visual techniques by measuring the direct distance physically. Hicks et al. built a ski goggle with a depth camera, a small digital gyroscope, and an LED display to assist poor vision individuals for navigation by utilising their functional residual vision [
20]. Aladrén et al. segmented obstacle-free pathways within the scenario by utilising depth and colour information captured via a consumer-grade RGB-D camera [
21]. The unobstructed path segmentation algorithm operated at a rate of two Frames Per Second (FPS), while the overall system, involving range data processing, RGB image processing, and user interface generation, ran at a slower speed of 0.3 FPS on a laptop [
21]. The method proposed by Yang et al. overcame the limitations of narrow depth field angles and sparse depth maps to improve close obstacle detection [
22]. Their approach expanded the initial traversable area via a seeded growing region algorithm [
22]. Lee and Medioni introduced a novel wearable navigation system combined with an RGB-D camera, a laptop, a smartphone user interface, and a haptic feedback vest [
23]. The system estimated real-time ego motion and created a 2D probabilistic occupancy grid map to facilitate dynamic path planning and obstacle avoidance [
23]. Diaz Toro et al. built a vision-based wearable system with a stereo camera for floor segmentation, occupancy grid built, obstacle avoidance, object detection, and path planning [
24]. The system operated at 11 FPS, effectively handling both the floor segmentation and the construction of a 2D occupancy grid [
24]. Takefuji et al. developed a system where a stereo camera is attached to clothing or a backpack [
25]. The system employed the YOLO algorithm, enhanced with distance information, to calculate the direction of obstacles at 14 to 17 FPS [
25]. The limitation of the system includes high energy consumption and a short battery life [
25]. Xia et al. integrated a laser ranging chip with an image processing unit to enable the recognition of traffic lights, obstacle avoidance, and payment functionalities [
26]. This system utilises a YOLO-lite algorithm; however, it is still significantly power-consuming with an average current of 226.92 mA per second [
26]. A common challenge in all vision-sensor-based works mentioned above is the significant computational cost associated with carrying out the algorithm or device, which typically requires the user to have a high-performance laptop with them. However, a high-end laptop is potentially unaffordable for the BVI people as 90% of them live in low- and middle-income countries [
27]. It is also impractical to walk around with a laptop all the time. Li et al. addressed the issue of high computational demands by cloud systems, but it necessitates confronting the substantial risks associated with the network as previously mentioned [
19]. Additionally, the performance of cameras is significantly impacted under conditions of low illumination, such as during nighttime [
26] or in low-light environments. This is due to their inherent sensitivity to lighting conditions, which are crucial for capturing clear images. We focus on investigating a feasible approach to create a lightweight and real-time solution. We aim to explore alternatives to traditional camera-based systems and computationally intensive computer vision algorithms and viable strategies that could potentially enable us to achieve real-time detection without a heavy computational burden.



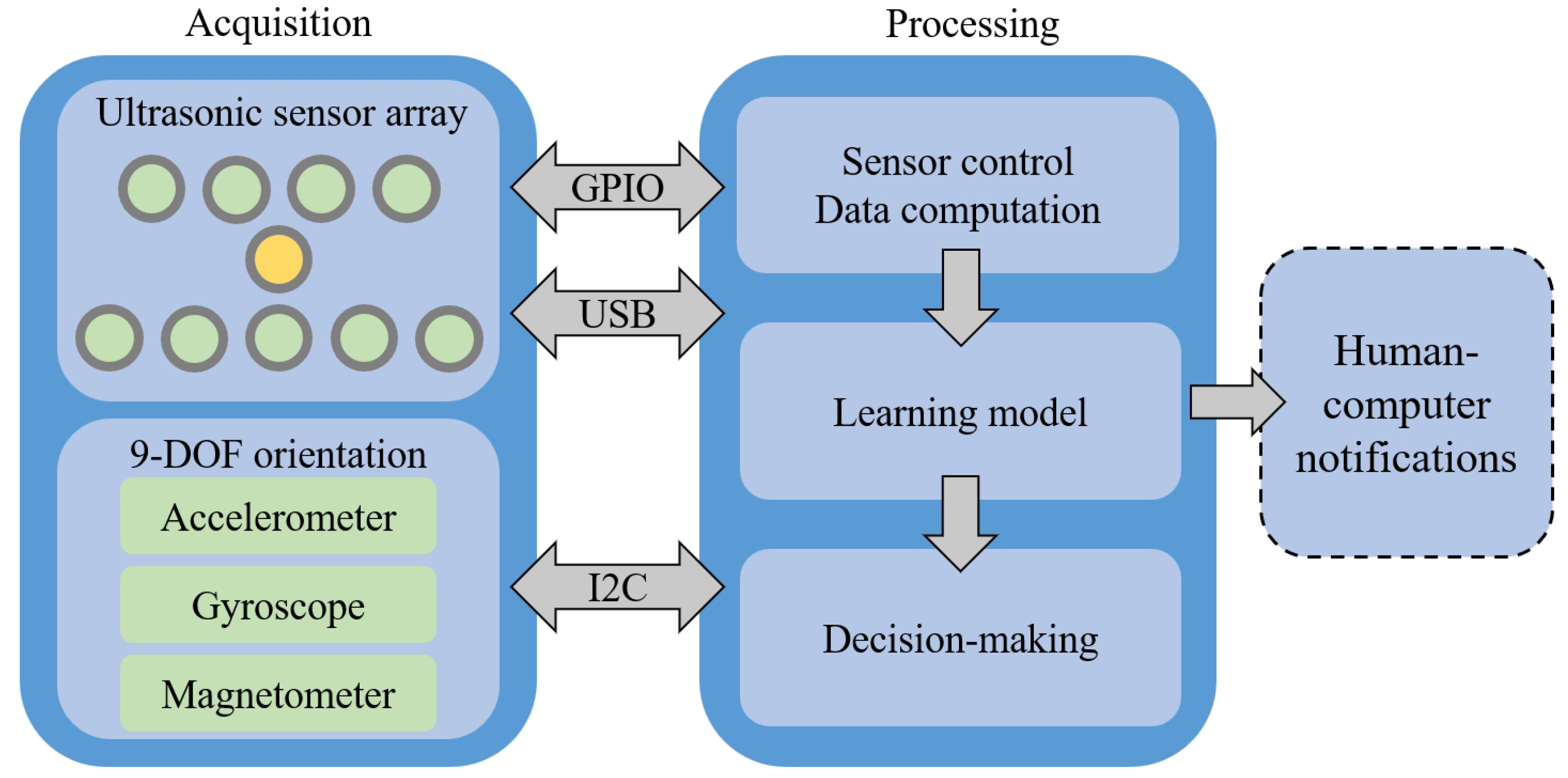





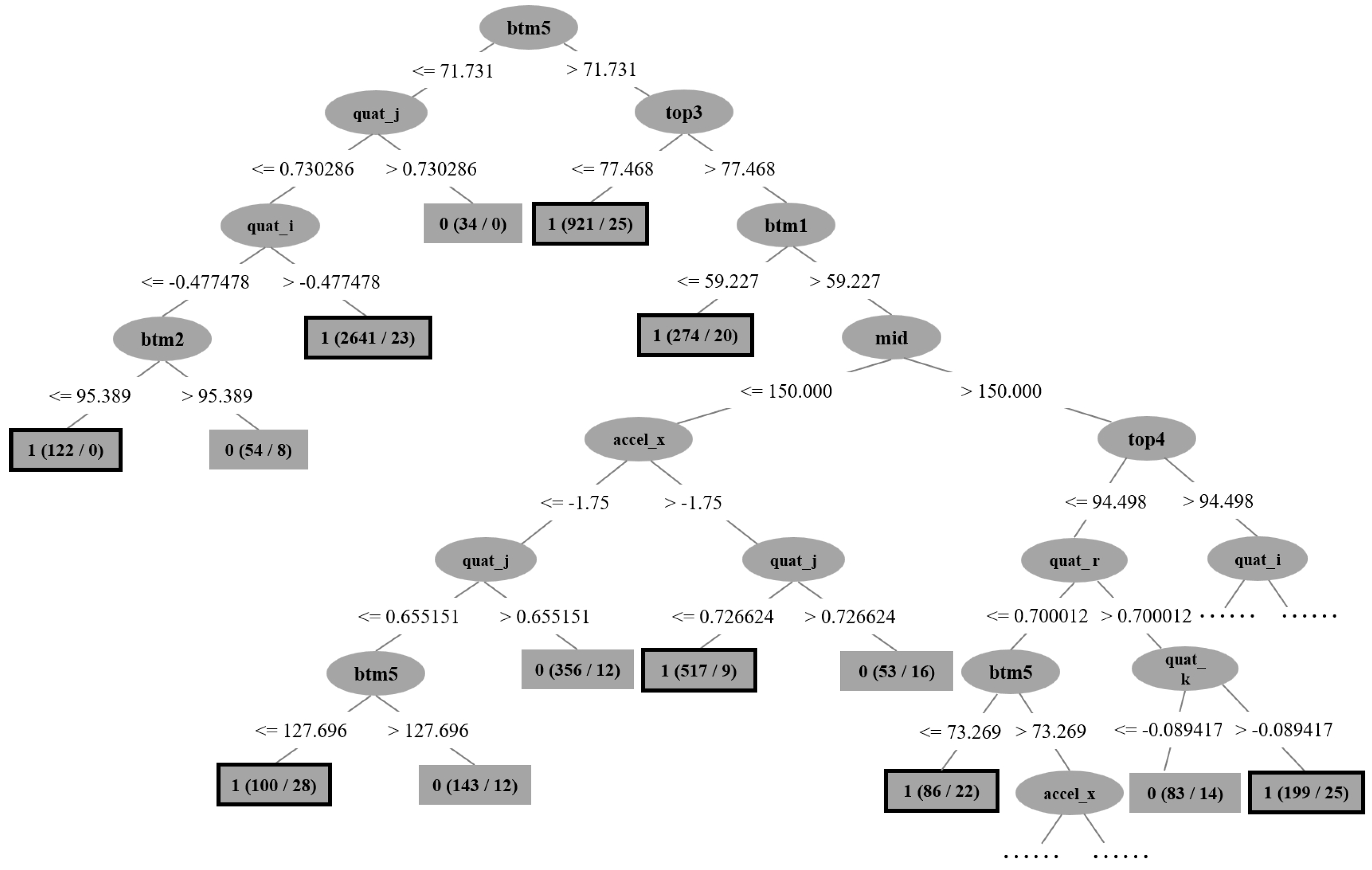

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}