
A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model
 ,
,  ,
,  , , and
, , and 
Abstract
1. Introduction
- The design and development of an innovative computational framework comprised of vehicle, edge, and cloud layers inspired by CCAM infrastructure.
- Acquisition of a novel custom-formatted multi-object dataset for perception tasks.
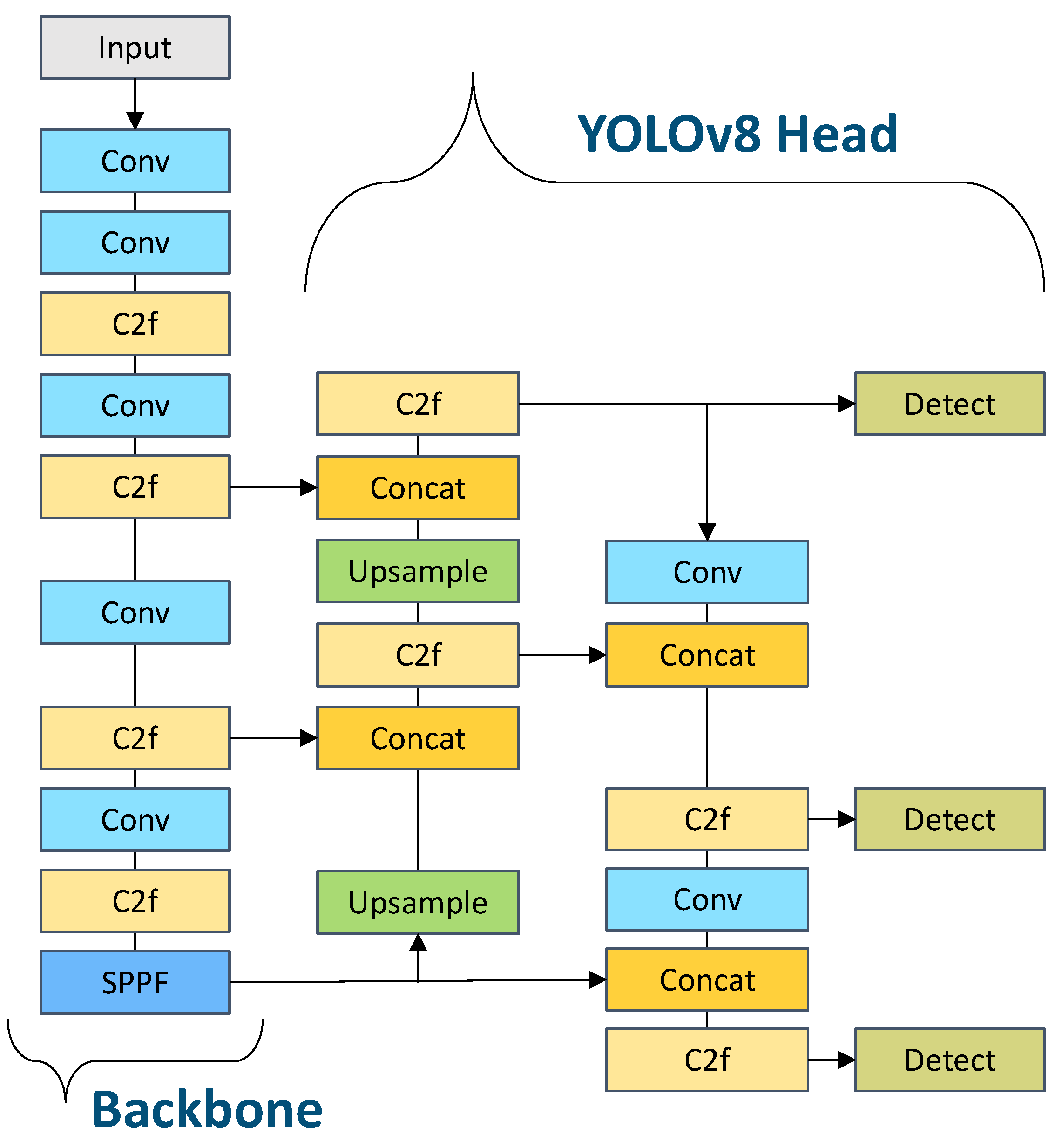
- Deployment of the fine-tuned DL YOLOv8 model over various devices, i.e., Raspberry Pi 4, Jetson AGX ARMv8, Jetson AGX Xavier, Apple M2 Max, Apple MPS, Intel Xeon CPU, Tesla T4, NVIDIA A100, and Tesla V100.
- Performance evaluation through metric-based analysis and comparative assessment of average times for various stages of perception task.
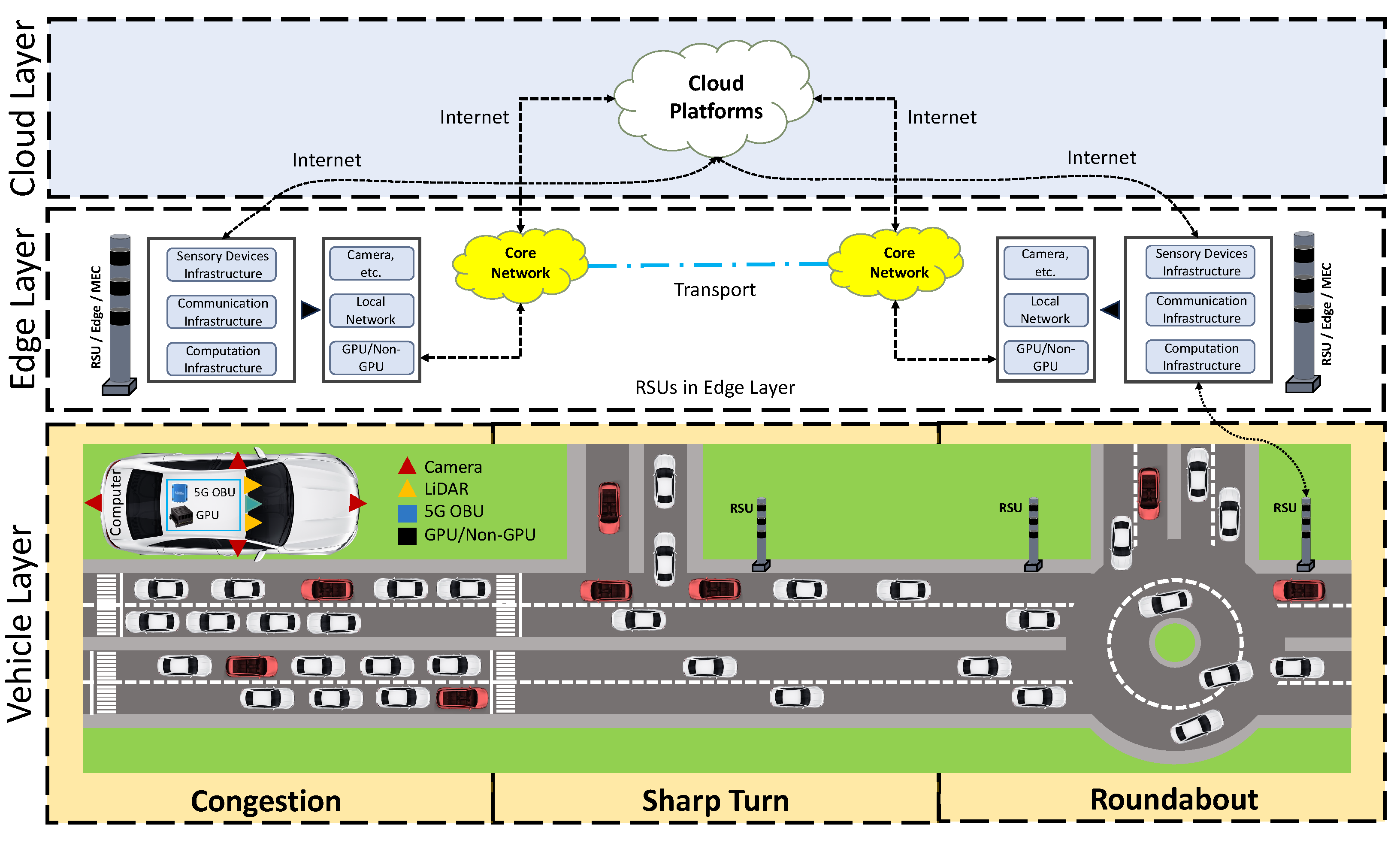
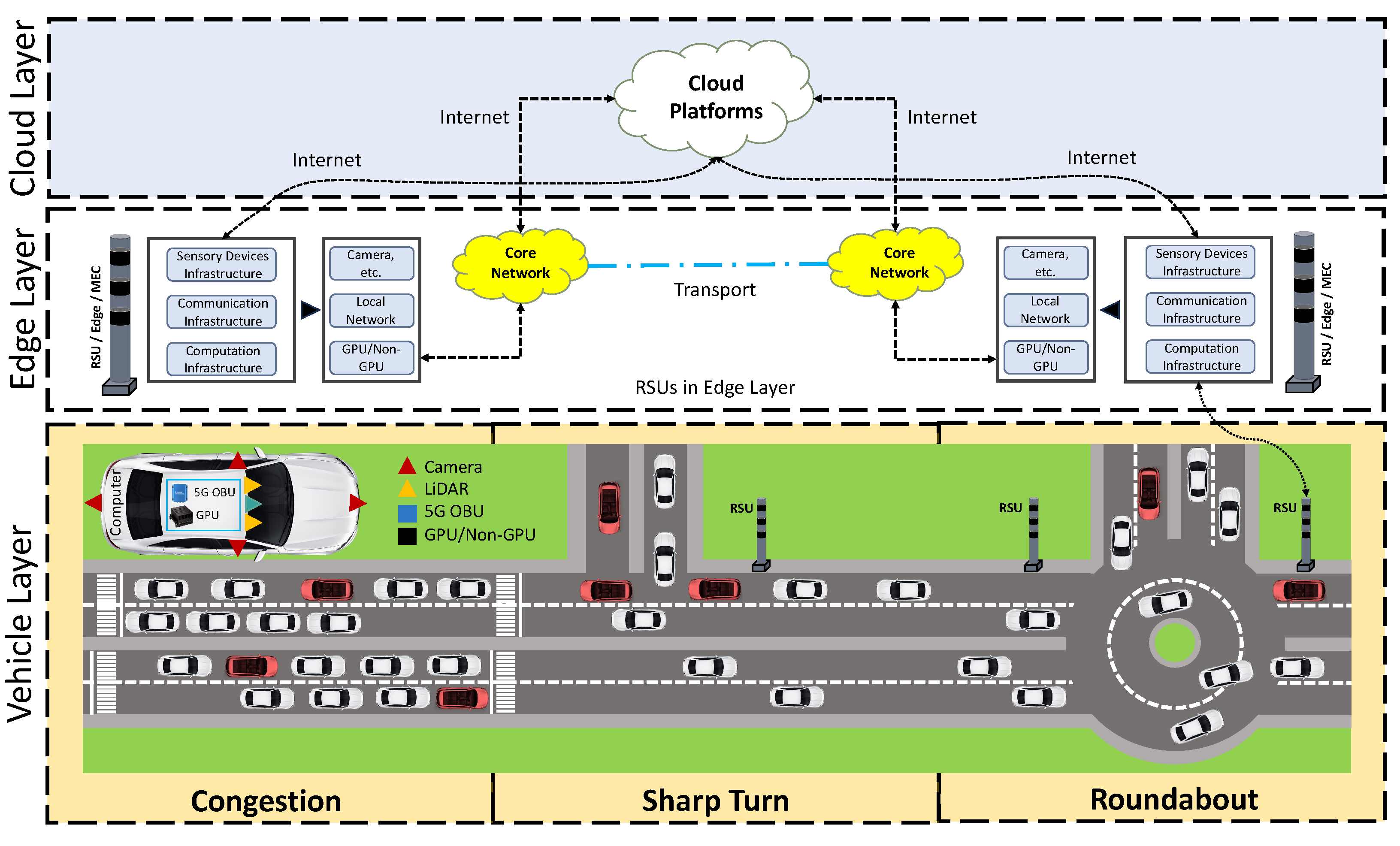
2. An Overview of the Proposed Framework
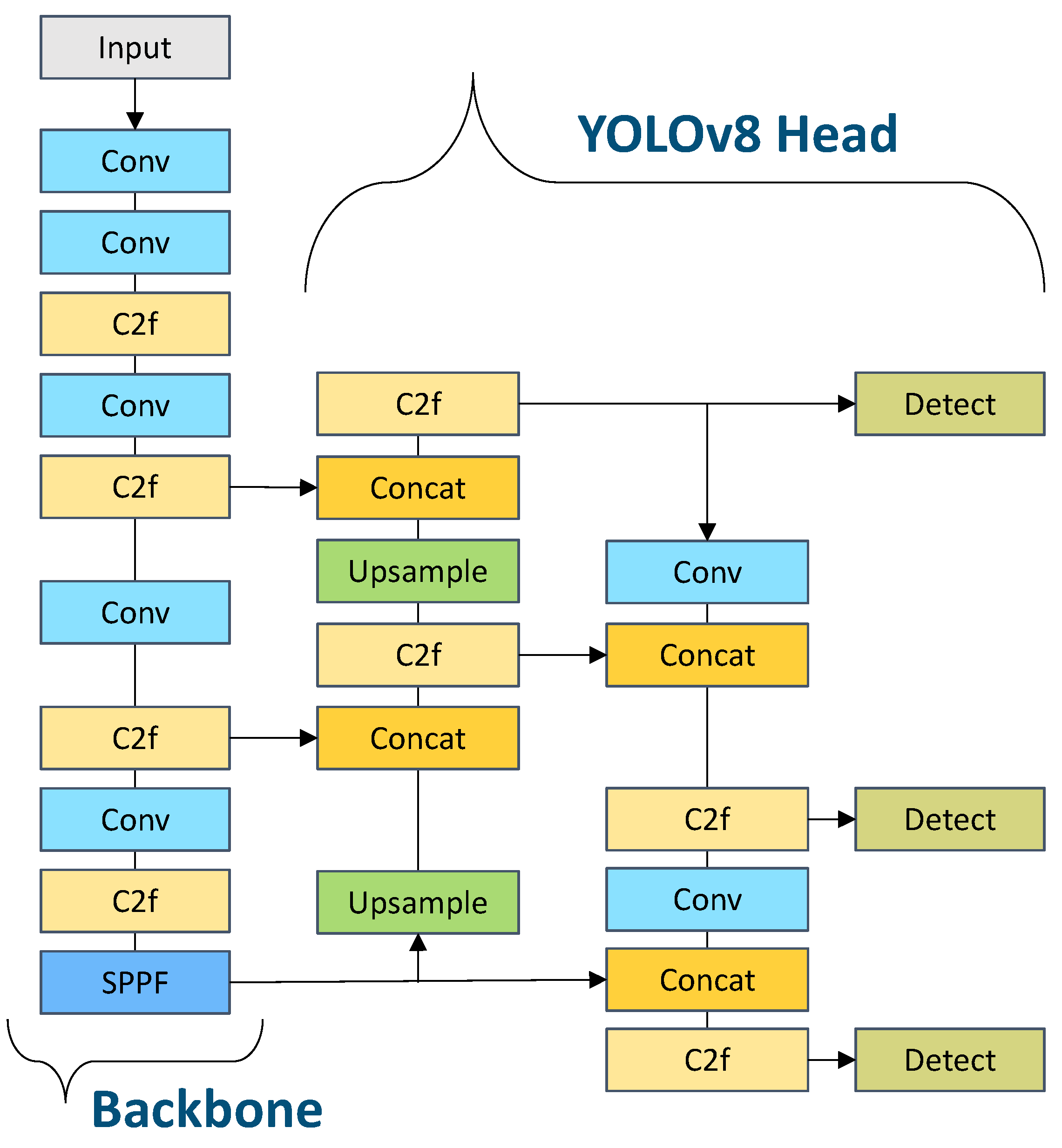
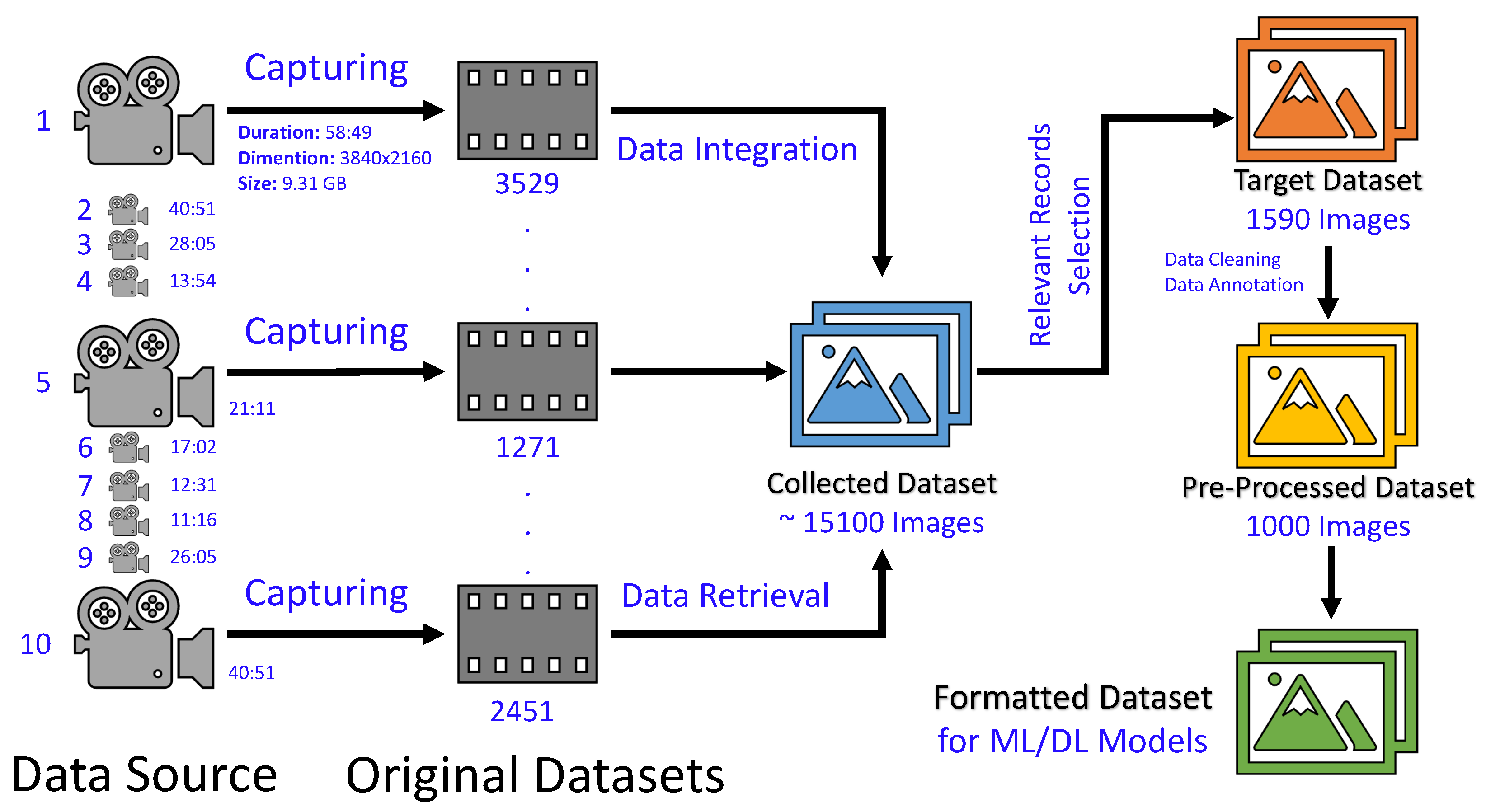
2.1. Data Acquisition and Model Fine-Tuning
2.2. The Vehicle Layer
2.3. The Edge Layer
2.4. The Cloud Layer
3. Experiments
3.1. Experimental Setup
3.2. Evaluation Metrics
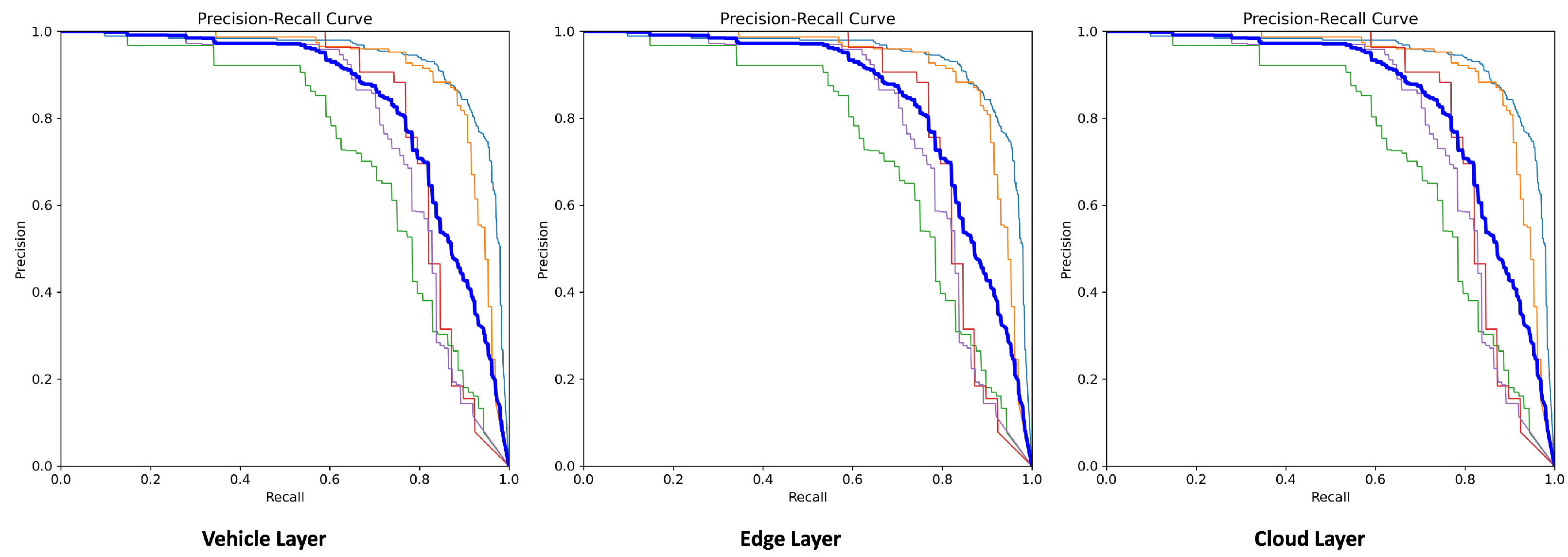
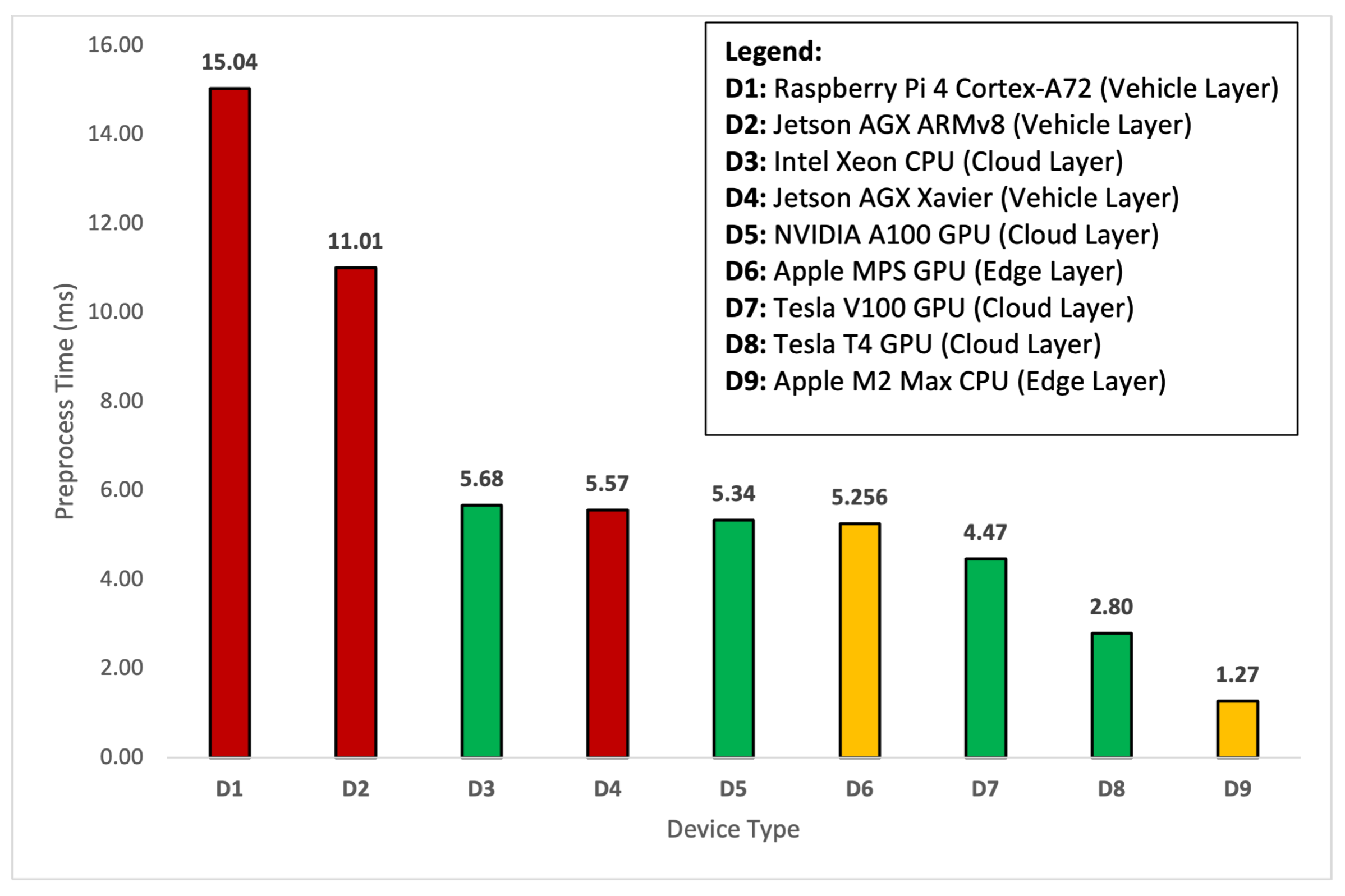
4. Results and Discussions
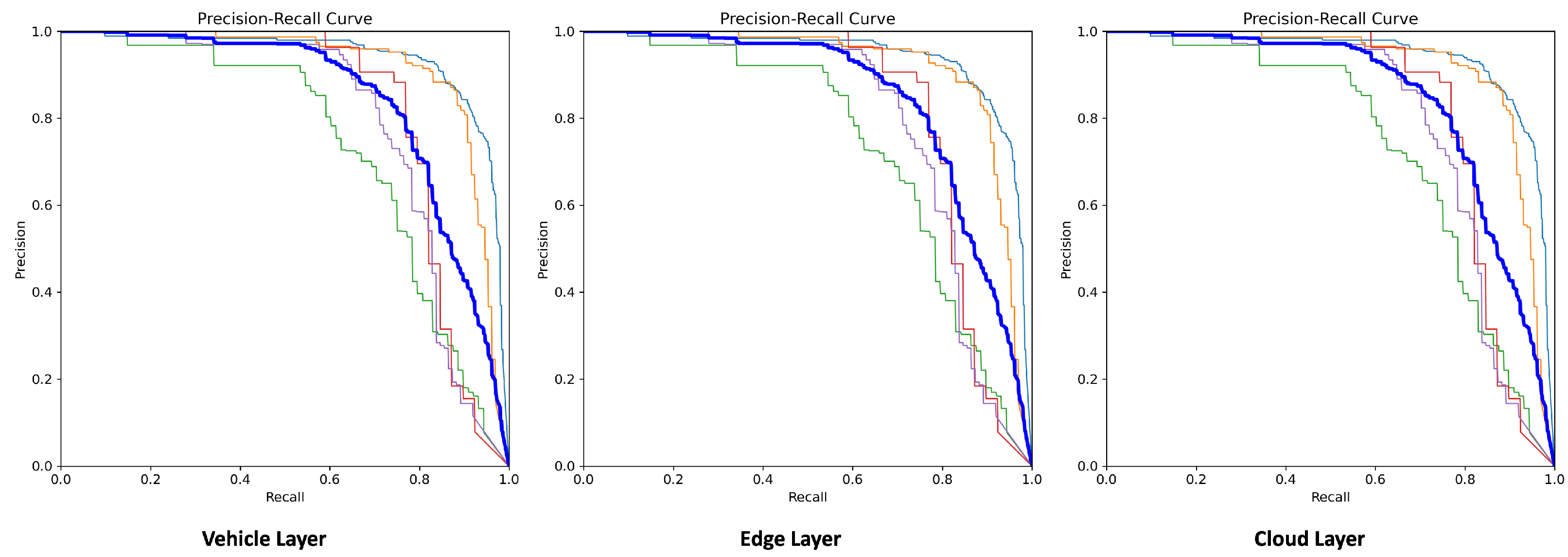
4.1. Model Performance Analysis
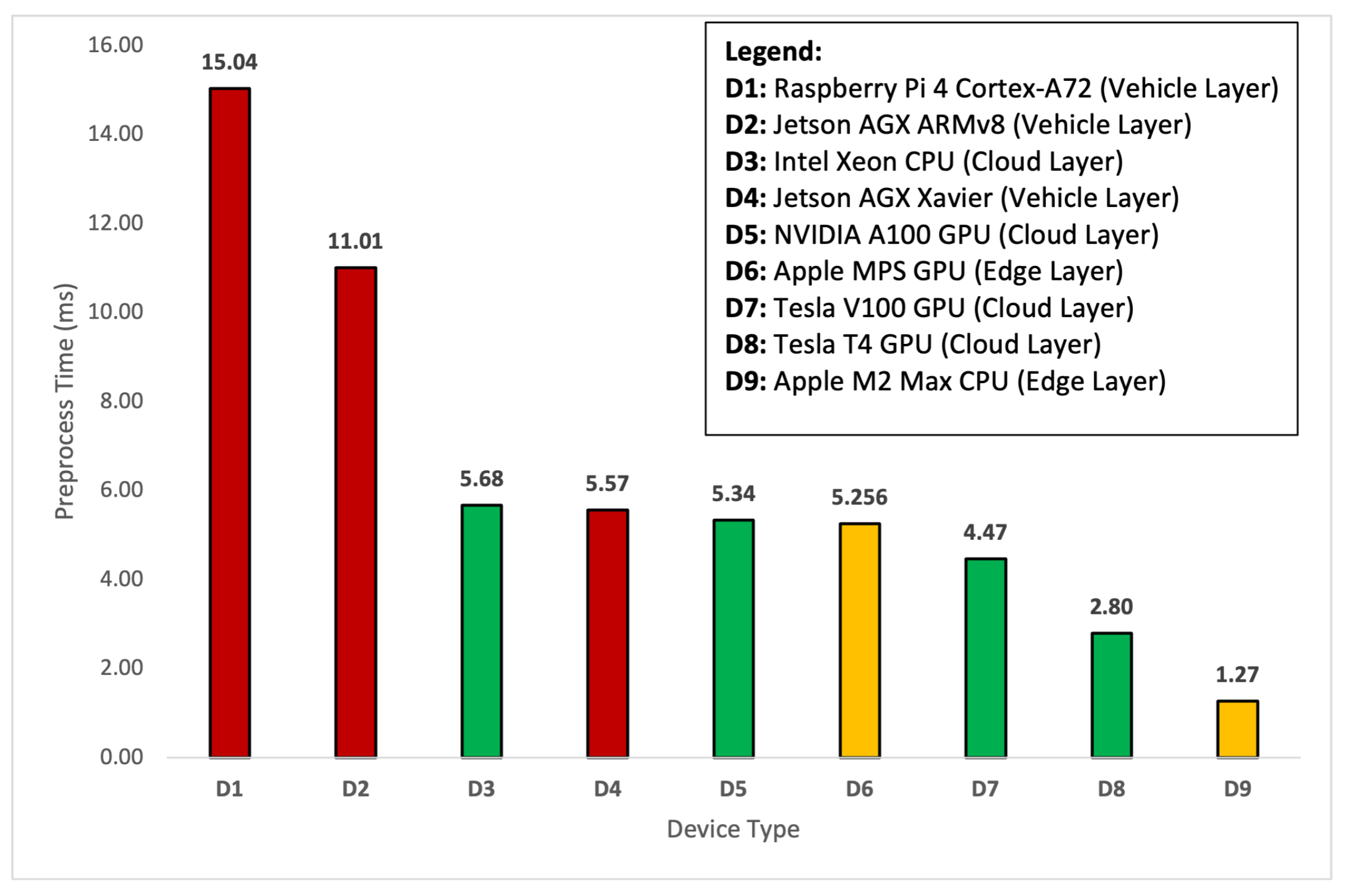
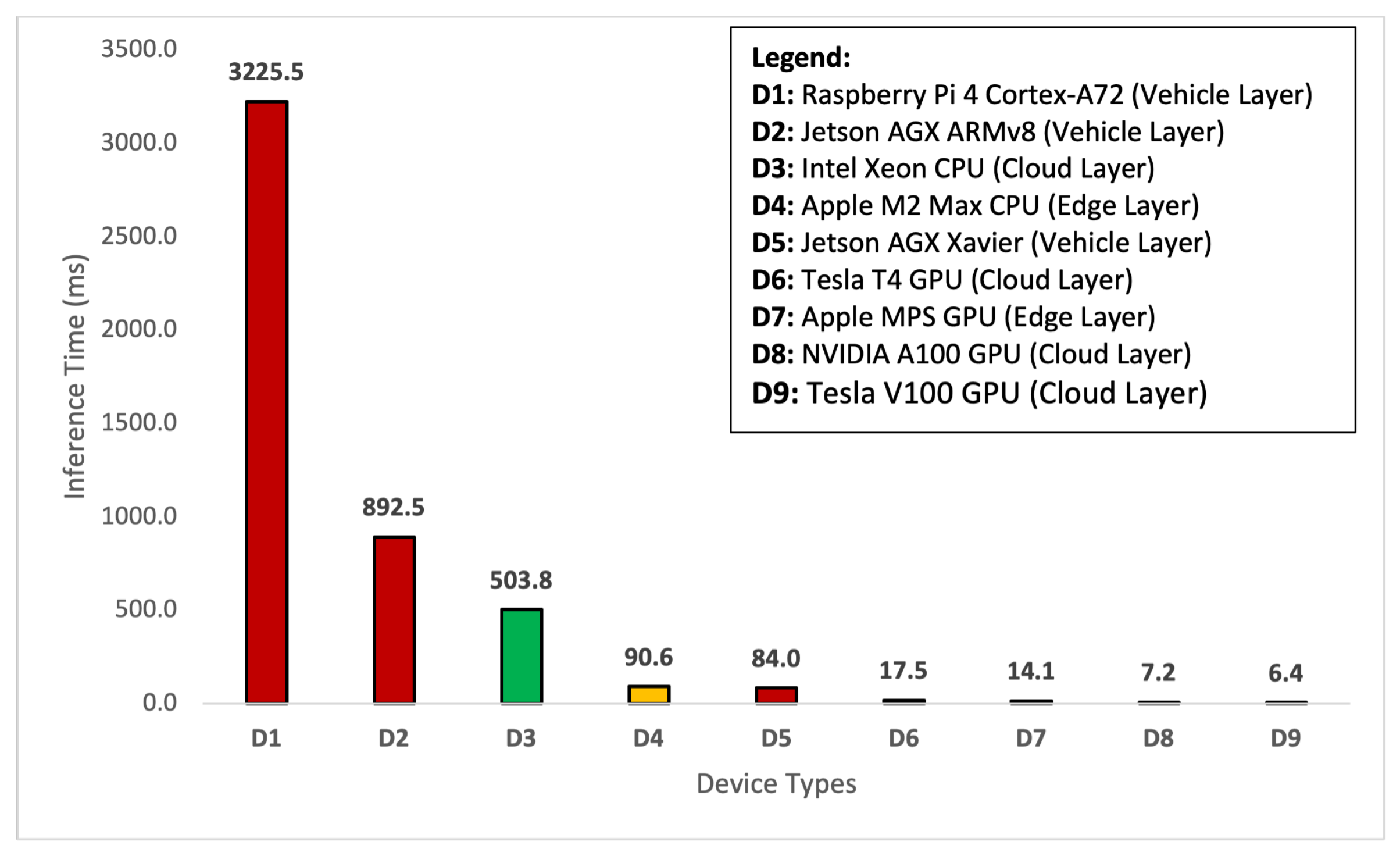
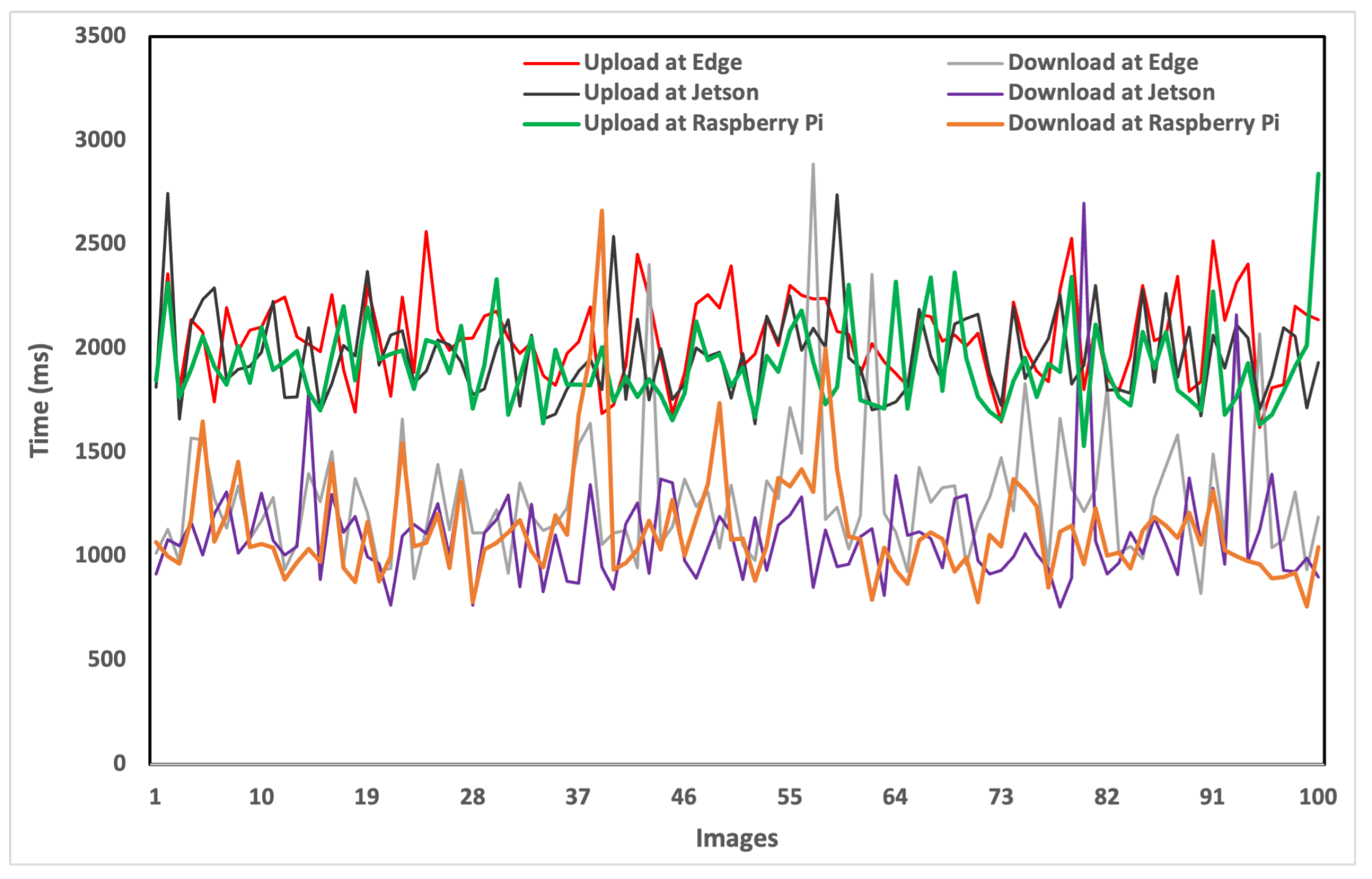
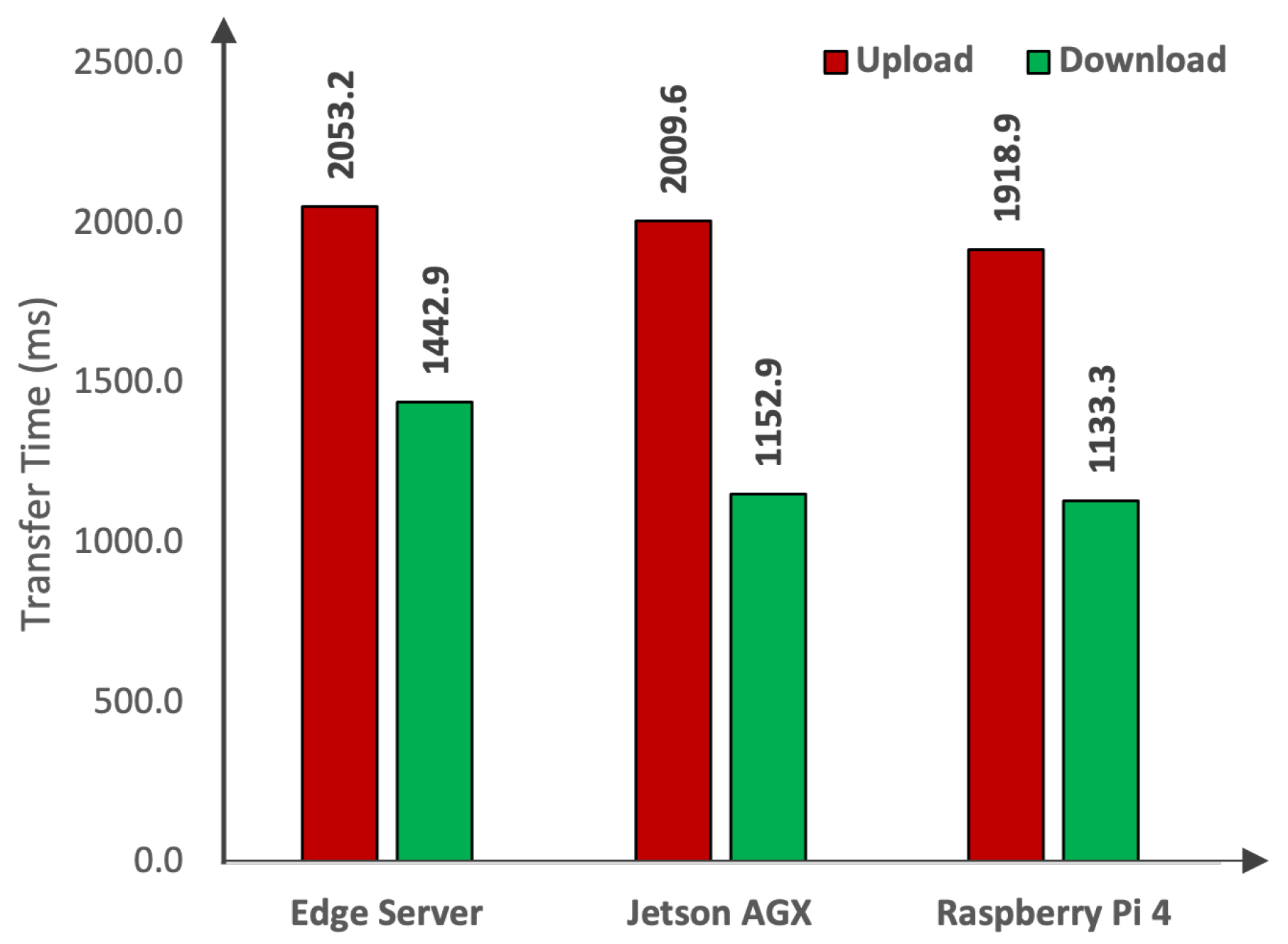
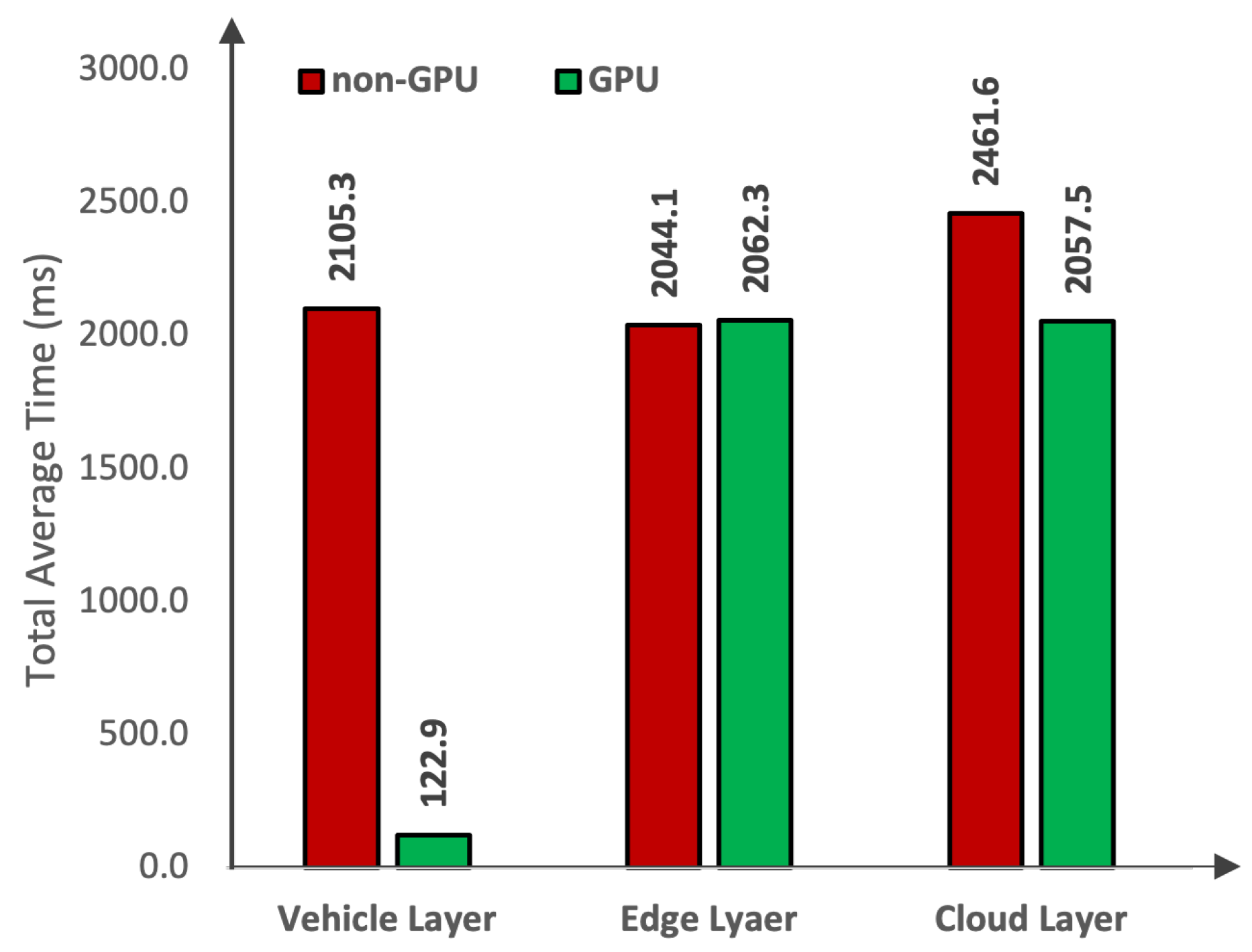
4.2. Time Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, M.A.; Sayed, H.E.; Malik, S.; Zia, T.; Khan, J.; Alkaabi, N.; Ignatious, H. Level-5 autonomous driving—Are we there yet? A review of research literature. Acm Comput. Surv. (CSUR) 2022, 55, 27. [Google Scholar] [CrossRef]
- Khan, M.A. Intelligent environment enabling autonomous driving. IEEE Access 2021, 9, 32997–33017. [Google Scholar] [CrossRef]
- Khan, M.J.; Khan, M.A.; Ullah, O.; Malik, S.; Iqbal, F.; El-Sayed, H.; Turaev, S. Augmenting CCAM Infrastructure for Creating Smart Roads and Enabling Autonomous Driving. Remote Sens. 2023, 15, 922. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D object detection for autonomous driving: A comprehensive survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- The KITTI Vision Benchmark Suite. Available online: https://www.cvlibs.net/datasets/kitti/ (accessed on 30 October 2023).
- nuScenes. Available online: https://www.nuscenes.org/nuscenes (accessed on 30 October 2023).
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Xie, Y.; Xu, C.; Rakotosaona, M.J.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. arXiv 2023, arXiv:2304.14340. [Google Scholar]
- Yan, J.; Liu, Y.; Sun, J.; Jia, F.; Li, S.; Wang, T.; Zhang, X. Cross Modal Transformer via Coordinates Encoding for 3D Object Dectection. arXiv 2023, arXiv:2301.01283. [Google Scholar]
- Song, Z.; Xie, T.; Zhang, H.; Wen, F.; Li, J. A Spatial Calibration Method for Robust Cooperative Perception. arXiv 2023, arXiv:2304.12033. [Google Scholar]
- Jiao, Y.; Jie, Z.; Chen, S.; Chen, J.; Ma, L.; Jiang, Y.G. MSMDfusion: Fusing lidar and camera at multiple scales with multi-depth seeds for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21643–21652. [Google Scholar]
- Liu, S.; Yu, B.; Tang, J.; Zhu, Y.; Liu, X. Communication challenges in infrastructure-vehicle cooperative autonomous driving: A field deployment perspective. IEEE Wirel. Commun. 2022, 29, 126–131. [Google Scholar] [CrossRef]
- Liu, S.; Wang, J.; Wang, Z.; Yu, B.; Hu, W.; Liu, Y.; Tang, J.; Song, S.L.; Liu, C.; Hu, Y. Brief industry paper: The necessity of adaptive data fusion in infrastructure-augmented autonomous driving system. In Proceedings of the 2022 IEEE 28th Real-Time and Embedded Technology and Applications Symposium (RTAS), IEEE, Milano, Italy, 4–6 May 2022; pp. 293–296. [Google Scholar]
- Zeng, X.; Wang, Z.; Hu, Y. Enabling efficient deep convolutional neural network-based sensor fusion for autonomous driving. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 283–288. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, IEEE, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Kim, J.; Kim, J.; Cho, J. An advanced object classification strategy using YOLO through camera and LiDAR sensor fusion. In Proceedings of the 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), IEEE, Gold Coast, QLD, Australia, 16–18 December 2019; pp. 1–5. [Google Scholar]
- Liu, Q.; Ye, H.; Wang, S.; Xu, Z. YOLOv8-CB: Dense Pedestrian Detection Algorithm Based on In-Vehicle Camera. Electronics 2024, 13, 236. [Google Scholar] [CrossRef]
- Ma, M.Y.; Shen, S.E.; Huang, Y.C. Enhancing UAV Visual Landing Recognition with YOLO’s Object Detection by Onboard Edge Computing. Sensors 2023, 23, 8999. [Google Scholar] [CrossRef]
- Pääkkönen, P.; Pakkala, D. Evaluation of Human Pose Recognition and Object Detection Technologies and Architecture for Situation-Aware Robotics Applications in Edge Computing Environment. IEEE Access 2023, 11, 92735–92751. [Google Scholar] [CrossRef]
- Chen, Y.; Ye, J.; Wan, X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electr. Veh. J. 2023, 14, 352. [Google Scholar] [CrossRef]
- Ragab, M.; Abdushkour, H.A.; Khadidos, A.O.; Alshareef, A.M.; Alyoubi, K.H.; Khadidos, A.O. Improved Deep Learning-Based Vehicle Detection for Urban Applications Using Remote Sensing Imagery. Remote Sens. 2023, 15, 4747. [Google Scholar] [CrossRef]
- Ullah, R.; Hayat, H.; Siddiqui, A.A.; Siddiqui, U.A.; Khan, J.; Ullah, F.; Hassan, S.; Hasan, L.; Albattah, W.; Islam, M.; et al. A real-time framework for human face detection and recognition in cctv images. Math. Probl. Eng. 2022, 2022, 3276704. [Google Scholar] [CrossRef]
- Elmanaa, I.; Sabri, M.A.; Abouch, Y.; Aarab, A. Efficient Roundabout Supervision: Real-Time Vehicle Detection and Tracking on Nvidia Jetson Nano. Appl. Sci. 2023, 13, 7416. [Google Scholar] [CrossRef]
- Buy a Raspberry Pi 4 Model B–Raspberry Pi. Available online: https://www.raspberrypi.com/products/raspberry-pi-4-model-b/ (accessed on 12 July 2023).
- Jetson Xavier Series|NVIDIA. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-xavier-series/ (accessed on 12 July 2023).
- MacBook Pro (16-inch, 2023)—Technical Specifications (AE). Available online: https://support.apple.com/kb/SP890?locale=en_AE (accessed on 12 July 2023).
- FFmpeg. Available online: https://ffmpeg.org/ (accessed on 10 August 2023).
- ultralytics/ultralytics: NEW—YOLOv8 in PyTorch > ONNX > OpenVINO > CoreML > TFLite. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 August 2023).
- Lin, B.Y.; Huang, C.S.; Lin, J.M.; Liu, P.H.; Lai, K.T. Traffic Object Detection in Virtual Environments. In Proceedings of the 2023 International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), IEEE, Pingtung, Taiwan, 17–19 July 2023; pp. 245–246. [Google Scholar]
- Afdhal, A.; Saddami, K.; Sugiarto, S.; Fuadi, Z.; Nasaruddin, N. Real-Time Object Detection Performance of YOLOv8 Models for Self-Driving Cars in a Mixed Traffic Environment. In Proceedings of the 2023 2nd International Conference on Computer System, Information Technology, and Electrical Engineering (COSITE), IEEE, Banda Aceh, Indonesia, 2–3 August 2023; pp. 260–265. [Google Scholar]
- ultralytics · PyPI. Available online: https://pypi.org/project/ultralytics/ (accessed on 10 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Platforms | Devices | Device Type | Memory |
|---|---|---|---|---|
| Cloud Layer | Google Cloud | Tesla V100 | GPU | 16 GB |
| Google Cloud | NVIDIA A100 | GPU | 40 GB | |
| Google Cloud | Tesla T4 | GPU | 15 GB | |
| Google Cloud | Intel Xeon | non-GPU | 16 GB | |
| Edge Layer | Apple | MPS | GPU | 32 GB |
| Apple | M2 Max | non-GPU | 32 GB | |
| Vehicle Layer | Jetson AGX | Xavier | GPU | 16 GB |
| Jetson AGX | ARMv8 | non-GPU | 16 GB | |
| Raspberry Pi 4 | Cortex-A72 | non-GPU | 08 GB |
| Layers | Devices | Objects | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|
| Cloud Layer Edge Layer Vehicle Layer | GPUs and non-GPUs | car | 0.842 | 0.901 | 0.938 | 0.724 |
| motorcyclist | 0.868 | 0.877 | 0.916 | 0.655 | ||
| pedestrian | 0.700 | 0.693 | 0.739 | 0.430 | ||
| rickshaw | 0.881 | 0.759 | 0.826 | 0.614 | ||
| truck | 0.783 | 0.716 | 0.794 | 0.583 |
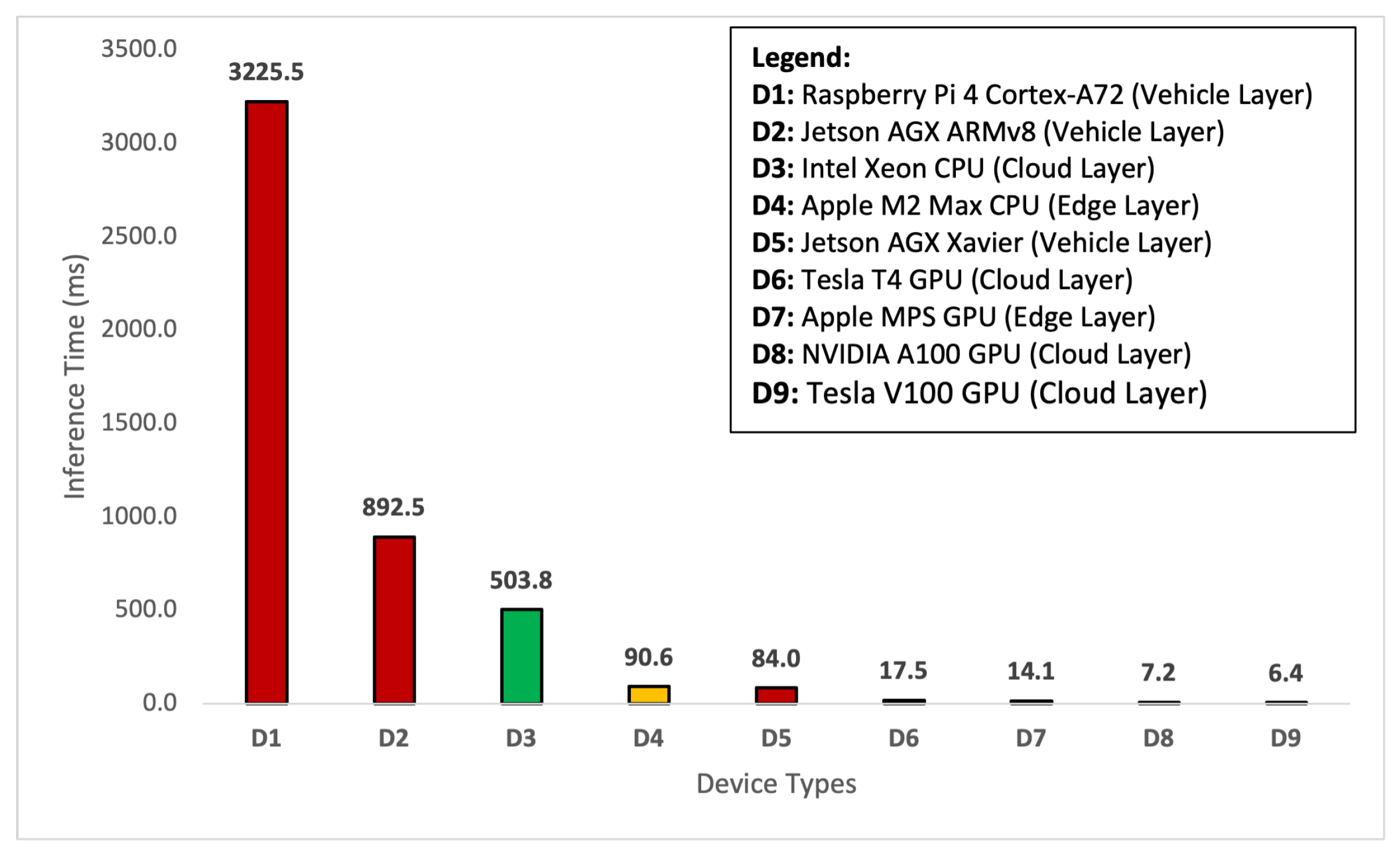
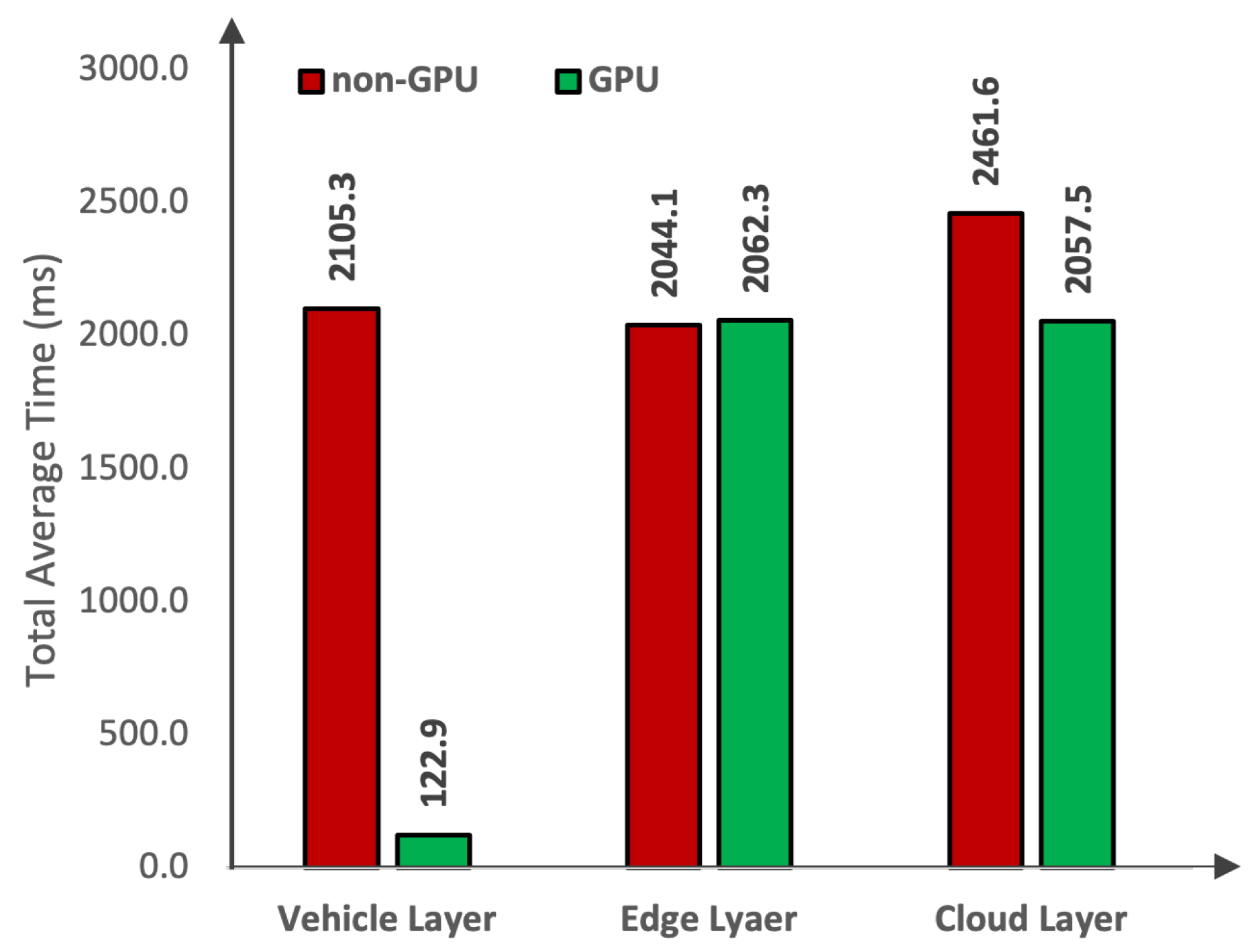
| Layers | Platforms | Devices | Capture | Transfer | Preprocess | Inference | Total |
|---|---|---|---|---|---|---|---|
| Cloud Layer | Tesla V100 | 33.34 | 2009.56 | 4.47 | 6.401 | 2053.77 | |
| NVIDIA A100 | 33.34 | 2009.56 | 5.34 | 7.223 | 2055.46 | ||
| Tesla T4 | 33.34 | 2009.56 | 2.80 | 17.456 | 2063.16 | ||
| Intel Xeon | 33.34 | 1918.86 | 5.68 | 503.75 | 2461.63 | ||
| Edge Layer | Apple | MPS | 33.34 | 2009.56 | 5.256 | 14.108 | 2062.26 |
| Apple | M2 Max | 33.34 | 1918.86 | 1.27 | 90.60 | 2044.08 | |
| Vehicle Layer | Jetson AGX | Xavier | 33.34 | 0 | 5.57 | 84.03 | 122.94 |
| Jetson AGX | ARMv8 | 33.34 | 0 | 11.01 | 892.51 | 936.86 | |
| Raspberry Pi | Cortex-A72 | 33.34 | 0 | 15.04 | 3225.46 | 3273.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.J.; Khan, M.A.; Turaev, S.; Malik, S.; El-Sayed, H.; Ullah, F. A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model. Sensors 2024, 24, 2080. https://doi.org/10.3390/s24072080
Khan MJ, Khan MA, Turaev S, Malik S, El-Sayed H, Ullah F. A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model. Sensors. 2024; 24(7):2080. https://doi.org/10.3390/s24072080
Chicago/Turabian StyleKhan, M. Jalal, Manzoor Ahmed Khan, Sherzod Turaev, Sumbal Malik, Hesham El-Sayed, and Farman Ullah. 2024. "A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model" Sensors 24, no. 7: 2080. https://doi.org/10.3390/s24072080
APA StyleKhan, M. J., Khan, M. A., Turaev, S., Malik, S., El-Sayed, H., & Ullah, F. (2024). A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model. Sensors, 24(7), 2080. https://doi.org/10.3390/s24072080