
Cross-and-Diagonal Networks: An Indirect Self-Attention Mechanism for Image Classification

Abstract
1. Introduction
- It can aggregate contextual information over long distances so that the entire network has rich local feature information while taking global features into account, improving network performance.
- In contrast to the non-local block, CDNet significantly simplifies the computational complexity of the network, resulting in a more streamlined architecture. This simplification enhances the GPU friendliness of the network, thereby improving the overall utilization efficiency.
- The cross and diagonal block as a plug-and-play module can be seamlessly integrated into the framework of fully convolutional neural networks. This integration is straightforward, requiring minimal modification to the existing network architecture.
2. Related Works
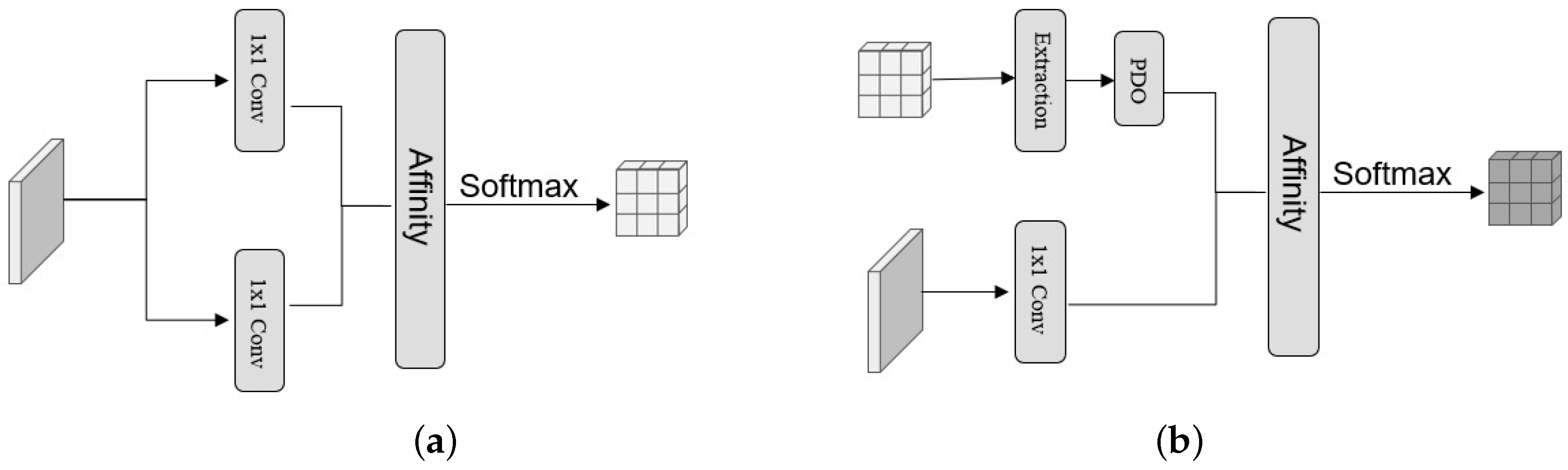
3. Methods
3.1. Overall Approach
3.2. Cross Attention
3.3. Diagonal Attention
4. Experiment
4.1. Details of the Experiments
- CIFAR-10: CIFAR-10 is a dataset of color images that represents a broader range of universal objects. It is a limited dataset designed for identifying general objects, arranged by Alex Krizhevsky and Ilya Sutskever. It includes 10 categories of RGB color images. The dataset contains 50,000 training images and 10,000 test images, with each category consisting of 6000 images measuring 32 × 32 pixels.
- CIFAR-100: The CIFAR100 dataset comprises 100 classes, each containing 600 color images of dimensions 32 × 32. Among these images, 500 serve as training data while the remaining 100 serve as test data, resulting in 60,000 images. Each image is assigned two labels: fine labels and coarse labels. These labels indicate the detailed and general classification of the image, respectively.
- Fashion-MNIST: Fashion-MNIST is a dataset comprising 28 × 28 grayscale images of 70,000 fashion products from 10 categories, with 7000 images per category. The training set has 60,000 images, and the test set has 10,000 images. Fashion-MNIST shares the same image size, data format, and structure of training and testing splits with the original MNIST.
- ImageNet: We employed the ImageNet1K dataset, comprising 1.28 million images for training and 50 K for validation across 1000 classes.
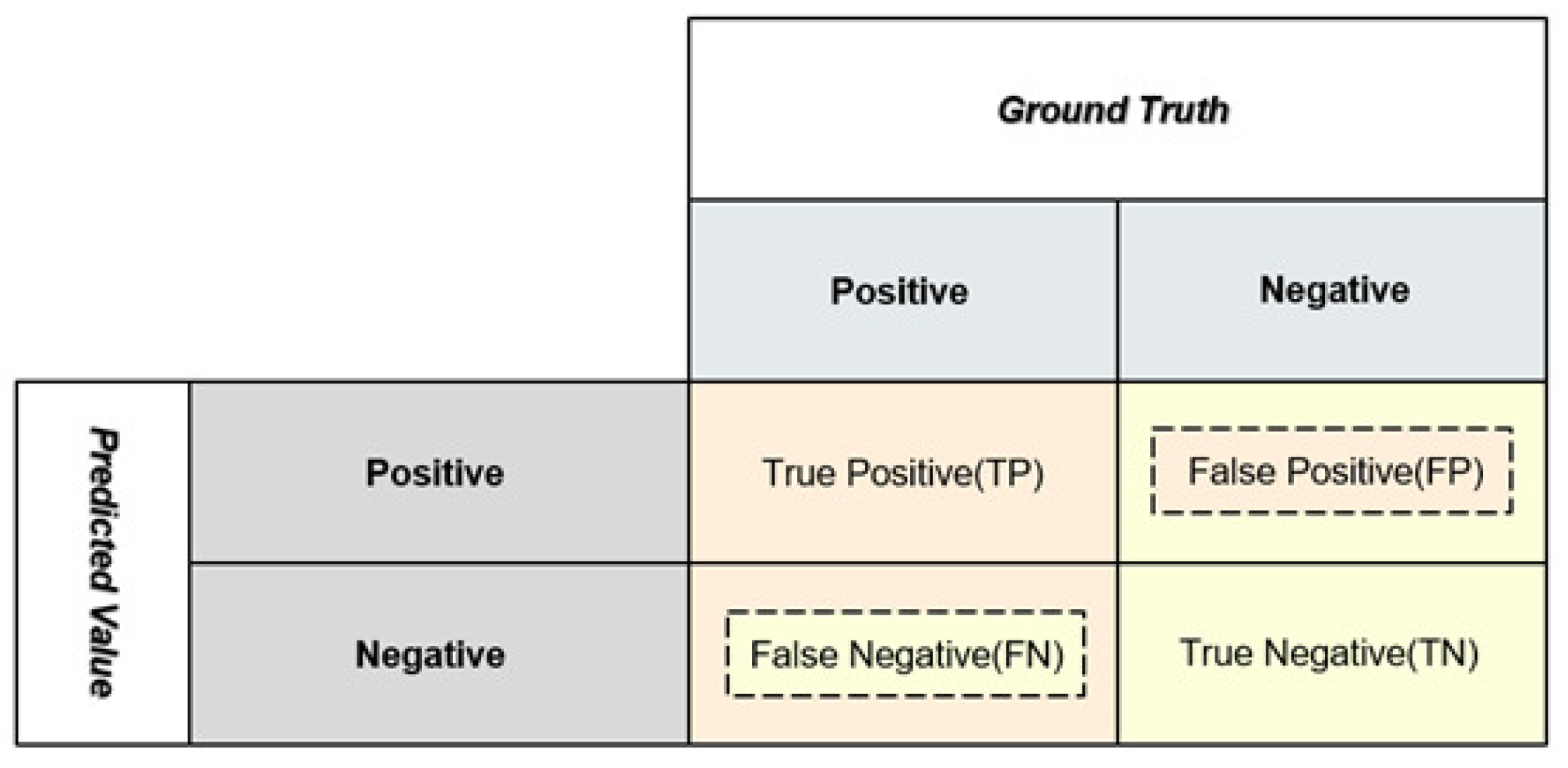
4.2. Evaluating Indicator
4.3. Cifar Classification
4.4. Ablation Experiments
4.5. Fashion-MNIST Classification
4.6. ImageNet 1k Classification
4.7. Efficiency Experiments
5. Conclusions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nocentini, O.; Kim, J.; Bashir, M.Z.; Cavallo, F. Image Classification Using Multiple Convolutional Neural Networks on the Fashion-MNIST Dataset. Sensors 2022, 22, 9544. [Google Scholar] [CrossRef]
- Shi, C.; Dang, Y.; Fang, L.; Lv, Z.; Shen, H. Attention-Guided Multispectral and Panchromatic Image Classification. Remote Sens. 2021, 13, 4823. [Google Scholar] [CrossRef]
- Badža, M.M.; Barjaktarović, M.Č. Classification of Brain Tumors from MRI Images Using a Convolutional Neural Network. Appl. Sci. 2020, 10, 1999. [Google Scholar] [CrossRef]
- Xie, J.; Hua, J.; Chen, S.; Wu, P.; Gao, P.; Sun, D.; Lyu, Z.; Lyu, S.; Xue, X.; Lu, J. HyperSFormer: A Transformer-Based End-to-End Hyperspectral Image Classification Method for Crop Classification. Remote Sens. 2023, 15, 3491. [Google Scholar] [CrossRef]
- Li, C.; Li, Z.; Liu, X.; Li, S. The Influence of Image Degradation on Hyperspectral Image Classification. Remote Sens. 2022, 14, 5199. [Google Scholar] [CrossRef]
- Zhou, L.; Zhu, J.; Yang, J.; Geng, J. Data Augmentation and Spatial-Spectral Residual Framework for Hyperspectral Image Classification Using Limited Samples. In Proceedings of the 2022 IEEE International Conference on Unmanned Systems (ICUS), Guangzhou, China, 28–30 October 2022; pp. 1–6. [Google Scholar]
- Yu, C.; Liu, C.; Song, M.; Chang, C.-I. Unsupervised Domain Adaptation With Content-Wise Alignment for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5511705. [Google Scholar] [CrossRef]
- Tang, H.; Li, Y.; Zhang, L.; Xie, W. Hyperspectral Image Few-shot Classification Based on Analogous Tensor Decomposition. In Proceedings of the 2022 7th International Conference on Signal and Image Processing (ICSIP), Suzhou, China, 20–22 July 2022; pp. 498–503. [Google Scholar]
- Ge, H.; Zhu, Z.; Lou, K.; Wei, W.; Liu, R.; Damaševičius, R.; Woźniak, M. Classification of Infrared Objects in Manifold Space Using Kullback-Leibler Divergence of Gaussian Distributions of Image Points. Symmetry 2020, 12, 434. [Google Scholar] [CrossRef]
- Ulhaq, A. Adversarial Domain Adaptation for Action Recognition Around the Clock. In Proceedings of the 2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, Australia, 30 November–2 December 2022; pp. 1–6. [Google Scholar]
- Benaouali, M.; Bentoumi, M.; Touati, M.; Ahmed, A.T.; Mimi, M. Segmentation and classification of benign and malignant breast tumors via texture characterization from ultrasound images. In Proceedings of the 2022 7th International Conference on Image and Signal Processing and their Applications (ISPA), Mostaganem, Algeria, 8–9 May 2022; pp. 1–4. [Google Scholar]
- Qiao, M.; Liu, C.; Li, Z.; Zhou, J.; Xiao, Q.; Zhou, S.; Chang, C.; Gu, Y. Breast Tumor Classification Based on MRI-US Images by Disentangling Modality Features. IEEE J. Biomed. Health Inform. 2022, 26, 3059–3067. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Shigang, C.; Yongli, Z.; Lin, H.; Xinqi, L.; Jingyu, Z. Research on Image Classification Algorithm of Haematococcus Pluvialis Cells. In Proceedings of the 2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Beijing, China, 14–16 May 2022; pp. 1637–1641. [Google Scholar]
- Nanni, L.; Minchio, G.; Brahnam, S.; Maguolo, G.; Lumini, A. Experiments of Image Classification Using Dissimilarity Spaces Built with Siamese Networks. Sensors 2021, 21, 1573. [Google Scholar] [CrossRef] [PubMed]
- Choe, S.; Ramanna, S. Cubical Homology-Based Machine Learning: An Application in Image Classification. Axioms 2022, 11, 112. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A. Non-local neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 12–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, C.; Zhu, X.; Li, Y.; Gong, Y. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2304.06312. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Meng, X.; Yang, Y.; Wang, L.; Wang, T.; Li, R.; Zhang, C. Class-Guided Swin Transformer for Semantic Segmentation of Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517505. [Google Scholar] [CrossRef]
- Chen, X.; Gao, C.; Li, C.; Yang, Y.; Meng, D. Infrared Action Detection in the Dark via Cross-Stream Attention Mechanism. IEEE Trans. Multimed. 2022, 24, 288–300. [Google Scholar] [CrossRef]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 4005615. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, B.; Xu, Y.; Luo, Y.; Yu, H. SQ-Swin: Siamese Quadratic Swin Transformer for Lettuce Browning Prediction. IEEE Access 2023, 11, 128724–128735. [Google Scholar] [CrossRef]
- Chen, J.; Yu, S.; Liang, J. A Cross-layer Self-attention Learning Network for Fine-grained Classification. In Proceedings of the 2023 3rd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 6–8 January 2023; pp. 541–545. [Google Scholar]
- Pang, Y.; Liu, B. SelfAT-Fold: Protein Fold Recognition Based on Residue-Based and Motif-Based Self-Attention Networks. Ieee/Acm Trans. Comput. Biol. Bioinform. 2022, 19, 1861–1869. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Yu, X. Contextual and Lightweight Network for Underwater Object Detection with Self-Attention Mechanism. In Proceedings of the 2023 IEEE International Conference on Mechatronics and Automation (ICMA), Harbin, China, 14–16 May 2023; pp. 1644–1649. [Google Scholar]
- Lyu, S.; Zhou, X.; Wu, X.; Chen, Q.; Chen, H. Self-Attention Over Tree for Relation Extraction with Data-Efficiency and Computational Efficiency. IEEE Trans. Emerg. Top. Comput. Intell. 2023. [Google Scholar] [CrossRef]
- Li, L.; Han, L.; Cao, H.; Hu, H. Joint Self-Attention for Remote Sensing Image Matching. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4511105. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, M.; Long, C.; Yao, L.; Zhu, M. Self-Attention Based Neural Network for Predicting RNA-Protein Binding Sites. IEEE/ACM Trans. Comput. Biol. Bioinform. 2023, 20, 1469–1479. [Google Scholar] [CrossRef]
- Liu, Q.; Peng, J.; Ning, Y.; Chen, N.; Sun, W.; Du, Q.; Zhou, Y. Refined Prototypical Contrastive Learning for Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Zhao, X.; Xu, Y.; Li, W.; Li, Z. Hyperspectral Image Classification with Multi-Attention Transformer and Adaptive Superpixel Segmentation-Based Active Learning. IEEE Trans. Image Process. 2023, 32, 3606–3621. [Google Scholar] [CrossRef]
- Xi, B.; Li, J.; Li, Y.; Song, R.; Xiao, Y.; Du, Q.; Chanussot, J. Semisupervised Cross-Scale Graph Prototypical Network for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9337–9351. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Luu, M.; Huang, Z.; Xing, E.P.; Lee, Y.J.; Wang, H. Expeditious Saliency-guided Mix-up through Random Gradient Thresholding. arXiv 2022, arXiv:2212.04875. [Google Scholar]
- Touvron, H.; Bojanowski, P.; Caron, M.; Cord, M.; El-Nouby, A.; Grave, E.; Izacard, G.; Joulin, A.; Synnaeve, G.; Verbeek, J.; et al. ResMLP: Feedforward networks for image classification with data-efficient training. arXiv 2022, arXiv:2105.03404. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Pinasthika, K.; Laksono, B.S.P.; Irsal, R.B.P.; Shabiyya, S.H.; Yudistira, N. SparseSwin: Swin Transformer with Sparse Transformer Block. arXiv 2023, arXiv:2309.05224. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Von Oswald, J.; Kobayashi, S.; Meulemans, A.; Henning, C.; Grewe, B.F.; Sacramento, J. Neural networks with late-phase weights. arXiv 2020, arXiv:2007.12927. [Google Scholar]
- Zhang, Z.; Zhang, H.; Zhao, L.; Chen, T.; Arik, S.Ö.; Pfister, T. Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding. arXiv 2021, arXiv:2107.02346. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Perez-Nieves, N.; Goodman, D.F.M. Sparse Spiking Gradient Descent. arXiv 2023, arXiv:2105.08810. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. arXiv 2023, arXiv:1704.06904. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | CIFAR-10 | CIFAR-100 | Parameters |
|---|---|---|---|
| ResNext18 | 4.45 | 23.67 | 11.7M |
| R-Mix (PreActResNet-18) [38] | 3.73 | / | / |
| Resnext29, 16 × 32 d | 3.87 | 18.56 | 25.2M |
| Resnext29, 8 × 64 d | 3.65 | 17.77 | 34.4M |
| Resnext29, 16 × 64 d | 3.58 | 17.31 | 68.1M |
| SENet29 [40] | 3.68 | 17.78 | 35.0M |
| SKNet29 [17] | 3.47 | 17.33 | 27.7M |
| R-Mix (WideResNet 28-10) [38] | / | 15.00 | / |
| SparseSwin [41] | 3.57 | 14.65 | 17.6M |
| Ghost-ResNet-56 [42] | 7.30 | / | 0.4M |
| Ghost-VGG-16 [42] | 6.30 | / | 7.7M |
| WRN28-10 [43] | 4.17 | 19.25 | / |
| Transformer local-attention (NesT-B) [44] | 2.80 | 17.44 | 68.0M |
| CDNet18 | 3.82 | 22.31 | 13.3M |
| CDNet29 | 2.31 | 14.32 | 27.3M |
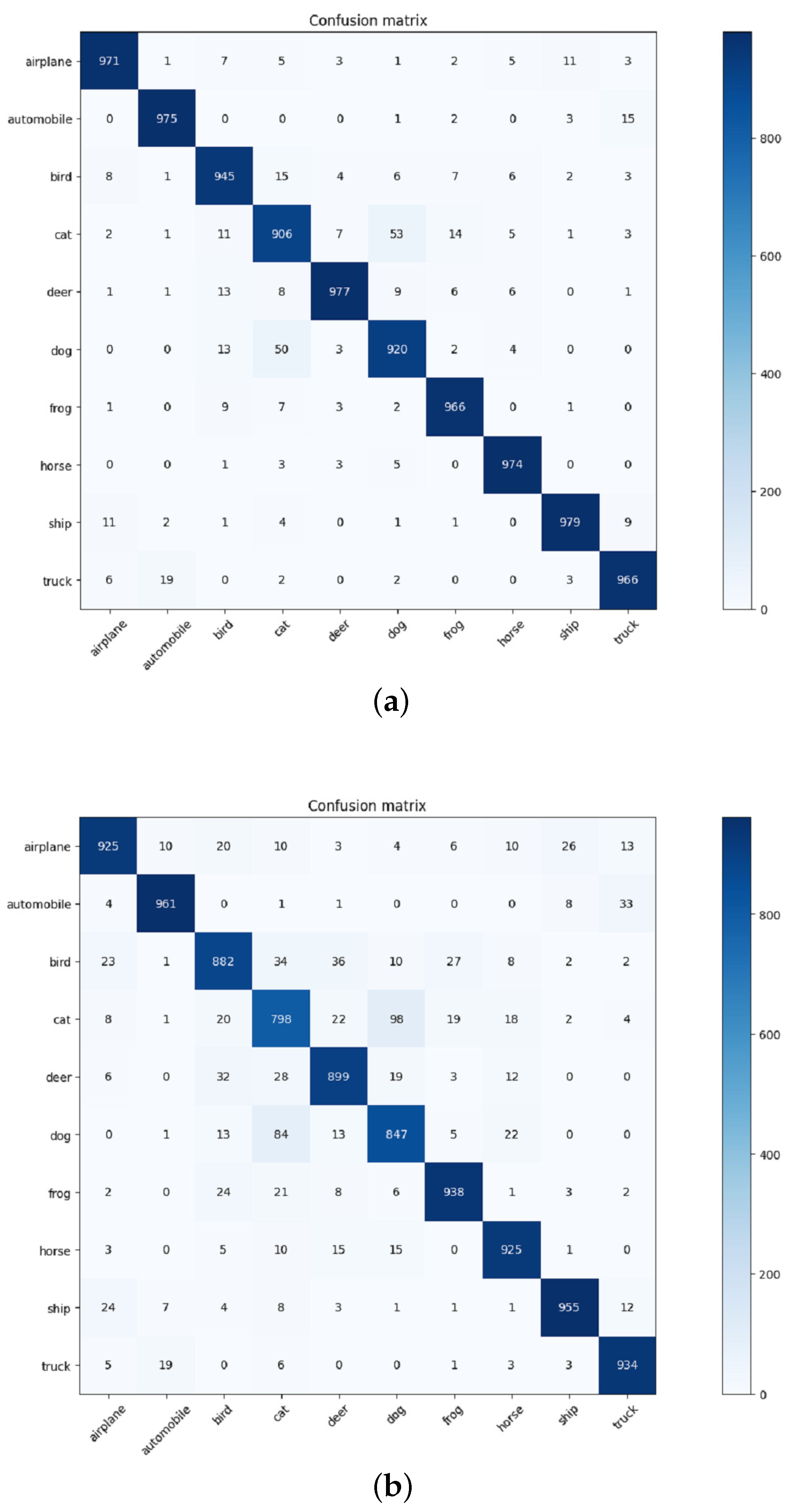
| Labels | ResNext29 | CDNet29 |
|---|---|---|
| Airplane | 925 | 971 |
| Automobile | 961 | 975 |
| Bird | 882 | 945 |
| Cat | 798 | 906 |
| Deer | 899 | 977 |
| Dog | 847 | 920 |
| Frog | 938 | 966 |
| Horse | 925 | 974 |
| Ship | 955 | 979 |
| Truck | 934 | 966 |
| Methods | Labels | Precision | Recall | Specificity |
|---|---|---|---|---|
| Airplane | 0.901 | 0.925 | 0.989 | |
| Automobile | 0.953 | 0.961 | 0.995 | |
| Bird | 0.860 | 0.882 | 0.984 | |
| Cat | 0.806 | 0.798 | 0.979 | |
| ResNext29 | Deer | 0.900 | 0.899 | 0.989 |
| Dog | 0.860 | 0.847 | 0.985 | |
| Frog | 0.933 | 0.938 | 0.993 | |
| Horse | 0.951 | 0.925 | 0.995 | |
| Ship | 0.942 | 0.955 | 0.993 | |
| Truck | 0.962 | 0.934 | 0.996 | |
| Airplane | 0.962 | 0.971 | 0.996 | |
| Automobile | 0.979 | 0.975 | 0.998 | |
| Bird | 0.948 | 0.945 | 0.994 | |
| Cat | 0.903 | 0.906 | 0.989 | |
| Deer | 0.952 | 0.977 | 0.995 | |
| CDNet29 | Dog | 0.927 | 0.920 | 0.992 |
| Frog | 0.977 | 0.966 | 0.997 | |
| Horse | 0.988 | 0.974 | 0.999 | |
| Ship | 0.971 | 0.979 | 0.997 | |
| Truck | 0.968 | 0.966 | 0.996 |
| Contributions | GFLOPs | Parameters | Top-1 Errors (%) | Top-5 Errors (%) |
|---|---|---|---|---|
| Baseline | 4.45 | 25.2M | 18.56 | 4.19 |
| +C | 4.47 | 26.4M | 16.97 | 3.93 |
| +D | 4.48 | 25.9M | 18.74 | 4.21 |
| +CD | 4.52 | 27.3M | 16.66 | 3.53 |
| Contributions | GFLOPs | Parameters | Top-1 Errors (%) | Top-5 Errors (%) |
|---|---|---|---|---|
| Baseline | 7.99 | 44.3M | 21.11 | 8.92 |
| +C | 8.00 | 46.8M | 20.57 | 7.98 |
| +D | 8.00 | 45.6M | 21.18 | 8.23 |
| +CD | 8.00 | 47.5M | 20.13 | 7.34 |
| Kernal Sizes | Top-1 Errors (%) | Top-5 Errors (%) |
|---|---|---|
| 16.66 | 3.53 | |
| 16.63 | 3.69 | |
| 16.77 | 3.83 | |
| 16.72 | 3.89 |
| Kernal Sizes | Top-1 Errors (%) | Top-5 Errors (%) |
|---|---|---|
| 20.13 | 7.34 | |
| 20.40 | 7.74 | |
| 20.72 | 8.06 | |
| 20.72 | 8.16 |
| Models | Top-1 Errors (%) | GFLOPs | Parameters |
|---|---|---|---|
| ResNeXt-50+BAM [45] | 17.40 | 4.31 | 25.4M |
| ResNeXt-50+CBAM [46] | 17.08 | 4.25 | 27.7M |
| SENet-50 [40] | 17.02 | 4.25 | 27.7M |
| SKNet-50 [17] | 16.73 | 4.47 | 27.5M |
| ResNeXt-101+BAM [45] | 15.35 | 8.05 | 44.6M |
| ResNeXt-101+CBAM [46] | 14.80 | 8.00 | 49.2M |
| SENet-101 [40] | 14.62 | 8.00 | 49.2M |
| SKNet-101 [17] | 14.20 | 8.46 | 48.9M |
| SSGD(MLP) [47] | 17.30 | / | 30.5M |
| SSGD(CNN) [47] | 13.30 | / | 51.4M |
| CDNet-50 | 16.44 | 4.25 | 27.3M |
| CDNet-101 | 13.21 | 8.00 | 47.5M |
| Models | Top-1 Errors (%) | GFLOPs | Parameters |
|---|---|---|---|
| R-Mix(ResNet-50) [38] | 22.61 | / | / |
| ResNeXt-50 | 22.23 | 4.24 | 25.0M |
| AttentionNeXt-56 [48] | 21.76 | 6.32 | 31.9M |
| ECA-Net [18] | 21.08 | 10.80 | 57.4M |
| ResNeXt-50+BAM [45] | 21.70 | 4.31 | 25.4M |
| ResNeXt-50+CBAM [46] | 21.40 | 4.25 | 27.7M |
| SENet-50 [40] | 21.12 | 4.25 | 27.7M |
| SKNet-50 [17] | 20.79 | 4.47 | 27.5M |
| ResNeXt-101 | 21.11 | 7.99 | 44.3M |
| DPN-92 [49] | 20.70 | 6.50 | 37.7M |
| DPN-98 [49] | 20.20 | 11.70 | 61.6M |
| ResNeXt-101+BAM [45] | 20.67 | 8.05 | 44.6M |
| ResNeXt-101+CBAM [46] | 20.60 | 8.00 | 49.2M |
| ResMLP-36 [39] | 20.30 | / | 45.0M |
| SENet-101 [40] | 20.58 | 8.00 | 49.2M |
| SKNet-101 [17] | 20.19 | 8.46 | 48.9M |
| CDNet-50 | 20.66 | 4.25 | 27.3M |
| CDNet-101 | 20.13 | 8.00 | 47.5M |
| Models | Training | Inference |
|---|---|---|
| ResNet-50 [50] | 1204 FPS | 1855 FPS |
| ECA-Net [18] | 785 FPS | 1805 FPS |
| ResNet-50+CBAM [46] | 472 FPS | 1213 FPS |
| SENet-50 [40] | 759 FPS | 1620 FPS |
| SKNet-50 [17] | 733 FPS | 1578 FPS |
| ResNet-101 [50] | 386 FPS | 1174 FPS |
| ResNet-101+CBAM [39] | 270 FPS | 635 FPS |
| ResMLP-36 [35] | 343 FPS | 978 FPS |
| SENet-101 [40] | 367 FPS | 1044 FPS |
| SKNet-101 [17] | 352 FPS | 1002 FPS |
| Transformer local-attention (NesT-B) [43] | 244 FPS | 566 FPS |
| CDNet-50 | 794 FPS | 1832 FPS |
| CDNet-101 | 372 FPS | 1135 FPS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, J.; Zou, R.; Wan, Q.; Xi, W.; Yang, Q.; Kodagoda, S.; Wang, S. Cross-and-Diagonal Networks: An Indirect Self-Attention Mechanism for Image Classification. Sensors 2024, 24, 2055. https://doi.org/10.3390/s24072055
Lyu J, Zou R, Wan Q, Xi W, Yang Q, Kodagoda S, Wang S. Cross-and-Diagonal Networks: An Indirect Self-Attention Mechanism for Image Classification. Sensors. 2024; 24(7):2055. https://doi.org/10.3390/s24072055
Chicago/Turabian StyleLyu, Jiahang, Rongxin Zou, Qin Wan, Wang Xi, Qinglin Yang, Sarath Kodagoda, and Shifeng Wang. 2024. "Cross-and-Diagonal Networks: An Indirect Self-Attention Mechanism for Image Classification" Sensors 24, no. 7: 2055. https://doi.org/10.3390/s24072055
APA StyleLyu, J., Zou, R., Wan, Q., Xi, W., Yang, Q., Kodagoda, S., & Wang, S. (2024). Cross-and-Diagonal Networks: An Indirect Self-Attention Mechanism for Image Classification. Sensors, 24(7), 2055. https://doi.org/10.3390/s24072055